
基于Spark的分布式并行推理算法①
2017-06-07 08:24叶怡新汪璟玢
计算机系统应用 2017年5期
叶怡新,汪璟玢
(福州大学 数学与计算机科学学院,福州 350108)
基于Spark的分布式并行推理算法①
叶怡新,汪璟玢
(福州大学 数学与计算机科学学院,福州 350108)
现有的RDF数据分布式并行推理算法大多需要启动多个MapReduce任务,有些算法对于含有多个实例三元组前件的OWL规则的推理效率低下,使其整体的推理效率不高.针对这些问题,文中提出结合TREAT的基于Spark的分布式并行推理算法(DPRS).该算法首先结合RDF数据本体,构建模式三元组对应的alpha寄存器和规则标记模型;在OWL推理阶段,结合MapReduce实现TREAT算法中的alpha阶段;然后对推理结果进行去重处理,完成一次OWL全部规则推理.实验表明DPRS算法能够高效正确地实现大规模数据的并行推理.
RDF;OWL;分布式推理;TREAT;Spark
语义万维网中的RDF和OWL标准已在各个领域有着广泛的应用,如一般知识(DBpedia[1])、医疗生命科学(LODD[2])、生物信息学(UniProt[3])、地理信息系统(Linkedgeodata)和语义搜索引擎(Watson)等.随着语义万维网的应用,产生了海量的语义信息.由于数据的复杂性和大规模性,如何通过语义信息并行推理高效地发现其中隐藏的信息是一个亟待解决的问题.由于语义网数据的急速增长,集中式环境的内存限制,已不适用于大规模数据的推理.
研究RDFS/OWL分布式并行推理是目前较新的一个领域.J.Urbani[4-6]等人在RDFS/OWL规则集上采用WebPIE进行推理,能够满足大数据的并行推理;但该算法针对每一条规则启用一个或者多个MapReduce任务进行推理,由于Job的启动相对耗时,因此随着RDFS/OWL推理规则的增加,整体推理的效率受到了限制.顾荣[7]等人提出了基于MapReduce的高效可扩展的语义推理引擎(YARM),使推理在一次MapReduce任务内即可完成RDFS规则的推理;但该算法并不适用于复杂的OWL规则的推理.此外,当某一规则产生的新三元组重复时,YARM会存在过多的冗余计算且产生无用数据.汪璟玢[8]等人提出结合Rete的RDF数据分布式并行推理算法,该算法结合RDF数据本体,构建模式三元组列表和规则标记模型;在RDFS/OWL推理阶段,结合MapReduce实现Rete算法中的alpha阶段和beta阶段,从而实现Rete算法的分布式推理;但该算法在连接beta网络推理时需要消耗较多的内存且进行多次迭代时效率低下,因而此算法受到集群内存和平台的限制.顾荣[9]等人提出了一种基于Spark的高效并行推理引擎(Cichlid),结合RDD的编程模型,优化了并行推理算法;但该算法未考虑规则能否被激活,均需要进行推理,因而造成了推理性能的浪费和传输的冗余.
为了解决上述问题,本文针对OWL Horst规则,提出 了 DPRS算 法 (Distributed parallel reasoning algorithm based on Spark).该算法结合TREAT[10]算法和RDF数据本体构建模式三元组的alpha寄存器RDD,预先对规则能否被激活做出判断并标记,仅对可激活的规则进行推理的处理,实现在一个MapReduce任务中完成OWL全部规则的一次推理.最后,实时地删除重复的三元组数据和更新冲突集数据到相应的寄存器中,以进一步提高后续迭代推理的效率.实验表明,该算法在数据量动态增加的情况下能够高效地构建alpha网络,并执行正确的推理.
