
“习近平抗战胜利70周年讲话”日文译本比较研究
2019-01-23 01:39朱鹏霄
天津外国语大学学报 2019年1期
朱鹏霄
“习近平抗战胜利70周年讲话”日文译本比较研究
朱鹏霄
(天津外国语大学 日语学院)
以习近平主席在抗战胜利纪念大会上讲话的四个日文译本为对象,对比分析了中国媒体的译出文本和日本媒体的译入文本。考察发现日文译本多用汉语词汇,这和日本同类文本形成鲜明对比。和中国媒体译出文本相比,日本媒体译入文本在词汇密度、平均句长方面更低,在可读性方面更强,和日本同类政治文本更趋同。在翻译技巧方面,日文译本多采用顺译、分译及简译,对倒译、合译及增译的使用较少。
政治文本;日译;可读性;翻译技巧
一、引言
2015年是中国人民抗日战争胜利70周年,也是世界反法西斯战争胜利70周年。为铭记历史,缅怀先烈,珍爱和平,开创未来,2015年9月3日,中共中央、全国人大常委会、国务院、全国政协、中央军委在天安门广场举行了盛大的纪念大会,中共中央总书记、国家主席、中央军委主席习近平在大会上作了重要讲话。为了向世界报道中国,传递中国声音,人民网、中国网、中国国际广播电台登载了讲话的英文、日文等多个外语译文。为让本国民众及时了解中国,日本《产经新闻》也登载了讲话的日文译文。本文将以习近平讲话的四个日文译本为对象,对比分析中国和日本媒体翻译文本的共性及差异。
二、文献综述
在中国知网检索后发现对于习近平主席在纪念大会上的讲话学界多从政治学或传媒学的角度予以解读,翻译角度的研究尚不多见。在中国知网选取哲学与人文科学、社会科学相关文献分类,以“抗战”、“周年”、“讲话”、“翻译”为关键词进行全文检索,发现中国学界目前仅有郝苗(2016)、朱琳和侯晓舟(2016)、胡明(2017)等为数不多的研究。在日本的学术文献检索平台CINII上检索后发现目前尚无相关研究。郝苗(2016)以习近平主席在纪念大会上的讲话英文口译语料为对象分析了口译中汉语四字格词语的翻译策略,并基于目的论探讨了汉语四字格词语口译的翻译原则。朱琳和侯晓舟(2016)以习近平主席在纪念大会上的讲话英文翻译为对象,以“抗日战争”一词的翻译变化为切入点,分析了中国政治时事术语的变化与完善过程。胡明(2017)以习近平主席在纪念大会上的讲话俄文翻译为对象探讨了汉俄翻译中的文化迁移现象,分析了汉俄翻译中文化迁移产生的原因,提出了处理文化迁移的翻译策略。这些研究均在不同程度上揭示了政治文献翻译的规律,但笔者认为有几个方面尚存不足。首先,研究的外文语种有限。从文献综述不难得知迄今的研究多以英文或俄文翻译为对象,对于日文翻译尚未见任何研究。此次纪念大会的目的之一是纪念抗日战争胜利70周年,缺少讲话的日文翻译研究不得不说是一种遗憾。其次,研究的翻译文本有限。这些研究多使用中国媒体译出的翻译文本,缺少和国外媒体译入的翻译文本的比较。根据中外媒体针对同一源语的不同翻译文本开展译出和译入比较可有效挖掘影响译者翻译策略的因素,改进今后的翻译活动。最后,研究的方法不尽合理。目前的研究多择取翻译的一个断面,在案例分析上多依靠研究者的主观内省判断,缺乏合理有效的统计数据支撑。
