
一个时态RDF存储系统的设计与实现
2018-12-20 02:06:16庞亚君
计算机技术与发展 2018年12期
庞亚君
(南京航空航天大学 计算机科学与技术学院,江苏 南京 210000)
1 研究背景及现状
随着时态数据处理和语义网的发展,越来越多的时态RDF格式的数据涌入网络。在对时态RDF的早期研究中,Gutierrez等提出了时态RDF的语法语义以及查询语言[1-3],Andrea等补充了非限定三元组的语法语义,并提出了tGRIN索引结构将时态RDF存储在关系型数据库中[3-4]。Geetha等针对海量RDF存储和语义网大量历史数据存储的问题,提出了一个基于语义的时态视图机制,通过演示验证了该机制可提高RDF三元组中的时变数据缓存到主存的效率[5-6]。时态RDF由于其独特的语义支持和推理机制,通常应用于人工智能领域中,如电力系统中[7]以及机器阅读技术中等。
对数据的管理离不开数据库的支持,而对于时态RDF数据的管理要建立在时态数据库研究的基础上。Tansel等在1993年对此前提出的时态数据库技术的研究及时态数据模型做了全面的总结[8]。之后,时态数据库研究重点由理论探讨逐渐转向模型的标准化和产品化。由于迄今为止时态模型尚不成熟未能完全统一等原因,各大数据库厂商还没有推出相关的时态数据库产品,目前大多数应用只是借助时态数据库的概念与传统的数据库相结合来完成的。文献[9-10]提出分层扩展RDBMS的思想,开发了TimeDB、TempDB等时态数据库产品。
文中以时态数据库管理系统TimeDB[11]为基础,设计并实现了一个时态RDF数据存储系统,切实解决当前时态RDF存储研究缺失的问题。
2 基础知识
2.1 时态RDF
2.1.1 时态RDF模型概念
对传统RDF时态扩展有两种方式:时态标签法和版本更新法。时态标签法也就是给产生变化的三元组添加时间标签;版本更新法不关心过去状态的时态RDF图存在何处,只记录更新后的时间快照。版本更新法可以更有效地获取事务时间,而在获取有效时间时通常使用时态标签法。虽然两种方法是等价的,当时态信息越多也就是RDF图更新频率越快,即产生的新版本也会越多,不断记录更新后的RDF图无疑增加了查询的复杂度,因此现有的时态RDF模型都是采用时态标签法进行时态扩展。
在时态RDF中,认为时间是离散的,线性有序的区域,使用时态标签法来对RDF进行时态扩展,也就是用时态元素t标记三元组(s,p,o)。时态元素包含时间点和时间区间,不难想到一个在时间区间时,该区间就等同与一个时间点t1。
2.1.2 时态RDF蕴含
一个RDF图可以看作是一个由其他知识库(也就是其他RDF图)得到的知识库。当为RDF蕴含扩展时态属性时,需要将时态数据库定义为所有快照的集合。
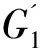
