
基于EWT和分位数回归森林的短期风电功率概率密度预测
2018-08-20 07:20孙国强俞娜燕倪晓宇卫志农臧海祥周亦洲
电力自动化设备 2018年8期
孙国强,梁 智,俞娜燕,倪晓宇,卫志农,臧海祥,周亦洲
(1. 河海大学 能源与电气学院,江苏 南京 210098;2. 国网无锡供电公司,江苏 无锡 214061;3. 无锡扬晟科技股份有限公司,江苏 无锡 214106)
0 引言
风力发电在电网中的装机比例逐年提升,有效地缓解了能源紧张、环境污染格局,但其间歇性和不确定性又严重影响着电网的安全、稳定及经济运行。短期风电功率预测作为自动发电控制和安排电力调度的重要决策依据,能够有效地提高电力系统的运行可靠性。为此,需要研究新技术与新方法,以提高风电功率预测精度,满足工程应用需求。
目前,国内外学者对短期风电功率预测进行了大量的研究,主要有时间序列分析、人工神经网络、支持向量机(SVM)、相关向量机等模型[1-6]。在现有研究的基础上,文献[7-9]提出了基于优化算法的改进预测模型。另外,为了进一步降低风电功率预测误差,相关学者提出了组合预测模型。实践证明:组合预测模型相较于单一预测方法能够优势互补,在提高预测精度的同时,增强了模型的鲁棒性。组合预测按机理策略的不同主要分为2类。第一类是采用不同原理的预测模型分别进行预测,然后将预测结果按一定的方式进行优化组合。文献[10]首先采用自回归积分滑动平均拟合风电功率序列,然后对拟合残差分别建立了人工神经网络、SVM预测模型;文献[11]通过权重矩阵集成最小二乘SVM、回声状态网络及正则化极限学习机3种模型的预测结果,并通过优化算法动态更新调整权重系数,从而有效地发挥各个模型的优势,提高预测精度。第二类是采用信号处理技术对原始风电功率序列进行分解处理,对不同分解量建立预测模型,最后对各分量的预测结果进行组合。文献[12-14]分别采用小波变换、经验模态分解(EMD)和集成经验模态分解对原始风电功率进行处理,然后对各子序列分别建立预测模型,有效地提高了预测精度。
一般的短期风电功率预测方法仅给出确定性点的预测结果,难以完全描述风能的不确定性、变化规律。因此,相关学者提出了风电功率的概率预测方法,如分位数回归、区间预测、密度预测等[15]。概率预测能更好地描述未来风电功率可能的波动范围、不确定性及面临的风险,从而更有研究价值[16-18]。
