
基于知识图谱的美妆产品信息可视化设计与研究
——以口红产品为例
2020-04-16 05:26:12黄靖越
中国传媒大学学报(自然科学版) 2020年5期
黄靖越
(中国传媒大学 动画与数字艺术学院,北京100024)
1 引言
据艾瑞咨询 2019 电子商务行业发布的报告显示,2019年Q2中国网络购物市场的交易规模达2.4万亿元,环增长 10.9%,较去年同期增长 26.5%。[1]可见,在电商平台进行购物已经成为大部分用户的习惯,在此背景下,各个电商平台的产品信息和用户评论呈现爆炸增长。对电商平台怎么能高效管理和组织产品、用户评论等信息,充分挖掘信息的价值提出了挑战。因此我们需要深挖信息和信息之间的关联,从海量信息中提取有效信息,满足用户的信息需求,推动用户行为发生。而知识图谱技术能很好的挖掘有效信息并建立联系。知识图谱的广义内涵可以从两方面来说:知识图谱作为一种语义网络,是大数据时代知识表示的重要方式之一,当知识图谱作为一种技术体系,是大数据时代知识工程的代表性进展。概念、属性、关系是人类认知的基本框架是认知的基石,而知识图谱富含实体、概念、属性、关系等信息,通过节点和边来描述真实世界的概念、属性、关系,并能推理发掘新的知识和观点,使得机器理解与解释真实世界成为可能。
相较于传统商务行业,电子商务平台的消费者无法切身体验产品,消费行为必须依靠网站上展示的信息进行判断,因此产品信息成为消费者购物决策的重要影响因素,特别是对于美妆产品,直接涂抹于消费者面部,首先,产品是否可靠安全,消费者在利用产品信息选择评估产品时会更加谨慎;其次,美妆产品属于体验型产品,体验型的产品所包含的信息受各种因素影响较大,简单的产品信息已经无法满足网购消费者的信息需求,消费者经常在无法实际感受情况下需要从其他各个渠道中花费时间搜寻信息,评估产品,因此利用知识图谱技术组织各个来源的彩妆产品信息,挖掘信息和信息之间的关系,形成彩妆产品知识图谱,将更利于用户直观搜索和获取产品信息。
2 构建美妆产品信息知识图谱:
要建立美妆产品信息知识图谱,按逻辑架构的维度可以划分为知识图谱的模式层建立和数据层处理。[2]知识图谱的数据层是由具体的、真实的事实组成,模式层规定了知识图谱数据层的规则,知识图谱模式层是整个知识图谱的基础,模式层的构建就是对知识的概念、概念和概念之间的关系进行一系列的描述,是经过提炼的知识。[3]知识图谱的模式层通常由本体库来管理。