时态蕴含的概念往往和时间区间的运算一起作用于时态推理机制中,例如若有(a,sc,b):[2,3]和(b,sc,c):[2](其中SC为rdf:SubclassOF属性的缩写形式),那么可以推出(a,sc,c):[2]。
2.2 Jena工具
网页上的RDF数据通常以文档的形式存在,通用的RDF语法为Turtle(Terse RDF Triple Language)或者RDF/XML的格式。RDF数据以三元组“主语—谓语—宾语”的格式存储在关系型数据库中,因此在RDF数据存储到数据库之前,需要对RDF文档进行解析。Jena是一个使用Java编写的API(application programming interface,应用程序编程接口)[12],用于创建和操作RDF图。Jena将以三元组为中心的解析方法与以资源及其属性为中心的解析方法相结合,既可以对RDF三元组进行操作,也可以对单个的资源进行操作。
2.3 时态数据管理系统TimeDB
目前分层扩展非时态的数据库管理系统建立时态中间件成为实现时态数据库管理系统的最好方法。时态中间件不改变底层RDB的功能和结构,而是作为上层构件添加到应用程序和关系数据库之间,使得时态SQL语句能够转换成下层关系数据库可以理解的标准SQL语句。在目前所有的时态数据库应用中,TimeDB不论是在数据管理还是用户交互上都是目前最受欢迎、使用最为广泛的时态数据库产品化应用。
TimeDB的时态查询语言ATSQL2是在SQL标准查询语言的基础上加入了一些时态相关的关键字,TimeDB很容易将这些关键字识别出来并解释其包含的时态语义,其次确定语句要进行查询的具体类型,进行时态语言验证后通过关系操作的算法来实现语句的转换。
3 TRDF-STORAGE的设计实现
3.1 系统体系结构
TRDF-Storage存储时态RDF数据的具体流程如图1所示。输入数据为RDF/XML文档,首先将其解析为时态RDF三元组。解析后的三元组要通过推理机制的处理,以保证时态RDF的数据库的一致性,最后将处理后的不违背一致性的时态RDF三元组集合插入到时态数据库中。
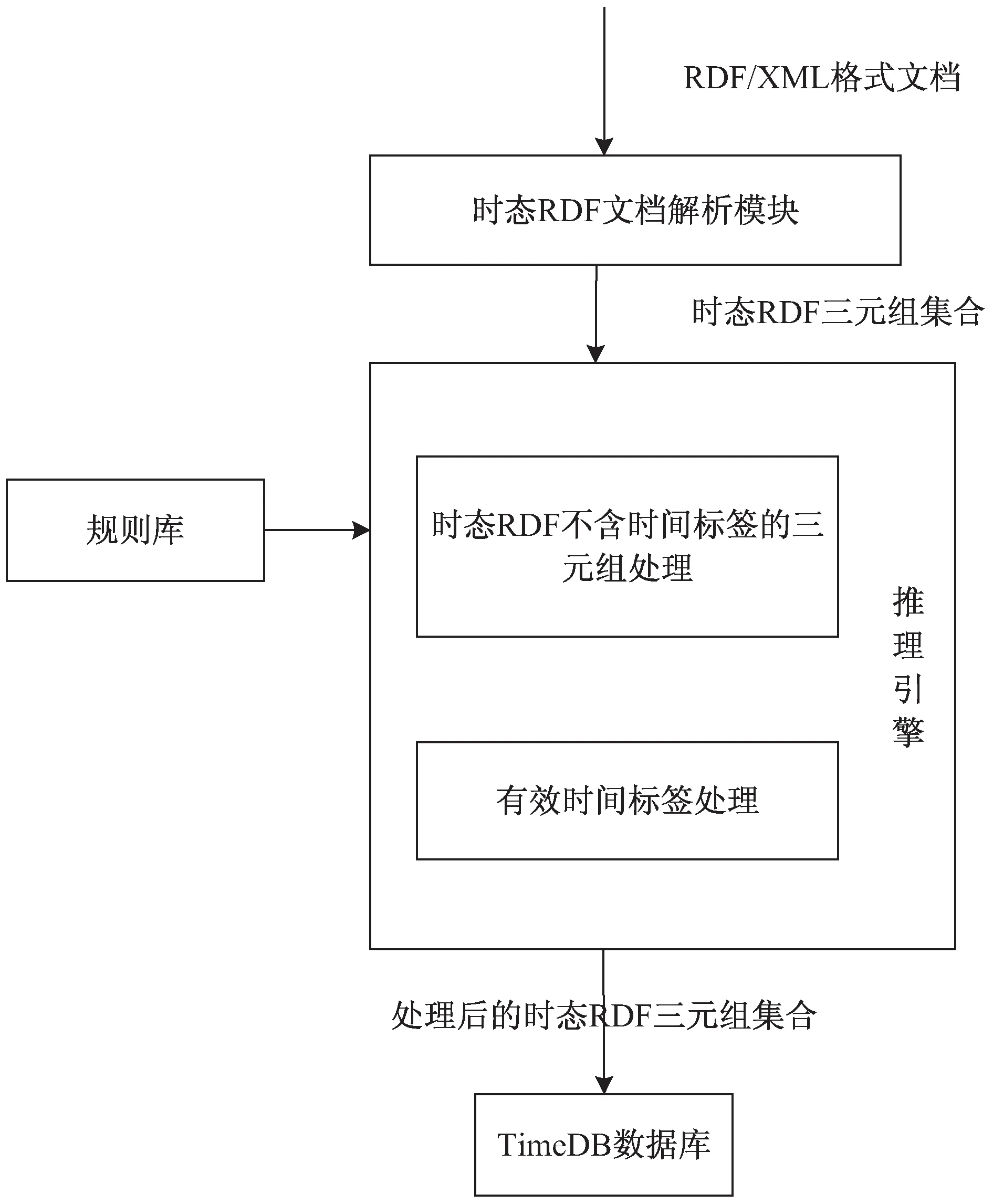
图1 系统层次图
3.2 时态RDF/XML文档解析模块
RDF标准规定在RDF中只存在三元组,如果直接为RDF三元组增加时间标签,那么三元组就变成了四元组。因此引入一个额外的对象即具体化(reification),将时态属性与原声明中的主语、谓语和宾语通过属性相关联。如时态RDF三元组(Joe,isFollowing,Marry):[2005-10-01,2017-06-27]被Jena工具解析后形式如图2所示。
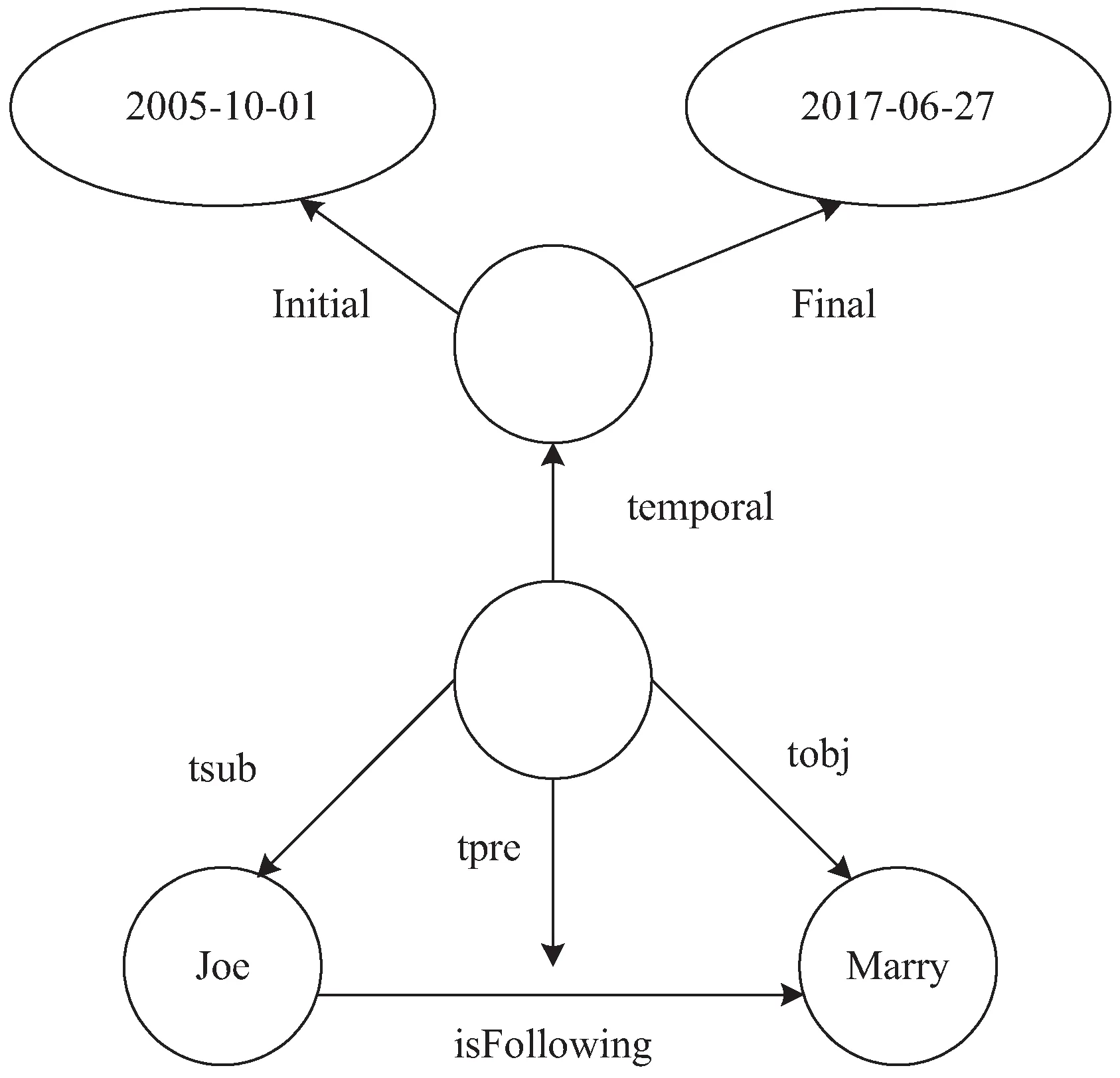
图2 Jena解析结果
