
基于最优线性无偏预测任意协方差下估计错误发现率
2018-06-15 06:46王湘玉张宝学齐春香
统计与决策 2018年10期
王湘玉,张宝学,齐春香
(1.河北科技师范学院 工商管理学院,河北 秦皇岛 066004;2.首都经济贸易大学 统计学院,北京 100070;3.东北师范大学 数学与统计学院,长春 130024)
0 引言
多重假设检验是高维统计推断的基本问题,也是目前统计研究的热点问题之一,应用的领域非常广泛。比如,在金融学中,需要对数以万计的原假设同时进行检验,用以确定哪个客户经理的能力更强。再如,在全基因组相关性研究中,希望在大量的基因数据中找到与某性状或疾病相关的SNP位点,同样需要同时对数以万计的原假设进行检验。而在进行多重假设检验的过程中,一个非常重要的问题,就是如何更好地控制总体的错误率。
Benjamini和Hochberg(1995)[1]提出了多重假设检验的FDR标准(E[V/R],即在m个原假设中,错误拒绝的原假设个数V占拒绝的原假设个数R的比例的期望)。之后,Storey(2002)[2]、Efron(2010)[3]等众多学者对FDR进行了更为深入的研究。然而大部分的研究往往都是基于原假设相互独立为前提。但是这种假设往往较为严苛,很难达到。因为实际问题中的原假设通常具有某种相关性。举例来说,如果某个原假设是显著的,那么在它附近的其他原假设就有更大的可能性也是显著的。
也有一些学者针对原假设相关的情况做了一些研究,比如Benjamini和Yekutieli(2001)[4]在正回归相依情况下研究了FDR的估计问题。再如,Storey等(2004)[5]在弱相关情况下估计FDR。但是这些相关关系都过于特殊,急需找到一种在原假设的任意相关情况下的FDR估计方法。
Fan等(2012)[6]提出了一种任意协方差结构下的FDP(False Discovery Proportion,即V/R)估计方法。然而在估计随机变量W时,将其当作参数,采用L1估计方法。实际上,所得的模型是一个混合效应模型,对此,本文基于最优线性无偏预测方法,估计随机变量W,进而提出一种新的FDP估计方法,最终估计FDR。
1 最优线性无偏预测
最优线性无偏预测[7]是针对混合效应模型,估计随机变量的一种方法。对于混合效应模型y=Xβ+Zu+ε,其中y是有N个观测的向量;X是N×p的已知矩阵;β是p×1的未知向量(p个未知常数),看作固定效应部分;Z是N×q的已知矩阵;u是q×1的随机向量,看作随机效应部分;ε是随机误差项,是N×1的随机向量。
显然有 E(u)=0,E(ε)=0 ,定义:
Var(u)=D'Var(ε)=R'Cov(u'ε')=0
因此,V=Var(y)=Var(Zu+ε)=ZDZ'+R
Henderson(1950)[8]得到β和u的最优线性无偏预测:

由公式[9]可得:

2 基于最优线性无偏预测估计FDP
2.1 理论分析
定义由n个样本构成的第j个SNP位点的基因型数据为个样本的表现型数据为Y=(Y1' …'Yn)T。现考虑和的边际线性回归可以得到βj的最小二乘估计。
这样可以同时检验p个假设:

其中,原假设表示第j个SNP位点与性状无关。
将标准化,记为 Z1'…'Zp,则有其中是 X 相关系数矩阵,∑的第(k ' l)个元素为rkl,对角元素为1。
因此,检验问题(2)等价于:
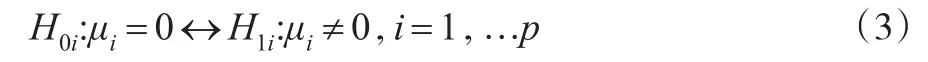
通过对∑进行特征分解,得出其中 λ1≥…≥λp是 ∑ 的p个特征值,γ1'…'γp是对应的p个特征向量,那么这样 Zi可被分解成:

