
基于语义相似度与XGBoost算法的英语作文智能评价框架研究
2020-07-01 04:53:32吕欣程雨夏
浙江大学学报(理学版) 2020年3期
吕欣,程雨夏
(1.杭州电子科技大学外国语学院,浙江杭州310018;2.杭州电子科技大学计算机学院,浙江杭州310018)
0 引 言
英语作文能够体现学生的写作、思维和分析能力,是平时测试训练、中考、高考、四六级、托福、雅思等[1-3]各类英语考试中必不可少的重要考核内容。目前,对作文的评价大多由人工完成[4],需要花费大量教师较长的时间。由于教师每天需要评阅很多份试卷,容易产生视觉疲劳;阅卷老师的主观偏好、身体疲劳程度、心情好坏等也会干扰评阅结果[5]。因此,作文评价具有一定的主观性,在公平和公正性上难以一而惯制。
近年来,随着大数据、自然语言处理、深度学习技术的迅猛发展,计算机在理解人类语言方面也取得了一些突破性进展,例如机器翻译,文本摘要等[6]。因此,有必要将计算机技术与语言学有机结合,研发一套性能优异的自动评分系统,在保证评分客观性的同时,大大降低人工评阅工作量,节约人力和物力资源。
作文自动评分主要借助统计学、数学分析、机器学习和自然语言处理等技术对作文进行自动评估。英语作文自动评分模型主要分为三类:基于专家系统的作文评分[7]、基于文本分类与回归思想的作文评分[8]和将人工评分与机器评分相结合的评分方式[9]。
基于专家系统的作文评分,是指将语言学规则编写为计算机程序,构建专家系统,对作文进行评分。1968年,Ellis Batten Page开发了一套作文自动评分系统PEG(project essay grade),从作文中抽取量化的语言学特征,作为反映作文质量的量化指标[1-2]。但由于PEG系统的评价角度较单一,完全依赖专家给定的得分指标统计结果,没有直接评测作文的内在质量,因此打分结果有所偏颇。而且,这类基于专家系统的模型,容易被考生摸索出得分规律。尽管如此,PEG系统是第一款公开发布的商业化自动作文评分软件,对后续作文自动评分系统的研究与应用有重要影响[1-2]。国内的批改网、冰果网等作文自动评分和评语生成系统,大多也是基于专家系统的原理进行评价的[10]。