美妆产品信息知识图谱本体的构建既可以通过人工手动构建、通过数据驱动自动构建以及半自动构建。[4]自动构建需要大量的数据进行训练,对数据量的需求较大。在本体的作用下,知识图谱在不断地收集、整合数据库的执行效率更高。本文知识图谱数据样本小,因此更适合采用人工编辑的方式手动构建,首先从最顶层的概念开始,然后逐步进行细化,形成结构良好的层次结构,定义好知识图谱的模式层后,再将数据层中的对象一一添加。本体的构建不是一个从零到一的过程,构建时可以考虑复用现有的本体,通常信息管理专家都会对某一领域的知识进行分类的分层,以便于领域的研究。本文通过分析淘宝电商平台的美妆产品信息分类和组织方式,把美妆产品信息构成要素分为四大类:美妆产品的固有信息、美妆产品物流信息、美妆产品店铺信息、美妆产品评价信息。
本文构建的美妆产品知识图谱以口红产品为例,其原因主要有两方面,一方面口红产品相比于其他美妆产品,例如粉底、眼影等彩妆产品,口红的色号更多,消费者需要评估的选择更多。另一方面,口红颜色能够用一定的原理较为客观、准确的量化,更适合可视化。以口红产品为例子,口红产品的固有信息包括口红品牌、口红价格、口红颜色、口红包装、口红质地、口红产地、口红销量七个子类;口红产品物流信息包括:物流价格、物流速度、物流公司三个子类;口红产品店铺信息包括:售后服务、店铺评分、是否是熟悉的店铺三个子类;口红产品评价信息包含商品好评率、商品评价内容、商品差评数三个子类。口红产品知识图谱模式层中的类、子类、属性、值之间大致包含四种关系,即:包含关系:包含关系是根据区间划分,两个或者两个以上的概念或者子概念在同一区间。例如:
将口红产品信息知识图谱模式层概念、关系定义好之后,需要对爬取收集的数据进行处理,获取数据主要有结构化、半结构化和非结构化三种类型,将不符合知识储存格式的数据进行处理,把数据处理成符合知识储存规则的格式,数据包括实体属性的提取、相似处理包括颜色的判断、评论内容的分词、去停用词、提取关键词,经过这一步,数据才成为了知识,最后处理好的知识,用三元组<实体、关系、实体>的形式表示,以CSV和TXT格式储存在数据库NEO4j中,方便可视化时提取和使用。
