
基于机器视觉的装配动作自动分割与识别
2017-06-15 17:02刘明周蒋倩男葛茂根
中国机械工程 2017年11期
刘明周 蒋倩男 葛茂根
合肥工业大学机械工程学院,合肥,230009
基于机器视觉的装配动作自动分割与识别
刘明周 蒋倩男 葛茂根
合肥工业大学机械工程学院,合肥,230009
在对装配作业人员进行动作分析的过程中,动作的识别和记录一般通过手工操作完成,这种方法不仅工作量大,而且效率低。为解决该问题,提出了一种新的基于机器视觉的装配动作自动分割与识别方法。首先利用基于内容的动态关键帧提取技术提取视频流中的关键帧,实现动作的自动分割;然后提取感兴趣区域的尺度不变局部特征点,据此得出关键帧的特征向量;最后,基于支持向量机构建特征向量分类器对动作进行分类。装配线上样本视频的实验结果表明,所提方法达到了96%的正确识别率。
动作的分割与识别;关键帧提取;尺度不变局部特征点;支持向量机
0 引言
在有人参与的机械产品装配作业中,需要通过动作分析来找到动作存在的问题,以改善动作的顺序和方法,进而消除浪费、减轻疲劳、提高工作效率[1-2]。动作分析的第一步就是对动作进行观察、分解、记录。一般情况下,动作的观察和分解是由人员多次观察作业实施过程来完成的,这就导致动作分析的工作量增大、效率降低,因此需要通过机器自动完成装配环境下连续动作的观察、分解、记录,进而减少动作分析的工作量,提高动作分析的效率。
随着图像获取与图像处理方法的发展,基于机器视觉的动作识别已经在视频监控[3]、视频检索、智能接口[4-5]、虚拟现实、医疗看护[6]等领域获得广泛应用。CAMPBELL等[7]利用立体摄像机实时采集的三维数据并基于HMM模型进行手势识别。DAVIS等[8]提出了一种基于视图的动作表示和识别方法,并利用18个健美操动作验证了方法的有效性。STAUFFER等[9]开发了一个可视化的监控系统,该系统在室内环境或室外环境中使用多个摄像头实现了人体的追踪。LAPTEV[10]采用图像处理技术提取人体动作的时空特征,当存在遮挡或背景发生变化时依据该特征仍能够实现行走动作的检测。NIEBLES等[11]提出了一种基于潜在主题模型的无监督学习算法,并利用该算法实现KTH数据集、Weizmann数据集以及花样滑冰动作集上人体动作的分类和定位。SHI等[12]利用半马尔可夫模型进行动作的分割与识别,通过Walk-Bend-Draw数据集以及CMUMobo数据集进行方法验证。REDDY等[13]提出了一种基于动作特征以及场景信息的动作识别方法,该方法能够解决HMDB51数据集中的动作识别问题。GUO等[14]应用基于时空特征的正则化的多任务学习方法,实现了TJU数据集的动作识别。
然而,装配环境下连续的人体动作的分割与识别问题在文献中尚未被讨论过。装配环境下连续的人体动作的分割与识别是一个具有挑战性的问题,该问题具有以下几个难点:①一段视频中往往包含一连串的动作,由于连续动作之间没有明显的边界,且动作执行的速度会影响动作的持续时间,因此,无监督的动作分割是非常困难的;②在装配环境中光照条件以及图像背景是不断变化的;③人体的装配动作与现实环境有密切的联系,人体动作的种类不仅取决于人体动作本身的特征而且与环境中的物体有直接的联系。
