
基于数据挖掘的脑白质疏松症相关因素分析
2018-10-31 07:43娜迪热艾孜热提艾力封红亮张帅美王美瑶刘煜敏
中国卒中杂志 2018年10期
娜迪热·艾孜热提艾力,封红亮,张帅美,王美瑶,刘煜敏
脑白质疏松症(leukoaraiosis,LA)是双侧侧脑室周围和(或)半卵圆中心区脑白质异常的影像学概念[1],属于脑小血管病的一种。LA在脑磁共振成像(magnetic resonance imaging,MRI)扫描时T1加权像上呈等信号或低信号影,T2加权像(T2-weighted imaging,T2WI)和液体衰减反转恢复序列(fluid attenuated inversion recovery,FLAIR)上均为高信号影[2]。需指出的是,LA有广义和狭义之分,广义LA指血管源性、中毒、感染、脱髓鞘、脑积水、肿瘤和免疫等多种病因引起的脑白质影像学改变;狭义LA专指血管源性LA(vasogenic leukoaraiosis,VLA)。本研究排除非血管因素所致LA患者,分析VLA相关因素。目前国内外研究报道年龄和高血压为VLA独立的危险因素[3],也有报道提出脑动脉粥样硬化、既往脑梗死或脑出血病史、糖尿病、吸烟、尿酸水平等多种因素与VLA相关[4-6],但仍存在多种争议[7]。既往大部分有关VLA相关因素的研究中使用单因素和多因素Logistic回归分析方法,有些研究中存在统计学分析不严谨或样本量较少等问题,因此,本研究尝试使用数据挖掘技术分析1197例住院患者临床数据,探讨VLA相关因素。
1 研究对象与方法
1.1 研究对象 回顾性地收集2015年4月-2017年2月武汉大学中南医院神经内科满足条件的住院患者。纳入标准:①年龄>40岁;②已通过1.5T或3T超导磁共振扫描获得T2WI-FLAIR图像。排除标准:①磁共振T2WI-FLAIR图像质量影响Fazekas评分的评估;②诊断为特异性的中枢神经系统脱髓鞘疾病或中枢神经系统感染性疾病;③MRI发现颅内肿瘤,颅内血肿等占位性病变;④患有急性或者陈旧性大面积脑梗死(>1/3大脑中动脉供血区),或者存在直径>2 cm的新发或陈旧侧脑室旁梗死灶;⑤存在其他可能影响Fazekas评分的疾病,如严重脑外伤、脑结构变异和各种原因导致的脑积水等;⑥住院资料中拟研究因素相关数据缺失较多等患者。
1.2 临床数据收集 收集的拟相关因素数据包括性别、年龄、颅内动脉狭窄[计算机断层扫描血管成像(computed tomography angiography,CTA)或磁共振血管造影(magnetic resonance angiography,MRA)检查发现任一颅内动脉狭窄超过50%]、颈内动脉狭窄程度、高血压病史、2型糖尿病史、冠状动脉粥样硬化性心脏病史、吸烟史。检验科指标:白细胞计数、红细胞计数、血红蛋白浓度、血小板计数、红细胞压积、平均红细胞体积、红细胞分布宽度、平均红细胞血红蛋白浓度、平均红细胞血红蛋白含量、尿素氮、肌酐、尿酸、空腹血糖、甘油三酯、总胆固醇、高密度脂蛋白和低密度脂蛋白。为了避免涉及患者隐私,在录用数据时为每位患者进行单独编码,隐去姓名、住院号等可能暴露患者身份信息的数据。
