
基于犹豫模糊集统计相关系数的多源异类数据融合识别
2018-03-14 02:26孙贵东
系统工程与电子技术 2018年3期
关 欣, 孙贵东, 衣 晓, 赵 静
(海军航空大学电子信息工程系, 山东 烟台 264001)
0 引 言
多传感器多源数据识别是根据各传感器上报的带有不确定性的身份信息需要进一步进行融合处理,给出量测目标身份判断的过程。实际上是对量测信息进行分类与处理的过程,给出量测目标的类别与属性。在融合识别问题中由于属性的差异性,导致描述方法往往不一致,有的属性倾向于用定量数据表示,而有的更适合用定性概念描述,产生了多源异类数据融合识别的问题。文献[1]指出数据融合的数据往往是处理描述同一现象的多源异类信息。由于数据源的多源异类性,往往导致融合识别的不确定性。而模糊集作为不确定性处理的一种重要手段,自文献[2]提出其概念来,经过半个多世纪的发展,相继产生了区间模糊集、二型模糊集、模糊多重集、直觉模糊集、犹豫模糊集等多种样式的模糊集,并且在多源异类数据融合领域得到了应用。文献[3]研究了实数、区间数、三角模糊数、直觉模糊数和语义变量组成的混合多属性决策问题,通过将混合数据统一到区间框架内进行多属性决策。文献[4]研究了实数、区间数、语义变量、直觉模糊数、犹豫模糊数和犹豫模糊标签组成的多源异类多属性群决策问题,并基于TOPSIS方法进行多属性决策判定。文献[5-7]则分别基于直觉模糊集、区间直觉模糊集数学规划方法,研究了具有直觉模糊信度和区间直觉模糊信度的区间直觉模糊数、直觉模糊数、三角模糊数、语义变量、区间数和实数组成的混合多属性决策问题,并采用逼近理想解的方法进行决策判定。尽管上述文献较好地处理了多源异类数据的决策问题,但是其框架主要是基于区间数和直觉模糊数讨论的,而犹豫模糊集作为新概念,2010年由文献[8-9]提出,相比其他模糊集,在确定隶属度函数时,不像2-型模糊集的隶属度为概率分布,也不像区间模糊集和直觉模糊集由不确定误差幅度确定隶属度,是因为隶属度的取值有一系列可能值。由于其隶属度是在[0,1]内犹豫不定,更能符合多源异类数据融合时各传感器上报的独立决策不确定性,因此基于犹豫模糊集描述多源异类数据来对多源异类数据的融合识别进行研究。
相关分析是衡量两个变量之间线性接近程度的重要方法,关于犹豫模糊集相关系数的研究目前也有许多进展。文献[10]首先定义了5种犹豫模糊数(hesitant fuzzy element,HFE)的相关系数,将其应用到医疗诊断领域。在此基础上,文献[11]提出了犹豫模糊集(hesitant fuzzy sets,HFS)相关系数,并解决聚类问题。文献[12]分析了现有相关系数的不足,提出了新的相关系数,在医疗诊断、聚类分析问题中得到了应用。文献[13-19]又分别将相关系数拓展到区间犹豫模糊集、二重犹豫模糊集、区间二重犹豫模糊集和犹豫语义标签集领域,并在特征提取、模式识别、多属性决策、聚类分析、水质评估和医疗诊断等领域具体应用。尽管上述文献提出了几种HFS相关系数,也在多个领域得到了应用,但是都存在不足。文献[10]中5种定义方法仅限于计算HFE的相关系数。文献[11]的定义虽然可以计算HFS的相关系数,但是其定义不符合统计学直觉,并且需要各HFE中隶属度个数相同。文献[12]的定义虽然符合统计学直觉,但相关定义过程中的数学概念存在争议。并且目前还没有以犹豫模糊集为框架的基于其相关系数的多源异类数据融合方法。
本文试图基于犹豫模糊集框架,解决多源异类数据的融合识别问题,主要讨论犹豫模糊数HFE、直觉模糊数IFN、区间数和实数4类基本数据组成的多源异类数据。首先将多源异类数据犹豫模糊描述以统一进行相关分析,其次在现有HFS相关系数基础上,提出HFS统计相关系数,使其既满足统计学直觉,又不需要各HFE中隶属度个数相同,并且修正了相关系数定义过程中数学概念不明确的问题,考虑实际问题中属性权重的影响将其拓展为加权HFS相关系数,最后利用所提出的HFS统计相关系数解决多源异类数据的融合识别问题。
1 犹豫模糊集描述