本文针对装配作业的连续动作提出了一种有效的自动分割与识别方法,为解决第一个难点,该方法应用基于内容的动态关键帧提取技术实现连续视频中动作的分割;为解决第二个难点,该方法一方面基于SIFT(scaleinvariantfeaturetransform)特征点匹配寻找目标区域,另一方面应用支持向量机(supportvectormachine,SVM)来构建分类器进行特征向量分类,进而增强了动作识别算法的鲁棒性;为解决第三个难点,该方法同时提取人手和工件的SIFT特征点,应用特征点之间的位移向量表示人与环境的联系。通过使用上述方法可以有效地完成装配环境下连续动作的自动观察、分解与记录。
1 方法
在进行动作识别之前,应首先对连续的动作进行分割,然后基于动作的静态特征、动态特征、时空特征或描述性特征对各个动作进行分类。动作的动态特征、时空特征以及描述性特征需从连续的图像帧中提取,而静态特征可从单帧图像中直接获取。由于本文是基于静态特征进行动作识别的,因此将单帧图像作为处理对象。
本文的动作分割与识别过程如图1所示。首先,利用基于内容的动态关键帧提取算法提取视频流中的关键帧,其作用是减少后续处理对象的数量,实现连续动作的自动分割;然后,提取关键帧中的感兴趣区域(regionofinterest,ROIs)(包括人手和工件两类区域)以及ROIs的SIFT特征点,并依据特征点计算ROIs之间的位移向量集,该位移向量集即为关键帧的特征向量;最后,基于支持向量机对样本图像的特征向量进行训练,得到特征向量分类器,接着将关键帧的特征向量输入到分类器中识别出特征向量种类,并结合关键帧的时序特征以及特定场景下的判断规则识别出动作所属的动素类型。
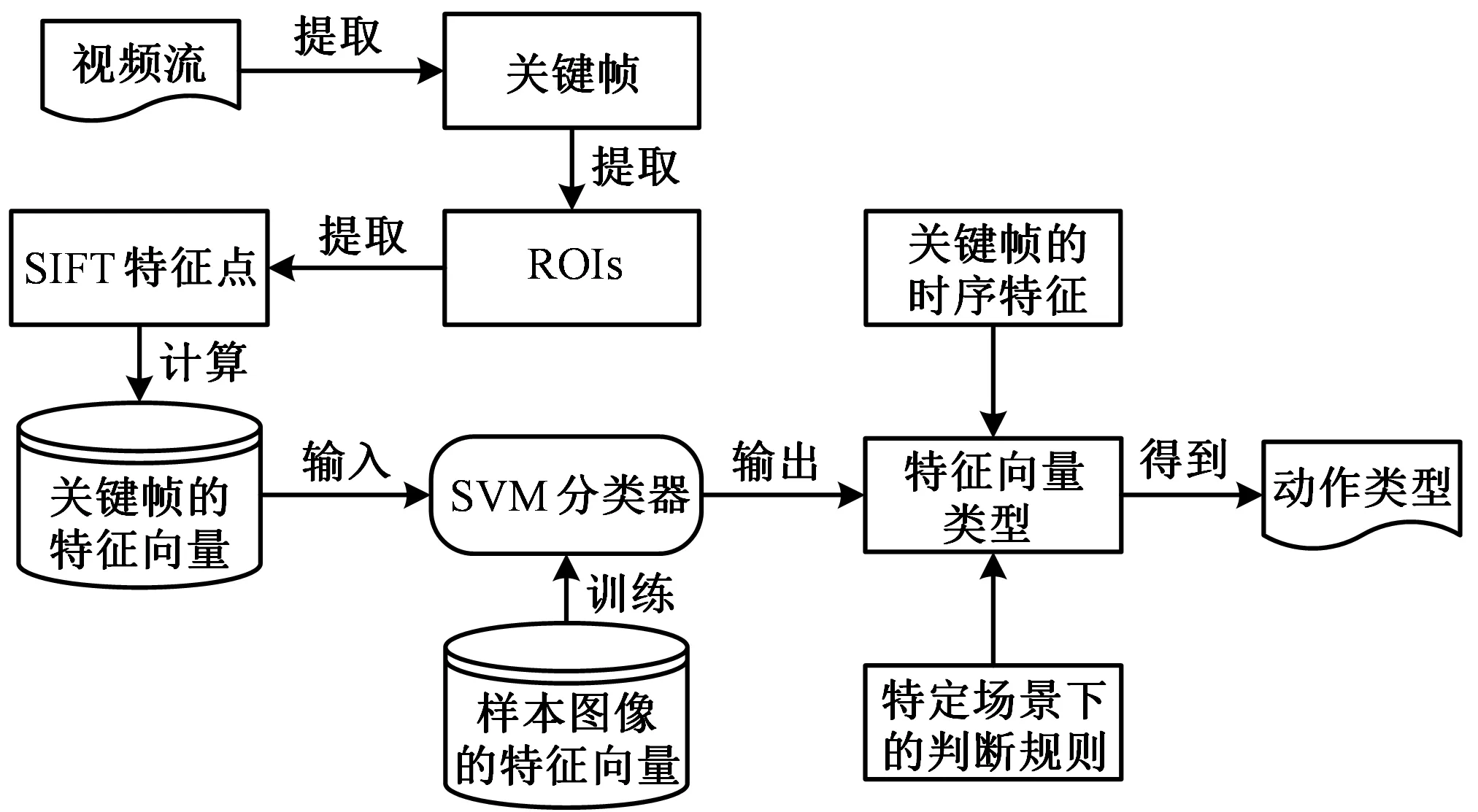
图1 动作识别的算法流程Fig.1 Algorithm flow of motion recognition
1.1 关键帧提取
关键帧提取的准则是考虑帧之间的不相似性[15]。基于内容的关键帧提取是依据每一帧的颜色、纹理等视觉信息的改变来提取关键帧[16],当这些信息有显著变化时,当前帧即可为关键帧。关键帧提取技术减少了后续图像处理计算帧的数量,从而确保了动作识别算法的时效性。
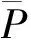
(1)
每个子块的平均灰度值表示为
(2)
i=0,1,2,…,K1-1
j=0,1,2,…,K2-1
t=0,1,2,…,N-1
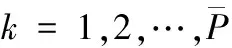
其中,i表示图像子块所在的行,j表示图像子块所在的列,N表示K1×K2个大小相同的图像子块数,E(Ht(i,j))表示第i行、第j列图像子块的平均灰度值。因此,可以得到每一帧图像的平均灰度值E(H)以及每个子块灰度值的分散程度σ2(E(Ht(i,j))):
(3)
σ2(E(Ht(i,j)))=[E(Ht(i,j))-E(H)]2
(4)
任意一帧图像s的特征向量为
Fs=(E(H1)s,σ2(E(H1(i,j)))s,E(H2)s,
σ2(E(H2(i,j)))s,…,E(HN)s,σ2(E(HN(i,j)))s)
(5)
令第p帧图像和第q帧图像的特征向量分别为Fp和Fq,则这两个特征向量的欧氏距离为
(σ2(E(Ht(i,j)))p-σ2(E(Ht(i,j)))q)2]