Fazekas评分:根据T2WI-FLAIR图像显示的脑白质损害程度和部位不同可进行Fazeks评分[8]。评分规则为侧脑室旁高信号:0分:无病灶;1分:病灶呈帽状或铅笔样薄层;2分:呈光滑的晕圈病灶;3分:不规则的脑室旁高信号,延伸到深部白质。深部白质高信号:0分:无病灶;1分:点状病灶;2分:病灶开始融合;3分:病灶大片融合[9]。对侧脑室旁和深部白质评分进行相加获得最终Fazekas评分(0~6分)。此项评分作为数据分析时目标特征,即为患者分类依据。Fazekas评分0分为非LA患者,评分1~6为LA患者。上述住院资料收集和Fazekas评分均由两名神经内科医师独立完成,数据不一致时通过协商或第三方再次审阅患者资料后确定。
1.3 数据挖掘方法分析步骤 数据挖掘是通过机器学习的算法搜索与发现隐藏于大量数据中的信息与知识的过程。随着医院电子病历系统的完善,临床医疗数据每天都以指数级别增长,而数据挖掘的优点正是快速有效地处理和分析大规模数据。因此本研究中尝试利用数据挖掘方法分析临床数据,以此探讨VLA相关因素。数据挖掘方法由三大步骤组成,分别为数据预处理、相关因素分析和预测模型的训练及其评价(图1)[10]。本文将通过这3个步骤讲述分析数据过程。
图1 数据挖掘的步骤图
1.3.1 数据预处理 首先从中南医院电子病历系统中收集研究对象临床数据。临床资料中存在大量非数值型数据,如既往史记录、影像学表现等。通过编码规则将文本资料转化为能进行分析利用的数据。本研究中,对于二分类变量(<60岁、男性、高血压病史等)进行0或1编码。对于检验科计量资料数据,根据非LA患者每项数据四分位数进行变量编码。编码后产生的数据集作为研究数据集。
由于电子病历系统中既往史等部分由人工录入,可能存在漏写等情况,因此收集临床数据时发现部分项目没有明确记录,即出现缺失值。本研究中颅内动脉狭窄、颈内动脉狭窄程度和吸烟史等因素都有缺失值,需进行缺失值处理。颅内动脉狭窄的缺失值占12.87%,建立自变量间简单相关系数矩阵所得颅内动脉狭窄跟年龄、高血压病史、2型糖尿病史、高密度脂蛋白胆固醇(high-density lipoprotein cholesterol,HDL-C)水平、白细胞计数等5种特征相关性最大。因此以上述5种变量为变量特征,利用已知1000余例患者数据,建立颅内动脉狭窄预测模型,以此获得相关缺失数据的替代值。颈内动脉狭窄程度特征的缺失值占29.57%,吸烟史特征的缺失值占78.95%,由于缺失值过多,无法准确预测出缺失值,因此删除这两项因素数据。
1.3.2 相关因素分析方法 特征是指纳入研究的VLA潜在相关因素,比如性别、年龄、是否有高血压等为患者3种不同特征。特征构建是指上述数据收集后对各项特征数据进行编码处理,删除存在大量缺失值的特征以及通过编码建立新的特征的过程(如血红蛋白浓度符合条件者为贫血,编码为1;不符合条件为非贫血,编码为0;条件为:男性血红蛋白浓度<120 g/L,女性血红蛋白浓度<110 g/L,以此构建出贫血特征)。最后的研究数据集中每例患者有24个特征,目标特征为MRI上是否发现LA,即Fazekas评分是否≥1。
利用数据挖掘技术从上述24种特征中选出与VLA相关性最大的因素,此过程称之为特征选择。过滤方法是最常用的特征选择方法,该方法通过对每一个特征进行评分,根据分数的高低将特征排序,然后选择指定数目的特征[11]。本研究中利用Pearson相关性分析和卡方检验(Chi2)方法对每一个特征进行评分,根据分数的高低对特征进行排序(表1)。Pearson相关性系数是衡量特征与目标因素之间的线性关系的指标,值越大表明相关性越强。卡方检验最基本的思想是通过观察实际值与理论值的偏差来确定理论的正确与否,卡方值越大表明特征与目标因素之间的相关性较强。为了确定上述二者中以哪个评分结果为最终排序,分别以两种特征排序结果为基础建立了数据挖掘模型,根据性能最佳的模型来确定最终特征排序和被选出的特征数目。
