
基于组合核函数的高校经济困难生分类
2020-05-11 09:02莫媛媛顾明言张辉宜
安徽工业大学学报(自然科学版) 2020年1期
莫媛媛,顾明言,张辉宜
(安徽工业大学信息化处,安徽马鞍山243032)
对家庭经济困难生的资助是促进教育公平公正的重要举措,也是高校实施中央“精准扶贫”工作的具体体现[1-2]。准确地评估在校生经济状况是实现高校经济困难生资助的决定性基础,国内部分学者和机构对评估在校生经济状况的方法进行了一定程度的研究。早期阶段,多采用选取特定指标、关联分析等方法对在校生的经济情况进行评估,如余鸣娇等[3]结合层次分析法原理设计一种多指标的层次模型并对指标进行量化,构建了经济困难生认定的指标体系;董丽娟[4]采用基于关联规则的决策树改进算法对在校生的经济情况进行分析,并将其应用到经济困难生的评选中,取得了较好的效果;任俊等[5]以问卷调查结果为依据,采用多粒度粗糙集分析出影响高校经济困难生评定标准的关键因素;李斌等[6]在分析高校智慧校园系统中一些有效数据的基础上,定义特定的预测因子,通过贝叶斯网络技术对高校学生的贫困等级进行分类预测。
伴随着大数据技术的快速兴起,高校在信息化迅速发展的过程中也积累了大量数据。在此背景下,部分学者将大数据理论应用到高校经济困难生的评定中,如吴朝文等[7]对大数据环境下经济困难生的资助模式进行了探讨,通过分析学生消费行为以实现对经济困难生资助体系的验证评估及特殊困难生的预警;夏杨等[8]以历史累积的海量一卡通数据为基础,借助当前流行的Hadoop技术构建了校园大数据分析平台,并将学生行为数据的分析结果用于经济困难生资助等级的预测;杨胜志[9]通过分析当前高校经济困难生资助工作存在的问题,综合考虑高校海量数据的社会价值及其独特优势,提出大数据环境下的经济困难生认定策略。但目前利用校园一卡通数据进行高校经济困难生资助的研究仍处于初始阶段,对于一卡通消费数据中特征较少、部分在校生的消费行为相似存在分类困难的问题。支持向量机(support vector machines,SVM)是建立在统计学习理论上的机器学习算法,其在处理小样本、不平衡样本、非线性和高维数据等方面上具有较大的优势,能够有效避免“维数灾难”和“过拟合”等问题[10-11]。基于组合核函数的SVM可以结合各核函数的优势,且在图像识别、文本分类、机械故障诊断等领域得到了广泛应用[12-14]。鉴于此,文中在校园一卡通消费特征的基础上,结合SVM 算法优势和高校在校生消费数据特点,构建基于组合核函数SVM 的高校经济困难生分类模型,探讨一种基于组合核函数SVM的高校经济困难生分类方法。
1 基于组合核函数的SVM分类模型
1.1 组合核函数的构造
核函数是SVM理论中的关键组成部分,直接决定SVM处理非线性数据的能力,进而影响SVM分类器分类效果的优劣。SVM中常用的核函数有:
线性核函数(linear kernel,KL)

多项式核函数(polynomial kernel,KPoly)

高斯径向基核函数(radial basis function kernel,KRBF)

多层感知器核函数(sigmoid kernel,KSig)

其中:为x,xi为相同维度的向量;q为多项式核函数的阶数;exp 为指数函数;σ为RBF 核函数的核半径;tanh 为双正切函数;ν为Sigmoid核函数系数;g为偏移量。通常SVM在分类时主要使用单一核函数构造分类器,然而,单一核函数均具各自的优点和不足,难以使分类效果达到最佳。对于n种不同核函数,其线性组合也是核函数。因此,结合各个核函数的优势将不同核函数进行组合,使分类器兼具多个核函数的优点,以提高分类准确率和模型的泛化能力。组合核函数K(x,x0)表示形式为[15]

