
基于深度学习的高鲁棒性恶意软件识别研究
2020-04-25 10:59彭伟
信阳农林学院学报 2020年1期
彭伟
(安徽工贸职业技术学院 计算机信息工程系,安徽 淮南 232007)
由于恶意软件的攻击导致的安全漏洞继续升级,构成了这个数字时代的一个主要安全问题。恶意软件攻击呈指数增长,许多计算机用户、企业和政府受到影响,因此恶意软件检测是一个热门的研究课题。当前,基于恶意软件签名和行为模式的静态、动态分析的恶意软件检测解决方案非常耗时,并且无法实时识别未知恶意软件。而且恶意软件会使用变形等规避技术来快速更改恶意软件行为并生成大量新恶意软件。为了实现高效、全自动的恶意软件识别系统,研究者们开始采用数据挖掘和机器学习技术。深度学习算法具有强大的学习能力,本文基于堆叠自编码器,提出了一种高鲁棒性恶意软件识别算法。自编码器是一种无监督的学习方法,与图神经网络等半监督学习算法相比,自编码器有着更低的训练成本,且能够学习并识别未知的恶意软件,具有更好的鲁棒性。
1 恶意软件识别算法
所提识别算法的流程如图1所示,由三个阶段组成,即特征选择阶段、图生成阶段和深度学习阶段。
1.1 数据集特征选择阶段
创建了一个包含1078个正常软件和128个恶意软件样本的数据集。所有恶意软件样本均来自威胁情报平台,所有正常软件来自各种官方App商店。
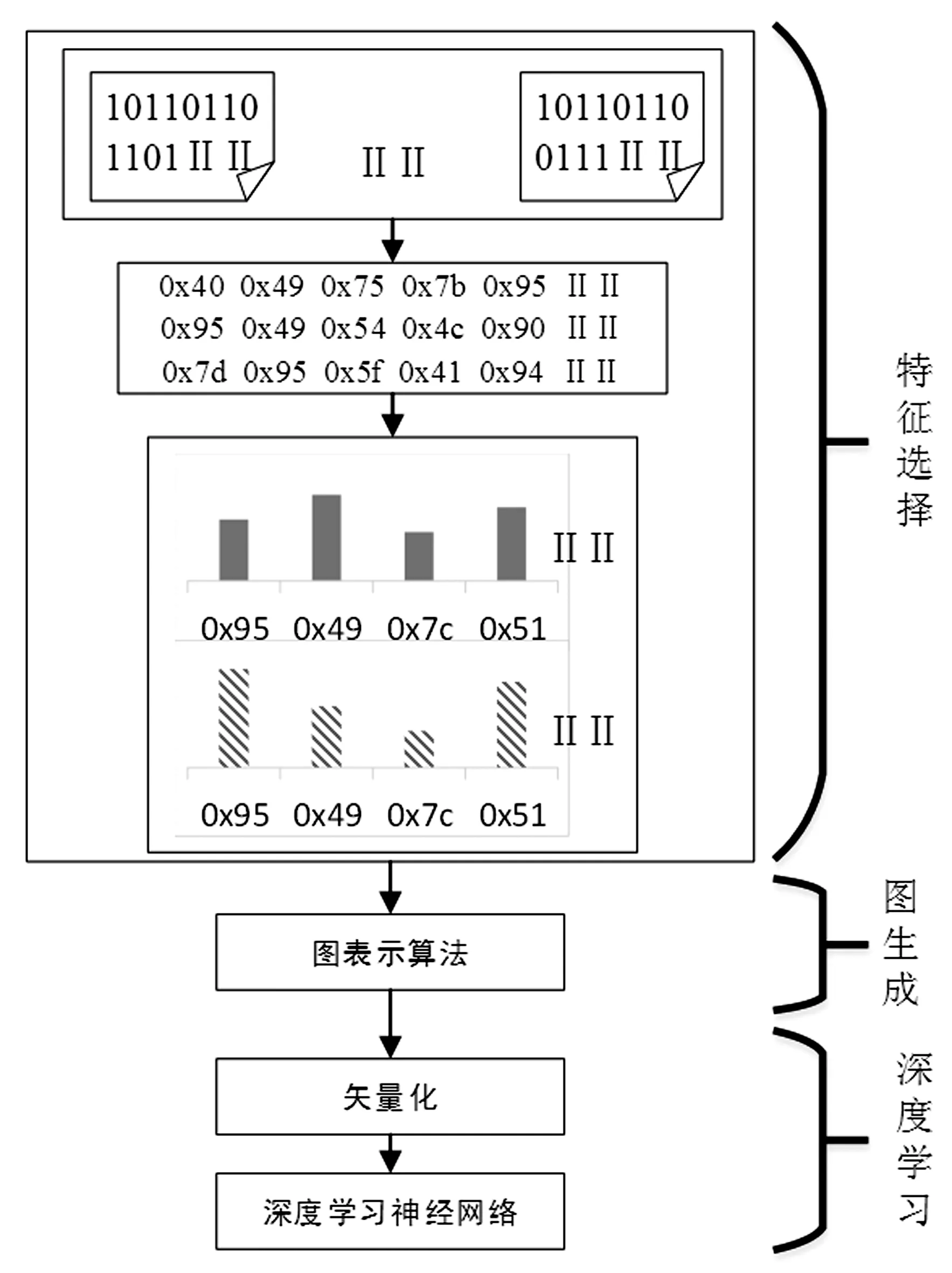
图1识别算法流程
应用程序包含一系列的操作码,这些操作码是在设备处理单元上执行的指令。利用Objdump作为反汇编程序来提取操作码s。创建n元模型操作码序列是基于反汇编代码对恶意软件进行分类的常用方法[1]。长度为n的基本特征的数量是Cn,其中C是指令集的大小。因此,n的增加将导致特征数量剧增,减小特征的大小能增加了检测的鲁棒性和有效性。
