
基于虚拟网格存储动态执行过程的研究
2020-04-25 10:59崔蓓蓓姜丽
信阳农林学院学报 2020年1期
崔蓓蓓,姜丽
(1.徽商职业学院 电子信息系,安徽 合肥 230001;2.国防科技大学 电子对抗学院,安徽 合肥 230000)
非结构化数据快速发展,存储压力进一步增大,而在云计算的环境中,存储的分布式,网络环境的虚拟化,使存储资源进一步池化。如何减少存储碎片化,提高云环境下存储效率是本文考虑的重点,“存储网格”是国际上提出的全新概念。
计算与存储在过去30年中一直未能同步发展,回顾其发展历程,处理器和网络带宽分别提升了3000倍和1000倍,而磁盘和内存带宽仅提升120倍,落后于摩尔定律[1]。阿姆达尔定律认为,系统中最慢部分存储的效率决定整个系统的效率。2012 年全球信息数据达到 2.1ZB(1ZB= 240GB)[2]。估计到 2020 年,全球总的数据量将达到35ZB,为了提升资源的利用效率,最终导致计算、存储架构的分离,访问控制技术朝着细化粒度、多级层次的方向发展,存储虚拟化(storage virtualization)屏蔽物理层,实现物理存储的逻辑化,提高了存储效率,存储网格式是在存储虚拟化之上提出的新概念。存储网格式在虚拟化[3]环境下解决了跨域的分散存储,然而虚拟网格式存储又给数据的容灾备份和寻址带来挑战,本文在考虑通过低颗粒度存储的同时,通过Erasure Code编码的动态网格存储技术,研究通过DHT寻址、从而提高虚拟存储效率。
1 虚拟存储模型

图1 SNIA存储虚拟技术的分类图
虚拟化发展历经了三个主要阶段,从基于主机的虚拟化、基于设备的虚拟化到目前基于网络的虚拟存储。网络虚拟存储可以整合多个存储子系统,目前的网络存储技术(Network Storage Technologies)大致分为三种:直连式存储(DAS:Direct Attached Storage)、网络存储设备 (NAS:Network Attached Storage)和存储网络(SAN:Storage Area Network)[4]。现在借用SNIA(存储网络工业协会)的分类方法,来观察网络虚拟化存储和系统资源的关系。图1为SNIA虚拟化存储层次图。
虚拟存储系统将各类存储资源进行整合,形成一个统一的资源管理池,提高资源的利用率,解决非结构化数据快速增长与存储力相对不足的矛盾。在虚拟管理模块中,根据数据通道管理位置,分为带内(In-Band)和带外(Out-of-Band)管理[5]两部分,屏蔽物理位置限制,形成一个大的“存储池”,为网格存储提供了资源依据,而采用Erasure code保证数据访问的安全性,对于存储资源的寻址采用负载均衡使用哈希数据路由[6]提高寻址效率。
2 Storage Grid用户态的数据模型
Storage GRID存储和管理大规模非结构化数据的下一代对象存储,2017年NetApp推出了NetApp Storage GRID Webscale将存储网格推向新的高度,NetApp在用户端与SAN之间添加中继层,扩展存储网格。然而学术界尚未对网格存储引起足够重视,存储网格为公有云提供了共享数据,分散用户对数据的频繁换进和换出,处理器以block块为调度单位的颗粒度的较大,进一步细分Data Blocks,提供颗粒度更细的内容存储,提高存储资源的利用效率[7],图2为DataBlocks数据结构图。

图2 DataBlocks数据结构