三、研究目的与语料
针对迄今研究之不足,本文将以中国媒体和日本媒体网站上发布的习近平讲话的日文译本为对象对比分析不同翻译文本在词汇类型、词汇密度、平均句长、可读性及翻译技巧上的共性及差异特征,以期弥补前人研究之不足。本研究使用的习近平讲话的日文译本共四个,中国媒体方面使用了人民网、中国网、中国国际广播电台的三个译本,日本媒体方面使用了日本《产经新闻》的译本。为了对照分析翻译文本和日语同类文本之间的异同还使用了日本首相安倍晋三在2015年8月14日战后70周年讲话原文。
和英语不同的是,研究日语文本中的词汇需使用分词工具。本文使用了日本国立国语研究所开发的网页版的茶まめ(http://chamame.ninjal.ac.jp/),该工具内嵌了日本京都大学信息研究科开发的开源分词工具MeCab。同时也辅助使用了日本立命馆大学樋口耕一开发的文本挖掘工具KH Coder,该工具除MeCab外还内嵌有日本奈良先端科学技术大学院大学开发的分词工具Chasen。
四、日文译本比较研究
本节将以上文提到的四个日文译本为对象,对照分析翻译文本及日语同类文本之间的异同,重点弄清中外媒体翻译文本在词汇类型、词汇密度、平均句长、可读性上的异同。
1 词汇类型
日语中的词汇按来源可分为汉语、和语、外来语、混种语。受母语干涉的影响,以汉语为母语的日语学习者多使用汉语词汇(胡晓睿,2012)。讲话日文译本中的词汇类型分布如何呢?翻译文本中的词汇类型和日语同类文本间是否存在差异呢?
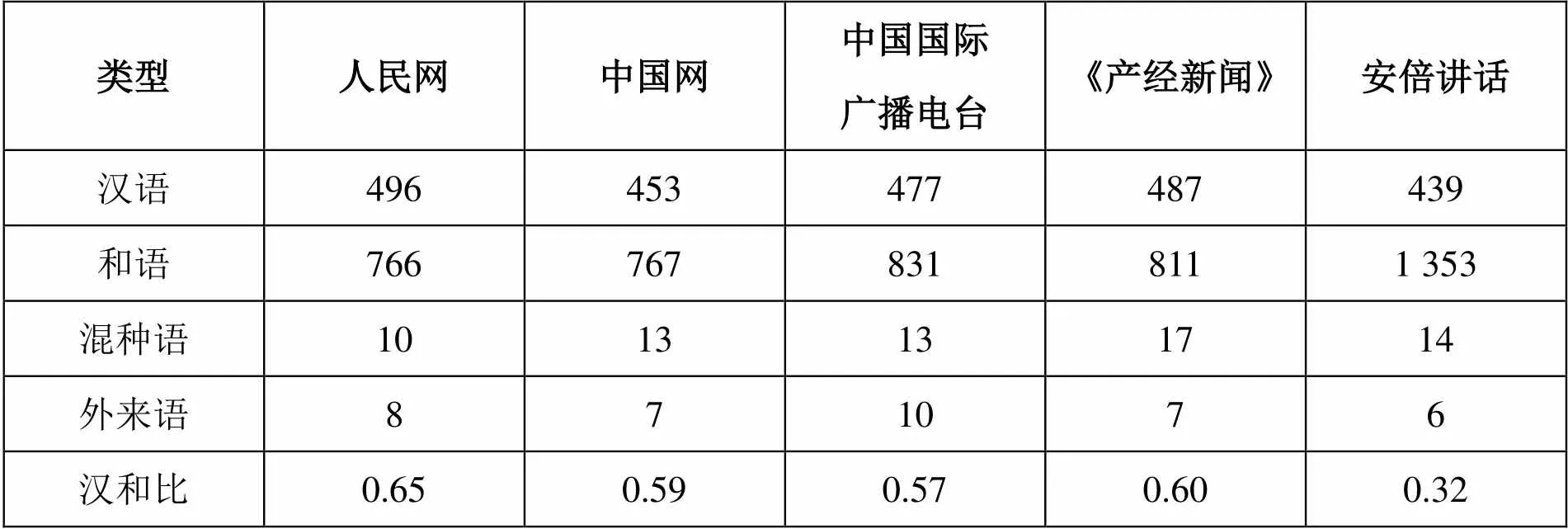
表1 翻译文本与日语同类文本的词汇类型
表1是以习近平讲话的四个日文译本及安倍讲话为对象,借助日本国立国语研究所的分词工具茶まめ进行解析后对文本中所用词汇类型进行统计的结果。从表1可知不论是中国媒体的译出文本还是日本媒体的译入文本,其中的汉语词汇与和语词汇之比均超过0.57,这和同类政治文本安倍讲话中的汉语词汇与和语词汇之比0.32形成了明显对照。
2 词汇密度
通过测量文本的词汇密度可以了解文本词汇的多样化和丰富性,还可以推知文本的文体。词汇密度的测定一般有三种方法:第一种是用不同词语数除以总词数再乘以100%(杨惠中,2002:168),第二种是用实词数除以单词总数再乘以100% (Ure,1971),第三种是用实词数除以篇章小句总数(Halliday,1985)。