记论域X={x1,x2,…,xn},则X上的犹豫模糊集(hesitant fuzzy sets, HFS)定义[8-9]为
M={[x,hM(x)]|x∈X}
(1)
式中,hM(x)为犹豫模糊数(hesitant fuzzy element,HFE),由一系列[0,1]内的不同数值组成,描述集合X中元素x对M的隶属度,有时候也称M为HFE,即HFES,HFES与HFS实际上是等价的,文中统一用HFS表示。
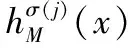
文献[8-9]提出犹豫模糊数包络的概念,用来表示直觉模糊数。对于X上的犹豫模糊数h(x),简记为h,γ为h中隶属度可能值,即γ∈h(x),表示为
μ=h-,h-=min{γ|γ∈h}
(2)
υ=1-h+,h+=max{γ|γ∈h}
(3)
犹豫模糊数的包络可以用直觉模糊数(μ,υ)表示,记为Aenv(h)。
文献[23-24]定义了犹豫模糊数的记分函数和方差来比较犹豫模糊数。对于犹豫模糊数h,其记分函数和方差为
(4)
(5)
式中,l(h)为h中元素的个数;γ∈h(x)。则对于两个犹豫模糊数h1和h2有
(1) 如果s(h1)>s(h2),则h1>h2。
(2) 如果s(h1)=s(h2),那么
满足v(h1)>v(h2),则h1 满足v(h1)=v(h2),则h1=h2。 记X上犹豫模糊数h(x)、直觉模糊数A(x)、区间数I(x)和实数R(x)分别为 (6) 式中,γ为h(x)的隶属度;u、v分别为A(x)的隶属度和非隶属度,且0≤u+v≤1;a-、a+分别为I(x)的下界和上界。 式(2)和式(3)将h(x)用A(x)表示,同理也可以将A(x)用h(x)表示[8-9],即对于给定的犹豫模糊数A(x)=〈u,v〉,可以将其用犹豫模糊数表示为 A(x)→h(x)={u,1-v} (7) 而直觉模糊数A(x)和区间数I(x)之间关系为 I(x)→A(x)={a-,1-a+} (8) 则可以用犹豫模糊数h(x)将区间数I(x)表示为 I(x)→h(x)={a-,a+} (9) 而实数R(x)的犹豫模糊数h(x)为 I(x)→h(x)={a} (10) 通过式(7)~式(10)实现将犹豫模糊数h(x)、直觉模糊数A(x)、区间数I(x)和实数R(x)组成的多源异类数据用犹豫模糊数h(x)统一表示,成功将多源异类数据问题转化为犹豫模糊集问题。为此,只需讨论犹豫模糊数的相关分析即可实现对多源异类数据的融合识别。 现有的犹豫模糊集相关分析方法主要为文献[10]提出的5种HFE相关系数、文献[11]提出的2种HFS相关系数以及文献[12]改进的HFS相关系数。 文献[10-11]定义的HFS相关系数,忽略了负相关,仅为一种相关的强度,理论上不符合传统统计学相关系数落于[-1,1]的要求,计算过程需要HFE中隶属度个数相同。而文献[12]改进的相关系数实际上仅为一种均值相关。文献[11]定义的HFS的相关和文献[12]定义的HFS加权均值、方差和相关均有待商榷,一方面形式上不符合直觉,另一方面不符合数学逻辑定义,存在类似重复等权重系数的问题,方差的定义也不符合统计数学逻辑。 因此,在现有HFS相关系数的基础上,首先定义HFS的数学概念,修正了现有HFS相关系数及其附属概念的定义方法,提出HFS统计相关系数,既满足取值落于[0,1]的统计学要求,又不需要HFE内隶属度个数相同。 统计学相关系数的定义是归一化随机变量的协方差。基于文献[12]首先定义HFS的均值、方差和协方差。 对于X={x1,x2,…,xn}上的犹豫模糊集M={〈x,hM(x)〉|x∈X},其均值定义为 (11) (12) 在HFS均值的基础上定义HFS方差为 (13) 在方差的基础上定义,HFSM和N之间的(互)协方差为 (14) 式中,lMj和lNj分别为HFEhM(xj)和hN(xj)中隶属度个数,且当M=N时,Cov(M,N)=Var(M,N)。 