基于文本分类与回归思想的作文评分,是指先将作文映射到结构化的向量空间,再采用分类器或回归模型进行打分。20世纪90年代末,LARKEY[8]基于分类器构建了作文文本分类模型,提升了打分质量;FOLTZ[11]基于潜在语义分析(latent semantic analysis LSA)开发了智能作文评价系统(intelligent essay assessor,IEA),IEA首先构建词语的共现矩阵,再基于奇异值分 解(singular value decomposition,SVD)将待评分作文与人工评分后的标准作文一起映射到潜在语义空间,求取两类作文间的相似度,将加权后的分数作为评分结果。基于LSA的方法在一定程度上表达了文本的语义信息,但无法体现语序信息;另外,LSA没有严谨的数理统计基础,无法对文本表层信息进行量化评估,与专家系统相反,其可解释性较差[12]。文献[13]用隐狄利克雷分布(latent dirichlet allocation,LDA)对文档进行向量化降维表达,基于相似度比较构建打分模型,得到的准确度较LSA模型提升了3%~5%。文献[14]基于贝叶斯理论的分类模型构建作文评分系统,但当评分所使用的特征相互不独立时,评分效果较差。CHEN等[15]基于Text Rank对文章质量先进行预排序,再采用分类器对文章进行等级制评分。该方法能够有效识别考生对高质量词组的运用水平,但仍无法提取深层次的语义特征。魏扬威等[16]采用多种级别的语义特征进行英语作文的特征提取,如通过提取英语作文的词法特征、从句特征、句子关系特征等,构建英语作文的语言学特征,再使用自编码器对特征进行重构,并采用分层多项模型进行得分预测,但这些特征更多的是从写作技巧上对英语作文进行评价,对于写作内容方面的特征,如词汇、句子与主题的相关性等,缺乏针对性提取;刘婷等[17]从单词、句子、文章整体结构三方面进行英语作文的特征提取,并根据这些特征采用分层指标体系对英语作文进行自动评分,但特征提取方法较为简单,例如在提取单词特征时仅采用各种英语等级的单词数量、错误单词数、主题相关度等作为特征,对词义未采用分布式表征。也有将人工与机器评分相结合的作文评分方式。1990年前后,美国教育考试服务中心(Educational Testing Service,ETS)开发了E-rater系统,它与阅卷教师同时给出某篇作文各自的分数,通过一定的加权方式得到综合得分。目前,E-rater已成为被广泛关注的商业性评分系统,并成功应用于GMAT,TOEFL,GRE等考试系统[9,12]。
为了提高英语作文自动评分和评语标签生成的准确性,笔者给出了包含具体操作流程的英语作文智能评价框架,见图1。该评价框架能从词、段落、词性、篇章、主题等多个维度挖掘作文的深层语义,将训练语料库中的作文表示为综合语义特征向量,采用XGBoost算法对待评分作文进行打分,并基于语义相似度模型给出作文的评语标签。
