
应用Empower Stats软件快速实现病例对照研究的个体匹配
2018-07-16 10:08刘文慧薛付忠穆玉兰
中国卫生统计 2018年3期
刘文慧 薛付忠 穆玉兰
病例对照研究(case-control study)是流行病学方法中最基本、最重要的研究类型之一[1],可用于发病危险因素的研究,也可用于临床回顾性治疗与探索预后因素的研究等[2]。其主要研究类型主要分为病例对照不匹配和病例对照匹配[3-5],前者只需对照数目等于或多于病例人数,而后者在目前的软件实现比较复杂,尤其是匹配因素较多,对照匹配比例较高(如1:2以上)时,很多医学工作者无从下手。为此,本文介绍通过Empower Stats软件快速实现病例对照研究的个体匹配。
Empower Stats软件当前最新版本的创建日期为2017年2月15日,可以从官方网站http://r.empowerstats.cn/cn/index.html下载获取。
举 例
某女性卵巢衰老问卷调查,内容包括编号(ID)、民族(race)、教育程度(edu)、年龄(age)、职业(occupation)、体质指数(BMI,body mass index)、抽烟史(smoking history)、饮酒史(drinking history)、母亲绝经年龄(mother’s menopause age)、是否卵巢早衰(SOF,premature ovarian failure)(表1)等项目。其中SOF项表示卵巢早衰(1:是,0:否)。现计划对发生卵巢早衰的研究对象采用1:1配比的病例对照研究方法,研究卵巢早衰发生的影响因素。匹配的原则是民族相同、教育程度相同、年龄差别2岁。

表1 某女性卵巢衰老调查问卷结果
步骤:
1.打开软件,点击“开始运行”。
2.“分析项目”——“创建新项目”——“浏览”导入要分析的数据文件。软件支持.Rdata,.xls,.csv,.txt,.sav,.dat,.sas7bdat等多种数据格式,本例采用.csv格式。
3.选择分析结果存放目录、修改“项目名称”,添加“项目描述”(可采用自动生成结果)。
4.“读取数据文件”,软件后台调用相关R程序,生成简单的数据分布情况。
5.“数据操作”——“数据记录”——“病例对照配对”,设置分组变量,配对变量、配对条件与匹配数、研究对象编号。race、edu差异范围缺失表示完全匹配,age差异范围2表示age相差2岁以内可以配对。
6.“查看结果”。
结 果
运行后,软件自动弹出结果页面,并在分析结果存放目录生成相应的网页(PROJ1_1_tbl.htm)、日志(PROJ1_1_tbl.log)、R程序(PROJ1_1_tbl.R)及2个匹配结果文件(PROJ1_1_tbl_SOF_match_cc.xls、PROJ1_1_tbl_SOF_match_dd.xls)。
其中自动弹出结果页面与PROJ1_1_tbl.htm一致,列出了分析数据中无法找到配对的病例编号。可以看出有18个病例没有找到对照,这18个病例的编号(ID)为25,26,31,…,196。
结果文件PROJ1_1_tbl_SOF_match_cc.xls横向展示了匹配结果(表2),每行是一个病例。group.id是配对组编号,group.n表示配对组内人数,ID.case、ID.cntl分别表示病例、对照在原始数据文件中的编号。NA表示未找到合适匹配对象。
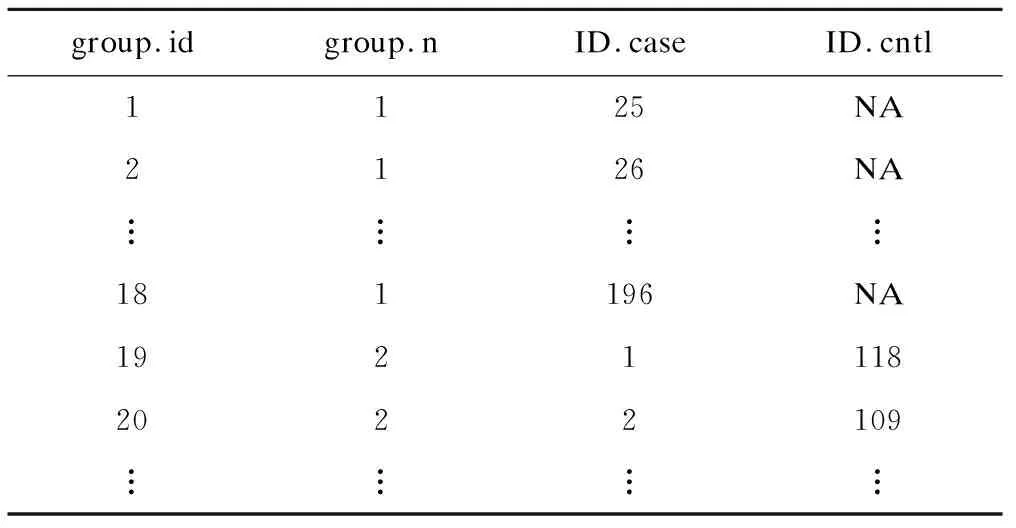
表2 匹配结果PROJ1_1_tbl_SOF_match_cc.xls
