
正交基低冗余无监督特征选择法
2022-01-21 05:10:30简彩仁翁谦
福州大学学报(自然科学版) 2022年1期
简彩仁,翁谦
(1.厦门大学嘉庚学院, 福建 漳州 363105; 2.福州大学计算机与大数据学院, 福建 福州 350108)
0 引言
高维数据广泛存在于机器学习、数据挖掘和模式识别等领域.这些数据存在许多无用或者冗余的特征,从而影响高维数据的识别研究.此外, 大量的冗余特征会占用内存空间,从而影响存储和计算效率.高维数据往往带来“维数灾难”[1-4].因此研究高维数据的降维具有重要的意义,而特征选择是数据降维的一种常用手段,本研究分析数据集的特征选择.
特征选择旨在从原始数据集中选出具有判别特性且相关的特征子集,同时减少冗余、不相关、高噪声的特征.许多研究人员提出了各种特征选择法,并广泛应用于机器学习的各个领域.根据样本的标签信息,特征选择可以分为有监督特征选择、半监督特征选择和无监督特征选择[1].由于获得样本的类别信息需要大量的工作,因此研究无监督的特征选择具有重要意义.不仅如此, 无监督特征选择在发现数据集内部隐含的信息也有一定的作用.基于此,本研究分析了无监督特征选择法.
一般地,无监督特征选择法可以分为过滤型特征选择法、捆绑型特征选择法和嵌入型特征选择法[4].过滤型特征选择法根据一定的规则给每一个特征打分排序选择特征,其典型代表是最大方差特征选择法(MV)和拉普拉斯特征选择法(LS)[5],MV选择方差最大的特征增加区分度,而LS利用局部近邻信息选择保持局部信息的特征.捆绑型特征选择法利用机器学习方法定义评价准则,从模型的表达能力选择特征,其典型代表是多簇特征选择法(MCFS)[6],利用保持多簇结构为准则选择特征.得益于表示理论的发展,嵌入型特征选择法得到了很好的发展.嵌入型特征选择法通过数据表示和l2, 1范数的组稀疏性选择特征.关于嵌入型特征选择法的研究层出不穷,Han等[7]提出一种基于正则回归的无监督并行正交基聚类特征选择法(SOCFS),该方法基于正交基构建目标矩阵来捕获投影数据的潜在簇中心进而选择具有更强识别能力的特征;Lim等[8]引入特征成对依赖的观点改进了该方法,提出特征依赖无监督特征选择法(DUFS),该方法可以选择更少的特征提高识别准确率.Mohsen等[9]提出自适应相似性学习与子空间聚类无监督特征选择法(SCFS),该方法不仅通过子空间聚类保持样本的相似性,同时也考虑了基于正则化回归模型的数据底层结构.因为嵌入型特征选择法能全面考虑数据的内部结构,是较好的一类特征选择方法,得到了研究学者的青睐.更多关于特征选择的研究可以参考相关综述 [3-4].
SOCFS基于正交基重构数据集从而选择具有判别能力的信息,然而没有考虑选择特征之间的相关信息,容易选择冗余特征.针对这一不足,借鉴最大互信息系数(MIC),提出正交基低冗余无监督特征选择法.
1 相关工作
1.1 符号说明
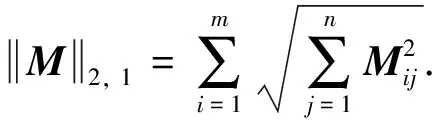
1.2 SOCFS

