
自媒体言语司法鉴定研究初探
2018-11-13 09:52王英利
中原工学院学报 2018年5期
关 鑫, 王英利
(1.肇庆学院 外国语学院, 广东 肇庆 526061; 2.广东省公安厅 刑事技术中心, 广东 广州 510050)
司法言语鉴定是对言语生产者的人身认定,司法言语鉴定要求鉴定人员依法对涉案言语材料与已知涉案嫌疑人的言语材料进行比对鉴别,为认定犯罪嫌疑人或当事人、证实犯罪事实或其他事实提供证据。司法言语鉴定可以进一步细分为司法口头言语鉴定和司法书面言语鉴定,其鉴定的言语材料分别为口头言语和书面言语[1]。随着电子信息技术的发展和互联网的普及,当今世界已经进入自媒体时代。在自媒体时代,口头言语材料和书面言语材料的载体及呈现形式更加多样化,而现有司法言语鉴定技术的发展和运用却未能跟上信息化社会和司法实践的需求[2]。在此背景下,本文旨在探讨以自媒体言语材料为鉴定对象的司法言语鉴定方法,以满足信息化社会司法实践的需求。
一、 言语司法鉴定研究现状
司法口头言语鉴定技术是应“案件侦查、法庭诉讼等司法实践对语音证据的迫切需要而产生,并在大量科学研究基础上逐渐发展起来的”[3]。目前,各国在司法实践中主要采用听觉-声学分析法鉴定口头言语证据,鉴定人员利用相关语音学和语言学知识,从涉案检材言语和已知嫌疑人或当事人的样本言语中挑选出足够多的可比对音段,综合比对分析音段中的听觉语音学特征和语音声学特征,给出定性的鉴定结论[4-7]。然而,语音变异是一种客观存在的现象,加之司法实践中涉案的检材语音生成环境复杂、难于掌控,造成司法实践中检材数量不够、检材和样本信道不匹配,无法从涉案检材言语和已知嫌疑人或当事人的样本言语中挑选出足够多的可比对音段,最终导致鉴定工作由于不具备鉴定条件而无法进行[8]。据美国FBI统计数据,在FBI历时15年内追踪的2 000个案例中,由于不具备鉴定条件而无法鉴定的案件占65.2%[8]。目前还没有科学有效的方法能够验证作为鉴定参数的听觉语音学特征和语音声学特征在司法实践条件下的效度与信度[6,9-10]。实验研究与实践应用脱节这一问题导致很多情况下鉴定结果的信度难以保障,语音证据的法庭采信度低[4-5,7-9,11]。为了解决口头言语鉴定实验研究与实践脱节问题,该领域的专家学者建议并尝试采用综合法[12]、协同印证法[4]、交叉印证法[13],并在实验研究中采用接近日常言语的录音材料作为实验语料[9,14]。目前,国际上从事司法书面言语鉴定研究和实践活动的研究者、从业者所采用的鉴定参数主要是能体现书面言语材料作者个人言语风格的字、词、句、语法、修辞、标点、篇章等言语特征[1,15-16]。司法书面言语鉴定实践对鉴定条件要求比较严格,首先,检材言语至少要500字以上;其次,样本言语的语体、题材要尽量与检材言语相同,形成时间尽量接近,而且样本数量应尽量多[1]。在网络时代,电子文本逐渐代替传统手写文本,成为书面言语鉴定研究的主要研究对象。随着书面言语鉴定理论研究不断深入,统计语言学、语料库语言学、语篇信息分析理论等知识也被不断应用到鉴定实践中辅助鉴定工作[15,17-18],这些方法对言语资料的数量要求更高。
二、 自媒体时代对言语鉴定技术的需求分析
