
基于不同核函数构建的退行性颈椎病支持向量机高危人群筛查模型的比较*
2018-07-16 10:06:58吕艳伟李文桓陈大方段芳芳王立芳刘志科
中国卫生统计 2018年3期
吕艳伟 李文桓 田 伟 陈大方 段芳芳 王立芳 刘志科
【提 要】 目的 评价基于不同核函数构建的退行性颈椎病支持向量机高危人群筛查模型的优劣,为退行性颈椎疾病高危人群的筛查提供工具支持。方法 利用北京地区社区人群骨科退行性疾病研究数据库,采用线性核、多项式核、Sigmoid核和高斯核函数构建支持向量机模型,并根据十折交叉验证率最大的标准确定核函数参数。根据约登指数最大化的标准选择切点值,计算模型相应的灵敏度、特异度和预测准确率。采用ROC曲线评价不同核函数构建的模型的性能。结果 在四种核函数计算的支持向量机模型中,多项式核函数计算ROC曲线下面积最大,为0.6928(95%CI:0.6502~0.7355),但不同核函数的ROC曲线下面积的95%CI存在重叠,尚未发现不同核函数建立本模型的优势。结论 可利用该模型进行高危人群筛查,但未发现不同核函数构建的支持向量机模型性能的差别。
退行性颈椎病是颈椎间盘组织退行性改变及其继发病理改变累及周围组织结构(神经根、脊髓、颈动脉、交感神经等),出现相应的临床表现[1]。退行性颈椎病患病率高[2-4]。颈痛是退行性颈椎病的常见症状,48.5%的人在一生中经历颈痛,使用屏幕等工作者的颈痛的年患病率高达55%[5-6]。退行性颈椎病的疼痛麻木等临床症状与患者抑郁和失眠相关,影响患者的生活质量[7-9]。根据全球疾病负担2013的研究报告,在全球188个国家301种疾病和损伤中,颈痛是十大影响疾病负担的疾病之一,全球顺位第四,在我国顺位第二[10]。随着老龄社会的到来,退行性颈椎疾病导致的疾病负担可能进一步增加。由于颈椎重要的解剖位置,退行性颈椎病不但影响生活质量,降低社会劳动力,甚至威胁生命。从患病率和疾病负担两个指标衡量,退行性颈椎病是需要干预的慢性非传染性疾病之一。高危人群策略是一种节省成本,效率比较高的健康保护策略[11]。筛选高危人群是实施高危人群策略的关键。通过筛选疾病的危险因素,建立疾病的发病风险预测模型,定量计算其发病风险值,精确筛选高危人群是值得推荐的方法。目前尚无退行性颈椎疾病的高危人群筛查方法。支持向量机(support vector machine,SVM)是一种新型的机器学习算法[12-13]。SVM是一种新的模式识别方法,对解决非线性、小样本及维度困扰等问题具有独特的优势。但不同核函数影响到该模型的分类性能[14]。本研究旨在利用基于社区人群的数据,比较基于不同核函数构建的退行性颈椎病支持向量机高危人群筛查模型的优劣,为退行性颈椎疾病高危人群的筛查提供工具支持。
原理与方法
1.SVM的原理
