
基于多尺度感受野网络和注意力机制的场景识别方法研究
2020-04-16 05:26:10张能欢王永滨
中国传媒大学学报(自然科学版) 2020年5期
张能欢,王永滨
(1.中国传媒大学协同创新中心,北京 100024;2.中国传媒大学计算机与网络空间安全学院,北京 100024)
1 引言
给我们一张图像,场景识别能预测出该图像内容的场景所在地,比如是办公室、操场还是书店。场景识别是计算机视觉的基本任务之一,近年来受到越来越多的关注,它可以广泛应用于人机交互、图像/视频检索、智能场景匹配拍摄等领域。然而,由于场景图像往往具有丰富的背景信息、多种多样的物体对象和灵活多变的拍摄视角,导致存在严重的类别模糊。场景识别的困难主要有以下两点:
一是场景图像对尺度敏感
关于场景图像对尺度敏感的问题,我们可以从数据集的角度来分析。深度学习的快速发展一方面得益于硬件条件的成熟,另一方面也得益于具有海量标注数据的数据集的出现,比如ImageNet、COCO等。考虑到场景图像中也包含很多的物体,所以利用ImageNet中包含的海量物体信息来辅助场景识别,提高场景识别的准确率应该是有效的。然而,Zhou等人[1]利用ImageNet和Places两个数据集来直接训练场景识别的任务模型,但是结果却比只用Places数据集来训练更差,额外增加的物体信息反而降低了准确率。另外,2016年,Herranz等人[2]提出了一个数据集偏差的概念,认为不同任务的数据集的尺度中心点是不一样的,一类是以Places为代表的的以场景为中心,另一类是以ImageNet为代表的以物体为中心,由于这两类数据集存在严重的尺度偏差问题,导致简单的融合这两类数据集来训练同一个网络,结果差强人意,所以,Herranz等人又提出了一个多尺度并行的模型结构,用不同尺度的模型来适应不同的数据集,最后结果进行融合,这样反而能取得很好的效果,由此表明尺度问题对场景识别来说很关键。图1中(a)展示了具有不同尺度的wave场景图像,(b)展示了需要大尺度信息的胡同场景,这些图像都需要网络能灵活捕捉不同尺度的场景特征。

图1 尺度敏感和特征模糊的例子