因此,需要先应用特征选择算法找到最佳特征,以减少特征集。信息增益(IG)是一种信息理论方法,通过根据分类问题中可用的信息内容量对它们进行排序来选择全局特征。IG使用统计工具来选择全局特征,而不考虑类别信息。但在数据集不平衡的情况下,全局特征选择方法忽略了类别特征,这可能会使系统效率降低。
因此,为了兼顾类别信息,采用类信息增益(CIG)[2]来克服全局特征选择不完善问题,其计算方式如公式(1)所示。
(1)
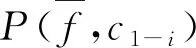
提取了操作码序列的1元模型和 2元模型,其数量分别为4543个和610109个。与此同时,还分别计算了信息增益CIG(f,ci)和CIG(f,c1-i)。由于第80个特征和第81个特征的信息增益的差别较大,因此选择了前80个特征。
1.2 图生成阶段
控制流图(CFG)是一种数据结构,表示可执行文件中操作码的顺序。图G=(V,E)由节点集合V和边集合E组成。现有研究表明,图的表示方式在恶意软件检测中是很有用的[3]。Vi∈{fj|j=1,2,…,80}是顶点,而边Eij的值表示顶点(特征)Vi和Vj之间的关系。
为了构造操作码s图,首先需要计算边的值。通常,当样本操作码序列中的Vi出现在Vj之后时,Eij的值会增加1。这样一来,将能为数据集中的每个样本应用程序生成邻接矩阵。在对矩阵的行进行归一化后,Eij的值将变成了Vi出现的概率。
这种做法虽然简单,却有比较明显的缺点。对于某些软件的操作码来说,在特征选择后简单地将Eij值递增1会产生一个稀疏的邻接矩阵,这种稀疏的表示方式并不适合分类任务。此外,恶意软件开发人员可能会注入无用的垃圾操作码,致使算法产生错误的图。
因此,提出了一个启发式规则来计算边的值,如式(2)所示。该启发式规则的基本要素是操作码s之间的距离:较长的距离会产生较小的Eij。α是调整操作码距离影响的权重参数。此外,α可以控制操作码s距离对检测率的影响。式(2)将为每个给定的恶意软件和良性样本生成82个顶点的图形,作为该方法的深度学习阶段的输入。算法1描述了每个样本的图生成过程。
