
融合句义特征的多文档自动摘要算法研究
2016-11-25 06:08罗森林白建敏潘丽敏韩磊孟强
北京理工大学学报 2016年10期
罗森林, 白建敏, 潘丽敏, 韩磊, 孟强
(北京理工大学 信息与电子学院,北京 100081)
融合句义特征的多文档自动摘要算法研究
罗森林, 白建敏, 潘丽敏, 韩磊, 孟强
(北京理工大学 信息与电子学院,北京 100081)
多文档自动摘要研究是自然语言处理领域的关键问题之一,为使抽取的摘要更能体现多文档主题,本文在子主题划分的基础上,提出了一种融合句义特征的句子优化选择方法. 该方法基于句义结构模型,提取句义结构中的话题、谓词等特征,并融合统计特征构造特征向量计算句子权重,最后采用综合加权选取法和最大边缘相关相结合的方法抽取摘要. 选取不同主题的文本集进行实验和评价,在摘要压缩比为15%情况下,系统摘要平均准确率达到66.7%,平均召回率达到65.5%. 实验结果表明句义特征的引入可以有效提升多文档摘要的效果.
多文档自动摘要;句义结构模型;句义特征;自然语言处理
多文档自动摘要是自然语言处理领域的一个重要问题. 它的目的是从主题相同或相似的文档集合中抽取重要信息生成信息丰富、语言简洁并且符合压缩比要求的摘要,从而提供一种快速浏览和获取信息的手段[1]. 多文档自动摘要技术经过多年的发展出现了很多方法和技术,比较有代表性的有:美国密歇根大学的Radev等[2]提出的MEAD多文档自动摘要系统,抽取句子生成文摘;Erkan等[3]提出了一种LexPageRank算法,并将其成功应用到了Google PageRank中. 近年来,有些学者通过概率浅层语义分析(probabilistic latent semantic analysis,PLSA)及浅层狄利克雷分布(latent Dirichlet allocation,LDA)[4]来生成多文档摘要,都取得了较好的效果.
中文多文档自动摘要相比于英文而言起步较晚,比较有代表性的有:哈工大王晓龙等[5]提出了一种面向多文档自动摘要任务的多文本框架(multiple document framework,MDF),该框架在生成摘要中获得较好的结果. 山东大学马军等[6]提出了一种基于LDA的多文档自动文摘方法,该方法在ROUGE的各个评测标准上均优于SumBasic方法.
多文档自动摘要过程可以分解为3个任务:主题识别、主题说明、摘要提取. 句子重要程度的衡量在摘要提取中起着十分关键的作用. 目前,句子重要程度的表述大多采用统计特征,导致所选摘要句与主题容易产生偏差. 针对特征向量的局限性本文提出了一种融合句义特征的文摘句抽取策略,通过构建句义结构模型,提取有效句义特征,进而根据综合加权选取法和最大边缘相关(maximal marginal relevance,MMR)[7]方法抽取摘要. 本文在多个文本集上进行实验验证了句义特征的有效性,并与两个参照系统进行对比验证了系统的优良性能.
1 句义结构模型及句义特征
目前自然语言处理中对句子主要是从词法和语法两个层次上进行分析,但是无论是词法理解还是语法理解都属于形式上的理解,没有深入到语义,不能反映句子所表达的真正含义.
句义结构模型是句义中的成分以及成分之间组合关系的形式化表达,不同于以往对句义的理解方法,目的是帮助计算机从深层的语义角度去理解汉语句子. 通过该模型将抽象的句义形式化表达为成分之间的数理结构. 句义结构模型包含的要素包括:句义的类型、句义中的话题和述题、构成句义的成分、成分之间的组合关系等[8].
句义特征是能够表述句子语义的特征,句义结构模型中的句义特征包括句义成分以及成分之间的关系. 其中,话题和述题是句义说明的对象以及对该对象的说明,是对句义结构的第一层划分;基本格与谓词结合,体现了谓词在搭配上的要求,并以谓词为中心组成了句义的框架;一般格和谓词或者其他的项结合,但不与谓词构成句义的框架,而只是说明、描述这框架. 本文利用上述句义特征构建文本句子的特征向量.
2 算法原理
本文提出的融合句义特征的多文档自动摘要算法是在子主题划分的基础上提取相关的统计特征,同时进行句义分析,提取相应的句义特征,最后根据综合加权选取法和MMR方法相结合的策略选取文摘句[9]. 算法原理框架如图 1所示.
系统主要包括:预处理、子主题划分、特征提取、文摘生成4个模块. 各个模块的具体算法和过程如下.