其中k。W1'…'Wk相互独立,且与K1'…'Kp独立。W=(W1…,
对于混合效应模型(4),当 y=Z'X=0'Z=L'u=W'D=Ik'R=A时,带入式(1)可得:

针对混合效应模型(4),取前75%p(记为m)个最小的对应m个最小的 | μi|,并且将L的分量对应排序后,取前m行,从而对应有的形式,取A=A11,这样可以将这些 ||Zi看成是在原假设式(6)下:

其中Z是有m个观测值的m×1向量是m×k矩阵;W 是k×1随机向量,是随机效应部分;K是m×1随机向量,是随机误差项。并且有,V=Var(Z)=∑=Var(LW+K)=LL'+A。
Tipping和Bishop(1999)[10]基于高斯潜在变量角度提出下述概率模型,此模型体现了主成分分析的思想:

其中
在原假设下,

因此,将模型(6)替代为模型(7),有:
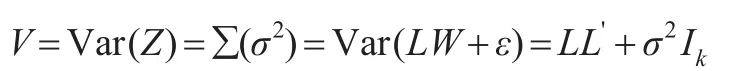
进而由式(5)可得到W 的估计为:

下面估计σ2,Z的密度函数是:

似然函数为:

对数似然函数为:

由得到:
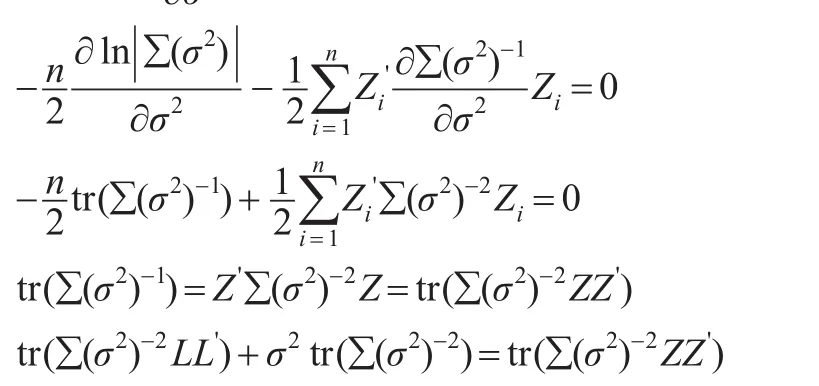
从而得到:

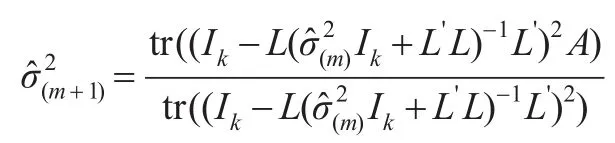
最终可以估计σ2,带入式(8)中得出:

这时,可以得出任意协方差结构下的FDP估计:

其中是标准正态分布的累积分布函数是标准正态下的分位数,ηi的估计记为。

2.2 模拟及结果
检验统计量现考虑以下六种模型下的协方差阵结构。其中,Xi产生过程分别如下:
(1)等相关模型其中 ∑为对角元素是1,其余元素是1/2的矩阵。
(2)Fan和Song[6]的模型令N(0'1),且:

其中
(3)独立柯西模型:对于是独立同分布的柯西分布的随机变量,其中x0=0'γ=1。
(4)三因子模型:对于 X=(X1'…,Xp),取 Xj=ρ(1)Wj(1)其 中
(5)双因子模型:对于 X=(X1'…'Xp),取其中
(6)非线性因子模型:对于取
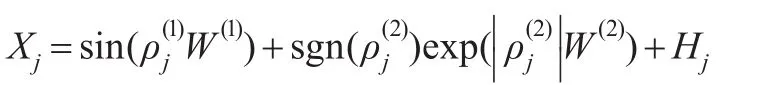
其中
令SNP位点个数 p=1000,n=100'σ=2,错误的原假设个数 p1=50,原假设下 β0=0,备择假设下 β1=1,做1000次模拟。上述六种相关模型下的FDP估计值与真值比较结果如图1所示。

