
基于词向量的文本分类研究∗
2019-02-27 08:31李沙沙
计算机与数字工程 2019年2期
马 力 李沙沙
(西安邮电大学 西安 710061)
1 引言
随着微博、微信等社交网络的兴起及迅速普及,社交网络成为了人们表达情感和相互交流的主流方式之一。个人和组织越来越多地将网络上情感观点信息用于决策,情感分析技术应运而生[1]。
微博文本大多简短,主要依靠词语级的情感分析得出句子级的情感倾向,特征选择是文本分类中非常重要的部分。Kim[2]等通过维基百科构建扩展词表,将文本表示为概念向量,使用SVM进行分类。Wang[3]利用知网确定文本中词语的上下位关系,并利用其进行特征扩展。Meng[4]等将短文本作为查询串提交给捜索引擎,取前N条返回结果作为短文本的背景知识,用来增强短文本的表达。Boyaziz[5]提出先利用LDA模型学习维基百科数据上的主题及主题在词语上的分布,用这些扩展短文本,再使用随机森林对扩展特征进行选择。
现有研究大多集中在提取词汇特征和句法特征,忽略了词语间的语义关系。近几年深度学习模型在自然语言处理方面也有很多应用[6~7],本文尝试将深度学习工具Word2vec训练得到的词向量应用到传统的特征选择过程中,使用大规模语料训练高质量的词向量,提出一种改进的特征选择算法,结合实验,所改进的算法具有较好的性能。
2 文本情感分析技术
文本情感分析[8]是指利用文本挖掘技术和自然语言处理技术,对文本中的情感信息进行提取的过程。文本分类大致可以分为训练和测试两个阶段,文本分类的基本流程如图1所示。

图1 文本分类流程图
语料库:准备训练文本和测试文本是文本分类的第一步,本文收集的文本数据主要来自于NLP&CC2014中文微博情绪识别评测任务中带标签的微博语料。
文本预处理,是滤除文本中的噪声词汇,准备处理模型所需的文本格式,为后续的文本处理奠定基础,其中主要包括处理编码格式、分词、去停用词等。本文分词工具采用张华平博士提供的NLPIR/ICTCLAS分词系统[9]。
特征表示[10~11],这个步骤处理结果会在很大程度上影响分类结果。文本的初始特征由文本中所有词语组成,为了降低维度和减少存储空间要选择合适的特征择方法来降维,同时提取到区分能力高的文本特征。本文主要工作就是对特征选择算法的改进。
分类器,经典的分类方法由贝叶斯Bayes、支持向量机SVM[12]、决策树、随机森林[13]等,选择合适的参数,通过训练构建分类器,对文本进行分类。本文对分类器不做过多研究和对比,直接选择性能较好的SVM对文本进行分类。
性能评价,针对文本分类问题提出性能评估的指标,对文本分类结果和分类器性能进行评估,一般选择正确率,召回率和F值。
3 情感特征抽取方法
如果把汉语词汇直接用做文本特征进行情感分类,其数据规模巨大,计算复杂度高。挑选具有强烈情感信息的特征词汇作为分类的依据,可以大幅度降低特征的维数,并提高分类的准确率。
3.1 特征选择
TF-IDF是常见的权重计算方法,考虑了词频和反文档频率的影响,使文本中较高频率的词组有相对比较大的权重。但权重计算不包含分类的相关信息,没有分辨哪个特征项在哪个类别中相对比较重要的功能,不能作为区分类别的方法,多数情况下是用来计算特征词在文本中的重要与否或者说重要程度。通过词频和文档频率,我们可以用TF-IDF权重计算方法计算出特征词在不同类别中的权重[14~15]。
文档集合D有K个分类D={D1,…,Dk},k∈K,Dk属于第k个分类的文档数量,对于特征词集T有:T={t1,…ti},i∈N(N个特征词)。dik代表特征词ti文档集Dk中出现的文档数量。tfik是特征词ti在Dk中的出现次数。idfik表示特征词的反文档频率。用式(1)进行计算:
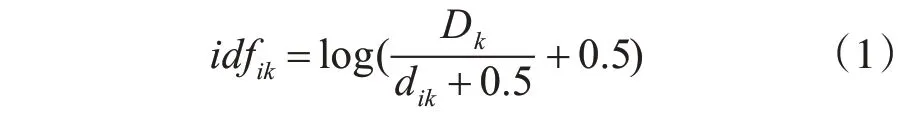
则特征词ti在文档集Dk中的权重为