(6)
式中,函数dis(Fp,Fq)表示特征向量Fp与Fq之间的欧氏距离;函数sqrt()表示一个数的平方根。
令相机采集的第一帧图像为关键帧,并预先设定一个关键帧阈值T,按图2所示的流程提取关键帧。首先,计算第一帧特征向量与它的后序帧特征向量间的欧氏距离,若某个后序帧的距离值大于T,则该后序帧即为关键帧,并从视频流中提取出来。然后,计算当前提取的关键帧特征向量与它的后序帧特征向量间的欧氏距离,若某个后序帧的距离值大于T,则提取新的关键帧。按此步骤依次进行,直到视频的最后一帧结束。按照以上流程不仅可以得到视频中的关键帧序列,而且可以实现连续动作的自动分割。
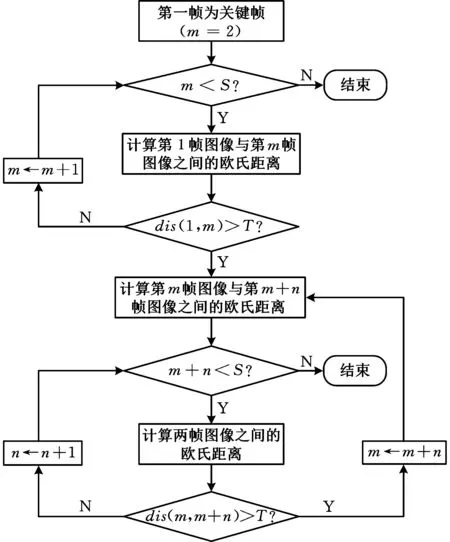
图2 关键帧提取流程Fig.2 Key frame extraction process
1.2 提取感兴趣区域
由于关键帧中的工件具有很好的形状特征,故本文采用基于形状的模板匹配算法提取工件区域。该算法将模板内像素梯度向量的内积总和作为相似性度量,并通过计算内积总和最小值来确定最佳匹配位置。同时,为能够进行较快的搜索,该算法采用图像金字塔进行分层搜索,先从金字塔的较高层搜索,得到模板的大概位置,然后使用次高层的图像在这个大概位置的周围进行更准确的搜索[17],依此进行,直到在图像金字塔的最底层搜索到模板区域。
为提取人手区域,本文首先将关键帧从原来的色彩空间变换到YCbCr色彩空间,基于肤色模型分割肤色区域与非肤色区域,获得多个连通区域,再对连通区域进行闭运算填充空洞,最终依据形状特征提取手部目标区域并去除其他连通区域。提取流程如图3所示。
1.3 提取ROIs的SIFT特征点
LOWE[18]提出一种优化的SIFT特征算子,该算子具有尺度不变性、平移不变性、旋转不变性、视角不变性、光照不变性,当外部因素发生变化(背景变化,环境噪声,遮挡)时该算法也能保持较好的匹配效果。因此,基于SIFT描述特征算子的匹配算法己经被成功地应用于物体识别、机器人定位、指纹及人脸识别等诸多领域[19]。
SIFT特征点提取和匹配算法包括如下3个步骤:
(1)提取模板图像和关键帧图像中ROIs的SIFT特征点。在高斯金字塔(DoG)尺度空间检测局部极值点,检测点如果和它同尺度的8个相邻点以及上下相邻尺度对应的18个点共26个邻域点比较是最大值或最小值,并且该检测点具有稳定性,那么该点就是图像在该尺度下的SIFT特征点。由于DoG值对噪声和边缘较敏感,因此,在上面DoG尺度空间中检测到的局部极值点还要经过进一步的检验才能精确定位为特征点[20]。
(2)生成模板图像SIFT特征点的描述子。首先在特征点邻域窗口内采样,并计算邻域像素的梯度直方图(直方图的峰值位置即为该特征点梯度的主方向),使算子具备旋转不变性[21]。为了增强匹配的稳健性,用4×4×8共128维向量表征特征点的描述子。

(a)原始图片

(b)肤色区域

(c)人手区域图3 人手区域提取流程Fig.3 The process of hand detection
(3)通过特征点匹配得到关键帧中的特征点集。通过计算模板图像目标特征点与关键帧目标特征点的SIFT描述子之间的欧氏距离作为SIFT特征点的相似度度量,在关键帧目标区域内SIFT特征点中,找出与模板图像目标中某个特征点描述子欧氏距离最近和次近的两个特征点。若最近的距离E与次近的距离F的比值d(E, F)小于阈值TE,F,则模板图像目标特征点与关键帧目标特征点匹配,从而得到关键帧中目标特征点的点集[22]。