本文针对EMD方法易出现模态混叠、计算效率低、缺乏理论基础等缺点,采用新型自适应信号处理方法——经验小波变换EWT(Empirical Wavelet Transform)对原始风电功率序列进行分解处理。该方法通过对信号频谱的自适应分割,在各个频谱构造合适的正交小波滤波器来提取Fourier频谱的调幅、调频成分,然后采用Hilbert变换对不同调幅、调频模态进行处理,获得瞬时频率和瞬时幅值[19-20]。EWT方法的计算量小且具有较强的鲁棒性。
分位数回归森林(QRF)结合分位数回归和随机森林(RF)的基本原理,可给出不同分位点的回归预测结果。作为一种非参数集成机器学习方法,QRF具有运算速度快、模型性能受参数影响小、容噪性较强等优点。本文建立基于QRF的风电功率预测模型,获得不同分位点的预测输出,然后采用核密度估计实现风电功率概率密度预测。
综上所述,本文结合EWT和QRF的优点,建立基于EWT-QRF的短期风电功率概率密度预测模型。首先,采用EWT将原始风电功率序列分解为一系列频率不同的经验模式,对每一经验模式分别建立QRF预测模型,获得不同分位点的回归预测结果,将各经验模式的预测结果叠加,得到最终的风电功率预测值。最后,采用核密度估计方法给出风电功率概率密度预测。
1 EWT方法的基本原理
经验小波本质上是根据信号频谱特性选择的一组带通滤波器,能够自适应地从原始信号中筛选调幅、调频成分。为了确定带通滤波器的频率范围,首先对信号的Fourier谱进行自适应分割,见图1。
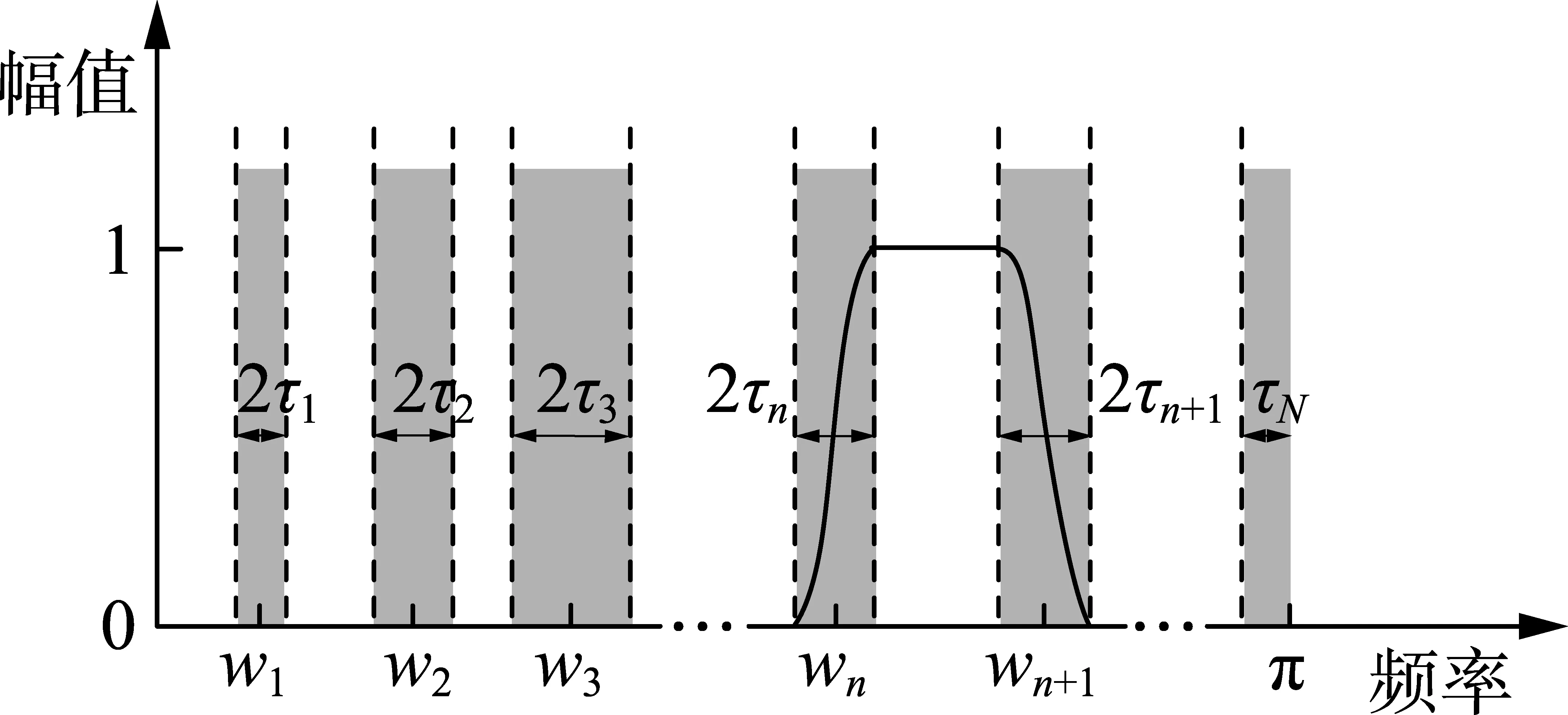
图1 Fourier频谱分割Fig.1 Partitioning of Fourier frequency spectrum
结合图1说明EWT的自适应分解过程。依据香农准则,定义Fourier支撑为[0,π]并假设其被分割成N个连续部分,令Λn=[wn-1,wn]表示各分割片段的边界,其中n=1,2,…,N,w0=0,wN=π,wn选取为信号Fourier谱相邻2个极大值点之间的中点,显而易见∪Λn=[0,π](n=1,2,…,N)。以每个wn为中心,定义宽度为Tn=2τn的过渡区域,见图1中阴影部分。在分割区间Λn上,定义经验小波为每个Λn上的带通滤波器,并根据Meyer小波的构造方法构造经验小波。Gilles构造的经验小波函数为[19]:
(1)