若在存储过程中将这样一个时态RDF图存储在数据库中显然是不现实的,因此需要将这个时态RDF图解析成图3所示的形式,然后以(S,P,O):[T1,T2]的形式存储在时态数据库中。

图3 标准时态RDF图
前文已经介绍了Jena API的解析过程,在此基础上,需要将多余的三元组进行合并。合并算法的主要思想是,一旦检测到节点类型中有temporl属性不作输出,而是直接获取下一节点,然后将Initial的属性值赋值给有效时间区间的起止时间点,Final属性值赋值给终止时间点,然后输出有效时间标签。
3.3 推理引擎的原理与实现
由于时态RDF的语义特性,在存储和删除数据的过程中都要考虑数据的一致性。时态RDF中时间标签用时间点表示,属于时态域,也就是一个正实数集合,与三元组集合属于两个互不相交的不同框架。因此时态RDF数据推理怡情可以分为对传统RDF三元组的推理以及时态标签处理两部分进行,文献[13]也证明了这一点。
3.3.1 RDF三元组的处理
在存储RDF三元组时,需要建立一个表格用于存储三元组之间的推理关系—Rule_Table表格(InfID,Stmt1,Stmt2,Rule)。其中InfID表示根据规则推导出的三元组ID,Stmt1和Stmt2表示证明该三元组的ID,允许为空,且当三元组是直接声明而不是通过推理规则产生时,Stmt1与Stmt2都为Null,Rule则是来自W3C RDF文档中的推理规则集。
另外,由于每一个三元组也是依赖自己作为推理条件的一个推理结果,所以规则之间会存在依赖循环问题,文献[14]中提出了克服循环依赖问题的算法。
文中的推理引擎基于Jena推理机。Jena推理机是一种基于规则的推理引擎,使用前向、后向和混合执行的推理模型[15-16]。表中的内容已经包含在Jena的推理规则中。此外,针对特定领域,Jena支持自定义规则,通过String rule_Name=“Rule1:(?xpredicate ?y),(?ypredicate? z)→(?xpredicate?z)”声明,然后通过绑定实例文件与自定义推理机的方式进行实现。
3.3.2 时态标签的处理
时态RDF是根据Allen在1983年提出的一种基于时间段的时态逻辑方式进行表示的[17]。
1.插入操作。
对于插入操作来说,对时态标签的处理方式包括四种:直接插入情况、不执行插入操作的情况、替换插入的情况以及合并插入的情况。下面分别就四种情况给出详细的算法。为了方便描述,给出如下定义:
S:表示数据库中已存的时态三元组集合。
A:表示待插入的三元组集合。这里的三元组集合都经过了第一步处理。
T:时间点集合。
Tn:时间区间集合。
四种算法的输入都是经过第一步RDF三元组处理后的时态RDF三元组集合,输出为经过时态标签处理后可直接进行插入操作的时态RDF三元组集合。