1.4 动作识别
1.4.1 获取图像的特征向量
机械产品装配作业中的动作识别实质上就是识别该动作所属的动素类型。一个简单的装配作业通常包含以下4类动素:伸手、握取、移物、装配。在需要双手同时操作的机械产品装配作业中,ROIs一般由人的左右手和2个工件组成。通过SIFT特征点匹配可得到左手的特征点集M1(含有m1个特征点)、右手的特征点集M2(含有m2个特征点)、工件1的特征点集N1(含有n1个特征点)、工件2的特征点集N2(含有n2个特征点)。若用(A , B)表示特征点集A和特征点集B间的位移向量集,那么特征点集M1、M2、N1、N2之间两两组合,可得到(M1, M2)、(M1, N1)、(M1, N2)、(M1, N1)、(M2, N2)、(N1, N2)这6类位移向量集,这些位移向量集就是关键帧的特征向量,且每类位移向量集中都包含Ri( i = 1,2,…,6 )个位移向量,其中
Ri=Aj×Bk
(7)
式中,Aj为特征点集A的特征点个数;Bk为特征点集B的特征点个数。
1.4.2 基于SVM构建分类器
SVM是在统计学习理论的基础上发展起来的一种新的机器学习方法,常用于解决小样本、非线性及高维的模式识别问题。当输入向量维数较多时使用BP、RBF等人工神经网络进行模式识别,可能造成网络规模过大、训练困难等问题,而对于SVM方法,它的计算量几乎与维数无关,因此SVM更适合处理输入维数较大的问题。基于SVM构建分类器的算法流程如下:
(1)样本准备。关键帧经上述处理后可以得到位移向量集(A,B),该位移向量集为图片的一个特征向量。在进行训练之前,由专家判定该特征向量的种类。如果两个感兴趣区域接近,则标记特征向量的类别z={1};如果两个目标区域不接近,则标记特征向量的类别z={0}。用T=(A,B)=((x1,y1),(x2,y2),…,(xm,ym))表示特征向量,其中(xi,yi)(i=1, 2,…,m)表示每一个位移向量的坐标。将(T,z)作为分类器的输入样本。
(2) 构建分类器。由位移向量集(A,B)在二维坐标系中的分布(图4)可知,该问题是线性不可分的。针对该问题,首先在低维空间中完成计算,然后通过满足Mercer条件的核函数K(X,Y)将输入空间映射到高维Hiltert特征空间,最终在高维特征空间中构造出最优分离超平面,使所有样本点到超平面的距离最小,从而使样本点在高维空间中变得线性可分。通过高斯核函数将样本数据映射到高维空间,映射过程如图4所示。

图4 位移向量点的分布以及映射过程Fig.4 Distribution of displacement vector points andmapping process
令X=T=((x1,y1),(x2,y2),…,(xm,ym))且令Yk=z(k=1,2,…,K;K为一张图片所包含特征向量的个数),则样本集合表示为{(X1,Y1),(X2,Y2),…,(XK,YK)},其中样本特征XK∈R2。将二维空间样本点映射到特征空间得到非线性判别函数:
(8)

f′(X)|≥1-ξkk=1,2,…,K
(9)