经验尺度函数为:
(2)
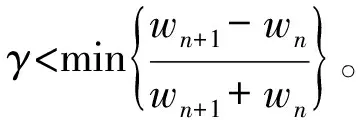
然后,原始信号可被重构为:
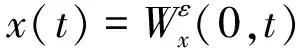
(3)
经验模式xk(t)按式(4)定义。
(4)
2 基于QRF的概率密度预测
2.1 分位数回归原理
分位数回归是单因变量Y的条件分位数对自变量X进行回归,从而获得所有分位点下的回归预测模型。
在给定条件X=[x1,x2,…,xk]下,条件分布函数是Y≤y的累积概率,即:
F(y|X)=P(Y≤y|X)
(5)
α分位数Qα(X)为在给定条件X=[x1,x2,…,xk]下,Y≥Qα(X)的累积概率恰好为α,即:
(6)
其中,inf{·}为取最小值运算。
一般的线性条件分位数回归表示为[21]:
QY(α|X)=β0(α)+β1(α)x1+β2(α)x2+…+
βk(α)xk≡X′β(α)
(7)
其中,QY(α|X)为因变量Y在自变量X=[x1,x2,…,xk]下的第α个条件分位数,α为分位点,α∈(0,1);X′=[1,x1,x2,…,xk]为X的扩展形式;β(α)为回归系数向量,它随着分位点α的变化而变动;≡表示恒等于。
条件分位数通过最小化损失函数求解参数向量β(α)的估计值,定义损失函数为:
(8)
从而分位数回归可以转化为如下最优化问题:
(9)

给定某个分位点α,通过求解对应的参数向量估计值,即可描述此时的自变量对因变量的影响。继而当α在可行区间(0,1)内连续取值时,即可得到Y的条件分布。
2.2 QRF的基本过程
QRF是RF算法的改进,通过结合分位数回归的特性,可提供因变量的全部条件分布信息。QRF作为一种非参数机器学习方法,具有理论基础,同时被证明具有一致性[22]。
RF被看作是一个适应性近邻分类和回归过程,对每一个X=[x1,x2,…,xk],可以得到原始M个观察值的一个权重集合wi(X)(i=1,2,…,M)。RF本质上是利用所有因变量观测值的加权和作为因变量Y条件均值E(Y|X)的估计。QRF决策树是以标准RF算法产生的,条件分布是通过观测到的因变量加权估计得到的,其中每个观测值的权重等于RF算法的权重[23]。
由此,QRF定义E(1{Y≤y}|X)的估计为观测值1{Y≤y}的加权平均,即:
(10)
QRF算法的具体步骤如下。