●直接插入情况:针对待插入数据与数据库中已存数据三元组以及时态标签都不重复的时态RDF三元组,具体算法思想如下:
(1)判断A是否为空,若为空终止算法,若A不为空,取ai∈A,i++,进入步骤2。
(2)对时间标签的有效性进行检查,若t1>t2,返回错误提示并进入步骤1,否则进入第2步。
(3)遍历已存RDF三元组数据的三元组集合S,检查a是否在S中,若不在则可以直接返回原时间标签,返回步骤1。若在,取相同三元组Sj对应的时间标签T2(t3,t4),进入步骤4。
(4)若t2
●不执行插入操作的情况:针对待插入数据被已存数据语义包含的时态RDF三元组,这种情况下,应直接在待存集合中删除对应时态RDF数据。若t3≤t1≤t2≤t4,即待插入三元组的有效时间T1区间被包含在数据库中已存的相同三元组的有效时间区间T2,即During(T1,T2)、Starts(T1,T2)以及Finishes(T1,T2)。对于这几种情况,直接返回步骤1而不执行插入操作,否则会产生重复性问题,造成存储空间浪费。
●替换插入的情况:该情况与第一种情况恰好相反,针对待插入数据语义包含已存数据的时态RDF三元组,也就是待插入数据的有效时间范围包含对应已存数据的有效时间。即如果两个时间区间中的四个时间点存在关系t1≤t3≤t4≤t2,即待插入三元组的有效区间T1包含了数据库中已存的相同三元组的有效时间区间T2,即During(T2,T1)、Starts(T2,T1)以及Finishes(T2,T1),在这几种情况下,要将原有数据库中的对应的三元组删除,插入有效区间更大的三元组。
●合并插入的情况:若插入数据的有效时间区间与已存数据库中对应有效时间区间部分重叠,出现t1≤t3≤t2≤t4的情况,即Overlaps(T1,T2)或Meets(T1,T2)(反之亦然),这时则需要将两个RDF三元组(即待插入三元组和对应的已存三元组)的有效时间区间进行合并操作,返回步骤1。
2.删除操作。
在对时态RDF三元组进行插入操作时,需要考虑时间区间的合并以防出现数据冗余,而对三元组进行删除操作时,则需要考虑时间区间的分裂以维持时态数据表格式的统一。例如对于待删除的三元组(a,b,c):[3,5],若在原有数据库中已经存在时态RDF三元组(a,b,c):[2,6],那么该删除操作不仅不会使原时态RDF数据库中的数据减少,反正会转变为插入两个三元组(a,b,c):[2,3]和(a,b,c):[5,6]的插入操作。
对于删除算法也需要根据有效区间进行分类探讨,分为三种情况:直接删除情况、区间一次分裂删除以及区间两次分裂删除。
S:表示数据库中已存的时态三元组集合。
D:表示待删除的三元组集合。这里的三元组集合同样也经过了第一步处理。
T:时间点集合。
Tn:时间区间集合。
