
Proposal of Initiative Service Model for Service Robot
2018-01-12 08:30ManHaoWeihuaCaoMinWuZhentaoLiuJinhuaSheLuefengChenandRiZhang
Man Hao, Weihua Cao, Min Wu, Zhentao Liu, Jinhua She, Luefeng Chen, and Ri Zhang
1 Introduction
Service robot is an important part of robot industry, and it is a key entry point to improve the way of human life. As service robot stepping into all aspects of people’s daily lives, e.g., guest service[1], family service[2], disabled pension[3-5], medical rehabilitation[6], etc., simple and mechanical service of robots has been unable to meet the needs of people. It is hoped that robots can be endowed with the human-like capabilities of observation, interpretation, and even emotion expression[7], i.e., robots have the ability to interact with people emotionally, including react appropriately to human expectations and behavior. Hence intelligent service research has attracted more attention.
In recent years, there are many researches on service robot. The ambient assisted living service system based on SIFT algorithm that proposed in [8] can locate the objects who have service demands for elderly and disabled. A service architecture is proposed to solve the problem of heterogeneity in multi-robot cooperation[9]. A mobile robot is able to perceive the surrounding environment and interact with people in [10]. However, function of cognitive and understanding object’s intention are still not enough to meet humans’ requirements. The Sacario service robot system that is used in the hotel service can realize the human-robot interaction, including speech recognition, face location, and gesture recognition[11]. This system, however, lacks the perception of emotion in speech recognition, thus it can’t correctly understand the intention of users. Robot behavior adaption and human-robot interaction researches have been done in [12,13]. Although these robots are able to execute corresponding service tasks through instructions mentioned above, the service pattern is passive, which causes robots can not integrate into people’s life. If a robot can serve users initiatively, i.e., robots provide initiative service for human, a natural and harmonious human-robot interaction (HRI) could be turned into reality.
To realize initiative service in HRI, communication information of human is necessary, which is divided into two parts, i.e., surface communication information and deep cognitive information[14,15]. Surface communication information refers to the information that can be obtained directly by sensors or the combination of knowledge base, e.g., speech, facial expression, and gesture. Deep cognitive information is based on human cognitive ability and inference ability to understand the intricate physiological or psychological changes in human mind, e.g., emotional states, personal intention, etc. Most of the service robots mentioned above serve for people based on surface communition information. They execute tasks mechanically according to the instruction, without understanding the thoughts and feelings of humans, (i.e., deep cognitive information). Deep cognitive information reflects people’s inner thinking, which is an important basis for initiative service if we can make good use of them.
An initiative service model for service robot is proposed to solve above problems, in which surface communication information and deep cognitive information are both taken into account. The initiative service model is composed of three layers. From bottom to top, the first one is information acquisition layer, in which surface communication information (e.g., speech, expression, and gesture) and other influence factors (i.e., personal information and environment information) are collected by sensors. The second layer is decision layer, where deep cognitive information (i.e., emotional state and personal intention) is obtained through emotion recognition and intention understanding. Furthermore, a demand analysis model is established to obtain a fuzzy relationship between deep cognitive information and users’ demands, by which users’ demands are obtained. The last one is initiative service execution layer, in which the task execution and emotion adaption is accomplished according to users’ demands. To validate the proposal, drinking service experiments are performed, in which 3 men and 2 women within 20-25 years old are invited as the experimenters. At the same time, the drinking time and water quantity of experimenters at each time by initiative service and passive service are recorded respectively. The experimental results validate that initiative service is real-time and reasonable.
The remainder of this paper is organized as follows. The architecture of initiative service model is proposed in Section 2. Initiative service method is introduced in Section 3. Drinking service experiments using initiative service model are given in Section 4.
2 Initiative Service Architecture
In recent years, service pattern of service robot is mainly passive service pattern, in which robot carries out tasks when an instruction is received. This pattern is too mechanized to meet humanized demands. To solve the problem, an initiative service model is proposed to provide a humanized and real-time service.
2.1 Introduction of passive service and initiative
service
For passive service, service robots need to receive commands (e.g., semanteme) from users, and then perform corresponding tasks. For instance, the user tells the robot that he/she wants to drink water specifically, and then the robot bring him/her water. The schematic of the passive service is shown in Fig.1.

Fig.1 Schematic of passive service.
For initiative service, emotional states and personal intention are obtained by analyzing surface communication information (e.g., physiological signals and speech), which are used to estimate user’s demand. According to this demand, the robot provides initiative service including corresponding task execution and emotion adaption. For example, the robot obtains user’s drinking demands through physical condition information and environmental information if the user is short of water, thereby providing water to the user initiatively and generating emotion adapting to the emotional state of the user. The schematic of the initiative service is shown in Fig.2.
Initiative service is the spontaneous execution of the robot via a series of decisions, and it doesn’t need to wait for users’ instructions, which can make the service more humanized and effective.
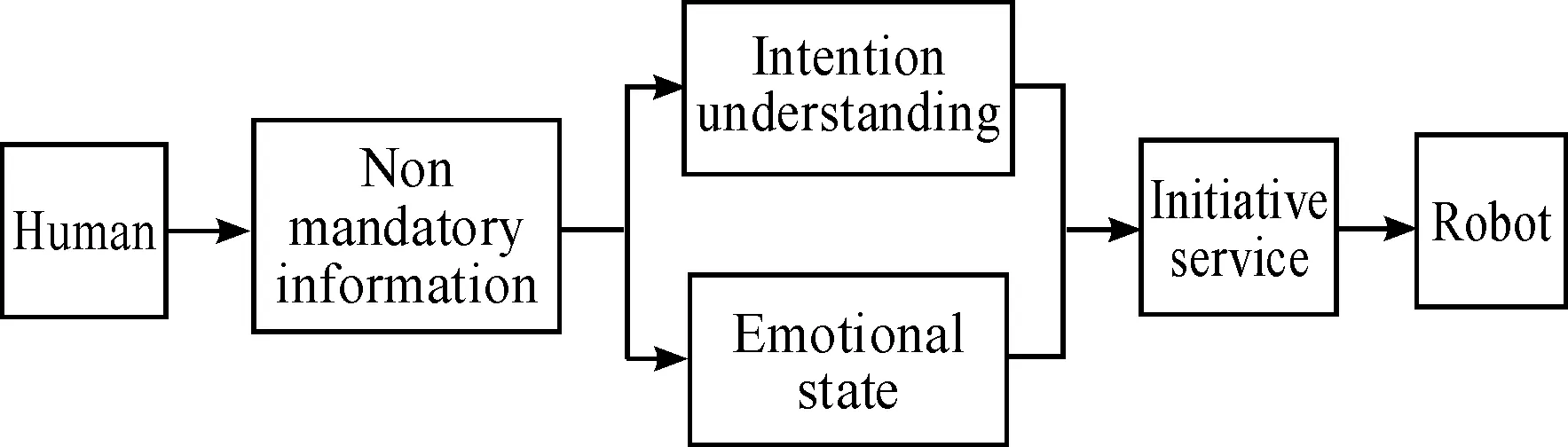
Fig.2 Schematic of initiative service.