对于X={x1,x2,…,xn}上的犹豫模糊集M、N,如果算子c(M,N)满足下列条件: (1)c(M,N)=c(N,M); (2) 当M=N时,c(M,N)=1; (3) -1≤c(M,N)≤1。 则称c(M,N)为M和N之间的相关系数。 在HFS方差和协方差的基础上,基于现有HFS相关系数,定义HFS统计相关系数为 (15) 例1给出一个简单例子进行统计相关系数的计算说明。 记X={x1,x2,…,xn}上的两个犹豫模糊集M和N分别为 M={〈x1,{0.7,0.5}〉,〈x2,{0.7,0.5,0.4}〉, 〈x3,{0.6,0.4,0.3}〉} N={〈x1,{0.5,0.4,0.2}〉,〈x2,{0.8,0.5}〉, 〈x3,{0.7,0.6,0.3}〉} 首先,计算M、N中各HFE均值分别为 则M、N的均值分别为 利用式(14)计算M、N的协方差、方差分别为 (0.367-0.517)+(0.533-0.522)×(0.65-0.517)+ (0.433-0.522)×(0.533-0.517)]=-0.003 89 (0.533-0.522)2+(0.433-0.522)2]=0.004 71 (0.65-0.517)2+(0.533-0.517)2]=0.013 48 所以,相关系数为 例1表明HFS统计相关系数方法能够很好处理HFS中和HFE中隶属度个数不相同的问题,而文献[10-11]相关系数不能直接处理此类数据,必须通过数值延拓后才能够处理,不可避免地增加了度量误差。 (16) (17) (18) 上述定义修正了文献[12]定义的不足,基于修正后的HFS的数学概念定义加权HFS相关系数为 cw(M,N)= (19) 多源异类数据的识别问题是现实生活中面临的基本问题,由于属性的差异性,导致属性描述的方式往往不一致,具体体现在属性数据类型的多源异类性,在前文叙述多源异类数据的犹豫模糊统一的基础上,基于统计HFS相关系数对多源异类数据进行融合识别判定。 记待识别的多属性多源异类数据集为A={A1,A2,…,Ai,…,An1},每类数据集具有m种属性P={p1,p2,…,pj,…,pm},其中属性数据由犹豫模糊数h(x)、直觉模糊数A(x)、区间数I(x)和实数R(x) 4种数据形成多源异类数据属性。由于多源异类数据之间无法直接融合处理,考虑将其统一到犹豫模糊域后再进行识别判定。为此,基于第2节所述的多源异类数据表述方法,用犹豫模糊数将多源异类数据表示为 (20) 则统一记待识别目标Ai在属性pj上的多源异类数据的犹豫模糊表示为hAi(pj),则待识别目标Ai在属性集P上的多源异类数据属性的犹豫模糊表示为 Ai={〈pj,hAi(pj)〉|pj∈P} (21) 则所有待识别多源异类数据集A的犹豫模糊表示为 A= (22) 式中,1≤i≤n1;1≤j≤m。基于HFS统计相关系数进行进一步识别判定即可。 记现有的目标多属性犹豫模糊数据库为B={B1,B2,…,Bk,…,Bn2},同样每类数据集具有m种属性P={p1,p2,…,pj,…,pm},其中属性数据仅由犹豫模糊数h(x)组成。记数据库数据Bk在属性pj上的犹豫模糊表示为hBk(pj),则Bk在属性集P上的犹豫模糊属性表示为 Bk={[pj,hBk(pj)]|pj∈P} (23) 则数据库B的犹豫模糊表示为 B= (24) 式中,1≤k≤n2;1≤j≤m。 基于HFS统计相关系数可以计算犹豫模糊表示后的多源异类数据集A和数据库B之间对应的犹豫模糊数据Ai和Bk之间的相关系数c(Ai,Bk),并在此基础上得到多源异类数据集A和数据库B之间的相关系数,两者分别为 (25) c(A,B)= (26) 式中,i=1,2,…,n1;j=1,2,…,m;k=1,2,…,n2;lAij和lBkj分别为Ai和Bk在属性pj上对应的HFE的隶属度个数。 根据多源异类数据集A和数据库B之间的相关系数c(A,B),即可实现对多源异类数据的识别判定。