其基本原理是将输入向量通过核函数定义的非线性特征影射,将其映射到具有更高维特征的空间,从而实现线性可分,然后在新的高维特征空间中构造最优分类超平面。最优分类平面不仅要保证将两类样本错分个数最少,还要求分类间隔最大[15]。最终实现对样本的分类决策。SVM的优化准则为最大化类间边际(margin,即围绕决策面的区域,由训练集样本与决策面间的最小距离确定)。通过最大化边际可使支持向量个数最小化。由支持向量决定分类决策函数。理论和实验结果表明SVM学习算法可以产生大边际分类器并有较好的泛化性能。当传统统计方法效果不佳或不能达到目的时,应用SVM建模分析往往能获得良好效果。SVM 的分类决策函数为[16]:
其中K(·)为核函数,x为待分类样本,训练样本集为(xi,yi),i=1,…,n,n为训练样本个数,xi∈Rd为训练样本,yi∈{+1,-1}是样本xi的类标记,SV为支持向量集,是训练样本集的一个子集。参数αi≥0通过训练(解优化问题)得到。
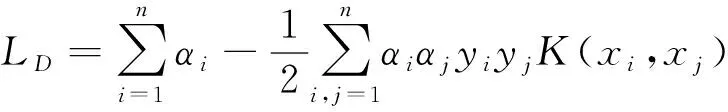
其中:C≥αi≥0
类间交迭由惩罚权C>0控制,C=0则不允许交迭。C为某个指定的常数,它实际上起控制对错分样本惩罚程度的作用,实现在错分样本的比例与算法复杂度的折中。b是分类的阈值,可由下式求得:
yi(w·xi+b)-1≥0,i=1,…,n
2.常用核函数的算法
(1)线性核函数:K(x,xi)=(x·xi)
(2)多项式核函数:K(x,xi)=[(x·xi)]q
(3)Sigmoid核函数:K(x,xi)=tanh(v(x·xi)+c)
(4)高斯核函数:K(x,xi)=exp{-(x-xi)2/σ2}
3.十折交叉验证法
将训练数据集分成k份相等的子集,每次将其中k-1份数据作为训练数据,而将另外一份数据作为测试数据。这样重复k次,根据k次迭代后得到的MSE平均值来估计期望泛化误差,最后选择一组最优的参数。留一法是k-交叉验证的特例,即每次用n-1个数据(n为训练数据集大小)训练,而用另一个数据测试。
4.模型构建与评价
本研究的数据分为训练集和测试集两个部分:设置种子数,从总体数据中随机抽取70%的数据形成训练集,用于模型的构建;剩余的30%形成测试集,用于模型的评价。建模分析软件选用的是R软件,其中支持向量机算法采用的为R软件中的e1071工具包。不同核函数的模型最优参数根据十折交叉验证率最大的标准进行确定。基于测试集对建立的模型进行ROC评价,根据约登指数最大化的标准选择切点值,计算模型相应的灵敏度、特异度和预测准确率。
对 象
本研究的对象来源于2010年北京地区社区人群骨科退行性疾病研究数据库,共包含3859例研究对象,其中,退行性颈椎疾病患者531例(13.76%)。退行性颈椎疾病的诊断采用文献[1]中的诊断标准。本研究中的危险因素为经logistic回归模型筛选的因素,赋值参见表1。

表1 变量赋值表
结 果
1.采用高斯核进行建模结果与评价
采用高斯核函数构建SVM时,不同参数对应的十折交叉验证率见表2。根据十折交叉验证率的结果,采用高斯核函数构建SVM的最优参数:gamma=1/50,惩罚系数C为50。