a. 生成KT棵决策树T(θt)(t=1,2,…,KT),考察每棵决策树每个叶节点的所有观测值。
b. 给定X,遍历所有决策树。计算每棵决策树观测值的权重wi(X,θt)(i=1,2,…,M;t=1,2,…,KT)。通过对决策树权重wi(X,θt)取平均得到每个观测值的权重wi(X)。
c. 对于所有y∈R,利用步骤b得出的权重,通过式(10)计算分布函数的估计。
对于每棵决策树的每个节点,RF回归只保留了观测值的均值而忽略了其他信息,而QRF保留了节点中所有观测值,并在此基础上计算条件分布。
2.3 基于条件分布的概率密度预测
采用核密度估计方法从条件分布中获得概率密度预测结果。核密度估计是通过一组观测的来自同一未知分布函数的随机变量来估计其密度函数的非参数计算方法。设X1、X2、…、XM是取自一元连续总体的样本,在任意点x处的总体密度函数f(x)的核密度估计定义为[24]:
(11)
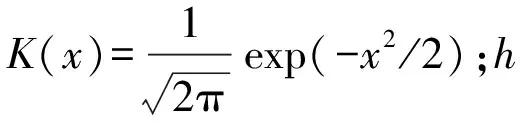
3 基于EWT-QRF的风电功率概率密度预测
针对一般风电功率点预测方法难以完全表征功率变化不确定性的缺点,本文建立了基于EWT-QRF的短期风电功率概率密度预测模型,可以获得任意时刻风电功率的波动范围及概率密度输出。图2为本文短期风电功率概率密度预测流程图。首先,采用EWT信号处理技术对原始风电功率序列进行预处理,将其自适应分解为若干频率互异的经验模式。通过EWT分解可以细致把握不同分量的变化规律并针对性地建立预测模型,从而有效地提高风电功率预测精度。为了减少建模任务量,将频率大小相近的经验模式合并为新的分量。然后,对新的分量选取输入变量集合并建立QRF预测模型,得到不同分位点下的风电功率预测结果,将不同分量预测结果叠加获得预测值的条件分布。最后,采用核密度估计方法输出风电功率概率密度预测。
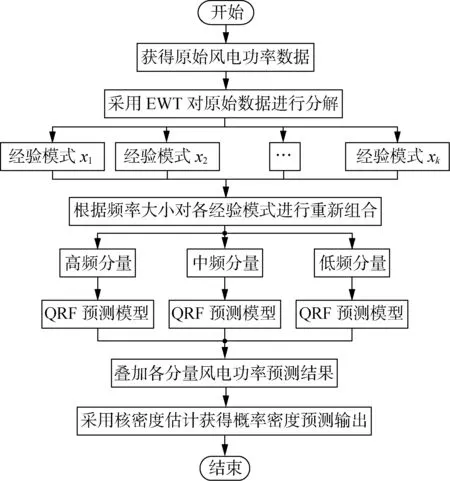
图2 短期风电功率概率密度预测流程图Fig.2 Flowchat of short-term wind power probability density forecasting
3.1 风电功率分解结果
