
基于混频数据模型的北京旅游需求短期预测
2020-04-16 05:26郭荣荣闵素芹郭晓航
中国传媒大学学报(自然科学版) 2020年5期
郭荣荣,闵素芹,郭晓航
(中国传媒大学 数据科学与智能媒体学院,北京 100024)
1 引言
随着社会的发展和人民收入水平的不断提高,人们对于旅游的需求也在逐步变大,使得我国旅游业呈现出一片欣欣向荣的景象。旅游的热门选择大部分集中在知名度高、自然风景秀丽的地点,同时旅游产业具有周期性的特点,季节的替换将直接影响旅游人数的数量。为了保持我国旅游业持续健康的发展,合理规划旅游产业就显得及其重要,而在这里发挥重要作用的就是对旅游需求的预测。及时准确地预测旅游需求,不仅有助于旅游部门能够及时预防景区容纳与游客人数需求不匹配的现象,而且有利于旅游从业者调整旅游服务的供给,避免出现供求失衡的现象,从而提高旅游的经济效益[1]。
对旅游需求的预测最早使用的方法是自回归移动平均(ARMA)模型和它的拓展形式、加入误差修正项的自回归分布滞后(ARDL)模型、选取多个预测模型进行对比等[2]。在上面这些模型的基础上进行预测虽然具有合理性,实际上却忽略了对旅游需求有指示性的相关变量,随着网络的飞速发展,旅游前游客会通过电子设备搜索目的地的相关信息。因此,国内外学者对互联网搜索量的加入是否能够提高传统模型预测精度这一问题,展开了很多研究。例如:秦梦和刘汉[2]、刘汉和王永莲[3]利用旅游需求的混频预测研究,并且将它与传统的同频预测模型作比较,研究结果证实基于网络搜索数据的混频预测模型的预测精度要比传统的同频模型预测精度更高。Park等[4]、任乐和崔东佳[5]通过对不同地区旅游人数的预测,研究结果表明加入谷歌搜索数据或百度指数的模型能够有效的提高模型预测精度,并且使得样本外预测更加具有有效性,同时也可提高拟合优度。Ghysels等提出混频数据抽样(MIDAS)模型,能够将各个频率不同的数据加入到同一模型里,从而不需要对原始数据进行分析处理[6]。以上观点表明了混频数据模型具有很好的预测效果。
因此,本文将高频百度指数数据应用到低频旅游需求的预测中,并构建基于百度指数的混频数据模型,对北京旅游需求进行短期的预测研究,为北京游客量的短期预测提供方法支持[3]。利用月度数据预测季度数据时,当季度数据中第一个月的数据发布之后,就可以使用MIDAS模型来预测季度北京旅游需求。利用网络的及时性对游客量的进行预测,不仅有利于旅游行业制定和调整旅游的发展规划,而且能够提高旅游需求预测的精确性。相对于已有的研究来看,本文主要研究基于混频数据模型对北京旅游人数进行短期预测,利用北京美食百度指数的月度数据来预测北京旅游人数的季度数据。具体方法步骤是,首先简单的介绍了北京旅游人数的MIDAS模型,以及四种不同的权重形式和估计方法;其次,构建加入百度指数数据的混频数据模型,得到了北京旅游人数的预测结果;最后,结合分析得到了本文的结论。