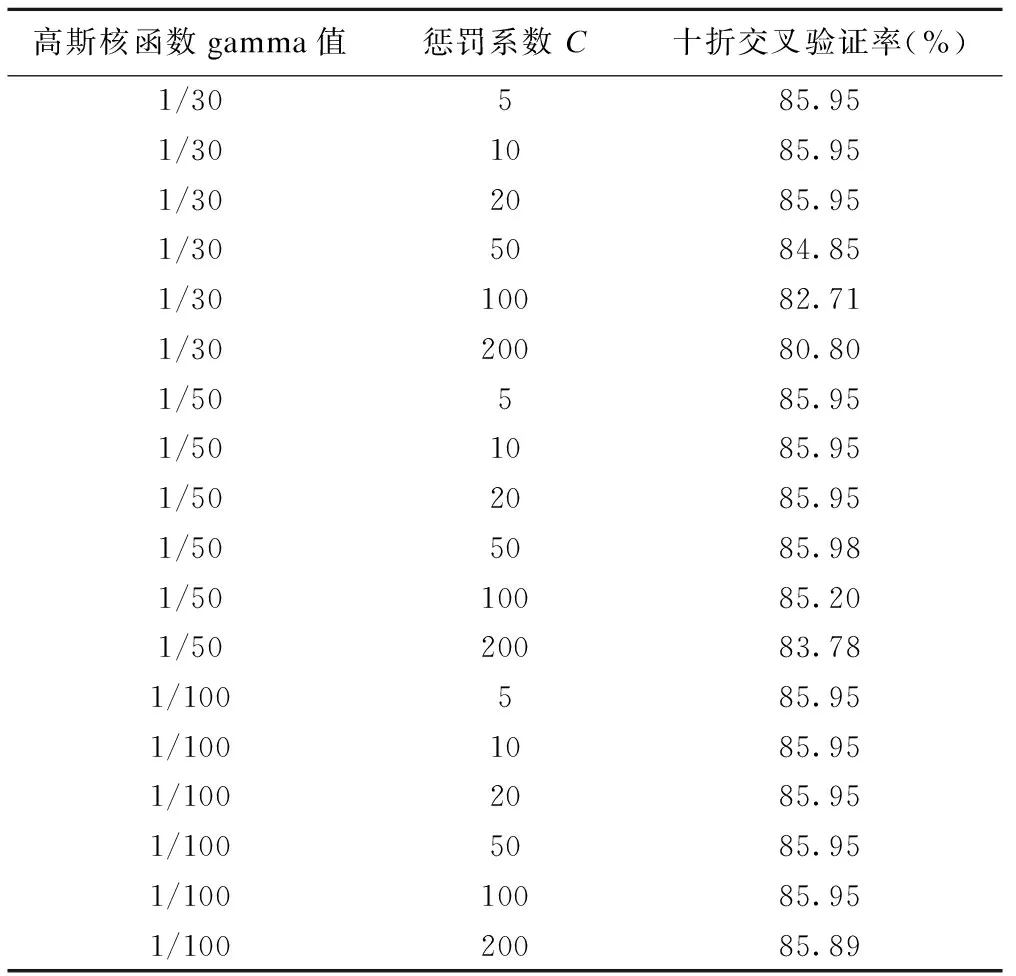
表2 不同参数的高斯核SVM总体人群十折交叉结果
2.采用线性核函数进行建模
根据线性核函数的不同参数预测准确性的结果(表3),线性核SVM的最优参数为惩罚系数C为0.1,据此建立线性核函数SVM模型。

表3 线性核函数不同参数构建SVM模型的预测准确性
3.采用多项式核函数进行建模
根据不同参数多项式核函数构建的SVM模型的十折交叉准确率,另考虑到参数degree越大,C越大,越容易出现过拟合的情况,多项式核函数的最佳参数为gamma=1/30,d=2,C=5。
4.采用Sigmoid核进行建模与评价
根据不同参数Sigmoid核构建的SVM模型十折交叉验证率,Sigmoid核函数的最佳参数为gamma=1/100,C=5。
5.不同核函数模型的比较
从ROC曲线下面积AUC考虑,在四种核函数计算的SVM模型中,多项式核函数计算出的模型最优(图1),AUC为0.6928(95%CI:0.6502~0.7355),预测准确率为57.64%(表4)。但是不同核函数的ROC曲线下AUC 95%CI存在重叠,尚未发现不同核函数建立本模型的优势。
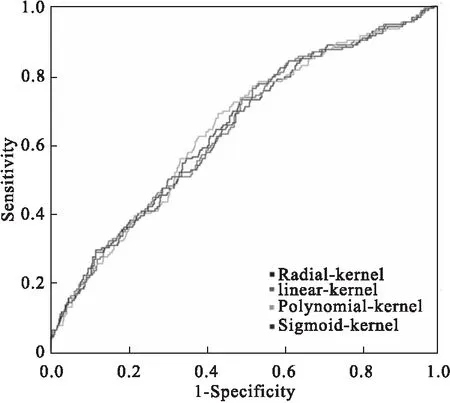
图1 4种核函数构建的SVM模型ROC曲线

指标AUCAUC 95%CI灵敏度(%)特异度(%)预测准确率(%)高斯核0.67460.6284~0.720867.1061.2462.12线性核0.69000.6473~0.732765.8167.0966.89多项式核0.69280.6502~0.735577.4254.1357.64Sigmoid核0.68780.6452~0.730564.5265.3765.23
讨 论
基于队列研究设计在区分危险因素与患病结局之间的因果先后顺序的优点,大部分的疾病风险预测模型是基于队列资料建立的。队列研究设计可以有效地建立疾病的发病预测模型。诸如糖尿病模型、Framingham的心血管疾病预测模型等[17-18]。目前尚无关于退行性颈椎疾病的发病风险预测模型。本研究的主要目的之一是筛选退行性颈椎疾病的高危人群,并能够定量评估其风险值。本研究建立的风险预测模型不是判断研究对象是否患有退行性颈椎疾病,而是主要用于退行性颈椎疾病高危人群的筛查。其首要目的是在大规模人群中简便地找出未被诊断但高危的退行性颈椎疾病人群,建议其改变不良的生活行为特征,从而达到延缓或减少退行性颈椎疾病发生的目的。根据Kazemi-Naeini M等利用横断面研究设计,预测糖尿病患者周围神经病变的SVM模型,其预测准确率达到76%[19]。该研究结果表明,在目前尚无其他退行性颈椎疾病高危人群筛查模型的情况下,利用该模型进行高危人群筛查是可以接受的。
