
基于多目标优化算法的图像匹配
2017-11-01 23:26张晓慧
阜阳职业技术学院学报 2017年3期
张晓慧
基于多目标优化算法的图像匹配
张晓慧
(阜阳职业技术学院,安徽 阜阳 236031)
作为计算机视觉和图像处理领域的重要研究内容,图像匹配的主要目的是寻找图形图像之间的匹配关系。因为传统的匹配方法主要是依靠点作为基本单元的一阶匹配方法和依靠线作为基本单元的二阶匹配方法,因此对采集特征点的选择和匹配方法的优化是很重要的。然而,基于局部图像信息的这两种方法的匹配效果不是很好,本文通过改进使用多目标优化算法NSGA-II,设计实现一种新的高阶图匹配算法,通过设计相关的目标函数和遗传算子,提取两幅图的特征,并在此基础上确定特征点匹配关系。实践表明,该方法在变形和噪声存在的情况下,能够正确匹配两幅图之间的特征点。
图像匹配;特征;多目标;NSGA-II
1 引言
随着计算机视觉的不断发展,图像匹配技术越来越受到人们的重视,其在很多科学技术领域中发挥着重要的作用,例如,目标追踪、图像分类或恢复、目标识别[1]、模型匹配[2]或宽基线立体融合[3]。由于图像在不同的时间、传感器以及视角下所获得的成像不同,对同一物体在图像中所展示出来的几何特性、光学特性、空间位置依然会有很大的不同,如果再考虑到噪声、干扰等影响会让图像发生更大的差异,图像匹配就是在这些不同之中寻找它们的相同点。NSGA-II算法是带有精英策略的快速非支配排序算法,笔者从已经提出的基于张量的高阶图匹配算法和现有的多目标优化算法的结合出发,对图像匹配算法进行探讨和研究,改进出一种新的图像匹配算法。
2 基于特征的图像匹配方法
图像匹配的过程一般可以分为图像的输入、预处理、特征提取、匹配、输出等步骤,由于所采用的方法不尽相同,不同匹配方法的步骤会有很大不同,具体体现在图像预处理的不同、图像特征提取方法的不同以及匹配所用适应度值计算方法的不同等,但它们的大致过程是一致的[4]。目前,国内外对图像匹配的研究重点在三个方面,即图像匹配三要素:特征空间、相似性度量、搜索策略。
2.1 张量介绍
张量是一个矩阵的n维泛化。2维矩阵可以被表示为表格形式,而张量则可以被描述为n维超矩形表格形式,这样一种张量的每一个元素都要被n个数索引:H={}。张量与向量可以通过不同的方式相乘,我们使用下面的公式表示:

式(2-2)
V是一个n维向量,A是一个n维张量,就好像一个矩阵和一个向量的乘积是一个向量一样,一个n维张量与一个向量的乘积是n-1维的,同样就像矩阵和向量的乘法有两种方式一样(向量分别在矩阵的左边和右边),张量和向量的乘法有n种不同的方式,标记符中的k表示我们按第k维相乘。

2.2 特征提取
本文重点研究的是基于图像特征的匹配,点匹配算法是基于图像特征的匹配算法中很重要的一部分,在各种特征中,特征点作为一种稳定的、旋转不变的、同时又能克服灰度反转的特征参与到匹配过程中不仅可以减少计算量,同时又能够不损失图像的重要灰度信息,而且对于不相似的图像还可以进行部分相似的匹配。
如果遇到了带有尺度、旋转、仿射变换的情况,传统的以点或者点对为单元的匹配算法的准确率就会很低,针对这种问题,Olivier Duchenne和Francis Bach提出一种基于张量的高阶匹配算法[5],该算法使用了更高阶的约束来建立两套视觉特征之间的对应关系,代替传统的点或点对的方法。
在本文中,我们使用3个点作为一个元组,即随机从同一幅图中取出3个点,然后利用这3个点做一个三角形,提取出这一个三角形的特征做为图像特征。