由于本文研究的重点在于犹豫模糊集统计相关系数,为此这里仅提供一种简单易实现的识别判定方法,采用最大相关系数识别判定准则 (27) 式中,增加门限ε、η,0.5<ε≤1,η根据相关系数计算区分度而定,如果满足 (28) 基于HFS统计相关系数的多源异类数据融合识别步骤为: 步骤1确定待识别多源异类数据集A和犹豫模糊数据库B; 步骤2用犹豫模糊数统一描述多源异类数据集A; 步骤3基于HFS统计相关系数计算犹豫模糊表示后的多源异类数据集A和犹豫模糊数据库B之间对应数据的相关系数c(Ai,Bk),并形成c(A,B); 步骤4以相关系数c(A,B)作为识别判定指标,采用最大相关系数识别判定准则,如果满足识别条件,则判定相关系数大的为识别结果。 将所提出的犹豫模糊集数统计相关系数应用到多源异类数据的融合识别问题中。设计了3组算例:①验证HFS统计相关系数的有效性并与文献[10]和文献[12]相关系数进行对比分析;②讨论HFS统计相关系数以及权重对识别结果的影响;③用HFS统计相关系数解决多源异类数据的识别问题。 本算例采用经典的医疗诊断识别算例,文献[10]和文献[12]均有介绍,一方面验证HFS统计相关系数识别的有效性,另一方面更好地与文献[10]和文献[12]的相关系数进行对比分析。假设诊断症状库内有5类症状信息,分别记为R1、R2、R3、R4、R5;每类症状具有5种属性,分别记为p1、p2、p3、p4、p5;属性描述采用犹豫模糊数表示,现有4位待识别个体,分别记为A1、A2、A3、A4,需要诊断其症状。5类HFS症状数据库及4位待识别个体的HFS数据分别如表1、表2所示。 表1 HFS症状数据库 表2 犹豫模糊待识别数据 采用本文提出的HFS统计相关系数(15)计算每位待识别个体与症状数据库之间的相关系数,将其作为识别指标,得到的计算结果如表3所示。 表3 症状识别相关系数表 通过表3得知,个体A1,A3,A4分别识别为症状R2,而A2识别为症状R4,识别结果与文献[9]中的计算结果一致,验证了HFS统计相关系数的有效性,并且HFS统计相关系数取值在[0,1]上,克服了文献[10]、文献[11]相关系数的不足。为了对比HFS统计相关系数与文献[10]、文献[11]相关文献的识别效果,本文将3种方法计算的结果进行对比,其中HFS统计相关系数与文献[12]相关系数的对比如图1所示,与文献[10]相关系数的对比如图2所示。3种方法的计算时间对比如表4所示。 图1 与文献[12]相关系数计算的识别对比图Fig.1 Correlation coefficient results compared with [12] 图2 与文献[10]相关系数计算的识别对比图Fig.2 Correlation coefficient results compared with [10] 图1中虚线表示文献[12]相关系数的计算效果,实线表示HFS统计相关系数的计算效果,通过图1的对比分析得知,两种方法的计算结果相同,但是注意到图1中各对应实线在0点上方总是位于虚线下方;而在0点下方总是位于虚线上方,表明其对应的相关系数取值的绝对值要小于文献[12]相关系数的绝对值,并且实线对应最大值与次大值之间的差距要比虚线大,表明HFS统计相关系数变化率要比文献[12]相关系数的识别变化率灵敏,即HFS统计相关系数在识别区分度上要比文献[12]相关系数有优势。 图2中虚线表示文献[12]相关系数的计算效果,而实线表示HFS统计相关系数的计算效果,通过图2的对比分析得知,两种方法的计算结果有所不同,但是主要问题在于文献[10]相关系数的取值均为[0,1]内,并且在与HFS统计相关系数相同的图像框架内,其识别效果近似一条直线,很难区分识别结果,文献[10]相关系数的计算结果在区分度上比HFS统计相关系数要差。 表4仅给出在计算机处理器为Inter i7 3770K 3.5 GHz、内存8 GB、64位操作系统环境下,使用Matlab软件对编写的3种相关系数函数处理时的计算时间,其中不包括后续的作图处理时间。 表4 相关系数计算时间对比 通过表4得知,3种方法在数据读取和计算速度的差异不大,尽管本文方法的时间是最长的,但是横向对比而言,3种方法计算时间都非常快,本文算法增加的计算时间在合理范围。