1 基本定义
定义1.模式三元组(SchemaTriple),指三元组的主语谓语和宾语都在本体文件(OntologyFile)中有定义.即:
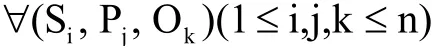
其中,n表示模式三元组的总数.若v∈{Si,Pj,Ok}, v∈OntologyFile,则:
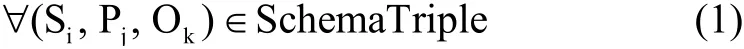
定义2.实例三元组(InstanceTriple),指主语谓语和宾语至少有一个在本体文件(OntologyFile)中未定义,是具体的实例.即:
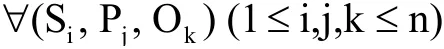
其中,n表示实例三元组的总数.若v∈{Si,Pj,Ok},∃v∉OntologyFile,则:
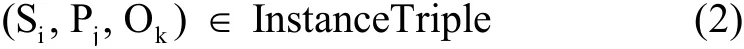
定义3.三元组类型标记(Flag_TripleType),用于标识模式三元组与实例三元组,结合定义1和定义2,三元组类型标记Flag_TripleType定义如下:
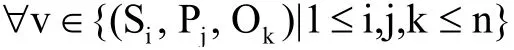
其中,n表示三元组的总数.则:

定义4.模式三元组列表(SchemaRDD).用于获取相同谓语或者宾语的模式三元组集合.结合定义1,模式三元组列表SchemaRDD定义如下:

其中,n表示模式三元组的总数.则,

其中,Om_RDD表示满足谓语Pj∈{rdf:type}且具有相同宾语的三元组集合,以该宾语命名;Pt_RDD表示满足谓语Pj∉{rdf:type}的所有具有相同谓语的三元组集合,以该谓语命名.具体定义如下:
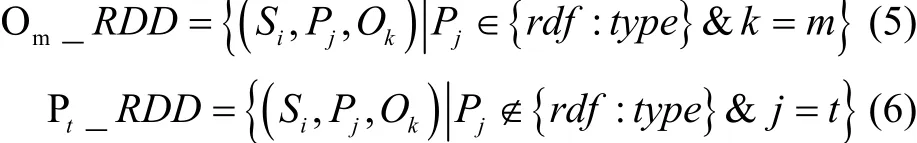
定义 5.连接变量(LinkVar).连接变量为在RDFS/OWL规则中用于连接两个前件的模式三元组项,根据规则描述,连接变量可以不止一个.本文将每一条规则的连接变量信息以
DPRS算法根据连接变量的类型,对OWL Horst规则进行分类.本文引用OWL Horst规则时采用OWL-规则编号的形式,例如OWL-4表示图1中的第4条规则.同时,给每条规则分配一个规则名称标记,规则名称标记即为该规则所对应的名称(例如,规则OWL-4的规则名称标记为OWL-4).具体的规则分类如下:
1)类型 1:只包含一个前件的规则或SchemaTriple与InstanceTriple组合的规则,且只有一个InstanceTriple,可以在Map推理过程中直接输出推理结果(图1中规则OWL-3、OWL-5a、OWL-5b、OWL-6、OWL-8a、OWL-8b、OWL-9、OWL-12a、OWL-12b、OWL-12c、OWL-13a、OWL-13b、OWL-13c、OWL-14a、OWL-14b).
2)类型2:SchemaTriple与InstanceTriple组合的规则,且有多个InstanceTriple的,需要结合 Map和ReduceByKey两个阶段推理(图1中规则OWL-1、OWL-2、OWL-4、OWL-7、OWL-15、OWL-16).
定义 6.设Cmn为第m条规则的第n个模式三元组前件,定义规则前件模式标记Indexmn, 用于标识是否有符合该前件的模式三元组存在,即以该模式三元组前件Cmn所命名的SchemaRDD是否为空.结合定义4,规则前件模式标记Indexmn定义如下:

定义7.规则标记Flag_Rule_m,用于标记该规则是否为不可能激活的规则.结合定义6进行定义规则标记Flag_Rulem如下:
Flag_Rulem={0,1,2}其中,规则不能激活时,Flag_Rulem=0;规则激活且为类型1时,Flag_Rulem=1;规则激活且为类型2时, Flag_Rulem=2.
由于图1中OWL规则5a、5b不影响推理的并行化,因而,本文所述推理不考虑这两条规则.

图1 OWLHorst规则
2 DPRS算法
在Rete算法中,同一规则连接结点上的寄存器保留了大量的冗余结果.实际上,寄存器中大部分信息已经体现在冲突集的规则实例中.因此,如果在部分匹配过程中直接使用冲突集来限制模式之间的变量约束,不仅可以减少寄存器的数量,而且能够加快匹配处理效率.这一思想称为冲突集支撑策略.基于冲突集支撑策略,TREAT[10]算法放弃了Rete算法中利用β寄存器保存模式之间变量约束中间结果的思想.