在实际应用中,口红产品信息知识图谱的所有概念、实体、关系并不能全部可视化出来,需要通过对口红产品消费者的研究,按照用户需求有重点、有选择地展示信息。
2 美妆产品用户需求分析
根据图1所示用户在电商平台网购时行为路径,可以看到产品信息对用户的行为决策起到关键性的作用。对于口红产品,要提供哪些产品信息,哪些产品信息对用户的决策影响更高,需要进行用户研究。本研究通过调查问卷的方式调查消费者对不同口红产品信息的关注程度,截止2020年10月30日,一共收集到调查问卷259份,其中有效问卷为242份。
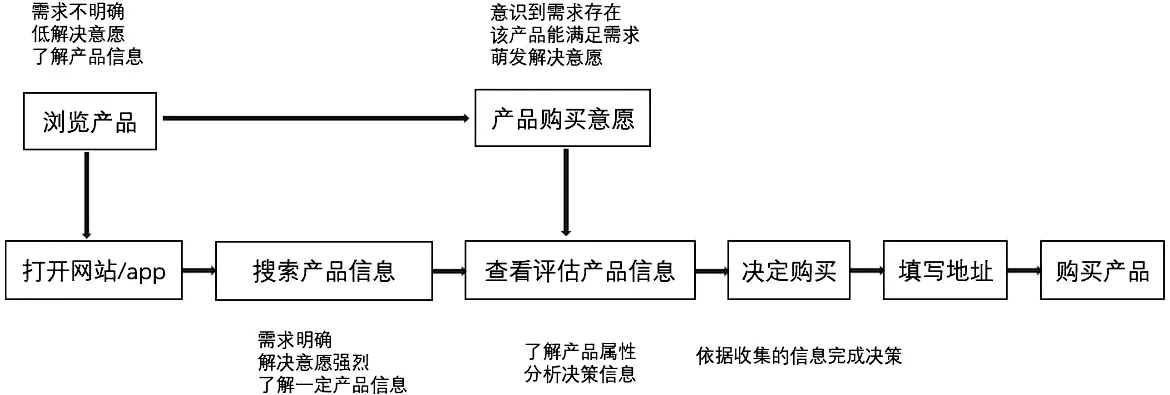
图1 用户网购行为路径
本文用户需求研究主要使用的是spss进行数据分析,包含了两个方面:一是信度效度的分析和因子分析。
通过KMO和巴特利特检验,一般认为数值大于0.7,证明问卷具有良好的结构效度,说明适合做因子分析,数值越接近1,各个变量之间的联系就越强;当数值小于0.5时,则不符合做因子分析的标准。分析结果如表1所示。
本次KMO和巴特利特的检验结果为0.648和0.733,基本符合因子分析的标准,巴特利特的球形检验中近似卡方值为2025.145和1875.287,自由度为105,sig值小于0.01,说明各个变量之间相关性强。综上所述,说明本次研究的问卷效度良好。
由表1所示,前五个公共因子的初始特征值均大于1,累计方差贡献率达74.510%,因子1的方差占总方差的22.608%,因子2的方差占总方差的20.522%,因子3的方差占总方差的13.586%,因子4的方差占总方差的9.568%,因子5的方差占总方差的8.226%说明五个公因子代表的信息基本能解释原始信息,所以可以用前五个公因子代替原来15个影响因素。
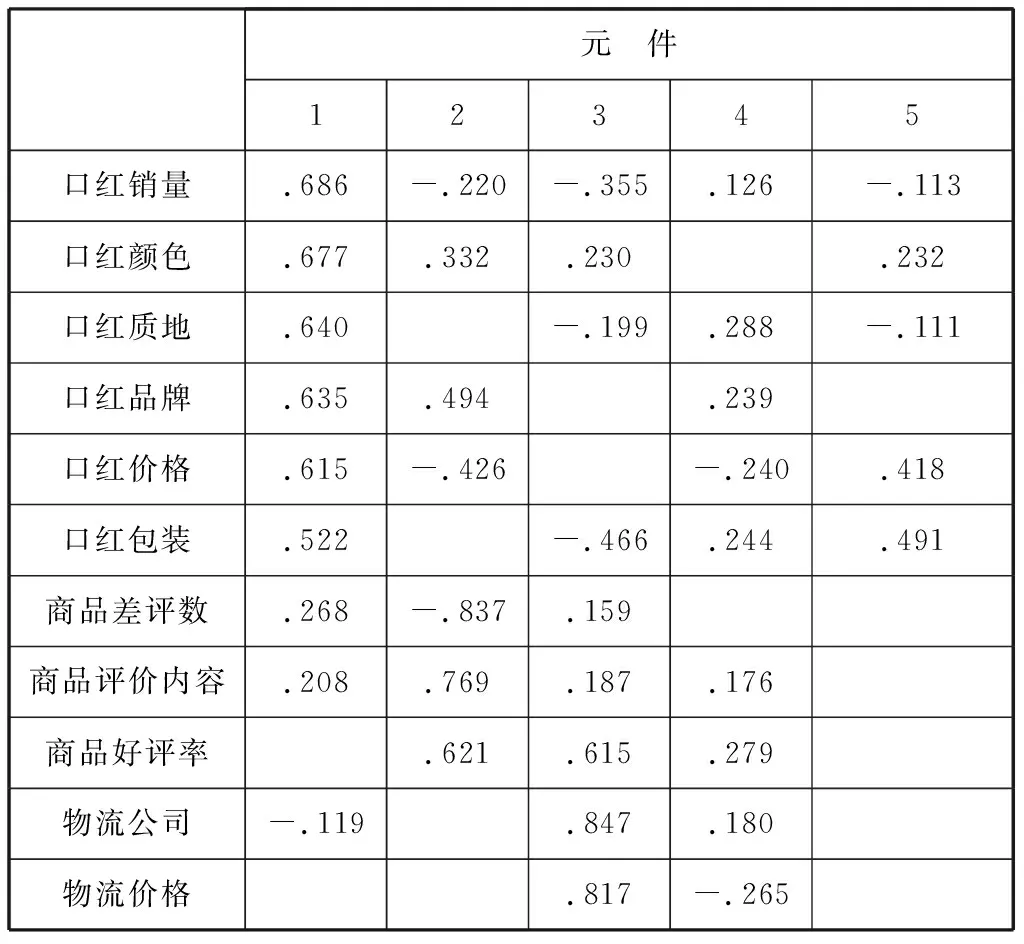
表2 旋转成分矩阵
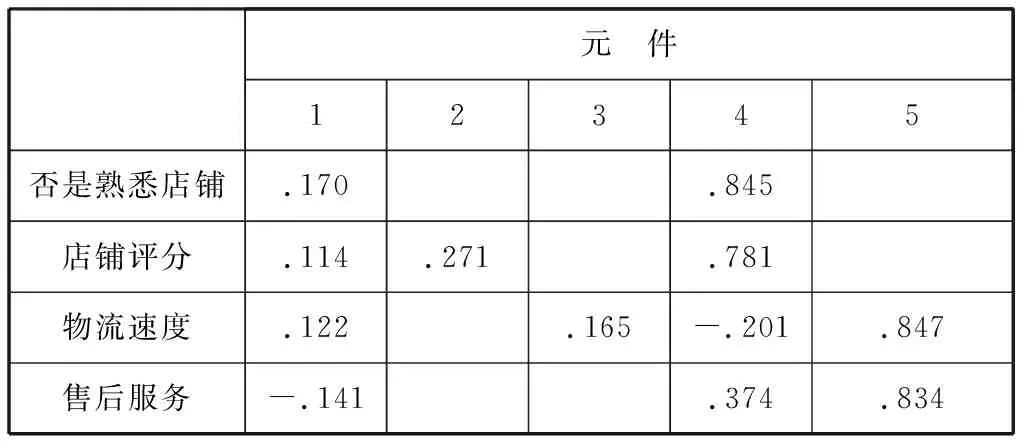
续表
为了更深入的解释各个公共因子的具体的含义,本文按照极大方差法对因子旋转,得到了旋转成分矩阵图。
综合得分可反映出消费者在进行网购时哪一部分的因素对购买决策影响最大。
综合得分计算公式:
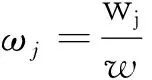
Fi=w1Pi1+w2Pi2+w3Pi3+w4Pi4+w5Pi5
权重公式(1)中的Wj为表1中的“方差百分比”表示各主成分之间的方差贡献率,各个方差贡献率相加为“累计方差贡献W”,根据权重公式(1),由方差贡献率和累计方差贡献率,可计算出五个公因子的权重,由公式(2)可计算出15个影响因素综合得分,由表3所示。
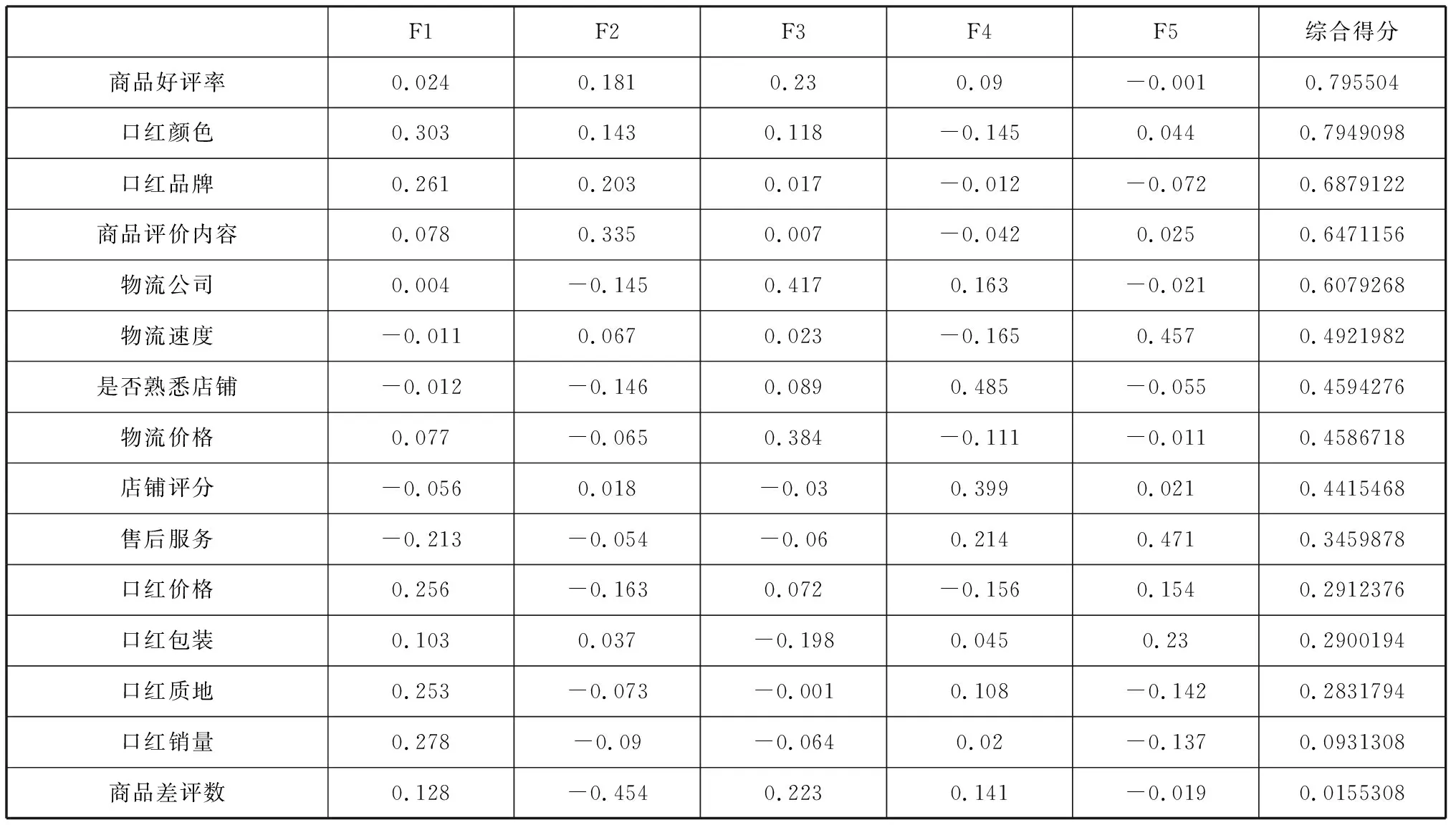
表3 因子得分与综合得分
根据用户网购产品行为路径,口红产品信息知识图谱可以为用户提供两大功能,一是产品信息展示,二是产品信息对比。由表3因子综合得分所示,口红产品信息中的商品好评率、口红颜色、口红品牌、商品评价内容是综合得分最高的四个因素,因此在进行口红产品信息可视化设计的时候,要着重展示口红产品这四个信息中的联系和关系。
3 美妆产品信息可视化设计方法
将信息设计成能被用户轻松理解的样式是信息可视化的目的。针对不同量级数据的可视化设计需要考虑不同的几个方面,对轻量级数据可视化需要关注数据的深层关系,在处理大型多变量数据集时,需要考虑有效内容的提取和数据的降维,把大量信息精简提炼,让用户能快速分析,并能迅速做出判断。
可视化是一种用图形表达数据的方式,可视化设计的中心流程就是信息的映射,信息的映射是指将数据转化用图形表示的。可视化映射需要以人的视觉认知为基础,可视化映射包括三个元素:空间基质、标记、视觉通道。[5]Card、Mackinlay、Sheniederman在《阅读信息可视化:用视觉思考中》种定义了这三个元素。首先,空间基质可视化元素种的空间基质是指设计师在可视化中需要打造的可视化空间,在早期的可视化作品种,主要都会将信息布局在二维空间中,但随着大数据的发展,数据量越来越大,数据关系越来越多,也会有三维甚至超维的表现方法。因此,如何在多维空间中进行可视化布局是现今可视化设计的一个难点。[6]其次是标记,标记是指在空间中出现的一些图形元素,例如:点、线、面、体等,根据数据、信息的类别、属性也可以用别的图形元素来表现。[5]最后是视觉通道,视觉通道是指用于控制数据、信息的标记的展示特性,常见的视觉通道有标记的位置、大小、形状、方向、色调、饱和度、亮度等。[5]可视化设计过程中要注意数据和图形转换映射关系要合理,图形要能够准确反映数据性质和数据关系。