其中:λ为组合核函数系数;n为核函数个数。
研究表明[16],线性核函数精度较低;RBF核函数局部信息拟合能力强、泛化能力差;多项式核函数的推广能力强,但局部学习能力差。故文中综合考虑各核函数的特点,将RBF核函数和多项式核函数进行组合生成组合核函数,具体形式为

其中α为核函数的权重系数,且0 ≤α≤1。
训练时采用分类准确率作为模型及参数优劣的评价标准,假定某类中的测试样本数为M,分类正确的样本数为N,则该模型在本类中的分类准确率A为

1.2 最优核参数及核函数组合系数
文中构造的组合核函数式(6)中,主要参数有RBF 核函数的核半径σ、多项式核函数的阶数q和组合核函数的权重系数α。在支持向量机优化问题中,惩罚因子C对模型的泛化能力也有重要影响。为确定上述4 个参数,文中采用多重网格搜索法[17]训练模型获取最优的参数以使组合核函数构造的SVM 分类效果最佳。组合核函数参数寻优过程如图1,主要步骤如下:
1)初始化组合核函数SVM参数C,σ,q,α的范围,设置最优核参数的初值、分类准确率初值、搜索网格的层数及搜索步长;
2)使用网格搜索算法生成核参数矩阵;
3) 判断是否完成参数寻优,如满足,转至步骤7);
4) 遍历核参数矩阵,构造组合核函数SVM 分类器,并计算分类准确率;
5) 判断是否满足核参数更新条件,如不满足,转至步骤4);
6)更新最优核参数值,转步骤3);
7)输出最优组合核函数SVM的最优参数值(C,σ,q,α)。

图1 基于多重网格搜索算法的组合核函数参数寻优流程图Fig.1 Optimization flow chart of combined kernel function parameters based on multigrid search algorithm
2 实验与结果分析
不同性别的学生消费差异较大,且历史受资助情况也会对在校生的日常消费产生影响,所以在校园一卡通数据的基础上,综合考虑学生性别、历史资助信息,构建基于组合核函数的SVM分类模型对在校生的经济情况进行分类。
2.1 实验数据预处理
选取最近一年在校生的一卡通消费数据、个人基本信息及历史资助信息。对于一卡通消费数据,首先去除冗余数据,删除如卡充值、卡延期等非消费记录;然后,将消费分为饮食、购物、水费、电费、网费、图书打印、医疗费等类别;再按日汇总在校生不同类别的消费额,根据学校教学日历,结合每年的教学时长,剔除消费时长较短的在校生日常消费数据。由于饮食消费、购物消费占在校生消费总额的90%以上,与其他类别消费存在数量级上的差异,为使分析结果准确,对不同类别的消费数据进行归一化处理,文中采用式(8)对不同类别的消费数据进行处理,生成日常消费样本特征数据。对于性别特征,女生初始化值为0,男生为1。由式(9)获取在校生获取资助的平均值,经式(8)处理后将其作为历史资助特征的初始值。


其中:Y为消费数据的归一化值;X为消费值;Xmax为最大消费值;Xmin为最小消费值;y为资助平均值;x为资助金额;s为资助人数。
从历史经济困难生中选取一卡通消费符合月均消费额在200元以上及月均消费时长超过20 d的一般困难生300人、中等困难学生300人、特别困难学生300 人及随机挑选非经济困难学生300 人,按日均消费额绘制各类经济困难生的消费情况分布,如图2。从一卡通数据库及学工系统中获取相关在校生的一卡通消费记录、基本信息及历史获资助信息,并按上述步骤构造样本数据,共1 200个样本记录;选用其中的900条数据作为训练数据,剩余部分作为测试数据。
2.2 实验设计及参数确定
在Python 环境下基于Sklearn 工具包开发分类模型并进行训练和测试,实验平台硬件配置为CPU i7-8550U,1.99 GHz,内存8 GB。主要设计2组实验:选取仅包含一卡通消费特征集合的样本和融入性别特征、历史资助特征的样本,分别构建基于单一核函数的SVM 分类器和基于组合核函数的SVM 分类器进行分类测试;相同实验条件下,分别使用逻辑回归分类器、KNN算法和基于组合核函数SVM进行分类,获取分类准确率。
实验过程中采用多重网格搜索法即如图1所示的流程确定最优参数,粗选阶段各参数的初始范围及搜索步长分别为:C∈[1,100],步长为5;σ∈[0,50],步长为2;q取值为1,2,3;α∈[0,1],步长为0.1。最佳参数C=18,σ=5,q=3,α=0.7。细选阶段各参数的起始范围及搜索步长分别为C∈[1,50],步长为1;σ∈[0,10],步长为1;q=3;α∈[0,1],步长为0.01。最佳参数为C=26,σ=8,q=3,α=0.7。对比实验中多项式核函数参数q=3,RBF核函数参数σ=8。
2.3 实验结果与分析
2.3.1 不同类型特征的分类结果
表1为针对原始特征、融合特征分别采用多项式核函数、RBF核函数、组合核函数SVM分类的结果。