权重计算方法是用来衡量特征项对文档中来说是否重要,并不能作为文本分类的特征项去进行文本分类。所以,我们用TF-IDF权重计算方法得出特征词在各种文档中的权重后,利用方差统计法和TF-IDF权重计算方法相结合。用方差的大小来表示数据是否平稳,方差小则数据平稳,方差大则数据不平稳。选择特征就是要选取具有明显类别区分能力的词汇,如果特征词在不同分类中计算出的方差值大,就可以认为这个被选择出来的词汇就是某种分类的代表。方差计算公式为如下:
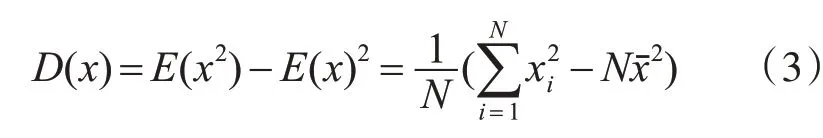
对K类中的某特征词xi的词频tfi计算其方差值,公式如下:

上式-tfi为特征词xi在各个类别中的平均词频,其中。
结合TF-IDF权重计算方法得出特征词在不同的类别中的权重wik。计算出其方差为

根据方差值的大小,将方差比较大、词频率高并且集中的特征词选择出来。影响这些词汇权重的是特征词的词频和分类中出现的文档数。
3.2 情感倾向判断
通过词频(TF)来进行情感倾向分析分类是最简单直接的方法,哪个类别的特征词在文本中的出现频率最高,该文本就会被认为是哪类情感。但由于训练文本的不完备性,这种方法的效果往往一般。我们选用TF-IDF权重计算方法计算特征词在不同的类别所占权重大小,选择权重最大的类别为该特征词的情感倾向。
经计算可以得出特征词xi分别在K类中的TF-IDF权重Wij,选择出权重最大的类别作为xi的情感倾向。情感倾向的计算公式如下:
TF方法:

TFIDF方法:
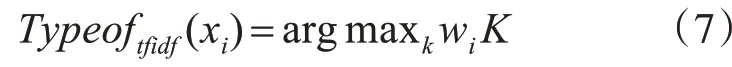
4 词向量特征选择改进算法
在传统NLP中,常用的词表示方法是One-hot Representation[16],这种方法把每个词表示为一个很长的向量。向量的维度是词表大小,只有一个维度的值为1,其余均为0,这个维度就代表了当前的词。这种方法非常简洁,但存在很严重的“词汇鸿沟”现象。在深度学习中,使用Distributed Representation表示一种低维实数向量,这种方法被称为“词向量”。
4.1 Word2vec
Word2vec,由Google的Tomas Mikolov团队提出并实现,是一款将词表征为实数值向量的高效工具,该算法能够在较短的时间内,从大规模语料库中学习到高质量的词向量。
Word2vec通过训练,可以把对文本内容的处理简化为K维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度,利用word2vec训练学习得到的词向量表示,考虑了词语之间的语义关联关系,可以被用来做很多自然语言处理或者文本数据挖掘的工作与研究,比如找同义词,聚类等。
使用Word2vec首先要针对自己的使用情景,准备一个语料库,然后对文本进行预处理,把语料整理成Word2vec的输入格式,然后对其进行训练。得到模型后可以查看单词的临近项,给定词语w1的词向量vw1和w2的词向量vw2,定义两个词语的语义相似度为两个词向量的余弦相似性,计算公式为