(2)

算法1输入:样本sample, 特征feature输出:图G1:k =|feature|;2:G =⌀3:for i in k do4: Vi=Fi5: for j in k do6: Vi=Fi7: CalEdgeValue(); //利用公式(2)计算边的值8: end for9:end for10:Normalize(G); //归一化11:return G;
1.3 深度学习阶段
1.3.1 矢量化 作为用于表示顶点之间关系的复杂数据结构,图是机器学习中的普遍数据类型,不过很少有数据挖掘和深度学习算法接受图作为输入[4]。因此,一种可能的替代方案是将图形嵌入向量空间。
2017年6月,在湖南通道县木脚青钱柳生产合作社基地采集7年生青钱柳老叶(枝条顶端倒数的第6~8片绿叶)与嫩叶(新冒芽的两叶一心),每个样品来自3个不同的单株.收集到的样本立即在液态氮冷冻、储存在-80℃.使用mirVana 试剂盒 (Ambion公司)提取总RNA.使用Agilent 2100生物分析仪(Agilent Technologies,Santa Clara,CA,USA)评估RNA完整性,RNA 完整性较好的样品 (RIN≥7)用于进行后续分析.
特征向量和特征值是图谱中的两个特征元素,它们可以将图的邻接矩阵线性转换为向量空间,如式(3)所示。
Av=λv
(3)
其中,v、λ和A分别表示特征向量、特征值和图的邻接。为了获得生成的CGF结构的信息,创建了一个图以阐述数据集中所有样本的累积。该图由两个主要的对角构建块(用红色边框标记)组成,表明给定的样本中存在两个主要数据分布。基于图的谱理论,在这种情况之下,矩阵的特征值之间存在一个明确的特征值差。
因此,与其他剩余的特征向量相比,具有较大特征值差的两个特征向量包含了更多邻接矩阵的信息,可以用来表示整个矩阵。此外,在学习阶段,由于恶意软件和正常软件特征值的数据分布不同,将使用特征值提高识别算法的性能。