DPRS算法根据Spark RDD的特点,结合TREAT算法的原理,首先根据RDF本体数据构建模式三元组对应的alpha寄存器Om_RDD或Pt_RDD并广播,然后对每条规则的模式前件进行连接并生成对应的连接模式三元组集合Rulem_linkvar_RDD,从而加快推理过程中的匹配速度,能够实现多条规则的分布式并行推理.DPRS算法主要包括以下几个步骤:
Step1.加载模式三元组集合Pt_RDD、Om_RDD和Rulem_linkvar_RDD并广播.
Step2.构建规则标记模型Flag_Rulem并广播.
Step3.并行执行OWL Horst规则推理.
Step4.删除重复三元组.
Step5.如果产生新的模式三元组数据,则跳至步骤Step2,如果产生新的实例三元组数据,则跳至步骤Step3,否则跳至步骤Step6.
Step6.算法结束.
DPRS算法的总体框架图如图2所示.
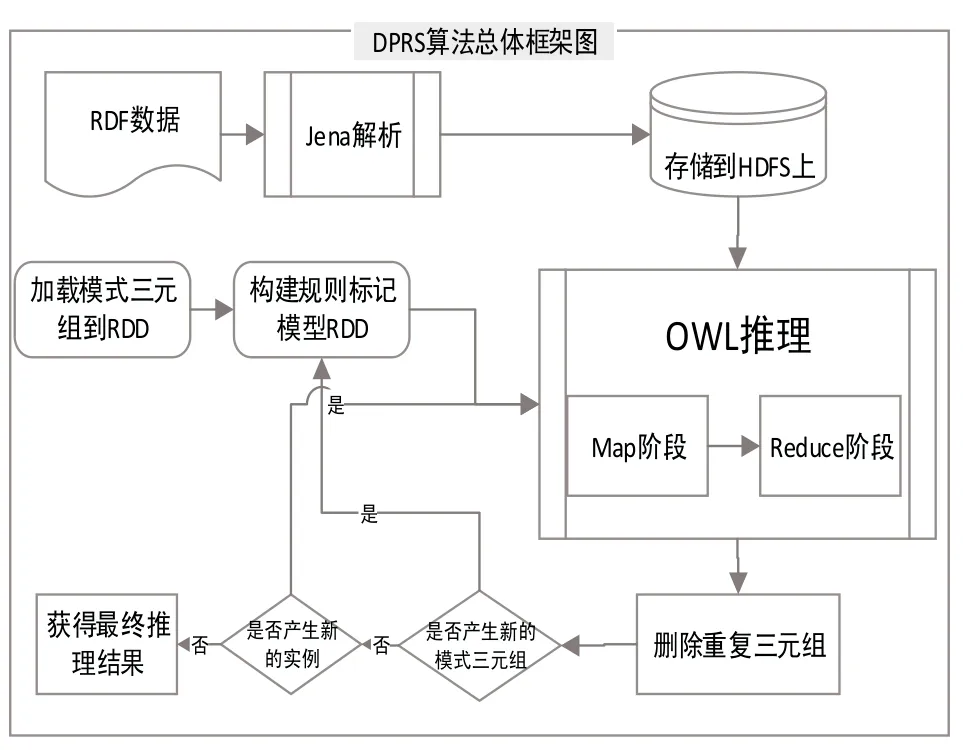
图2 DPRS算法总体框架图
2.1 加载模式三元组与构建规则标记模型
由于模式三元组的数量远远少于实例三元组, DPRS算法将SchemaTriple加载到SchemaRDD中并广播.并构建每条规则中的模式三元组或模式三元组连接后的数据(Rulem_linkvar_RDD或 Om_RDD或Pt_RDD)为 alpha寄存器并广播,保存对应的SchemaTriple.
为了尽早判断出不可能被激活的规则,DPRS算法根据OWL规则构建每一条规则内SchemaTriple间的关系Om_RDD或Pt_RDD,并判断SchemaRDD中是否存在规则前件中的SchemaTriple,生成对应规则的标记Flag_Rulem,构建所有规则的标记模型,将规则标记模型加载到Flag_Rulem并广播.
通过SchemaRDD和构建规则标记模型能够过滤大量InstanceTriple,减少Map阶段键值对的输出,从而减少了无效的网络传输,提高整体推理效率.
2.2 Map阶段
Map阶段主要完成数据选择过滤与类型1推理,将过滤的结果以键值对的形式输出,本文提出的数据分配与过滤算法具体步骤如下:

Step1.获取广播变量中的Om_RDD、Pt_RDD和
Rulem_linkvar_RDD以及规则标记Flag_Rulem.