图2 不同类别困难生的日均消费额分布Fig.2 Distribution of average daily consumption of different types of difficult students
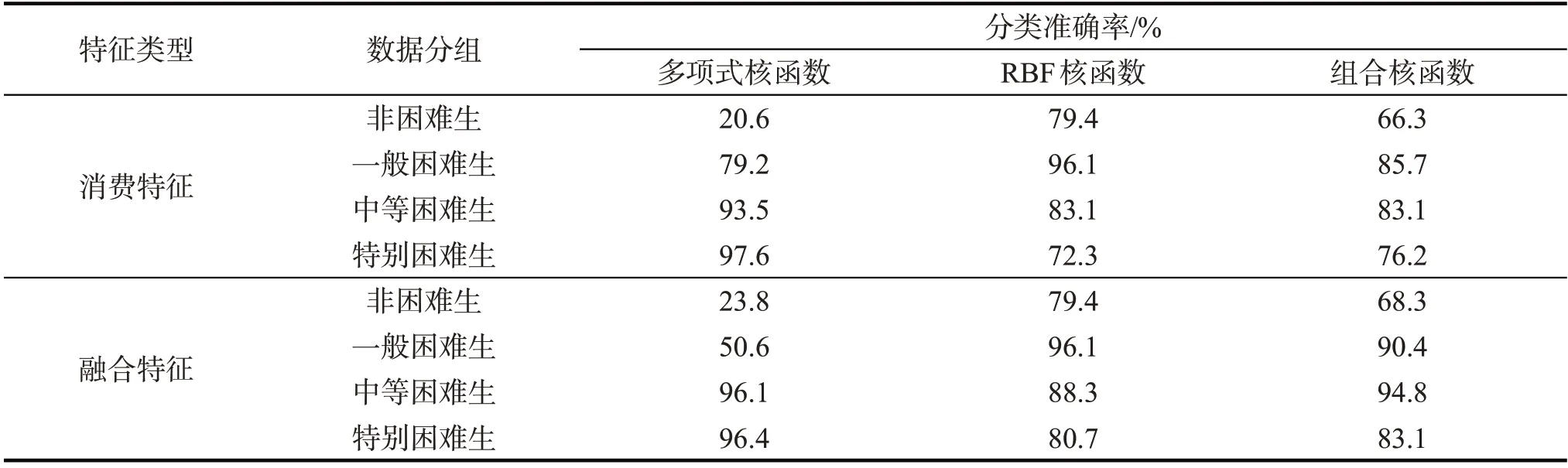
表1 基于不同特征与核函数的分类准确率Tab.1 Classification accuracy with different features and kernel functions
由表1可知:多项式核函数SVM在非困难生与一般困难生的样本中分类准确率较高,RBF核函数SVM在中等、特别困难生样本上的分类表现较好,组合核函数SVM分类整体效果优于多项式核函数与RBF核函数;基于组合核函数的SVM分类器在对一般经济困难生和非经济困难生的分类中,准确率提升相对其他两类经济困难生高,说明对于特征值相似度较高的样本,组合核函数兼备RBF核函数和多项式核函数的优点;相对于仅使用原始特征的样本数据,使用包含在校生的性别特征、往年受资助信息的特征集数据,3组分类模型对经济困难生的分类准确率均有一定程度的提升,且组合核函数对融合性别、受资助信息的特征数据集具有更强的适应性。
2.3.2 核函数参数对分类结果的影响
表2为在不同核参数值时,多项式核函数、RBF及组合核函数SVM的分类结果。由表2可看出:核参数的变化对多项式核函数SVM和RBF核函数SVM的分类效果有较大的影响,当参数q增加时,多项式核函数SVM在非困难生及一般困难生样本上的分类急剧下降;参数σ减小,RBF核函数SVM在中等困难生与特别困难生样本上的分类准确率有明显的降低,而组合核函数SVM的表现受参数变化的影响较小,反映出组合核函数具有较强的鲁棒性。