其中,ξk为松弛变量,ξk≥0,它们用于度量一个数据点对线性可分理想条件的偏离程度。当0<ξk≤1时,数据点落入分离区域的内部,且在分类超平面的正确一侧;当ξk>1时,数据点进入分类超平面错误一侧;当ξk=0时,相应的样本点满足f′(X)|=1,表明该样本点离超平面最近,且称这样的样本点的特征向量为支持向量。由于f′(X)|≥1-ξk与Yk(|f′(X)|)≥1-ξk等价,所以最优分类面的问题就可以转化为约束条件下最小化关于wTw和松弛变量ξk的代价函数问题。代价函数如下所示:
(10)
式中,C是使用者选定的正参数,它控制对错误分类样本的惩罚程度,称为惩罚因子。
采用Lagrange系数方法解决约束最优问题。Lagrange函数变为
(11)
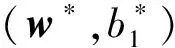
(12)
1.4.3 动作识别
对于简单的机械产品装配作业,可以将位移向量分为三类:人手相对于工件的位移向量(M,N)、人手相对于人手的位移向量(M,M)、工件相对于工件的位移向量(N,N)。按照上述方法由位移向量集(M,N)、(M,M)、(N,N)训练出三类分类器F1(X)、F2(X)、F3(X)。将关键帧的特征向量输入分类器,按图5所示的流程识别出关键帧中动作的动素类型。图5中,第Ⅰ类位移向量表示手与工件靠近,第Ⅱ类位移向量表示手与工件远离;第Ⅲ类位移向量表示手与手靠近,第Ⅳ类位移向量表示手与手远离;第Ⅴ类位移向量表示工件与工件靠近,第Ⅵ类位移向量表示工件与工件远离。

图5 动素类型识别流程Fig.5 The process of therblig recognition
首先,将不同种类的特征向量输入到不同的分类器中,识别出位移向量的种类。然后,依据机械产品装配场景下的判定规则和关键帧的时序特征识别出动素类型。若关键帧中包含第Ⅱ类位移向量、第Ⅳ类位移向量、第Ⅵ类位移向量,则该关键帧中的动素类型为伸手;若关键帧中包含第Ⅰ类位移向量、第Ⅳ类位移向量、第Ⅵ类位移向量,则该关键帧中的动素类型为握取或移物;若关键帧中包含第Ⅰ类位移向量、第Ⅲ类位移向量、第Ⅴ类位移向量,则该关键帧中的动素类型为装配。包含握取动素的图像帧和包含移物动素的图像帧具有不同的视觉信息,因此都能作为关键帧被提取出来。由于视频流中的图像帧是按时间的先后排列的,所以包含握取动素的关键帧一定在包含移物动素的关键帧之前。因此,按照关键帧的时序特征即可将握取和移物两种动素区分开来。
2 实验过程及结果分析
本文通过模拟真实的螺栓装配过程来验证本文方法的可行性以及鲁棒性。实验框架包括操作者、工件以及机器视觉系统,其中工件包括螺栓(M8×15)和螺母(M8×1.5);机器视觉系统包括光源(DH, LER2-90S W2)、CCD彩色相机(DH, SV2000GM/C 1/1.8″ 1628 × 1236 )以及镜头(DH, model M3Z1228C-MP)。装配线上的原型系统如图6所示。本文利用HALCON进行图像处理,利用MATLAB进行分类器训练以及动作识别。实验过程如下:①拍摄左手握取螺栓、右手握取螺母的样本图片各一张;②拍摄双手装配螺栓的样本图片一张;③拍摄操作者装配螺栓的视频,且拍摄过程中光照强度不断变化,视频中包含500个动作周期,每个动作周期都包含伸手、握取、移物、装配4个动素。将50个动作周期作为一个大周期,第一个大周期的光照强度为500 lx,第二个大周期的光照强度为300 lx,按照以上规律,每隔1个大周期光照强度交替变化。