1.3.2 深度学习算法 深度学习(DL)是神经网络(NN)的进化版本。标准NN包括几个或多个简单的、相互连接的神经元节点。DL专注于隐藏层的能力和功能,专注于更深入的数据结构学习。深度学习最近已被用于各种应用,例如语音识别和机器视觉。虽然基于浅层学习架构的分类方法(如支持向量机、贝叶斯分类器、决策树和人工神经网络)可以用于恶意软件的识别,但是深度学习由于其强大的学习能力,可以实现更好的性能。典型的深度学习模型包括堆叠自编码器、深度信念网络、卷积神经网络等。探讨了一种采用堆叠自编码器的深度学习架构,该架构是由一组自编码器组成。
自编码器是一种用于学习有效编码的人工神经网络,由输入层、输出层和一个或多个隐藏层组成。自编码器的目标是将输入层的表示编码到隐藏层中,然后将其解码到输出层。隐藏层可以充当特征空间的另一种表示,并且由于隐藏层比输入层具有更少节点,输入的数据会被隐藏层压缩。图2示出了具有一个输入层、一个隐藏层和一个输出层的单层自编码器模型。
(4)
编码器fθ将输入xi变换为隐藏表示向量yi,具有以下的形式:
yi=fθ(xi)=s(Wxi+b)
(5)
其中,W是一个d0×d1的权重矩阵,d1是隐藏层的神经元数量,b是偏移向量。接下来,解码器将隐藏层的输出yi作为输入,解码器具有以下的形式:
zi=gθ'(xi)=s(W'yi+b')
(6)
其中,W'是一个d1×d0的权重矩阵,b'是偏移向量。一般来说,隐藏层的神经元数量远小于输入和输出层的神经元数量。当数据经过堆叠自编码器网络时,会被隐藏层压缩,然后会被重构。目标是尽量减少重构的误差,误差具有以下形式:
(7)
算法2展示了自编码器的训练过程。