2003年美国新闻学会媒体中心出版的自媒体(We Media)研究报告把自媒体定义为一种了解普通民众如何借助连接全球知识体系的数字科技,提供与分享关于他们自身的事实和新闻的途径,并指出由普通民众生产的自媒体信息注重对话、协作和平等,信息传播参与者以个人身份参与信息传播[19]。国内学者申金霞认为,自媒体强调传播者的主动性和传播内容的个性化与自主性,又可成为“个人媒体”或“私媒体”[20]。宋全成指出自媒体的信息制作和传播行为具有个体化、自主化、信息内容多样化、传播途径的圈群化和传播的高速性等特点[21]。以上介绍的自媒体主体和传播内容的特点决定了自媒体言语具有如下特点。首先,自媒体传播主体的自主性、个体性和传播内容的互动性说明自媒体言语能够体现某一自媒体传播主体有别于其他自媒体传播主体的个性特征;其次,自媒体传播主体的民众化、信息内容多样化、传播途径的圈群化和传播的高速性决定了自媒体言语语料数量巨大,易于获取。
在我国,主要的自媒体平台除了微信还有博客、微博和各种软件客户端等。截至2018年6月,我国网民规模达8.02亿,互联网普及率为57.7%;我国手机网民规模达7.88亿,网民通过手机接入互联网的比例高达98.3%[22]。越来越多的人习惯性地使用手机查看微信、微博,并转发或评论[23]。以微信为例,微信用户在2018年第一季度首次突破10亿,达10.4亿[24]。以上数据显示,自媒体传播主体以智能手机为主要上网工具,这不但决定了自媒体言语语料数量巨大、易于获取,同时也表明自媒体言语既包括文本也包括语音、言语多样形式。
以上自媒体言语特点分析说明,自媒体时代给司法言语鉴定实践带来了无限机遇。首先,自媒体言语体现传播主体的个性特征,可以作为司法言语鉴定的鉴定对象;其次,数量巨大、易于获取的自媒体言语语料会改善在司法实践中由于检材数量不够最终导致鉴定工作无法进行的现状。同时,在自媒体时代司法言语鉴定技术研究也面临着巨大挑战。首先,言语检材的生成环境更加复杂,确定检材言语与样本言语的可比性更加困难;其次,多数言语检材与言语样本的长度有限,不能达到现有言语鉴定技术的鉴定条件要求;再者,自媒体言语中口头言语与书面言语交替出现,很难截然分开。为了应对自媒体时代司法实践需求,司法言语鉴定研究必须依据自媒体言语的特点,探索挖掘更加稳定、受司法实践现实环境影响小的、具有言语人识别能力的言语特征。
三、 基于语篇信息分析的自媒体言语鉴定研究
为了挖掘更加稳定、受司法实践现实环境影响小的司法言语鉴定特征,本文基于语篇信息理论,认为可以采用语篇信息分析方法分析自媒体言语,挖掘可以用于司法口头言语和书面言语鉴定的具有言语人识别能力的言语特征。
(一) 语篇信息分析法
语篇信息分析法源于法律语篇树状信息结构模式[25]。根据语篇树状信息结构模式,语篇信息结构是由一个表达语篇中心思想的核心命题及该核心命题的下层命题构成的树状层级结构。语篇信息由命题承载,是能够用于交际的最小完整意义单位。一个命题就是一个信息单位。宏观上,语篇信息结构是由语篇的核心命题及发展该核心命题的语篇信息单位构成的树状层级结构。信息单位之间的上下层关系可用15类信息点表示,标注语篇时可用如下15个疑问词的缩写形式表示:WT(何事)、WB(何据)、WF(何事实)、WI(何推断)、WP(何处置)、WO(何人)、WH(何时)、WR(何地)、HW(何方式)、WY(何因)、WE(何效果)、WA(何态度)、WC(何条件)、WG(何变化)、WJ(何结论)[26]。