图6 原型系统Fig.6 Prototype system
2.1 提取样本图片的特征向量
在进行样本图片特征提取之前,应该对样本图片进行一系列的预处理。首先,利用高斯滤波器消除图片的噪声和光照影响,并将RGB色彩空间转化成YCbCr色彩空间;然后在Cr分量下设定肤色阈值范围为140~160,通过阈值分割获得多个连通区域,再对连通区域进行闭运算填充空洞;最后,提取区域面积大于35000的区域,该连通区域即为人手区域。在获取人手区域后,将经过去噪处理的样本图片与创建好的螺栓模板以及螺母模板进行模板匹配,得到螺栓和螺母所在区域。样本图片经过预处理得到ROIs后,提取ROIs的SIFT特征点,其中左手和右手各有58个特征点,螺栓和螺母各有21个特征点。依据SIFT特征点的坐标,将人手作为起点计算人手到工件的位移向量,将左手作为起点计算双手之间的位移向量,将螺栓作为起点计算工件之间的位移向量,得到样本图片的特征向量。
2.2 动作识别
首先提取视频流中的关键帧,图7为关键帧的4个图例。由图7可知,关键帧提取技术在实现关键帧提取的同时也对动作进行了分割。然后,基于样本SIFT特征点获取关键帧ROIs的特征点,并计算特征点集之间的位移向量,进而得到(M1,M2)、(M1,N1)、(M1,N2)、(M1,N1)、(M2,N2)、(N1,N2)6类位移向量集,且(M1,M2)包含3364个位移向量,(M1,N1)、(M1,N2)、(M1,N1)、(M2,N2)包含1218个位移向量,(N1,N2)包含441个位移向量。图7中4幅关键帧的特征向量如表1~表4所示。

图7 关键帧的4个图例Fig.7 Four legends of key frames
当关键帧提取相关参数K1=16、K2=12、T=14.14时,从包含500个动作周期的视频中可提取2524个关键帧。在进行分类器训练与验证之前,先由专家识别出每一个关键帧的动作所属的动素类型。本文选定下面的高斯核函数来构建支持向量机模型:
exp(-γ|X-Xk|2)
(13)
利用交叉验证方式选择精度最高的参数对(C,γ)作为分类器模型的参数,并将前1516个关键帧(包含300个运动周期)作为训练集,将余下的1008个关键帧(包含200个运动周期)作为验证集。每个样本包含3类位移向量(M,N)、(M,M)、(N,N),它们分别用于分类器F1(X)、F2(X)、F3(X)的参数选择。交叉验证优化后得到F1(X)的最优参数为:C1=2.0,γ1=0.031 25;F2(X)的最优参数为:C2=3.5,γ2=0.055 56;F3(X)的最优参数为:C3=5.0,γ3=0.125。由训练得到的模型来对全部的2524个样本进行测试,测试结果如图8所示,识别准确率为96%。以上过程通过MATLAB程序实现。
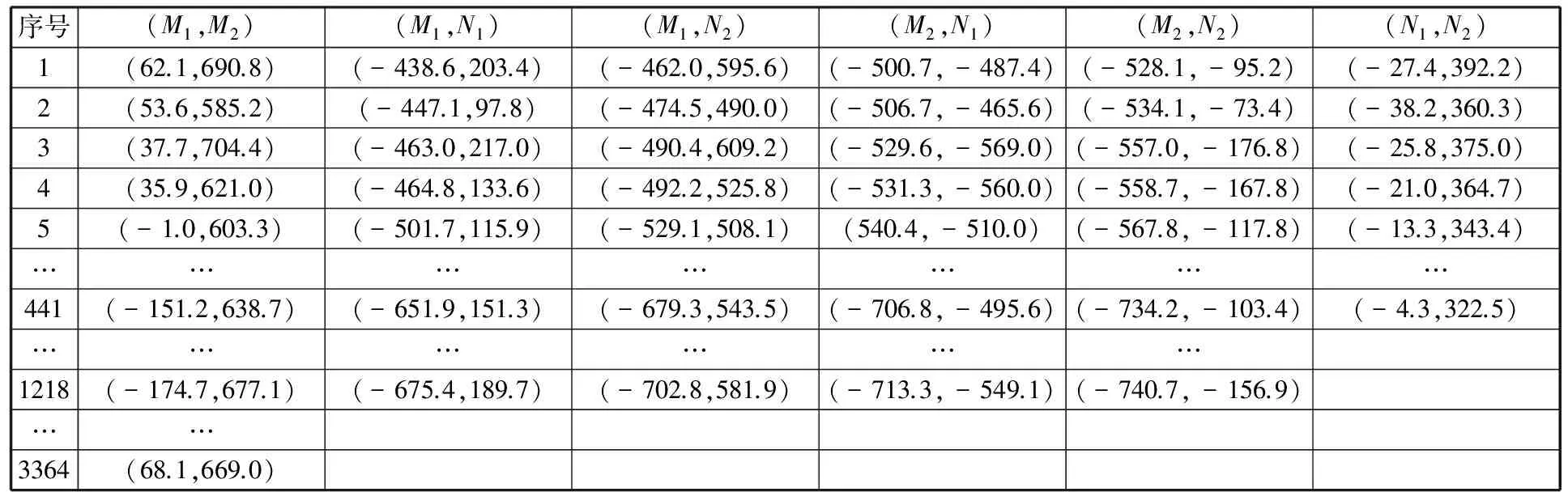
表1 关键帧A的特征向量
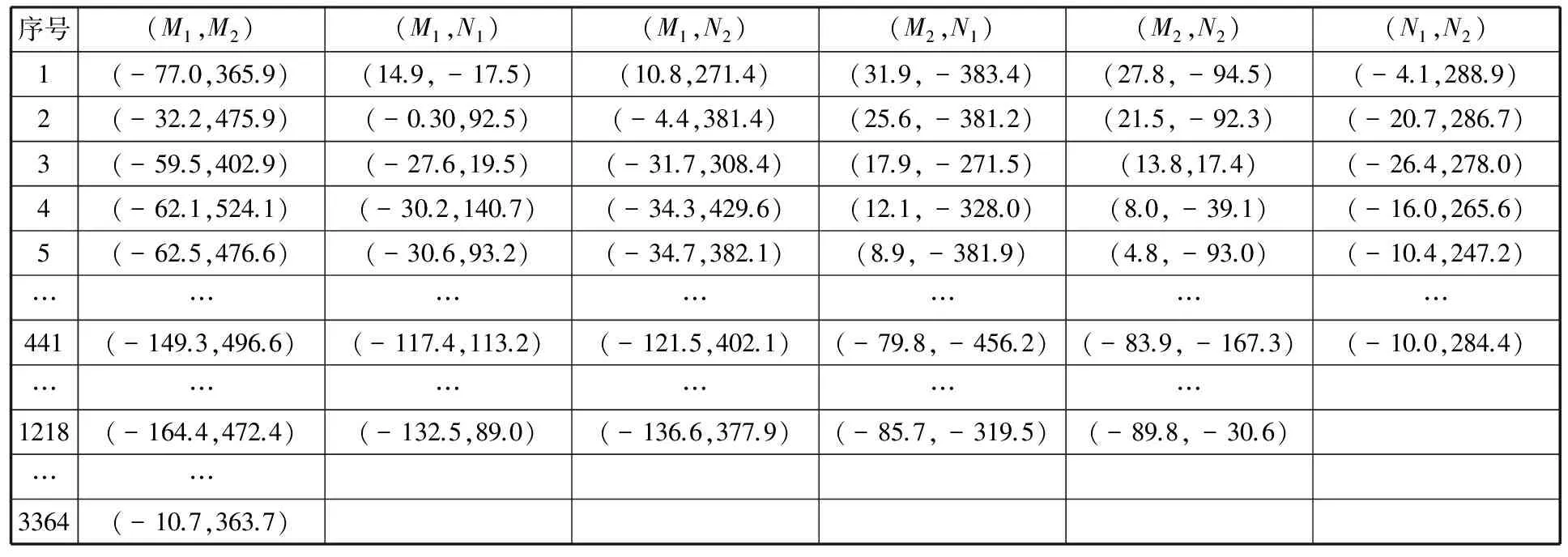
表2 关键帧B的特征向量
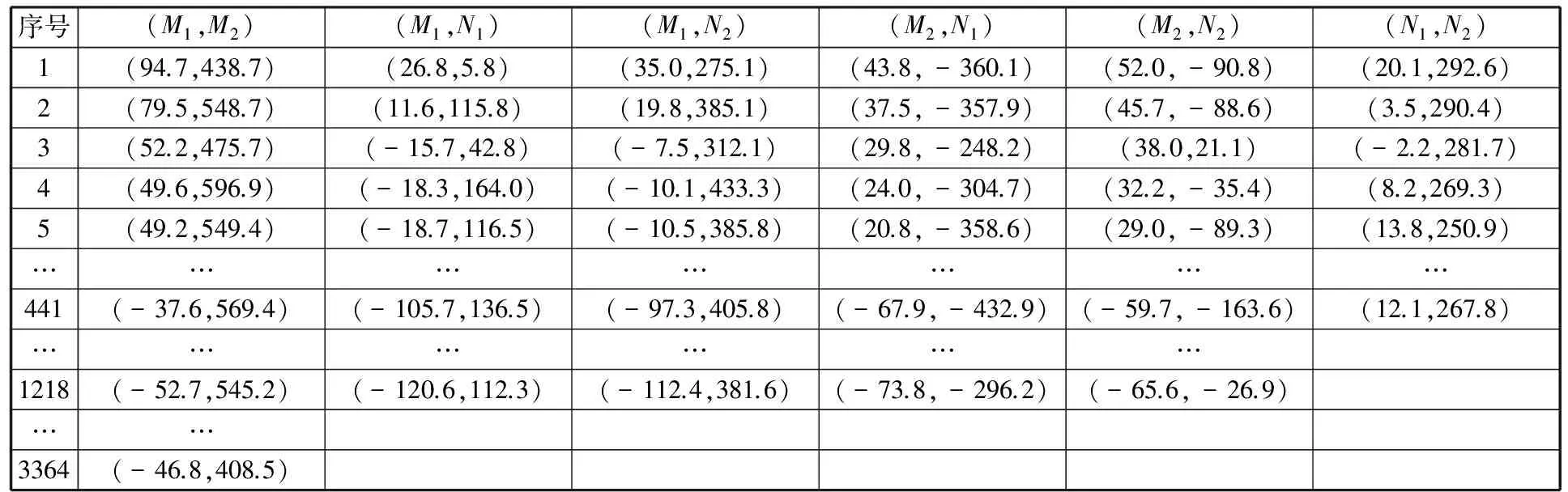
表3 关键帧C的特征向量