表2是以习近平讲话的四个日文译本及安倍讲话为对象,借助日本国立国语研究所的分词工具茶まめ进行解析后①按上述三种公式对词汇密度的计算结果。观察表2不难发现两个倾向。首先,不论是采用杨惠中(2002)还是Ure(1971)的算法,四个日文译本的词汇密度均高度一致。Ure(1971)指出,词汇密度在40%以上时对象文本为正式的书面语体,在40%以下时为口语语体。不论是中国媒体的译出文本还是日本媒体的译入文本,均属于词汇密度较高的正式书面语。其次,采用Halliday(1985)的算法计算词汇密度时发现日本《产经新闻》译文中的词汇密度低于中国媒体的译出文本,更接近于日语同类文本安倍讲话的词汇密度。Halliday(1985)指出,词汇密度显示了文本中的信息密集度。词汇密度越大说明文章中的信息过度密集,阅读者理解起来越困难。相较于中国媒体的译出文本,日本《产经新闻》的译入文本更容易为目标语言的阅读者所接受。
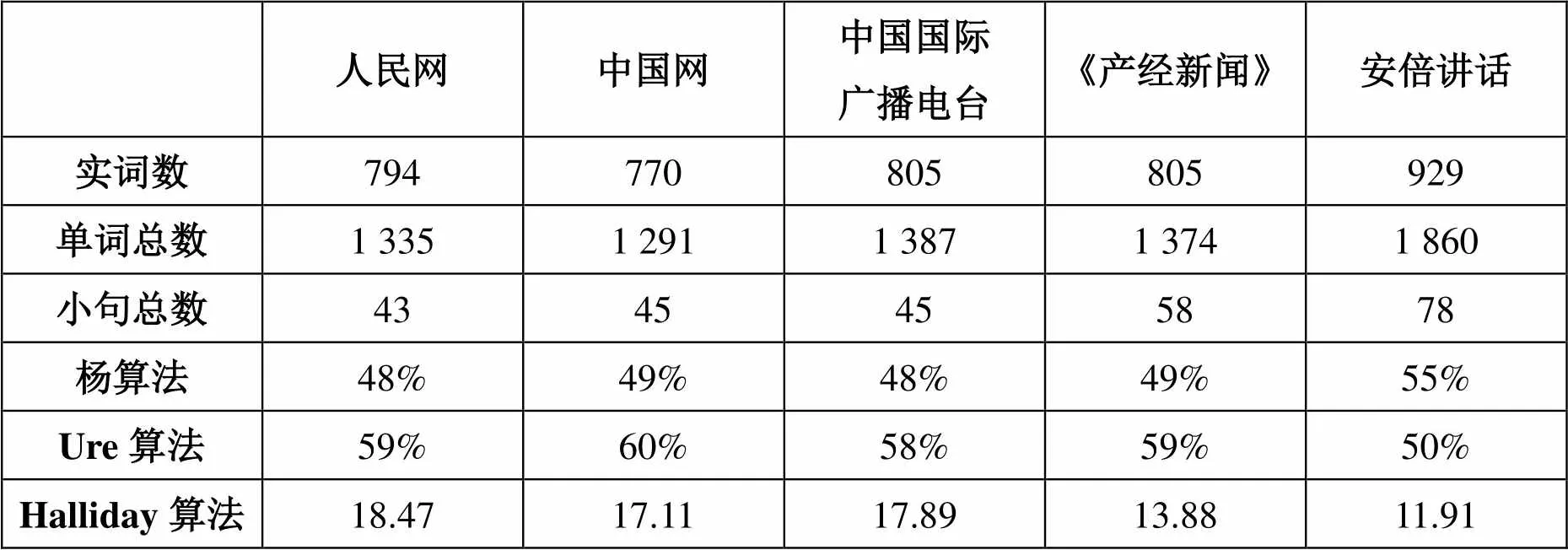
表2 翻译文本及日语同类文本的词汇密度
3 平均句长
平均句长是指文本中句子的平均长度,该指标参数多用来描述对象文本的句法复杂性,或用来衡量文本难易程度。一般而言,文本句子越长难度越大,可读性也随之降低。平均句长的统计一般有两种方法:一种是只统计每句中的含词数量,另一种是统计每句中连同标点符号在内的数量。考虑到标点符号的使用会影响阅读时的难易度,本研究采用后一种统计标准。目黑(2009)以1989-2009年间的《朝日新闻》、《读卖新闻》在日本宪法纪念日的朝刊社论为资料调查了日本政治文献的平均句长,发现《朝日新闻》的平均句长为22.8,《读卖新闻》的平均句长为24.2。这一调查结果也为我们评价政治文本的日文译本提供了一个参考。

表3 翻译文本及日语同类文本的平均句长
表3是对习近平讲话原文及四个日文译本、安倍讲话平均句长的统计结果,日文译本的平均句长均低于讲话原文平均句长,这说明译者均进行了句长简化处理。和中国媒体的译出文本相比,日本《产经新闻》的译入文本平均句长更短,更接近安倍讲话及目黑(2009)调查得出的日语同类文本的平均句长。这说明日本《产经新闻》译者为提高目标语言阅读者的可接受度进行了更高程度的句长简化。
4 可读性
可读性是衡量一个文本是否容易阅读和理解的重要指标参数。文本可读性研究最早始于美国,常用来测量英文文本可读性的指标公式有福格指数、福来士易读指数、福来士难度级、自动可读性指数等(张燕、陈建生,2010:105)。受日语文本特点的制约,日本的可读性研究直到上世纪60年代才开始起步,此后阪本(1964)、建石(1988)、柴崎(2010)、佐藤(2012)、李在镐(2016)等陆续提出了各自的评测公式。鉴于佐藤(2012)和李在镐(2016)均以大规模语料库作参照,本文采用两者的评测指标。
