
序贯安慰剂平行对照设计和双向富集设计的样本量估计*
2018-07-16 12:23:14柏建岭陈梦锴魏永越蔡晶晶
中国卫生统计 2018年3期
秦 飞 柏建岭△ 陈梦锴 陈 峰,2 魏永越 赵 杨,2 蔡晶晶 刘 晋 于 浩△
【提 要】 目的 探讨临床试验中序贯安慰剂平行对照设计和双向富集设计的样本量计算方法。方法 在不同参数设置条件下,计算序贯安慰剂平行对照设计和双向富集设计所需要的样本量,并与传统的平行组设计、交叉设计等进行比较。结果 序贯安慰剂平行对照设计和双向富集设计相比于传统的平行组设计、交叉设计需要的样本量更少,其中,双向富集设计的优势更为明显。对于连续性结局变量,第二阶段的疗效越大,第一阶段的权重越小,需要的样本量越小。对于二分类结局变量,得分检验参数取9.8和6.2时,SPCD和TED分别需要的样本量最少。假定两阶段疗效相同时,第一阶段分配到安慰剂组的比例取0.57和0.50时,SPCD和TED需要的样本量最少。结论 在安慰剂效应较高或是没有彻底治愈方案的慢性疾病试验中,序贯安慰剂平行对照设计和双向富集设计相比于传统设计有很大的优势。
在精神类药物的临床试验中,一个很普遍的问题就是高安慰剂效应[1-2]。为解决这一问题,有人提出在试验中加入了一个安慰剂导入期(run-in phase),导入期内所有受试者均接受安慰剂的治疗。然后将安慰剂无效者进行随机分组,分别接受试验药和安慰剂,从而有效地排除了安慰剂效应。然而,Trivedi等人[3]在meta分析中综合了101项研究结果之后得出结论,并没有直接证据表明安慰剂导入期有助于检验试验药的疗效。考虑原因是研究者和受试者在该类试验中很难再维持盲态,从而对研究结果产生了很大的干扰。后续也有人提出了随机撤药试验(randomized withdrawal design)的概念[4],试验初,所有受试者都接受试验药的治疗,从而把对试验药易感的群体提前筛选出来。当单纯使用安慰剂对照试验存在伦理问题时,使用随机撤药试验更容易被接受。但其估计的疗效一般是有偏的,由于滞后效应的存在可能会高估第二阶段安慰剂的效应,同时随机分组的群体只是全部受试者的一个子集,因而缺乏代表性[5]。
考虑到以上两种方法的弊端,序贯安慰剂平行对照设计(sequential parallel comparison design,SPCD)在2003年被正式提出[1]。SPCD在第一阶段对所有受试者都会进行随机分组,只有安慰剂无应答者会进入第二阶段,再次进行随机分组。后来又有人在此基础上提出了双向富集设计(two-way enriched design,TED)[6],不同于前者,第一阶段中的试验组有效者也会进入第二阶段,并进行随机分组。在这两种设计中,我们会综合第一阶段和第二阶段的疗效差值,并结合权重进行评价,从而得出更为可靠的结论。