2.2 Architecture of initiative service
Users’ demands are essential to implement initiative service of robots. Usually, emotional states and personal intention are closely related to users’ demands, therefore, emotion recognition and personal intention understanding are indispensable for initiative service, which could be obtained by surface communication information (e.g., facial expression, speech), personal information, and environmental information. Based on the above analysis, a three-layer framework for initiative service model is proposed, which is composed of three parts, i.e., information acquisition layer, decision layer, and initiative service execution layer, as shown in Fig.3.
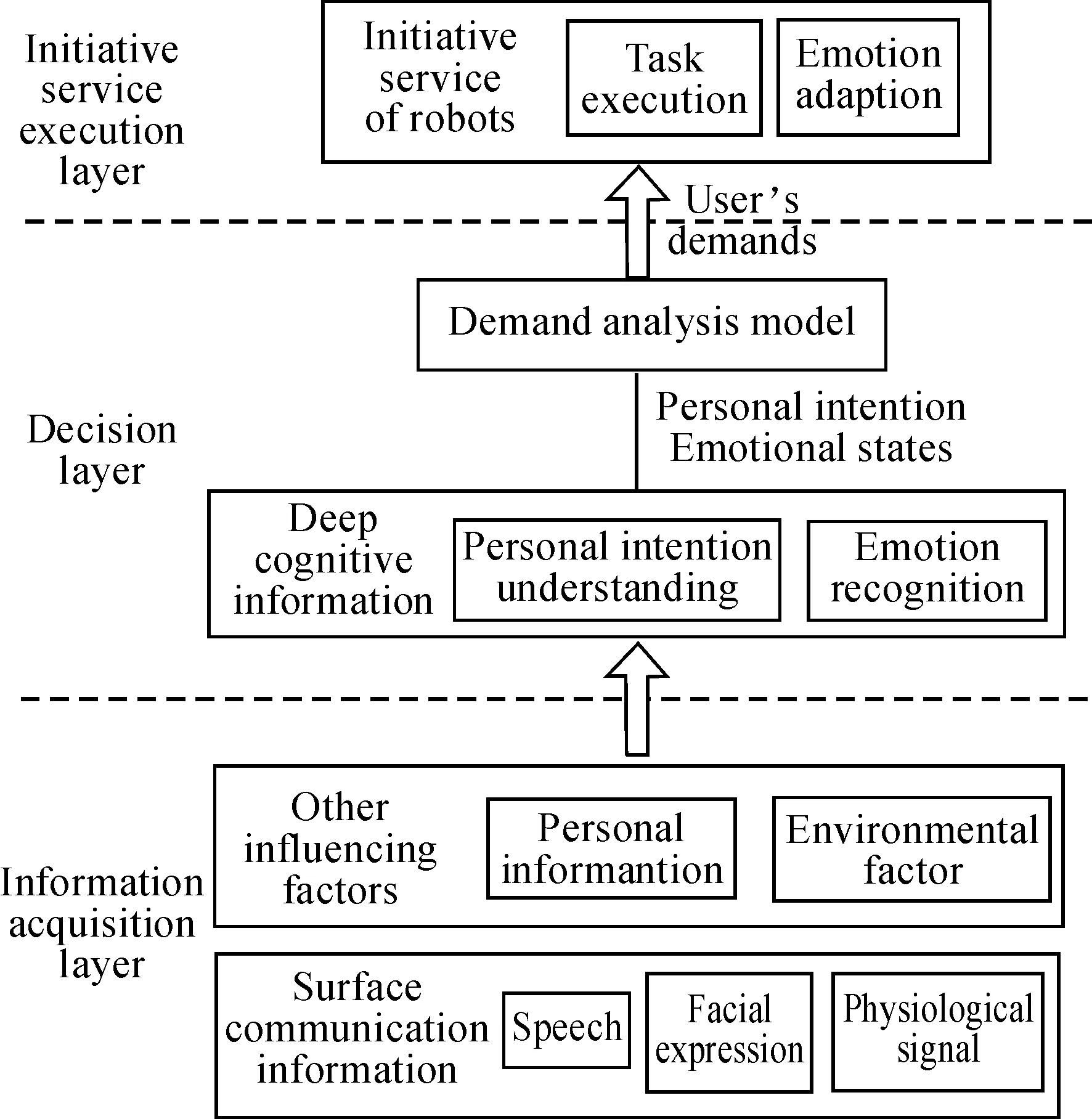
Fig.3 Initiative service architecture.
In decision layer, emotional states of the user are obtained through the identification of multi-modal information, and personal intention is inferred based on emotional states, personal information, and environmental information. In the demand analysis model, machine learning, fuzzy inference, etc., could be used to get the relationship between deep cognitive information (i.e., personal intention and emotional states) and users’ demands.
In initiative service execution layer, there are two kinds of services, i.e., task execution, in which appropriate task according to user’ demands are executed; emotion adaption, in which appropriate emotion is generated adapting to user’s emotional state.
3 Demand Analysis Based on Deep Cognitive Information
The premise of realizing initiative service is to obtain user’s demand, which is related to user’s emotional state and personal intention. Firstly, emotional state is obtained by emotion recognition, including speech emotion recognition, facial expression recognition, etc. Secondly, personal intention is inferred by intention understanding. And then a demand analysis model is established, in which fuzzy inference is adopted to acquire user’s demand.
3.1 Multimodal emotion recognition
Humans’ emotion is usually divided into seven basic categories, i.e., neutral, happy, anger, surprise, fear, disgust and sadness[16]. In the communication between humans and robots, surface communication information (e.g., speech, facial expressions) can reflect humans’ emotional state that is obtained by emotion recognition.
3.1.1 Speech recognition
As fast and easy understand way for communication, speech signal is considered to identify emotions[17]. It is believed that speech conveys not only syntactic and semantic contents of the linguistic sentences but also the emotional states of humans[18]. Speech signal can be collected by audio sensors, and the preprocessing of speech signal is adopted at the same time. Firstly, the emotion features (e.g., fundamental frequency, Mel-frequency Cepstral Coefficients and other statistic features) are extracted according to our previous works[19]. After obtaining the initially extracted features from preprocessed speech signal samples based on the analysis and extraction of speech emotion features, the correlation analysis is used to gain the lower redundancy features and reduce the dimension of selected feature set. Next, these selected features are put into pre-trained ELM model, by which the speech emotion is recognized.
