
大数据时代的文学经典解读*
——《罗密欧与朱丽叶》计量文体分析
2017-07-03 15:42:18
外语与翻译 2017年2期
大数据时代的文学经典解读*
——《罗密欧与朱丽叶》计量文体分析
当今时代,文体学研究范式正在发生转变。单纯的传统范式有其不足之处,计量文体分析与传统范式互补才能相得益彰。本文回顾计量文体分析的特点、手段及应用,并在此基础上对莎士比亚戏剧《罗密欧与朱丽叶》中男女主角的台词进行量化分析,以love相关句式为文体探测点,发现他们爱意表达方式的差异。笔者认为,计量文体分析的核心环节是,选取恰当的文体探测点进行数据挖掘(data mining),提出假设并用数据验证假设,最后结合数据对文学作品的风格进行解读。
莎剧,文体学,计量文体学,大数据
“大数据”,就是难以用传统软件技术和方法分析的超大型复杂数据。关于对大数据的定量描述,最早是Laney (2013) 提出的三个维度描述——也称3V(Volume, Velocity, Variety)。在此基础上,IBM的研究人员作了补充,认为应当用4V——即容量、速度、多样性和真实性(Veracity)等四个维度来描述大数据(祝智庭、沈德梅 2013)。
大数据会引起一系列的社会转变。舍恩伯格(2013)前瞻性地指出,大数据带来的信息风暴正在变革我们的生活、工作和思维,大数据开启了一次重大的时代转型,在科学研究领域也会引起研究范式的转变。过去,一个学者一条板凳坐十年做一件事啃一本书。这种情况之所以可能,是因为过去信息不均衡、不流通,信息垄断(如这本书来路独特、为其独有)。在当今时代这种情况几乎是不可能的。
1.文体学研究范式的转变
当今时代,文体学研究范式正在发生转变。传统意义上的文体学是对交流过程中选取和运用的语言、超语言或者是艺术表达方式的研究。20 世纪末,文体学开始取代早期的修辞学,并在此基础上不断扩展。
从本质上说,文体学就是运用语言学中的方法对语篇进行分析,根据研究对象的不同,将文体学划分为普通文体学和文学文体学。文学文体学被认为是语言学和文学批评的桥梁,是文学中语言使用的研究,Leech(1969: 2)说文体学是“语言学与文学交汇的地方”。Widdowson(1975)也将文学文体学定义为“从语言学方向对文学语篇的研究”。普通文体学,是对非文学类语篇的分析,如法律、科技、新闻报道、广告、体育评论、商务报道等语篇的语言或语域特点。
本文中的文体学指的是文学文体学,目标是运用现代语言学的知识对文学作品的语言进行分析和研究,从而帮助读者从语言技巧和思想内容的关系角度去更深入地理解、合理地解释。
文体学研究最早也是始于对文学文体的研究,文学研究有很长的历史,所以研究方法非常丰富,过去对文学作品的分析主要采用定性的方法,定量的方法是近些年才逐步发展完善起来。
传统的定性的文体分析,为了解读不同的作家的风格,必定要从当时的文化、社会背景、作者的生活背景、性格特点等方面进行考虑,而这种分析也会因为不同时代不同人,得出不同的结论。
量化的分析减少对时代背景的考虑,通过统计词汇、句法、篇章层面上的特点来总结得出其文体的特点。计量文体研究的特点是:文本自然真实,文本数量巨大,机器自动处理,定量数据分析(Biber, Conrad & Reppen 1998)。计量文本分析,用数据说话,有其独特的优势:可以发现人们肉眼发现不了的文本特质(Flanders 2005)。文本分析的(freq.)数据分两类:出现频数、共现频数。
计量文体分析不能替代传统范式,只是传统范式的补充。数据自己不会说话,只能用数据说话,最终还是需要人来说话——对数据进行解读。对于特定作品,采用何种特定计量分析手段?全面分析不太可行,必须有针对性地选择分析对象和分析手段。
2. 计量文体学的“三观”分析
文体效果,观察点文体标记(style marker)的选择非常多,如句子长度、某个特定的或特定类别的词(情态动词、转述动词、修饰词),或某种特定的句型等(不及物动词句)。对应的文体效果也很复杂。卢卫中、夏云(2010)从个体语言特征、主题、作家风格三方面综述,阐明三者不是平行或递进关系,有重叠和交叉,需要新的归纳方式。