佐藤(2012)以教科书语料库为参照,根据文本中的文字出现概率来评估文本可读性,提出的评测公式为L(Gi/T)=ΣC(W)LogP(W/Gi),公式中的T指评测的对象文本,W指对象文本中包含的单词,C(W)指对象文本中单词的频度,P(W/Gi)指难易度Gi的语料库中单词的出现概率。李在镐(2016)以日语书面语均衡语料库为参照,首先对对象文本进行形态素解析,计算其中的平均句长、动词及助词的占比,并将所得结果带入评测指标公式({平均句长*-0.056}+{汉语比率*-0.126}+{和语比率*-0.042}+{动词比率*-0.145}+{助词比率*-0.044}+11.724)来评估文本可读性。

表4 翻译文本及日语同类文本的可读性
表4是以习近平讲话的四个日文译本及安倍讲话为对象的文本可读性计算结果。由于算法不同,数值解读方式也不同。在佐藤(2012)的算法中,数值越低说明可读性越高;在李在镐(2016)的算法中,数值越高说明可读性越高。安倍讲话原文的文本难度要低于习近平讲话的日文译本。日本《产经新闻》的译入文本的可读性更高,文本难度最低,这一观察结果和前面表2和3的数据结果相一致。
五、翻译技巧
熊兵(2014)在梳理了翻译策略、翻译方法、翻译技巧三个概念后,将翻译策略分为归化和异化两大类,将翻译方法分为八类,并归纳了增译、减译、分译、合译、转换等五种翻译技巧。本文在熊兵(2014)的基础上将翻译技巧分为顺译和倒译、分译和合译、减译和增译六种,探析政治文本翻译技巧的特点。
1 顺译和倒译
顺译是指在保持原文结构和形式的前提下表达出原文所有的含义(薛志懋,1986:89)。例如:
(1)中国人民抗日战争和世界反法西斯战争,是正义和邪恶、光明和黑暗、进步和反动的大决战。
中国人民抗日戦争と世界反ファシズム戦争は正義と邪悪、光と闇、進歩と反動の大決戦でした。(人民网)
翻译过程中有时会对状语等作必要调整,但调整后的结构和原文相仿,形式也大致相近,仍属顺译范畴(同上:90)。例如:
(2)为了和平,中国将坚持走和平发展道路。
平和のため、中国は平和的発展路線を堅持します。(人民网)
倒译是翻译中的一种变序操作,即根据需要将原文中间或后面的内容向前推译的一种方法(同上:92)。例如:
(3)让我们共同铭记历史所启示的伟大真理:
歴史の啓示したこの偉大な真理を共に銘記しましょう。(人民网)

表5 日文译本中的顺译和倒译