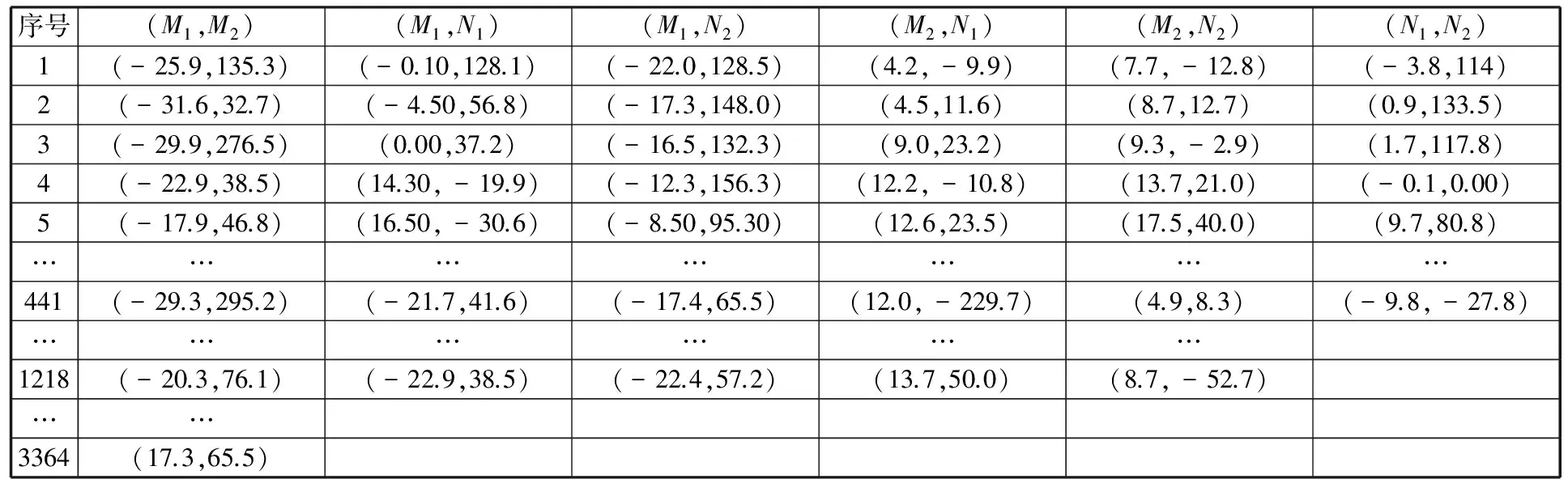
表4 关键帧D的特征向量

图8 动作分类的混合矩阵Fig.8 Confusion matrix of motion categories
2.3 动作记录
由于每个动作周期都包含伸手、握取、移物、装配4个动素,因此500个动作周期应包含2000个动素,由此可见,视频的关键帧的数目大于动素的数目。因此,视频中相邻的关键帧可能属于同一个动素,为了避免动素的重复记录,当相邻关键帧动素类型不同时,记录两个动素,当相邻关键帧的动素类型相同时,只记录第一个动素。将基于本文方法识别出的动素类型与实际的动素类型相比较,前4个周期的比较结果如图9所示。
由图9可知,基于该方法能够准确地识别出动作所属的动素类型,但是依据该方法得到的动素持续时间与实际观测得到的动素持续时间之间存在微小的差异。产生这种现象的原因在于:该方法的识别对象是关键帧,而不是视频流中的每一帧。当对视频流中的每一帧图像都进行识别时,不会出现图9中的时间差异,但逐个识别所有帧就会大大降低整体算法的时效性,同时也会产生大量的冗余数据。因此,当对动作分析的时间精度要求不高时,把关键帧作为动作识别的对象是合理的。
3 结论
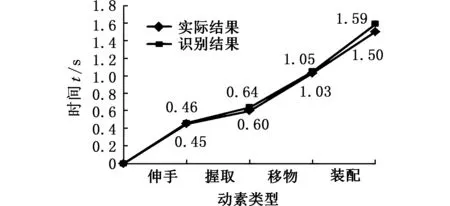
(a)周期1
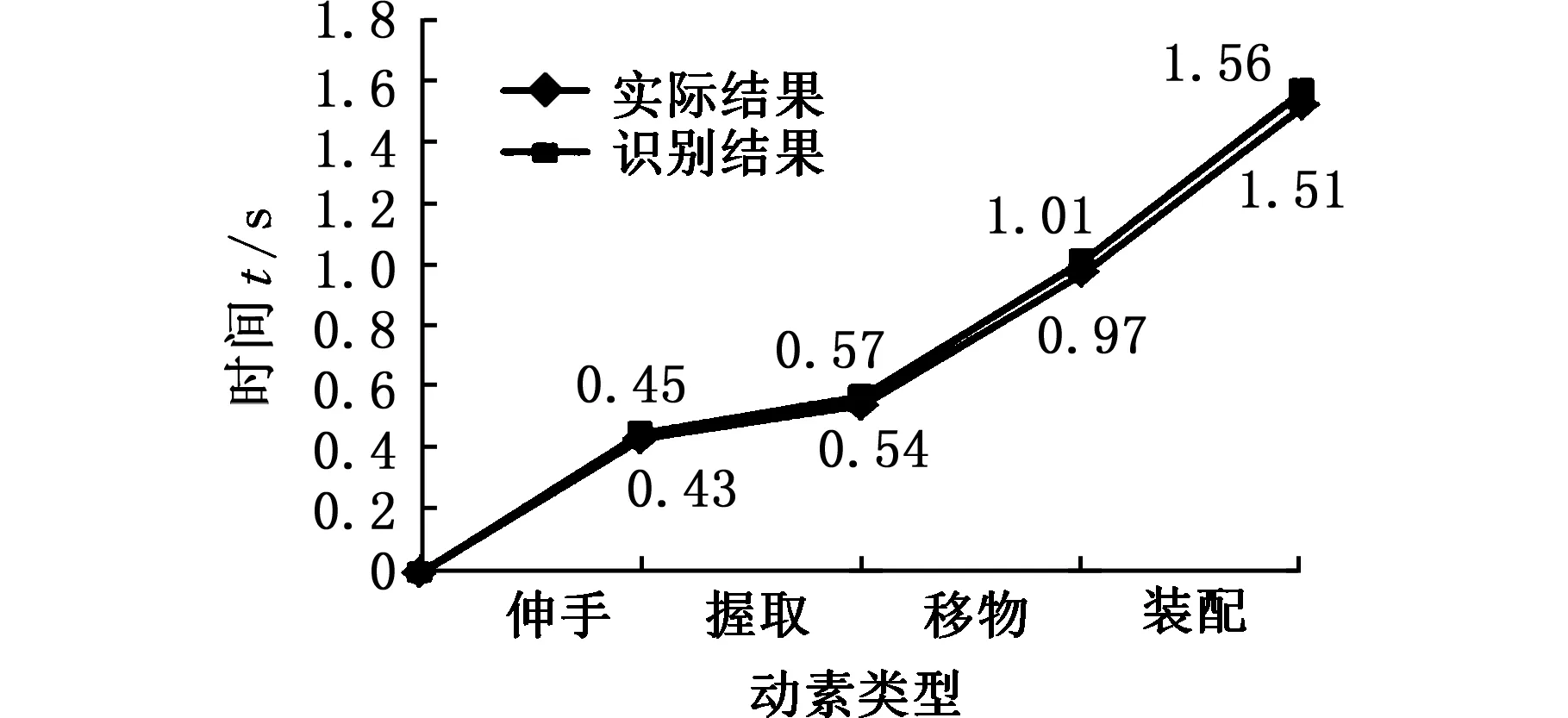
(b)周期2

(c)周期3
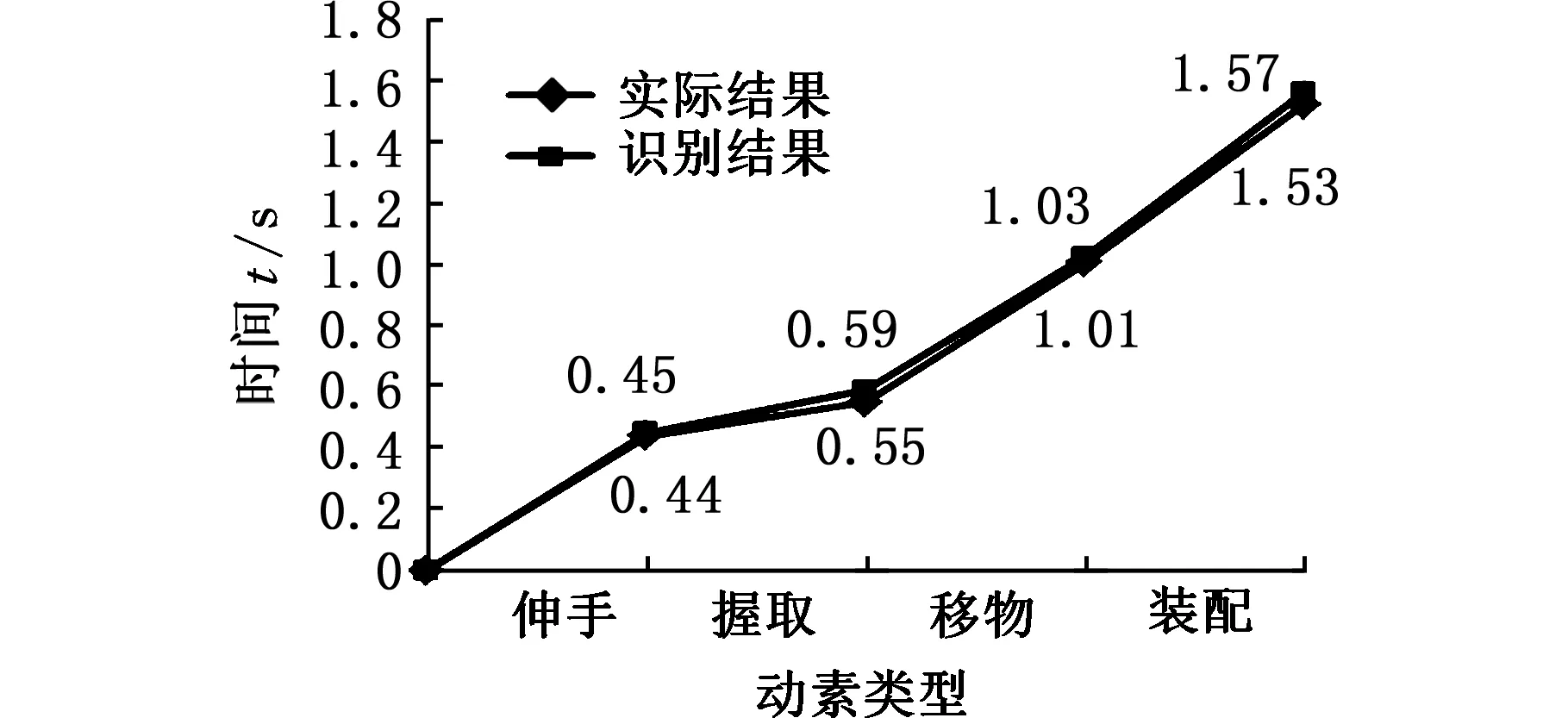
(d)周期4图9 前4个周期的对比结果Fig.9 The comparison results of the first four cycles
本文提出了一种新的基于机器视觉的装配动作自动分割与识别方法。实验结果表明该方法能够准确地识别出动素所属类型,并记录每个动素以及每个动素持续的时间。该方法具有以下特点:①基于ROIs的SIFT特征点建立动作与环境的联系;②为提高方法的时效性,一方面,利用关键帧提取技术减少后续待处理图像的数量,另一方面,提取ROIs减少后续待处理像素的数量;③基于SVM构建动作分类器,解决了由于输入维数较大造成的训练困难等问题;④该方法不仅实现了动作的自动观察、分解和记录,而且减少了动作分析员的工作量,提高了动作分析的效率。该方法还可以推广到其他人机交互识别领域。
[1]HUANGC,NOFSY.HandbookofIndustrialEngineering:TechnologyandOperationsManagement,ThirdEdition[J].QualityProgress, 2007(May):1041-1110.
[2]FLOREANR,KOTAPATIS,KUTIJL,etal.CostAnalysisofContinuousVersusIntermittentInfusionofPiperacillin-tazobactam:aTime-motionStudy[J].AmericanJournalofHealth-systemPharmacyAJHP:OfficialJournaloftheAmericanSocietyofHealth-systemPharmacists, 2003, 60(22):75-83.