因为这种基于正则化回归的特征选择方法已被证明在有监督和无监督的情况下都能有效地处理数据,形如下式的特征选择方法被广泛应用. 在有监督的特征选择中,Y可以通过给定的标签信息来定义. 然而,在无监督特征选择中,由于标签信息不可用,聚类结果(如k-means)通常被用来代替Y.目标矩阵的因式分解在机器学习和数据挖掘中表现出了良好的性能. 此外,矩阵分解在无监督特征选择中有显著的效果. SOCFS将隐式Y分解为A∈Rc×c和H∈Rn×c,得到如下的目标函数:
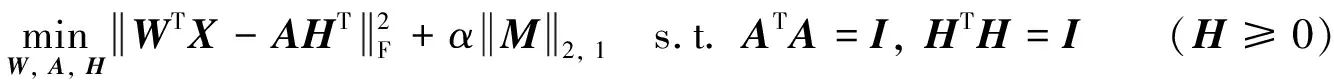
(1)
其中,I是单位矩阵,正交约束ATA=I使得A的列向量是独立的.H的正交性和非负约束使得H的每一行只有一个非零元. 约束条件使投影数据WTX进行正交聚类.最小化问题意味着W选择的特征子集实现正交聚类[7].
2 正交基低冗余无监督特征选择法
2.1 目标函数
特征选择矩阵W在去除不相关特征的同时,也会选择有区别的特征.然而,同时选择具有高冗余率的特征可能会导致机器学习算法的性能退化.例如,训练具有冗余特征的分类器可能会降低分类的准确率.因此,有必要施加一个惩罚项来最小化所选特征的冗余程度.最大互信息系数(maximal information coefficient, MIC)[10]适用于测量线性和非线性数据的相关性,本研究采用最大互信息系数作为相关性评价标准.基于MIC的低冗余惩罚项定义如下:
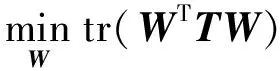
(2)
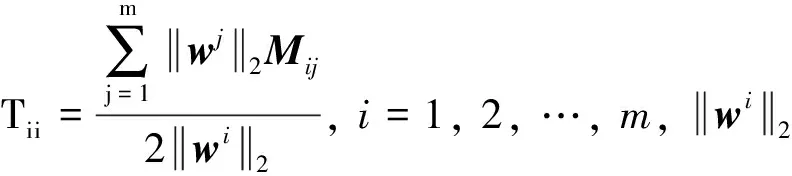
利用SOCFS得到的W可以选择具有判别能力的特征,然而容易导致选择的特征子集具有高冗余率.最大互信息系数(MIC)能降低选择特征子集的冗余性,因此利用MIC改进SOCFS,将公式(1)~(2)合并得到如下的目标函数:
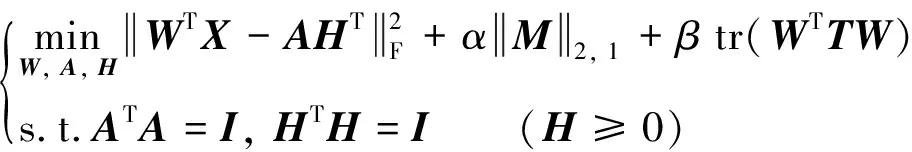
(3)
其中,β≥0是正则参数,目标函数的第三项是低冗余惩罚项,用于选择冗余度较低的特征.
公式(3)通过低冗余惩罚项改进SOCFS得到具有选择低冗余特征子集的无监督特征选择法,将这种方法称为正交基低冗余无监督特征选择法(orthogonal basis minimization redundancy unsupervised feature selection method,OBMRFS).
2.2 模型求解

(4)
其中,γ>0是另一个正则化参数,用于控制其他项之间的比例.当其他变量不变时,这个公式在每个变量上都是凸的.因此,可以用一次求解一个变量的方式求解公式(4)[7-8].将公式(4)的目标函数记为:
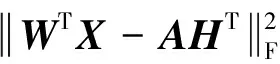
(5)

W=(XXT+αD+βT)-1XHAT
(6)
2) 更新A.目标函数关于A的部分为:
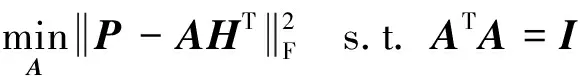
(7)
其中:P=WTX.
定理1最优的A可以通过奇异值向量得到A=UVT,PHT=UΣVT,Σ=diag(w),其中(U,Σ,V)是PHT的SVD分解.
证明 公式(7)可以转化为:


根据定理1,可得A的最优解为:
A=UVT
(8)
其中:WTXHT=UΣVT. 式(3)更新H,目标函数关于H的部分为:

类似于定理1,最优的H可以通过奇异值向量得到H=UVT,XTWA+γG=UΣVT,Σ=diag(w),其中(U,Σ,V)是XTWA+γG的SVD分解. 因此,H的最优解为:
H=UVT
(9)
其中,XTWA+γG=UΣVT.
式(4)更新G,辅助矩阵G满足:
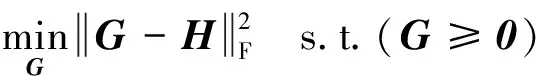
(10)
则不难得到:

(11)
2.3 正交基低冗余无监督特征选择算法
将2.2的算法流程总结成本研究提出的正交基低冗余无监督特征选择法.

算法1: 正交基低冗余无监督特征选择法(OBMRFS)Input: 数据集X, 最大互信息系数矩阵M, 参数α, β, γ, 类别数量c, 选择特征数量pInitialize: t=0, D, T, A, H当t≤maxIter 执行:利用公式(6)更新W; 利用公式(8)更新A; 利用公式(9)更新H; 利用公式(10)更新G; 更新D和T: Dii=12wi2, Tii=∑mj=1wj2Mij2wi2, i=1, 2, …, m; 结束while循环Output: 将wi2按降序排列, 选择前p个特征为特征子集.
2.4 收敛性与计算复杂度分析
定理2当固定A,H和G时,用公式(6)更新W,目标函数都是单调不增的.
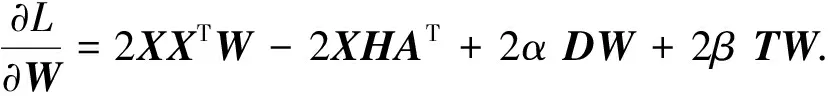
定理2说明每次更新W目标函数都是单调不增的.当W和H固定时,有:
上式是一个具有等式约束的二次函数优化问题,基于KKT条件[11],利用拉格朗日乘数法得到A的最优解,因此更新A,目标函数是单调不增的. 当W,A和G固定时,则:
上式是一个具有等式约束的二次函数优化问题,基于KKT条件[11],利用拉格朗日乘数法得到H的最优解,因此更新H,目标函数是单调不增的.
固定Ht利用公式(10)更新G,有:
根据文献[8],显然有L(Ht,Gt+1)≤L(Ht,Gt),于是利用公式(10)更新G,目标函数是单调不增的. 因此,通过以上分析,保证了算法1的收敛性.
公式(3)的求解过程,主要运行时间消耗在计算矩阵W、A、H和G上,其中,W的计算量主要涉及矩阵乘法和矩阵求逆,时间复杂度为O(m3);A和H的计算时间复杂度主要表现在奇异值分解上,SVD的时间复杂度为O(mcn);G的计算主要涉及矩阵加法,时间复杂度为O(cn). 一般地,m>n>c,因此本研究提出的求解方法的一次迭代的时间复杂度为O(m3).
3 实验分析
3.1 实验数据与参数设置
沿用文献[12]研究的FERET、PIE、ORL和Yale 4个图像数据集进行实验,其基本信息如表1所示.

表1 数据信息
为验证OBMRFS选择的特征子集的有效性,将选择的特征子集用k-means进行聚类.对比方法为最大方差特征选择法(MV),拉普拉斯特征选择法(LS),多簇特征选择法(MCFS),正交基聚类特征选择法(SOCFS),特征依赖无监督特征选择法(DUFS),自适应相似性学习与子空间聚类无监督特征选择法(SCFS).计算所有方法选择的特征子集的聚类准确率,对给定样本,令ri和si分别为聚类方法得到的标签和样本自带标签,定义聚类准确率[13]为:
其中:n为样本总数;map(ri)将每一个标签ri映射成与样本自带的标签等价的类标签. 即有

因为OBMRFS、SOCFS、DUFS和SCFS等方法都涉及参数的选择问题,因此统一将参数的搜索空间设置为{10-3, 10-2, 10-1, 100, 101, 102, 103, 104, 105, 106}, 选择特征数量设置为{30, 60, 90, 120, 150, 180, 210, 240, 270, 300}.
3.2 实验结果与分析
对比4个数据集在不同特征选择方法下选择的特征子集其使用k-means聚类得到的聚类准确率.图1给出了各种方法选出的特征子集下的聚类准确率,表2给出了其平均聚类准确率.其中,ALL表示不进行特征选择,对原始数据集聚类得到的聚类准确率.