用户的信息需求不是一成不变的,尤其在信息更新换代速度越来越快的今天,在不同阶段用户对信息的复杂性、深度和形式的需求各不相同,可视化设计需要给用户提供能够进行探索和交互的空间,能够进一步深入发现信息,而不是单纯的信息输出。
(1)同类色系口红关系的建立与可视化设计:
通过软件和手工爬取电商平台和口红官方网站,采集了7个品牌、35个系列的口红RGB值与口红评论。按照Card等人在《Readings in information visualization using vision to think》中提出以步骤为中心的信息可视化流程模型,对数据进行清洗和规范。由于RGB色彩规则并不适用于人认识色彩的规则,故这里将RGB色彩转化为HSL,H代表色调、S代表饱和度、L代表亮度,据HSL颜色模型可得,H的取值范围在0~360,通过整理收集的口红颜色数据,五个品牌口红颜色H值集中在(0-65)和(295-360),呈现出由正红到偏黄和正红到偏紫,用户可滑动色环,选择心仪的口红色调。
一个颜色最终的准确呈现必须由H、S、V三个参数决定,色环体现色相的选择,中间的方块呈现口红的明度和饱和度变化,用户在选择色调后,中间的方块呈现出该色调的所有口红数据的分布,用户可在其中了解信息。
(2)相似口红颜色关系的建立与可视化设计:
在这部分的可视化设计中,主要展示各个品牌之间口红颜色的相似关系,利用大小不同的原点表示每个品牌目前口红数量的比例关系,在每个品牌和品牌之间有颜色相似的口红则建立起联系,比较两个颜色的相似关系主要是通过计算颜色距离,HSV色彩空间模型为圆锥体,其中r为圆锥底面半径,具体公式为:
x=r×S×cosH
Y=r×V×sinH
Z=h×(1-V)
根据公式计算出两个颜色在HSV色彩空间中的坐标点(x,y,z),再计算出两个颜色的距离,距离小于一定数值,则两个颜色相似,可建立相似链接。
遵循可视化设计中的准确原则,不同的用户色彩感知不同,每个人对色彩的相似判定也不同,将色彩相似度划分为5-10分,按照色彩距离数值的大小,可视化呈现比分,由图2可见。