Step2.对于输入的∀(Si,Pj,Ok)∈InstanceTriple判断所有Flag_Rulem的值.如果值为0,则跳至Step3,如果值为1,则跳至Step4,否则跳至Step5.
Step3.对(Si,Pj,Ok)不做任何处理.
Step4.结合Om_RDD或Pt_RDD执行类型1的规则推理,根据规则的结论直接输出对应的三元组
Step5获取对应规则中的模式三元组alpha寄存器Om_RDD、Pt_RDD或Rulem_linkvar_RDD,判断当前的实例三元组是否满足前件连接变量的条件;满足,则构建对应的键值对
以图1中规则8a(inverseOf)为例,伪码描述如下:

类似于规则8,推理可以在Map阶段就得到规则产生的三元组结果,那么reduce阶段就可以对规则8产生的三元组去重并输出.
以图1中规则9(type+sameAs)为例,伪码描述如下:

以图1中规则15(someValuesFrom)为例,伪码描述如下:

如上所描述的规则9和15,以规则9为例,在Map阶段需要对输入的三元组进行处理,以“Rule9+连接变量”为key,如果谓语为type,那么value中标记为type且资源为连接变量;如果谓语为sameAs,那么value中标记为sameAs且资源为宾语.
2.3Reduce阶段
Reduce阶段主要完成连接推理.利用RDD的reduceByKey,结合OWL规则,根据SchemaRDD和alpha寄存器以及Map阶段的InstanceTriple输出结果完成连接推理,得到推理结果.本文提出的连接推理算法具体步骤如下:

Step1.获取广播变量中的Om_RDD、Pt_RDD和Rulem_linkvar_RDD以及规则标记Flag_Rulem.
Step2.获取相同键对应的迭代器;如果key为Rulem,则表示为类型1,直接将value的三元组输出;如果key为Rulem_linkvar,则表示为类型2,则根据该key对应的OWL规则和连接变量,结合alpha寄存器Rulem_linkvar_RDD与value迭代器完成连接推理,得到推理结果并输出连接后的三元组在执行连接推理过程中,因为符合条件的SchemaTriple已经在构建alpha寄存器时已连接完毕,所以只需要执行SchemaTriple与InstanceTriple或InstanceTriple与InstanceTriple间的连接即可.
为了更加明确Reduce阶段的连接推理,以图1中规则9(type+sameAs规则)为例,伪码描述如下:

以图1中规则15(someValuesFrom规则)为例,伪码描述如下:

由上述的规则9和规则15的伪码,以规则9为例,在Reduce阶段,根据输入的key和values,我们通过values中的flag值来进行区分并构建输出的三元组.
2.4 删除重复三元组和冲突集更新策略
在执行算法推理的过程中会产生大量重复的三元组数据到冲突集中,如不删除冲突集中的重复三元组,则更新alpha寄存器时将会产生重复三元组数据,浪费系统资源,降低推理效率.如果每次推理后都能够及时删除冲突集中的重复三元组,那将会减少很大的网络传输开销.本文借助RDD的distinct和subtract完成删除重复三元组算法.
通过上述的删除重复三元组后,冲突集中的模式三元组分别更新到对应的alpha寄存器中,实例三元组合则并到实例文件中.
2.5 算法的复杂度与完备性
复杂性分析是算法分析的核心,DPRS算法的复杂性与集中式算法复杂性的分析不太相同,将DPRS算法的最坏情况下的时间复杂性分为Map阶段的时间复杂性和Reduce阶段的时间复杂性.假设数据集的规模大小为N个三元组,其中模式三元组为n个,在MapReduce中Map阶段的并行数为k,Reduce阶段传入的实例三元组个数为m,Reduce阶段的并行数为t.
由于DPRS算法在Map阶段对每个输入的三元组,结合SchemaList、Flag_Rulem扫描一次,即可判断该三元组是该舍弃或是能参与某些规则推理,如能参与后续规则推理,则以该规则名称为key结合此三元组输出.因此,Map阶段的时间复杂性为:O(n*N/k).
由于图1 OWL规则中,规则1、2、3、4、15、16都含有两个实例三元组前件,将上述规则称作多实例变量规则,多实例变量规则的Reduce阶段则需要遍历两次输入的实例三元组与模式三元组连接,才能得到推理结果.因此在Reduce阶段的时间复杂性分为单变量和多变量进行分析.