Mahlberg(2014)认为,假如我们使用新型范畴(innovative categories)描述语言形式,那么凡是偏离这些形式的地方就会为文学文本的阐释提供新的线索。
这些新型范畴就是语料库相关的范畴,可以归纳为“三观”(Jockers 2013)分析,即微观、中观、宏观分析。但没明确界定所指为何,只是把三个词用于章节标题。根据章节的内容,推断其大致意思。微观分析是词语层面的,其对象是单个词;中观分析是短语层面的,其对象是多个词,包括连续的和非连续的;宏观分析是内容层面的,其分析对象是主题词。计量文体学的“三观”分析分别如下:
计量文体学的微观分析:词表wordlist, 词图word plot,
计量文体学的中观分析:词丛word clusters, 搭配collocational analysis,
计量文体学的宏观分析:主题词keyword analysis, 主题建模topic modeling.
为实现上述任务,计量文体分析需要用到语料库、自然语言处理、统计相关的工具和软件,如WordSmith, AntConc, R语言,Python语言等。

图1 语料分析工具(AntConc)
2.1 微观分析——词表(词频)
词语是作品的最小单位,所以被称作微观层面。语料库的词表功能可以提供以下信息:作品总字数,各章节字数,句子长度,平均词长。按字母个数排列,不同长度的单词有哪些?每个词的出现频数?高频词有哪些?低频词有哪些?词汇丰富性?(Lexical richness)
词频分布图,看上去很像条形码,提供的信息比较特别,显示某个词在文本中的分布情况。

图2 词频分布图
文体测量手段可以有效识别不同作家的风格和同一部小说中不同人物的风格,并能够区分仿作 ( parody)与原作风格的异同。文体计量手段多用于著作权归属(authorship attribution)的识别,即通过文体特征的量化统计分析,对特定历史时期由于缺乏外部证据而难以确定作者身份的作品进行甄别。有的研究根据情态动词的使用来确认作品的归属,有的通过考察句长来确定作品的归属(Mannion 2004)。
2.2 中观分析——词丛、搭配
词丛(clusters)是语言使用中的词语聚合现象,在语料库中频率较高的多词单位。Mahlberg借用语料库工具对比分析了容量为四百五十万词的狄更斯的 23 部小说及相同容量的19世纪18个作家的29部小说中的词丛,重点研究了前者语料中由五个词组成的词丛,探讨了这些五词词丛突显人物特点、突出时间和地点信息以及揭示上下文语境等语篇功能。
2.2.1 搭配分析与人物形象
Inaki & Okita(2006)分析了《爱丽丝漫游奇境》和《爱丽丝镜中奇遇》这两个童话故事中爱丽丝角色的转变。他们通过提取转述动词(asked,replied)和“爱丽丝”一词的修饰成分等来分析主人公的角色形象,提出假设,如果人物多用asked表示其角色是积极主动的,如果多用replied则表示被动。索引检索结果显示:前一部作品的主人公作为闯入仙境的不速之客,扮演的是一个小心翼翼的、处境被动的角色,而后一部作品的主人公则是一个积极乐观的、独立的探索者。
2.2.2 搭配分析与文体效果
词语搭配是词语的惯用的组合。在文学作品中,并不是所有的搭配都是循规蹈矩的,有时候非常规搭配能起到非常规的文体效果。Louw(1993)分析了《小世界》(Smallworld)中的搭配bent on self-improvement。
The modern conference resembles the pilgrimage of medieval Christendom in that it allows the participants to indulge themselves in all the pleasures and diversions of travel while apparently bent on self-improvement.