表5是对习近平讲话四个日文译本中顺译和倒译的统计结果,文中数字表示使用相应翻译技巧的数量。不论是中国媒体的译出译文还是日本媒体的译入译文,均绝对多数地采用了顺译,仅在人民网译文中出现了上面例(3)一处倒译。
2 分译和合译
分译是指把原文一个句子切分为两个或两个以上的句子(熊兵,2014:87)。本文将习近平讲话四个日文译本中采用分译的条件和动机分为了四类。第一类是原文中存在并列关系和结构,如例(4)中的“共同维护”、“积极构建”、“共同推进”所引领的小句构成了并列关系。
(4)世界各国应该以联合国宪章宗旨和原则为核心的国际秩序和国际体系,以合作共赢为核心的新型国际关系,世界和平与发展的崇高事业。
世界各国は共に、国連憲章の趣旨と原則を核心とする国際秩序と国際体制を守るべきだ。協力し共に利益を得ることを核心とする新型国際関係を積極的に構築し、ともに世界の平和と発展という崇高な事業を推進すべきだ。(《产经新闻》)
第二类是原文中存在因果关系,如例(5)中的句首小句和后面构成了一定的因果关系,同时句首以外的小句之间还存在并列关系。
(5)中国人民解放军是人民的子弟兵,全军将士要牢记全心全意为人民服务的根本宗旨,忠实履行保卫祖国安全和人民和平生活的神圣职责,忠实执行维护世界和平的神圣使命。
中国人民解放軍は、人民の子弟たる兵だ。全軍の将校と兵士は、全身全霊をかけて人民のために奉仕するという根本的な趣旨を心に刻み、忠実に祖国の安全と人民の平和的な生活を守るという神聖な職責を履行しなければならない。忠実に世界平和を守るという神聖な使命を遂行しなければならない。(《产经新闻》)
第三类是原文中存在转折关系,如例(6)中的句首小句和第二个小句就构成了转折关系。
(6)今天,和平与发展已经成为时代主题,但世界仍很不太平……
今日、平和と発展はすでに時代の主題となっている。しかし、世界はなお、どうも太平ではない。(《产经新闻》)
第四类是为凸显内容而采取的分译,如例(7)中为凸显裁军数量,译者刻意将谓语的内容独立分开译为了一句。
(7)我宣布,中国将裁减军队员额30万。
私は宣言する。中国は今後、軍隊の人員を30万人削減する。(《产经新闻》)
合译是指将原文的两个或多个句子合并为一个句子(熊兵,2014:87)。本文将习近平讲话四个日文译本中采用合译的条件和动机分为三类。第一类是两个原文间存在相同的主语,如例(8)中两个句子的主语均是“这一伟大胜利”,译者为了避免重复采取了合译。
(8),重新确立了中国在世界上的大国地位,使中国人民赢得了世界爱好和平人民的尊敬。,开辟了中华民族伟大复兴的光明前景,开启了古老中国凤凰涅槃、浴火重生的新征程。
この偉大な勝利により中国は世界において大国としての地位を再び確立し、平和を愛する世界の人民に尊重され、中華民族の偉大な復興の光を切り開き、古い中国の再生の道を歩み始めた。(中国网)