目前,针对序贯安慰剂平行对照设计和双向富集设计中样本量估计问题的探讨还很有限,因而本文的主要目的就是将这两种设计与我们临床试验中传统的几种设计在样本量估计方面进行比较,为今后临床试验设定样本量提供参考意见。
原理及方法
1.序贯安慰剂平行对照设计概述
筛选合格的受试者在第一阶段随机分成试验药组和安慰剂组,安慰剂组占总受试者的比例会事先确定。第一阶段的安慰剂无应答者进入第二阶段,并再次随机分为试验药组和安慰剂组(图1)。实际试验中,为了维持盲态,第一阶段安慰剂有效组和试验药组还是会进入第二阶段,分别服用安慰剂和试验药,其结果不会纳入最终分析。计算药物疗效时会拿第一阶段的疗效加权第一阶段安慰剂无效者在第二阶段的表现,综合分析得出结论。
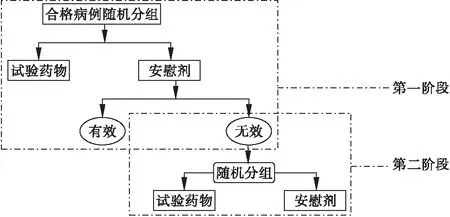
图1 序贯安慰剂平行对照设计流程图
2.双向富集设计概述
不同于序贯安慰剂平行对照设计,双向富集设计会有两个子集进入第二阶段,第一阶段的安慰剂无效者和试验药有效者均被随机分为试验药组和安慰剂组(图2)。此时再进行分析时,就是把三个亚组的疗效加权进行分析。同样,第一阶段安慰剂有效组和第一阶段试验药无效组还是会在第二阶段进行服药,只是结果不会纳入最终分析。

图2 双向富集设计流程图
3.连续性结局变量样本量计算
依据最小二乘法,Chen等[7]推导出了SPCD中连续性结局变量的样本量计算公式,此后,我们在此基础上变换得到了适用于TED和SPCD的样本量计算公式,具体为:
式中:b:第一阶段分配到安慰剂组的比例(第二阶段的分配比例常定为1:1)
θ1:第一阶段试验组和安慰剂组的疗效差值
θ2:第一阶段安慰剂无效者在第二阶段的疗效差值
θ3:第一阶段试验组有效者在第二阶段的疗效差值

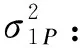

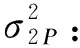

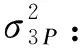
1-q1:第一阶段安慰剂组无效者的比例
p1:第一阶段试验组有效者的比例(只针对TED)
w1:第一阶段疗效的权重
w2:第一阶段安慰剂无效者在第二阶段疗效的权重