二是场景图像的特征模糊
场景中涵盖的背景信息和物体信息非常丰富,导致很难明确出什么是某一类场景的特征,比如图1中(c)展示的沙龙场景,虽然是同一类场景,但是内容却完全不同。而(d)中展示的内容很相似,但是场景却不同,所以场景的特征存在模糊性。以往的方法,很多都采用多特征融合来实现场景识别。Sun等人[3]提出融合物体信息、全局外观信息和背景信息来表征场景特征。Seong等人[4]提出用物体信息和场景信息结合来训练场景识别的模型。虽然已经有了很多的尝试,但是效果却不是很显著。场景特征的选择还是需要依靠网络训练来自适应地完成。
在本文中,我们引入空洞卷积,设计了一个多尺度感受野模块,来解决尺度敏感问题,同时加入注意力机制来提高特征的区分度和代表性,最后,我们在三个公开的场景识别数据集上验证了方法的可行性和有效性。
2 模型介绍
本文提出一种基于多尺度感受野和注意力机制的场景识别模型,整体模型结构如图2所示。模型结构中主要包括两个模块:多尺度感受野模块和注意力模块,其中多尺度感受野主要基于空洞卷积设计的。注意力模块包括空间注意力和通道注意力两部分内容。我们的基础网络模型根据数据集大小分别采用了ResNet-18和ResNet-50两种不同的网络结构。
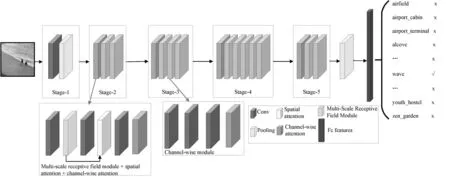
图2 基于多尺度感受野和注意力机制的场景识别模型整体结构
2.1 多尺度感受野模块
空洞卷积是由Holschneider等人[5]首先在小波分解任务中提出的。由于空洞卷积能够在不增加额外计算量的同时捕获大的感受野信息,所以空洞卷积开始在很多领域得到广泛应用。本文的多尺度感受野模块就是基于空洞卷积设计的。具体多尺度感受野模块结构如图3所示。
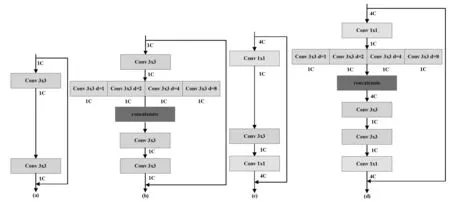
图3 多尺度感受野模块结构图
假设模块的输入为F∈H×W×4C,然后送入到具有不同空洞因子的卷积层中,再将输出进行拼接,最后再送入到一个普通卷积层中,实现特征降维,具体操作可表述如下:
(1)
(2)