第二类是两个原文间存在相同或类似的谓语,如例(9)中的“致以崇高的敬意”和“表示衷心的感谢”结构类似。
(9)向为中国人民抗日战争胜利作出重大贡献的海内外中华儿女,!向支援和帮助过中国人民抵抗侵略的外国政府和国际友人,!
中国人民抗日戦争勝利のために大きな貢献をしていた国内外の中華民族の皆様に崇高たる敬意をあわらし、中国人民による侵略抵抗の戦いのために援助し支援していた外国政府と交際の友人の皆様に心から感謝申し上げる。(中国网)
第三类是两个原文间存在因果关系,可以采取合译的方法,如例(10)。
(10)为了和平,我们要牢固树立人类命运共同体意识。偏见和歧视、仇恨和战争,只会带来灾难和痛苦。
平和のために我々は、人類が運命共同体であるという意識をしっかり持ち、偏見や差別、憎しみや戦争が災難と苦痛を導くものでしかないことを認識するべきである。(中国网)
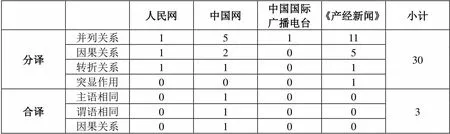
表6 日文译本中的分译和合译
表6是对习近平讲话四个日文译本中分译和合译的统计结果,不论是中国媒体的译出译文还是日本媒体的译入译文,均绝对多数地采用了分译,仅在中国网的译文中出现了三处合译。相较于其他译文,《产经新闻》的译文中采取的分译更多,这也间接说明了其平均句长短和可读性强的原因。
3 简译和增译
减译是指根据目标语言的词法、句法等需要删减内容(熊兵,2014:86)。本文根据习近平讲话四个日文译本中删减的句子成分将减译分为四类。第一类是称呼语的减译。为增强与听众的交际互动性,原文前后使用了四次称呼语。对于这些反复出现的称呼语日文译本均不同程度地进行了减译甚至不译。例如:
(11)全国同胞们,尊敬的各位国家元首、政府首脑和联合国等国际组织代表,尊敬的各位来宾,全体受阅将士们,:
全国同胞の皆様、尊敬する各国首脳、政府首脳と国連なのどの国際機構の皆様、尊敬するご来賓の皆様、閲兵式に参観する兵士の皆様、。(中国网)
第二类是定语的减译。对于原文中出现的根据语境不言自明的定语或前后句反复出现的定语译者多进行减译,如例(12)原文中出现了两次“世界反法西斯战争”,译文的后半句则删减了一次定语。
(12)在那场战争中,中国人民以巨大民族牺牲支撑起了的东方主战场,为胜利作出了重大贡献。
あの戦争中、中国人民は多大な民族の犠牲を以て、の東方の主戦場を支え、勝利のために大きな貢献を果たした。(《产经新闻》)
第三类是谓语的减译。上下文语义相近且结构并列时,译者多对这种重复性的谓语进行删减,以保持译文的简洁。例如:
(13)伟大的爱国主义精神,伟大的抗战精神,万众一心,风雨无阻,向着我们既定的目标继续奋勇前进!