(a) FERET
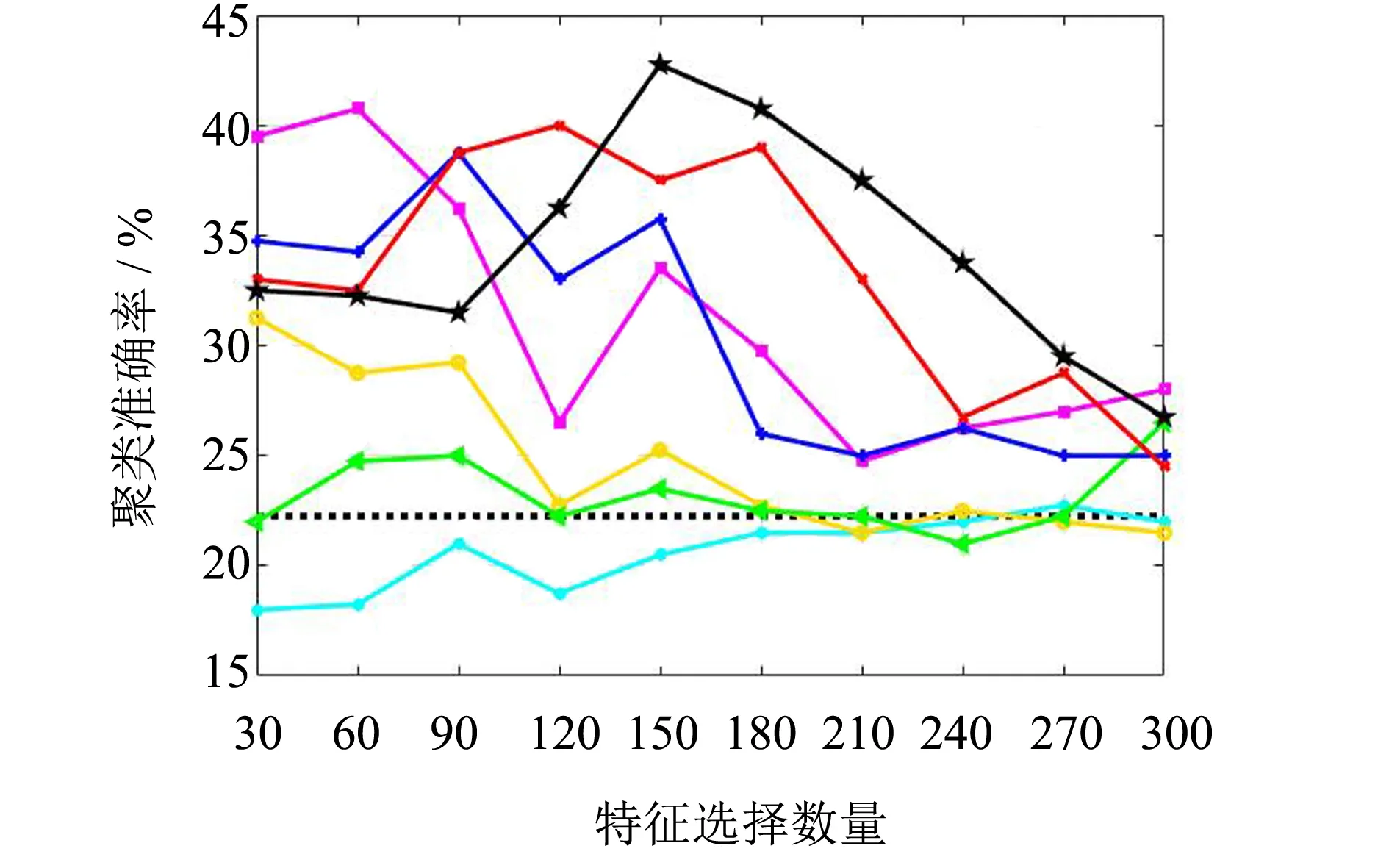
