
基于数据挖掘技术的考试作弊风险预警研究
2017-12-16 12:59刘丽娜
吉林省教育学院学报 2017年9期
刘丽娜

摘要:采用数据挖掘技术对广州科技职业技术学院已毕业的2009级~2013级5个年级的学生信息进行分析评估。利用SPSS Modeler挖掘工具中的Apriori关联规则模型对预处理后的数据进行挖掘,发现潜藏其中有应用价值的规则。最后将所挖掘出的规则进行分析解释,将其应用到教学改革当中,对具有潜在作弊风险的学生进行教育引导,形成考试作弊的预警机制,降柢学生作弊辍学风险,提高学校教育教学质量。
关键词:数据挖掘;Apriori;考试作弊;预警
中图分类号:TP311.1 文献标识码:A 文章编号:1671-1580(2017)09-0120-03
一、数据挖掘技术概述
数据挖掘技术是从不同的角度分析数据并将其归总为有用信息的过程——可以利用其以增加收入,降低成本或二者兼有之。虽然数据挖掘是一个相对较新的术语,但其技术却不然,早在数据挖掘一词出现的很多年前就有公司利用强大的电脑来筛选大量的超市扫描仪数据,并以此来分析市场研究报告。
一谈到数据挖掘应用就不得不提到经典的商业零售之啤酒与尿片关联分析销售规则。就是人们在大量的购物清单的分析中发现,一般购买啤酒的客户也会同时购买尿片,这可以启发零售商有针对性地将这两样东西放同一个地方或附近以增加销售量,事实证明这是一种效果显著的销售决策。
数据挖掘包括多种实现算法,不同的算法适用于不同的数据及分析角度,一般较为复杂的挖掘系统会以几种算法相结合的方式运行。数据挖掘算法技术包括以下几种常见的算法。
(一)关联规则
关联规则是一种规则,它意味着(如“一起出现”或“一个事件的出现必然包含另一个事件”)在数据库中的某些关联关系。
(二)遗传算法
遗传算法依靠其模仿生物的方法,常用于为运营商解决最优化和搜索问题。
(三)神经网络
神经网络近年来备受关注,它以模仿动物神经网络的行为特征运行在自学学习的数学模型基础上,为解决大型的负责问题提供了一种相对简单有效的方法。
(四)决策树
它是一种决策支持工具,用类似于树的图形或模型表示决策或可能的输出结果。
二、关联规则挖掘算法Apriori
关联规则是数据挖掘算法中发现属性之间关联性的基于规则的机器学习方法,它主要用于发现“一起出现”或一个事务与另一事务之间出现的必然联系。它的目的是利用识别措施来发现数据库中有趣的关系,发现强规则。
Agrawal等人对关联规则挖掘问题的定义为:设数据库即所有交易的集合为D:{t1,t2,t3…tn},n为交易记录数。所有项目(属性)的集合为I-{i1,i2…im},m为项目(属性)数量。在数据库D中,每条记录都有唯一的m,记录里所包含的项目(属性)都在集合I中。而规则的定义为:X→Y,且x,Y∈I。
每条规则都由两个或两个以上的项目(属性)组成,X和Y,其中X称为规则前项,Y称为规则后项。
例如,在超市购物时,有一个交易记录为I={青菜,豆腐,酱油,盐,面包},在所有交易中选择其中5条交易记录组成一个小的数据库D(如表1所示),用一个表格表示该数据库,1表示交易中有购买该项商品,0则表示没有购买该项商品。
该数据库中的规则为{青菜,豆腐}→{盐},则表示如果顾客购买了青菜和豆腐,那么他们同时也会购买盐。
为了从所有可能的规则中找出强规则,关联规则设置了最低约束指标置信度和支持度来筛选有趣的规则。在以上规则R=X→Y中,支持度为:
Sup=(COUNT(X∧Y)/COUNT(D))*100% (1)
其中COUNT(X∧Y)為同时包含X和Y的项目(属性)交易记录总数,COUNT(D)为数据库记录数。规则的置信度为:
Conf=(COUNT(X∧Y)/COUNT(X))*100% (2)
其中COUNT(X)为包含X项目(属性)的交易记录总数。
在以上例子中,规则{青菜,豆腐}→{盐}的支持度为3/5*100%=60%,置信度为3/4*100%=75%。
Apriori关联规则通常需要满足用户指定的最小支持度和最小置信度约束,关联规则的运行程序分为两个独立的步骤:
(一)在数据库中找到所有符合最小支持度的频繁项集;
(二)在所有找到频繁项集中根据最小置信度找到强规则。
三、学生数据关联挖掘模型设计
(一)目标分析
数据挖掘的挖掘结果虽然通过数据分析挖掘才知道具体的规则方向,然而数据挖掘也有明确的挖掘主题和挖掘目标。从所收集到的各数据源进行分析挖掘找出潜在的关联关系,之后分析关联结果,并将其应用于教学决策当中。
(二)数据准备
在对数据进行挖掘之前,所有数据源所提供的数据都是杂乱无章的,或数据缺失,或存在噪声等,增加了数据的运行处理时间,降低了数据的处理效率。因此,在数据挖掘前需对数据进行整合清洗,以使挖掘效率和挖掘结果更快捷准确。
