
基于闭环割线学习律的超声波电机转速控制
2019-11-15 08:09:38史敬灼
微电机 2019年9期
周 颖,宋 璐,史敬灼
(河南科技大学 电气工程学院,河南 洛阳 471023)
0 引 言
超声波电机固有的非线性运行特性,要求其控制策略具有应对这种非线性的能力,以得到良好的控制性能[1]。迭代学习控制策略利用简单的学习律,通过在线学习过往控制经验来逐步改善系统运行状态[2],不断趋近期望的控制性能。同时,传统的迭代学习控制策略还具有复杂度相对较低的特点,在伺服系统中的应用日益增多[3-5]。
文献[3]引入迭代学习控制策略以改善重复定位控制的稳态性能。文献[4]、文献[5]分别将闭环P型和PI型迭代学习律、非线性正割迭代学习律用于超声波电机转速控制,实现了转速控制性能的逐渐改进。文献[6]在开闭环迭代学习控制律的基础上,增加带有遗忘因子的修正项以提高轨迹跟踪速度和精度。
本文针对超声波电机非线性运行和时变特性,给出了闭环割线迭代学习控制策略,并给出了适应于超声波电机转速非线性控制关系的学习增益在线调整机制。实验表明,电机转速控制性能在迭代学习过程中逐渐改善,控制效果较好。
1 闭环割线迭代学习控制策略
文献[2]借用数值分析中求解非线性方程的牛顿法,给出牛顿学习律。牛顿学习律的控制量计算需要用到被控对象输出函数对控制量的偏微分。考虑到超声波电机等控制对象的非线性及时变特性,该微分值不易准确获取,影响控制性能。为此,可借鉴数值分析中的割线法,用差分代替牛顿学习律中的微分项,得开环割线学习律:
(1)
式中,uk+1(i)为系统第k+1运行过程中i时刻的控制量,本文讨论超声波电机转速控制,所用控制量为电机驱动电压的频率;uk(i)、uk(i-1)分别为系统第k次运行过程中i、i-1时刻的控制量;ek、nk分别为系统第k次运行过程的转速误差、转速;KP为学习增益。
式(1)所得控制量与当前控制信息无关,是开环的迭代学习控制策略,适用于传统迭代学习控制策略的应用领域,即具有“可重复性”的应用场合,控制策略简单有效。但是,当“可重复性”不满足时,例如用于具有时变特性的控制对象,或是转速给定值、电机负载变化等,开环迭代学习律的控制效果会不尽如人意。可行的改进方法是在控制量的计算式中,引入当前控制过程的控制量和/或误差信息,使控制策略具有闭环控制的特征。即将式(1)修改为
(2)
式(2)利用了当前转速误差信息,以减小当前误差值作为直接的控制目的,有可能更好地应对给定值、电机负载变化及超声波电机的时变性,得到较好的控制效果。
2 学习增益的在线自适应调整
为将割线法用于构造迭代学习控制律,需要改进割线法以使迭代过程能够保持稳健的下降趋势,使得控制响应经过渐进的学习过程,收敛于期望状态。数值分析中将下山法与牛顿法相结合,得到能够保证函数值持续下降的“牛顿下山法”。下山因子,即式(2)中的学习增益KP,通常采用尝试的方法来确定其值。常用的尝试法为若当前的迭代计算值不再持续下降,则将系数值减半,再次进行当前的迭代计算;有必要时,重复减半,直至满足持续下降的要求。当应用于迭代学习控制时,上述的每一次迭代计算,对应于一次控制响应过程。本文所述超声波电机转速控制系统的性能指标,要求超调为0,这是伺服系统常见的性能要求。这种以当前响应过程是否出现超调为判据来确定KP值的在线尝试方法,显然不适用于本文所述超声波电机转速控制。为得到稳健并且更快的收敛过程,可考虑采用在线变化的KP值。