这短语的搭配比较特别,在英语语料库中,bent on后面所接的词语都有负面的意思。因此,bent on是贬义的。这里用的self-improvement,自然也就有了负面的意思,表达反讽的效果。可译为:专注于(岌岌于)所谓的“个人发展”。
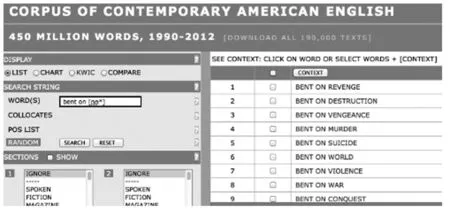
图3 美国当代英语语料库中搭配检索结果
对于一般的外文读者来说,这种现象可能不易被发觉,仅仅依赖字典,只能理解字面意义。只有高水平读者(近似本族语者),对词语用法掌握全面,才能体会到搭配的特殊性和文体效果的精妙之处。

图4 朗文词典中Bent on的释义
2.3 宏观分析
宏观分析不是大而空的泛泛而谈,而是基于数据的与主题内容相关的分析,包括两种分析手段,主题词(Keyword)分析:主题建模。
宏观分析一是主题词(Keyword)分析,计算机能够在瞬间“读懂”大量的文本(几百万字以上),自动抽取出若干主题词。其工作原理是把当前文本与通用语料库中的词频进行对比,根据概率公式计算出每个词的关键值(keyness),关键值较高的几个词就能体现其主题内容,就是语料库中的“主题词”(Scott 2008)。Fischer-starcke (2009)通过比较《傲慢与偏见》与同时代的文学作品,发现比较显著的主题词主要与爱情、婚姻、家庭、女性相关,如family, marriage, sister, cousin。再观察修饰family的人称代词,发现多为第三人称。由此可以说明,说话人不是当前家庭的成员,是外人的身份。
宏观分析之二,主题建模基于主题词的分析。通常情况下,主题词分析的结果是最显著的几个词,但这些词都是孤立的。为了进一步把握文本的主题,有必要在多个主题词之间形成网络。这一目标可通过主题建模实现。工作原理(Jockers 2014)是用概率公式计算每个词的关键值,赋予不同的权重,结果形成可视化的词云图(word cloud)。下图是用MALLET软件Shawn Graham, Scott Weingart, and Ian Milligan’s online tutorial titled “Getting Started with Topic Modeling and MALLET.” http://programminghistorian.org/lessons/topic-modeling-and-mallet.和R语言的程序包,对43部小说的主题建模分析产生的词云图,可以看出主题是“在加州的爱尔兰人”。

图5 词云图
3. 《罗密欧与朱丽叶》计量文体分析
Culpeper (2009)用计量方法分析RomeoandJuliet中人物的特点。他把每个人物的台词抽取出来,建成对比语料库。通过主题词技术,即计算词语的关键值(keyness),发现Juliet最显著的主题词的if,反映女主人公的心理状态:经常猜测未来可能发生的事情,心里感到不确定性。Romeo最显著的主题词是love, beauty, blessed。词频分布(图6)分析表明,love分布最广,几乎涵盖每个场景,尤其集中于第一幕第一场和第二幕第二场。Beauty指的是两个女性,而blessed用来专指Juliet。这些都是用于表达“概念功能”(ideational)的关键词,其它功能(人际、语篇)的关键词也适用于文体分析(Culpeper 2009)。
上述研究从中观层面,用主题词技术分析RomeoandJuliet,但是还不够全面。还有若干问题尚未解决,如关键词之间是如何关联的(即有哪些显著搭配词)?Love是Romeo台词的关键词,为什么不是Juliet的关键词?本文在上述先行研究的基础上继续探讨这些问题。
3.1 研究对象
《罗密欧与朱丽叶》的主题是爱情。本研究关注的问题是:男女主角的爱意如何表达?男女主角表达爱意有何异同?分别有什么文体效果?