(b) PIE
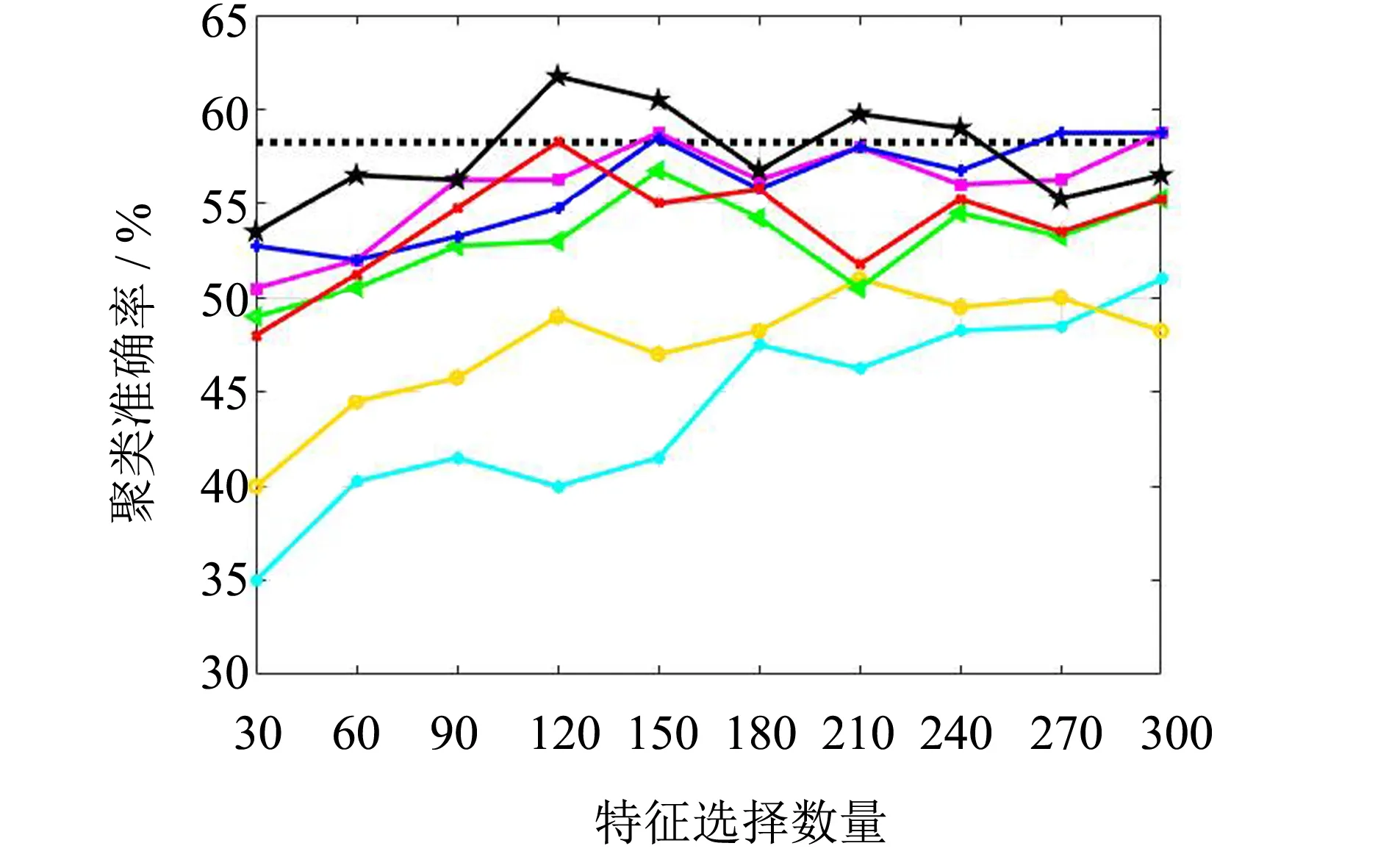
(c) ORL