其中vw1⋅vw2表示两个向量的内积,||vw1||表示向量vw1的模长度。
对Word2vec训练后对“干净”一词查看它的临近项得到的结果如表1所示。

表1 词向量最相关词实例
在训练数据集数据量比较大的情况下,利用Word2vec训练学习得到的词向量质量较高,利用词向量计算词语的相似度准确率很高,这为本文基于词向量的文本特征选择改进算法提供了良好的保证。从表中结果可以初步判断,通过词向量进行特征扩展的想法是可行的。
4.2 基于词向量的特征扩展算法
得到词向量是特征扩展算法的第一步,词向量的表示方式支持直接对词语进行语义相似度的计算,因此可以根据前面特征选择的结果进行基于词向量的特征扩展。
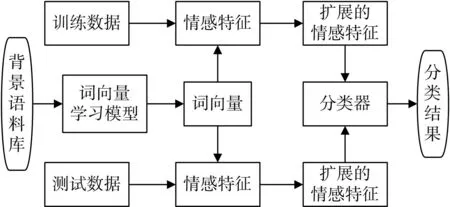
图2 基于词向量的特征扩展流程
本文将词向量存在语义关联关系的特性应用到文本特征选择中,提出基于词向量的特征选择算法,对传统特征选择算法进行改进,改进的主要思想是基于词向量之间的语义关联性,对特征词按照一定规则进行扩充,使得扩充后的特征词更有类别表征能力。基于词向量的特征选择算法改进基于如下假设:与具有较强类别表征能力的特征词最相似的词语,也同样具有较强的类别表征能力。具体改进步骤如表2所示。

表2 特征扩展算法
利用上述扩展方法对训练数据进行处理,计算扩充后的特征词集合中特征词的TF-IDF权值,得到扩展结果后进行分类。
5 实验分析及结论
5.1 实验语料
本次实验数据选用微博语料库(NLPIR)通过自然语言处理与信息检索共享平台予以公开共享的23万条数据训练Word2vec工具,得到词向量备用。然后从NLP&CC2014中文微博情绪识别评测任务语料中,抽取带标签的微博语料用于实验,其中包括2000条正面类别样本和2000条负面类别样本。分别使用文中介绍的特征提取方法和改进的基于词向量的文本特征扩展方法进行实验。
词向量训练时语料库的量级、向量维数等对分类性能都有影响,实验过程采用单一变量控制法进行对比。
5.2 基于TFIDF特征选择
本文的文本分类实验,首先对文本进行预处理;然后采用方差统计和TF-IDF权重计算相结合的特征选择算法进行特征选择,并根据每个特征词的类别区分能力采用TF-IDF算法对其赋予相应的权值;最后将选择好的特征词送入分类器进行训练,这里的文本分类器采用的是SVM。对测试文本进行分类测试,通过结果评价分类效果。通过取不同特征维数观察分类器的分类效果如图3所示。
特征向量通过3.1中介绍的特征选择方法取得。由实验结果可以看出,特征维数较小时,准确率的波动较大,当特征维数在100左右时分类准确率达到最大,当特征维数大于100后准确率又逐渐减小。分析原因可能是当维度过大时会加入一些对类别区分能力有影响的词,而维数过小又不能准确概括类别,选择合适的维数会对分类效果有一定的提升。
5.3 特征扩展算法
首先利用大量微博语料训练Word2vec工具得到词向量,这里语料库越大所得到的词向量的相关性越准确,当然语料库太大会导致训练时间过长。通过4.2中提出的特征扩展算法观察扩展的特征词个数对分类结果的影响,这里特征维数选择100,分类准确率如图4所示。

图4 不同扩展特征词个数分类准确率
由实验结果可以看出,在基于词向量的特征扩展方法中,扩展特征词个数对分类结果有较为明显的影响。当加入的扩展词较少时,那么加入的词与短文本的内容就越相关,准确率会得到提升,但提升效果有限。随着扩展词加入的越多,这些扩展的词与原短文本的相关性就越难保障,这些噪音词的引入会对文本的分类准确率带来负面影响。通过实验发现当特征扩展个数为4时分类的准确率达到最高。

图5 不同特征选择算法的分类准确率
从图5可以看出,在特征维数相同的条件下,改进后的基于词向量的特征扩展算法的分类准确率明显高于原始提出的特征选择算法,验证了本文所提方法的有效性。
实验结论:特征词的质量在很大程度上影响文本分类的准确率,特征词的个数及类别区分能力对分类结果有很大影响。通过实验发现选择100维左右的特征词并对这些类别区分能力较强的特征词进行扩展,当扩展特征词的个数为4时分类效果达到最优。
6 结语
本文基于深度学习的词向量训练工具Word2vec的工作原理,将原始特征选择算法忽略的词语间的语义关系应用到对原始特征选择算法的改进上,提出了一种基于词向量的特征扩展算法,通过对比实验验证了改进算法的有效性。本文着重研究情感特征的量化,并研究其对情感极性分类的影响,对情感细粒度的分类将是下一步需要继续研究的问题。
猜你喜欢
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