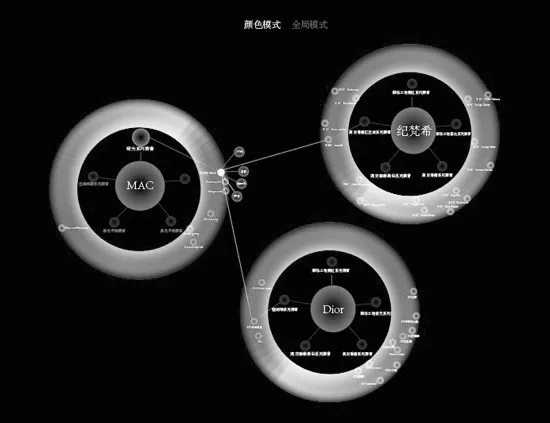
图2 口红颜色相似关系可视化
(3)口红评价内容观点的提取与可视化设计:
口红评价内容是所有数据中最难处理的部分,首先评论都是非结构性的文本,内容的语义、关系复杂,其次文本中存在许多噪音数据,对用户的购物决策没有任何意义,因此要对评论内容进行预处理,预处理分为两部分,一是将评论的句子进行分词处理,二是将评论中的停用词去除,评论中常见的评论词包含三类:标点符号、特殊符号、无意义的虚词。这里用的是jieba中文分词组件对评论进行预处理。
评论的内容包含了用户对口红产品评价的各个维度,要遵循可视化减少用户理解时间,直观的原则,要将复杂维度的数据进行降维,这里对评论中的关键词进行提取,统计词频出现最高的TOP30。
根据词频所见,将评论内容划分为五个维度:物流、服务、产品属性、性价比、包装。可视化由图3所见。

图3 口红评论观点可视化
4 结语
本研究通过知识图谱技术,用户研究等方法,将美妆产品信息知识图谱进行可视化,提出基于知识图谱的美妆产品信息可视化设计方法,展示产品信息可视化的部分实例,对更高效、直观的产品信息可视化设计进行了实践探索和讨论。
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-05-25 12:17:42
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09 06:09:10
少先队活动(2020年12期)2021-01-14 01:47:40
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:32
初中生世界·九年级(2017年10期)2017-11-08 21:30:36
中成药(2017年3期)2017-05-17 06:09:01
婚姻与家庭·性情读本(2017年4期)2017-04-18 16:10:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
疯狂英语·阅读版(2013年11期)2013-12-09 06:46:27
杂草学报(2012年1期)2012-11-06 07:08:33