(d) Yale

表2 不同方法的平均聚类准确率
图1表明OBMRFS选择的特征子集可以得到较高的聚类准确率.除了在ORL数据集上,OBMRFS都取得了最高的聚类准确率.表2的平均聚类准确率说明OBMRFS选择的特征子集是有效的,可以提高聚类方法识别的准确率.尽管在ORL数据集上,OBMRFS的聚类准确率没有超过ALL,但是OBMRFS在选择120个特征时的聚类准确率优于ALL方法.不仅如此,在4个数据集上,OBMRFS的聚类准确率都优于其他特征选择方法.对比OBMRFS和SOCFS,不难发现,OBMRFS有明显的优势,因此本研究提出的改进方法是有效的.利用低冗余惩罚项可以降低选择特征子集的冗余性,选择更有效的特征子集.
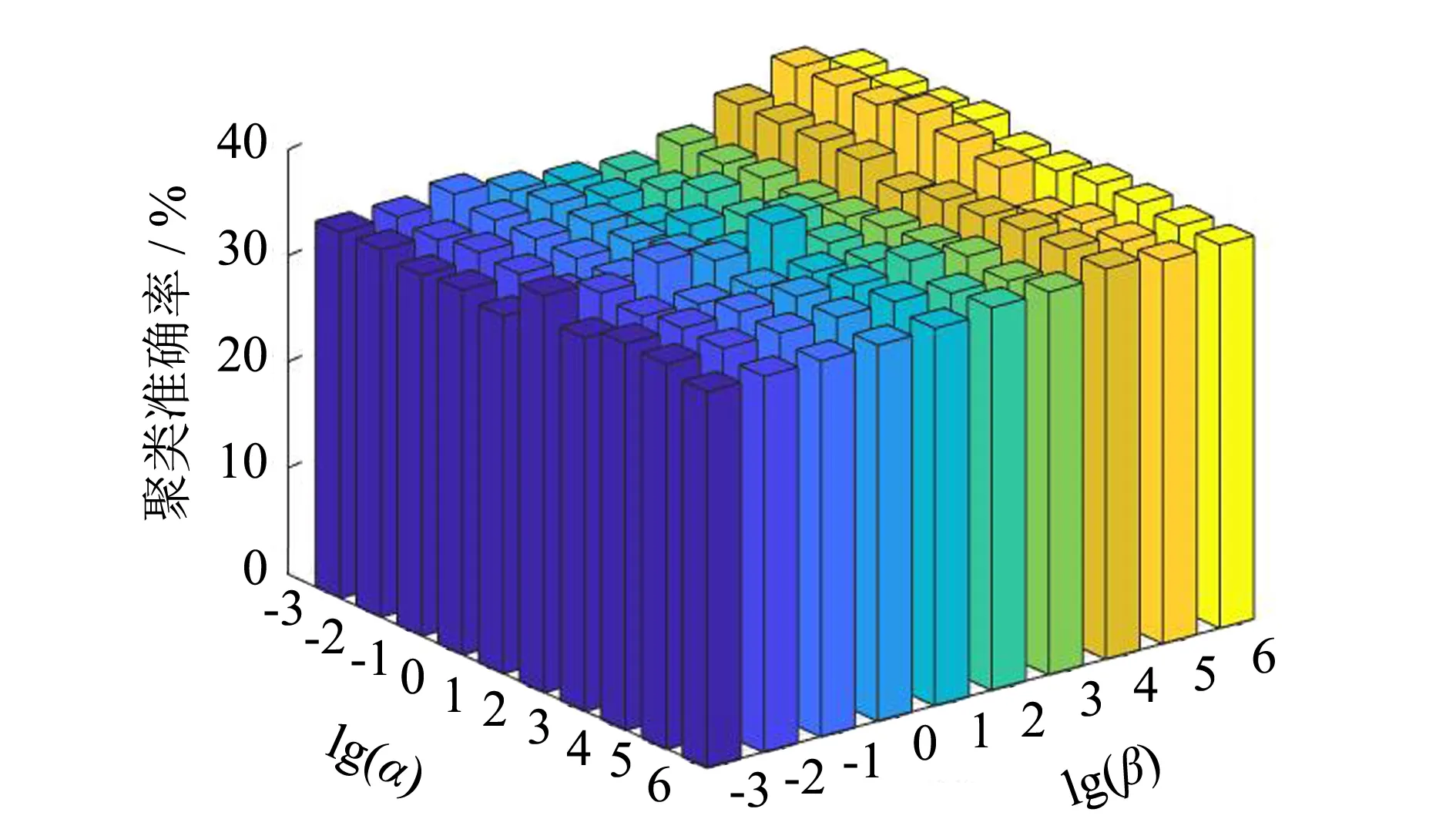
3.3 参数分析

