
A Lane Detection Algorithm Based on Temporal-Spatial Information Matching and Fusion
2018-01-12 08:30JunWangBinKongTaoMeiandHuWei
Jun Wang, Bin Kong, Tao Mei, and Hu Wei
1 Introduction
Unmanned vehicles have a significant influence on the development of national defense, society, economy, and science and technology and are currently part of the strategic research objectives of all countries in the high-tech field[1-3]. Unmanned systems consist of multiple functional modules with various functions, including environmental perception, behavioral decision-making, path planning, vehicle motion control, and so on. Lane detection is one element of environmental perception and has a very important role in the behavioral decision-making and path planning of unmanned vehicles[4-6].
Lane detection has been a hot research topic since the 1990s[11-18]and has been widely used in driver assistance systems, serving as lane departure warning system for highway environments with simple road conditions and well-defined lanes[19-21]. Studies show that the usage of lane departure warning systems in the United States has driven down the lane departure crashes of small cars by 10% and those of large pickups by 30%[7,8].At the University of California PATH Program, for example, magnetic markers were embedded in the road and used with a magnetometer mounted to the front of the car[9]. While this is a very reliable system, the implementation cost is too high to be practical in all roads. Another system, implemented at the IV Lab at the University of Minnesota, combines differential GPS information with high resolution digital maps to determine lane position and is demonstrated to work in all weather conditions[10]. However, this system requires digital maps with under a meter of accuracy which currently do not exist at wide enough level to make this system practical. Based camera- systems provide an extremely rich stream of data produced by imaging equipment, typically mounted in the crew cabin, to identify lane lines.
In recent years, studies on lane detection have always focused on the applicability, robustness, timeliness, and other characteristics of the algorithm[22-26]. In terms of their features, detection algorithms can be categorized into the following two classes: (1) feature-based and (2) model-based algorithm.
The former primarily uses the road surface features, such as gradient, color, texture, and so on and extracts road information by detecting the growth of the region and variations in the edge gradient[27-35]. In Ref.[29], an inverse perspective projection transformation is applied to search the virtual image of the ground plane for the horizontal brightness contour and to detect the segmented region by changing the brightness via the adaptive threshold. In Ref.[30], the lane direction in the near-vision field is found via the edge distribution function (EDF), and a direction-changeable filter is used to process the image, suppress the interference of unwanted information and noise, and effectively enhance the lane information. However, edge features depend on the quality of the input image, so that the processing effects of the algorithm in which shadows, watermark, and/or any other noise interfere are not good. To solve these problems, a gradient-enhanced algorithm is proposed[31], and a color conversion vector is generated and converted, thereby attaining the gray-level image with the maximum lane gradient and effectively reducing shadow interference. Ref.[32] proposes the conversion of the RGB image into the CIE color space for significance analysis and the use of k-means clustering to calculate the lane section obtained from image segmentation. In Ref.[33], linear analysis is conducted on each color channel of the RGB image, which facilitates the calculation of the color distribution of the road surface and signs and the segmentation and extraction of the lane region. In Ref.[34], the calculation is simplified: the size of the input color image is reduced, the Bayes classifier is used, and the likelihood of each pixel of the road surface is determined, with the image segmented into two sections, the road and non-road sections. The feature-based lane detection algorithm is chiefly characterized by insensitivity to road shape and by a relatively higher robustness; however, it is more sensitive to shadows and watermarks and involves a relatively complicated calculation process.
The model-based algorithm transforms road detection into the solution of the road model[36-47, 51, 52]. Considering that the road has a specific model, it is modeled to exert some constraints on and simplify the detection process. Given that the model accounts for the overall road status, with the parametric representation of the road, the model-based algorithm has a strong resistance to the interferences of shadows, watermarks, and other external influences.
The model-based algorithm can be subdivided into the image space-based algorithm and the top-view space-based algorithm. The former is used to establish lane line models to detect the lane lines in the original image space. Representative studies on the model algorithm based on the vanishing point cite the following sources: in Ref.[42], a lane detection algorithm based on the spline curve model is proposed. The spline curve is used to characterize the lane line model in the original image space. The concept of the vanishing point is formed based on the perspective projection transformation. By segmenting the image plane and detecting lines through the Hough transform, the vanishing point is predicted with the control point of the spline curve used for fitting the lane, thereby ultimately obtaining the final lane by fitting the spline curve using the control point. In Ref.[43], a CHEVP algorithm is put forward, with the probability of the vanishing line based on the model of the vanishing point. The vanishing point and the vanishing line are predicted by iteratively introducing the Hough transform. In Ref.[44], the vanishing point and the vanishing line are tracked based on the CHEVP algorithm by introducing the particle filter algorithm. Considering the results of the adjacent frames in the lane detection process, the algorithm is robust against occlusions, shadows, and traffic signs. In Ref.[50], a new structured road detection algorithm based on the well-distributed and aperiodic B-spline model is proposed. The edge image is extracted using the Canny edge detection algorithm, and the least squares is used to fit the road surface markings. The middle line of the road is finally obtained from the extracted road surface markings, thereby fitting the road. To accurately locate the curve, the control point of the road model is solved using the maximum deviation of the position shift (MDPS). In Ref.[51], a lane detection algorithm is proposed based on the B-Spline, and the borders of the road are assumed to be two parallel straight lines. Road detection is abstracted as the middle line of the road, and the B-spline curve is used to fit the road. The algorithm based on the original image space model is vulnerable to non-edge interference because the adopted lane detection model cannot reflect the actual road structure and the detection rate is not very high.