图1 特征三角形
如图1所示,我们可以从三角形中提取到很多的特征作为图像匹配的特征,例如通过提取三角形的三个内角值,可以找到两幅图中的相似三角形,当图像发生尺度和旋转变换时,可以通过特征三角形的内角值特征进行图像匹配,为了简化计算,我们可以使用内角的正弦值代替角度值;通过提取三角形三条边的比值作为特征,可以应对图像的仿射变换。在我们的实验中,就是用三角形的内角值和边长比作为特征。
根据张量的计算公式,在这里我们可以定义一个新的目标函数:

在这个函数中,只有当点元组{i,j,k}和{i,j,k}匹配的时候,的值为1,此时,将添加到目标函数中,其它情况下,目标函数值都为0。
H代表一种相似测量方法,当点元组{i,j,k}和{i,j,k}相似的话,H的值就会很高,同样,对于同一幅图中的每一组点,每一个特征向量f,我们要重新定义H:

2.3 改进的稀疏张量计算方法
如果对于从图中提取的每一个特征三角形,我们都需要计算与之对应的特征三角形之间的张量值,这将会大大增加计算量和算法的复杂度。我们在这里使用一种改进的稀疏张量计算方法,通过省略掉不必要的张量计算,大大提高算法的效率。在我们的实验中,我们使用一个高斯核函数:
所以,对我们选取的每一个点元组,找到σ范围内的近邻点元组,实验中我们使用ANN(近似最近邻算法)寻找点元组的近似最近邻,这种ANN算法是基于kd-trees搜寻近似最近邻的。
然而,如果对全部点元组都使用ANN算法的话,这将是一个非常耗时的工作,所以,我们只取一部分点元组进行计算,这样就可以减少计算,但是要注意不可取太少的点元组数目,因为当元组数目过少将会影响匹配效果。
然后,计算每一个特征三角形的标识符,并把它们存储在kd-tree中,为了更高效的查找,对选中的三角形,我们这样计算张量:
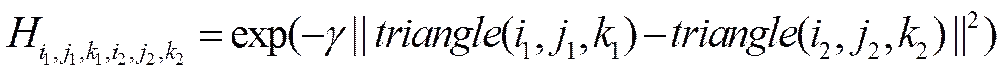
如果triangle(i,j,k)triangle(i,j,k)属于triangle(i,j,k)的k个近似最近邻的话,否则H为0。
基于ANN算法的高效计算张量方法:

input:图像I1,I2和点集P1,P2;output:张量HH←空张量for each t∈P2产生的所有特征三角形 do f←computetupleFeature(t,I2);endT ←computeANNtree(F);S ←选择一些三角形在I1;for each s∈S do N←搜寻k个最近邻(T , s); for each n∈N do H(index(s),index(n))←相似度(特征值(s),特征值(n)); endend
3 图像匹配的多目标设计方法
3.1 NSGA-II算法与图像匹配问题的对应关系
NSGA-II算法是以遗传学为基础的问题求解模型,下面给出生物遗传概念在图像匹配中的对应关系,如下:

生物遗传概念图像匹配问题中的作用 个体可行解的编码 适应性目标函数值的大小 适者生存目标函数值越大的编码被保留的机会越大 交配根据适应度值选定的一组分配方案,通过交叉操作产生一组新个体的过程 变异编码的某一分量发生变化的过程
3.2 图像匹配的编码解码设计
NSGA-II算法中能够操作的数据是经过编码后的基因,而不能是实际问题中的数据,所以我们必须先完成编码工作,实现由问题空间(可能解空间)向遗传空间(经过编码的个体组成的空间)的映射。编码方式的不同对NSGA-II算法的操作有着很大的影响,好的编码不仅能够加速NSGA-II算法的收敛速度,而且能够提高准确率。一般来说,使用最多的编码方式是二进制编码,但是在图像匹配时选点数量比较多的时候,使用二进制编码,基因串的位数会很长,进而影响到求解效率,因此本文采用十进制编码。

1 2 3 ……… N
为了方便起见,这里我们假设分别从待匹配的两幅图中取n个特征点,并把这n个点进行排序,然后我们建立一个n维向量,这个n维向量里存储的是从1到n这n个数字的一个排列组合,例如:

……
这里表示第i,j,k……n个特征点分别与第1,2,3……n个特征点分别是对应匹配的。
3.3 适应度值的计算
适应度值是NSGA-II算法中的一个重要指标,我们就是通过这个指标进行下面的非支配排序以及选择操作的,通常适应度的计算就是我们的目标函数的计算,必须要求我们所需要的个体的适应度值高,即越靠近最优解的一些个体的适应度值越高,而越偏离最优解的个体的适应度值越低。我们使用式(2-3)作为目标函数。
3.4 快速非支配排序
NSGA-II采用了快速非支配排序方法,对于每个个体i都设有以下两个参数ni和si,ni为在种群中支配个体i的解个体的数量,s为被个体i所支配的解个体的集合。
①首先判断所有个体的n值,并保存n=0的个体。
②对于每一个n=0的个体,就可以将它所支配的解集合s中的每一个个体k的n值减1,即去除掉能支配个体k的个体i。
③将n=0作为第一级非支配个体,这些个体是最优面上的解,赋予这些个体一个相同的非支配序,它们只支配其它个体,但不被其他任何个体所支配,然后去除掉这些个体,对其它个体继续进行非支配排序,然后分别给它们相应的非支配序,直到所有的个体都被分级。
3.5 交叉操作
交叉操作的方法有很多种,比如单点交叉、多点交叉、洗牌交叉、均匀交叉等。本文采用的是两点交叉,随机找到染色体上的两点位置,然后父母双方这两点位置之间的基因互换,这样就会产生两个新的子代个体。
但是,本文中,单纯地使用这种交叉方式是有问题的,因为本文使用的编码结构,同一个基因在不同的位置处代表的意义是不同的,因而通过改变基因的位置可以生成新的染色体,然而本文使用的编码结构是有一定的约束条件的,那就是每一个基因位上的数字都互不相同。
如果只是简单地使用两点交叉,必然会导致某些新基因而有些基因位上的数字是相同的,为了解决这个问题,我们使用下面的方法:

13467952108 35796821410
我们假设将第4位到第8位之间的基因相互交换,即

13496821108 35767952410
然后我们遍历这两个新个体的第1位到第3位以及第9位到第10位的每一段基因,例如,第一个新个体的第1位基因与第8位基因相同,那么我们把第二位新个体的第8位的基因2赋给第一位新个体的第1位基因,即变为:

23496821108
这时我们发现该个体的第1位基因与第7位基因相同,所以我们把第二位新个体的第7位基因赋值给第一位新个体的第1位基因,这时就变为:

53496821108
这时我们发现第一位基因已经是独一无二的了,然后我们接着遍历下一位基因。如此重复下去直到遍历完所有的基因,我们就可以得到两个满足约束条件的新个体:

53496821107 31867952410
3.6 变异操作
变异的目的是充分挖掘出种群的多样性,解决可能陷入局部最优的问题。本文采用随机变异策略,对每一个参与变异操作的个体,随机地选取两个基因位,然后把这两个基因位的基因相互交换位置。

12345678910
假设第1位与第2位基因发生交换,即产生新个体:

21345678910
使用这种变异方式主要出于两点考虑:一是因为本文的十进制编码结构,同一数值在不同的基因位所代表的意义不同,因此通过互换基因位的数值可以生成新的染色体;二是因为如果使用一般的变异算子,必然会引入新的不满足约束条件的基因,就需要通过上述的遍历来使每一个染色体都满足约束条件,影响到算法的速度。
3.7 算法步骤
我们已经分别介绍了计算张量和NSGA-II的步骤,那么只需要简单的结合就可以作为我们的图匹配的NSGA-II算法步骤,步骤如下:

input:张量H;output: 最优解集;初始化种群;for 进化代数=1:max计算种群个体的目标函数值;对种群个体进行非支配排序;依照排序结果进行选择、交叉、变异产生新一代种群;end
4 实验结果及对比
为验证算法的可行性和有效性,利用Matlab编程工具实现,仿真实验在Intel(R) Core(TM) i5 2.67GHz、6GB内存的计算机上进行,首先随机产生一个点集(),对该点集进行平移、旋转、尺度变换,并添加高斯噪声产生第二个点集,然后对这两个点集进行匹配。