Reduce阶段多变量的时间复杂性为:O(n*m/t).由于n的数目非常少,可以认为其量级为常数.
DPRS算法首先将数据集中的模式三元组载入内存并广播,根据定义7和OWL规则的描述构建各个规则的Flag_Rulem,从而过滤掉不可能激活的规则.在能被激活的规则并行推理过程中的Map阶段,对于输入的一个三元组,DPRS判断其是否满足某个规则前件,只要满足,就将此规则名称作为键(key),值(value)为该三元组输出;若一个三元组数据满足多个规则前件,我们也将据此方法产生多个不同键(key)的输出,以保障Reduce阶段推理连接的正确性和数据完整性.如果Reduce阶段产生的三元组去重后,有产生新的模式三元组,那么 DPRS算法将重新计算各个规则的Flag_Rulem,再执行规则的并行推理迭代;如果Reduce阶段产生的三元组去重后产生的是实例三元组,那么DPRS算法直接执行规则的并行推理迭代,直到没有新的三元组数据产生为止.因而DPRS算法所得到的推理结果是完备的.
3 实验与结果分析
实验所使用的软件环境为操作系统Linux Ubuntu,采用scala作为编程语言,开发环境为IntelliJIDEA.在实验环境中,用表1所示配置作为本系统Spark集群的配置,共计8台,其Hadoop集群中1台作为HDFS的名称节点,1台作为JobTracker节点,6台为HDFS的数据节点和TaskTracker节点,Spark集群中1台作为Master兼Worker节点,7台作为Worker节点.集群工作站的基本配置如表1所列.

表1 Hadoop集群工作站的基本配置
本文将DPRS算法与DRRM[4]和Cichlid-OWL[9]在相同的实验环境下针对不同的数据集进行对比实验.本实验采用LUBM[11](Lehigh University Benchmark)数据集和DBpedia[1]数据集进行测试.数据集的基本参数说明如表2所列.
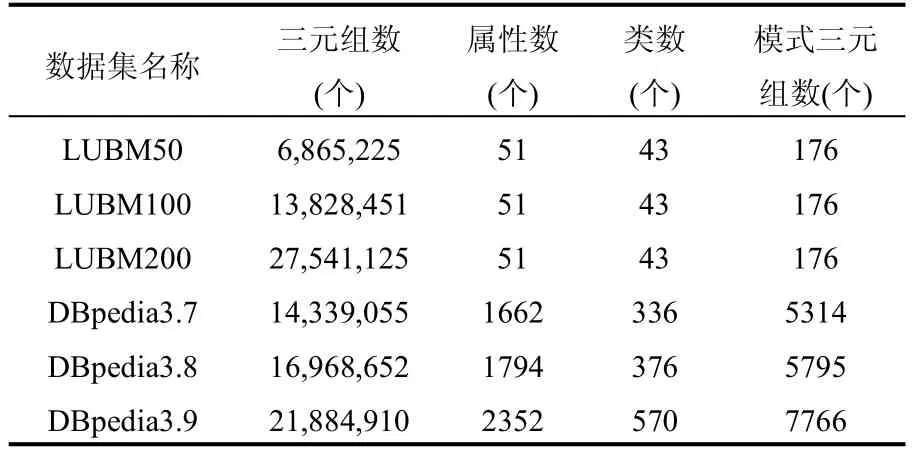
表2 数据集的基本参数说明
我们将实验数据集中的模式三元组数进行统计如表2所示,与整个数据集的大小相比,模式三元组的数量非常少,在所测试的数据集范围内,模式三元组数目最高仅仅达到了整个数据集的0.04%.