1.联接各数据源形成学生信息总表
将所收集到的数据源整理形成电子数据表,根据各数据表的主键(“学号”或“身份证号”)与外键的关系联接合并为一张有唯一主键的多属性学生信息总表。联接后清除与挖掘主题无关的属性,如“姓名”“身份证号”等。
2.数据泛化
数据泛化即将数据库中包含的数据原始概念层的细节信息从较低的概念层抽象到较高层次的过程。例如学生成绩中同专业同课程的成绩属性在0至100之间有大量的不同值,不利于数据关联挖掘,故需对数据做泛化处理。成绩在泛化时可以根据范围[90,100],[80,90),[70,80),[60,70),[0,60)依次分为优秀、良好、中等、及格和不及格5个成绩段,其他属性以此类推形成各维度的数据总表。endprint
3.噪声及缺省值处理
信息数据在泛化后有了较统一的结构模式,然而,无论是历史数据还是现在进行的数据都因为文件错误或保存不当,大多存在噪声或缺失值。数据的不完整性将影响挖掘规则的支持度及可信度,而全部剔除不完整的数据记录则可能会使重要规则也被一并删除又或者缩小原本的数据库。不完整数据的处理方式一般有人工填写、属性均值填充、全局常量填充、同类均值填充和忽略记录等几种。本研究所收集的数据来自不同的数据源具有不同的表现形式,部分属性缺失严重地选择了舍弃,而其他缺失值根据数据的性质和类型采用同类均值填充法。
四、依托数据挖掘工具SPSS Modeler的学生数据挖掘实现
本研究以广州科技职业技术学院已毕业的2009级一2013级5个年级的学生数据为研究对象,将预处理后的17381条记录,28个维度导入SPSSModeler中的Apriori模型当中,设最小支持度:最小置信度=0.05。
数据经过过滤之后进行类型分类,再进入Apri-ori莫型,运行之后生成各个支持度与置信度的规则分析结果。
五、挖掘结果及规则理解
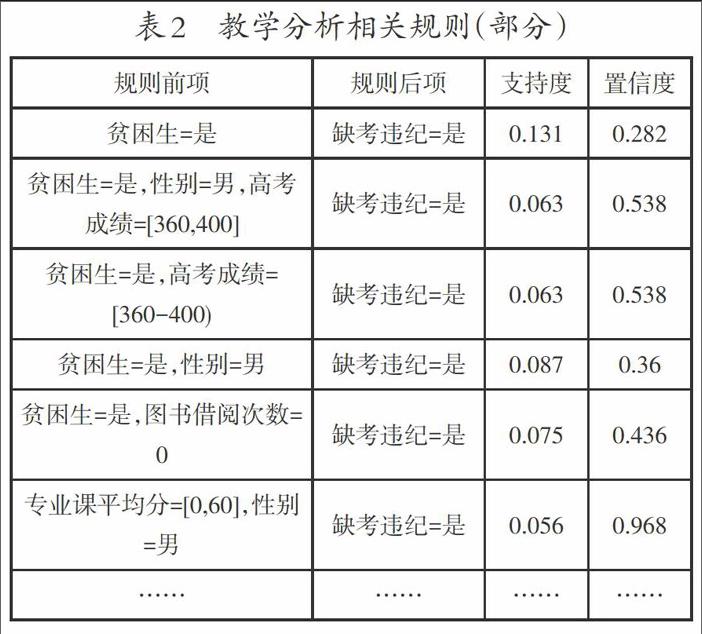
经Apriori挖掘模型得出的挖掘结果需再进行进一步解释筛选,本研究所挖掘出的结果解释如表2。
在所有缺课超过1/3、缺考、舞弊记录当中(如表2所示),规则“高考成绩:[360-400),贫困生=是→缺考违纪=是”以及规则“贫困生=是,图书借阅次数=0→缺考违纪=是”,支持度和置信度分别为0.063,0.538和0.075,0.436,高考成绩为360~400在案例学院(3本B线)所有的录取成绩当中属于良好层次,在此规则中的学生高考成绩较好且家庭比较贫困,在学费相对较高,来之不易的上学机会却出现缺课或缺考甚至舞弊的现象。数据显示这批学生大部分鲜少在图书馆借阅图书。实验抽取符合该规则中的4名入学成绩良好的贫困学生进行调研,其中有2名学生为舍友且同辅导员,经调研发现他们皆因沉迷上网(网络游戏、电子小说)。在上大学前家庭贫困且无需购置电脑(或手机),大学期间购置之后使他们沉迷于新事物(网络游戏、电子小说)当中,最终因担心成绩不合格愧对家人继而铤而走险。这4名学生其中有2名互为舍友。在了解了这一规则后,学校可以未雨绸缪,帮助并挽救这些学生,同时,这些有网瘾的学生有可能会影响整个宿舍,或带动舍友一起玩游戏或影响他人作息,学校可以根据该规则,在宿舍分配上做相应调整,比如学习好意志力强的学生中插入一些成绩差的,把误入歧途的学生引向正道。
六、结束语
本研究以广州科技职业技术学院已毕业的5个年级的学生数据为研究对象,采用当前比较新颖的信息技术分析手段——数据挖掘技术,选取数据挖掘技术中的关联规则Apriori算法模型,SPSS Model,er分析工具对预处理后的数据进行分析。对挖掘结果进行了分析,提出了一种基于数据挖掘的学生考试作弊风险预警机制:基于预警事件和其他事件之间存在依赖或关联关系定义了一种预警规则知识,根据预警规则可找出存在作弊风险的学生,在学生可能实施作弊之前采取应对措施,防止其作弊。实验显示,该预警机制在我校实施取得了一定的效果,嚴肃考风考纪,规范学校管理,提高人才培养质量。
[责任编辑:周海秋]endprint
猜你喜欢
意林原创版(2021年7期)2021-08-03
经济数学(2020年4期)2020-01-15
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
考试周刊(2016年85期)2016-11-11
考试周刊(2016年80期)2016-10-24
哈尔滨理工大学学报(2016年2期)2016-09-12
科技视界(2016年10期)2016-04-26
考试周刊(2016年2期)2016-03-25
科技与企业(2015年18期)2015-10-21