从表2可以看出18个配对组没有对照(group.id=1,2,…,18),其组内人数均为1(group.n=1),在原始数据中的编号为25,26,…,196。而配对组group.id=19 ,group.n=2,ID.case=1,ID.cntl=118表示配对组19的组内有2个研究对象,其中病例在原数据中的编号是1,对照在原数据表中的编号是118。
结果文件PROJ1_1_tbl_SOF_match_dd.xls则是另一种格式(表3)。此表每行是一个研究对象。group.id、group.n与表2中含义相同,分别表示配对组编号及配对组内的人数。ID表示在原始数据表中的编号。匹配成功的病例和对照排在临近的两行,如group.id=19有两行,一行id=1,SOF=1,另一行id=118,SOF=0,表示原始数据中编号是1的病例匹配到了对照组,其编号是118。表格的右侧是原始数据表的其他变量即相应的问卷调查结果,便于进行下一步的数据统计分析。

表3 PROJ1_1_tbl_SOF_match_dd.xls
讨 论
Empower Stats是一款基于R软件进行流行病学分析的“傻瓜”软件,不必具有编程基础,就能运用R程序进行数据管理、处理和分析。具有编程基础的则可以通过软件生成的R文件进行更加合适、个性化的修改。由于其功能强大而操作简单,该软件已逐步受到医学科研工作者的青睐[6-7]。
本文的重点是利用该软件快速实现病例对照的1:1匹配,相较于公开发表的文献报道中用Excel VBA、C#语言编程方式实现病例对照个体匹配[8-9]的方法而言,更加的简单,尤其是对于没有编程基础的科研工作者。本文中匹配变量为民族、教育程度和年龄,假如读者的研究方法与本研究不同,如匹配的变量不同,只需在设置匹配条件界面“用于配对的变量”中选择自己所需的匹配变量即可。如匹配比例不同(假设为1:2),则只需在相应界面“1:n配对(n=)”处输入数字2即可。
此外,Empower Stats软件还可以实现近年来新兴的倾向得分匹配(PSM,propensity score matching)[10],该方法被广泛应用于临床试验、流行病学病因研究以及大部分观察性试验研究和设计中[11-12],用于降低由于混杂因素导致的选择性偏倚,从而保证组间基线数据的均衡可比。其操作也非常方便,只需在界面勾选“计算倾向性评分再按评分配对”,并设定倾向性评分配对的病例对照相差范围即可。
需要注意的是,Empower Stats软件是一款收费软件,安装成功并注册后可获得一个月的试用期,期间可以使用软件的高级模块(病例对照匹配、广义估计方程多应变量回归、随机(混合)效应模型meta分析等),否则只能使用基本模块(T检验、方差分析、直线相关与回归、生存分析等)。若通过电子邮件向好友推荐可延长试用期。此外,由于该软件是基于R软件来进行数据分析的,因此在安装该软件时会自动安装R软件。因为其对于数据处理分析全面、功能强大且操作简单,相信其在医学科研中的应用前景会更加广泛。
猜你喜欢
中老年保健(2021年11期)2021-11-30
电脑爱好者(2021年12期)2021-06-22
物联网技术(2020年12期)2021-01-27
中国生殖健康(2020年8期)2021-01-18
中国临床医学影像杂志(2019年5期)2019-08-27
中国生殖健康(2018年1期)2018-11-06
汽车零部件(2017年4期)2017-07-12
中国石油石化(2013年5期)2013-05-03
演艺科技(2013年1期)2013-01-30
计算机应用文摘·触控(2009年15期)2009-09-27