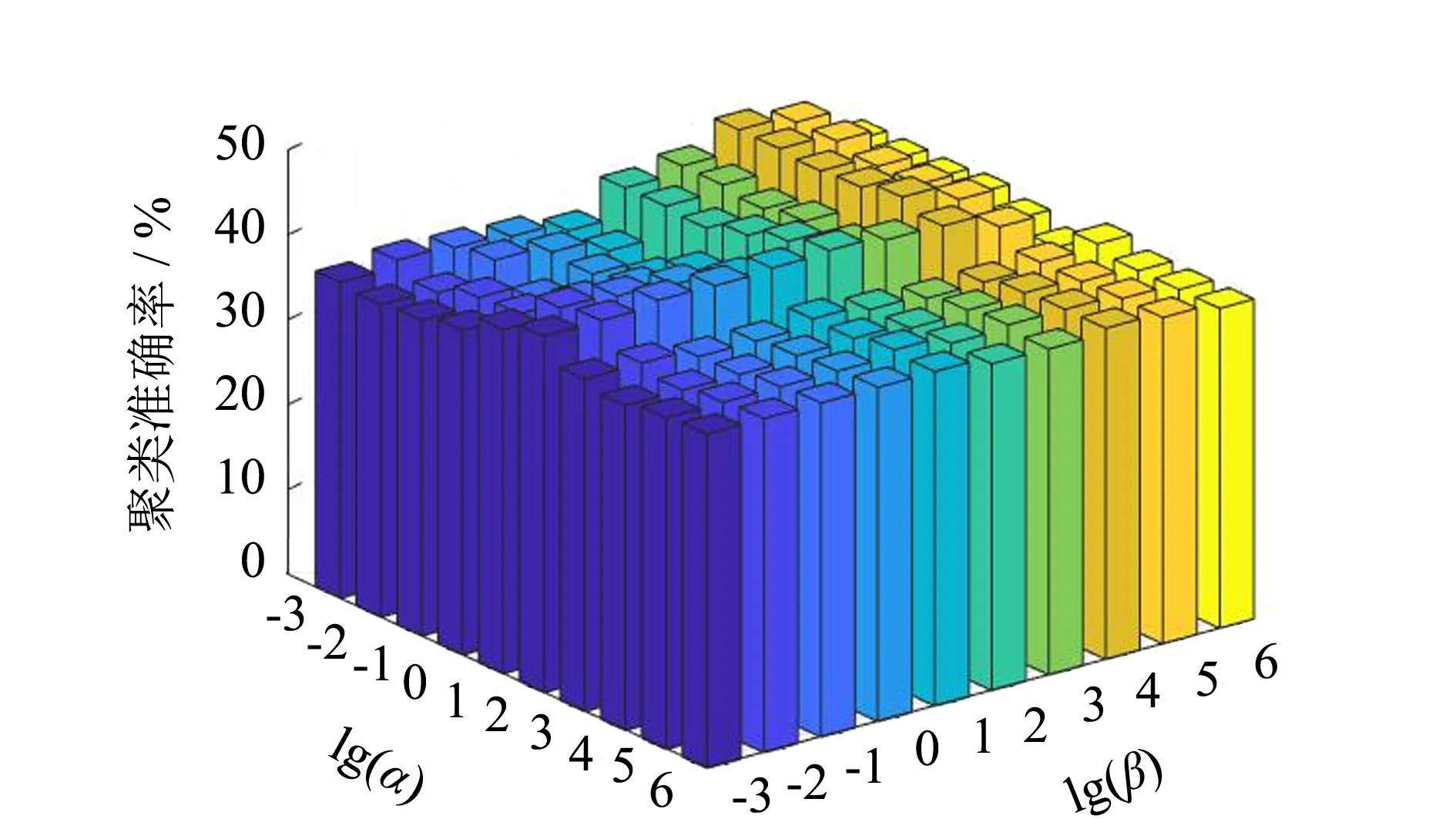
(a) FERET

(b) PIE

(c) ORL
(d) Yale
图2的实验结果表明,α和β的选择对OBMRFS的影响是明显的,但是不难发现较小的α和较大的β可以得到较好的聚类准确率.因此,在使用OBMRFS进行特征选择时可以选择较小的α和较大的β,从图2的实验结果,不难发现α在10-3到1取值,β在104到105取值时,OBMRFS选择的特征子集得到的聚类准确率较为理想.不仅如此,较大的β说明低冗余惩罚项对特征选择有重要的作用,加大这一项可以选择有效的特征子集,进而提高聚类准确率.这一发现,表明本研究提出的方法可以降低选择特征子集的冗余度.
3.4 收敛性分析
通过实验分析验证算法的收敛性,固定参数α=0.1,β=107,γ=10时,50次迭代下目标函数的取值情况如图3所示.图3的收敛曲线表明了本研究提出的算法是收敛的,验证了2.4小节的收敛性分析.此外,从图中可以发现本研究所提的算法可以快速收敛.