2 数据选取及描述
2.1 数据选取
北京旅游需求选用北京季度接待国内旅游区(点)游客人数来反应,下面简称为北京旅游人数,数据来源于北京市统计局官方网站,时间范围为2015年第一季度至 2019年第四季度。百度指数能够提供免费的分析数据功能,可以反映出基于不同关键词的用户关注度[7]。在百度指数中以“北京美食”为关键词,并将时间范围设为2015年1月至 2019年12月,即可得到北京美食所对应的百度指数日数据。每月百度指数日数据所对应的平均值,即为本文所使用的百度指数月度数据。
2.2 数据描述
2.3 数据图形
由图1可以看出,北京季度旅游人数与北京美食百度指数月度数据波动趋势大体相仿,但波动幅度有所差异,且北京旅游人数总体呈上升趋势,这反映了我国人民生活水平的提高,对旅游的需求也在不断增加。同时也可以看出无论是来北京的旅游人数还是北京美食的搜索量都表现出了显著的季节性,其中北京旅游人数在每年的6到8月以及10月较高,北京美食搜索量的关注度集中体现在每年的6月到8月。此外,它们的基本走势表现出来了一定的趋同性,变化幅度大致相同。这说明百度指数在一定程度上能够表现出人们喜欢来北京旅游的意愿,对预测来北京的旅游人数能够起到作用,也为后文的建模提供了参考。
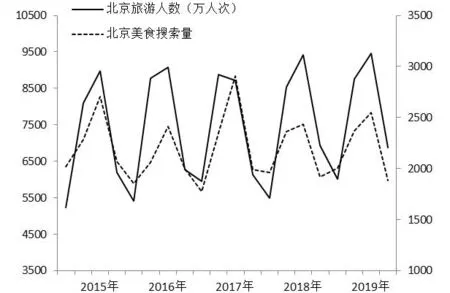
图1 北京季度旅游人数与北京美食百度指数月度数据的走势图
3 MIDAS预测模型简介
3.1 MIDAS模型构建
混频数据抽样模型(MIDAS)是Ghysels基于分布滞后模型的基础上提出来的,它最大的优势是可以提取高频数据中隐藏的重要且有效的信息,进而可以把提取出来的信息进行分析和预测。本文将比较分析指数Almon权重函数、Almon权重函数、Beta权重函数、UMIDAS权重函数这4种权重函数形式下混频数据抽样模型的预测精度,并在其中选择出预测精度最高的多项式权重函数形式。
单变量MIDAS(m,k)模型是指单独考虑一个解释变量对被解释变量产生的影响,研究两者之间的动态关系[8]。因此,北京旅游人数预测的MIDAS模型可以表示为:
(1)
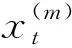
自回归单变量混频数据抽样模型MIDAS(m,k)—AR(ρ)的原理:它是在混频数据抽样模型的基础上,思考前期的北京旅游人数对当期北京旅游人数的影响。换言之就是考虑了北京旅游人数自身之间的动态效应。模型的表达式写为如下的形式[9]:
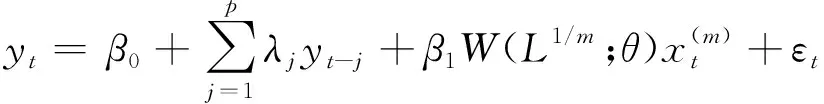
(2)
其中,j表示北京旅游人数的滞后阶数,p是它的最大滞后阶数,λj表示北京旅游人数各个滞后期对当前的影响反应。
(3)淬火温度 当材料和原始组织一定时,相变温度随加热速度增大而提高,为得到合格的淬火组织,相应的淬火温度也应随之提高。通常加热速度越大,淬火温度的上下限越高,允许的淬火温度范围越大。
3.2 多项式权重的选取
MIDAS模型估计中的重要问题是有关权重函数W(k;θ)中的滞后阶数K和参数向量θ的选择,这与权重函数的选择有关系,因为多项式权重对减少模型的待估计参数很有效果[10]。本文共讨论了4种多项式权重对混频数据抽样模型预测精度的影响,并在其中选择出了最优的多项式权重形式。
Almon多项式函数,其基本形式为:
(3)
指数Almon多项式函数,使用范围最广,可以构造出各种不同的权重函数。它能够保证权重数为正数,同时能够使方程得到零逼近误差的性质,基本形式为:
(4)
Beta多项式函数可以构造各种形式的权重函数,同时它是只带有两个参数的多项式函数,具体形式为:
(5)
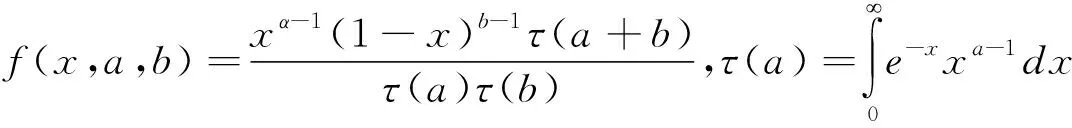
UMIDAS多项式函数是指没有基础模型里对多项式权重的限制,具体形式为:
(6)
4 北京旅游人数的预测结果及分析
对2015年第一季度至 2019年第四季度的北京旅游人数进行建模,并加入百度指数的月度数据,然后分别利用不同形式权重函数的混频数据模型对2015年第一季度至2018年第四季度的基于百度指数的旅游需求混频数据模型进行估计,根据该模型可以预测出2019年第一季度至 2019年第四季度的北京旅游人数。
本文首先根据MIDAS模型的样本预测精度确定出北京旅游人数和北京美食百度指数的最优滞后阶数和最优参数估计。以2015年第一季度至 2018年第四季度的北京旅游人数和相应时间内的月度北京美食百度指数为模型的估计样本,在此基础上对2019年第一季度至 2019年第四季度的北京旅游人数进行样本外预测。在研究的过程中,以均方根误差(RMSE:Root Mean Square Error)指标作为判断模型好坏的根据,因为RMSE指标对于反映模型的预测精度有较好的效果。混频数据模型的预测精度越高RMSE的值越小。
在下面的分析过程中,为了展示RMSE随变量滞后阶数的变化而产生的变动,经过多次试验的反复修改,最后确定北京美食百度指数月度数据的滞后阶数从1阶到12阶,低频北京旅游人数的滞后阶数从0阶到5阶,以确定月度北京美食百度指数与季度北京旅游人数的最优滞后阶数。利用4种参数权重形式和不同滞后阶数的北京美食百度指数与北京旅游人数来构造不同的混频数据模型。在参数估计的时候,用均方根误差RMSE最小的原则来确定高频北京美食百度指数和低频北京旅游人数的最优滞后阶数和最优权重函数形式[11]。各混频数据模型的样本外预测精度如表1所示。