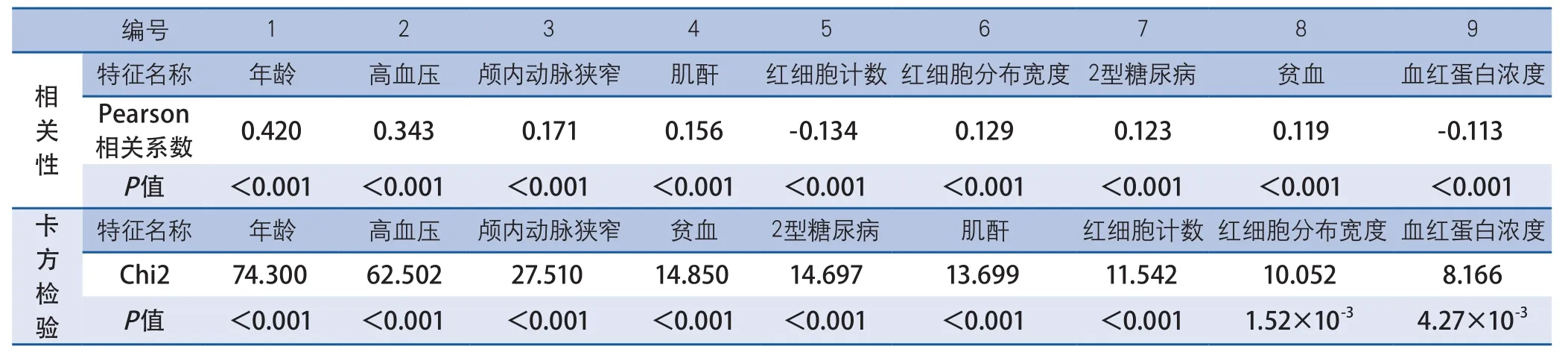
表1 特征选择表
1.3.3 预测模型的训练及其评价标准 目前有多种数据挖掘模型,其中常用于临床数据分析的有决策树模型(decision tree model,DT)、逻辑回归模型(logistic regression model,LR)、支持向量机模型(support vector machine model,SVM)和人工神经网络模型(artificial neural network model,ANN)。其中DT利用树形结构在数据集中自动构建分类规则,该模型的最大优点是直观,便于理解与解释。LR在线性回归模型的基础上用逻辑函数f(x)=1/(1+e-x)将数据进行分类。

图2 Pearson相关性方法的性能图

图3 Chi2特征选择方法的性能图

表2 各个模型在最佳特征下的性能比较
SVM首先利用核函数将数据转化为高维数据集,然后在高维数据集上寻找分开数据集的完美分割线。人工神经网络模型模仿人脑的结构,构建多层网络结构,通过多层网络结构表达线性模型难以表达的非线性关系。
本研究同时建立了上述4种数据挖掘模型,利用敏感度、特异度、准确率及受试者工作特征曲线下面积(area under the curve,AUC)(横坐标为false positive rate,纵坐标为true positive rate的曲线)值等评价模型性能。一般情况下AUC面积值大于0.5小于1。AUC值越大表示模型的预测性能越好。
2 结果
2.1 特征排序方法比较 为比较两种评分方法(Pearson相关性分析和卡方检验)所得出的特征排序准确性,用数据挖掘算法分别在两种特征排序基础上构建出模型,模型的性能比较图见图2和3。根据AUC值评价模型的性能,卡方检验排序的特征基础上建立的4种模型性能更佳,因此预测模型性能比较,特征选择等步骤将在卡方检验方法排序基础上进行。
2.2 预测模型性能比较 4个模型在最佳的特征集上的性能见表2,表中显示每一个模型在最佳特征下性能的95%可信区间。敏感度最高的是神经网络模型,特异度最高的是SVM模型,准确率最高的是LR模型。用AUC值综合评价时性能最佳模型为LR模型。
2.3 相关因素分析(特征选择)LR模型最高AUC值对应的特征数量为9,因此我们选取了卡方检验排序法前9项特征(表1)为本研究特征选择结果,即VLA相关因素。根据LR模型中此9项特征对应的回归系数β的大小,9项特征中跟VLA正相关的有:年龄(β=1.59),高血压病史(β=1.06),颅内动脉狭窄(β=0.33),贫血(β=0.27),2型糖尿病(β=0.24),肌酐(β=0.14),红细胞分布宽度(β=0.10);而跟VLA负相关的有:红细胞计数(β=-0.07),血红蛋白浓度(β=-0.03)。
2.4 决策树可视化结果 利用决策树模型预测性能最佳时(AUC=0.788±0.017)对应的4个特征,得到该决策树的可视化结果见图4。图中E表示决策路径对应的错误率。这种结果图更为直观地揭示几种不同的VLA相关因素共存的情况,也比较符合临床上老年患者多种危险因素共存的现状。