考察割线学习律式(2),其中分式计算值为使转速误差变化单位量所需的控制量变化量,再乘以转速误差,即为使该转速误差减为零所需的控制量增量。但在转速上升从而使转速误差不断减小的过程中,当前的分式计算值总是大于实际需要的控制增量,导致控制作用强度过大,出现超调。为避免上述问题,应设置合适的学习增益KP值来减弱控制强度,而且不同转速情况下的KP值应是不同的。
为得到KP值在线自适应调整的表达式,可考虑从实测的转速阶跃响应曲线中得到控制量的变化规律,进而得到使控制量增量大小合适的KP值。具体来说,对每一组阶跃响应数据中的每一个数据点,计算式(2)中的分式值,作为“计算值”;为与计算值进行比较,对同一组数据中的每一个数据点,按照式(3)计算所得数值作为“实际值”:
(3)
式中,FC(i)、e(i)分别为第i个数据点的控制量、转速误差数值;FCS为该组阶跃响应数据中,转速达到稳态之后的控制量数值。

图1 比值数据拟合曲线
由于各个数据点的自变量(转速)数值不相等,在相同的转速变化范围、插值点数的前提下,分别对两组数据进行插值,再对两组数据的两条计算值插值曲线、两条实际值插值曲线分别取平均。为了得到统一的KP值表达式,同样采用先插值再求平均值的方法,将不同转速给定值情况对应的平均值曲线整合。实际值除以计算值所得的比值数据即为不同转速情况下的学习增益KP值。对这些比值数据进行函数拟合,如图1所示。兼顾在线计算量和拟合精度,得到2阶拟合多项式
(4)
式中,n为电机转速,单位r/min。
式(4)给出了KP值随转速的变化规律,使KP值跟随电机转速变化进行在线自适应调整,提高非线性迭代学习控制的动态性能。考虑到超声波电机的时变特性,式(4)给出的KP值与当前的实际电机状况之间会出现偏差。另一方面,式(4)是以“给出的控制量增量使当前误差减为0”为前提得到的。但在实际中,作为控制量的驱动频率值变化量过大,超声波电机会突然停转,无法适应过快变化的控制量输入。因此,考虑实际应用,学习增益KP可按下式计算
(5)
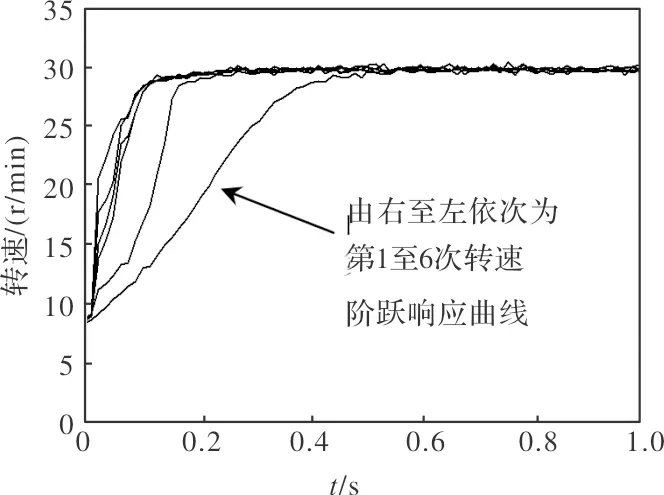
式中,q为强度因子,且有-1 通过DSP编程实现式(2)迭代学习控制律,学习增益KP根据式(4)、式(5)在线自适应调整,进行迭代学习转速控制实验研究。所用实验电机为USR60型两相行波型超声波电机,电机驱动主电路采用H桥结构。与电机同轴刚性连接的光电编码器,在线测量电机转速并反馈到控制器输入端,控制器输出量取为电机的驱动频率。 转速阶跃给定值30 r/min,以比例系数为-1、积分系数为-2的固定参数PI控制器进行第1次转速阶跃响应实验,设置学习增益的强度因子q值为-0.3,连续进行5次割线迭代学习控制实验,得到实验结果如图2所示。从图中可以看出,所有阶跃响应的超调量均为0,经过6次阶跃响应过程,响应速度明显加快,控制性能改善。转速响应较为平稳,稳态波动小。 图2 转速阶跃响应曲线(q=-0.3,空载) 取转速阶跃给定值为60 r/min,并施加0.2 Nm负载,取强度因子q=-0.2,得到迭代学习控制实验结果如图3所示。