表2 不同核参数取值时的分类准确率Tab.2 Classification accuracy with different values of kernel parameters
2.3.3 不同分类器的准确率
采用逻辑回归模型、最近邻算法(KNN)及文中构建的组合核函数等3种分类器对高校经济困难生分类,结果如图3。由图3 可看出,组合核函数的分类准确率优于其他两种分类器。由于样本的非线性,使得逻辑回归模型的分类效果较差;部分在校生的消费行为相似,造成使用最近邻算法进行分类时,分类错误的概率增大。由此表明,相同实验条件下,组合核函数SVM在文中的分类场景中具有较大优势。
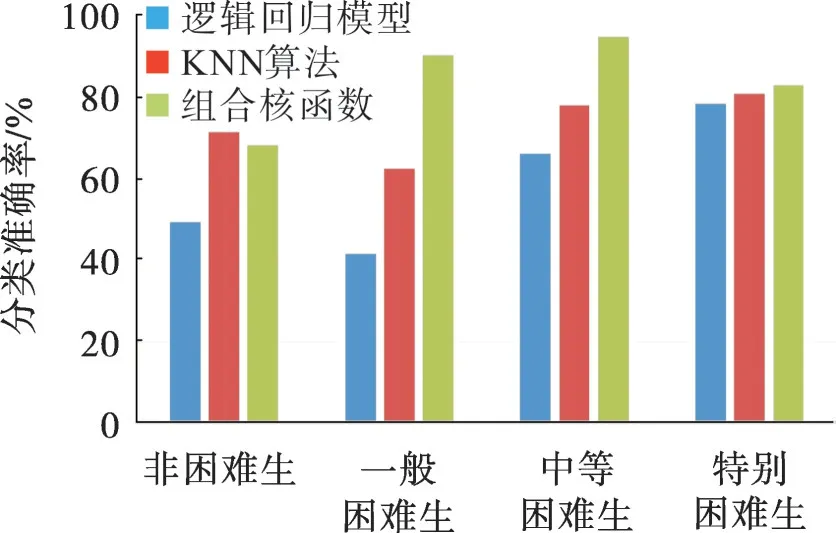
图3 不同分类器的分类结果Fig.3 Classification results of different classifiers
3 结 论
在一卡通消费数据特征的基础上,综合考虑在校生的性别、历史受资助信息,结合RBF核函数局部学习能力强的特点及多项式核函数泛化能力强的优势,构建基于组合核函数的高校经济困难生分类模型。实验结果表明:基于组合核函数SVM可对在校生的经济情况进行较准确的分类;使用融合特征可以增加不同类别样本数据的差异性,能够提高分类准确率,构建的模型对高校经济困难生分类的准确率高于其他分类器模型。同时,对于RBF核函数及多项式核函数的组合核函数SVM分类模型,其模型参数是否全局最优需进一步研究;学生消费数据不完善,部分第三方支付的数据未被采集等问题有待后续逐步解决。
猜你喜欢
锦州医科大学报(2022年3期)2022-06-06
电子产品世界(2022年4期)2022-04-21
科教新报(2021年9期)2021-05-17
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
卫生职业教育(2019年6期)2019-03-14
现代职业教育·高职高专(2017年9期)2017-07-09
科技视界(2015年24期)2015-08-22
新高考·高一物理(2015年5期)2015-08-18