其中l表示层,di表示空洞因子,在本文中我们选了1,2,4,8四种空洞因子,*r表示空洞卷积操作,concat(·) 表示拼接操作,CONV2(·) 表示一个二维卷积操作。
2.2 注意力模块
注意力的设计初衷是模仿人类的视觉机制,人类在观看一张图片时,并不是所有内容都一视同仁,而是有选择地看更重要的内容,注意力机制就是让网络模型去学习更相关的特征。在场景识别任务中,不同的图像空间区域和语义特征对识别的准确率贡献是不一样的,所以我们加入了空间注意力和通道注意力来提高模型的特征选择能力。
具体注意力模块的结构如图4所示,其中,空间注意力的操作如下:
Fl=concat(GMP(Fl-1),GAP(Fl-1))
(3)
Fl+1=CONV2(Fl)
(4)
Fl+2=σ(Fl+1)
(5)
通道注意力的操作如下:
Fl=GAP(Fl-1)
(6)
Fl+1=CONV1(Fl)
(7)
Fl+2=σ(Fl+1)
(8)
其中GMP(·)和GAP(·) 分别表示全局最大池化和全局平均池化操作,σ表示激活函数,CONV1(·) 表示一维卷积操作。
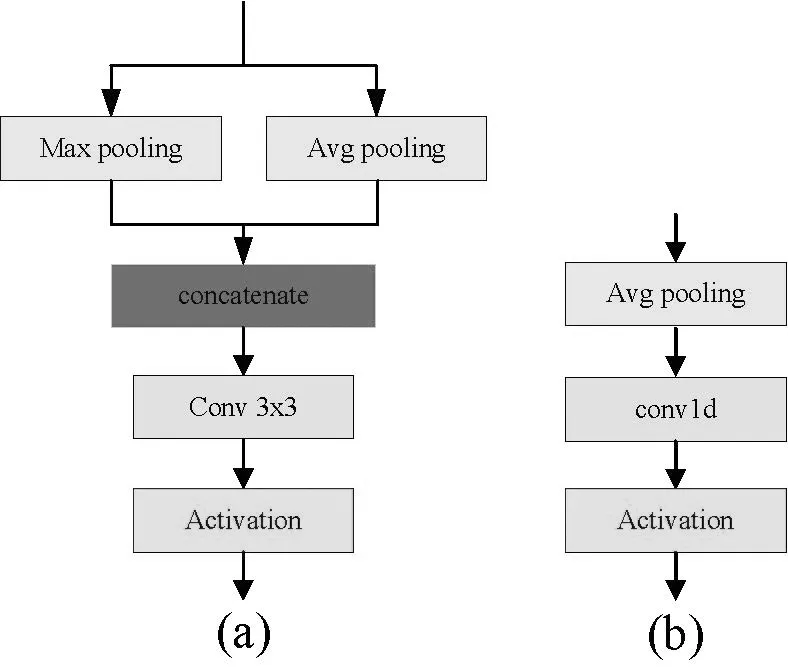
图4(a)是空间注意力模型结构 (b)是通道注意力模型结构
3 实验及分析
3.1 实验数据和实验配置
本实验主要采用了三个公开的场景识别数据集,分别是Places365[6],SUN397[7]和MIT Indoor67[8]。
Places365数据集是Places2数据集的子集,有两个版本,分别是Places365 challenge和Places365 standard,我们采用的是Places365 standard,它有365类场景,每类场景大约有3068到5000张图片不等,总共有1803460张训练图片。
SUN397数据集有397类场景,108754张图片。我们采用和大多数对比实验相同的实验方案,随机从每个类别中选取50张图片用于训练,50张图片用于测试。
MIT Indoor67数据集有67类室内场景,15620张图片,实验中,我们从每个类别中随机选取80张图片用于训练,20张图片用于测试。