偉大なる愛国主義精神、抗日戦争精神をさせながら、一体となって、風雨に負けることなく、我々が決めた目標に向かって勇敢に前進し続けよう。(中国网)
第四类是主语的减译。和汉语不同,日语中的主语常常省略,省略后的主语可以通过谓语的变化来提示和推知。例如:
(14)宣布,中国将裁减军队员额30万。
ここに、中国は兵員を30万人削減することを宣言いたします。(中国国际广播电台)
增译是指在翻译时增添内容(熊兵,2014:86)。本文根据习近平讲话四个日文译本中增加的句子成分将增译分为三类。第一类是增加定语,如例(15)中的“苏联”在翻译时根据目标语言的表述习惯增加了定语进行了限定说明。
(15)死亡人数超过2700万。
の死者は2700万人を超えた。(《产经新闻》)
第二类是增加状语,如例(16)的原文蕴含了今后的语义,但未表诸于形,在翻译时增加“これから”进行了凸显。
(16)也一定能够创造出更加灿烂的明天。
もきっと、一層輝かしい未来を築くことができる。(中国国际广播电台)
第三类是增加宾语,如例(17)中的“扩张”一词尽管日语和汉语用法相同,但为了准确传达信息,也为了和前面的动宾结构“称霸”保持平衡,翻译时增加了宾语。
(17)中国都永远不称霸、永远不搞扩张。
中国は永遠に覇権を唱えなく、拡張することもない。(中国网)
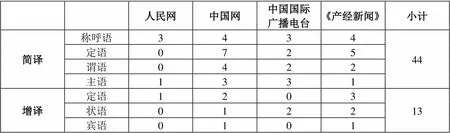
表7 日文译文中的简译和增译
表7是对习近平讲话四个日文译本中简译和增译的统计结果,不论是中国媒体的译出译文还是日本媒体的译入译文,均较多地采用了简译。这也间接印证了译者往往会在目标语文本中对源语文本进行简化处理的倾向(于红,2016:79)。当然政治文本中的简译对象多为重复出现或通过文脉可推知的内容,随意性并不强。政治文本翻译中尽管使用增译,但出于忠实原则的考虑,增加的多非必要成分。
六、结语
本文以国家主席习近平在抗战胜利纪念大会上讲话的四个日文译本为对象统计了词汇类型、词汇密度、平均句长、可读性,并与同类政治文本安倍讲话进行了对比,在此基础上对日文译本中的翻译技巧进行了分析。考察发现日文译本均多用汉语词汇,这和日本同类政治文本形成鲜明对比。和中国媒体的译出文本相比,日本媒体的译入文本在词汇密度、平均句长方面更低,在可读性方面更强,和日本同类政治文本更趋同。日文译本中多采用顺译、分译及简译,对倒译、合译及增译技巧的使用相对较少。相较英语等学科的翻译研究而言,日语学界的翻译研究尚不繁盛,基于语料的统计分析尚不多见。本文也仅仅是对政治文本日译语言特征的个案研究,受语料规模及研究工具所限,今后还有必要对文中所得结论进一步验证。
注释:
①在使用杨惠中(2002)的算法时采用了KH Coder工具中内嵌的Chasen的自动统计结果。
[1] Halliday, M. A. K. 1985.[M]. Victoria: Deakin University Press.
[2] Ure, J. 1971. Lexical Density and Register Differentiation[A]. In G. Perren & J. Trim (eds.)[C]. Cambridge: Cambridge University Press.
[3] 佐藤理史.2012.日本語テキストの難易度判定ツール[A].第3回産業日本語研究会・シンポジウム予稿集.
[4] 坂本一郎.1964.文の長さの比重の測定法[J].読書科学, (1): 2-6.