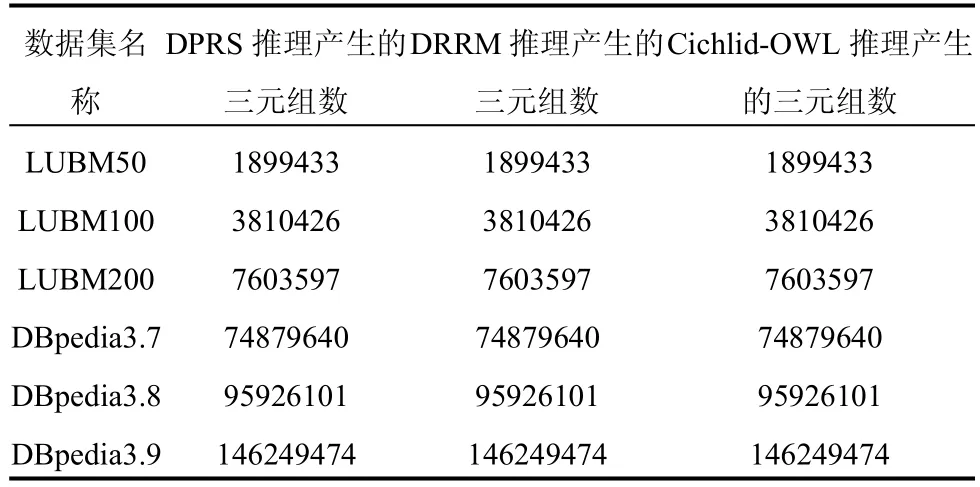
表3 不同数据集三种算法在OWL推理产生的三元组数对比
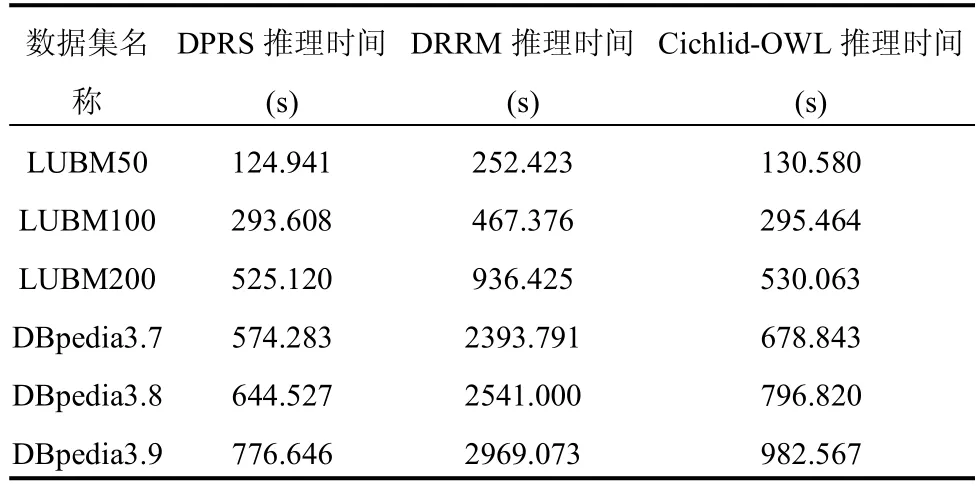
表4 不同数据集三种算法在OWL推理时间对比
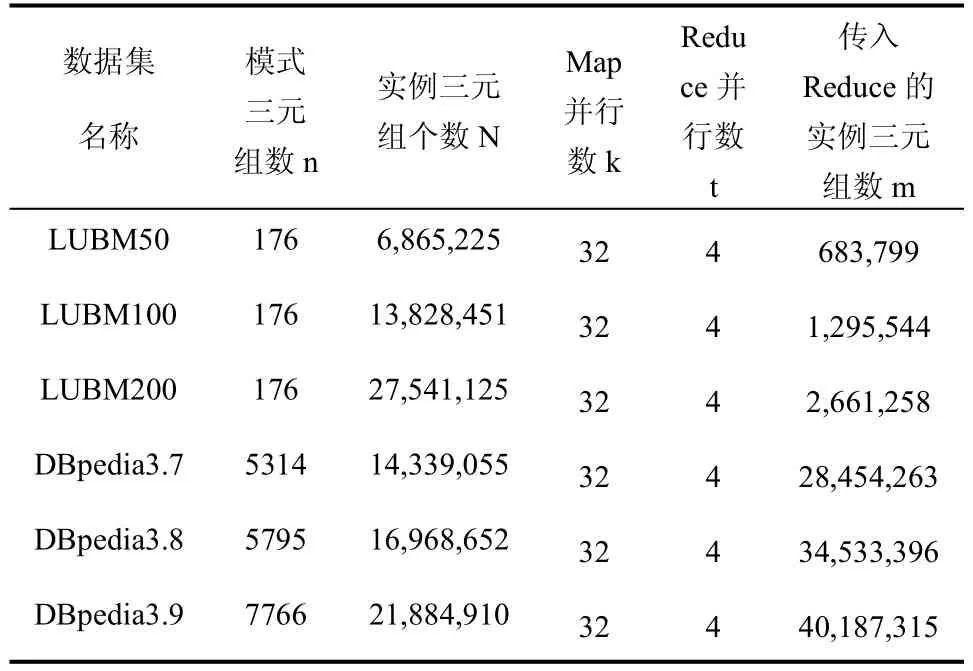
表5 DPRS算法在不同数据集上执行推理的数据
从表3和表4可知,在OWL规则推理结果一致的情况下,DPRS比Cichlid-OWL具有优势.其中,由于LUBM数据集本体比较简单,OWL Horst中的许多规则无法被激活,所以DPRS相比Cichlid-OWL的优势比较微弱;对于比较复杂的DBpedia本体而言,OWL的大部分规则都可被激活,由于本文使用了alpha寄存器广播、连接变量、规则标记和冲突集更新策略,使得DPRS算法的推理时间相对Cichlid-OWL算法最大缩短了21%的时间.