本文算法计算时间长的原因在于,本文方法在相关系数计算时,采用了最大值遍历函数,相比其他两种方法直接乘性和开方计算要多消耗一部分时间,但是消耗的时间与增加计算精度相比而言是可以接受的。 前一节的计算结果是在没有考虑权重的条件下得到的,但在实际计算过程中,属性权重对识别结果十分重要。为此采用与算例1相同的算例计算,利用加权HFS相关系数(19)重复上述算例的计算,其中各属性权重分别设定为0.1、0.2、0.3、0.3、0.1,得到的计算结果如表5所示。 表5 症状识别相关系数表 通过表5得知,个体A1、A3分别识别为症状R2,A2识别为症状R4,但是个体A4的识别结果本例中判定为未识别,即未在症状库中找到个体A4的症状。一方面在于其计算相关系数比较低,另一方面相关系数最大值与次大值之间比较接近,因此不能简单判定识别结果为相关系数最大值对应的症状R2,而判为未找到识别结果更为合适。属性权重的改变导致识别结果发生了变化,为了进一步验证属性权重的重要性,仿真设计属性4的权重从0.1按步长0.2变化到0.9,其余属性权重平均,利用加权HFS相关系数重新计算上例,并得到个体A4的识别效果随权重的变化图如图3所示,其余个体的识别效果图可类似给出,这里仅以A4为例分析。 图3 个体A4的识别效果随权重的变化图Fig.3 Recognition effect of A4 with different attribute weights 由图3得知,个体A4的识别效果随权重的变化图而改变,当属性4权重较小时,可以判定A4的识别结果为症状R2,随着权重的增加,其识别效果越来越不明显,识别结果在R1和R2之间不易区分,此时记判定为未找到识别结果一类。通过对HFS相关系数属性权重的分析得知,识别结果会随着属性权重的改变而变化,因此实际问题中,在进行加权HFS相关系数的计算时应充分考虑权重的分配,以得到更合理的识别结果。 上例分析了HFS统计相关系数在犹豫模糊集数据域的识别效果,本节将HFS统计相关系数应用到多源异类数据的识别问题中。采用的是犹豫模糊数据库,如表6所示,具有5类已知目标特征,也分别记为R1、R2、R3、R4、R5;每类目标具有5种属性,分别记为p1、p2、p3、p4、p5。 表6 犹豫模糊数据库 而待识别多源异类数据如表7所示,主要由4类待识别目标组成,分别记为A1、A2、A3、A4。每类目标均具有5类属性信息,并且5类属性信息分别由实数、区间数、直觉模糊数、犹豫模糊数和这4种数据组成的多源异类数据描述,因此此问题就变成了多源异类数据的识别问题。基于HFS统计相关系数,采用第4节的识别方法对其进行识别判定。 表7 多源异类待识别数据 基于第2节所述的多源异类数据统一方法,将由实数、区间数、直觉模糊数、犹豫模糊数组成的多源异类数据用犹豫模糊数统一表示,并按照降序排列,得到多源异类数据转化后的犹豫模糊属性,如表8所示。 表8 多源异类转化后犹豫模糊待识别数据 采用HFS统计相关系数计算多源异类数据转化后的犹豫模糊属性和表5犹豫模糊数据库之间的相关系数,作为识别指标,得到的计算结果如表9所示。 表9 多源异类数据识别相关系数表 由表9得知,目标A2识别为数据库中R5,A4识别为数据库中R3,而目标A1和A3则由于相关系数不足及区分度不高,判定为未在数据库中找到识别类一类,即需要在扩充的数据库中进行再识别。本算例验证了HFS统计相关系数在处理多源异类数据识别问题的有效性,并且HFS统计相关系数计算时不需要对应属性的HFE隶属度个数相同,解决了传统方法需要补齐隶属度再计算相关系数的问题,因而相比传统方法具有更好的计算精度。 针对多源异类数据的融合识别问题,基于犹豫模糊集框架,由犹豫模糊数、直觉模糊数、区间数和实数4类基本数据组成的多源异类数据,由犹豫模糊数统一描述,提出了HFS统计相关系数进行融合识别判定。首先分析了现有HFS统计相关系数的局限性,主要表现为定义违背统计学直觉、数学概念不明确、计算需要HFE中隶属度个数相同和取值局限于[0,1]内等。