●直接删除情况:针对待删除数据与已存数据的对应时间标签完全匹配的时态RDF三元组数据,主要思想如下:
(1)判断待删除三元组集合D是否为空,若为空则终止运算,否则i++,进入下一步。
(2)对删除三元组语句的合法性进行分析,对于每一个待删除三元组di∈D,若其时间标签[t1,t2]中t1>t2,返回错误提示并返回第一步,否则就进入第三步。
(3)进一步对语句有效性进行判断,遍历已存三元组集合S,若对于每一个s∈S,都不能与待删除di匹配,说明删除语句无效,返回步骤1,否则就进入下一步。
(4)取与待删除三元组di匹配的已存三元组s的有效区间T2=[t3,t4],若待删除三元组的有效区间与s的有效区间存在关系t2
(5)若T1严格等于T2,即t1=t3且t2=t4,也就是说两个时间区间存在关系Equals(T1,T2),此时将已存三元组集合中的s直接删除,同时清除删除列表中的di,返回第一步。
●区间一次分裂删除:针对待删除数据有效时间区间包含在对应已存数据的有效时间区间内的时态RDF数据。首先对删除语句的有效性进行判断(以下所有情况都与第一种情况的前四步相同,都予以省略),然后通过两个有效区间的大小关系将待删除数据的有效区间在对应已存数据中的有效区间中删除,即将删除操作转化为插入操作,并将对应数据库中的数据删除。
●区间两次分裂删除:针对待删除数据的有效区间将对应已存数据有效区间分成三段的时态RDF数据。将原有数据库中的三元组时间标签分成两个不相连的部分存储,当四个时间点之间存在关系t3≤t1≤t2≤t4时,即存在关系During(T1,T2),那么此时在删除s的同时,还要执行对以下两个三元组的插入操作,即时态三元组(di,T3)和时态RDF三元组(di,T4),其中T3=(t3,t1),T4=(t2,t4)。
3.4 时态RDF数据存储到TimeDB
按照前文提出的关系表结构,将处理后的时态RDF三元组数据存储在TimeDB中。
TimeDB在Java中提供了三类调用接口:TimeDB的调用接口(TDBCI)、结果集(ResultSet)类接口和结果行(ResultRow接口)。
部分实现代码如下:
/*设置数据库的链接参数*/
TDBCI t=new TDBCI();
t.setPrefs(“C:TimeDB2.2”,1,“Oracle.jdbc.driver.OracleDriver”,
“jdbc:oracle:thin:1512:ORCL”);
……
/*对于每个时态RDF三元组,分别将解析出的主语、谓语、宾语以及有效时间区间对应插入TimeDB,以时态RDF实例信息为例*/
String atsql=“VALIDTIME PERIOD[+“Begintime+”-“+Endtime+”]”+“INSERT INTO TStatement_Table values(?,?,?,?,?)”
