
基于实体相似度信息的知识图谱补全算法
2018-12-14 05:30王子涵邵明光刘国军郭茂祖毕建东
计算机应用 2018年11期
王子涵,邵明光,刘国军,郭茂祖,毕建东,刘 扬
(1.哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001;2. 北京建筑大学 建筑大数据智能处理方法研究北京市重点实验室,北京 100044)(*通信作者电子邮箱yliu76@hit.edu.cn)
0 引言
在知识图谱中,知识以三元组〈头实体,关系,尾实体〉的形式存储,使得知识能够得到结构化整理[1], 但是知识图谱中的知识称不上完善,尤其是在大规模知识图谱中,需要不断补充实体关系进行知识图谱补全[2], 而由于信息量过大,实体之间的关系多且复杂,传统的利用链接预测的方法已经不能完成大规模知识图谱的补全[3], 所以对知识图谱的补全往往采用学习知识表示, 并定义得分函数、采用对三元组进行打分的方法实现关系预测。这样知识图谱的补全算法就成了对三元组的得分进行排序的算法[4]。
目前,学习知识表示的代表模型有距离模型、单层神经网络模型、能量模型、双线性模型、张量神经网络模型[5]、矩阵分解模型和翻译模型等[6]。其中效果较好的张量神经网络模型[5]和基于文档特征向量空间模型[7]都是在现有模型中加入了多层神经网络来进行知识图谱的补全[4]。这些方法虽然提高了链接预测能力,却增大了参数规模,并且一次仅能考虑一种关系,导致模型的扩展性较差、效率较低,无法应用于大型知识库[8],所以,翻译模型因其简单和准确性引起了广泛的关注。Mikolov等[9-10]通过类比实验发现, 词向量空间的平移不变现象普遍存在于词汇的语义关系和句法关系中[5],该现象的发现使得翻译模型TransE[11]被提出。该模型的主要思想是将关系作为对头实体的翻译(Translation),并根据尾实体和关系对头实体的翻译的相似度来定义得分函数。TransE模型的参数少、计算复杂度低却能够直接建立起实体和关系之间的复杂语义联系,在大规模稀疏知识图谱上,TransE的性能更是惊人[5]。为了能够更加精确地描述实体和关系之间的语义联系,Trans系列模型[3,12-16]都在TransE的基础上被提出。虽然这些模型的预测能力相较TransE有所提升,但是增大了参数规模,部分模型[3,14-16]还需要用TransE对参数进行预训练,这些都增加了计算的复杂度,使得模型扩展性变差。文献[4]提出ProjE (Embedding Projection for Knowledge Graph)模型成功避免了这些问题,该模型不需要预训练,参数规模小且预测能力较强。然而,由于ProjE的关注点在于实体与关系之间的联系导致它并没有能够充分利用神经网络感知和分析实体向量所代表的语义信息。通过研究Unstructured Model (UM)[17],得到具有关系的实体可能集中在一些小区域内的结论。由于向量空间可以看作是实体的语义空间,也就是说比较相似的实体之间更可能具有关系,所以实体是否相似可作为是否存在关系的一个衡量标准。利用这个标准和ProjE模型,神经网络可以同时分析两个实体之间是否存在关系和具体存在什么关系,相当于侧重分析在实体分布集中的那些局部空间中的实体之间的具体关系,所以本文提出了一种新的算法——LCPE(Local Combination Projection Embedding),并通过在标准数据集上的实验证明LCPE的预测能力优于ProjE。
综上所述,本文的主要贡献是:
1) 发现了一种可以用于辅助判断实体之间是否存在关系的辅助信息——实体之间的语义相似度,而语义相似度可以利用实体向量在实体嵌入空间中的距离来判断;
2) 提出了LCPE算法,将ProjE模型和实体相似度信息融合,该模型可以同时判断两个实体是否存在关系和具体存在什么关系,并通过实验验证了LCPE在与ProjE参数规模相同的情况下预测能力提升。
1 LCPE模型
1.1 相关模型
翻译模型TransE[11]的中心思想是将关系看作是头实体到尾实体的翻译,头实体h、关系r和尾实体t之间的关系表示如下:
h+r≈t
(1)
因此,TransE的得分函数定义为:
E(h,r,t)=|h+r-t|L1/L2
(2)
即向量h+r和t之间的L1或L2距离,其本质上是衡量h+r和t之间的相似度。
通过以上介绍可知, TransE模型的参数规模为nek+nrk,其中ne和nr分别是知识库中实体和关系的数量,k是特征维数。
ProjE模型[4]的基础模型是共享变量的神经网络模型, 它利用组合矩阵D对实体和关系进行组合作为关系对头实体的翻译,组合运算如式(3)所示:
e⊕r=Dee+Drr+bc
(3)
假设实体和关系被嵌入到k维向量空间中,那么e∈Rk表示实体向量,r∈Rk表示关系向量,De、Dr∈Rk×k是组合矩阵,由于在这类问题中考虑同一实体和关系的不同的特征维度之间的相互作用关系意义并不大[5],所以De、Dr被设为对角阵,bc表示偏置量。
利用(3)定义的组合规则,结合关系作为头尾实体的翻译的核心思想,ProjE提出得分函数(4)用于衡量尾实体与e⊕r之间的相似度:
h(e,r)=g(Wcf(e⊕r)+bp)
(4)
其中:f和g是激活函数,Wc∈Rs×k是候选实体集组成的矩阵,其中s表示候选实体的数量,bp表示偏置。
ProjE模型与TransE模型相比,参数量只多了5k+1,其中,得分函数中的偏移量、组合矩阵和组合运算中的偏移向量分别占1、4k和k个参数。不仅如此,ProjE模型不需要预训练,相较需要通过预训练提高预测精确度的模型[3,15-17],它训练模型所需要的时间更少,模型的扩展性也得以增强。
1.2 LCPE算法概述
由于ProjE模型只是简单地考虑向量t和向量h⊕r之间的相似度,并没有充分利用实体嵌入向量的语义信息,导致神经网络可以分析的信息不足,优势无法完全发挥。
Unstructured Model[17]是r=0时的TransE模型,在UM中,所有实体之间的关系都视为单关系,即不考虑实体之间的具体关系类型,只考虑这实体之间是否存在关系。由于r=0,结合TransE的得分函数式(2)可知,在UM中,当两个实体之间具有某种关系时,这两个实体嵌入向量之间的距离会比较小,并且两个实体之间具有的关系越多,得到的嵌入向量之间的距离就会越小。直观来说,实体是由多个属性描述的,实体在语义空间中的嵌入向量就是用于描述实体的属性值集合,实体嵌入向量之间的距离越小,就代表这两个实体越相似。综上所述,实体越相似,实体之间存在关系的可能性越大。这个结论适用于大多数事实,例如父子关系,这个关系产生于同类实体之间,并且父子之间具有很多相同或相似的属性,比如所在地、长相、家庭等,这些属性值相同或接近都缩小了父子这两个实体的嵌入向量之间的距离。
综上,两个实体是否相似可以作为实体之间是否存在关系的一个判断条件,并通过判断两个实体之间是否存在关系来加强模型的链接预测能力。由于相似的实体嵌入向量在向量空间中距离更近,所以相似的实体嵌入向量会集中在向量空间中的一些小区域中,利用两个实体是否相似作为加强预测能力的辅助信息就意味着侧重于在那些实体分布稠密的局部空间判断实体之间的具体关系类型,因此本文提出了LCPE模型,它将ProjE模型和实体相似度信息相结合,充分发挥了神经网络模型的优势,提高了模型的链接预测能力。
本文将实体之间的相似度作为辅助信息加入ProjE模型,定义得分函数:

(5)
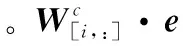
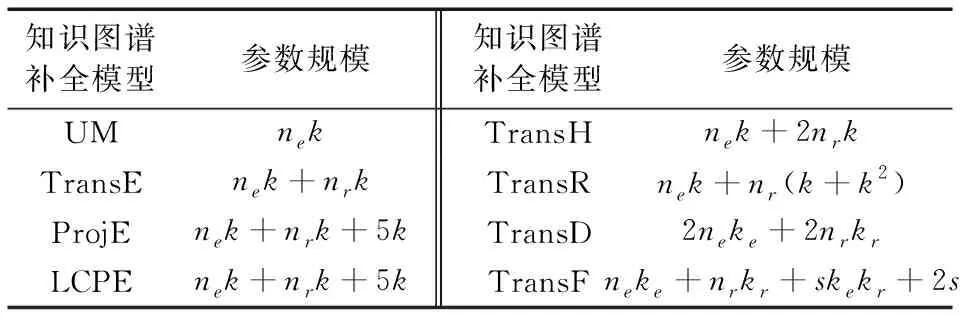
表1 各模型的参数规模对比
注:ne表示实体数,k表示对应实体向量和关系向量的参数个数,
s表示关系基空间的个数。
如图1所示,LCPE模型是一个由判断两个实体之间相似度的网络和判断两个实体之间是否具有某种关系的网络共同构成的神经网络。Wc是由候选实体向量组成的矩阵,WE表示实体向量构成的矩阵,WR表示关系向量构成的矩阵,Ei和Ej分别是从Wc和WE中提取出的一个实体向量,R是从WR中提取出的关系向量,De和Dr分别代表组合矩阵。
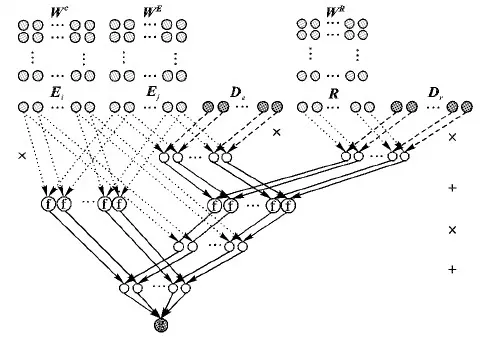
图1 LCPE模型结构
1.3 模型训练