表达爱意最常见的说法当然是“我爱你”。假设一个恋人从来不向对方说“我爱你”,是否表示不爱?所以,有必要调查戏剧人物台词中涉及“谁爱谁?”说法。“谁爱谁?”的问题又可以分解成两个:爱谁?谁爱?分别对应Love的对象和Love 的主体。在英语中love的主体和对象一般用人称代词表达。
通过调查Love 与人称代词的共现,可以知道“谁爱谁”。戏剧的视角一般是第一人称。人物在对白或独白的台词中,主要使用第一人称和第二人称,基本不涉及第三人称视角。尤其是在爱情表达方面,必须是当事人亲自面对面表白才有效。所以,本研究关注的love相关的人称代词也只限于第一人称和第二人称代词。
3.2 研究方法与步骤
3.2.1 建立小型语料库
语料是莎士比亚戏剧《罗密欧与朱丽叶》电子版,选自《英文世界名著1000部》(光盘版)。从词语拼写(Thou=you,你)和语法曲折形式(第三人称单数-th=-s,)来看,这个版本是1595年的原版。手工把剧本中Romeo和Juliet的台词分别提取出来,存入单独的纯文本文件,分别命名为romeo.txt, juliet.txt。容量分别是4688, 4606。原始语料,未做词原归并处理(lemmatization)。
3.2.2 语料检索
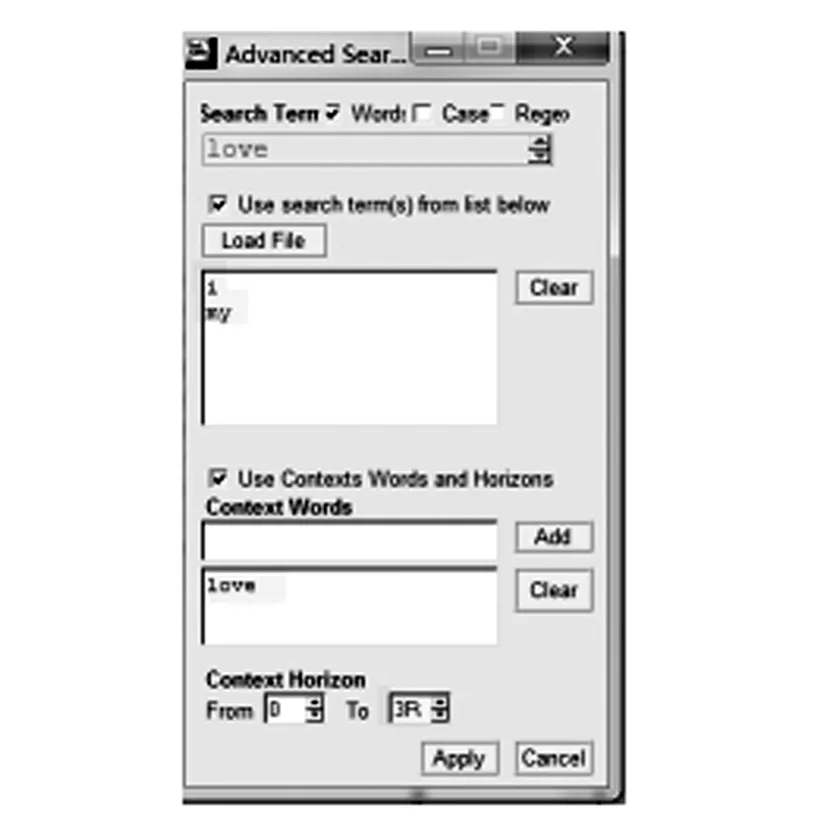
图6 第一人称代词+Love的检索式
为了调查love的表达,本研究用语料库软件AntConc,从两个小语料库中检索love与人代称词共现情况。根据人称代词与love的位置,分别检索love前的第一人称代词和love后的第二人称代词。以前者为例,搜索设置如下:在高级搜索界面,把I, my列入搜索词表,把love加入语境词,语境跨度设为0-3R。Love+第二人称代词的检索式与此相似,只是把人称代词换成thee, thy,语境跨度改为3L-0。
3.3 数据分析
爱的对象——爱谁?根据语料库中“Love+第二人称代词”的搜索结果,Juliet的台词中,love thee的字眼根本没有,只有一例以第二人称为love宾语,thy company。经过重新搜索,却发现Love me有三例,Love him有一例。而在Romeo的台词中,love与 thee共出现六次,其中无关的一次被剔除后还有五次(图7)。由此可见,Romeo与Juliet在爱意的表达方面各有特色。Juliet没有说爱“你”,只要求对方爱“我”,Romeo却把爱“你”挂在嘴边。

图7 Romeo台词中love与第二人称代词共现的索引行
爱的主体——谁爱?在戏剧的台词中,爱的主体默认是说话人,英语中对应的第一人称代词有两种选择:I或my。语料库中“第一人称代词+Love”的搜索结果如表1所示。Romeo的两个代词(I, my)的使用频数比较平均,分别是6次和7次。
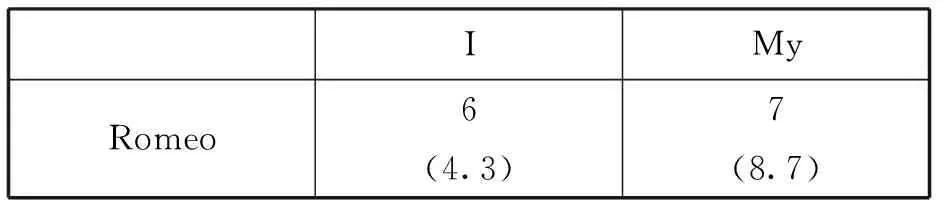