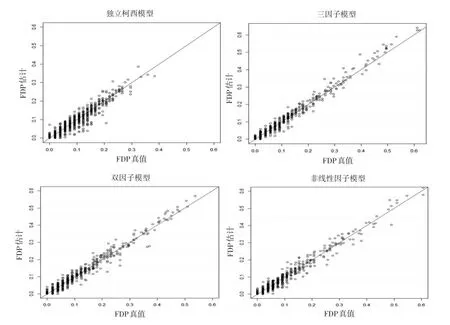
图1
图2为六种模型的FDP估计值与真值的相对误差(即

图2
从模拟结果可以看出,本文给出的FDP估计值在真值附近波动,理论上合理。
3 结论
多重假设检验是高维统计推断的基本问题,也是目前统计研究的热点问题之一,应用领域十分广泛。比如,金融领域内,要得知哪个客户经理的能力更强。再如,全基因组相关性的研究中,要在大量的基因数据中寻找与性状或疾病相关的SNP位点,往往都需要同时对数以万计的假设进行检验。而在进行多重假设检验问题时,往往需要控制总体错误率FDR。棘手的是,实际问题中的原假设往往具有一定相关性。对此,本文提出一种新的估计FDR的方法,即在检验统计量的任意协方差结构下,对混合效应模型使用最优线性无偏预测方法估计随机变量W,从而估计FDP,进而估计FDR。模拟表明,本文给出的FDP估计值在真值附近波动,理论上比较合理。
但是由于采用最优线性无偏预测的方法,估计FDP在运算速度上不够快捷,还有待在今后的研究中进一步地完善。
[1]Benjamini Y,Hochberg Y.Controlling the False Discovery Rate:A Practical and Powerful Approach to Multiple Testing[J].Journal of the Royal Statistical Society,SeriesB,1995,(57).
[2]Storey J D.,A Direct Approach to False Discovery Rates[J].Journal of the Royal Statistical Society,2002.
[3]Efron B.Correlated Z-Values and the Accuracy of Large-Scale Statistical Estimates[J].Journal of the American Statistical Association,2010,(105).
[4]Benjamini Y,Yekutieli D.The Control of the False Discovery Rate in Multiple Testing Under Dependency[J].The Annals of Statistics,2001,(29).
[5]Storey J D,Taylor J E,Siegmund D.Strong Control,Conservative Point Estimation and Simultaneous Conservative Consistency of False Discovery Rates:A Unified Approach[J].Journal of the Royal Statistical Society,2004,(66).
[6]Fan J,Han X,Gu W.Estimating False Discovery Proportion Under Arbitrary Covariance Dependence[J].Journal of the American Statistical Association,2012.
[7]王松桂,史建红,尹素菊,吴密霞.线性模型引论[M].北京:科学出版社,2004.
[8]Henderson C R.Estimation of Genetic Parameters[J].Ann.Math.Statist.,1950,(21).
[9]Benameur S,Mignotte M,Destrempes F,et al.Estimation of Mixtures of Probabilistic PCA with Stochastic EM for the 3D Biplanar Reconstruction of Scoliotic Rib Cage[J].Image Processing,2004,(5).
[10]Tipping M E,Bishop C M.Probabilistic Principal Component Analysis[J].Journal of the Royal Statistical Society,1999.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
现代职业教育·高职高专(2020年1期)2020-08-16
计算机应用与软件(2019年2期)2019-04-01
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
卷宗(2018年14期)2018-06-29
统计与决策(2018年5期)2018-04-08
雷达学报(2017年3期)2018-01-19
时代金融(2017年6期)2017-03-25
考试周刊(2016年54期)2016-07-18