3.1.2 Facial expression recognition
Facial expression is the most expressive way to convey emotions, and facial expression contributes 55% to the effect of the speakers’ message[20]. User’s emotional state can be estimated through facial expression recognition. The procedure of facial expression recognition mainly consists of three steps[21], i.e., face detection and segmentation, in which Adaboost learning is adopted for detecting the face region and Haar classifiers are used to further detecting and segmenting salient facial expression patches which are closely related to facial expressions; feature extraction, in which 2D Gabor and LBP are combined to extract discriminative features of facial expressions, and principal component analysis (PCA) is used for dimensionality reduction; facial expression classification, in which ELM is adopted for facial expression classification using the extracted features.
3.1.3Fusionofmulti-modalemotionrecognition
To improve the accuracy of recognition results, the multi-modal emotion information is taken into account. There are two fusion layers for multi-modal emotion recognition[21]. The first one is feature level fusion, where the features from all modalities are transformed into one feature vector for emotion recognition. An ELM classifier is designed for the feature vector, and the final emotion result is obtained. The other is the decision level fusion, where Naive Bayes classifier is designed for every modality. The probability of each basic emotion estimated by single modality is multiplied to obtain the final probability. By the product rule, the emotion with biggest probability is chosen as the final decision result of multi-modal fusion.
3.1.4Emotionalstaterepresentedina3Demotionspace
A 3-D emotion space named Affinity-Pleasure- Arousal (APA) space is employed to represent emotional state of humans[22], in which emotional state and its dynamic changes can be presented intuitively, as shown in Fig.4, being thought over the similar relationship between the three axes of emotion space, namely, “Affinity”, “Pleasure-Displeasure” and “Arousal-Sleep”. For instance, “Affinity” relates to the mutual relationship among individuals, “Pleasure-Displeasure” relates to favor, and “Arousal-Sleep” relates to liveliness in communication. Moreover, by using APA emotion space, it is not only possible to represent fixed mentality states but also possible to take into account rapid variations in emotional states.
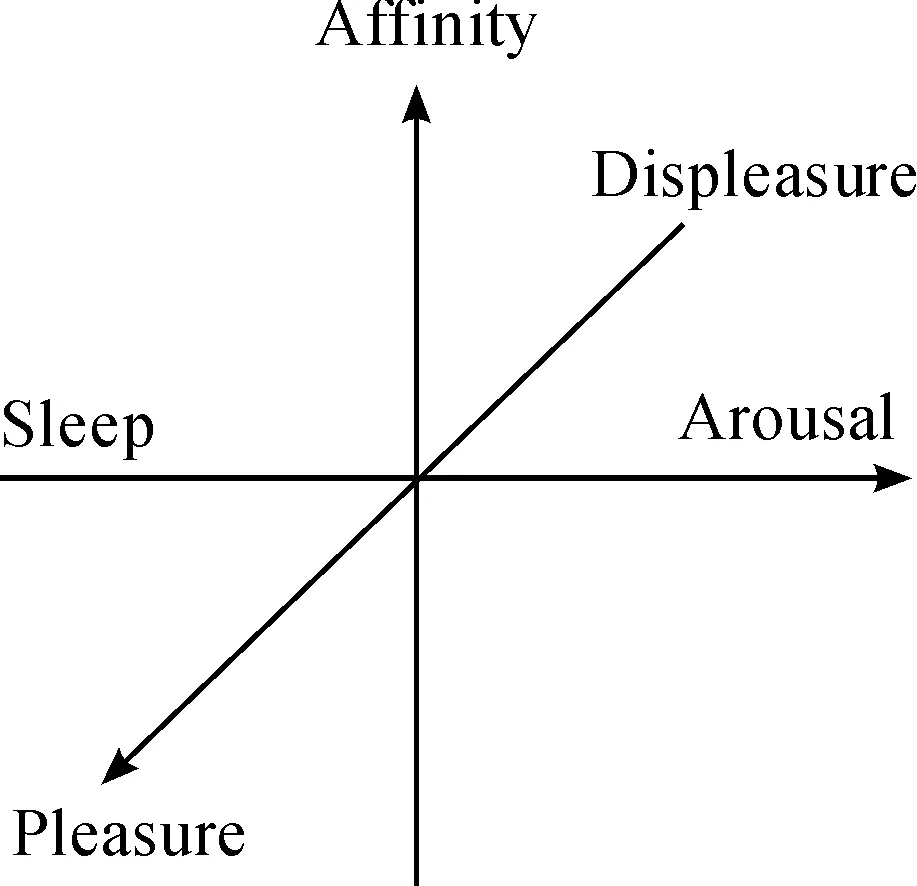
Fig.4 Affinity-Pleasure-Arousal emotion space.
3.2 Personal intention understanding
Intention understanding is mainly obtained by emotion, and intention is understood by collecting and analyzing of multimodal information (e.g., speech, expression and gesture). In addition, personal intentions also can be affected by personal information and surrounding environment information. Personal information (e.g., the gender and exercise) are obtained through the sensor detection and the knowledge base. And the surrounding environment information (e.g., temperature, humidity, etc.) are obtained directly through the sensor.
An intention understanding model based on two layers fuzzy support vector regression is adopted to comprehend humans’ inner thoughts in our previous work[14], which includes two parts, i.e., local learning layer and global learning layer. In the local learning layer, fuzzy C-means (FCM) clustering is used to classify the input data, and then the training data set are split into several subsets using the FCM algorithm. Therefore, the center and spread width is obtained. After the local learning, the global output of the proposed two-layer fuzzy support vector regression is based on the fusion model which is calculated using fuzzy weighted average algorithm.
3.3 Task execution and emotion adaption
It is difficult to describe user’s demands with accurate mathematical model, which belongs to the empirical model. Therefore, fuzzy production rule is adopted in this paper. Firstly, personal intention and emotional state of humans are fuzzified. Secondly, the relationship between deep cognitive information (i.e., emotional states and personal intentions) and user’s demands are established. And user’s demands are obtained by fuzzy inference. Thirdly, robots’ tasks and emotion are defuzzified, and execute corresponding task and emotion adaption. The model of fuzzy production rules is shown in Fig.5.