The algorithm based on the top-view space model obtains the original image from the top-view space via reverse perspective transformation and establishes a lane model to detect the lane. As mentioned in Ref.[41], Pomerleau et al. enhanced the constraints on the algorithm with the clothoid-based lane model on the assumption that the width between the lanes is fixed. The algorithm is conducive to the rapid location of the road surface markings to meet the constraints in the image and has good timeliness in a relatively simple road environment. When the road model is complex, that is, the road widens or the lane is missing, the detection results are undesirable. In Ref.[45], a rapid structured road detection algorithm based on the hyperbola is introduced, and it involves extracting two parallel marking lines of the road via the mid-to-side method. The algorithm is simple and has strong anti-interference, but adopts the hyperbola for fitting the road. When more interference points appear, the fitting curve of the road fluctuates violently. A statistical Hough transform-based lane detection algorithm with gradient constraints is introduced for the first time for lane detection in Ref.[47], where the original image is converted into the top-view space by conducting reverse perspective transformation, calculating the brightness, gradient, size, and direction of the image, extracting the lane features by means of the gradient constraints, and finally detecting the lane through the statistical Hough transform. This method is effective in freeways and other straight road environments, but poor in curvy roads, especially in those marked with dotted lines. The TLC algorithm, which is used in Ref.[46] as a typical algorithm for lane detection in the top-view space, directly converts the original image captured with a camera into the top-view image by creating geometric correspondence between the visual plane and the top-view plane, extracting the edge features from the top-view image, searching the lane features, and finally fitting the lane using the quadratic curve. A lane detection algorithm based on the top-view space is offered in Ref.[40]. First, the contours are extracted after the adaptive binarization of the original image. Next, it is converted into the top-view space through reverse perspective transformation. Third, the lane features from the top-view space are searched using linear cluster analysis. Finally, the lane is fitted using the cubic B-spline. This algorithm exerts certain constraints on the detection process by introducing the actual road model parameters. However, given the single-frame image information for detection and the less information and presence of more interference in the real road scene (e.g., shadows, stains, lane wear, etc.), they are likely to cause mistakes in lane detection.
Considering these issues, a lane detection algorithm based on the matching and fusion of the top-view space is proposed in this study. The image features are converted into the top-view space after segmentation using reverse perspective transformation. The constraints on the detection process are derived by introducing the actual road model parameters. Combined with INS information, the continuous multi-frame lane feature information is integrated into a single-frame feature image using the matching algorithm. Consequently, the lane information containing abundant data within a wider range is obtained, the interference of unrelated edges is reduced, and the anti-interference ability in the lane detection is improved. The detection results of adjacent frames are tracked and predicted, thereby establishing a long-distance and wider-range lane-tracking model of the top-view space and further improving the accuracy of lane detection.
2 Implementation of the Algorithm
2.1 Algorithm flowchart
The algorithm proposed in this study is divided into the following parts. (1) Image segmentation is mainly designed for image binarization and noise filtering. (2) Reverse perspective transformation is conducted to convert the results of image segmentation into the top-view space and facilitate subsequent processing. The core of the lane detection algorithm in this study is processed in the top-view space. (3) The position relations between multi-frame images in the top-view space within a continuous time are predicted using the unmanned vehicle INS information, specifically through the matching and fusion of the feature information. The matching and fusion of the continuous multi-frame lane data are implemented, and more abundant lane data are obtained. (4) The lane search results are clustered to obtain the lane data from the above item classified through fuzzy clustering analysis, and the feature data of each lane are finally classified. (5) Lane fitting is conducted to classify the lane feature data as the above item is fitted into a parameter curve using the least-squares fitting algorithm. (6) Lane tracking is then applied using the Kalman filter algorithm to establish the prediction-tracking relationship between the frames before and after the lane detection and further improve the accuracy and efficiency of lane detection. The entire process involved in the lane detection algorithm is shown in Fig.1.
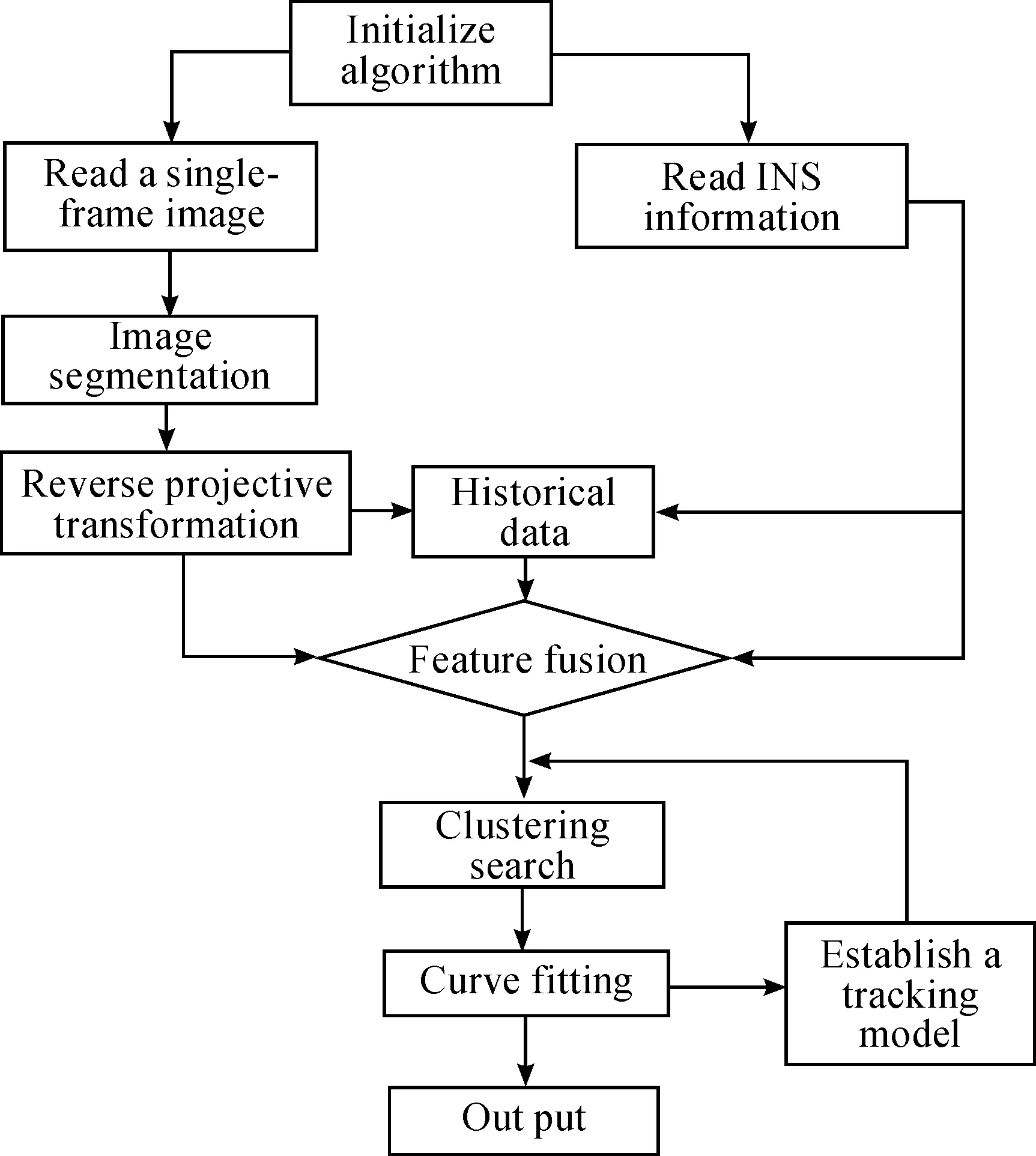
Fig.1 Flowchart of the lane detection algorithm.
2.2 Image segmentation
Urban roads are structured roads with some white and yellow markings that are particular to them. Road detection essentially consists of conducting lane-marking detection in the resultant image. The most commonly used method is image segmentation, a process and technique in which the captured image is divided into a plurality of specific regions with unique properties. Objects of interest are also raised, as well as the key to shift from image processing to image analysis.
Image segmentation typically involves contour extraction and edge detection. The simplest method of contour extraction is global binarization, which involves the conversion of the gray-level image into a binary image based on a gradient threshold. This method results in apparent defects in the image detail, and it is a time-consuming and complicated process that hardly meets the requirements of timely road image processing. Using the local binarization method, the whole image is segmented into N windows according to certain rules, and all the pixels of each window is divided into two parts for binarization by a unified threshold T. Using the local adaptive binarization method[40]and based on local binarization, the settings of the threshold are optimized, and the threshold for the binarization of each pixel depends on the surrounding pixel, thereby better showing the details of the binary image.
The edge features contain important lane feature information. In the road image, the gray level at the junction of the lane and road surface changes dramatically and can be analyzed by edge detection. The basic idea of edge detection is to highlight the edge of the image locally using the edge enhancement operator and to extract the edge point set by setting the threshold. The commonly used detection operators include the differential operator, Laplacian operator, and canny operator[48,49]. The canny edge detection operator is a relatively new edge detection operator that allows the following: Gaussian filtration, prediction of the magnitude and direction of the gradient via the finite difference of the first-order partial derivatives, non-maxima suppression of the magnitude of the gradient, good edge detection and connection via the dual-threshold algorithm, and better balance between edge detection and noise reduction. Given that the lane is substantially extended longitudinally, the lane edge features can be effectively extracted along the direction of y.
The method of image segmentation in this study combines contour extraction and edge detection, through which the binary contour of the image is extracted using the local adaptive binarization algorithm and the contour noise is filtered. Using the edge detection algorithm, the edge features of the image in the longitudinal direction are extracted, and the boundary noise in the horizontal direction is filtered. Finally, the binary images obtained from the two methods are processed using the logical AND operator (&&), thereby attaining the desired effect of image segmentation. The implementation of the image segmentation algorithm is shown in Fig.2.
Fig.3b represents the contour extraction results, with good contour extraction effects, but with boundary noise in the horizontal direction. Fig.3c represents the edge extraction results, which show that the boundary noise in the horizontal direction is effectively suppressed, but too much contour noise is produced. Fig.3d represents the final results after the combination of the two, effectively filtering the contour noise and the boundary noise.
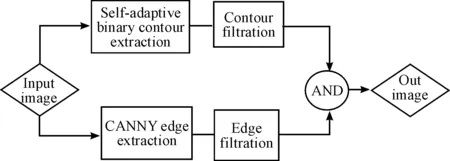
Fig.2 Flowchart of image segmentation.

