
一种基于语料的词汇语义相似度认知算法∗
2019-02-27 08:31孙伟晋
计算机与数字工程 2019年2期
吴 华 罗 顺 孙伟晋
(上海通用识别技术研究所 上海 201112)
1 引言
随着互联网信息的爆炸式增长,如何让机器具有类似于人类阅读和理解信息的能力、学习和认识知识的能力、思考和解决问题的能力,从而使机器智能成为人类智能的延伸和拓展,已成为当前计算机领域的重要技术发展方向与产品开发策略之一。而词汇的语义相似度计算正是机器智能的重要基础之一,在信息检索、自然语言处理、推荐系统等领域都有广泛的应用,正在为越来越多的研究人员所关注[1]。
目前,词汇语义相似度计算的主要方法是根据某 种 世 界 知 识 来 构 建 计 算 模 型,如HowNet[2~3]、CCD[4]、同义词林[5~6]等语义词典[7~8],按照概念在语言学中结构层次关系来计算词汇语义相似度。这种方法直观、简单有效且易于理解,但是不可避免地面临主观性较强、领域敏感性较差、新词或新语用的扩展性较弱等困难。
本文通过提取词汇的上下文语境特征作为词汇语义的承载单元,构建了一种基于特定语料的词汇的语义相似度计算模型。模型通过对词汇的语境特征的距离计算,来给出词汇在当前语料中的相互可替代度量,并以此作为词汇的语义相似度。
2 词汇的语境特征
词向量方法是目前统计语言学广泛使用的一种方法,相关模型具有计算复杂度小、灵敏度高、易训练等特点[5~6]。将词向量方法应用于词汇的语义相似度计算,分别取对象词汇的上文和下文相邻实词作为语境特征向量,将基于样本语料的词汇语境特征向量之间的距离作为词汇间的语义相似度度量。
举例来说,若样本语料如下:
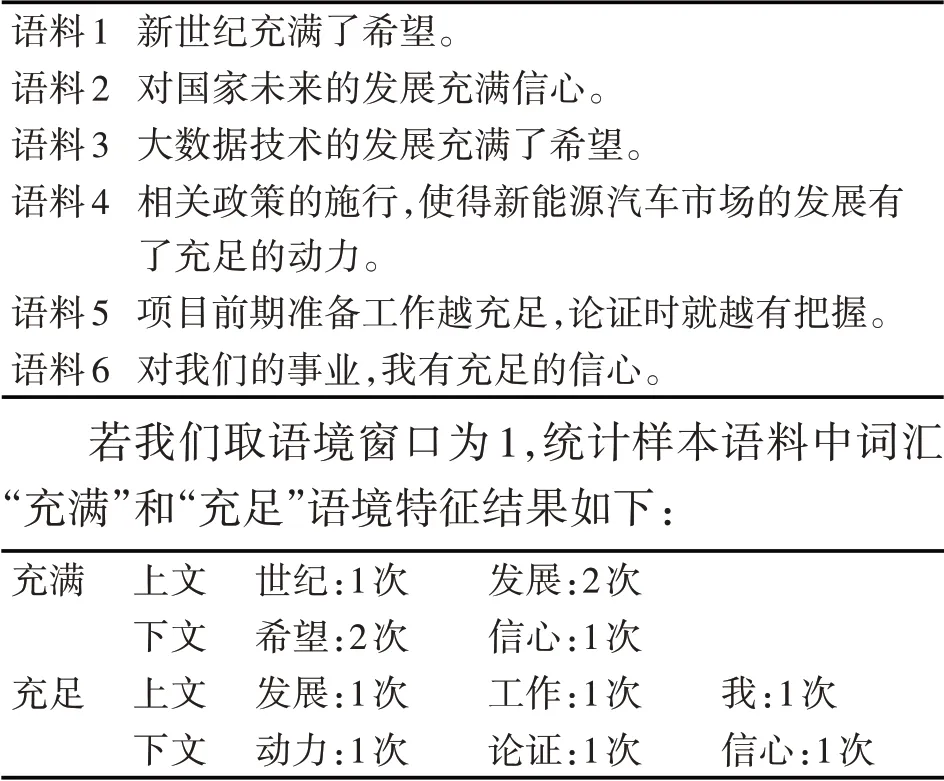
语料1语料2语料3语料4语料5语料6新世纪充满了希望。对国家未来的发展充满信心。大数据技术的发展充满了希望。相关政策的施行,使得新能源汽车市场的发展有了充足的动力。项目前期准备工作越充足,论证时就越有把握。对我们的事业,我有充足的信心。若我们取语境窗口为1,统计样本语料中词汇“充满”和“充足”语境特征结果如下:充满充足上文下文上文下文世纪:1次希望:2次发展:1次动力:1次发展:2次信心:1次工作:1次论证:1次我:1次信心:1次
设样本的上文语境空间为{世纪、发展、工作、我},词汇“充满”的上文语境特征向量为{1,2,0,0},词汇“充足”的上文语境特征向量为{0,1,1,1}。同样的,设样本的下文语境空间为{希望、信心、动力、论证},词汇“充满”的下文语境特征向量为{2,1,0,0},词汇“充足”的下文语境特征向量为{0,1,1,1}。
3 语义相似度计算模型
3.1 模型准则
一般而言,词汇语义相似度都采用归一化度量,相似度值域为[0,1]。词汇语义相似度计算模型需要满足以下几个条件:
1)词汇和其自身的相似度为1;
2)若两个词汇在任何上下文中都不可替换,那么其相似度为0;
3)相似度度量是单调的,即两个词汇语义越相似,其相似度就越高。
对于两个词汇S1和S2,我们记其相似度为Sim( S1,S2),只要满足上述条件的计算模型,都可以作为语义相似度的度量。
3.2 基于语境特征向量的相似度度量
若记样本语料的语境空间为C={c1,c2,…,cn},其中ci表示语料中的某一个实词。记词汇S1和S2的语境特征向量分别为S1={s11,s12,…,s1n}、S2={s21,s22,…,s2n} ,其中sij表示第i个词汇的语境特征向量中实词cj的出现次数。