w3:第一阶段试验组有效者在第二阶段疗效的权重(SPCD:w3=0,w1+w2=1;TED:w1+w2+w3=1)
4.二分类结局变量样本量计算
Ivanova等人[8]在2011年基于得分检验(score test)的方法推导出了二分类结局变量的样本量计算公式,具体为:
n=(z1-β+z1-α/2)2/γ1
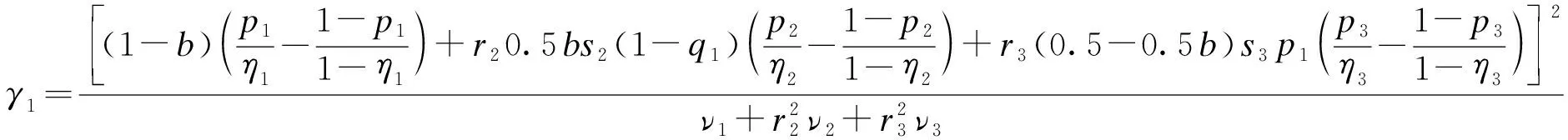
η1=(1-b)p1+bq1
η2=0.5p2+0.5q2
η3=0.5p3+0.5q3
式中:b:第一阶段分配到安慰剂组的比例(第二阶段的分配比例常定为1:1)
p1:第一阶段试验组的有效率
q1:第一阶段安慰剂组的有效率
p2:第一阶段安慰剂无效者在第二阶段试验组的有效率
q2:第一阶段安慰剂无效者在第二阶段安慰剂组的有效率
p3:第一阶段试验组有效者在第二阶段试验组的有效率
q3:第一阶段试验组有效者在第二阶段安慰剂组的有效率
s2:第一阶段中的安慰剂组无效者完成第二阶段试验的比例
s3:第一阶段中的试验组有效者完成第二阶段试验的比例
r2、r3:得分检验中的检验参数,推荐设定为1,应用SPCD时取r3=0
SPCD和TED样本量比较
连续性结局变量的样本量估计中,考虑到没有现有的参数信息,我们依据Ivanova等[9]提供的一个评价振动性仪器对缓解疼痛功效的试验来帮助确定参数。由于第二阶段比第一阶段疗效低的可能性很小,最终我们设定的第一阶段试验组和安慰剂组的疗效差值θ1=0.87,各阶段的方差均为7.37。TED第一阶段分配到安慰剂组的比例b设为0.50,SPCD设为0.67。 针对两阶段的疗效权重,我们取了两种情况,对于TED设计,一种是w1=w2=w3=0.33,即三个亚组权重相同;另一种是w1=0.5,w2=w3=0.25,保证第二阶段的两个亚组权重一致。对于SPCD设计,一种是w1=w2=0.5,另一种是w1=0.75,w2=0.25。一类错误和检验效能分别设定为0.05和0.8。我们比较了不同参数设置下SPCD、TED、传统的单阶段随机对照设计和交叉设计所需的样本量。二分类结局变量中,我们根据一个随机、双盲、安慰剂对照的两阶段交叉设计试验来帮助参数设置。这是一个用来评价高频刺激止痛效果的试验[10],高频刺激作为试验组。分两种情况进行讨论:(1)假定在两阶段疗效不相同时,探讨得分检验参数r2、r3和样本量之间的关系,r2、r3是用来估计第二阶段疗效与第一阶段疗效的比值,一般在一次试验中需要事先确定[8];(2)假定两阶段疗效相同时,探讨第一阶段分配到安慰剂组的比例b与样本量之间的关系,此时r2、r3选择推荐值,即r2=r3=1。具体参数设置见表1。一类错误和检验效能分别设定为0.05和0.80。