Fig.3 Effect drawing of image segmentation: (a) the original image captured with a video camera, (b) the image after contour extraction and filtration, (c) the image after edge extraction and filtration, and (d) the final results of image segmentation.
2.3 Reverse perspective transformation
Given the presence of an included angle between the optical axis of the camera and the road when shooting, some visual attributes of the lane are difficult to intuitively represent in the camera plane. For instance, different lane lines are parallel and have relatively fixed spacing. In addition, the lane image matching between different frames is hard to implement in the camera plane. Thus, the lane data on the camera plane must be converted into the top view. In the top-view coordinate system, the shadows and interferences of other vehicles within the lane are eliminated using the lane attributes, and between-frame data matching and fusion are implemented.
The visual system of the unmanned vehicle consists of three coordinate systems: the image, camera, and world coordinate systems. The image coordinate system is a coordinate system of the image captured using a video camera. Each pixel serves as the unit, and the coordinates of the pixel (u,v) represent the column and row, respectively, where the pixel is located. The camera coordinate system is a 3D coordinate system with the camera as the physical center. The relationship between the image and the camera coordinate systems is established by the camera imaging model, usually using the pinhole camera model. Assuming that the light of the imaging model is cast on the video camera image via an infinitely small hole, a 3D scene is formed, as shown Fig.4. In the figure,xc,yc, andzcrepresents a 3D scene point under the camera coordinate system,Xc,Yc, andZcrepresent the coordinate axes of the camera, and f represents the focal length of the camera.
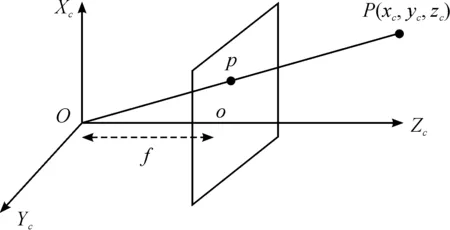
Fig.4 Perspective projection in the pinhole camera model.
The world coordinate system (WCS) refers to the absolute coordinate system of the camera in a real environment, the coordinate system in the unmanned vehicle system, or the coordinate system in the top-view space, as mentioned in this study paper, which consists ofXw,Yw, andZw. The relationship among the image coordinate system, camera coordinate system, and WCS are as shown in Fig.5. In the figure,Xw,Yw, andZwrepresent the WCS coordinate axes,Xc,Yc, andZcrepresent the camera coordinate axes, and u, v represent the image coordinate axes.
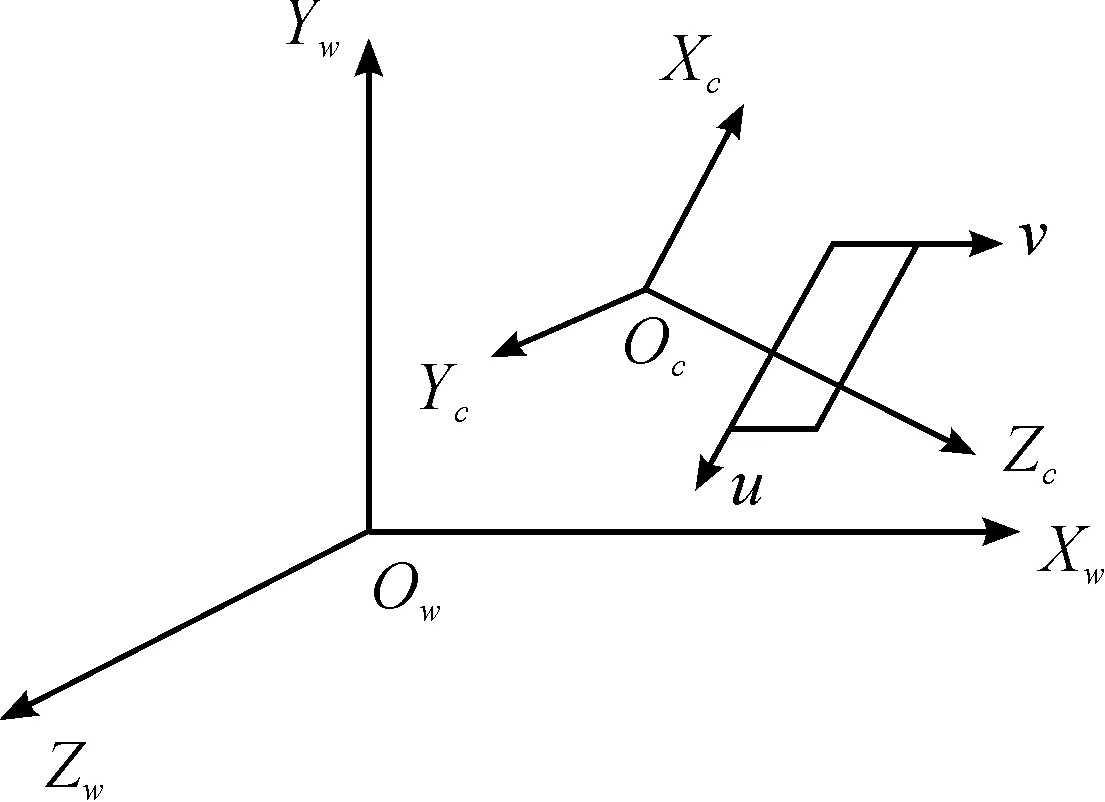
Fig.5 Relationship between the camera and WCS.
The conversion relationship between the image coordinate system and the WCS is as shown in Equation (1):
(1)
where dX, dYrepresent the physical dimensions of each pixel in the directions of theX-andY-axis, respectively,srepresents the scale factor,Rrepresents the spin matrix,trepresents the translation vector,fx=f/dXrepresents the scale factor in the direction of theU-axis,fy=f/dYrepresents the scale factor in the direction of the V-axis,M1represents the internal parameter matrix of the camera,M2represents the outer parameter matrix of the camera, andMrepresents the perspective projection matrix.
Reverse perspective transformation consists of the reverse of the perspective projection, which indicates the process in which the image space coordinates (u,v) on the camera plane are converted into those in the top-view space (Xw,Yw,Zw). The reverse perspective transformation matrix is obtained from the mapping between the image coordinate system and the top-view space coordinate system. Converting Equation (1),
(2)
whereNrepresents the 3×4 matrix determined by the internal and external parameters of the camera. Converting Equation (2),
(3)
whereN′ represents the 4×3 reverse perspective transform matrix.
NN′=E3
(4)
The reverse perspective transform matrixN′ can be obtained by calibrating the camera[50], and the (Xw,Yw,Zw) that corresponds to the image pixel (u,v) on each camera plane can be calculated by Equation (3). Fig.6 shows an effect drawing of the reverse perspective transformation after image segmentation.