为解决上述问题,提出HFS统计相关系数,使其既满足统计学直觉,又不需要各HFE中隶属度个数相同,并具有更强的数学概念。考虑实际问题中属性权重的影响,将其拓展为加权HFS相关系数。最后利用所提出的HFS统计相关系数解决多源异类数据的融合识别问题。仿真算例对比分析并验证了HFS统计相关系数的有效性,具有精度高、区分度好的优点。 从犹豫模糊的角度,为多源异类数据的融合识别问题提供了可行方法,具有现实意义。所提出的HFS统计相关系数计算方法可以拓展到区间犹豫模糊集、二重模糊集和犹豫语义标签领域相关系数的计算中,以进一步地研究及应用。 [1] BUCCI D J. Assessing the performance of data fusion algorithms using human response models[J].Dissertations & Theses-Gradworks,2015. [2] ZADEH L A.Fuzzy sets[J].Information & Control,1965,8(3): 338-353. [3] SUN G D, GUAN X. Research on hybrid multi-attribute decision-making[C]∥Proc.of the International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, 2016: 272-277. [4] ZHANG X, XU Z, WANG H. Heterogeneous multiple criteria group decision making with incomplete weight information: a deviation modeling approach[J]. Information Fusion, 2015, 25: 49-62. [5] WAN S P, DONG J Y. Interval-valued intuitionistic fuzzy mathematical programming method for hybrid multi-criteria group decision making with interval-valued intuitionistic fuzzy truth degrees[J]. Information Fusion, 2015, 26(C): 49-65. [6] XU J, WAN S P, DONG J Y. Aggregating decision information into Atanassov’s intuitionistic fuzzy numbers for heterogeneous multi-attribute group decision making[J]. Applied Soft Computing, 2016, 41: 331-351. [7] WAN S P, LI D F. Atanassov’s intuitionistic fuzzy programming method for heterogeneous multi-attribute group decision making with Atanassov’s intuitionistic fuzzy truth degrees[J]. IEEE Trans.on Fuzzy Systems, 2014, 22(2): 300-312. [8] TORRA V. Hesitant fuzzy sets[J].International Journal of Intelligent Systems, 2010, 25(6): 529-539. [9] TORRA V, NARUKAWA Y. On hesitant fuzzy sets and decision[C]∥Proc.of the 18th IEEE International Conference on Fuzzy Systems, 2009: 1378-1382. [10] XU Z S, XIA M M. On distance and correlation measures of hesitant fuzzy inforrnation[J]. International Journal of Intelligent Systems, 2011, 26: 410-425. [11] CHEN N, XU Z S, XIA M M. Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis[J]. Applied Mathematical Modeling, 2013, 37(4): 2197-2211. [12] LIAO H C, XU Z S, ZENG X J. Novel correlation coefficients between hesitant fuzzy sets and their application in decision making[J].Knowledge-Based Systems,2015,82(C):115-127. [13] EBRAHIMPOUR M K, EFTEKHARI M. Feature subset selection using information energy and correlation coefficients of hesitant fuzzy sets[C]∥Proc.of the 7th International Conference on Information and Knowledge Technology, 2015: 1-6. [14] MENG F Y, CHEN X H, ZHANG Q. Correlation coefficients of interval-valued hesitant fuzzy sets and their application based on the Shapley function[J]. International Journal of Intelligent Systems, 2016, 31(1): 17-43. [15] WANG L, NI M F, ZHU L. Correlation measures of dual hesitant fuzzy sets[J]. Journal of Applied Mathematics, Volume 2013, 2013(4):1-12 [16] YE J. Correlation coefficient of dual hesitant fuzzy sets and its application to multiple attribute decision making[J]. Applied Mathematical Modeling, 2014, 38(2): 659-666. [17] TYAGI S K. Correlation coefficient of dual hesitant fuzzy sets and its applications[J]. Applied Mathematical Modeling, 2015, 39(22): 7082-7092. [18] FARHADINIA B. Correlation for dual hesitant fuzzy sets and dual interval-valued hesitant fuzzy sets[J]. International Journal of Intelligent Systems, 2014, 29(2): 184-205. [19] LIAO H C, XU Z S, ZENG X J, et al. Qualitative decision making with correlation