加载0.2 Nm时,第1次到第6次阶跃响应,控制性能的改进幅度较小,这是施加外部扰动的必然结果。 图3 转速阶跃响应曲线(q=-0.2,加载0.2Nm) 传统的迭代学习控制策略以被控对象和运行环境的“可重复性”为前提。但在实际的电机控制系统中,尤其是在伺服控制领域,实际的电机及其系统往往具有或快或慢的时变特性,给定值、负载等外界扰动也往往是变化的。为拓展迭代学习控制策略的适用范围,越来越多的学者开始关注非重复情况下的迭代学习控制效果。下面,进行转速给定值变化、空载加载交替等实验,来进一步研究闭环割线学习律的控制性能。 在空载情况下,进行改变转速阶跃给定值的实验,进一步验证闭环割线学习律式(2)的控制性能。实验中,采用PI转速控制器进行第1次转速给定值为30 r/min的阶跃响应控制过程,从第2次阶跃响应开始,转速给定值改为60 r/min的柔化阶跃给定曲线(图4中虚线所示),迭代学习控制参数仍设为q=-0.2,测得超声波电机转速响应如图4所示。 图4 转速阶跃响应曲线(q=-0.2,空载) 从图4可以看出,采用闭环割线学习律,使第2次阶跃响应过程能够通过当前误差值感知给定值的变化,并及时跟踪。只是由于式(2)所示控制量仍然是在前次控制量的基础上进行计算的,所以,转速给定值为30 r/min的第1次阶跃响应导致第2次阶跃响应起始阶段的转速上升稍慢。随后,在迭代学习控制律式(2)的作用下,第3次阶跃响应中,转速就已经可以快速上升了。 进一步,改变加载方式进行实验。仅对第2次和第4次阶跃响应过程加载0.1 Nm的情况下,取阶跃给定值为60 r/min,得到实验结果如图5所示。可以看出,加载0.1 Nm时,转速阶跃响应过程与空载时的实验结果差别不大,表明式(2)所示闭环割线迭代学习控制对负载扰动具有一定的鲁棒性。 图5 转速阶跃响应曲线(q=0.2,第2、4次加载0.1Nm) 综上所述,本文所述闭环迭代学习控制律对负载扰动、给定值变化具有较强的鲁棒性,适用于不满足“可重复性”的应用场合。 本文给出一种闭环割线学习控制策略。针对超声波电机的非线性及时变特性,设计学习增益在线自适应调整机制,并给出了自适应调整公式的确定方法。超声波电机空载、不同负载转矩及不同加载形式、变转速给定值等实验结果表明,闭环割线学习律的控制性能良好,对负载扰动、给定值变化具有较好的鲁棒性,适用于不满足“可重复性”的应用场合。3 闭环割线迭代学习转速控制实验研究



4 结 语
猜你喜欢
黑龙江大学自然科学学报(2021年4期)2021-11-19 07:05:06
天津教育·下(2018年9期)2018-07-13 08:25:47
中国水利水电科学研究院学报(2018年2期)2018-05-24 02:39:00
黑龙江电力(2017年1期)2017-05-17 04:25:05
中学生理科应试(2016年10期)2016-12-06 20:02:32
福建中学数学(2016年8期)2016-12-03 10:31:50
环境科技(2016年5期)2016-11-10 02:42:12
系统工程学报(2015年2期)2015-02-28 19:53:43
电网与清洁能源(2015年2期)2015-02-28 16:03:12
电力自动化设备(2013年11期)2013-09-18 02:55:14