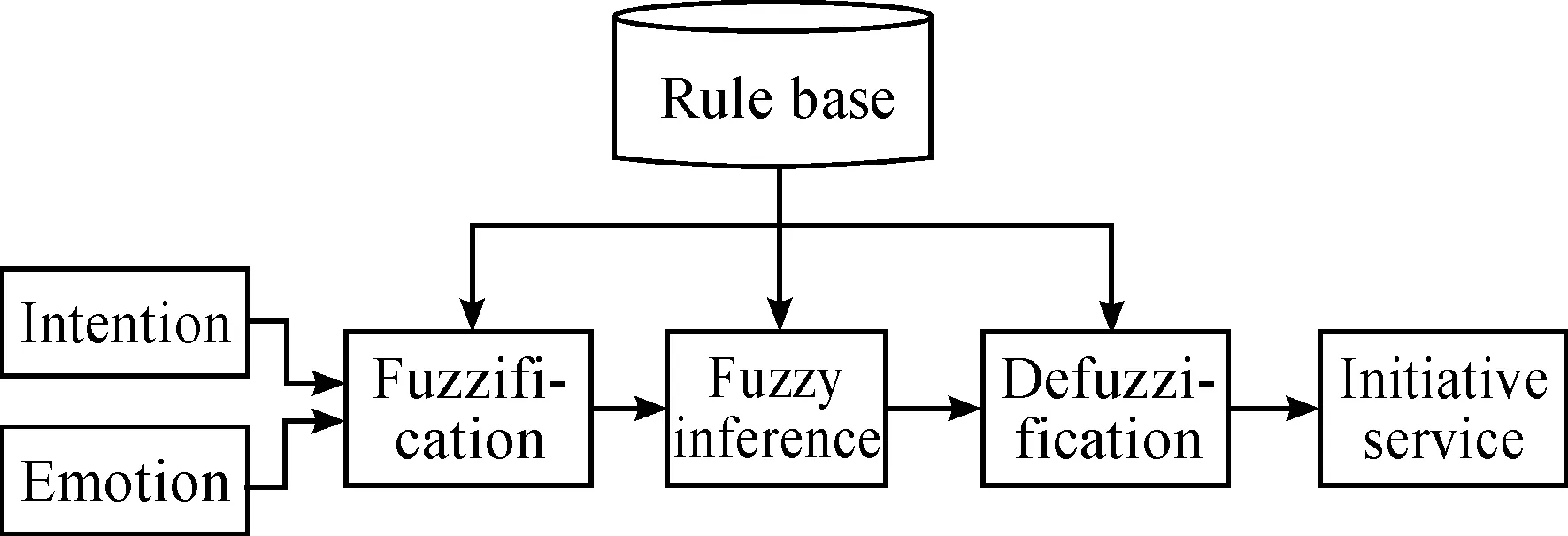
Fig.5 Fuzzy production rules model.
3.3.1 Fuzzification
There are many kinds of intention of users when robot service for people. When the intention is estimated, the intention level (IL) of user’s desire is divide into four levels, i.e., urgent (U), normal (N), slight (S), and needless (NL).
Emotional state of humans is usually divided into seven categories, i.e., happiness, surprise, fear, neutral, disgust, sadness, and anger. For each categories, the emotional state level EL can be divided into five levels, i.e., very strong (VS), strong (S), normal (N), weak (W), very weak (VW).
The level of robot’s tasks and emotional states are fuzzified as IL (i.e., U, N, S, NL) and EL (i.e., VS, S, N, W, VW), respectively, which are the same as humans’ in order to achieve smooth communication between humans and robots.
3.3.2 Fuzzy inference and defuzzication
The intention and emotional state of robots can be obtained by using IF-THEN rules shown in Eq. (1) on the basis of fuzzification.
If Humans={ILandEL}
Then Robots={ILandEL}
(1)
The initiative service of robots includes two kinds of service, i.e., task execution and emotion adaption.
补救措施:如果实际施工中遇到黏锤现象,则可考虑下列办法解决。一是让钻机的钢丝绳受力,并将钻机尾部吊起,然后在钻机尾部缓慢增加配重,但要注意缓慢增加,避免钢丝绳拉断。二是如黏锤现象发生时现场具备空压机,则可用钢管作为导气管伸入到钻孔底部,边送气边调整钢管位置,此种方法见效较快,一般不会超过1小时即可解决黏锤现象。
For task execution, it will generate the corresponding intention to perform a task when it receives user’s demands, and according to the users’ desire level of demands, the corresponding task execution (TE) and the rules are expressed in Eq. (2). For instance, task execution can be expressed as the water quantity in drinking service is large amount, normal, small amount and none.
If Robot={IL}
ThenTE
(2)
For emotion adaption, the three-dimensional emotion space is used to generate robot’s emotion to maintain consistency between robots and humans. It can generate its own emotional state to adapt to users according to the emotional state of users. The emotion adaption of robots (EA) is expressed through screen, mechanical arm, and other executive agencies, in which each emotional state is divided as very strong (VS), strong (S), normal (N), weak (W), very weak (VW). And the rules are expressed in Eq. (3).
If Robot={EL}
ThenEA
(3)
4 Experiments on Initiative Service Model for Drinking Service
In our daily life, there is a significant relationship between people’s drinking habits and the health of the body. In this paper, experiments on drinking service are performed to validate the proposal. In the scenario of drinking service, how often and how much should people drink is an important problem. The goal of the initiative service model is to ensure that people can drink water at the right time and supplement enough water.
4.1 Drinking water demand analysis
People often forget to drink water because of tedious daily works, and they only drink water when they feel thirsty. However, the body has been lack of water when they feel thirsty. People lose fluid so rapidly that the brain can’t respond in time. Therefore, it is hoped that the robot can provide water initiatively according to the demands of users to ensure the health of people.
In addition to drinking time, water quantity is another important thing in drinking habits. When you drink too much water, you may develop a condition known as hyponatremia, in which the excess water floods your body’s cells, causing them to swell up. Lack of water, or dehydration inversely, reduces the amount of blood in your body, forcing your heart to pump harder in order to deliver oxygen-bearing cells to your muscles. The amount of daily drinking water of an adult is 1500~2000 mL according to a survey. And the quantity of each time is 100~400 mL approximately. Furthermore, factors such as speech, physiological signal, temperature, humidity, and gender affect people’s drinking water requirements[23].
Usually, talking makes human short of water, and we want to drink water when talking for more than 20 minutes continuously ordinarily. Thus, it hints that users need to drink water when they speak a lot or the voice becomes hoarse. The length of speech can be obtained by recording equipment and timers. Firstly, a fixed threshold is set, and then two sound acquisition units are set up. Recording equipment starts recording when the intensity ratio of two sound signals is larger than the threshold, and stops when the ratio is less than the threshold. At the same time, the length of speech is acquired by timer during recording. In addition, the frequency of sound decreases when voice becomes hoarse. The collected speech set is processed to realize frequency spectrum analysis, in which the change of frequency is obtained to determine the change of tone.
The body will consume a lot of water after exercise, therefore, exercise is an important factor affecting people’s drinking water demand. The common measures of exercise intensity are oxygen intakes and heart rate. Heart rate is easy to measure with a small instrument, while the measurement of oxygen intake is not easy to get since it needs expertise and a large apparatus[24]. Thus heart rate is adopted to calculate users’ exercise intensity in this paper, which is obtained by sphygmomanometer.