表1 LOVE与第一人称代词的选择

Juliet3(4.7)11(9.3)
*(括号内的数字为理论频数)
Juliet与Romeo台词中的Love总频数差不多,但Juliet更多地使用My love这种名词短语(共11次)。而且,在Juliet的台词中,love前面多用修饰词true (3次), sweet (2), only (1)(例句见图8),这是与Romeo表达爱意的另一种差别。这些形容词的使用,使感情表达显得更为细腻和丰富。

图8 Juliet台词中love与第一人称代词共现的索引行
如何解读这些爱意的表达的差异?从词类看,love兼作动词与名词,都是“爱”的意思。恋人表达爱意时,可以说I love you,也可以说(you are) my love,似乎两者的意思是等同的。实际上,效果略有不同。根据认知语法理论(Langacker 2008),动词表示一种过程(process),名词表示一种实体(entity)。过程是动态变化的,实体是相对静态的永恒。所以,在表达爱情时,人们都希望爱情能够持久永恒,所谓“天长地久”。相对于动词的love而言,名词短语my love更适合表达这种意思。而且,从字面上看,I love you中,我是我,你是你,我和你是两个成分,是两个彼此独立的客体;在my love中,你已然是我的人,两者在同一个短语中,句法距离更近,心理距离也更近。
这种爱意表达式及其意义的区别,是塑造人物性格的重要手段,也说明莎士比亚的语言驾驭能力之娴熟。这种浑然天成的效果应该有一定的必然因素。
4.结论
由于受制于剧本篇幅不长的客观因素,本研究语料规模偏小,但采用的方法具有大数据的主要特点:机器自动处理;定量数据分析。计量文体分析不是为数据而数据,其核心环节是选取恰当的文体标记或文体探测点,提出假设并用数据验证假设,最后结合数据对文学作品的风格进行解读。文体探测点尤其重要,是数据挖掘(data mining)的定位器,好比是采矿过程中的试金石。研究者需要结合当前语料,从复杂的语言系统中选择特定的语言单位作为文体探测点,通过计量观测,可以有效的揭示文学作品的文体风格。
本研究以love相关句式为文体探测点,对莎士比亚戏剧《罗密欧与朱丽叶》中男女主角的台词进行量化分析,发现他们爱意表达方式的差异。Romeo的爱是直接的、直白的,而Juliet的爱是间接的、深沉的、细腻的。这一结论符合男性和女性语言交际和表达的一般规律。虽然本文的结论算不上高大上,但研究的步骤和推理的过程比较严谨。如果学者认可这种基于数据得出结论的方法,可以推广到长篇文学作品研究。
Biber,D., Conrad, S., & Reppen,R.1998.CorpusLinguistics:InvestigatingLanguageStructureandUse[M].Cambridge: Cambridge University Press.