[3]LAOW,HANJ,DeWITHPHN.AutomaticVideo-basedHumanMotionAnalyzerforConsumerSurveillanceSystem[J].IEEETransactionsonConsumerElectronics, 2009, 55(2):591-598.
[4]POPPER.ASurveyonVision-basedHumanActionRecognition[J].Image&VisionComputing, 2010, 28(6):976-990.
[5]TURAGAP,CHELLAPPAR,SUBRAHMANIANVS,etal.MachineRecognitionofHumanActivities:aSurvey[J].IEEETransactionsonCircuits&SystemsforVideoTechnology, 2008, 18(11):1473 - 1488.
[6]JALALA,UDDINMZ,KIMTS.DepthVideo-basedHumanActivityRecognitionSystemUsingTranslationandScalingInvariantFeaturesforLifeLoggingatSmartHome[J].IEEETransactionsonConsumerElectronics, 2012, 58(3):863-871.
[7]CAMPBELLLW,BECKERDA,AZARBAYEJANIA,etal.InvariantFeaturesfor3-DGestureRecognition[C]//InternationalConferenceonAutomaticFaceandGestureRecognition.NewYork:IEEE, 1996:157-162.
[8]DAVISJW,BOBICKAF.TheRepresentationandRecognitionofActionUsingTemporalTemplates[J].Proc.ofCVPR, 2000, 23(3):928-934.
[9]STAUFFERC,GRIMSONWEL.LearningPatternsofActivityUsingReal-timeTracking[J].IEEETransactionsonPatternAnalysis&MachineIntelligence, 2000, 22(8):747-757.
[10]LAPTEVI.OnSpace-timeInterestPoints[J].InternationalJournalofComputerVision, 2005, 64(2):107-123.
[11]NIEBLESJC,WANGH,LIFF.UnsupervisedLearningofHumanActionCategoriesUsingSpatial-TemporalWords[J].InternationalJournalofComputerVision, 2008, 79(3):299-318.
[12]SHIQ,CHENGL,WANGL,etal.HumanActionSegmentationandRecognitionUsingDiscriminativeSemi-MarkovModels[J].InternationalJournalofComputerVision, 2011, 93(1):22-32.
[13]REDDYKK,SHAHM.Recognizing50HumanActionCategoriesofWebVideos[J].MachineVision&Applications, 2013, 24(5):971-981.
[14]GUOW,CHENG.HumanActionRecognitionviaMulti-taskLearningBaseonSpatial-temporalFeature[J].InformationSciences, 2015, 320:418-428.
[15]CHATZIGIORGAKIM,SKODRASAN.Real-timeKeyframeExtractiontowardsVideoContentIdentification[C]//InternationalConferenceonDigitalSignalProcessing.Piscataway,NI:IEEEPress, 2009:1-6.
[16]NAVEEDE,TAYYABBT,SUNGWookBaik.AdaptiveKeyFrameExtractionforVideoSummarizationUsinganAggregationMechanism[J].JournalofVisualCommunicationandImageRepresentation, 2012,23(7):1031-1040.
[17]TANIMOTOSL.TemplateMatchinginPyramids[J].ComputerGraphics&ImageProcessing, 1981, 16(4):356-369.
[18]LOWEDG.DistinctiveImageFeaturesfromScale-invariantKeypoints[J].InternationalJournalofComputerVision, 2004, 60(2):91-110.
[19]LIY,SNAVELYN,HUTTENLOCHERDP.LocationRecognitionUsingPrioritizedFeatureMatching[M]//KostasDaniilidis,PetrosMaragos,NikosParagios.ComputerVision-ECCV2010.Berlin:Springer, 2010:791-804.
[20]APROVITOLAA,GALLOL.EdgeandJunctionDetectionImprovementUsingtheCannyAlgorithmwithaFourthOrderAccurateDerivativeFilter[C]// 2014TenthInternationalConferenceonSignal-ImageTechnology&Internet-BasedSystems(SITIS).WashingtonDC:IEEEComputerSociety, 2014:104-111.
[21]MAYM,TURNERM,MORRIST.AnalysingFalsePositivesand3DStructuretoCreateIntelligentThresholdingandWeightingFunctionsforSIFTFeatures[C]//PacificRimConferenceonAdvancesinImageandVideoTechnology.Heidelberg:Springer-Verlag, 2011:190-201.
[22]LIB,YUS,LUQ.AnImprovedK-nearest-neighborAlgorithmforTextCategorization[J].ExpertSystemswithApplicationsanInternationalJournal, 2012, 39(1):1503-1509.
(编辑 苏卫国)
Automatic Segmentations and Recognitions of Assembly Motions Based on Machine Vision
LIU Mingzhou JIANG Qiannan GE Maogen
School of Mechanical Engineering,Hefei University of Technology,Hefei,230009
The observations, decompositions and records of motions were usually accomplished through artificial means during the processes of motion analyses. This method had a heavy workload, and the efficiency was very low. A novel method was put forward herein to segment and recognize continuous human motions automatically based on machine vision for mechanical assembly operations. First, the content-based dynamic key frame extraction technology was utilized to extract key frames from video stream, and then automatic segmentations of actions were implemented. Further, the SIFT feature points of the region of interested were extracted, on the basis of which the characteristic vectors of the key frame were derived. Finally, a classifier was constructed based on SVM to classify feature vectors, and the motion types were identified according to the classification results. Experimental results demonstrate that the proposed method achieves correct recognition rates of 96% on sample videos which were captured on the assembly lines.
segmentation and recognition of motion; key frame extraction; scale invariant feature transform(SIFT) feature points; support vector machine(SVM)
2016-04-21
国家自然科学基金资助项目(51375134)
TP391.4
10.3969/j.issn.1004-132X.2017.11.015
刘明周,男,1968年生。合肥工业大学机械工程学院教授、博士研究生导师。主要研究方向为制造过程监测与控制、机器视觉等。蒋倩男,女,1992年生。合肥工业大学机械工程学院博士研究生。E-mail: 1191758741@qq.com。葛茂根,男,1992年生。合肥工业大学机械工程学院博士研究生。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
现代计算机(2022年4期)2022-04-24
保定学院学报(2022年2期)2022-04-07
计算机系统应用(2021年2期)2021-02-23
微型电脑应用(2020年12期)2020-12-25
电子技术与软件工程(2019年18期)2019-11-18
扬州大学学报(自然科学版)(2019年2期)2019-08-12
数学大世界(2019年7期)2019-05-28
软件导刊(2018年4期)2018-05-15
电子技术与软件工程(2017年14期)2017-09-08