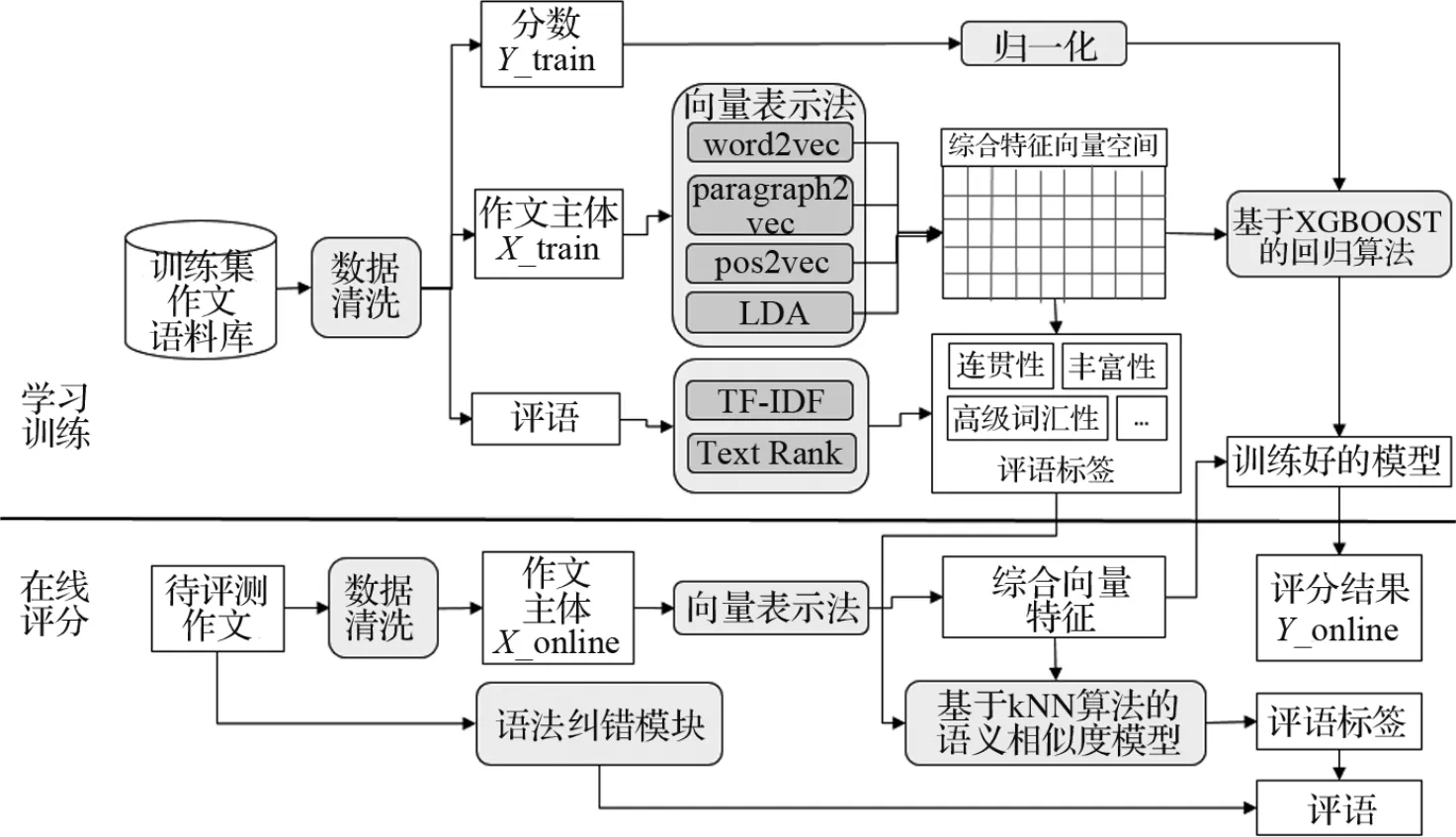
图1 基于语义相似度与XGBoost算法的英语作文智能评价框架Fig.1 Automated English essay evaluating framework based on semantic similarity and XGBoost algorithm
1 理论模型
1.1 智能作文评价框架
1.1.1 离线学习训练阶段
步骤1将N篇文档按统一编号(ID)进行归整,采用数据清洗模块检查训练语料的完整性(每篇作文需包含作文主体、评语、分数)、编码的一致性等;
步骤2对每篇作文主体文本(X_train),依次求取该作文的word2vec,paragraph2vec,pos2vec,LDA的特征向量vw2v,vp2v,vpos2v,vLDA;
步骤3将所有语义向量从左至右进行拼接,得到1×M维的综合特征向量,所有训练作文(N篇)构成N×M维的综合特征向量空间Vall=[Vw2v,Vp2v,Vpos2v,VLDA]T;
步骤4将N篇作文对应的分数(Y_train)进行归一化处理,得到1×N维的分数向量空间W;
步骤5将V和W输入XGBoost回归算法中进行训练,得到打分模型;
步骤6采用TF-IDF和Text Rank 2种算法对所有作文的评语分别计算评语标签集,得到P1和P2,取其交集P=P1∩P2作为综合评语标签。
步骤7基于kNN算法,查找与待评测作文相似的训练集作文,利用训练集作文的综合评语标签生成待评测作文的最终评语标签。
1.1.2 在线评价阶段
步骤1对待评测作文进行主体文本、编码规范、字数达标等检查;
步骤2基于已经训练好的向量库,将待评测作文主体表示为综合特征向量;
步骤3将待评测作文的综合特征向量输入训练好的打分器,得到作文评分结果Y_online;
步骤4采用基于k NN算法的语义相似度模型,找到与该作文最相匹配的前k篇作文,得到评语标签,并借助基于规则的语法纠错模块进行语法勘误,综合后给出作文的评语。
1.2 考虑分布式特征的综合特征向量表示法
以往的文本表示法,主要以one-hot编码为主,其缺点是维数过多,而且无法表示深层次的作文语义。本文采用多种分布式表示技术,从不同尺度构造文本向量,从词(word2vec)、段落(paragraph2vec)、篇章(LDA)角度抽取深层语义,共同构造综合特征向量。