[5] 柴崎秀子.2010.12学年を難易尺度とする日本語リーダビリティー判定式[J].計量国語学, (1): 215-232.
[6] 建石由佳. 1988.日本文の読みやすさの評価式[J].文書処理とニューマンインターフェース, (4): 1-8.
[7] 李在镐.2016.日本語教育のための文章難易度に関する研究[J].早稲田日本語教育学, (21): 1-16.
[8] 目黒健太. 2009.憲法九条をめぐるメディアの主張——朝日新聞・読売新聞の社説の比較[EB/OL].https://www.msi.co.jp/tmstudio/stu09contents/stu09_03.
[9] 陈爱兵. 2012.基于语料库的政论文英译语言特征研究[J]. 山东外语教学, (1): 102-107.
[10] 郝苗. 2016.目的论指导下汉语四字格词语的口译策略——以习近平主席抗战胜利70周年阅兵式讲话为例[J]. 海外英语, (1): 101-103.
[11] 胡明. 2017.汉俄翻译中的文化迁移探析——以习近平在纪念抗战胜利70周年大会上的讲话为例[J]. 中国翻译, (4): 101-103.
[12] 胡晓睿. 2012.日本語学習者の作文における漢語の使用について[A].第九回国際日本語教育・日本語研究シンポジウム予稿集.
[13] 熊兵. 2014.翻译研究中的概念混淆——以“翻译策略”、“翻译方法”和“翻译技巧”为例[J]. 中国翻译, (3): 82-88.
[14] 薛志懋. 1986.谈翻译中的顺译和倒译[J]. 杭州师院学报(社会科学版), (4): 89-95.
[15] 杨惠中. 2002.语料库语言学导论[M]. 上海: 上海外语教育出版社.
[16] 于红. 2016.基于语料库的政府公文翻译“简化”趋势考察——以白皮书《2010年中国的国防》英译文为例[J]. 外语研究, (3): 79-86.
[17] 张燕, 陈建生. 2010.《霍小玉传》两个英译本的翻译风格[J]. 重庆工商大学学报, (4): 111-116.
[18] 朱琳, 侯晓舟. 2016.“抗日战争”一词的翻译变化研究[J]. 社会科学论坛, (12): 242-247.
A Comparative Analysis of the Four Japanese Versions of President Xi’s Speech on the 70th Anniversary of the Victory of Anti-Japanese War
ZHU Peng-xiao
Based on the four Japanese versions of President Xi’s speech on the 70th anniversary of the victory of anti-Japanese war, this paper makes a comparative analysis of the texts of Chinese media and Japanese media. It reveals that Chinese words are borrowed a lot in the Japanese version, which is obviously different from other Japanese political texts. Compared with Chinese media’s text, Japanese media’s text is characterized by low lexical density, short sentence and good readability, similar to other Japanese political texts. In the aspect of translation strategy, sequential translation, split translation and omission are much more used than reverse translation, combined translation and amplification in the Japanese version.
political texts; Japanese translation; readability; translation strategies
H315.9
A
1008-665X(2019)1-0065-11
2018-05-31;
2018-08-16
天津市哲学社会科学规划重点委托项目“习近平著述及讲话日译策略研究”(TJWYZDWT1801-04);天津市哲学社会科学规划项目“基于平行语料库的主题省略汉日对比与翻译研究”(TJWW17-026)
朱鹏霄,教授,博士,研究方向:日语语言学
猜你喜欢
意林·作文素材(2022年3期)2022-03-19
中国卒中杂志(2021年7期)2021-07-31
戏曲研究(2019年3期)2019-05-21
红楼梦学刊(2019年4期)2019-04-13
西夏研究(2019年1期)2019-03-12
西夏学(2019年1期)2019-02-10
读书(2015年1期)2015-09-10
新闻前哨(2015年2期)2015-03-11
读者·校园版(2014年14期)2014-05-14
中国记者(2014年2期)2014-03-01