coefficients of hesitant fuzzy linguistic term sets[J].Knowledge-Based Systems, 2015,76(1):127-138. [20] XU Z S, XIA M M. Distance and similarity measures for hesitant fuzzy sets[J].Information Sciences,2011,181(11): 2128-2138. [21] LIAO H C, XU Z S. Hesitant fuzzy decision making methodologies and applications[M]. Singapore Springer, 2017: 1-34. [22] XU Z S, ZHANG X L. Hesitant fuzzy multi-attribute decision making based on TOPSIS with incomplete weight information[J]. Knowledge-Based Systems, 2013, 52(6): 53-64. [23] XIA M M, XU Z S. Hesitant fuzzy information aggregation in decision making[J]. International Journal of Approximate Reasoning, 2011, 52(3): 395-407. [24] LIAO H C, XU Z S, XIA M M. Multiplicative consistency of hesitant fuzzy preference relation and its application in group decision making[J]. International Journal of Information Technology and Decision Making, 2014, 13(1): 47-76.2 多源异类数据分析
3 犹豫模糊集统计相关系数
3.1 HFS的数学概念

3.2 HFS统计相关系数
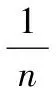
3.3 加权相关系数

4 基于HFS统计相关系数的多源异类数据融合识别
4.1 多源异类数据的犹豫模糊表示
4.2 基于HFS统计相关系数的识别判定
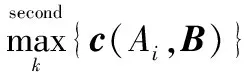
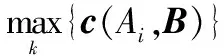
5 多源异类数据融合识别
5.1 算例1



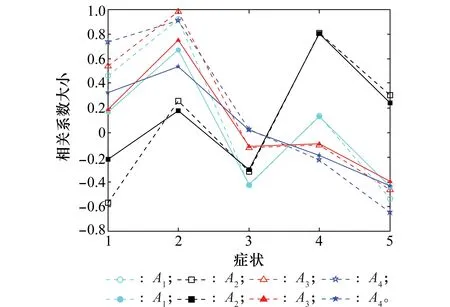
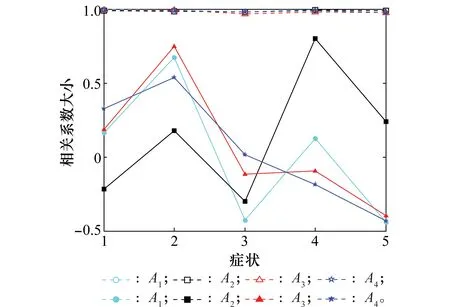

5.2 算例2

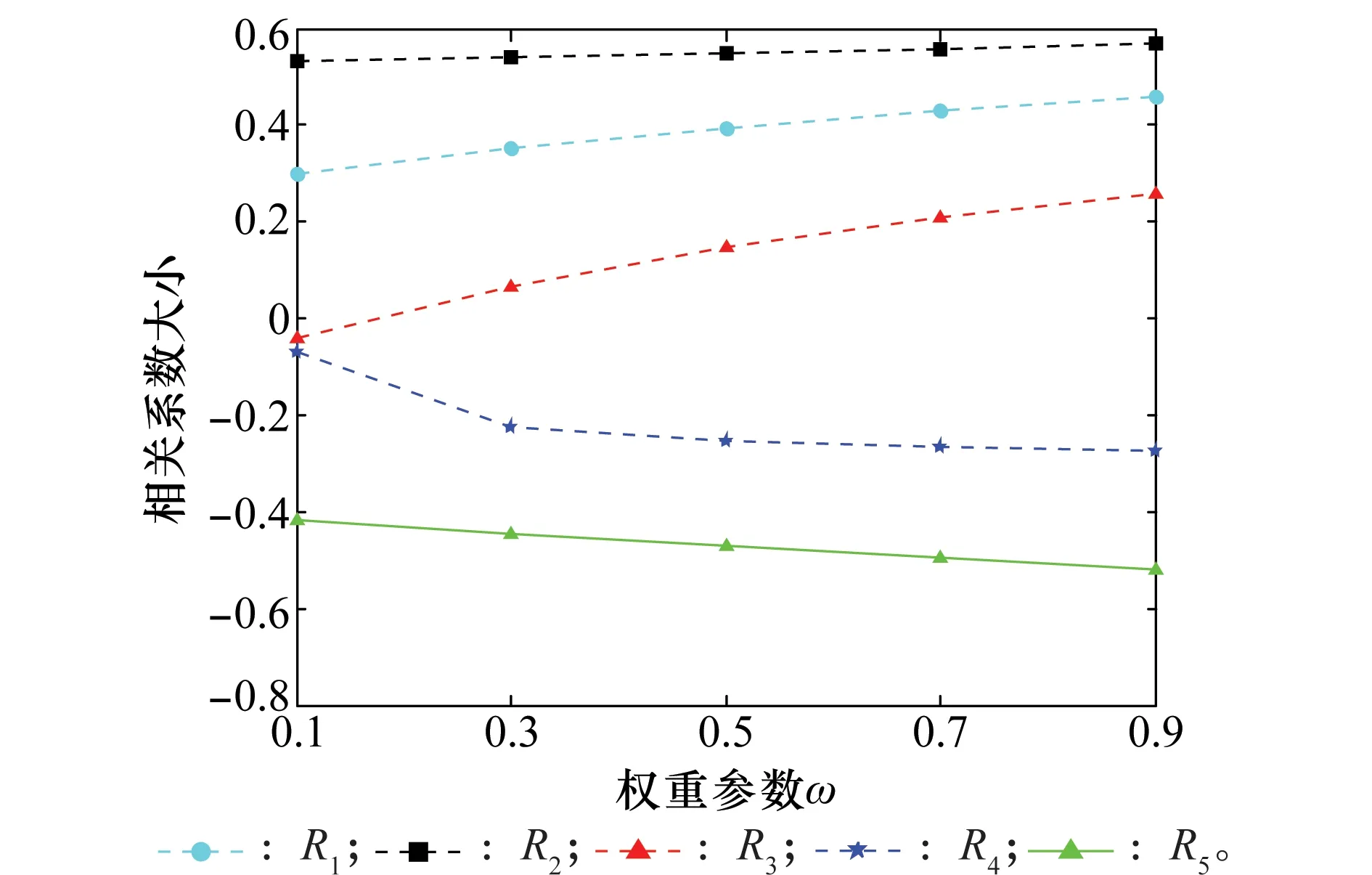
5.3 算例3
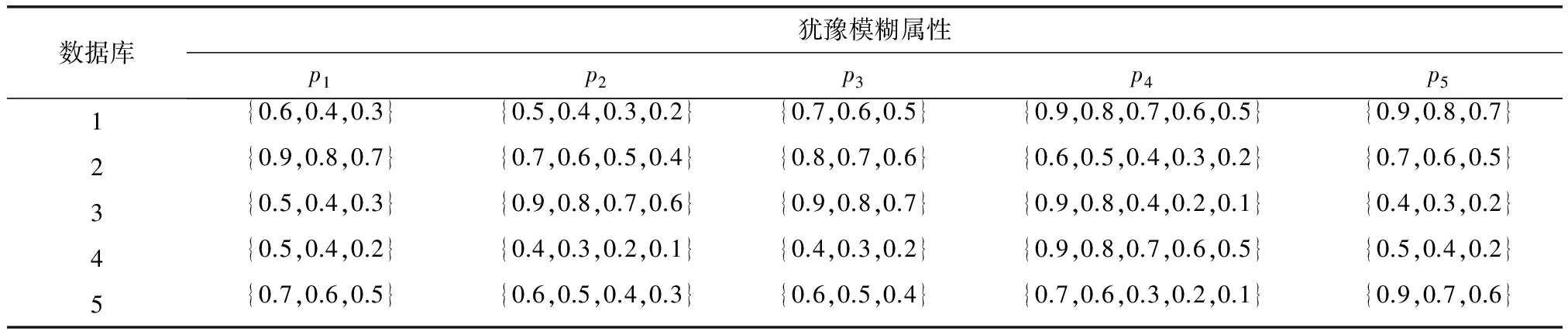



6 结 论
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18
新世纪智能(数学备考)(2021年5期)2021-07-28
湖北民族大学学报(自然科学版)(2021年1期)2021-04-02
数学大世界(2021年4期)2021-03-30
山东农业大学学报(自然科学版)(2020年5期)2020-11-02
海峡姐妹(2020年7期)2020-08-13
新世纪智能(数学备考)(2020年12期)2020-03-29
西华大学学报(自然科学版)(2018年6期)2018-11-24
儿童故事画报·智力大王(2015年12期)2016-01-23
儿童故事画报·智力大王(2015年9期)2016-01-03