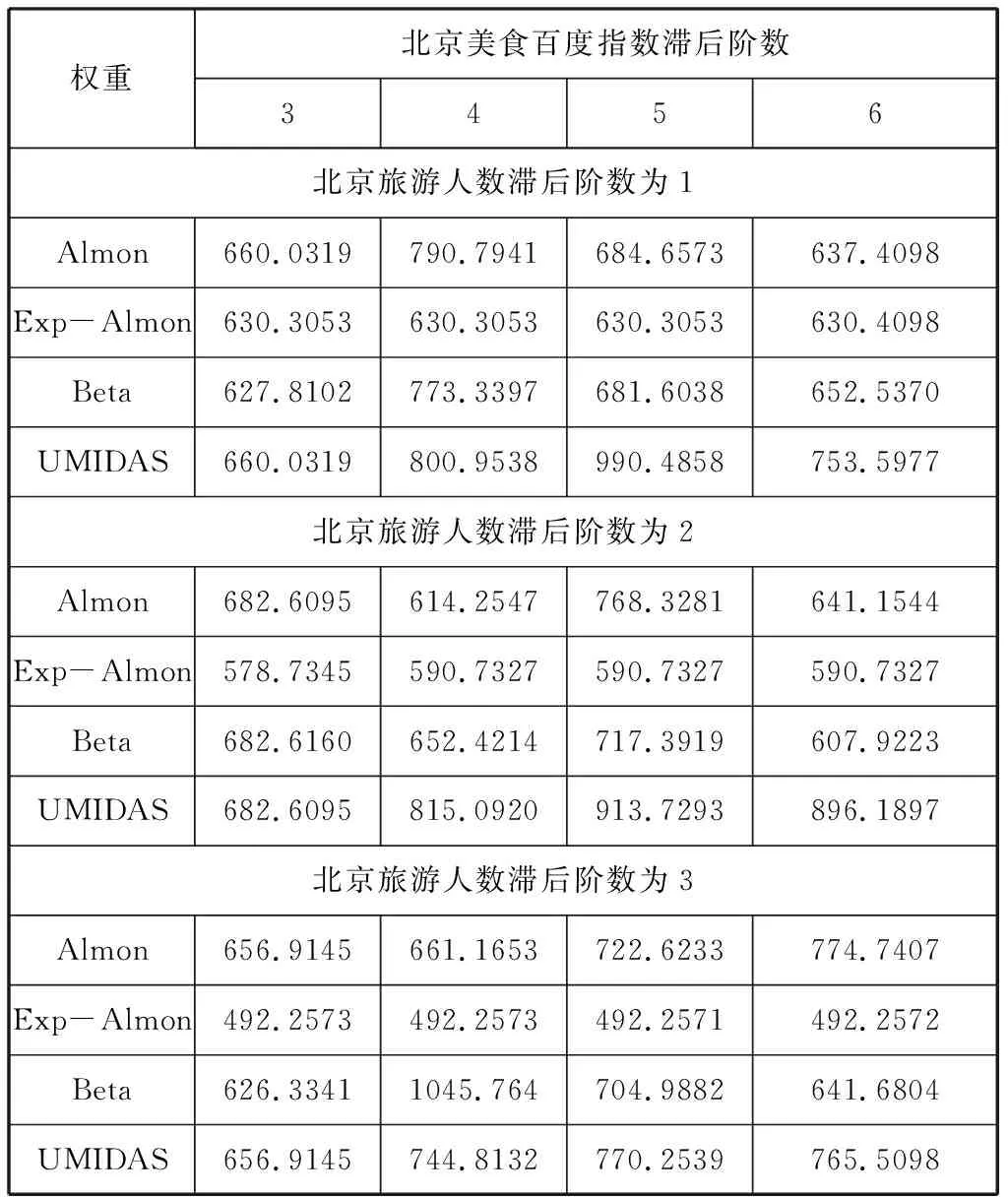
表1 不同混频模型RMSE值
在表1中本文只写出了具有代表性的北京旅游人数滞后阶数的MIDAS模型的预测精度。北京旅游人数滞后阶数的MIDAS模型预测精度随着高频数据北京美食百度指数滞后阶数的变动,其样本外预测精度也在发生变化。由表1可以看出,当北京旅游人数的滞后阶数是1阶时,北京美食的百度指数的最优滞后阶数是3阶,同时最优多项式权重形式是Beta,它的预测精度是627.8102;当北京旅游人数的滞后阶数是2阶时,北京美食的百度指数最优滞后阶数是3阶,同时最优多项式权重形式是Exp-Almon,它的预测精度是578.7345;当北京旅游人数的滞后阶数是3阶时,北京美食的百度指数最优滞后阶数是5阶,同时最优多项式权重形式是Exp-Almon,它的预测精度是492.2571。通过对比可知,当北京旅游人数的滞后阶数是3阶、北京美食的百度指数最优滞后阶数是5阶时,指数Almon混频数据模型(AR(3)-Exp-Almon(3,5))的模型预测具有较高的精度。
由上面的分析可以看出当北京旅游人数的滞后阶数是3阶、北京美食的百度指数最优滞后阶数是5阶时,指数Almon权重混频预测精度较高。为了充分比较预测结果,下面列出了在滞后阶数相同时,指数Almon权重、Almon权重、Beta权重、UMIDAS权重的混频预测结果的具体数值。
由表2可以看出这四种权重的混频预测人数与2019第一季度至2019年第四季的北京实际旅游人数误差较小,与实际结果接近程度很高。同时也可以看出不同形式的权重函数预测出来的结果是不同的,会对预测来北京旅游的人数是有影响的。
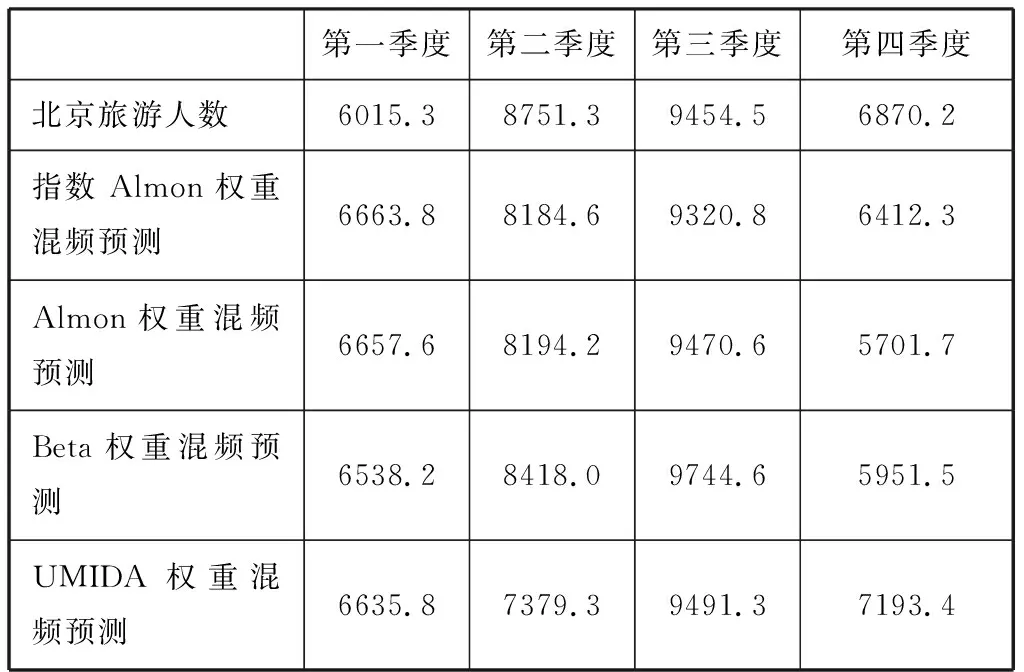
表2 不同混频模型预测2019年北京旅游人数值(万人次)
因此当北京旅游人数的滞后阶数是3阶、北京美食的百度指数最优滞后阶数是5阶时,分别采用指数Almon、Almon、Beta、UMIDAS权重函数的MIDAS-AR模型对 2015年第一季度至 2018年第四季度的北京旅游人数和相应时间内的月度北京美食百度指数数据的混频模型进行估计,并根据该模型对2019年第一季度至 2019年第四季度的北京旅游人数进行预测,其预测结果如图2所示。
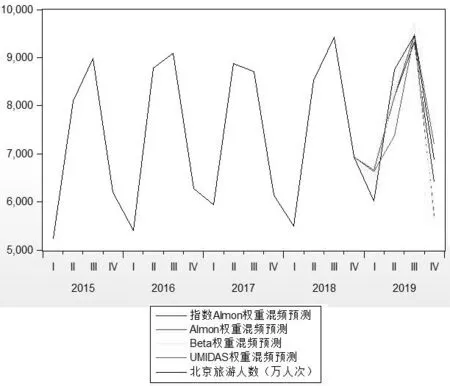
图2 MIDAS模型预测结果