根据语言学相关理论,命题被看成过程,该过程以谓词为中心,所涉及的事物是个体,过程在一定环境中进行。因此,微观上,信息单位由过程、个体和环境3类主要信息成分构成,它们是标识信息具体内容和特征的重要参数。过程信息成分下有8个子类,分别为状态、性质、出现、关系、行为、生成、改变、否定;个体信息成分下有5个子类,分别为施事、经受、客体、使成、归附;环境信息成分下有12个子类,分别为工具、方位、来源、目标、伴随、时间、影响、借助、情景、依据、方式、详陈[26]。
以下采用语篇信息分析方法对一篇含有4个语篇信息单位的法庭辩护词语篇[26]的宏观信息结构和微观信息结构进行基本分析。
① 辩护人认为被告人周某某的行为不构成犯罪。
② 理由如下:周某某对自己身份的宣传应当属于夸大而不是虚构。
③ 在案件中我们看到,周某某在对某房地产公司的领导介绍自己时,确实自称是中央党校办公室副主任。
④ 但这里我们有两点需要说明……
宏观上,该辩护词语篇共包含①、②、③、④ 4个信息单位,这4个信息单位之间的层级关系如图1所示。信息单位①表述了该辩护词语篇的中心思想,是该语篇的核心命题。信息单位②从何原因角度发展核心命题,是位于第1层级的信息点。即第1层级包含一个信息点,即何因(WY)。该信息点标示信息单位②与表述核心命题的信息单位①之间的关系。信息单位③提供事实信息支持信息单位②。信息单位④阐明需要说明的其他事项,发展信息单位②。即第2层级包含2个信息点,分别为何事实(WF)信息点和何事(WT)信息点。何事实(WF)标识信息单位③与信息单位②之间的关系,何事(WT)标识信息单位④与信息单位②之间的关系。
微观上,信息单位①中包含2个个体类信息成分:“行为”和“犯罪”,2个过程类信息成分:“不”和“构成”,2个环境类信息成分:“辩护人认为”和“被告人周某某的”。个体信息成分“行为”和“犯罪”分别属于其下2个子类:“经受”和“归附”;过程信息成分“不”和“构成”分别属于其下2个子类:“否定”和“关系”;环境信息成分“辩护人认为”和“被告人周某某的”分别属于其下2个子类:“情景”和“详陈”。

图1 示例辩护词语篇中各信息单位间关系示意图
(二) 基于语篇信息分析的自媒体言语鉴定研究的可行性
源于法律语篇树状信息结构模式的语篇信息理论认为口语语篇和书面语语篇很难截然分开。典型口语语篇和典型书面语语篇分别处于同一连续体的两端;兼具口语和书面语特点的混合型语篇位于同一连续体的中部;口语特点不如典型口语语篇明显的类口语语篇位于典型口语语篇与混合型语篇之间;书面语特点不如典型书面语语篇明显的类书面语语篇位于典型书面语语篇与混合型语篇之间[26]。
基于语篇信息理论中语篇类型的分类及现有的自媒体主要言语语篇形式的自身特点,自媒体言语类型既包括典型书面语语篇、典型口语语篇,也包括混合性语篇、类口语语篇和类书面语语篇。常见类型的自媒体言语语篇在语篇同一连续体上的位置如图2所示。其中,电话/语音/视频交谈属于典型口语语篇,自撰较长博文属于典型书面语语篇,语音信息属于类口语语篇,电子邮件和发表的文字等属于类书面语语篇,即时聊天文本信息和互动留言等属于混合性语篇。

图2 语篇同一连续体上的自媒体言语语篇主要类型