表1 二分类结局变量样本量估计参数设置
我们比较了不同参数设置条件下SPCD、TED、经典的单阶段安慰剂随机对照设计、安慰剂导入期设计、随机撤药设计和交叉设计的样本量。其中,TED和SPCD又分为最佳参数设置和推荐参数设置两种情况,最佳参数设置是指依据估计的各阶段各组有效率来设置r2和r3,同时求出最佳的分配比例b,以达到样本量最小。推荐参数设置中,SPCD的b取0.67,r2=1,r3=0,TED的b取0.50,r2=r3=1。本次试验中假定数据的缺失率为0,故s2=s3=1。本次研究均采用SAS 9.4来进行分析。
结 果
当结局变量为连续性时,在不同参数条件下需要的样本量见表2,此外单阶段设计需要的样本量为2253,交叉设计需要的样本量为1130。显然,当第二阶段的疗效优势越明显,SPCD和TED需要的样本量就越少。相同参数条件下,TED相比于SPCD需要的样本量更少,但两者均显著优于单阶段设计和交叉设计。第一阶段疗效的权重设置的越大,总体疗效越差,因而需要的样本量越大。此外,第一阶段安慰剂组无效者和试验组有效者的比例越大,相当于有更多的受试者进入了第二阶段,最终需要的样本量更少。
二分类变量样本量和r2、b的关系可见图3。图3(a)是假定两阶段疗效(试验组有效率-安慰剂组有效率)不同时样本量与r2的关系,可见随着r2的增加,SPCD和TED的样本量急剧下降,SPCD中,当r2到达9.8时,样本量变化趋于稳定,并在此后缓慢升高。TED中,当r2到达6.2时,样本量趋于稳定,并在此后缓慢回升。总体来看,TED比SPCD需要的样本量要多,主要原因应该是SPCD分配到安慰剂组的比例更大。图3(b)是假定两阶段疗效相同时样本量与第一阶段安慰剂组分配比例b的关系,随着b的增加,SPCD和TED的样本量都经历了先下降再升高的过程,SPCD的最低点位于b=0.57的时候,TED是当b=0.50时需要的样本量最小。总体来看,TED比SPCD需要的样本量少。
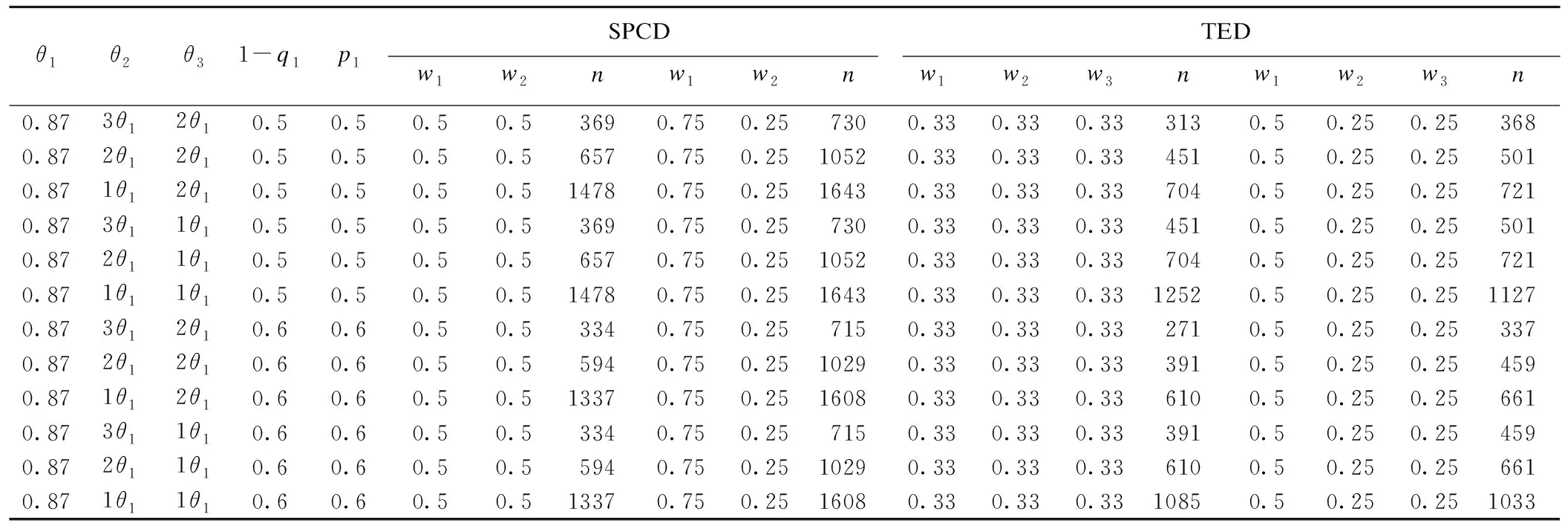
表2 连续型结局变量两种设计的样本量估计
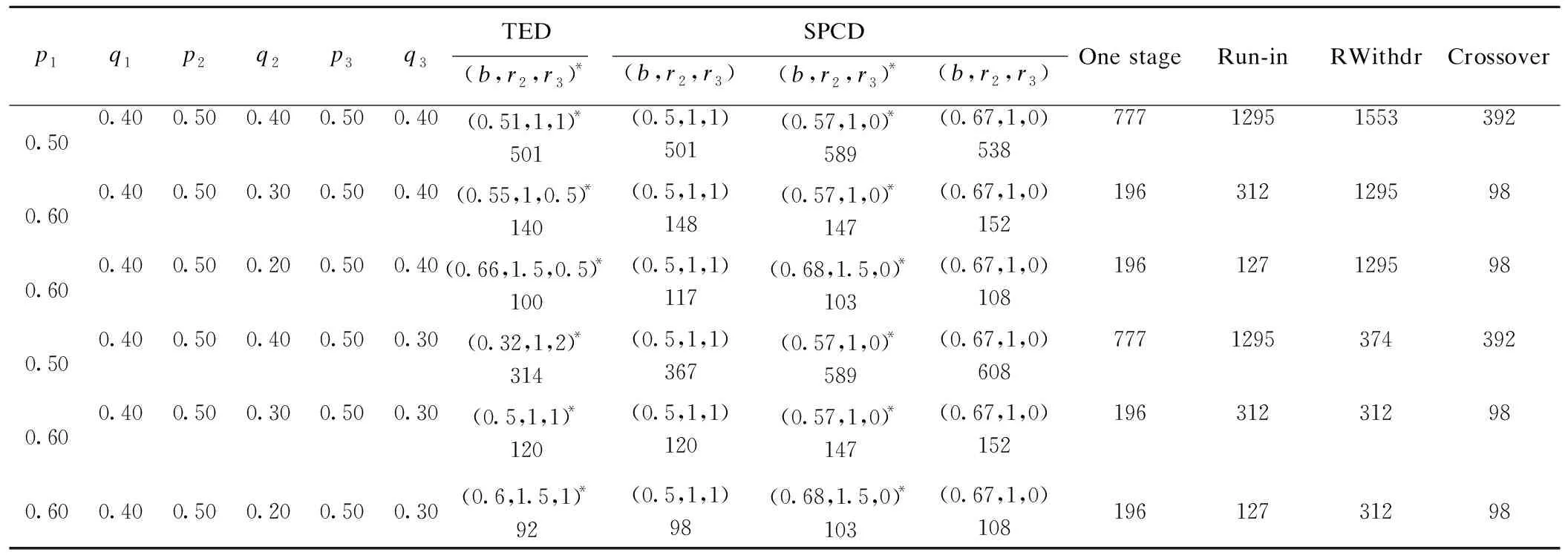