另外,DPRS与DRRM相比均有较大的优势.首先, DPRS使用Spark平台比DRRM使用的Hadoop具有迭代性能优势;再者,DPRS采用冲突集更新策略,避免了beta网络的开销,大大减少了传输冗余造成的浪费.使得DPRS算法的推理时间相对DRRM算法最大缩短了73.8%的时间.
根据2.5节的复杂度分析,其中k和t为常数,所以推理时间的复杂度与N和m成线性关系.结合表4和表5,考察数据集LUBM50和LUBM200,实例三元组个数N的比例为1:4.01,传入Reduce的实例三元组数m的比例为1:3.89,推理时间的比例为1:4.20;考察数据集DBpedia3.7和DBpedia3.9,实例三元组个数N的比例为1:1.53,传入Reduce的实例三元组数m的比例为1:1.41,推理时间的比例为1:1.35.可以发现,我们的推理时间基本是与N和m成线性关系.从实验结果上符合了理论的分析,证明了算法的正确性.
从图3和图4可知,在执行OWL规则推理时,虽然两种算法都需要多次迭代才能使得推理最终停止,但是DPRS在推理前构建并广播了模式三元组的alpha寄存器,并且在每次迭代中采用高效的过滤机制,过滤掉大量的实例三元组数据,减少了并行计算量和网络传输的开销,使得DPRS算法在最终的推理时间较Cichlid-OWL略占优势,尤其是在DBpedia数据集下,从表2中可以看出,Dbpedia的模式三元组占比相对LUBM高,且数据集较为复杂,其优势更加明显.
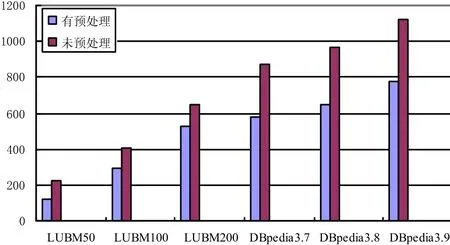
图3 采用未预处理与预处理算法在OWL推理的时间对比

图4 采用过滤算法与未过滤算法产生的中间结果数目对比
由于在执行推理过程中会产生重复的三元组数据,重复三元组数据会造成系统资源无谓的浪费并增加网络的开销.文中3.4节提出的删除重复三元组算法,能够减少重复的三元组数据.为了评估算法的有效性,将删除重复三元组前后的数据量进行对比如图5所示.删除重复三元组后的三元组数量少于推理三元组数量,在所测试的数据范围内.
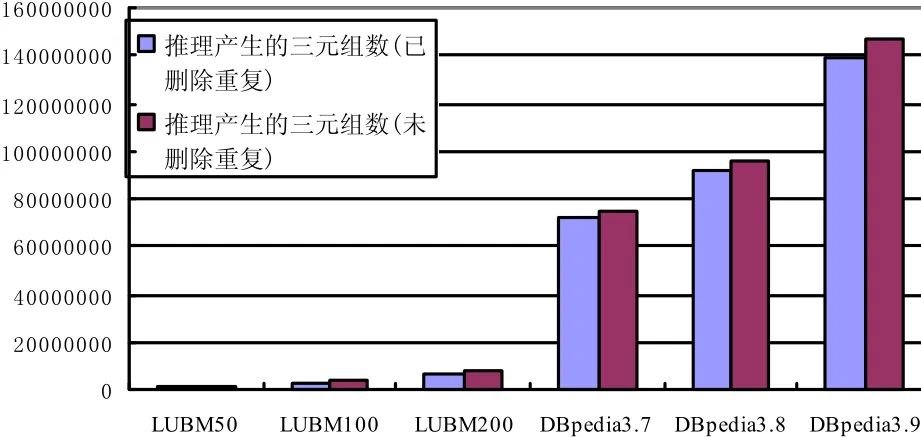
图5 删除重复三元组前后三元组数量对比
4 结语
本文提出的 DPRS算法能够通过执行一次MapReduce任务就完成OWL所有规则的一次推理,弥补了现有方法大多需要启动多个MapReduce任务以及在大规模数据下无法对OWL规则中含有实例三元组的规则进行推理的问题.DPRS算法能够在MapReduce计算框架下高效地实现大规模数据的并行推理,但无法对流式数据进行推理.下一步将会在此方面进行改进,且研究更深一步的OWLDL推理.