In addition, environmental factors also affect people’s drinking water demand. For example, the amount of water will increase in demand when the temperature rises or humidity decreases. For example, daily water requirements for any given energy expenditure in temperate climates (20 ℃) can triple in very hot weather (40 ℃), as shown in Fig.6[25]. In addition to air temperature, other environmental factors also modify sweat losses, including relative humidity, air motion, solar load, and choice of clothing for protection against sweat losses. And the personal information (e.g., gender and age) affects drinking demands as well. A study from Maastricht University in the Netherlands found that women lose more water during exercise than men[25].
4.2 Experiments on drinking service
Experiments are performed using the multi-modal emotional communication based human-robot interaction (MEC-HRI) system[21], which consists of 3 NAO robots, 2 mobile robots, Kinect, eye tracker, 2 high-performance computers (i.e., a server and a workstation), and other wearable sensing devices as well as data transmission and network-connected devices. The topology structure of MEC-HRI system is shown in Fig.7. And we selected 3 men and 2 women who are within 20-25 years old as the experimenters. In the experiment, some foundational data, such as humidity, temperature, and physiological data are collected under our supervision. If there is a big mistake in acquiring information such as physical condition and environment, we will intervene in the data collection until it returns to normal. Thus the reliability of the collected data is guaranteed by our supervision. The scenario of drinking service is shown in Fig.8.
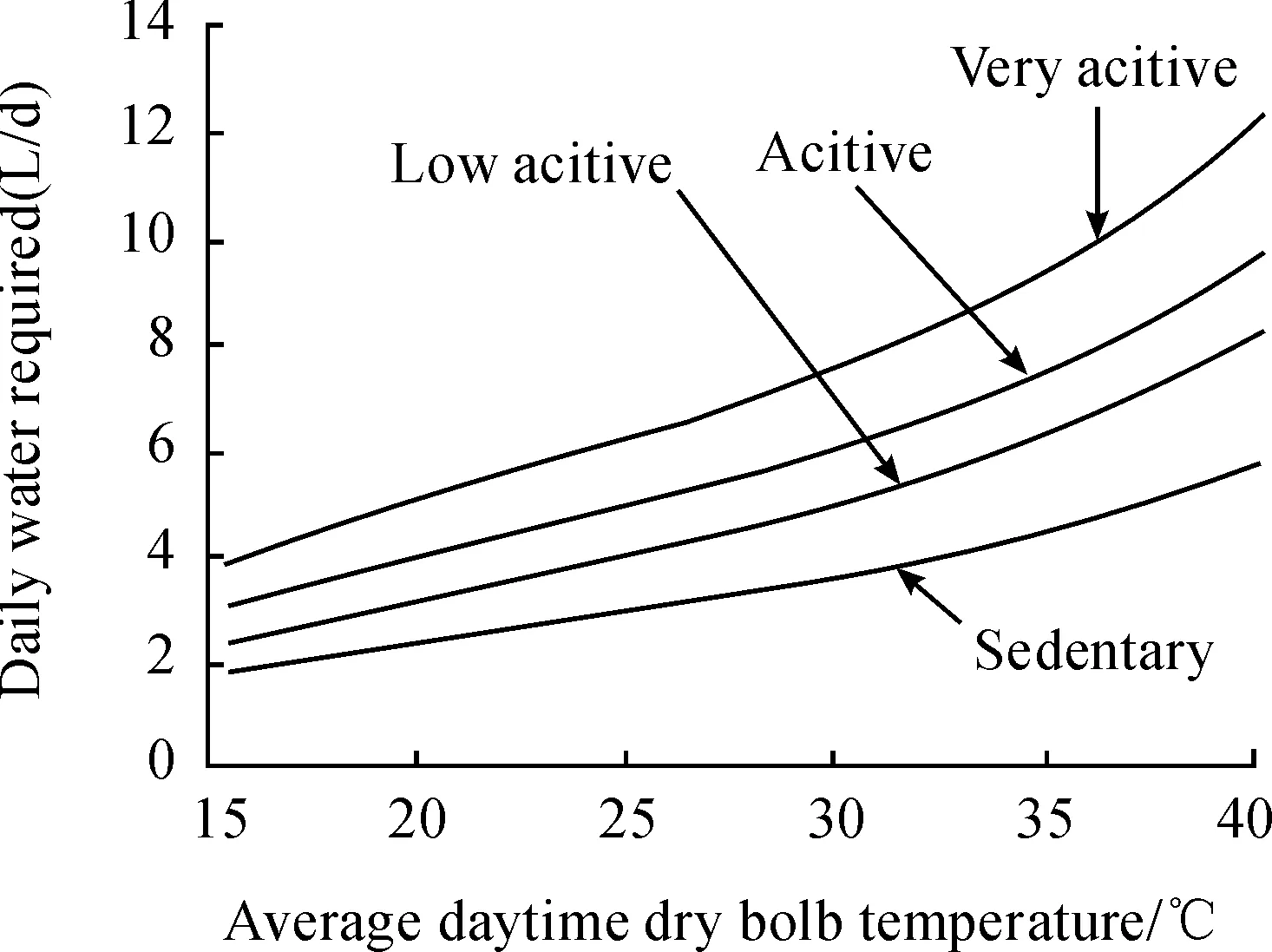
Fig.6 Relationship between temperature and drinking need[25].