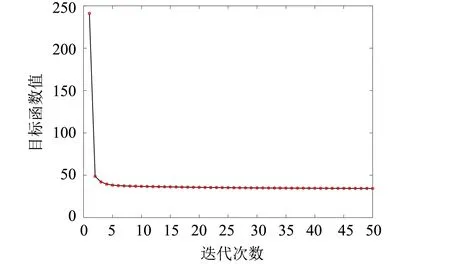
(a)FERET

(b) PIE
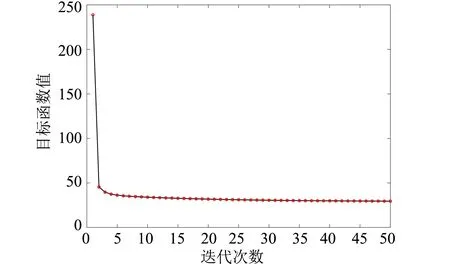
(c) ORL
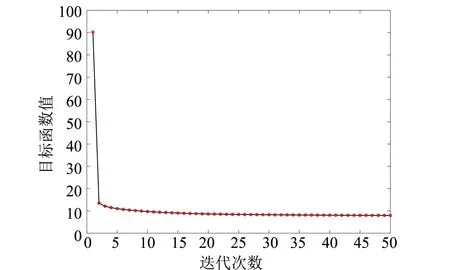
(d)Yale
4 结论
本文提出正交基低冗余无监督特征选择法,该方法在正交基下选择具有判别能力的特征,并用最大互信息系数矩阵选择低冗余性的特征子集.在4个图像数据集上的实验表明,该方法可以选择有效的特征子集提高聚类准确率.所提的最大互信息系数矩阵的构造需要较大的运行时间开销,如何更高效地去除冗余特征将在以后的研究中给出.
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2017年23期)2017-02-02 07:17:06
智能系统学报(2015年4期)2015-12-27 09:38:21
都市丽人(2015年4期)2015-03-20 13:33:22