Fig.6 Effect drawing of reverse perspective transformation: (a) the camera coordinate system and (b) top-view space coordinate system after reverse perspective transformation.
2.4 Matching and fusion of feature information
During the processing of single-frame image information, the single-frame image contains less information, as well as more interference in the real road scene, such as shadows, stains, wear, and so on, which are likely to cause lane detection errors. The lane feature information in the sequence of multi-frame images captured with a camera is retained. Given the INS speed of the unmanned vehicle and the angular speed information, the multi-frame lane information is matched and fused, which in turn retains the historical information of the road image captured while driving, builds a lane image within a wider range, and improves the current accuracy and robustness of lane detection.
Given the speed and angular velocity of unmanned vehicles, the equation for the position conversion is as follows:
E=B+VΔtcos(wΔt)
(5)
whereErepresents the end position,Brepresents the start position,Vrepresents the speed of vehicle,wrepresents the angular speed, and Δtrepresents the camera sampling cycle.
For multi-frame camera images converted into the top-view space within a period of time, the appropriate policy must be selected to obtain the image sequence fused into one and form continuous and effective information. The lane coordinates in the top-view space constantly change with the current position of the unmanned vehicle in the top-view space, given that the origin of coordinates constantly changes while driving. Thus, the first few frames of the lane position must be re-described every time the top-view space image is updated; that is, the position must be converted in accordance with certain laws of motion. InX-Yof the top view coordinate system, the travel direction of the unmanned vehicle is assumed to be in the direction of theY-axis, and the lane position of t in theX-Ycoordinate system is (xt,yt). When the acceleration of the unmanned vehicle can be ignored, the lane position oft+1 is calculated by the following equation:
(6)
(7)
whereVrepresents the speed of the unmanned vehicle and Δtrepresents the top-view image update cycle. When the angular speed of the unmanned vehicle isw, the rotation of the lane position in the coordinate system is calculated by the following equation:
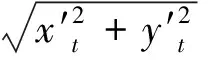
(8)
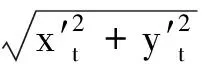
(9)
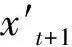