1.2.1 基于word2vec的词表示法
2013年,Mikolov在Hinton的分布式语义表达基础上提出了词向量(word2vec)模型,其核心是基于Skip-Gram语言理论的三层神经网络模型(neural network model,NNM)[17]。Skip-Gram 的核心思想是根据当前词去预测其上下文可能出现的词,图2为基于Skip-Gram的word2vec模型原理图。
在给定训练词语序列w1,w2,…,w T的情况下,根据Skip-Gram原理所构造的目标函数为
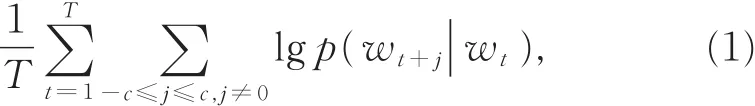

图2 基于Skip-Gram的word2vec模型原理图Fig.2 Schematic diagram of word2vec model based on Skip-Gram
其中,c指以w t为中心的训练上下文的词语数量,c越大考虑的上下文越广,需耗费的计算时间越多。通常用层次Softmax函数表示式(1)中的语言概率集合p(w t+j|w t),并采用Huffman树编码,按词频将长度为L的句子表示出来。采用该数据结构能够快速找到高频词,极大地降低了计算复杂度。
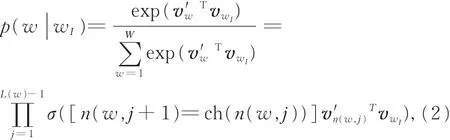
其中,v w和v′w为词w的输入向量和输出向量;W为所有词的总数;σ(x)=1/[1+exp(-x)];从j节点到根节点的路径为n(w,j),特别地,n(w,1)=root,n(w,L(w))=w。
结合图2中预测最大概率邻近词的核心思路,采用多层感知器(multi-layer perceptron,MLP)神经网络模型求解目标函数(2),根据输入词向量v w,预测输出词向量v′w,即
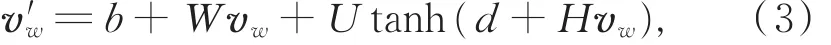
其中,tanh是神经元激活函数,b,d,W,U,H均为待求解参数。参数集的寻优可采用随机梯度下降(stochastic gradient descent,SGD),遗 传 算 法(genetic algorithms,GA)等求解。
对于词性向量(pos2vec,part of speech to vector),将给定词语序列w1,w2,…,w T对应的词性序列表示为ps1,ps2,…,psT,其中,词性主要包括:名词(n),动词(v),形容词(adj),副词(adv)等。该特征主要从词性角度考核作文的词语搭配合理性。