此外,表3还列出各种参数设定条件下常见几种设计需要的样本量。可见,交叉设计优势最明显,只有在p1=0.50,q1=0.40,p2=0.50,q2=0.40,p3=0.50,q3=0.30时,需要的样本量略多于双向富集设计和随机撤药设计。当安慰剂无效组的疗效有限时,安慰剂导入设计需要的样本量较大。当试验药有效组的疗效有限时,随机撤药设计需要的样本量较大。SPCD需要的样本量要略大于TED设计。单阶段安慰剂对照设计的样本量主要取决于第一阶段的疗效,疗效越大,需要的样本量越小,考虑到我们主要针对的是有高安慰剂效应的精神类疾病,因而单纯用单阶段设计没有优势。
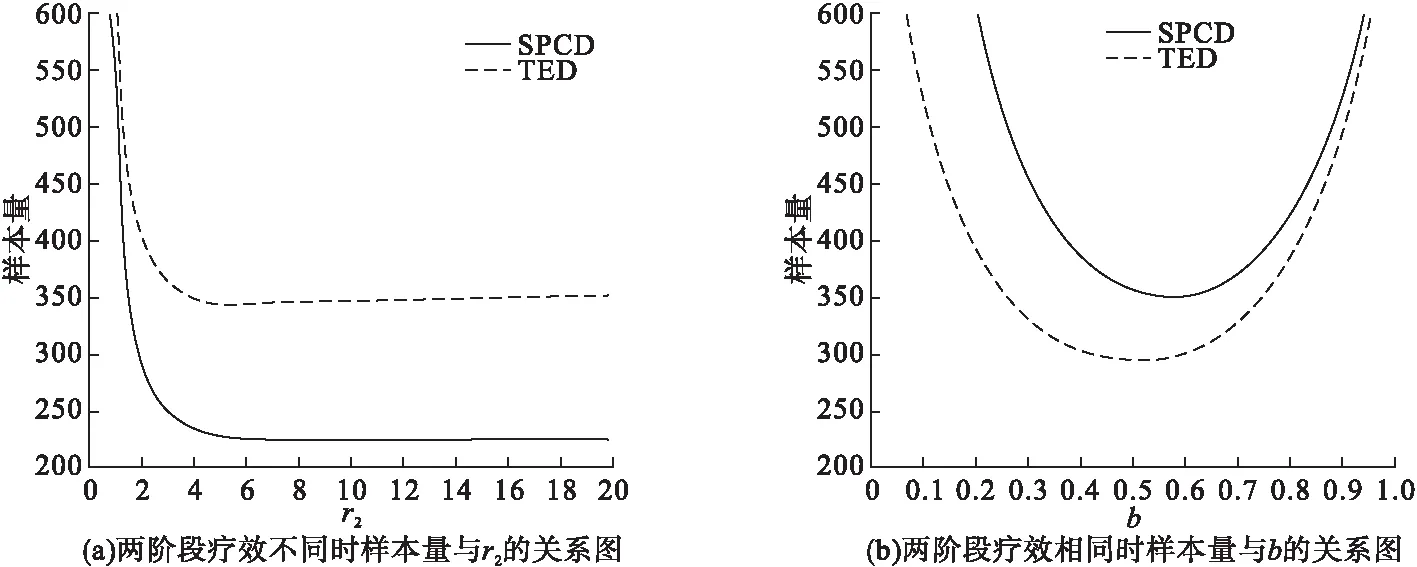
图3 二分类变量样本量和r2、b的关系
p1q1p2q2p3q3TEDSPCD(b,r2,r3)*(b,r2,r3)(b,r2,r3)*(b,r2,r3)One stageRun-inRWithdrCrossover0.500.400.500.400.500.40(0.51,1,1)*501(0.5,1,1)501(0.57,1,0)*589(0.67,1,0)538777129515533920.600.400.500.300.500.40(0.55,1,0.5)*140(0.5,1,1)148(0.57,1,0)*147(0.67,1,0)1521963121295980.600.400.500.200.500.40(0.66,1.5,0.5)*100(0.5,1,1)117(0.68,1.5,0)*103(0.67,1,0)1081961271295980.500.400.500.400.500.30(0.32,1,2)*314(0.5,1,1)367(0.57,1,0)*589(0.67,1,0)60877712953743920.600.400.500.300.500.30(0.5,1,1)*120(0.5,1,1)120(0.57,1,0)*147(0.67,1,0)152196312312980.600.400.500.200.500.30(0.6,1.5,1)*92(0.5,1,1)98(0.68,1.5,0)*103(0.67,1,0)10819612731298
*One stage:经典的单阶段安慰剂对照设计;Crossover :2×2交叉设计;Run-in:安慰剂导入期;RWithdr:随机撤药设计;*表示最佳参数设置,未加*表示一般推荐的参数设定
模拟研究
为了验证我们样本量计算公式的可靠性,我们进行了模拟研究来检验把握度。连续性变量中,现设定α=0.05,β=0.20,其它参数设置见表4。最终计算得到SPCD需要的样本量为450,TED需要的样本量为296。 根据设定的参数进行模拟分析,分析方法采用的是Chen等[11]提出的最小二乘法,模拟循环1000次,最终计算得到的SPCD的检验效能为0.870,TED的检验效能为0.769。