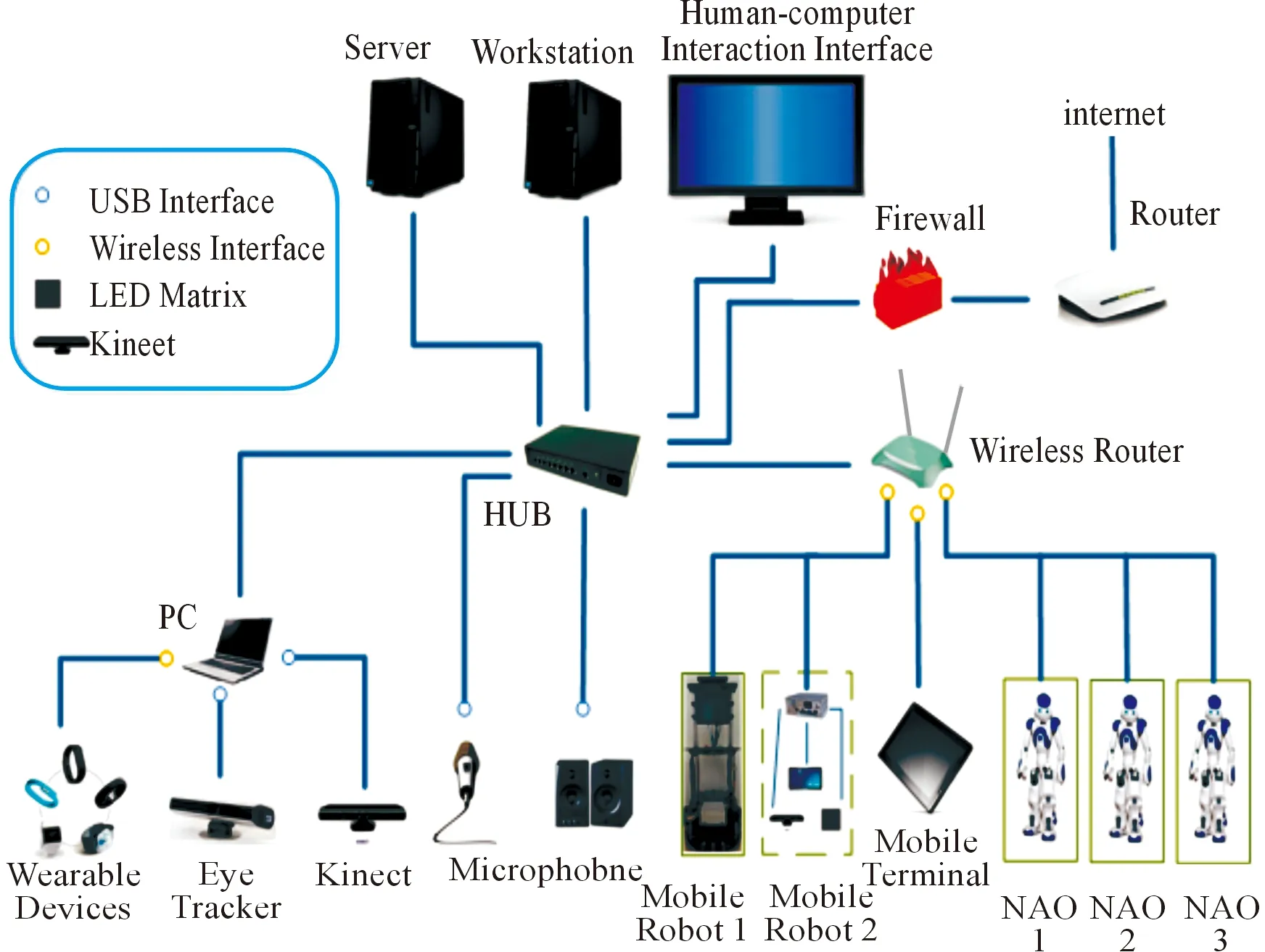
Fig.7 The topology structure of MEC-HRI system.

Fig.8 Scenario of “drinking service”.
People often forget to drink water because of busy work, and they may drink water when they feel thirsty. However, when people feel thirsty, it may have been a long time since the body has been lack of water. To solve above problems and ensure human health, firstly, the factors that influence humans’ drinking water demands are selected after in-depth analysis, including physical activity, physical condition, and environment. Secondly, drinking time and water quantity are inferred according to correlation analysis between these factors and water demand. Thus, robots can provide water to users timely and moderately even if users are unaware of their lack of water or forget to drink water. Consequently, initiative service can ensure a real-time and rationality drinking service.
User’s information (e.g., speech, physiological, signal, and gender) and environmental information (e.g., temperature and humidity) are captured by the underlying hardware including Kinect, eye tracker, microphone, and other wearable devices respectively. Then emotional state and personal intention are obtained by emotion recognition and intention understanding, respectively, and users’ water demand is obtained by the demand analysis model.
When the intention of drinking is estimated, the intention level can be divided as urgent (U), normal (N), slight (S), and needless (NL) and the emotion state level of human is divided as very strong (VS), strong (S), normal (N), weak (W), very weak (VW). According to Section 2.3, the water quantity provided by the robot is divided into three level correspondingly, i.e., large amount (400 mL), normal (300 mL), small amount (100 mL) and none (0 mL). The emotional state level of robot is divided as VS, S, N, W, and VW.
4.3 Experimental results and discussion
Experimental results are recorded, including activities from 5 experimenters, drinking time and water quantity at each time, as shown in Table 1. The curve of drinking time that robots serve the user initiatively shown as the solid line in Fig.9a. The time when experimenter feels thirsty and orders robot to provide water is shown as the dotted line in Fig.9a. The curves of water quantity supplied initiatively to the user each time are shown as the solid line in the Fig.9b. The water quantity that experimenter orders robot to provide is shown as the dotted line in the Fig.9b.
In the experiments, two experimenters began to discuss at 9:40, and after a period of discussion, robot recorded this discussion time has reached 20 minutes, then the robot renders a drinking service at 10:00. However, experimenters were busy discussing until they felt thirsty and drank water at 10:30. As time goes by, temperature rose after 11:00, robot provides normal amount of water to experimenters after the temperature reached 30℃. Aircondition is used in our laboratory due to the heat in summer, which makes air dry, thus robot provided water to experimenters at 12:50 and 14:00, while experimenters felt thirsty and drank a lot of water at 12:00 and 14:00 in fact. Then experimenters ran for 30 minutes during 19:00—19:30, and heart rate of the experimenter was transmitted to robot, from which robots judged that the experimenter have a strong exercise and served experimenters drink a large amount of water at 19:30, since their body had lost a lot of water due to sweat losses.