Fig.7 Effect drawing of feature matching and fusion: (a) the image of the current frame in the top-view space and (b) image after the matching and fusion of the feature information.
2.5 Lane clustering algorithm
After the feature matching and fusion of the sequence image data in the top-view space are completed, a lane feature image with abundant data is obtained. This contains the data information of multiple lanes, and the data information of each lane is classified as a class through cluster analysis. Cluster analysis is conducted on the feature image to classify the data of the feature image by lane features, with each cluster representing the feature data set of a lane, as in Fig.8. In this study, a linear cluster analysis algorithm based on the density features is adopted. By locating the high-density region with linear features that are separate from the low-density region, the feature dataset of different lanes is differentiated.

Fig.8 Diagram of the cluster analysis: (a) the original feature image and (b) cluster analysis Clustering is implemented on the lane feature image in this study as discussed below.
An overview of the presentedcluster algorithm is given in Algorithm 1.

Algorithm1Clusteringalgorithmproposedinthisstudy1.Q←changecolumnfromstarttoend2.S←findpixelformrowstarttoend3.iffindpixelvalue>0;do4.T←k⁃meansclusteringfromcurrentcolumntoend;5.ifhavek⁃meansclustering;do6.putpixeltoclusteringnumber;then7.putpixelvalue==0;8.else9.returnT;10. ifT(columnnumber)==length11. returnS;12. iffindpixelvalue==0;do13. returnS;14. if(rownumber)=width;do15. returnQ;16. ifQ(columnnumber)==length17. end;
2.6 Curve fitting
The general shape of a real urban road is regular, with a unitary trend appearing within a limited distance, so that the road shape is fully embodied by the quadratic curve, instead of any cubic curve, which is prone to the divergence phenomena caused by a small amount of data interference. The general quadratic equation is given by:
y=c0+c1x+c2x2
(10)
Using the least squares method, and substitutingc0,c1, andc2in the undetermined coefficients, the quadratic curve is plotted, with the corresponding data points close to the curve as much as possible. In general, the data points do not fall on the quadratic curve completely, which indicates that the corresponding coordinates have certain errors and that the curve equation is not satisfied. The overall error of all the data points is then expressed by the following residual sum of squares:
(11)
This is a triple function with regard to c0, c1, and c2, and k represents the total number of data points. The value of each line equation parameter is determined by taking the minimum value of the objective function. Assumingthe function:
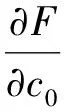
(12)
The following equation of a normal to a quadratic polynomial function is obtained, thereby finding the minimum point of the function:
(13)
The above equation is solved by the select all PCA Gaussian elimination method. The solutionsc0,c1, andc2are obtained, and the quadratic equation in question is therefore determined with the fitting results, as shown in Fig.9.
2.7 Lane tracking
The shaking of the vehicle body, light and shade changes, vehicle interference, and other factors during driving may cause image jitter, damages to lane markings, dirt pavement and shadows, thereby resulting in the failure to recognize single- or multi-frame lane images. Given that the video sequence changes continuously over time, the lane on the timeline also has some connection properties, and the position correlation between two adjacent frames can be established, thereby allowing the use of the detection results of the previous image to detect the lane in the current image. The algorithm proposed in this study is based on the top-view space model, where the lane changes between the adjacent frames are very insignificant. This is approximated by the following linear equation:
X′(k+1)=A(k)X(k)+B(k)
(14)
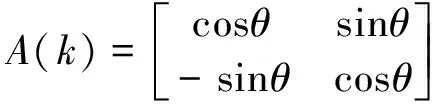
(15)
(16)
whereinX(k) represents the lane detection results at the time point ofk,X′(k+1) represents the prediction results ofk+1,θrepresents the included angle between the unmanned vehicle body and the road in front,xkandykrepresent the location of the unmanned vehicle in the image at the time point of k, and Δxkand Δykrepresent the changes in the location of the unmanned vehicle in the horizontal and longitudinal directions at the time point of k. These data can be obtained from the INS-based information. Using Equations (14-16), the most likely close-range lane region in the next frame can be predicted from the detection results of the lane image of the current frame, thereby achieving lane detection and tracking, with the lane feature search scope narrowed and the detection accuracy improved. An effect drawing of lane tracking is shown in Fig.10.

Fig.9 Effect drawing of curve fitting: (a) the original feature image and (b) the clustering results with white points and the least squares-based curve fitting results with a red curve.
3 Results
The algorithm proposed in this study is applied to the “Pioneer Smart” unmanned vehicle (Fig.11) developed by Hefei Institutes of Physical Science of the Chinese Academy of Sciences. It is furnished with several visual and INS sensors for lane detection, a camera for image acquisition (640 pixels×480 pixels, 15 Hz), and hardware and software platforms (Intel CoreTMi5-3120M CPU 2.5 GHz, RAM 2.5 G, VS2008, and OpenCV). Figs. 12-18 show the lane detection results of several typical urban roads using the algorithm: (a) the original image captured by a camera, (b) the feature image after image segmentation, (c) the feature image after matching and fusion, and (d) the image after lane tracking and fitting, where the lane tracking results are marked in green and the fitting results are marked in red.

Fig.10 Effect drawing of lane tracking: (a) the image after the matching and fusion in the top-view space and (b) the lane tracking, the results for which are marked in green and those for the curve fitting are marked in red.