将分散的DataBlocks定义为D={D1,D2,L,Dn},其中n表示 DataBlocks的数目,其资源在虚拟机的位置集合V={V1,V2,L,Vm},m表示虚拟机的总数。物理机上虚拟机位置向量为H={hi1,hi2,L,Dim},当系统调用存储资源时,需要消耗cpu、内存、网络带宽和存储用向量Pi=(SCi,SMi,SNi,SHi)表示,相应的虚拟机的系统态资源GridTablei=(sci,smi,sni,shi)。F=min(Pused),物理资源使用越少,资源利用率越高。
在进程调度过程中,用户态下对资源的动态访问的数据模型,可以定义为:GridTable[j]=(storage[j],active[j],domain[j],MaxOline[j])。
storage[j]是指第j个虚拟主机存储云的存储能力指数,单位为字节;
active[j],表示第j个虚拟机是否占用活动的资源;
domain[j],表示第j个虚拟机在虚拟云中区域范围;
oline[j],表示第j个虚拟主机存储云在线连接数;
MaxOline[j],表示第j个虚拟机能够分配的最大在线连接数。
存储节点存放Data Blocks文件,Storage Grid 根据这些信息执行数据管理,Grid主要从解决存储资源的数量级的角度出发。Grid在使存储的颗粒度变小的同时,考虑虚拟主机动态执行过程,将 blocks 块进行网格式划分,并将Storage Grid的动态化执行过程用简单的算法模型表示,在网格存储的颗粒度研究上具有一定的积极意义。
3 Erasure code 的数据冗余机制
3.1 Erasure code的编码
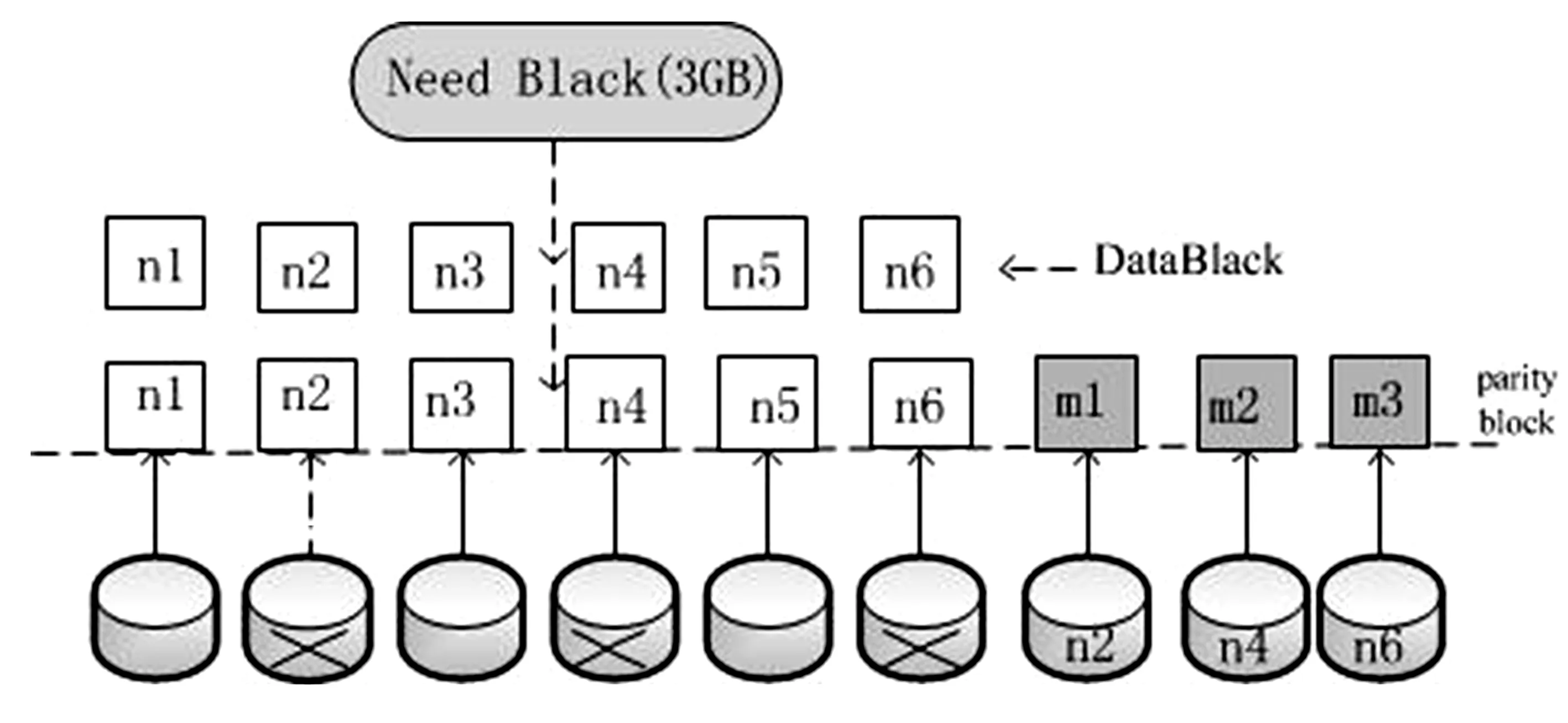
多资源池的数据同步访问,需要跨站点的数据同步能力,在保持随时随地访问数据能力的同时,要保持数据访问的安全性,如何利用有限的存储资源满足迅速膨胀的存储需求成为一个巨大挑战。采用多副本策略在满足存储可靠、优化数据读写性能的同时可能造成资源利用率低的缺陷。Erasure code编码的存储策略可以提高存储资源的利用效率。Erasure Code(N+M)的数据方式进行数据冗余保护,有效地提网格的利用效率,如果客户端需要N个DataBlack,进行冗余校验时需要M个校验块,其空间利用率为N/(M+N)。如果有任意小于M的数据失效,仍然能通过剩下的数据还原出来。也就是说,通常N+M的erasure编码,能容M块数据故障的场景,这时候的存储成本是1+M/N,通常M Erasure Code对N个Data blocks原始数据块进行编码,编码后产生M个数据块(M>N),从编码后的M个数据块进行解码还原出原始数据块,而部分存储的损失,不影响数据的恢复[9]。根据图3可知,如n2、n4、n6出现存储故障,系统态会从其他节点或硬盘把n2、n4、n6数据进行重建出来,n1、n3、n5、m1、m2、m3为一个EC条带,当校验块增大时,开销增大,图3为DataBlack的Erasure Code冗余备份图。 图3 N+M的Erasure Code冗余 Erasure code编码解决了存储的稳定性,提高了空间的利用效率,但编码、解码尚属于复杂的数学运算,是以牺牲一定的计算性能为代价的。目前erasure code还仅适用于对冷数据的离线处理阶段,如何从根本上降低erasure code带来的performance overhead,使得编码存储技术得以真正大量适用,将为大数据存储[8]带来不容质疑的重大意义。