1.2.2 基于paragraph2vec的段落表示法
Paragraph2vec的核心计算原理与word2vec一致,均基于MLP模型,在求取目标函数(1)的过程中得到建模对象的向量,其差别在于建模对象的选取。为了更多地考虑单词排列顺序对语义的影响,paragraph2vec引入了paragraph id,使每个句子都有唯一的id,如图3所示。给定paragraph id,统计上下文中出现4个词的概率,即把句子的位置也当成一项重要特征,以记录段落之间隐含的语义。
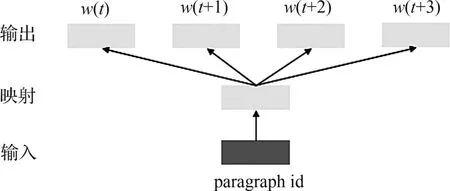
图3 Paragraph2vec模型原理图Fig.3 Schematic diagram of paragraph2vec model
在训练步骤中,只需在式(1)的词语序列前增加id的特征,即 paragraph id,w1,w2,…,w T,后续的参数求解步骤不变。
1.2.3 基于LDA的篇章表示法
LDA模型是一种生成式的主题模型,是由词语、主题、文档构成的三层贝叶斯概率模型,其核心在于如何计算给定文档的主题变量(即隐变量)的分布[18]。参数的具体估计过程如图4所示。
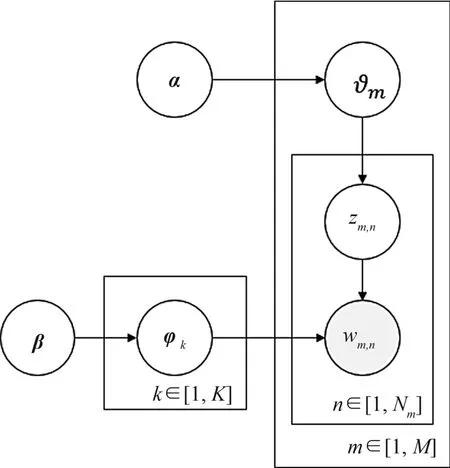
图4 LDA的概率图模型Fig.4 Probability graph model of LDA
图4 中,各参数之间满足:
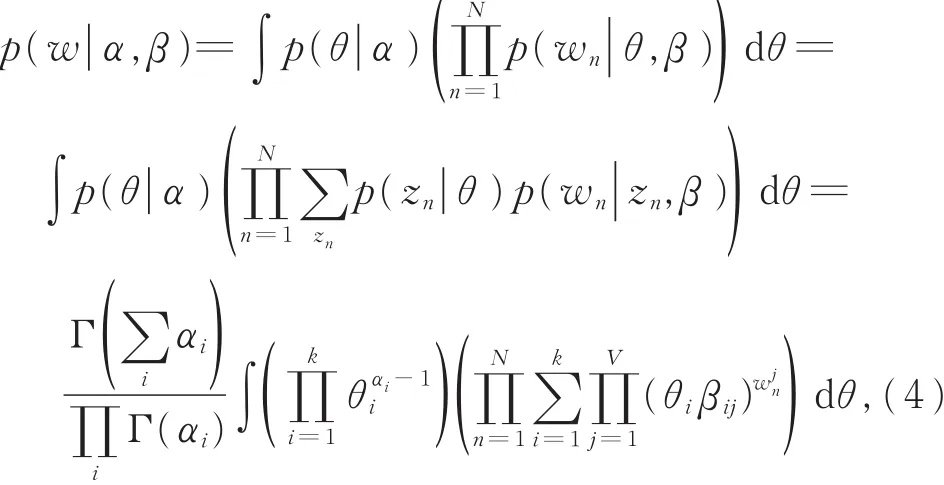
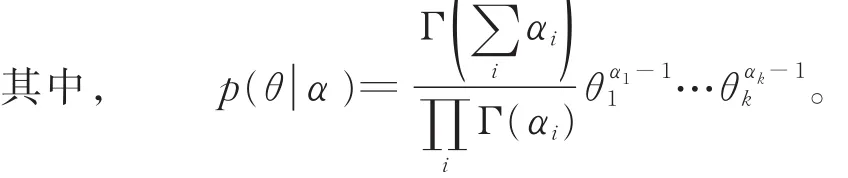
以下为LDA模型的计算步骤:
步骤1基于共轭理论,采用Dirichlet计算每个主题上特征词的多项式分布φ=Dir(β),即参数β刻画了该分布;
步骤2基于Poisson分布,估计每篇作文特征词语的规模 N=Poisson(ζ);
步骤3基于Dirichlet分布,估计每篇作文中主题分布概率向量ϑ=Dir(α);
步骤4对于第m篇作文(m=1,2,…,M;M为作文总数)的某特征词w,从主题分布概率向量ϑ中随机抽取某主题z,再从z中挑选一个特征词w。最后通过期望最大化(EM)方法对参数α,β进行最大似然估计,从而建立LDA三层模型。
综上所述,LDA通过构建概率模型,对主题分布ϑ和特征词分布φ之间的关系进行描述。上述2个变量可以通过Laplace近似估计、变分推理、Gibbs采样等方法得到。最终由LDA主题模型得到的语义向量来描述“文本-主题-特征词”之间的量化关系。