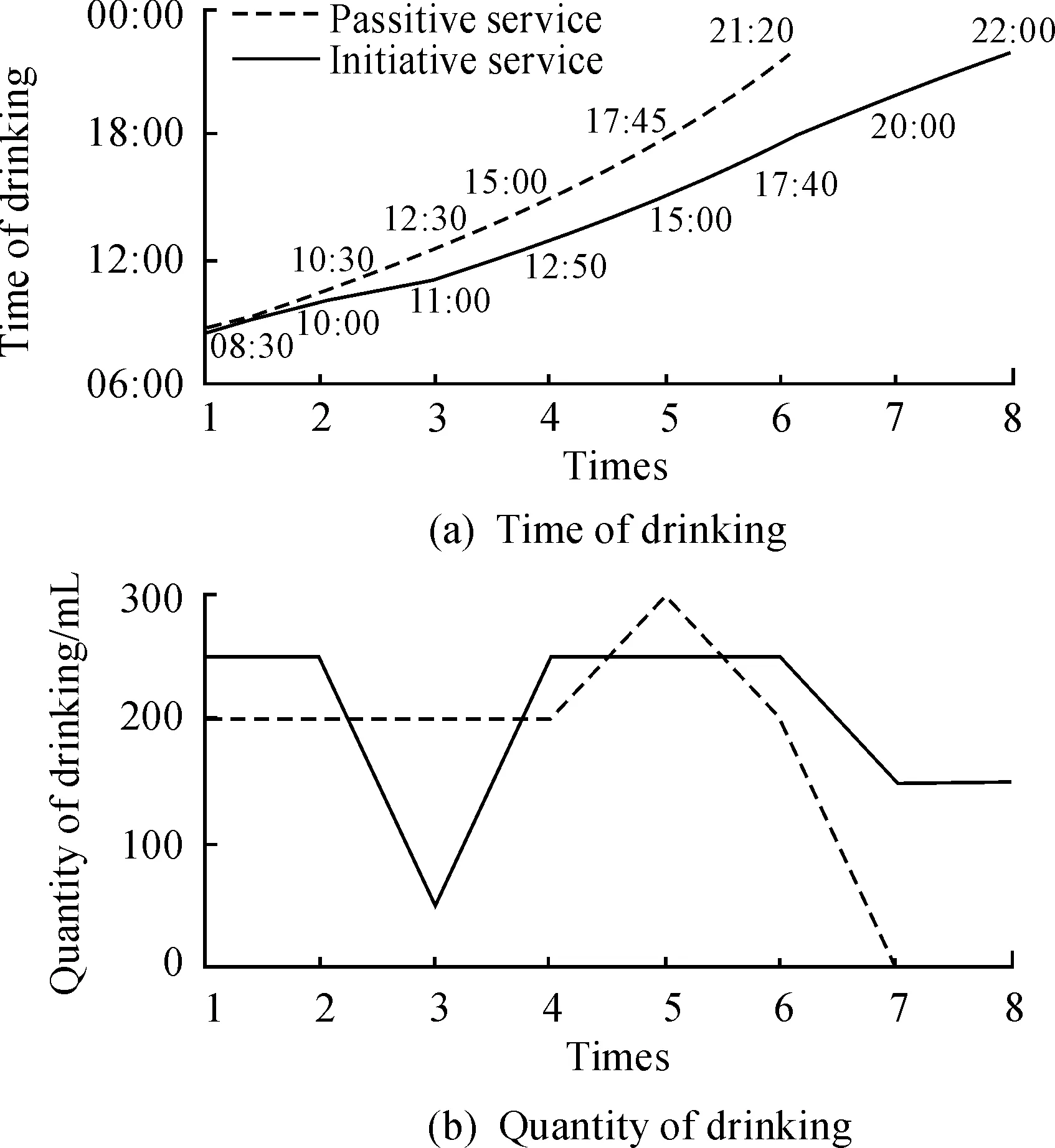
Fig.9 Experimental results of drinking service.
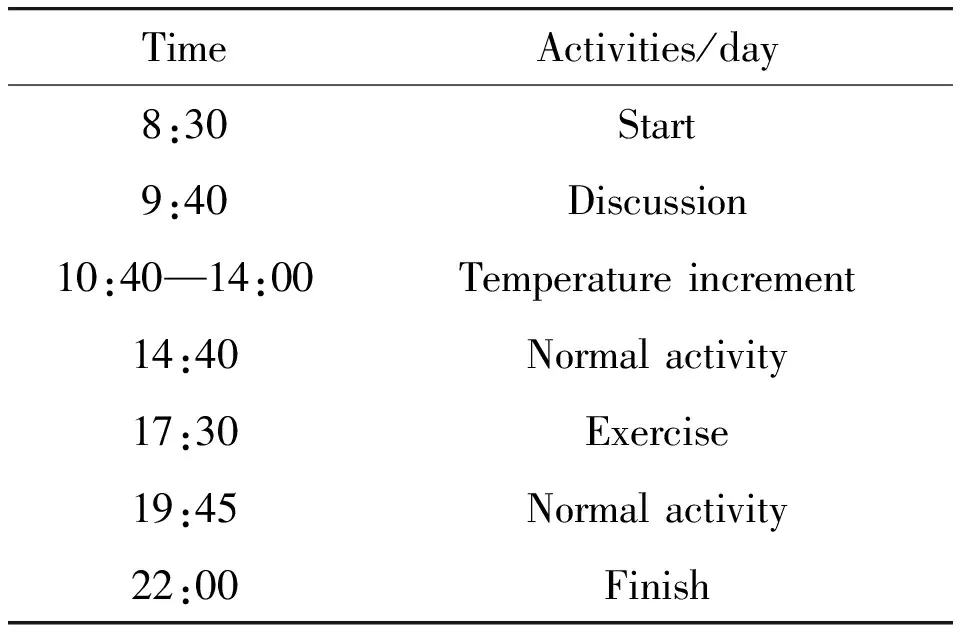
Table 1 The activities of experimenters.
From the experiment results, the time of passive service lags behind the initiative service 30 minutes on average; the initiative service renders 2 times water supply more than passive service on average; in initiative service, the water quantity for each time is decided according to the loss of water in the body, which is more reasonable.
It can be seen that the drinking time of initiative service and passive service is consistent when the water loss of the body is serious, for example, the drinking time and water quantity provided by initiative service is the same as passive service after exercise, but it is not be noticed by experimenters when the body drains a small amount of water. Experimenters do not drink water until they feel thirsty, which leads to belated water supplying by passive service.
5 Conclusion
An initiative service model for service robot is proposed. Firstly, multi-modal information (e.g., speech, expression and gesture) is collected by the underlying hardware (e.g., Kinect, eye tracker, and microphone). And deep cognitive information (i.e., emotional state and personal intention) is acquired by using emotion recognition and intention understanding. User’s demands are obtained by a demand analysis model using deep cognitive information. Finally, robot executes corresponding task and realizes emotion adaptation. By using this model, robots could understand actual demands of people in such an initiative and humanized way and provide corresponding service correctly.
Drinking service experiments are performed by 3 men and 2 women aged from 20 to 25 years old. For initiative service, robots can render drinking service for the user in a timely manner. Experimental results show that the time of passive service lags behind the initiative service 30 minutes on average and the water supply in initiative service is 2 times more than passive service on average, which avoids the situation that the body is short of water. In addition, by initiative service, water quantity for each time is more reasonable, which ensures that the user can supplement enough water.
Initiative service of service robot is a new concept, which promotes the realization of intelligence and humanization. Initiative service model can be applied to many scenarios in our daily life, e.g., family service, caring for the elderly, medical rehabilitation.
Acknowledgement
This work was supported by the National Natural Science Foundation of China under Grants 61403422 and 61273102, the Hubei Provincial Natural Science Foundation of China under Grant 2015CFA010, the Wuhan Science and Technology Project under Grant 2017010201010133, the 111 project under Grant B17040, and the Fundamental Research Funds for National University, China University of Geosciences (Wuhan).
[1]A.D.Nuovo, G.Acampora, and M.Schlesinger, Guest editorial cognitive agents and robots for human-centered systems,IEEETransactionsonCognitive&DevelopmentalSystems, vol.9, no.1, pp.1-4, 2017.
[2]F.Zhou, G.Wang, G.Tian, Y.Li, and X.Yuan, A fast navigation method for service robots in the family environment,JournalofInformation&ComputationalScience, vol.9, no.12, pp.3501-3508, 2012.
[3]S.Bedaf, G.J.Gelderblom, D.S.Syrdal, and H.Michel, Which activities threaten independent living of elderly when becoming problematic: inspiration for meaningful service robot functionality,Disability&RehabilitationAssistiveTechnology, vol.9, no.6, pp.445-452, 2014.