3 讨论
已有多项研究表明年龄和高血压为VLA的独立危险因素[12-13],本研究得出的特征中,年龄和高血压均与VLA呈正相关,根据特征排序结果认为与VLA相关性最大的因素为年龄,其次为高血压病史,此结果与既往研究结果一致。VLA是脑小血管病的一种,但Seung-Jae Lee等[14]发现,LA在大动脉粥样硬化性卒中患者中很常见。本研究中颅内动脉狭窄与VLA呈正相关,这可能是因为二者有共同危险因素。Pierleone Lucatelli等[15]认为糖尿病与LA呈正相关,但也有一项Meta分析认为二者无关[16],糖尿病是否与VLA相关仍需进一步研究。因为肾脏和大脑特殊的微脉管系统,两个系统均易受血管因素损害[17],因此肌酐值作为肾功能损害的指标,或许与VLA有一定相关性,本研究也发现肌酐与VLA呈正相关。
特征选择发现的其余4个相关因素均为红细胞数量和功能方面检验指标。贫血是结合性别和血红蛋白浓度进行编码的特征,而国内外很少有研究报道贫血与VLA关系,Marco Inzitari等[18]发现合并有贫血的高血压患者患LA风险增高,而无高血压的群体中,贫血与脑白质病变无关。本次研究通过特征选择发现贫血与VLA呈正相关,且相关程度仅次于年龄、高血压、颅内动脉狭窄等特征,或许这结果为后期研究提供一个新的潜在相关因素。有关红细胞分布宽度与VLA关系的研究不多,有研究报道,红细胞分布宽度可能为急性脑梗死合并VLA的独立危险因子且与LA的严重程度呈正相关,对LA具有一定的预测价值[19],本研究表明红细胞分布宽度可能是VLA的相关因素。

图4 决策树的可视化图
本次研究利用数据挖掘技术分析临床数据,探讨了VLA相关因素,并通过特征选择方法选出9种与VLA有关的因素。其中年龄、高血压等是已被公认的危险因素,且在决策树可视化图中可见这两项因素在预测VLA发病时权重很大,也比较符合临床上老年高血压患者LA发病率很高的现实。除此之外,本次研究也发现贫血、红细胞分布宽度、肌酐值等仍没被广泛研究的因素也跟VLA发病相关,对后期进一步研究有一定的指向性作用。本次研究另一特点是探讨数据挖掘方法在临床数据分析应用方面的可行性。本次研究不足之处为患者例数仅为1000余例,研究纳入的潜在相关因素也只有24种,仍然不能很好地体现数据挖掘技术的优越性。医院信息系统功能的完善和临床专业数据库的建立为这种崭新的数据分析方法提供更为广泛的数据来源,这也一定程度上呼吁临床工作者了解和探讨数据挖掘技术在临床科研中的应用,以此获得更多有意义的、可指导临床工作的研究成果。
猜你喜欢
中国临床医学影像杂志(2022年6期)2022-07-26
九江学院学报(自然科学版)(2022年2期)2022-07-02
中国临床解剖学杂志(2022年2期)2022-04-22
中国临床解剖学杂志(2022年1期)2022-02-14
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
包头医学院学报(2021年3期)2021-04-29
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
计算机应用(2017年3期)2017-05-24