Fig.11 Installation of the sensors of the unmanned vehicle.
Fig.12 shows an undulating road with double yellow lines in the middle. Given that the algorithm proposed in this study paper is based on reverse perspective transformation in the top-view space, the real lane model can be visualized intuitively in the top-view space. In an actual road environment, the lanes should be parallel to one another with fixed spacing and directly constrained by the actual road model parameters, so that the double yellow lines are not mistakenly detected as two lanes.

Fig.12 Effect drawing of lane detection and tracking with double yellow lines.
As shown in Figs.13 and 14, despite the presence of passing vehicles and shadows in the actual road environment, the algorithm proposed in this study has a good filtering effect, with the shadows filtered by image binarization and the vehicle interference eliminated based on the wider-range and abundant lane feature data obtained after the reverse perspective transformation in the top-view space and temporal-spatial information matching and fusion.

Fig.13 Effect drawing of lane detection and tracking in the presence of shadows and vehicle interferences.

Fig.14 Effect drawing of lane detection and tracking in the presence of shadows and serious vehicle interferences.
Fig.15 represents a road containing intersections with zebra crossings, traffic signs, and some other interfering factors. The lane feature information in the binary image of the current frame is blurred. The algorithm, along with the wealth of available wider-range data and lane tracking mechanism, introduced in this study allows the full use of historical information in the lane detection of the current frame, thereby avoiding any false detection or any missing caused by the lack of lane feature information on the current frame.

Fig.15 Effect drawing of lane detection and tracking in the presence of zebra crossings and arrow signs.
Figs.16 and 17 represent the curves depicted by the dotted lines. In Fig.16, the feature information of three lanes with four lines is well matched and fused, with good detection results. However, in Fig.17, given that the curvature of the dotted-line curve is too large, the field of view of the camera contains only the left lane and the present lane, with a total of three lines for matching and fusion. Thus, the final detection results are limited to the left lane and the current lane.

Fig.16 Effect drawing of lane detection and tracking of the curve depicted by dotted lines.

Fig.17 Effect drawing of lane detection and tracking with an excessively large curvature.
Fig.18 represents a curve that is depicted by dotted lines and contains a small intersection with zebra crossings and traffic signs and whose curvature is also large. The algorithm proposed in this study eliminates the interferences of the dotted-line curve and other non-lane interferences under such road condition, thereby successfully achieving matching, fusion, and tracking. The final test results are accurate, and the algorithm exhibits good flexibility and strong anti-interference.

Fig.18 Effect drawing of lane detection and tracking with curvature and in the presence of zebra crossings and arrow signs.
To verify the superiority of the algorithm proposed in this study, two typical algorithms—the CHEVP algorithm proposed by Wang Yue and the TLC algorithm proposed by Gianni Cario—are selected for comparison. The CHEVP algorithm is a lane detection algorithm based on the original image space model, and the TLC algorithm is a typical lane detection algorithm based on the top-view space model.
In Figs.19-23, the detection results of the algorithm proposed in this study are compared with those of the CHEVP and TLC algorithms: (a) the lane detection results of the CHEVP algorithm, (b) those of the TLC algorithm, and (c) those of the algorithm proposed in this study (i.e., all the results are marked in red).
Under undulating road conditions with double yellow lines, as shown in Fig.19, neither the CHEVP algorithm nor the TLC algorithm has detection errors. However, the CHEVP algorithm can detect only the current lane, and without introducing the actual lane model, the double yellow lines on the left side are often mistakenly detected as the left-sideline of the lane, as shown in Fig.19a. The TLC algorithm requires image processing in the top-view space, which allows the introduction of the actual lane model. However, given the limited information of the current frame, the lane detection results of the left or right-side lanes are not very good, as shown in Fig.19b. The algorithm proposed in this study overcomes the shortcomings of the CHEVP and TLC algorithms and can effectively detect the side lines of the three lanes, as shown in Fig.19c.

Fig.19 Comparison of the algorithms in terms of their detection results.
The CHEVP algorithm mistakenly detects zebra crossings and arrow signs as lane features, as shown in Fig.20a. Fig.20b shows the detection results of the TLC algorithm, and the zebra crossings and arrow signs lead to a failure to detect the left-sideline of the current lane and errors in detecting the right-side line. By contrast, the detection results of the algorithm proposed in this study are correct, as shown in Fig.20c.
Fig.21 represents a curve depicted by dotted lines. The CHEVP algorithm predicts the vanishing point via linear detection using the Hough transform and detects the left and right-side lines of the current lane by seeking the optimal lines on the left and right sides. This leads to the solid line having a higher weight than the dotted line and to the direct estimation of the vanishing point from the left yellow solid line of the left lane and the right white solid line of the right lane, as shown in Fig.21a. The TLC algorithm fails to detect the left-side line of the lane and causes errors in detecting the right line because of failed clustering, as shown in Fig.21b. By contrast, the results of the algorithm proposed in this study are correct, as shown in Fig.21c.

Fig.20 Comparison of the algorithms and their detection results.

Fig.21 Comparison of the algorithms and their detection results.
Under the road conditions shown in Fig.22, the CHEVP algorithm fails to correctly detect the left-side line of the lane within the dotted-solid line transition region because of the large curvature, as shown in Fig.22a. The clustering analysis of the TLC algorithm is difficult to complete because of insufficient information in the current frame, and only a very small part of the lane is detected, as shown in Fig.22b. By contrast, the algorithm proposed in this study can detect the lane correctly. However, given the very large curvature, the field of view of the camera does not cover the right lane, so that the algorithm detects only the side lines of the current and left-side lanes, as shown in Fig.22c.

Fig.22 Comparison of the algorithms and their detection results.
Fig.23 represents a curve depicted by dotted lines and contains zebra crossings and arrow signs. Both the CHEVP and TLC algorithms result in errors in detection because of the interfering factors, as shown in Figs. 23a and 23b. By contrast, the results of the algorithm proposed in this study are correct, as shown in Fig.23c.
To further prove the effectiveness and robustness of the algorithm proposed in this study, several sections of the freeways and urban roads in Hefei, Anhui Province are chosen for a test. Such sections involve a wide variety of road conditions, such as tree shadows, sidewalks, vehicle interferences, strong light, horizontal linear lanes, and others. During the test, the accuracy of the algorithm is evaluated by comparing the difference between the detection result and the ground truth. When collecting experimental data, all the data contains lane line information, although there are a variety of interference. Therefore, it can be assumed that all video frames should be detected lane.The correct rate of the lane line detection is the ratio of the correctly detect lane number of frames and the total number of frames.