在本文实验中,所有数据集图片均调整为224×224 的大小,学习率初始化为0.001,然后每30轮降为0.1倍。批大小为64。采用SGD的优化算法。采用PyTorch框架,在一个NVIDIA Titan Xp GPU(12G)上进行实验。
3.2 模型分析
这一部分的实验,我们采用Places365数据集来进行的,主要分三部分进行对比,第一部分是关于多尺度感受野模块的有效性验证;第二部分是空间注意力的可视化效果;第三部分是通道注意力的可视化效果。
为了验证多尺度感受野模块的有效性,我们设计了三个模型的对比实验方案,其中均采用了基于ImageNet的预训练模型参数进行初始化。首先,我们在原始ResNet-50网络上基于Places365数据集进行了实验,之后加入了本文提出的多尺度模块重新进行了实验,最后,我们用普通的3x3卷积操作替代了多尺度感受野模块,最终三个实验的对比结果如图5所示。从图5可以看出,本文提出的多尺度感受野模块的效果是最优的。
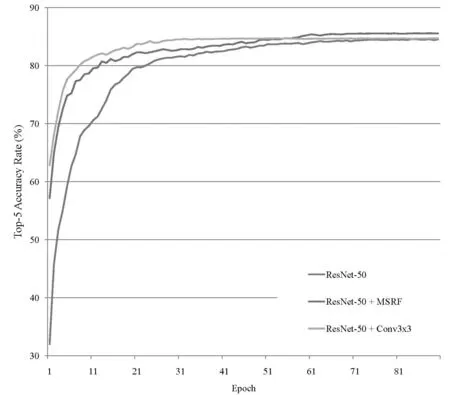
图5 三种网络的准确率对比
同时,为了更直观地看出多尺度感受野模块的效果,我们进行了可视化展示,如图6所示,可以看出多尺度感受野模块有效提高了模型的感受野,从而间接提高了场景识别的准确率。

图6 多尺度感受野模块的可视化效果
表7展示了注意力模块的可视化效果。其中前两列展示的是通道注意力的效果,可以看出提取的特征更准确。后两列展示的是空间注意力的效果,可以看出加入空间注意力模块后,在空间区域的定位上更精准。

图7 注意力模块的可视化效果
3.3 与其他方法的对比
为了更进一步验证本文方法的先进性,我们在三个公开数据集上进行了广泛的实验,并与其他场景识别方法进行了对比。
表1给出了在Places365-standard数据集上的统计结果。从表1可以看出,在ResNet50基础网络模型上分别单独增加的多尺度感受野模块、空间注意力模块和通道注意力模块的结果都比原始ResNet50要好,表明这三个模块是有效的。之后,我们将这三个模块进行融合,其结果时最优的,表明了本文方法的有效性。