根据语篇树状信息结构模式,所有语篇都由3个层面构成,分别是可听或可读的语言形式层面、承载命题内容的信息层面和反映语篇生产者认知结构的认知层面。语篇信息处于语言形式表层和认知底层之间,其结构较形式多变的表层语言形式稳定,并能反映语篇生产者的认知结构,这使得采用同一处理方法,即语篇信息分析方法同时研究口语语篇和书面语语篇成为可能[26]。也就是说,理论上可以采用语篇信息分析法分析语篇类型覆盖面宽泛的自媒体言语。相关实验研究也证明可以采用语篇信息分析法挖掘用于司法书面言语鉴定或司法口头言语鉴定的特征参数。如:张少敏通过实验研究验证语篇信息特征能够根据信息量多寡、表达方式强弱、对语言的修饰程度及对一个命题的详述程度鉴别文本作者[27];(关鑫)研究发现语篇信息特征具有潜在的口头言语说话人识别能力[28];关鑫还以日常面对面交谈会话和电话交谈会话为实验材料,提取并验证了若干可以用于司法口头言语鉴定的语篇信息特征[29]。以上研究表明,语篇信息特征可以作为司法书面言语鉴定和司法口头言语鉴定的识别特征鉴定言语人。
综上所述,理论上语篇信息分析法可以同时处理分析不同类型的言语语篇,实证研究也证明采用语篇信息分析法分析言语材料可以挖掘具有言语人识别能力的语篇信息特征。因此,采用语篇信息分析法分析自媒体言语,挖掘不同类型的自媒体言语语篇共享的、具有言语人识别能力的语篇信息特征,在理论层面和实际实施层面都是可行的。
(三) 个案分析
本文采用语篇信息分析法分析4位教育背景、职业相同的言语人的自媒体言语语料,尝试提取具有潜在的言语人识别能力的语篇信息特征,并采用判别分析法检验所提取的语篇信息特征的识别能力。表1所示为4位言语人的基本信息。
所抽样的4位言语人自媒体言语语篇的基本信息如表2所示。言语人S1的第1份言语资料是电话交谈的录音,这是典型口语语篇;言语人S1的第2份言语资料是QQ即时聊天文本信息,这是混合性语篇;言语人S2的第6份言语资料是在微信上发表的文字,这是类书面语语篇;其他言语资料都是微信即时聊天文本信息和微信语音信息,其中微信即时聊天文本信息是混合型语篇,微信语音信息是类口语语篇。表2还显示,最短的言语语篇只包含2个信息单位,信息结构只有1层;最长的言语语篇包含11个信息单位;信息结构最复杂的言语语篇有5个层级。

表1 言语人基本信息

表2 自媒体形式言语数据信息
注:S1.1指言语人S1的第1份言语语篇,S1.2指言语人S1的第2份言语语篇……S4.8指言语人S4的第8份言语语篇。
本文选取10个语篇信息特征,依次以F1至F10表示(特征说明见表3)。其中,F1和F2可能反映言语人的言语语篇宏观信息结构个性特征,F3可能反映言语人的言语语篇微观信息结构个性特征,F4至F10是信息成分频率特征。Johnstone Barbara和Biber Douglas指出,体现某一语言特征的有规律持续出现的绝对频率 (absolute frequencies) 能反映言语人的个性身份特征[30-31]; Aitken Colin等认为,相对频率(relative frequencies) 作为统计数据证据更加有效[32]。因此,F4至F10可能反映言语人的言语语篇微观信息结构个性特征。
本文采用判别分析法,以F1至F10这10个语篇信息特征总体为自变量,言语人为分组变量,用SPSS21软件对所抽样的20份自媒体言语数据进行判别分析,把4位言语人的20份自媒体言语材料归入不同的分组。如果这些特征具有言语人识别能力,则4位言语人的20份自媒体言语材料会被正确分组。

表3 语篇信息特征及说明