Fig.23 Comparison of the algorithms and their detection results.
It can prove the effectiveness of the experimental results in several aspects. (1) Lane shape and trend, we can determine the effectiveness of the experimental results by comparing the test results with the original image lane shape and trend. (2) Lane position. In this paper, the experimental data is collected by the human driving experimental vehicle, so the real situation of the vehicle in most of the time in the middle of the current lane regional location, so we can determine the effectiveness of the experimental results through the result of lane location of the results. (3) Lane width. As the lane on the road there is a relatively fixed width, so we assume that the current lane test results fall within a certain width are considered correct detection.Table 1 shows the detection results of the CHEVP and TLC algorithms and those of the algorithm proposed in this study for lane detection, with several videos of a video sequence that is statistically tested. The results consist of the statistics of the current lane, and the statistics of the urban roads exclude intersections. (4) Practical application effect. The method has been applied to series of unmanned vehicles those researched by Chinese Academy of Sciences and achieved good results. When collecting experimental data, all the data contains lane information, although there are a variety of interference. Therefore, it can be assumed that all video frames should be detected lane. The correct rate of the lane line detection is the ratio of the correctly detect lane number of frames and the total number of frames.
As Table 1 shows, the CHEVP algorithm has good effects on the processing of the original image captured with a camera. However, given a limited practical range, it is susceptible to any non-lane interference and has a poor lane edge detection rate. The TLC algorithm, which requires image processing in the top-view space, is easy to introduce into the actual road model and therefore effectively eliminates simple road surface interferences. However, the algorithm, which relies on single-frame image processing, is difficult to apply in a wider range and abundant lane data from the top-view image, and also is not very good in eliminating some complex road surface interferences, such as traffic signs, zebra crossing, and others. The lane algorithm proposed in this study has wider-range and complete lane feature data, reduces the interference of any irrelevant edge, and achieves a higher detection rate regardless of freeways or urban roads. Although windows, vehicles, and some traffic signs exist, freeways have very few changes in terms of road conditions and more complete lanes. Moreover, the detection rate of the algorithm proposed in this study is close to 100%. Given serious lane wear and more complex interferences in the part of the sections of urban roads, the detection rate of the algorithm decreases slightly,but is still better than the CHEVP and TLC algorithms.

Table 1 Comparison of the algorithm proposed in this stu-dy and the CHEVP/TLC algorithm in terms of detection rate.
Fig.24 shows the calculations of the preview point using the CHEVP and TLC algorithms and the algorithm proposed in this study. The preview point refers to the center point of the lane with a certain distance between the target lane and the unmanned vehicle. Based on practical experience, the center point of the lane with a distance of 20 m between the current lane and the unmanned vehicle is taken as the preview point in this study. The working principle of the unmanned vehicle system is that the decision-making system does not directly use any lane information from the sensing system but converts lane information into preview point information to guide the direction of the motion of the unmanned vehicle. Thus, the accuracy and reliability of the preview point information have direct effects on the travel of the unmanned vehicle. The preview point data in Fig.24b are obtained from the results of the same set of lane data using the three algorithms. As the figure shows, the fluctuations of the preview point obtained from the lane detection algorithm proposed in this study, which are marked in red in Fig.24b, are less significant than those obtained from the other two algorithms, which are marked in blue and green, respectively, in Fig.24b. This indicates that the algorithm proposed in this study is superior to the CHEVP and TLC algorithms in terms of the accuracy and reliability of lane detection.
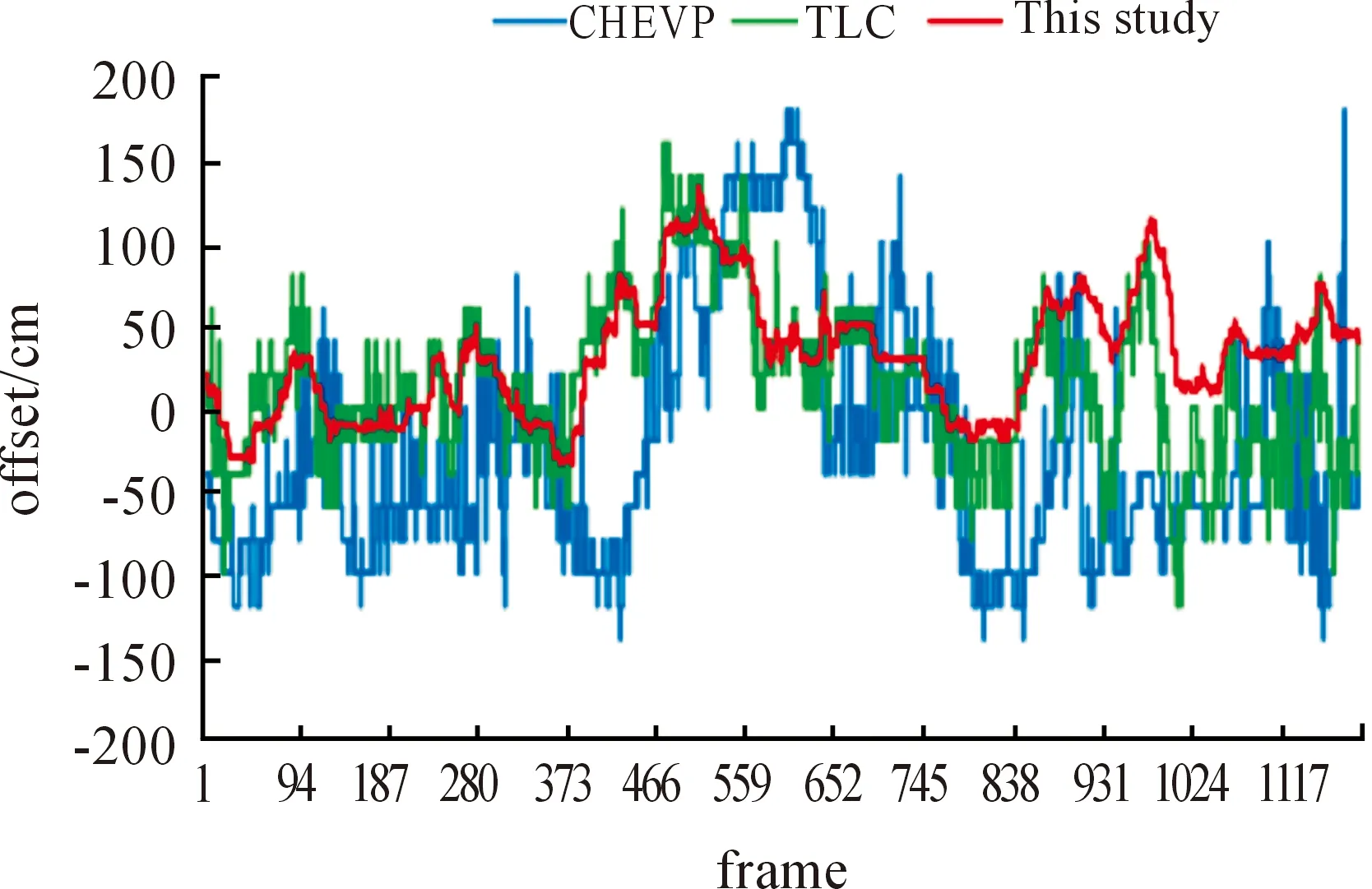
Fig.24 Statistics of the three algorithms in calculating the preview point.
The algorithm proposed in this study also has an ideal processing speed and therefore facilitates the statistics of the captured videos. Table 2 presents the average processing time of the CHEVP and TLC algorithms and the algorithm proposed in this study. As the table shows, the CHEVP algorithm is more time consuming because of the repetitive adoption of the Hough transform for line calculation. Both the TLC algorithm and the algorithm proposed in this study adopt reverse perspective transformation. However, the TLC algorithm first directly processes the original image by reverse perspective transformation, whereas the algorithm proposed in this study is less time consuming and processes the original image by reverse perspective transformation after segmentation.