1 Auer S,Bizer C,Kobilarov G,et al.Dbpedia:A nucleus for a web of open data.The Semantic Web.Springer Berlin Heidelberg.2007.722–735.
2 Jentzsch A,Zhao J,Hassanzadeh O,et al.Linking Open Drug Data.I–SEMANTICS.2009.
3 Apweiler R,Bairoch A,Wu CH,et al.UniProt:The universal protein knowledgebase.Nucleic AcidsResearch,2004, 32(s1):D115–D119.
4 Urbani J,Kotoulas S,Maassen J,et al.WebPIE:A web-scale parallel inference engine using MapReduce.Web Semantics: Science,Services and Agents on the World Wide Web,2012, (10):59–75.
5 Urbani J,Kotoulas S,Maassen J,et al.OWL reasoning with WebPIE:Calculating the closure of 100 billion triples. Extended Semantic Web Conference.SpringerBerlin Heidelberg.2010.213–227.
6 UrbaniJ.On web-scale reasoning[PhD.dissertation]. Amsterdam,Netherlands:Computer Science Department, Vrije Universiteit,2013.
7顾荣,王芳芳,袁春风,等.YARM:基于MapReduce的高效可扩展的语义推理引擎.计算机学报,2015,38(1):74–85.
8汪璟玢,郑翠春.结合Rete的RDF数据分布式并行推理算法.模式识别与人工智能,2016,(5):5.
9 Gu R,Wang S,Wang F,et al.Cichlid:Efficient large scale RDFS/OWL reasoning with spark.Parallel and Distributed Processing Symposium(IPDPS),2015 IEEE International. IEEE.2015.700–709.
10 Miranker DP.TREAT:A new and efficient match algorithm forAI production system.Morgan Kaufmann,2014.
11 Guo Y,Pan Z,Heflin J.LUBM:A benchmark for OWL knowledge base systems.Web Semantics:Science,Services andAgents on the World Wide Web,2005,3(2):158–182.
Distributed Parallel ReasoningAlgorithm Based on Spark
YE Yi-Xin,WANG Jing-Bin
(College of Mathematics and Computer Science,Fuzhou University,Fuzhou 350108,China)
Multiple MapReduce tasks are needed for most of current distributed parallel reasoning algorithm for RDF data;moreover,the reasoning of instances of triple antecedents under OWL rules can’t be performed expeditiously by some of these algorithms during the processing of massive RDF data,and so the overall efficiency can’t be fulfilled in reasoning process.In order to solve the problems mentioned above,a method named distributed parallel reasoning algorithm based on Spark with TREAT for RDF data is proposed to perform reasoning on distributed systems.First step, alpha registers of schema triples and models for rule markup with the ontology of RDF data are built;then alpha stage of TREAT algorithm is implemented with MapReduce at the phase of OWL reasoning;at last,reasoning results are dereplicated and a whole reasoning procedure within all the OWL rules is executed.Experimental results show that through this algorithm,the results of parallel reasoning for large-scale data can be achieved efficiently and correctly.
RDF;OWL;distributed reasoning;TREAT;Spark
国家自然科学基金(61300104)
2016-09-21;收到修改稿时间:2016-10-31
10.15888/j.cnki.csa.005790
猜你喜欢
计算机与生活(2022年3期)2022-03-13
计算机应用与软件(2021年4期)2021-04-15
计算机应用(2020年5期)2020-06-07
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机研究与发展(2019年4期)2019-04-18
计算机技术与发展(2018年12期)2018-12-20
电子技术与软件工程(2018年1期)2018-03-22
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