图2 幂迭代算法、遗传算法、NSGA-II算法的比较
从图2可以看出,随着特征点的增加,幂迭代和遗传算法的准确率都在降低,而与之相反的是,NSGA-II算法得到的结果依然很好。同时我们在利用真实照片来验证算法的可行性,在图像的匹配的过程中,特征点的选取是一个很关键的步骤,我们这里通过手工选点的方法,手动地从图像中选取一些交点、角点等作为特征点。

图3 仿射变换的房子图片匹配

图4 大小变换的吉他图片匹配

我们可以看到实验结果是很不错的,这些特征点总是可以被正确地匹配。图3所示的待匹配图片仅包含仿射变换,从图中可以看出,仿射变换破坏了单个特征点的属性,并且破坏了特征点与特征点之间的相对位置属性,利用特征三角形的几何不变性,就能够较好地识别出两幅图中对应的特征点。图4所示的待匹配图片仅包含大小变换,从实验结果可以看出,利用特征三角形可以非常好地识别出两幅图片中对应特征点。图5是从不同的取景角度获得同一栋建筑的照片,其中包含了仿射变换、大小变换、平移变换等多种变换方式,从实验结果来看,本文提出的算法依然能够较好地应用于多种变换交织的待匹配图像。
5 结束语
将多目标遗传算法NSGA-II引入到图像匹配中,实现了基于多目标优化算法的高阶图匹配,保证了经过复杂变化的两幅图片之间高效、正确的匹配。
[1] A. Berg, T. Berg, and J. Malik,“Shape Matching and Object Recognition Using Low Distortion Correspondence,”Proc. IEEE Conf. Computer Vision Pattern Recognition,2005.
[2] M. Leordeanu and M. Hebert,“A Spectral Technique for Correspondence Problems Using Pairwise Constraints,”Proc.IEEE Int’l Conf. Computer Vision,2005.
[3] S. Lazebnik, C. Schmid, and J. Ponce, “Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories,”Proc. IEEE Conf. Computer Vision and Pattern Recognition,2006.
[4]公茂果,焦李成.进化多目标优化算法研究[J].软件学报,2009(2).
[5]崔海波.基于NSGA-Ⅱ的炮兵群火力分配问题研究[D].国防科技大学,2010.
[6] 阮宏博.基于遗传算法的工程多目标优化研究[D].大连理工大学,2007.
On the Image Matching Based on Multi-objective Optimization Algorithm
ZHANG Xiao-hui
(Fuyang Institute of Technology, Fuyang, Anhui 236031, China)
As an important part in the field of computer vision and image processing, the key objective of image matching is to find out the match relationship between graphics and images. Since the traditional matching method mainly depends on the point as one-order matching method of basic unit, and depends on line as two-order matching method of basic unit, it is important to optimize matching method and choose capturing feature points.
However, the matching of the two methods doesn’t work so well based on the local image information. The paper aims to design a new matching method of high-order image through using Multi-objective optimization algorithm NSGA-II, and to extract the features of images through design related objective function and the genetic operator, and to conform the matching relation of the feature points on this basis. The results show that the method correctly matches the feature points of the twographics in the presence of noise and transformation.
Image matching; Feature; Multi-objective;NSGA-II
TP
A
1672-4437(2017)03-0047-06
2017-03-07
安徽省高等学校省级质量工程项目(2015tszy051);安徽省高校自然科学研究重点项目 (KJ2016A563)。
张晓慧(1978-),女,安徽阜阳人,阜阳职业技术学院副教授,硕士,主要研究方向:图像处理、多媒体技术。
猜你喜欢
电脑报(2021年14期)2021-06-28
数学物理学报(2021年1期)2021-03-29
五邑大学学报(自然科学版)(2020年4期)2020-12-09
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
计算机测量与控制(2017年6期)2017-07-01
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
集美大学学报(自然科学版)(2015年1期)2015-02-28
西安建筑科技大学学报(自然科学版)(2014年5期)2014-11-10
航天器工程(2014年4期)2014-03-11