由图2可以看出,指数Almon权重函数的MIDAS预测模型预测精度较高,主要是由于高频北京美食百度指数数据作用于低频北京旅游人数的方式上,同时也可以看出加入月度数据的MIDAS模型预测结果与实际大致符合
因此,旅游需求预测需要考虑到加入具有预测效果的百度指数搜索数据,它可以体现游客在旅游之前做的准备工作、游玩时所参与的活动以及旅游后在网络上留下的反馈痕迹,这些都隐含着非常多丰富的信息[12]。混频数据模型能够把这类数据合理应用,同时也对旅游需求预测模型起到了良好的补充作用。
5 结论
准确的旅游需求模型预测,不仅对旅游业的从业者来说具有非常重要的参考价值,同样也对于游客的行为产生了重要的影响。本文以北京旅游人数作为旅游需求的代替变量,利用了加入百度指数数据的混频数据模型对旅游需求进行预测分析。实证结果表明:加入百度指数月度数据的混频数据模型预测结果与实际情况非常接近,这主要是因为百度指数可以表现游客的在线行为,即表现了游客对旅游目的地的关注行为,而这种关注行为在百度指数中得到了体现。由于百度指数是传统意义上影响旅游需求以外的因素,所以能够对旅游需求预测结果加以改进。而指数Almon权重的MIDAS模型比其它不同权重形式的MIDAS模型预测精度高,这表明了混频数据模型所采用的权重形式不同,旅游需求预测的结果也不相同。因此我们在分析预测时,需要进行优化处理去找到最合适的预测模型,从而将它用于旅游需求的预测中。
基于百度指数的混频数据模型对北京旅游需求的预测具有有效性,同时百度指数与混频数据模型相结合也使得旅游需求的预测兼具时效性和准确性的特点。本文的结论为其它地区或景点旅游需求的预测提供了新思路,游客及旅游业相关部门可据此及时准确地预测旅游人数,以实现该地区旅游产业的蓬勃发展,具有指导、实践意义。
百度指数所蕴含的信息十分丰富,本文用“北京美食”这个关键词作为百度指数月度数据的代表还具有一些不足。具体的可以将游客旅行前后的行为,例如游客在出行之前会从衣、食、住、行、游、购等方面来选取相关关键词,若把这些关键词都包括进行研究,这样研究得到的结果会加大可信度。
猜你喜欢
南华大学学报(自然科学版)(2021年3期)2021-07-21
华东师范大学学报(自然科学版)(2021年3期)2021-06-03
现代信息科技(2021年21期)2021-05-07
Defence Technology(2020年4期)2020-07-02
舰船科学技术(2020年2期)2020-04-17
上海大中型电机(2020年1期)2020-03-27
教育教学论坛(2018年39期)2018-09-25
青年与社会(2018年2期)2018-01-25
小猕猴智力画刊(2017年7期)2017-08-09
党政干部学刊(2015年7期)2015-12-24