算法2输入:训练数据集X输出:参数{W,b}1:iter = 0;2:while iter >= max_iter or E <= threshold do3: for i in X do4: CalHiddenlayer(); //使用公式(5)计算yi5: CalOutLayer(); //使用公式(6)计算zi6: end for7: CalError(); //使用公式(7)计算误差E8: UpdateParameter();9:end while
为了形成一个深层网络,通过菊花链将自编码器连接在一起创建一个堆叠自编码器模型:前一层自编码器的输出作为下一层自编码器的输入。为了使用堆叠自编码器进行恶意软件检测,需要在顶层添加一个分类器。堆叠自编码器和分类器组成了用于恶意软件检测的结构模型,如图2所示。
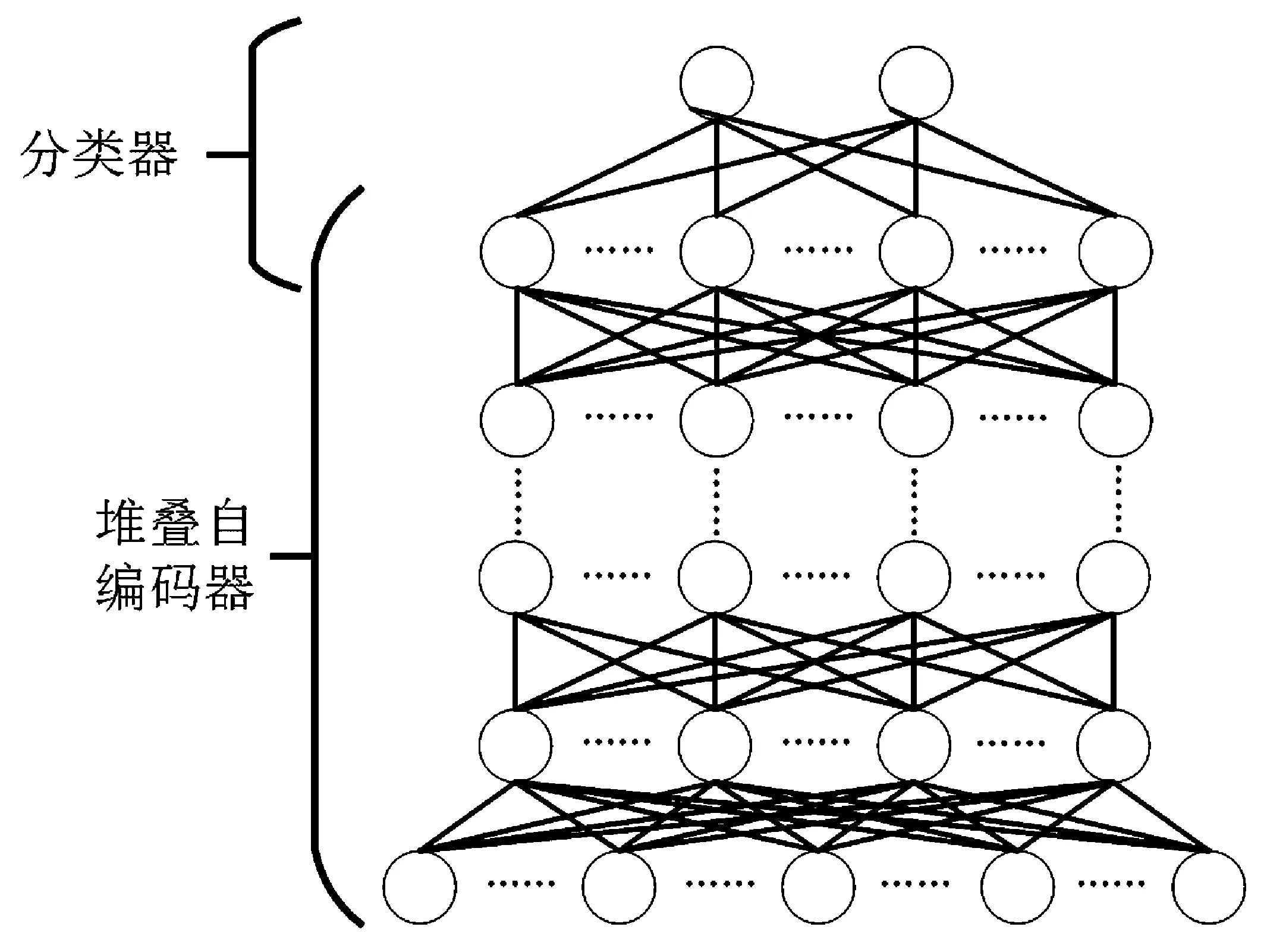
图2 恶意软件检测的结构模型
采用基于梯度下降的反向传播来训练深度网络是很简单的,然而以这种方式训练的深度网络具有较差的性能。因此采用贪婪分层无监督学习算法,以自下而上的方式逐层对深层网络进行预训练,然后以自上而下的方式应用BP来微调参数,从而获得更好的结果。算法3中描述了使用堆叠自编码器深度学习架构进行恶意软件检测的训练算法。

算法3输入:训练数据集X,隐藏层数量h,每一层的神经元数量kj输出:所有参数{W,b}1:for l in 堆叠自编码器 do2: TrainEachLayer(l); //采用算法2训练每一层神经网络3:end for4:Initialze(h+1); //初始化第 层网络的参数5:CalClass(X); //对样本进行分类6:BackPropagation(); //进行反向传播
2 性能评估
在本节中,评估了提出的方法的准确性、精度、召回率和F度量,以验证其在检测恶意软件方面的鲁棒性。为了验证提出算法的鲁棒性,将其与两个现有的算法进行比较,分别是DMBD[5]和GUMD[6]。采用MATLAB作为实验评估平台。在验证中使用了10-fold交叉验证,表1展示了算法对比的结果。显然,提出的方法优于其他两种算法。