Culpeper.I.2009.Keyness: Words, parts-of-speech and semantic categories in the character-talk of Shakespeare’sRomeoandJuliet[J].InternationalJournalofCorpusLinguistics(14):29-59.
Fischer-Starcke, B.2009.Keywords and frequent phrases of Jane Austen’sPrideandPrejudice: A corpus-stylistic analysis[J].InternationalJournalofCorpusLinguistics(14):492-523.
Flanders, Julia.2005,Detailism,digital texts, and the problem of pedantry[J].TEXTTechnology(2):41-70.
Inaki, A.&Okita.T .2006.A small-corpus-based approach to Alice’s roles[J].LiteraryandLinguisticComputing(3): 13-16.
Jockers, Matthew,L.2013.Macroanalysis:DigitalMethods&LiteraryHistory[M].UIUC Press.
Jockers, Matthew L.2014.TextAnalysiswithRforStudentsofLiterature[M].Springer.
Laney, Doug.3-D Data Management: Controlling data volume, velocity and variety[DB/OL].[2013-04-10].
Langacker,R.W.2008.CognitiveGrammar:ABasicIntroduction[M].Oxford University Press.
Leech, G.N.1969.ALinguisticGuidetoEnglishPoetry[M].London: Longman.
Louw.W.1993.Irony in the text or insincerity in the writer?The diagnostic potential of semantic prosodies [A].M.Baker, G.Francis & E.Tognini-Bonelli (Eds).TextandTechnology[C].Amsterdam: John Benjamins 157-176.
Mahlberg, M.2014.Corpus stylistics[A].M.Burke (Ed.),TheRoutledgeHandbookofStylistics[C].London & New York: Routledge.
Mahlberg,Michaela.2007.Clusters,key clusters and local textual functions in Dickens[J].Corpora(1): 1-31.
Mannion, D.2004.Sentence-length and authorship attribution:The case of Oliver Goldsmith[J].LiteraryandLinguisticComputing(4): 497-508.
Scott, M.R.2008.WordSmith tools help manual (version 5.0)[Z].Liverpool: Lexical Analysis Software.
Widdowson, H.G.1975.StylisticsandtheTeachingofLiterature[M].London: Longman.
编者,1999,《英文世界名著1000部》[Z]。上海:复旦大学出版社。
卢卫中、夏云,2010,语料库文体学:文学文体学研究的新途径[J],《外国语》(1):47-53。
迈尔·舍恩伯格,2013,《大数据时代》[M]。杭州:浙江人民出版社。
祝智庭、沈德梅,2013,基于大数据的教育技术研究新范式[J],《电化教育研究》(10): 5-13。
(詹宏伟:杭州师范大学外国语学院教授,博士; 黄四宏:杭州师范大学外国语学院副教授)
通讯地址:311121浙江省杭州市杭州师范大学外国语学院
*本文系国家哲学社会科学基金青年项目的阶段性成果,项目号:13CYY001。
詹宏伟
黄四宏
杭州师范大学
H06
A
2095-9648(2017)02-0056-06
2017-02-02
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
三联生活周刊(2016年51期)2016-12-24 21:33:57
文学教育(2016年11期)2016-12-15 19:29:28
南风窗(2016年22期)2016-11-02 19:43:31
南都娱乐周刊(2016年36期)2016-10-20 16:42:41
西北工业大学学报(2015年1期)2015-02-22 00:29:19
西北工业大学学报(2015年1期)2015-02-22 00:29:19
沈阳医学院学报(2014年4期)2014-12-27 13:44:34
疑难病杂志(2014年12期)2014-04-16 05:19:35
首都外语论坛(2014年1期)2014-03-20 15:21:28