对照第3.1节中的相似度模型准则,基于词汇的语境特征向量,我们构造基于语境特征向量的相似度计算模型如下:

易知Sim( S1,S2)∈[0 ,1]、Sim( S1,S1)=1,若有词汇S3={s31,s32,…,s3n},那么
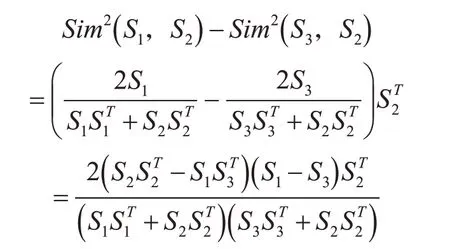
假设s31≠s11,s32=s12,s33=s13,…,s3n=s1n(s3i≠s1i的情况同理),我们从上述公式中可以发现,当 |s31-s21|< |s11-s21|时,有 Sim( S3,S2)>Sim( S1,S2) ;当 |s31-s21|> |s11-s21|时,则 有Sim( S3,S2)<Sim( S1,S2)。也就是说,当词汇S3在样本语境空间的投影(某一实词的词频)相比词汇S1更接近S2时,其语义相似度也就越高。
从而,上述构建的模型符合词汇语义相似度度量的一般准则。
3.3 针对上下文语境的模型优化
针对中文的语言特点,对上、下文语境空间分别赋以不同权重,对第3.2节中的相似度模型进行优化如下:
其中SU,i、SD,i分别表示词汇Si的上、下文语境特征向量,( α,β)为权重向量,考虑到中文“语义后置”的特点,一般我们配置β>α。
4 算法描述
step1:统计样本语料中出现的主要实词(为避免矩阵过于稀疏),作为语境特征空间;
step2:通过统计得到对象词汇的上、下文语境特征向量,并向样本的语境特征空间中进行投影;
step3:通过第3.2节或第3.3节中公式计算对象词汇间的语义相似度;
step4:将计算结果保存至本地,构建面向语料或面向领域的语义词。
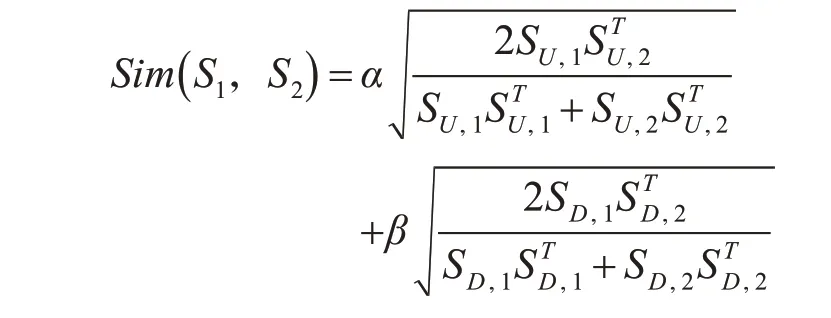
5 算例
仍以第2节中语料为例,利用第3.3节中语义相似度计算模型,配置上、下文语境特征权重( 0 .4,0.6),计算词汇“充满”和“充足”在当前语料中的相似度如下:
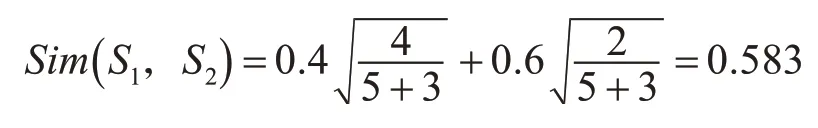
基本符合样本语料实际。
若采用同义词林[5],“充满”=“Jd06A01=”,“充足”=“Ed39A01=”采用按位计算的方法计算相似度,结果为

语义相似度度量结果也较为接近。
6 结语
本文提出的基于语料的词汇语义相似度计算方法是一种基于计算的模糊认知类方法,把词汇语义相似度度量的建立在基于样本语料统计的语言事实上。因而具有以下三方面的特点,一是具有客观性,词汇语义相似度度量不受人为主观影响,词汇的语义相似度完全由语料统计给出;二是具有领域性,一方面能对领域中的新概念、新术语进行语义度量,一方面能对多义词汇的领域义项自动识别;三是不需要词法、句法、语义、语用等先验知识,是一种模糊认知的经验主义方法,便于组织大型的语义词典。
猜你喜欢
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
数学学习与研究(2018年15期)2018-11-12
中国计算机报(2018年12期)2018-10-08
读与写·下旬刊(2017年3期)2017-04-27
中学生数理化·教与学(2016年2期)2016-11-25
语文周报·教研版(2014年11期)2015-01-17
试题与研究·高考语文(2009年1期)2009-04-16
中学英语之友·高一版(2008年11期)2008-12-10
中学生英语高效课堂探究(2008年10期)2008-11-19