准确率是评估恶意和正常软件识别算法性能的一般标准。所提出的方法达到了99.5%的准确率。召回率也是一个重要标准,本文算法具有高达98.8%的召回率。与此同时,提出的方法在精度和F度量方面也优于其他算法。
图3是对本文算法进行鲁棒性评估的实验结果。代码注入技术对恶意软件进行随机代码注入,以达到混淆恶意软件的操作码、降低恶意操作码的比例,最终令识别算法失效的目的。由实验结果可知,随着注入代码的比例增加,算法的各项度量指标均有下降。但是下降的幅度并不明显,这说明了本文算法具有一定的鲁棒性。
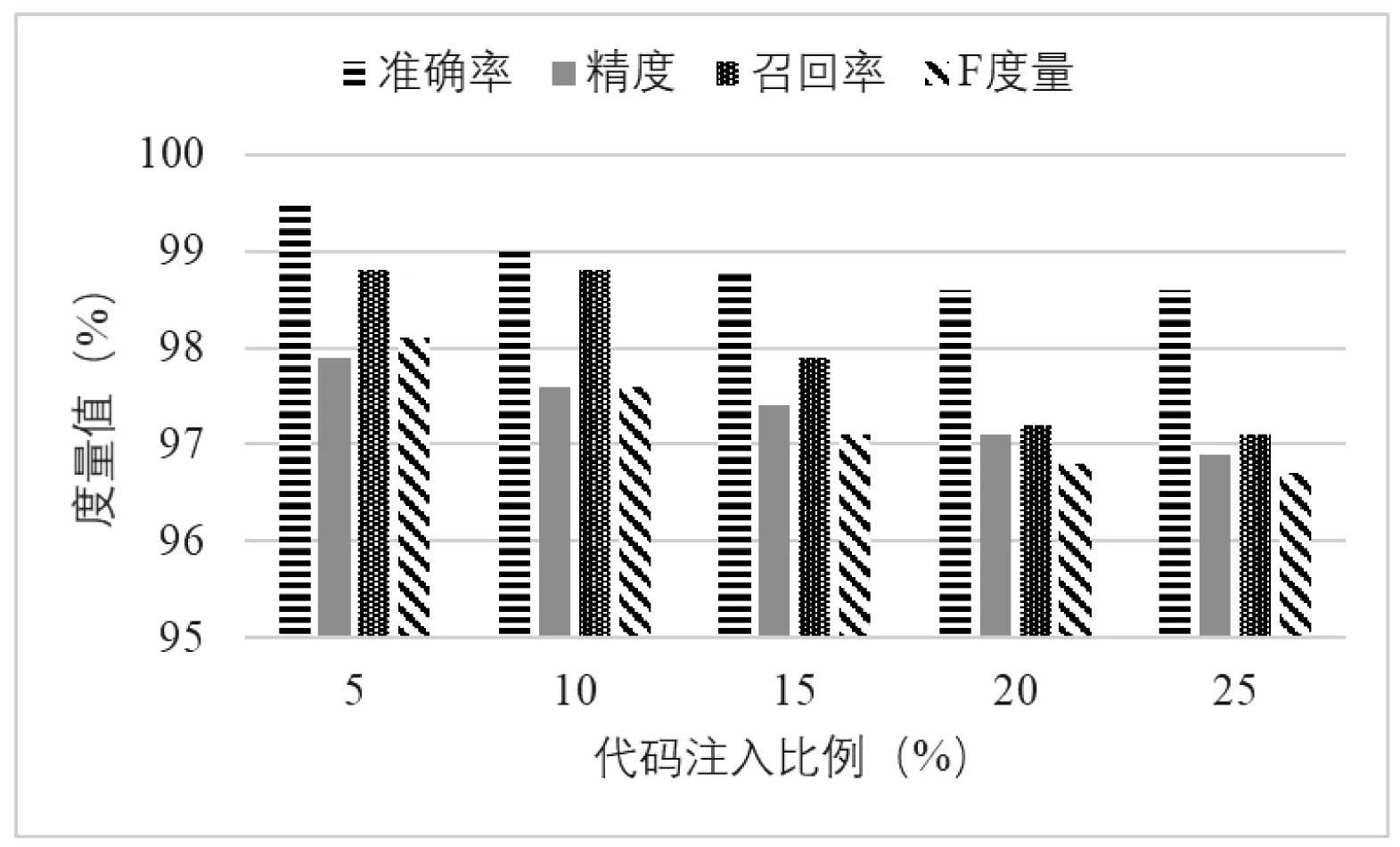
图3 算法鲁棒性评估结果
3 结论
提出的恶意软件识别算法使用软件操作码作为特征,并为每个样本创建了特征的图表示。然后使用基于堆叠自编码器的深度学习框架进行恶意软件识别。实验评估的结果表明了本文的算法具有较高的鲁棒性。未来的工作在于采用更大规模和更具多样性的数据集,在实际的应用环境中验证算法的性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
南京理工大学学报(2021年4期)2021-09-15
科技研究·理论版(2021年22期)2021-04-18
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
农业机械学报(2020年2期)2020-03-09
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
小型微型计算机系统(2018年5期)2018-07-04
计算机应用(2017年3期)2017-05-24
课程教育研究·新教师教学(2016年18期)2017-04-12
电子制作(2017年23期)2017-02-02