1.3 XGBoost算法原理
与传统 GBDT(gradient-based decision tree)方法相比,XGBoost在误差逼近和数值优化两方面都进行了改进,近年来,在各类基于机器学习的应用和比赛中,XGBoost已成为最受欢迎的方法之一。
假设有k棵树组成模型:
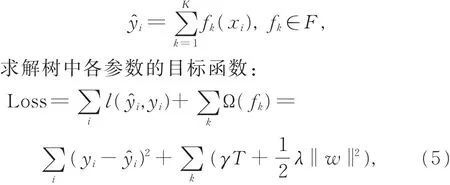
其中,Ω(fk)包含两部分:参数γ反应叶子节点数量T对误差的影响;参数λ反应叶子节点权重w对误差的影响,此处采用L 2正则化,以防止叶子节点过多出现过拟合现象。目标函数(5)的详细求解过程参见文献[20]。
1.4 基于k NN算法的作文评语标签生成方法
基于kNN算法的作文评语标签生成方法的总体思路是:首先,通过TF-IDF方法和Text Rank方法筛选出训练集中每篇作文的若干个典型评语标签;然后,用1.2节中的综合特征向量表示待评测作文和所有训练集作文,并比较待评测作文与每篇训练集作文特征向量的余弦相似度;最后,选取kNN算法的k值,将与待评测作文相似度较高的前k篇训练集作文的典型评语标签去重后,形成待评测作文的评语标签。具体步骤如下:
步骤1针对第i篇作文的评语Ci,采用TFIDF方法(式(6))计算各评语短句的TF-IDF权重值,按从大到小排序,得到一组评语短句序列:
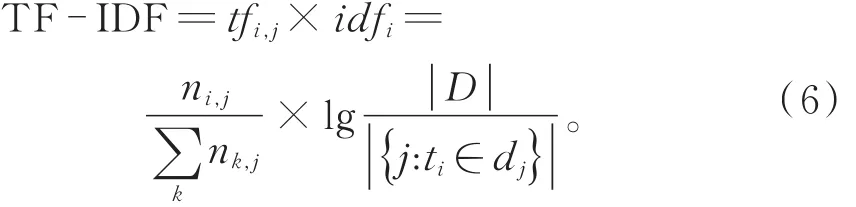
步骤2采用Text Rank方法(式(7))计算各评语短句的TR权重值,按从大到小排序,得到一组评语短句序列KTextRank:
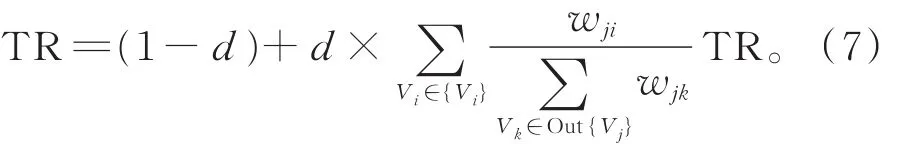
步骤3分别将TF-IDF权重值排在前n位的评语短句记为,将TR权重值排在前n位的评语短句记为,取交集得到该篇作文的综合评语短句序列,依此类推,计算得到所有作文的综合评语短句序列。
步骤4图1中,在线计算评语时,将待评测作文i的综合向量vaill与训练库中各作文的综合向量进行相似度计算(式(5)),并按照从大到小的顺序进行排序:
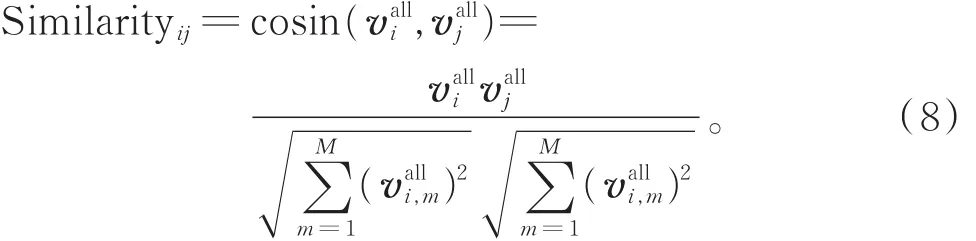
步骤5最后,基于k NN算法的思想,选取相似度排名前k位的评语短句,并去除重复的短句,组合为该作文最后的评语。
2 实验效果