采用江苏省某一风电场实测风电功率数据作为研究对象,验证所提模型的预测性能。该风电场内风机总数为33台,装机容量为49.5 MW。已知数据采样时间间隔为30 min,原始风电功率序列为2008年8月13日至8月22日共480个点的风功率数据。采用EWT方法对原始风电功率序列进行分解,结果如图3所示。从图3中可以看出,EWT将原始风电功率分解为11个经验模式,各个模式的频率特征较为明显。按照频率大小将经验模式分为3类:低频、中频和高频,然后将类中的经验模式进行合并,分别重构为低频分量、中频分量和高频分量,如图4所示。对各分量分别建立QRF预测模型,从而降低建模工作量、提高效率。
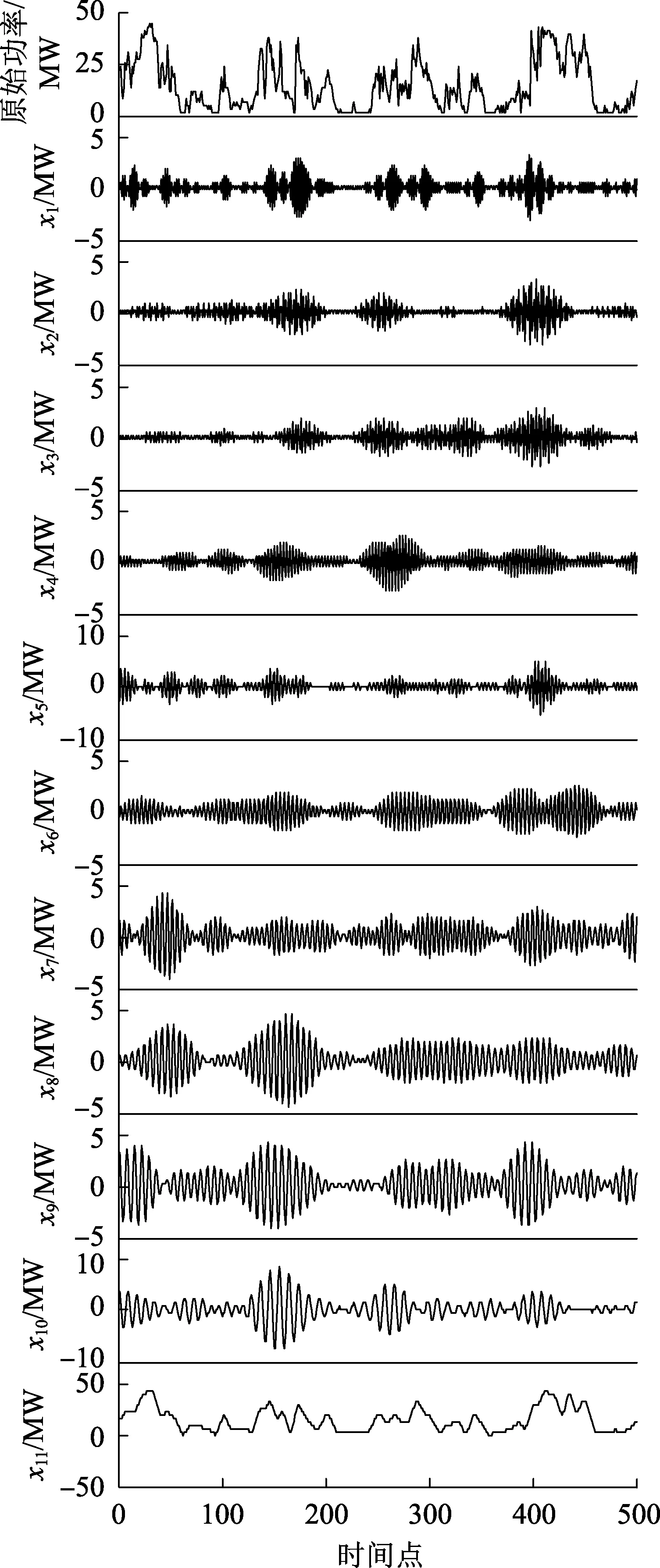
图3 原始风电功率序列及EWT分解结果Fig.3 Original wind power sequence and EWT decomposition results

图4 经验模式重构结果Fig.4 Empirical mode reconstruction results
为了说明EWT用于风电功率预测的有效性,同时将EMD方法用于功率数据的分解,并对比预测结果。EMD结果及重构分量分别见图5、图6。

图5 原始风电功率序列及EMD结果Fig.5 Original wind power sequence and EMD results
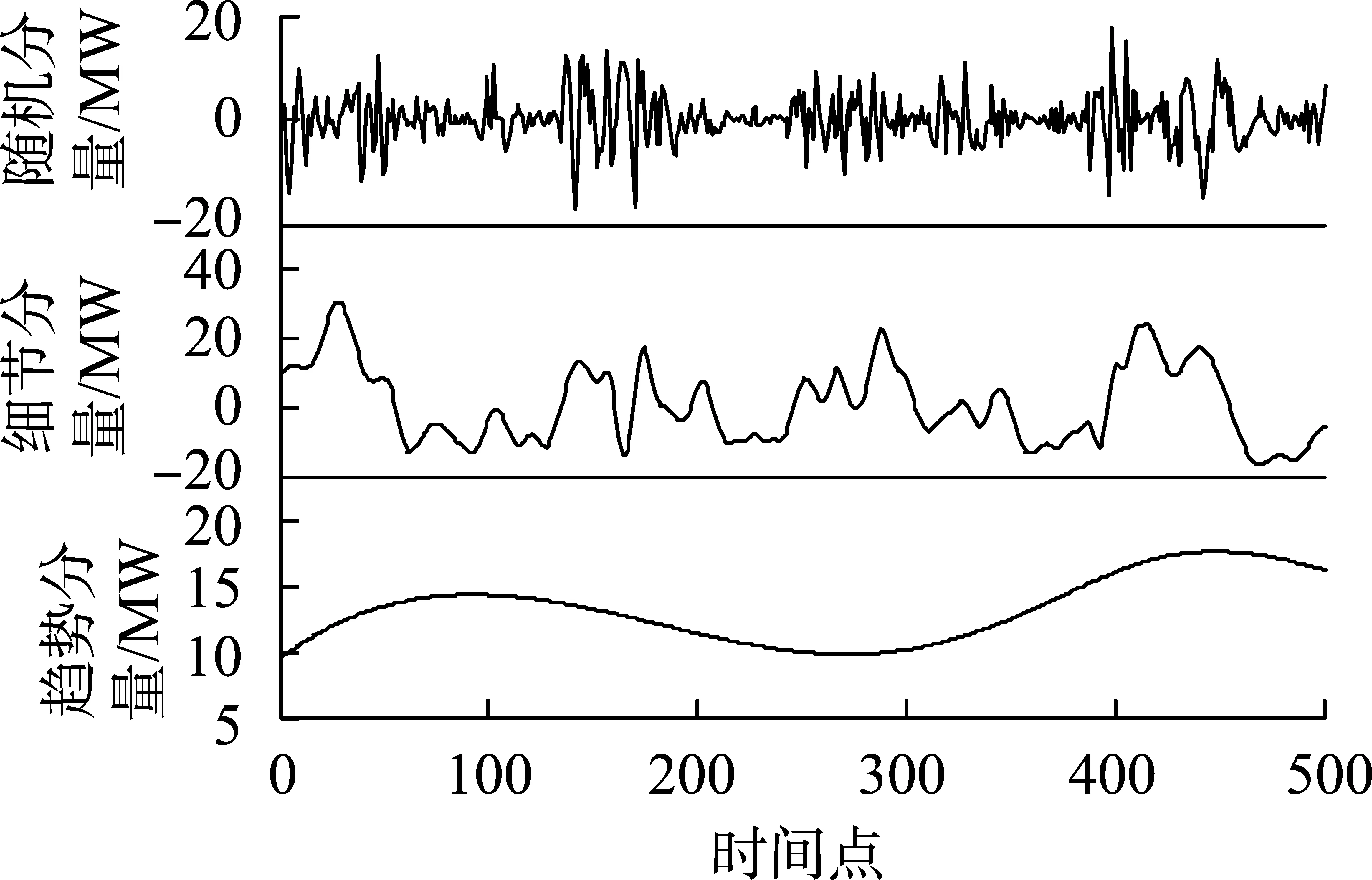
图6 EMD重构分量Fig.6 Reconstruction components of EMD
3.2 输入变量选择
输入变量的选取对模型预测性能有直接影响,采用皮尔森相关系数定量评价变量间的相关性,并从待预测时刻的前10个时刻中选取相关性较大的输入变量集合。给定时间序列,皮尔森相关系数衡量了xt与xt-τ间的相关关系[25]。其中,τ为滞后阶数。皮尔森相关系数r的取值范围为[-1,1],1表示完全正相关,-1表示完全负相关,0表示变量间无相关性。当|r|>0.3时,即认为变量间存在较强的相关关系。待预测时刻风电功率与滞后τ阶功率间的相关系数计算公式为:
(12)
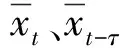
分别对EWT和EMD的分量选取输入变量集合,结果如表1和表2所示。

表1 EWT分量输入变量选择结果Table 1 Selection results of input variables for EWT method