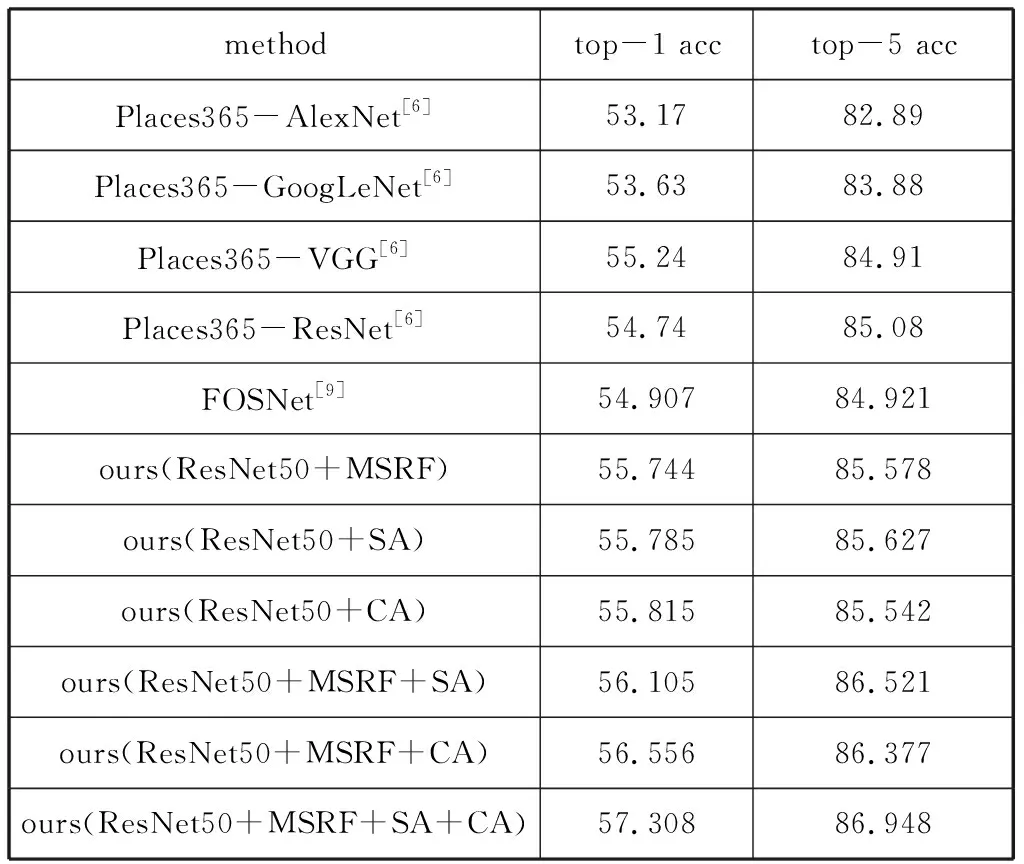
表1 在Places365 standard上的实验结果
表2是基于MIT Indoor67数据集的对比结果,考虑到MIT Indoor67数据集的规模比Places365 standard小很多,所以基础网络我们采用了ResNet-18。从表2的结果可看出本文的方法取得了最优的效果。
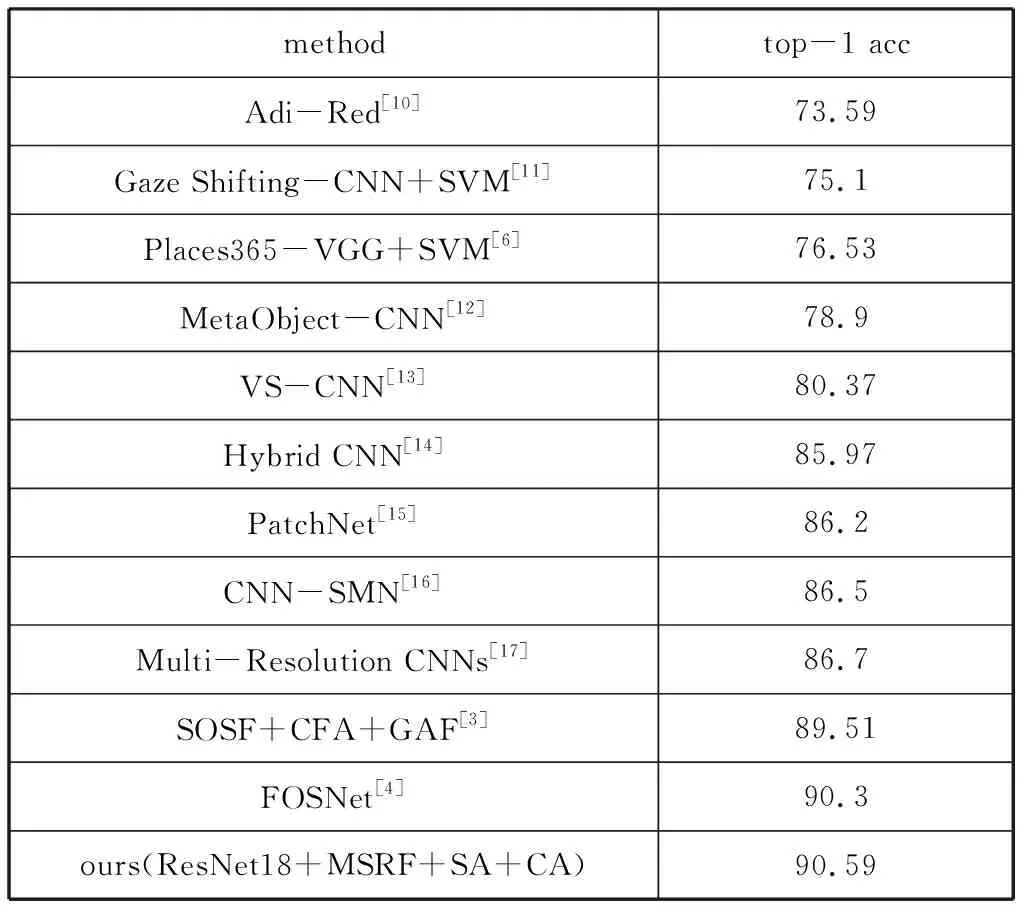
表2 在MIT Indoor67上的实验结果
表3是基于SUN397数据集的对比结果,也可以看出本文方法是有效的。
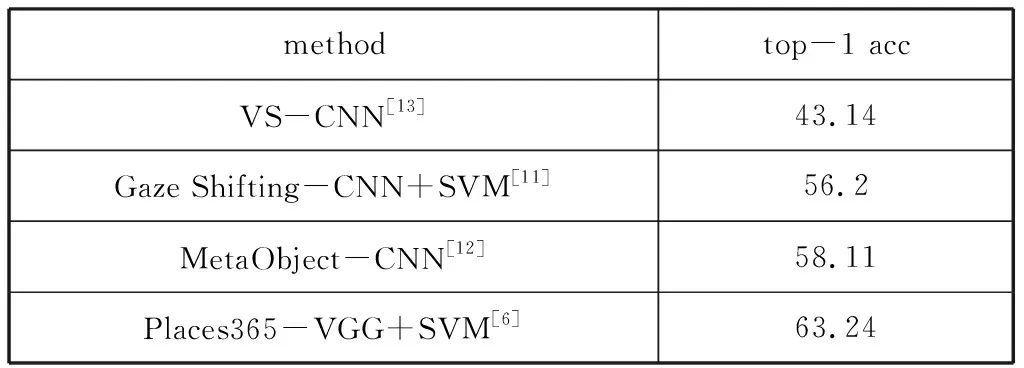
表3 在SUN397上的实验结果
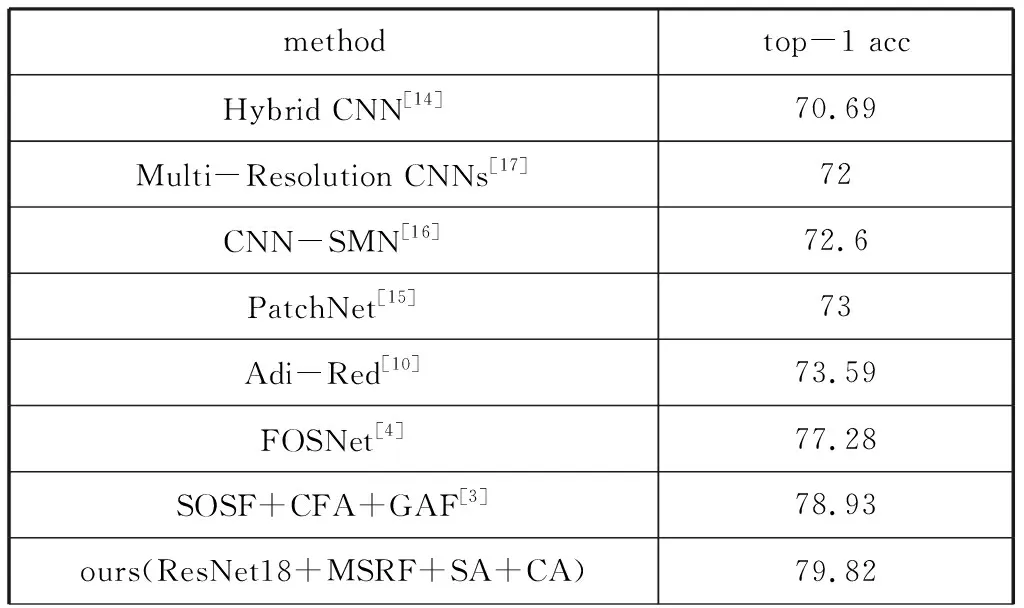
续表
4 结论
本文提出了一种利用感受野和注意机制来提高场景识别性能的新方法。我们首先设计了一种基于空洞卷积的多尺度感受野模块,可以提取更大感受野的特征,从而对场景图像有更全面的了解。其次,采用了一个空间注意模块和一个通道注意模块,它们能够自适应地提取与场景更相关的区域和语义特征。最后,通过大量的实验表明,我们的方法比现有的场景识别方法简单、高效。作为下一步的工作,我们将根据不同的场景类别和图像内容来研究感受野的自适应大小。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
传媒评论(2017年3期)2017-06-13 09:18:10
故事作文·高年级(2017年2期)2017-03-01 13:03:27
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
新闻传播(2015年20期)2015-07-18 11:06:46
时代英语·高三(2014年5期)2014-08-26 17:01:17
世界科学(2013年11期)2013-03-11 18:09:47
漫画月刊·哈版(2009年10期)2009-03-26 02:36:06