PreparedStatement prest=conn.prepareStatement(sql,ResultSet.TYPE_SCROLL_SENSITIVE,
ResultSet.CONCUR_READ_ONLY);
For(int i=0;x { prest.setString(1,rdfnode.getSubject()); prest.setString(2,rdfnode.getPredicate()); prest.setString(3,rdfnode.getObject()); prest.setString(4,rdfnode.Begintime()); prest.setString(4,rdfnodeEndtime());//将时态RDF三元组的主语、谓语、宾语以及有效时间分别插入。 } …… 1.插入操作。 系统将会通过TimeDB的调用接口(TDBCI),将三元组中的三个字符串分别插入到数据表中的主语、谓语和宾语对应列,然后将有效时间区间插入到起始时间列和终止时间列。 将时态RDF三元组(Manager,rdfs:SubclassOf,Employee):[0,Now]实例信息和(Ailsa,rdf:type,Manager):[2017,NOW]本体信息分别存入时态三元组表和时态本体信息表, TimeDB通过执行下列ATSQL2语句: VALIDTIME PRIOD [0-Now] INSERT INTO TOntolygy_Table VALUES(OT002,‘Manager’,‘rdfs:SubclassOf’,‘Emolyee’); VALIDTIME PRIOD [2017-Now] INSERT INTO TStatement_Table VALUES(T001,‘Ailsa’,‘rdf:type’,‘Manager’); 通过查看时态本体信息表得到结果如图4所示。 图4 F-Storage系统示意图(1) 2.删除操作。 下面删除时态RDF三元组(Ailsa,rdf:type,Manager):[2017,NOW],执行操作后,查看时态RDF表和规则信息表,结果如图5和图6所示。 图5 F-Storage系统示意图(2) 图6 F-Storage系统示意图(3) 由于T002三元组在规则中依赖于删除的时态RDF三元组T001,因此在删除T001时,推理算法会将T002也删除,并将它们在规则信息表中的数据一并删除。 针对时态RDF数据存储研究相对缺失的现状,提出了一种时态RDF数据存储系统的设计方案。针对TRDF-Storage存储系统中最重要的推理引擎进行了详细阐述,针对不同的时间区间关系,将插入操作和删除操作分类讨论,就每种区间关系的操作实现提供了算法。最后通过一个公司的模拟时态RDF数据,对存储系统的使用进行验证。实验结果表明,系统可以完成时态RDF本体信息和实例信息的分别存储,且推理机制可以得到正确的推理结果并对事态RDF数据进行存储或删除,维护了时态RDF数据库的一致性。但该研究内容也有一些不足之处,例如存储所涉及的时态RDF模型没有针对匿名时间点的处理以及对于海量时态RDF数据的处理还未能进行有效验证,这些都有待进一步的研究与改进。4 系统演示


5 结束语
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
中学数学研究(广东)(2023年9期)2023-06-03 03:32:40
中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:48
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
家庭影院技术(2021年2期)2021-03-29 07:18:22
疯狂英语·新策略(2019年12期)2020-01-04 02:48:06
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
现代防御技术(2014年6期)2014-02-28 18:26:29
海外英语(2013年4期)2013-08-27 09:38:00