表2 EMD分量输入变量选择结果Table 2 Selection results of input variables for EMD method
3.3 评价指标
采用平均绝对百分比误差(MAPE)和均方根误差(RMSE)作为确定性点预测模型效果评价指标。
(13)
(14)

可靠性和清晰度是风电功率概率区间预测模型的2个重要评价准则[26]。可靠性为实际观测值落入预测区间的概率,此值越大,表明预测结果更准确;清晰度用预测区间宽度表征,预测区间宽度越窄,表明模型预测性能越好。高可靠性及尽可能小的区间宽度是风电功率概率预测追求的目标,但实际上两者是矛盾的。引入预测区间覆盖率(FICP)指标计算预测区间可靠性,计算公式为:
(15)
其中,ξ在给定置信水平1-α条件下的取值为0和1,若实际值落于预测区间上下限范围内,则ξ(1-α)=1,否则ξ(1-α)=0。
引入预测区间平均宽度(FIAW)指标计算模型清晰度,计算公式为:
(16)
其中,ui为第i个预测点置信区间上限;li为第i个预测点置信区间下限。
4 算例分析
以2008年8月13日至8月22日共480个点的风功率数据为训练数据,对8月23日48个实测风电功率进行提前30 min预测。本文中EWT分解、QRF算法及BP神经网络、SVM算法均在MATLAB R2014a编程平台实现,CPU主频为3.3 GHz,RAM为4 GB。
a. 直接对原始功率数据进行预测。QRF参数设置如下:决策树数目为500,节点最小尺寸为5,每棵决策树从输入变量集合中随机选取mtry=2D/3个变量进行权重学习,D参照表1选取。为了获得条件分布,设置分位点范围为0.01~0.99,步长为0.01,对每个预测点即可获得99个预测结果。同时,建立BP神经网络、SVM算法的对比模型。BP神经网络的学习率为0.001,学习目标为0.01,迭代10 000次,模型结构参数经多次试验比较后设置为:9-15-1(输入层变量个数为9,隐含层神经元个数为15,输出层神经元个数为1)。SVM模型的学习参数C和ε通过网格搜索法优化选取,参数范围为[-8,8],迭代步长为1。图7为原始功率曲线及BP神经网络、SVM和QRF模型的预测结果,QRF模型取0.5分位点条件下的预测值。不同模型风电功率预测结果统计如表3所示。从图7、表3可以看出,采用单一预测模型时,预测值落后于真实值的变化趋势,存在滞后,有较大的预测误差。