当前,Microsoft、Google、Facebook、Amazon、阿里巴巴等互联网巨头将erasure code编码存储技术应用于主流存储系统中。 对存储的研究除提高存储效率,增加存储的额外备份之外[9],最重要之处是保证数据的安全性,跨域的核心数据备份将能很大程度降低由于宕机而造成的数据丢失,本节通过跨域的冗余策略及DHT的寻址方式来阐述数据的完整性保护。新增或减少映射节点时尽可能少地避免原有的映射关系,使数据能均匀的分布在各个节点。我们称这种算法为一致性Hash算法,又称分布式哈希DHT[10]。 具体步骤为: (1)将共享存储的数据块用Erasure Code进行冗余编码; (2)根据在线存储节点的性能参数获取存储节点群,并将文件分布式地储在当前域内的存储节点中,保存文件的存储路由表信息; (3)将文件的最低级目录利用hash算法进行寻址。 采用DHT的方法,将物理节点node映射到2k的环状拓扑结构上,总空间为2k-1,通过hash 图4分布式存储系统DHT数据路由 (node)%2k,物理节点建立了与hash环的联系,如果在IPv4的环境下可以取k=32,node在hash环上的映射位置将表现为实际的物理地址,将存储对象DataBlocks的数据块以同样的方式映射到hash环上,即hash(DataBlocks)%2k=key,这样就建立了DataBlack和node的唯一联系,当node的节点增加或减少时,只影响附近的一个节点,不会影响全部节点的数据。 分布式Hash技术,天然支持分布式自动精简配置(Thin Provisioning),无须预先分配空间。由于DHT具有动态维护的特征,允许节点的自动加入或退出,在虚拟的计算环境中形成DHT的覆盖网络,而不考虑存储节点的具体属性。 存储网格主要解决存储资源的数量级的问题,Storage GRID 为存储和管理大规模非结构化数据[10]的下一代对象存储,StorageGRID 将架构在VMware虚拟机架构之上,将块存储以更小的网格化呈现,使算法在满足用户需求的前提下,提高存储资源的利用率,减少碎片化的概率。 存储网格主要解决了存储资源的数量级的问题,并能提供支持多种应用,在研究过程中会遇到多应用,多站点,多种访问协议的情况,可采用对存储资源访问保留策略,包括在一段时间内对放置位置、存储级别、副本数量进行日志记录和删除。网格存储采用分布式块存储,具有高性能,采用分布式哈希数据路由实现负载均衡,采用Erasure code对数据进行有效备份,用DHT的进行数据路由,使分布式网格存储在虚拟化存储的条件下具有更高的可靠性,单个物理设备的故障不影响业务使用,支持高扩展性非集中式访问,支持平滑扩展,容量不受限制,易管理。3.2 Erasure Code的解码
4 Erasure code 的冗余网格数据DHT寻址机制

5 结论
猜你喜欢
湖南电力(2022年3期)2022-07-07
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年10期)2019-06-17
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年14期)2018-08-21
制导与引信(2017年3期)2017-11-02
电子制作(2017年7期)2017-06-05
电子制作(2017年24期)2017-02-02