从某高校面向四级考试进行写作训练的英语作文中收集了900篇进行实验,具体情况如表1所示,作文单词数在150~200。为了保证原始标签的准确性与公平性,要求2位老师分别对每篇作文进行评分,求取该作文的平均得分,将2位老师的评语进行汇总得到综合评语。最后得到每个得分区间的作文数量,如表2所示,平均每篇作文包含7.2条评语短句。

表1 各种主题的作文数量Table 1 Number of essays on various topics
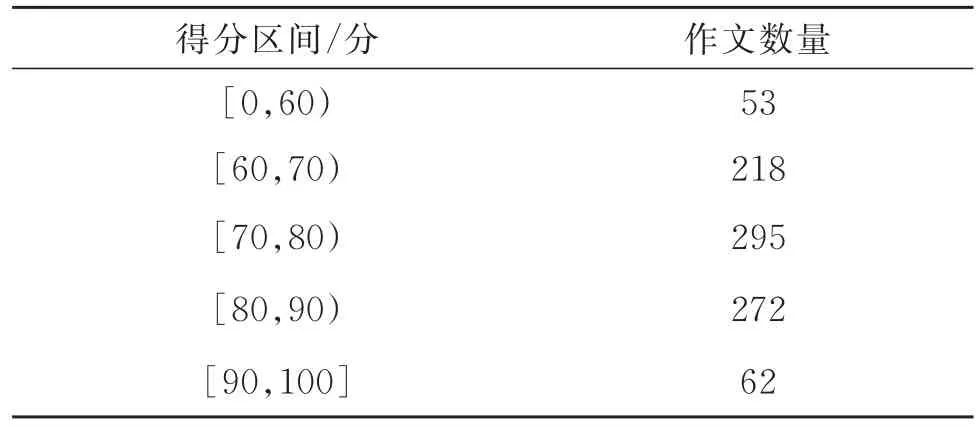
表2 各得分区间的作文数量Table 2 Number of essays in each score range
根据图1的技术路线,将900份作文平均分成5份(即每份180篇),随机取其中4份(即80%)作为训练样本,剩余1份作为测试样本。采用5轮交叉验证的方式循环训练和测试5次,每次得到一份评价指标,将5次指标的平均值作为评分结果。本文方法的打分效果与以往几类评分方法效果的比较见表3,其中,本文方法的输入特征包括四部分:

表3 各类作文评分方法的评分效果Table 3 The scoring effect of various essay scoring methods
word2vec,paragraph2vec,pos2vec和LDA,分别取50维、100维、20维、100维,则第i篇作文的综合特征向量为valli=[vw2v,vp2v,vpos2v,vLDA],即 1×270 维的向量。从表3中可以看出,相比其他方法,本文方法评分结果具有最小的均方误差和最大的皮尔逊相关系数,说明本文方法与教师评分结果的误差最小,且相关性最高。
在评语标签生成过程中,对TF-IDF权重值和Text Rank权重值前5位的综合评语短句取交集,并将其作为综合评语短句序列,采用k NN算法,取k=3,给出待评价的作文评语。比较新方法生成的作文评语标签和教师评语,统计其平均准确率(precision)、召回率(recall)和F-score,并与单独使用TF-IDF和Text Rank方法进行了对比,结果如图5所示。
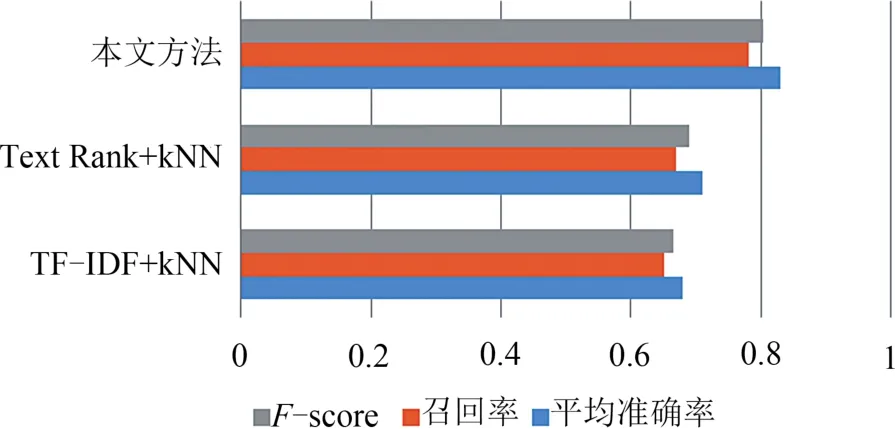
图5 作文评语标签生成方法效果对比Fig.5 Comparison of essay comment label generation methods