统计数据显示,初始判别分析中4位言语人的20份言语材料被100%正确分类。判别分析中衡量判别函数有效判别力的一个标准是正确分类的比率应该超过随机分组比率的20%或25%。随机分组比率计算公式为 (100%÷G)×1.2或(100%÷G)×1.25,其中G指总类别数[33]。在本文交叉验证分析中,源于4位言语人的20份言语材料正确分类率为50%,大于随机准确率31.2%。此外,在判别分析所构建的3个函数中,前两个判别函数的特征值都大于1 ,分别为12.510和2.857;判别函数1达到0.03的显著水平,判别函数2略高于显著水平0.1。也就是说,该判别分析结果有效。
图3所示为言语样本的联合分布图,展示了4位不同言语人的20份言语样本在判别空间中的联合分布情况。图3显示,言语人S1、S3相距较远,而且它们的空间位置也远离S2、S4,函数2成功把言语人S1与言语人S2、S3、S4分开,函数1成功把言语人S3与言语人S1、S2、S4分开。函数2可以把两位男性言语人S1和S2成功分类,函数1可以把两位女性言语人S3和S4成功分类。
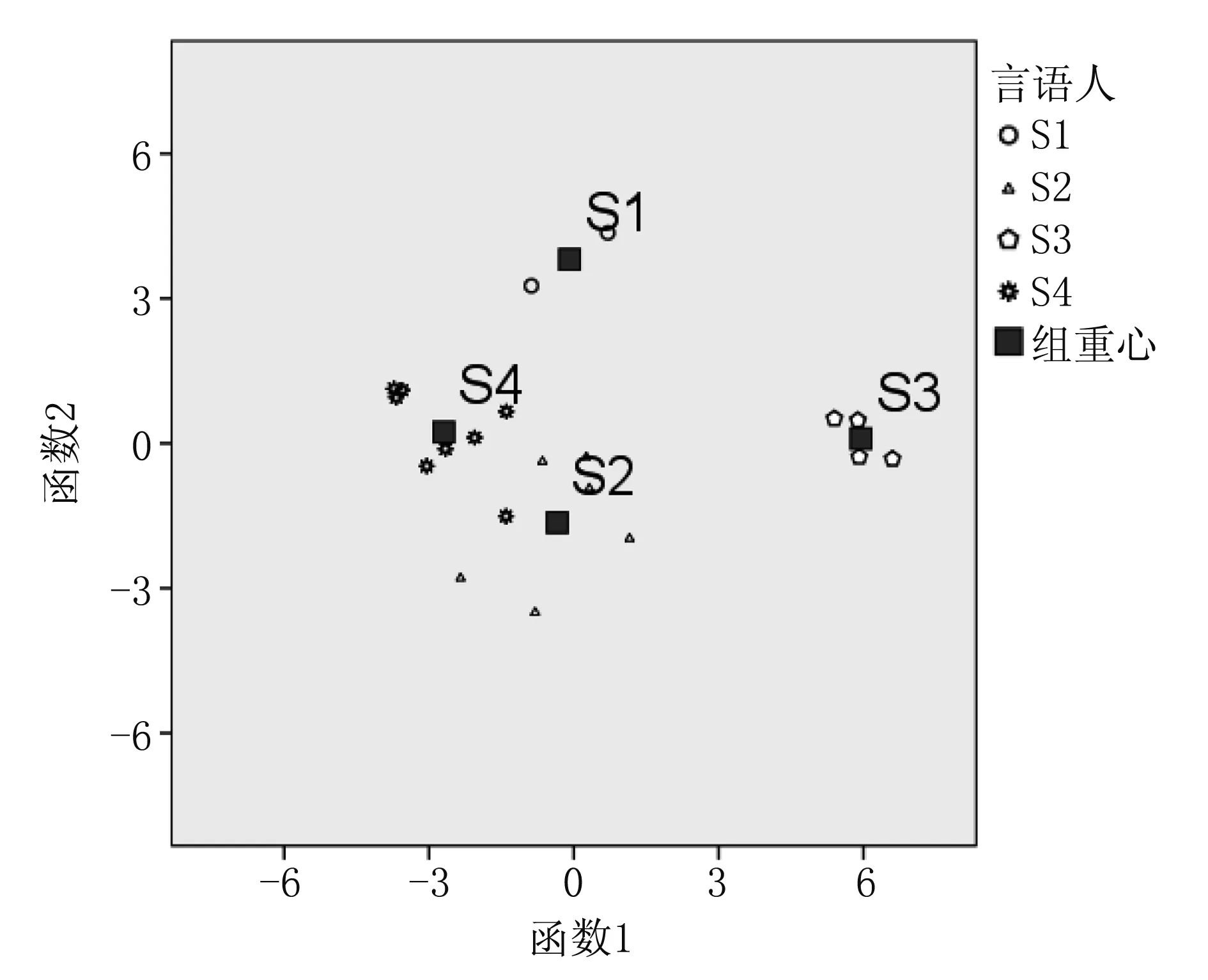
图3 言语样本联合分布图
图3还显示,言语人S4的一份言语样本所占空间位置更接近言语人S2的组重心。也就是说,误判可能会发生在S2与S4之间。但S2为男性,S4为女性,他们的言语样本中都包含语音信息和聊天文本,可以借助口头言语鉴定技术和书面言语鉴定技术进一步比对这两位言语人的言语样本,再将结果与本实验结果进行交叉验证。
以上个案数据分析结果表明,虽然自媒体言语几乎覆盖了从典型口语到典型书面语这同一连续体上的所有语篇类型,同一言语人的不同类型的自媒体言语语篇在语篇信息层面具有共同的能体现言语人个性身份的语篇信息特征。
四、 结语
自媒体时代,言语人的言语资料数量巨大,容易获取,这为司法言语鉴定技术的实践应用带来了无限机遇。但是,由于目前司法言语鉴定技术的鉴定对象通常为典型口语语篇或典型书面语语篇,而自媒体言语形式多样,口头言语与书面言语很难截然分开,从而使司法言语鉴定研究面临巨大挑战。为了应对自媒体时代司法实践的需求,本文以自媒体言语为研究对象,探讨采用语篇信息分析方法挖掘自媒体言语司法鉴定特征的可行性,并在个案分析中,运用判别分析统计方法检验所挖掘的语篇信息特征是否具有言语人识别能力。个案研究结果证明,本研究中所挖掘的语篇信息特征能有效区分言语人。如果这些特征和现有的司法言语鉴定方法相结合,鉴定结果会更加可信。
本文的局限性在于,个案分析中言语人数量及言语样本数量有限,语篇类型较单一。尽管如此,该研究揭示了自媒体时代司法实践中书面言语鉴定和口头言语鉴定很难截然分开,强调司法口头言语鉴定和书面语鉴定必须相辅相成、互为补充、相互印证,以提高言语鉴定证据的信度和法庭采信度。司法言语鉴定研究应以满足不同时代司法实践需求为目标,时刻关注不同时代言语的特点,探讨挖掘不同时代言语中言语人识别特征的新方法。
猜你喜欢
小学教学研究·教研版(2022年3期)2022-04-08
天津外国语大学学报(2021年1期)2021-03-29
新世纪智能(语文备考)(2019年1期)2019-05-31
福建基础教育研究(2019年5期)2019-05-28
作文世界(小学版)(2017年5期)2017-06-08
外语教学理论与实践(2014年4期)2014-06-13
当代修辞学(2014年1期)2014-01-21
当代修辞学(2014年1期)2014-01-21
中国诗歌(2013年3期)2013-08-15
中学教学参考·语英版(2008年8期)2008-11-26