二分类变量中,设定一类错误α=0.05,二类错误β=0.20,其它参数设置见表5。最终计算得到SPCD需要的样本量为388,TED需要的样本量为267。统计分析采用的Ivanova和Tamura[6]提出的得分检验,自由度为1。模拟循环1000次,最终计算得到的SPCD的检验效能为0.821,TED的检验效能为0.760。

表4 连续性变量模拟研究参数设置
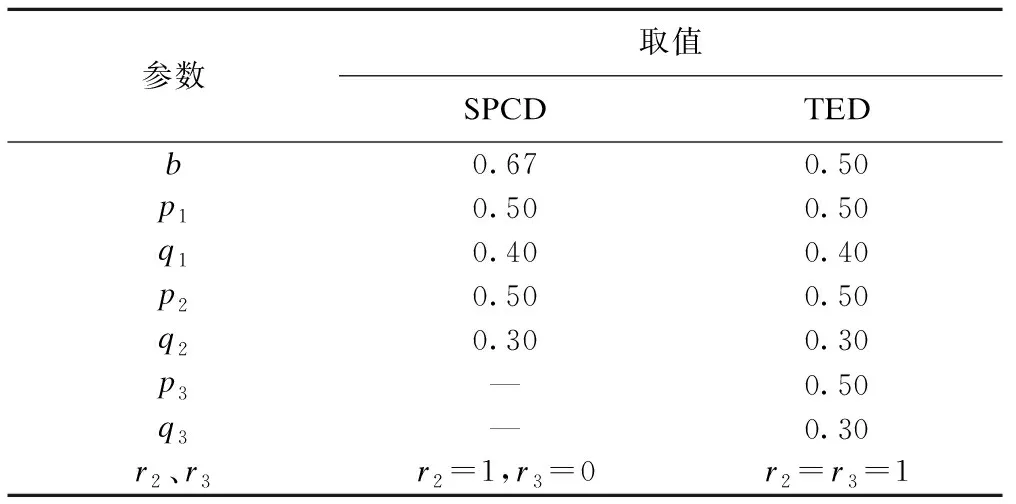
表5 二分类变量模拟研究参数设置
讨 论
相比于传统的单阶段随机对照设计,序贯安慰剂平行对照设计和双向富集设计在第二阶段利用了更多受试者的信息,因而在相同参数设置条件下,无论是连续型结局变量还是二分类结局变量,它们需要的样本量都更少。其中,TED的优势又格外明显。当然,在二分类的结果中,交叉设计在部分参数条件下需要的样本量比TED还要少,但交叉设计的样本量估计是基于两阶段疗效相同的前提下进行的,但在试验的开始阶段,我们是没法得出这样的结论的,而本文介绍的这两种设计是没有这样的假设前提的,因此适用性更强。在交叉设计中,很大比例的受试者要在服用试验药之后再服用安慰剂,有可能存在迟滞效应,从而高估安慰剂的疗效,影响最终的试验结论。相比于安慰剂导入设计以及随机撤药设计,SPCD和TED除了在样本量上的优势外,还减轻了前面两种方法在试验中维持盲态的困难,因而值得推荐。
结果显示,两阶段疗效相同时,对于SPCD,当第一阶段安慰剂组的比例b=0.57时,样本量最小,实际试验中,一般第二阶段的疗效要明显优于第一阶段,因而我们会尽量取较大的b值,使更大比例的受试者进入第二阶段,从而更易得到有统计学意义的结论。但一般,我们不会将此比例设置超过3:1[12],否则会对维持盲态带来困难,从而影响整个试验的疗效,所以推荐将b取为2/3~3/4之间。对于TED,我们一般推荐b=0.5。两阶段疗效不同时,本文在r2=9.8和6.2时,SPCD和TED需要的样本量最小,但实际试验中,一般实际有效率事先是未知的,因而很多时候还是推荐r2=r3=1[6]。通过模拟研究我们得到了相应样本量下的检验效能,连续型变量和二分类变量SPCD的Power均达到了80%以上,另外两组TED的Power也达到了76%以上,稍有损失。