在本文算法中,候选实体集虽然因为共享实体变量而没有增加参数的数量,但是如果每次都用全部实体集进行训练,也会导致巨大的运算量,所以要使用候选抽样的方法来减小候选实体集Wc的规模[18-20],并且利用Word2Vec[19]的规则对候选集进行负例抽样效果最好[4]。具体方法是对于一个给定的实体e,其训练所使用的候选实体集由全部的正例中的实体集和一部分负例中的实体集构成,为了简单起见,利用二项分布B(1,Py)来表示某个负例中的实体是否被选中,即Py表示该负例被选中的概率,而1-Py表示未被选中的概率,实验表明最优的负例抽样概率为25%[4]。
Trans系列模型通常都采用了pairwise方法对模型进行训练,损失函数L定义为如式(6)形式:
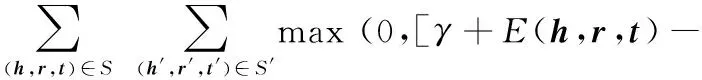
E(h′,r′,t′)])
(6)
其中:E表示三元组的得分函数;S表示正例三元组的集合,正例三元组是在原知识库中存在的三元组;S′表示负例三元组的集合,负例三元组是通过用知识库中其他的实体或关系替换正例三元组中的h、r或t产生的在原知识库中不存在的三元组。
近年来,softmax回归在多标签图像注释任务中取得了良好的效果,这是因为多标签图像注释以及许多其他分类任务应该综合考虑其预测出的候选集中的所有分数[5],因此,模型采用softmax函数以便考虑所有候选实体的分数,用softmax和tanh作为激活函数,将式(5)中的g和f分别用softmax函数和tanh函数替换可以将得分函数写成式(7)所示形式:
h(e,r)i=
(7)
并利用listwise方法进行训练。LCPE模型的损失函数定义为式(8):
(8)
其中:y∈Rs是一个二元标签向量;s是候选实体集的个数;yi=1代表第i个候选实体和实体e,关系r组成的三元组是一个正例三元组, 1(·)代表当括号内的等式成立时,1(·)=1,否则1(·)=0;h(e,r)表示三元组的得分函数(式(5)),而h(e,r)i表示第i个候选实体和实体e,关系r组成的三元组的得分。
预测问题归根结底是一个对得分进行排序的问题,而pairwise的训练方法并没有很好地解决实体预测排名的问题,所以利用考虑了整体的得分排名的listwise方法对模型进行训练效果更好[4]。
2 实验结果与分析
本章展示了实体相似度作为辅助项的可行性以及LCPE与之前提到的模型的预测结果对比。关系预测实验在两个公开数据集FB15k[21]和WN18上进行,FB15k是一个知识图谱的重要子集,WNID是一个WordNet[22]的子集,ID表示在WordNet中的ID,用于在WordNet中唯一标记一个子集。FB15k和WN18的实体、关系和三元组数如表2所示。

表2 实验使用的数据集
2.1 参数设置

2.2 实体相似度对比
为了防止嵌入向量的大小的影响,本文将计算实体之间的余弦距离用以衡量实体之间的相似度。随机提取LCPE中发生关系的实体对,计算它们的嵌入向量的余弦距离,同时对于上述实体,计算它们在ProjE中的余弦距离,最后计算二者的比值。实验在WN18数据集上进行。
实验结果如图2所示,纵坐标代表同一实体对在两个模型中的余弦距离比值(ProjE中的实体之间的余弦距离/LCPE中的实体之间的余弦距离)。实验结果显示距离比值大多大于1,这说明LCPE中具有关系的实体的余弦距离更小,和本文预期相符,也说明了实体相似度的辅助信息可以用作增强预测能力的辅助项。
2.3 链接预测结果
链接预测是为了预测三元组中缺失的头实体和尾实体的任务,而实体的预测问题归根结底是实体的得分排序问题,所以使用Raw Mean Rank、Filtered Mean Rank和Raw Hits@10、Filtered Hits@k作为对链接预测的预测效果评估指标。Raw Mean Rank是正确的实体在得到的得分序列中的平均排名; Raw Hits@k是指正确的实体在得分为前k的元素中出现的概率,但是,有其他的正确实体排在待测的正确实体之前的情况,所以还有一种衡量标准就是将其他的已知的正确实体删去之后再排序得到Filtered Mean Rank和Filtered Hits@k,它们分别代表删去了其他的正确实体后目标实体的平均排名和在前k个元素中出现的概率。由上述介绍可知,Raw Mean Rank和Filtered Mean Rnak越低越好,Raw Hits@k和Filtered Hits@k越高越好。本文将CLPE与Trans系列模型[3,11-17]及ProjE模型[4]进行对比。实验结果如表3所示。