SVM由Vapnik等在1992年推出后,受到了广泛的关注并得到了全面深入的发展。SVM已成为机器学习和数据挖掘领域的标准工具。SVM集成了最大间隔超平面、Mercer核、凸二次优化、稀疏解和松弛变量等多项技术,主要用于模式分类和回归估计。SVM核心是结构风险最小化。它根据有限的样本信息在机器的学习能力和复杂性之间寻求最佳折中。与传统的神经网络学习算法相比,SVM克服了局部极小和维数灾难等问题,泛化能力明显提高[20]。SVM是一种在特征空间实施线性判决的学习算法,且其特征空间由核函数隐式定义。从理论层面考虑,核函数有很大的选择空间。但在实际操作层面,如何选择合适的核函数存在困难[21]。一般通用核函数,诸如Gaussian核函数、线性核函数等可以解决一部分问题。对于SVM模型,核函数的构造非常重要,而核函数中参数的确定亦非常关键。对于同一个核函数,参数不同,其性能差别可能很大[22]。核函数参数选取方法主要有:经验选择法、实验试凑法、梯度下降法、交叉验证法、Bayesian 法等[14]。在本研究中,采用的是交叉验证技术。本技术的基本思想是通过测试非训练样本在固定参数值上的分类错误率,通过持续地修正参数,达到测试错误率最小的目的[23]。本方法在参数选择上采用遍历所有参数的方法,即在参数空间无穷尽搜索,测试每一组可能的参数组合,测试SVM模型,进而找到效果最好的参数组合[21]。采用交叉验证法进行核函数参数的确定,其计算量非常大。另外,当参数超过两个时,将难于实现。此时可以考虑留一法进行参数的计算和确定[24-25]。
在本研究中,阳性样本退行性颈椎疾病患者为531例,占总样本的13.76%;阴性样本非退行性颈椎疾病例数为3328例,占84.24%。阳性样本与阴性样本的比例约1∶6,存在类间分配不平衡的问题。这可能是造成模型预测准确率较低、AUC较小的原因。在支持向量机建模中,可采用SMOTE算法处理此问题[19]。根据Sun T等一项队列研究的结果,采用SMOTE进行数据构建早期肺癌SVM预测模型,其ROC曲线下面积为0.949(P<0.001),预测性能良好[26]。SMOTE法按照一定的规则生成了新的样本,引入了新的信息,同时结合欠抽样,随机减少多数类的样本,避免了随机过抽样的局限性,在一定程度上避免了过学习的问题[27]。在后续的研究中将结合SMOTE算法进一步进行SVM模型的构建。
猜你喜欢
大自然探索(2024年1期)2024-02-29 09:11:26
保健医苑(2022年1期)2022-08-30 08:40:00
保健医苑(2022年6期)2022-07-08 01:25:34
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国生殖健康(2019年10期)2019-01-07 01:21:20
老年医学与保健(2017年6期)2017-02-06 05:30:03
中华肩肘外科电子杂志(2017年1期)2017-01-11 03:27:59
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
中外医疗(2015年5期)2016-01-04 03:57:57