[4]J.Jiang and T.U.Dawei, Human-robot collaboration navigation of service robots for the elderly and disabled in an intelligent space,CAAITransactionsonIntelligentSystems, vol.9, no.5, pp.560-568, 2014.
[5]S.Xu, D.Tu, Y.He, S.Tan, and M.Fang, ACT-R-typed human-robot collaboration mechanism for elderly and disabled assistance,Robotica, vol.32, no.5, pp.711-721, 2014.
[6]X.Cheng, Z.Zhou, C.Zuo, and X.Fan, Design of an upper limb rehabilitation robot based on medical theory,ProcediaEngineering, vol.15, no.1, pp.688-692, 2011.
[7]S.Iengo, A.Origlia, M.Staffa M, and A.Finzi, Attentional and emotional regulation in human-robot interaction, inProceedingsof21stIEEEInternationalSymposiumonRobotandHumanInteractiveCommunication, Paris, France, 2012, pp.1135-1140.
[8]N.Hendrich, H.Bistry, and J.Zhang, Architecture and Software Design for a Service Robot in an Elderly-Care Scenario,Engineering, vol.1, no.1, pp.27-35, 2015.
[9]Y.Cai, Z.Tang, Ding Y, and B.Qian, Theory and application of multi-robot service-oriented architecture,IEEE/CAAJournalofAutomaticaSinica, vol.3, no.1, pp.15-25, 2016.
[10] A.Hermann, J.Sun J, Z.Xue, S.W.Ruehl, J.Oberlaender, A.Roennau, J.M.Zoellner, and R.Dillmann, Hardware and software architecture of the bimanual mobile manipulation robot HoLLiE and its actuated upper body, inProceedingsofIEEE/ASMEInternationalConferenceonAdvancedIntelligentMechatronics, San Diego, 2013, pp.286-292.
[11] R.Pinillos, S.Marcos, R.Feliz R, E.Zalama, and J.Gómez-García-Bermejo, Long-term assessment of a service robot in a hotel environment,Robotics&AutonomousSystems, vol.79, pp.40-57, 2016.
[12] L.F.Chen, Z.T.Liu, Wu M, F.Y.Dong, and K.Hirota, Multi-Robot Behavior Adaptation to Humans’ Intention in Human-Robot Interaction Using Information-Driven Fuzzy Friend-Q Learning,JournalofAdvancedComputationalIntelligence&IntelligentInformatics, vol.19, pp.173-184, 2015.
[13] X.Wang and C.Yuan, Recent Advances on Human-Computer Dialogues,CAAITransactionsonIntelligenceTechnology, vol.1, no.4, pp.303-312, 2016.
[14] L.F.Chen, Z.T.Liu, M.Wu, M.Ding, F.Y.Dong, and K.Hirota, Emotion-Age-Gender-Nationality Based Intention Understanding in Human-Robot Interaction Using Two-Layer Fuzzy Support Vector Regression,InternationalJournalofSocialRobotics, vol.7, no.5, pp.709-729, 2015.
[15] B.Schuller, A.Batliner, S.Steidl S, and D.Seppi, Recognizing Realistic Emotions and Affect in Speech: State of the Art and Lessons Learnt From the First Challenge,SpeechCommunication, vol.53, no.9, pp.1062-1087, 2011.
[16] G.Sandbach, S.Zafeiriou, M.Pantic M, and L.J.Yin, Static and dynamic 3D facial expression recognition: A comprehensive survey,Image&VisionComputing, vol.30, no.10, pp.683-697, 2012.
[17] M.E.Ayadi, M.S.Kamel, and F.Karray, Survey on speech emotion recognition: Features, classification schemes, and databases,ElsevierScienceInc, vol.44, no.3, pp.572-587, 2011.
[18] C.N.Anagnostopoulos, T.Iliou, and I.Giannoukos, Features and classifiers for emotion recognition from speech: a survey from 2000 to 2011,ArtificialIntelligenceReview, vol.43, no.2, pp.155-177, 2015.
[19] Z.T.Liu, K.Li, D.Y.Li, L.F.Chen, and G.Z.Tan, Emotional feature selection of speaker-independent speech based on correlation analysis and Fisher, inProceedingsofthe34thChineseControlConference, Hangzhou, China, 2015, pp.3780-3784.
[20] Mehrabian A, Communication without words,CommunicationTheory, pp.193-200, 2008.
[21] Z.T.Liu, F.F.Pan, M.Wu M, W.H.Cao, L.F.Chen, J.P.Xu, R.Zhang, and M.T.Zhou, A multimodal emotional communication based humans-robots interaction system, inProceedingsofthe35thChineseControlConference, Chengdu, China, 2016, pp.6363-6368.
[22] K.Hirota, Fuzzy inference based mentality expression for eye robot in affinity pleasure-arousal space,JournalofAdvancedComputationalIntelligenceandIntelligentInformatics, vol.12, no.3, pp.304-313, 2008.
[23] M.Hao, W.H.Cao, M.Wu, Z.T.Liu, L.F.Chen, and R.Zhang, An initiative service method based on intention understanding for drinking service robot,IECON, 2017
[24] J.She, H.Nakamura, and K.Makino, Selection of Suitable Maximum-heart-rate Formulas for Use with Karvonen Formula to Calculate Exercise Intensity,InternationalJournalofAutomationandComputing, vol.12, no. 01, pp.62-69, 2015.
[25] M.N.Sawka, N.Samuel, and P.R.Cheuvront, Robert Carter III PhD, MPH, Human Water Needs,NutritionReviews, vol.63, no.s1, pp.s30-s39, 2005.
猜你喜欢
设备管理与维修(2022年21期)2022-12-28
舰船科学技术(2022年20期)2022-11-28
建材发展导向(2021年11期)2021-07-28
红领巾·探索(2019年6期)2019-08-01
今日农业(2019年10期)2019-01-04
电子制作(2017年17期)2017-12-18
工业设计(2016年7期)2016-05-04
工业设计(2016年7期)2016-05-04
工业设计(2016年10期)2016-04-16
中国塑料(2015年4期)2015-10-14
 CAAI Transactions on Intelligence Technology2017年4期
CAAI Transactions on Intelligence Technology2017年4期
- CAAI Transactions on Intelligence Technology的其它文章
- An Efficient Approach for The Evaluation of Generalized Force Derivatives by Means of Lie Group
- Magnetic Orientation System Based on Magnetometer, Accelerometer and Gyroscope
- A Mixed Reality System for Industrial Environment: an Evaluation Study
- Diagnosis System for Parkinson’s Disease Using Speech Characteristics of Patients and Deep Belief Network
- Visual Navigation Method for Indoor Mobile Robot Based on Extended BoW Model
- A Lane Detection Algorithm Based on Temporal-Spatial Information Matching and Fusion