图2 WN18中实体之间的余弦距离

数据集方法Raw Mean Rank(头实体/尾实体) Filtered Mean Rank(头实体/尾实体)Raw Hits@10(头实体/尾实体)Filtered Hits@10(头实体/尾实体)WN18UM31530435.338.2TransE26325175.489.2TransH318/401303/38875.4/73.086.7/82.3TransR232/238219/22578.3/79.891.7/92.0TranSparse(US)233/223221/21179.6/80.193.4/93.2TranSparse(S)235/224223/22179.0/79.892.3/92.8TransD242/224229/21279.2/79.692.5/92.2TransF—198—95.3ProjE248.9/254.3231.2/238.478.7/80.295.3/95.0LCPE234.2/238.3216.6/222.478.9/80.295.2/95.0FB15kUM1074 9794.56.3TransE24312534.947.1TransH211/21284/8742.5/45.758.5/64.4TransR226/19878/7743.8/48.265.5/68.7TranSparse(US)216/19066/8250.3/53.778.4/79.9TranSparse(S)211/18763/8250.1/53.377.9/79.5TransD211/19467/9149.4/53.474.2/77.3TransF—62—82.3ProjE278.7/181.883.8/58.741.1/48.774.5/79.6LCPE269.2/176.475.5/54.744.4/52.177.2/82.3
神经网络模型由于其出色的信息感知和分析能力可以利用更少的参数实现更强的关系预测能力。LCPE模型和ProjE模型充分发挥了这一优势,同时针对知识图谱补全问题采用listwise方法训练神经网络模型,考虑所有三元组的得分,尽可能保证所有正例的得分比负例的得分高,这也是它们的预测能力强的重要原因之一。
LCPE比ProjE在WN18数据集上Mean Rank平均提前了11,Hits@10提升了0.2个百分点; 在FB15k上Mean Rank提前了7.5,Hits@10平均提升了3.05个百分点。这也说明了实体相似度信息可以用于辅助判断实体间的具体关系类型,从而提高预测能力。
3 结语
知识图谱补全算法是对实体之间关系的预测算法,由于当今时代的信息量过大导致了预测模型可能具有巨大的参数量,所以如何利用尽可能少的参数量达到更高的预测精度就成了一个很重要的问题。ProjE算法不仅实现了小参数量并且能够更为出色的预测到实体之间的各种关系。通过对ProjE算法和Unstructured Model的研究,本文提出了CLPE模型,它将利用了实体之间的相似度作为辅助信息优化了ProjE模型,并通过实验证明了实体之间的相似度作为辅助信息的合理性以及CLPE在没有增大参数规模的基础上将模型的预测能力进一步提升。
以简单的共享变量神经网络为基础的算法在知识图谱补全方面取得了很好的效果,而如何将更多看似简单但其实很有效的方法利用到知识图谱补全算法中,或如何优化现有模型以取得更好的效果仍然有待研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
计算机与生活(2022年3期)2022-03-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少先队活动(2020年12期)2021-01-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
新城乡(2018年6期)2018-07-09
计算机系统应用(2017年5期)2017-06-07
领导科学论坛(2016年9期)2016-06-05