由于序贯安慰剂平行对照设计和双向富集设计都是两阶段,因而相比于传统的单阶段随机对照设计受试者经历的药物暴露时间会更长。但由于两阶段设计需要的样本量更少,整个试验的周期还是会缩短,这就为药物的早日上市以及患者早日得到有效的治疗赢得了宝贵的时间。然而,两阶段试验还是有部分缺点,由于它们需要在第二阶段重新进行随机分组,这就可能给整个试验维持盲态带来困难。首先第一阶段使用安慰剂的受试者,如果在第二阶段分配到了试验药组,可能会明显察觉到疗效的提升而意识到自己的用药情况,即使病人觉察不出来,医生也有可能因为病人症状在第二阶段的改善而发现用药的变化。其次,第一阶段的安慰剂无效者,如果在第二阶段依旧分配到了安慰剂组,受试者的疾病症状可能会一直得到不到改善,甚至越来越恶化,从而怀疑自己用的是安慰剂,病情严重的话也难以得到伦理委员会的同意。
对于统计分析,近年来,陆续有人已经提出了SPCD和TED的分析方法,针对二分类结局变量,主要是得分检验[6]的方法。针对连续性变量,有似不相关回归[13]、最小二乘法[7]和重复测量的混合效应效应模型[14]。使用SPCD或TED时,会存在较大比例的缺失,前两种方法对于缺失数据的处理一般是忽略或是判为缺失,这在很大程度上影响了整个试验的检验效能,而重复测量混合效应模型在处理缺失数据时有很大的优势,所以一般还是推荐用混合效应模型来处理该类数据。SPCD和TED虽然都是二阶段的,但考虑到一阶段结束后没有进行假设检验,同时也不存在因疗效显著而提前终止试验的情况,因而不要校正一类错误[5]。
综上所述,在安慰剂效应较高或是没有彻底治愈方案的慢性疾病试验中,序贯安慰剂平行对照设计和双向富集设计相比于传统设计有很大的优势,但如果是某些病情严重或是治愈方案明确的疾病,还是不推荐使用。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06 02:49:20
特别健康·下半月(2019年6期)2019-08-01 01:45:35
祝您健康(2019年3期)2019-03-22 08:57:08
测控技术(2018年4期)2018-11-25 09:46:52
时代英语·高一(2018年5期)2018-11-19 10:55:06
上海精神医学(2017年5期)2017-11-29 06:03:10
时代英语·高一(2017年5期)2017-11-14 15:52:20
电脑知识与技术(2016年22期)2016-10-31 20:38:41
江西通信科技(2015年3期)2015-12-05 05:52:05
山西大同大学学报(自然科学版)(2014年6期)2014-01-23 02:00:17