Table 2 Comparison of the algorithm proposed in this stu-dy and the CHEVP/TLC algorithms in terms of speed.
4 Conclusion
This study mainly describes a lane detection algorithm based on reverse-projection space feature matching and fusion. The algorithm improves the binarization of lane features by combining the contour extraction and edge detection. It also obtains wider-range and multi-lane feature data by converting the binary image into the top-view space via reverse perspective transformation combined with continuous multi-frame image feature matching and fusion of the INS information in the top-view space. It overcomes the shortcomings of conventional lane algorithms in the camera plane, such as the difficulties of representing the lane model intuitively and the lack of wider-range lane data from a single image. It also improves anti-interference in lane detection. Finally, the algorithm also builds a lane prediction model for tracking lane detection, establishes correspondence between two adjacent frames of the lane image, and further increases the reliability and robustness. Several road scenes are selected for lane detection, and the results indicate the effectiveness and robustness of the algorithm proposed in this study. In addition, the algorithm is compared with two typical algorithms—the CHEVP and TLC algorithms—in terms of lane detection results. The comparison shows that the algorithm proposed in this study is superior to the two conventional algorithms under the road conditions. Several sections of freeways and urban roads are also selected for testing, and statistics show that the algorithm proposed in this study is better than the two conventional algorithms in terms of detection rate and reliability. Furthermore, it is less time consuming, has good timeliness, and satisfies the motion planning for unmanned vehicle systems.
Although the algorithm proposed in this study can achieve better results, some problems remain to be addressed. For instance, when a road surface takes an undulating form, the accuracy of continuous multi-frame feature matching and fusion declines. In certain particular sections, such as long-distance tunnels and others, the INS data accuracy may decrease, thereby affecting the accuracy of continuous multi-frame feature matching and fusion and weakening the lane detection and tracking. In future research, multiple road features will be further combined with more sensor information to enhance the flexibility and robustness of the proposed algorithm.
Acknowledgment
The authors gratefully acknowledge the help of our team members, whose contributionswere essential for the development of the unmanned vehicle. The authors also acknowledge the support of two National Nature Science Foundations of China: “Key technologies and platformfor unmanned vehicle in urban integrated environment” (91120307) and “Key technologies and platform forunmanned vehicle based on visual and auditory cognitive mechanism” (91320301).
Author Contributions
All four authors contributed to this work during its entire phase. Jun Wang was responsible for the literature search, algorithm design, and the data analysis. Tao Mei, Bin Kong and Hu Wei made substantial contributions in the plan and design of the experiments. Jun Wang was responsiblefor the writing of the article. Hu Wei helped in modifying the paper. Finally, all the listedauthors approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
[1]B.Wilcox, L.Matthies, D.Gennery, B.Cooper, T.Nguyen, T.Litwin.A.Mishkin, and H.Stone, Robotic vehicles for planetary exploration, inProceedingsofIEEEInternationalConferenceonRoboticsandAutomation, 1992, pp.175-180.
[2]G.Bekey, R.Ambrose, V.Kumar, A.Sanderson, B.Wilcox, and Y.Zheng,WTECPanelReportonInternationalAssessmentofResearchandDevelopmentInRobotics.World Technology Evaluation Center, 2006.
[3]U.Franke, S.Mehring, A.Suissa, and S.Hahn, The Daimler-Benz steering assistant a spin-off from autonomous driving, inProceedingsoftheIntelligent.Vehicles’94Symposium, Paris, 1994.
[4]R.Bishop, A survey of intelligent vehicle applications worldwide, inProceedingsoftheIEEEIntelligentVehiclesSymposium(IV’2002), 2000.
[5]D.J.Verburg, A.C.M.van der Knaap, and J.Ploeg, VEHIL: developing and testing intelligent vehicles, inProceedingsoftheIEEEIntelligentVehicleSymposium(IV’2002), 2002, vol.2, pp.537-544.
[6]T.Mei, H.W.Liang, B.Kong, J.Yang, H.Zhu, B.C.Li, J.J.Chen, P.Zhao, T.J.Xu, X.Tao, W.Z.Zhang, Y.Song, H.Wei, and J.Wang, Development of “Intelligent Pioneer” unmanned vehicle, inProceedingsoftheIntelligentVehiclesSymposium(IV), 2012, pp.938-943.
[7]B.H.Wilson, Safety benefits of a road departure crash warning system, inTransportationResearchBoard87thAnnualMeeting, 2008, no.08-1656.
[8]C.Visvikis, T.L.Smith, M.Pitcher and R.Smith, Study on lane departure warning and lane change assistant systems,TransportResearchLaboratory.Rep, 2008, no.PPR 374.
[9]R.Rajamani, H.S.Tan, B.K.Law and W.B.Zhang, Demonstration of integrated longitudinal and lateral control for the operation of automated vehicles in platoons,IEEETransactionsonControlSystemsTechnology, vol.8, no.4, pp.695-708, 2000.
[10] R.Bishop,IntelligentVehicleTechnologyandTrends.Norwood, MA: Artech House, 2005.
[11] K.Kluge, Extracting road curvature and orientation from image edge points without perceptual grouping into features, inProceedingsofIEEEIntelligentVehiclesSymposium, 1994, pp.109-114.
[12] Z.W.Kim, Robust Lane Detection and Tracking in Challenging Scenarios,IEEETransactionsonIntelligentTransportationSystem, vol.9, no.1, pp.16-26, 2008.
[13] A.Houser, J.Pierowicz, and D.Fuglewicz, Concept of operations and voluntary operational requirements for lane departure warning systems (LDWS) on-board commercial motor vehicles,FederalMotorCarrierSafetyAdministration, Washington, DC, 2005.
[14] H.Y.Cheng, B.S.Jeng, P.T.Tseng, and K.C.Fan, Lane detection with moving vehicles in the traffic scenes,IEEETransactionsonIntelligentTransportationSystem, vol.7, no.4, pp.571-582, 2006.
[15] Q.B.Truong and B.R.Lee, New lane detection algorithm for autonomous vehicles using computer vision, inProceedingsoftheIEEEInternationalConferenceonControl,AutomationandSystems, Seoul, Korea: IEEE, 2008, pp.1208-1213.
[16] A.Amditis and M.Bimpas, A situation-adaptive lane-keeping support system: overview of the SAF- ELANE approach,IEEETransactionsonIntelligentTransportationSystems, vol.11, no.3, pp.617-629, 2010.
[17] M.A.Lalimi, S.Ghofrani, and D.Mclernon, A vehicle license plate detection method using region and edge based methods,Computers&ElectricalEngineering, vol.39, pp.834-845, 2013.
[18] S.Jung, J.Youn, and S.Sull, Efficient Lane Detection Based on Spatiotemporal Images,IEEETrans.IntelligentTransportationSystems, vol.17, pp.289-295, 2016.
[19] S.B.Yacoub and J.M.Jolion, Hierarchical line extraction,IEEEProcVisImageSignalProcess, vol.142, no.1, pp.7-14, 1995.
[20] P.H.Batavia,Driver-adaptivelanedeparturewarningsystems.CMU-RI-TR-99-25, 1999.
[21] C.R.Jung and C.R.Kelber, A lane departure warning system based ona linear-parabolic lane model, inIEEEIntelligentVehiclesSymposium, 2004, pp.891-895.
[22] H.Yoo, U.Yang, and K.Sohn, Gradient-enhancing conversion for illumination-robust lane detection,IEEETransactionsonIntelligentTransportationSystems, vol.14, no.3, pp.1083-1094, 2013.
[23] A.Borkar, M.Hayes, and M.T.Smith, An efficient method to generate ground truth for evaluating lane detection systems, inProceedingsoftheIEEEInternationalConferenceonAcousticsSpeechandSignalProcessing(ICASSP), 2010, pp.1090-1093.
[24] A.B.Hillel, R.Lerner, D.Levi, and G.Raz, Recent progress in road and lane detection: a survey,MachineVisionandApplications, vol.25, pp.727-745, 2014.
[25] B.S.Shin, Z.Xu, and R.Klette, Visual lane analysis and higher-order tasks: a concise review,MachineVisionandApplications, vol.25, pp.1519-1547, 2014.
[26] J.Son, H.Yoo, S.Kim and K.Sohn, Real-time illumination invariant lane detection for lane departure warning system,ExpertSyst.Appl., vol.42,no.4, pp.1816 -1824, 2015.
[27] K.Y.Chiu and S.F.Lin, Lane detection using color-based segmentation, inProceedingsoftheIEEEIntelligentVehiclesSymposium, Washington D.C., USA: IEEE, 2005, pp.706-711.
[28] S.Azali, T.Jason, M.H.A.Hijazi, and S.Jumat, Fast lane detection with randomized hough transform, inProceedingsoftheInformationSymposiumonInformationTechnology, KualaLumpur, Malaysia: IEEE, 2008,pp.1-5.
[29] M.Bertozzi and A.Broggi, GOLD: A Parallel Real-Time Stereo Vision System for Generic Obstacle and Lane Detection,IEEETransactiononImageProcessing, vol.7, no.1, pp.62-81, 1998.
[30] C.R.Jung and C.R.Kelber, A robust linear-parabolic model for lane following, inProceedingsofthe17thBrazilianSymposiumonComputerGraphicsandImageProcessing, Curitiba, Brazil, 2004, vol.10, pp.72 -79.
[31] H.Yoo, U.Yang, and K.Sohn, Gradient-Enhancing Conversion for Illumination-Robust Lane Detection,IEEETransactionsonIntelligentTransportationSystems, vol.14, no.3, pp.1083-1094, 2013.
[32] C.Ma and M.Xie, A method for lane detection based on color clustering, inProceedingsofInternationalConferenceonKnowledgeDiscoveryandDataMining, Phuket, 2010, pp.200-203.
[33] Z.Tao, P.Bonnifait, V.Fremont, and J.Ibanez-Guzman, Lane marking aided vehicle localization,inProceedingsof2013 16thInternationalIEEEConferenceonIntelligentTransportationSystems(ITSC), 2013.
[34] A.Geiger, M.Lauer, C.Wojek, C.Stiller, and R.Urtasun, 3D Traffic Scene Understanding From Movable Platforms,IEEETransactionsonPatternAnalysisandMachineIntelligence, vol.36, no.5, pp.1012-1025, 2014.
[35] Q.Q.Li, L.Chen, M.Li, S.L.Shaw, and A.Nuchter, A sensor-fusion drivable-region and lane-detection system for autonomous vehicle navigation in challenging road scenarios,IEEETransactionsonVehicularTechnology, vol.63, no.2, pp.540-555, 2014.
[36] H.J.Liu, Z.B.Guo, J.F.Lu, and J.Y.Yang, A fast method for vanishing point estimation and tracking and its application inroad images, inProceedingsofthe6thInternationalConferenceonITSTelecommunicationsProceedings, Chengdu, China: IEEE, 2006, pp.106-109.
[37] M.Meuter, S.Muller-Schneiders, A.Mika, S.Hold, C.Nunn C, and A.Kummert, A novel approach to lane detection and tracking, inProceedingsofthe12thInternationalIEEEConferenceonIntelligentTransportationSystems, St.Louis, USA: IEEE, 2009, pp.1-6.
[38] B.G.Zheng, B.X.Tian J.M.Duan, and D.Z.Gao, Automatic detection technique of preceding lane and vehicle, inProceedingsoftheIEEEInternationalConferenceonAutomationandLogistics, Qingdao, China: IEEE, 2008, pp.1370-1375.
[39] A.Watanabe, T.Naito and Y.Ninomiya, Lane detection with roadside structure using on-board monocular camera, inProceedingsoftheIEEEIntelligentVehiclesSymposium, Xi’an, China: IEEE, 2009, pp.191-196.
[40] J.Wang, T.Mei, B.Kong, and H.Wei, An approach of lane detection based on Inverse Perspective Mapping, inProceedingsof2014IEEE17thInternationalConferenceonIntelligentTransportationSystems(ITSC), 2014, pp.35-38.
[41] D.Pomerleau and T.Jochem, Rapidly adapting machine vision for automated vehicle steering,MachineVision, vol.11, no.2, pp.19-17, 1996.
[42] Y.Wang, D.Shen, and E.K.Teoh, Lane detection using Catmull-Rom spline, inProceedingsofIEEEInt.Conf.IntelligentVehicles,1998, pp.51-57.
[43] Y.Wang, E.K.Teoh, and D.Shen, Lane detection and tracking using B-Snake, ImageVisionComputing, vol.22, pp.269-280, 2004.
[44] Y.Wang, L.Bai, and M.Fairhurst, Robust road modeling and tracking using condensation,IEEETrans.IntelligentTransportationSystems, vol.9, pp.570-579, 2008.
[45] Q.Chen and H.Wang, A real-time lane detection algorithmbased on a hyperbola-pair model, inProceedingsoftheIEEEIntelligentVehiclesSymposium, Tokyo, Japan: IEEE, 2006, pp.510-515.
[46] G.Cario, A.Casavola, G.Franze, and M.Lupia, Predictive Time-to-Lane-Crossing Estimation for Lane Departure Warning Systems,NationalHighwayTrafficSafetyAdministration, 2009.
[47] Y.Z.Peng and H.F.Gao, Lane detection method of statistical Hough transform based on gradient constraint,Int.J.Intell.Inf.Syst., vol.4, no.2, pp.40-45, 2015.
[48] C.Y.Chang and C.H.Lin, An efficient method for lane-mark extraction in complex conditions, inProceedingsofInternationalConferenceonUbiquitousIntelligenceandComputingandAutonomicandTrustedComputing, Fukuoka, 2012, pp.330-336.
[49] Y.J.Fan, W.G.Zhang, X.Li, L.Zhang, and Z.Cheng, A robust lane boundaries detection algorithm based on gradient distribution features, inProceedingsof2011 8thInternationalConferenceonFuzzySystemsandKnowledgeDiscovery(FSKD), Shanghai, 2011, no.3, pp.1714-1718.
[50] M.B.Du, T.Mei, H.W.Liang, J.J.Chen, R.L.Huang, and P.Zhao, Drivers’ Visual Behavior-Guided RRT MotionPlanner for Autonomous On-Road Driving,Sensors, vol.16, no.1, pp.102, 2016.
[51] H.R.Xu, X.D.Wang, and Q.Fang, Structure Road Detection Algorithm Based on B-spline Curve Model,ActaAutomaticaSinica, vol.37, no.3, pp.270-275, 2011.
[52] J.Deng, J.Kim, H.Sin, and Y.Han, Fast lane detection based on the B-Spline fitting,Int.J.Res.Eng.Technol., vol.2, no.4, pp.134 -137, 2013.
 CAAI Transactions on Intelligence Technology2017年4期
CAAI Transactions on Intelligence Technology2017年4期
- CAAI Transactions on Intelligence Technology的其它文章
- An Efficient Approach for The Evaluation of Generalized Force Derivatives by Means of Lie Group
- Magnetic Orientation System Based on Magnetometer, Accelerometer and Gyroscope
- A Mixed Reality System for Industrial Environment: an Evaluation Study
- Diagnosis System for Parkinson’s Disease Using Speech Characteristics of Patients and Deep Belief Network
- Visual Navigation Method for Indoor Mobile Robot Based on Extended BoW Model
- Proposal of Initiative Service Model for Service Robot