图7 原始功率曲线及提前30 min预测结果Fig.7 Original wind power curve and forecasting results ahead 30 minutes

预测模型MAPE/%RMSE/MW运行时间/sBP神经网络27.445.167SVM27.275.1232QRF26.814.9015EMD-BP16.142.5037EMD-SVM13.772.22121EMD-QRF13.822.4369EWT-BP12.111.8248EWT-SVM11.901.79136EWT-QRF10.771.7174
b. 分别采用EMD和EWT方法对原始功率数据进行分解处理,然后对每个分量分别建立预测模型,结果如图7、表3所示。从图7及表3可以看出组合模型有效地缓解了滞后效应。此外,EWT方法的性能表现优于EMD方法,相较于EMD-BP、EMD-SVM、EMD-QRF模型,EWT-BP、EWT-SVM和EWT-QRF模型的MAPE指标分别降低了24.97%、13.58%和22.07%,RMSE指标分别降低了27.20%、19.37%和29.63%。其中,EMD-BP模型随机分量、细节分量和趋势分量的结构参数分别为4-11-1、8-16-1以及10-17-1;EWT-BP模型高频分量、中频分量和低频分量结构参数分别为5-9-1、7-15-1和10-15-1;SVM和QRF参数设置同步骤a。
图8为70%、80%、90%、95%置信水平下功率区间预测结果。由图8知,EWT-QRF模型的区间宽度更窄,优势明显,从而更有利于科学决策。
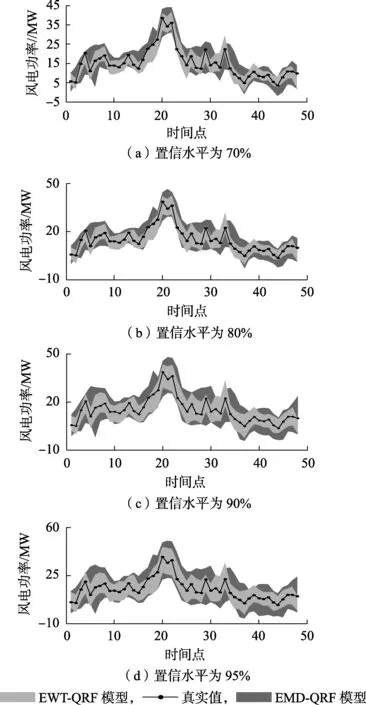
图8 不同置信水平下功率区间概率预测结果Fig.8 Probability forecasting results of power interval under different confidence levels
图9为不同置信水平下的FICP、FIAW指标变化曲线。由图9可看出,虽然QRF模型比EMD-QRF模型有更窄的区间宽度,但由于QRF模型的滞后性,导致其可靠性较差,较难反映风电功率真实值;EWT-QRF模型有最窄的区间宽度,在40%~90%置信区间范围内,其与EMD-QRF模型间的FIAW差值逐渐增大,导致EWT-QRF模型的FICP指标较差,这符合FIAW、FICP指标相互矛盾的规律。