由图5可知,本文方法通过结合TF-IDF方法和Text Rank方法,有效筛选出了典型的英语作文评语标签,较采用单一标签提取算法有较大优势,同时借助k NN算法使英语作文评语生成的准确性达到了较高水平(F-score大于0.8)。将主要的评语标签(出现次数超过 3次)按 5个评分等级,即[0,60),[60,70),[70,80),[80,90),[90,100]进行聚类,其可视化图见图6。
图6体现了不同分数等级中,学生作文的一些集中特点,如分数偏低的普遍小错误较多、语言不流畅、词汇使用或拼写存在问题等。相邻分数区间的评语标签有一定的重叠性,跨分数区间的评语差异性较大。
3 结 论
提出的英语作文智能评价框架的主要创新点在于 :结 合 了 word2vec、pos2vec、paragraph2vec和LDA等文本表示技术生成英语作文的综合特征向量,能够对英语作文多维度的语义特征进行深层次提取,为作文评分和评语标签生成提供依据;采用了较为先进的XGBoost模型和结合TF-IDF、Text Rank和k NN算法的语义相似度模型进行评分和评语生成,提高了英语作文自动评分和评语标签生成的准确性。另外,通过框架流程的合理设计,使综合特征向量可以同时用于英语作文的评分和评语标签生成,有效降低了框架的模型复杂度。
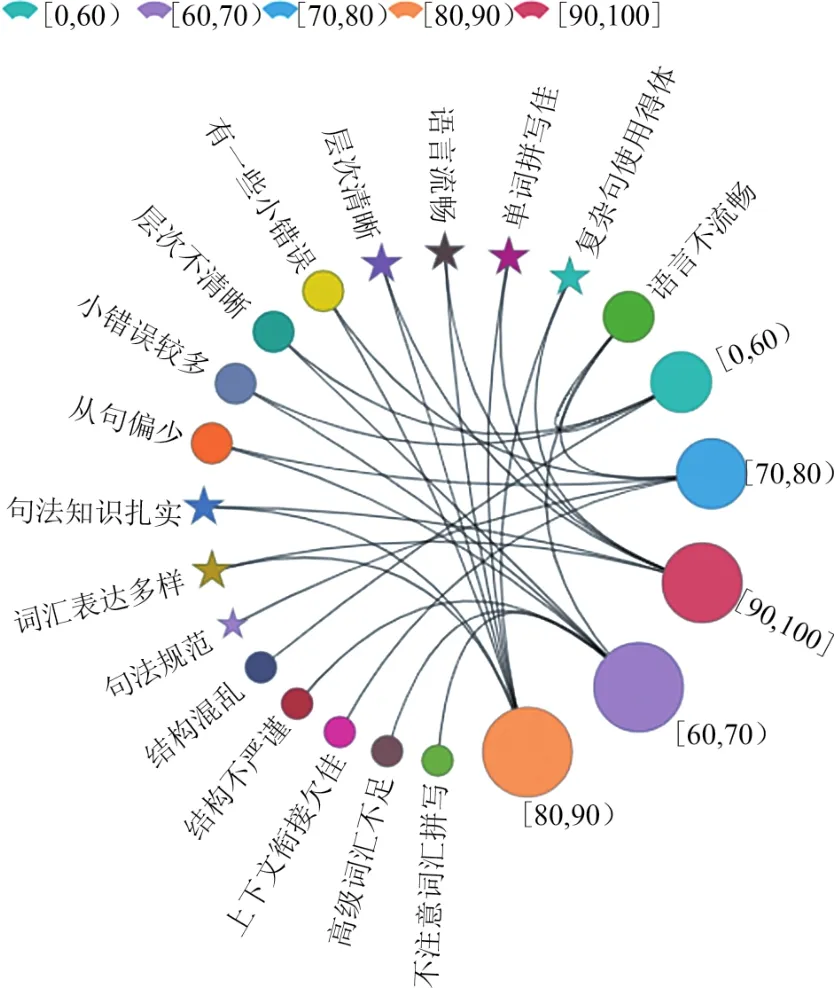
图6 评分等级对应的作文评语标签聚类Fig.6 Clustering of essay comment labels corresponding to scoring levels
在本文的评价框架中,还有一些语言类的特征没有考虑在内,如基于依存句法/语法的特征,以后可将其加入到特征向量中,以提升评分指标;还可以研究综合向量特征与评语标签、学生常用词句的关系,对常见问题、常犯错误和高分用法进行关联性挖掘,以便针对性地指导学生进行规范写作。
猜你喜欢
十几岁(2022年34期)2022-12-06 08:06:24
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
四川文学(2020年11期)2020-02-06 01:54:52
娃娃画报(2019年8期)2019-08-05 18:21:56
娃娃画报(2019年8期)2019-08-05 18:21:56
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
散文百家(2014年11期)2014-08-21 07:16:36
中学教学参考·语英版(2008年8期)2008-11-26 10:42:12