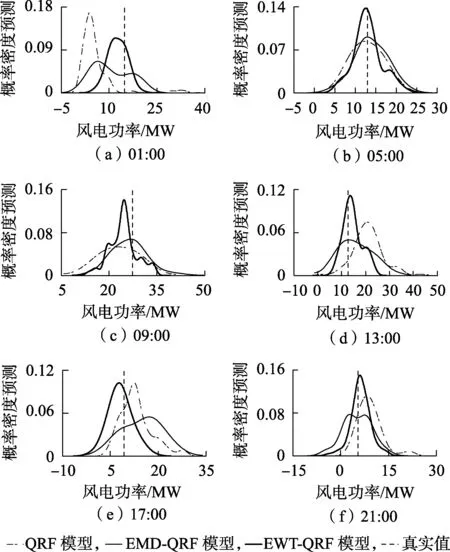
图10 不同时刻风电功率的概率密度预测Fig.10 Probability density forecasting of wind power at different moments
对QRF、EMD-QRF和EWT-QRF模型获得的条件分布采用核密度估计可给出任意时刻风电功率概率密度预测,取一天中不同时刻预测结果见图10。可以看出,EWT-QRF模型以较高的概率接近真实值,概率密度曲线更瘦高,波动范围更集中,有利于在更窄范围内做出可靠决策。
5 结论
针对一般风电功率点预测方法输出结果单一的缺点,本文建立了基于EWT-QRF的概率密度组合预测模型。
a. 采用EWT这一新型自适应信号处理方法对原始风电功率序列进行分解处理,将其分解为多个频率特征互异的经验模式。相较于EMD方法,EWT分解的分量更具有解释意义。所建立的EWT-QRF预测模型相较于EMD-QRF模型具有更好的预测精度,MAPE指标降低了22.07%,RMSE指标降低了29.63%;同一置信水平下,EWT-QRF模型的区间宽度更窄,更有利于做出科学决策。
b. QRF能够给出任意分位点下的预测结果,从而获得预测值的条件分布。作为一种非参数估计方法,其具有受模型参数影响小、鲁棒性强、计算量较少的优点,适用于短期风电功率概率密度预测。
概率区间的可靠性和清晰度是相互矛盾的评价指标,不可能有同时获得高可靠性和高清晰度的预测模型。下一步将研究评价指标优化模型,使得概率区间输出在具有较好可靠性的条件下,具有更窄的区间宽度。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
数学年刊A辑(中文版)(2021年4期)2021-02-12
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
数学学习与研究(2020年15期)2020-11-28
中学生数理化·中考版(2018年12期)2019-01-31
数学年刊A辑(中文版)(2015年1期)2015-10-30
河北建筑工程学院学报(2015年2期)2015-04-29
振动工程学报(2015年2期)2015-03-01
航天返回与遥感(2014年4期)2014-07-31