2.1 预处理
生成摘要的第一步是对多文档集合进行预处理,预处理模块的输入是多文档集合,首先进行段落切分,以段落为子主题划分模块的聚类单元,之后对文本进行分词和词性标注,并去除停用词.
2.2 子主题划分
多文档集合中子主题是对中心主题不同侧面的描述. 子主题的引入可以提高多文档摘要的信息覆盖率,去除与中心主题不相关的信息. 子主题划分就是把内容相似的文本单元聚合在一起. 本文采用层次聚类和K-means聚类相结合的方法. 首先通过层次聚类进行大体的子主题划分,确定文本的聚类数目K和聚类集合C1,C2,…,Ck. 聚类后得到子主题,通过特征线性加权和组合词生成与过滤的方法提取关键词得到子主题的主题词[10].
本文采用凝聚方式的层次聚类方法,为了避免最终聚为一类,加入一个阈值s作为停止条件,当类间距离大于阈值时就停止合并,阈值的选择为
(1)
式中:a为常数,经实验分析,a为0.8时聚类数目较为合理;N为文档中所包含的所有段落数;段落Pi=(Wi1,Wi2,…,Win),Pj=(Wj1,Wj2,…,Wjn),W为段落中的有效词;sim(Pi,Pj)为文档中两个段落之间的相似度,用向量间的余弦值表示相似度.
2.3 特征提取
句子是人理解语言含义的基本单元,也是摘要抽取的基本单元. 特征提取模块分别对句子的统计特征和句义特征进行提取,最后依据特征向量计算句子权重.
2.3.1 统计特征提取
本文提取句子的统计特征如表1所示.

表1 句子统计特征
2.3.2 句义特征提取
针对统计特征的局限性,本文引入句义特征增强特征向量的表述能力,句义特征的提取采用课题组的研究成果[11]. 经分析,从句义结构模型中得到的句义特征如表2所示.

表2 句子句义特征
实验选取同一主题多文档集合(全国众志成城抗冻灾)作为语料,实验设置摘要压缩比为15%. 为了衡量句义特征的有效性,假设每个特征同等重要,然后依次去除句义特征得到相应的评价结果. 特征筛选实验采用准确率、召回率、F值对摘要进行评价,计算方法如下:
式中:K为系统生成的摘要句包含在标准摘要中的数目;N为系统生成的摘要所包含的句子数目;M为标准摘要所包含的句子数目.
实验中,首先考虑所有特征,然后按照特征编号从高到低的顺序依次去除句义特征,实验结果如图2所示.
由图2可知,在不断去除句义特征后,摘要的效果越来越差,在去除F_COMMARG特征和F_COMMENT特征后,系统性能基本不变;在去除F_PREDICATE特征后,摘要准确率下降了5.3%,召回率下降5.6%;去除F_TOPIC特征后,摘要准确率下降了近9%,召回率下降8.8%. 由此可得,去除F_COMMARG特征及F_COMMENT特征在现有的数据源下并没有影响,因此可以去除这两个特征,最终保留F_TOPIC特征(用FTC表示)及F_PREDICATE特征(用FPE表示).
2.3.3 句子权值计算
由于不同特征的重要程度是不一样的,所以特征提取后要根据每个特征的重要程度获取特征向量的权向量,本文通过层次分析法获取权向量[12]. 首先建立层次分析模型,然后通过对语言学的分析与实验,构造成对比较矩阵A,本文中构造的成对比较矩阵如下所示
经过分析Α具有满意的一致性. 当矩阵为一致性矩阵时,矩阵的主特征向量就是特征的权向量. 以此求得权向量为:
U=
[0.061 0.202 0.106 0.271 0.180 0.180],
设为U=[u1u2u3u4u5u6],各个特征的相对重要性由权向量U的各分量所确定.
本文假定各个特征相互独立,将句子的统计特征和句义特征构成特征向量
F=[FAFWFTFKFTCFPE],
各个特征的加权系数构成权向量U,句子权值如式(2)所示
(2)
式中:Wi为第i个句子的权值;Fi为第i个句子的特征向量.
2.4 文摘生成
文摘生成模块首先根据句子的权值以及子主题内的句子数目等因素对子主题进行排序,确定摘要抽取的顺序[13],之后采取一定策略抽取文摘句,最后进行后处理生成可读性较高的摘要. 本文采用综合加权选取法和MMR方法相结合的方法进行句子抽取. 具体步骤如下:
① 文摘句抽取前对句子进行过滤,将祈使句、问句等不适合作为文摘句的句子去掉,将长度系数CL>0.8及<0.2的句子去掉. 句子长度系数定义如下所示
(3)
式中:L为句子的长度;Lm为最长句子的长度;
② 根据有效子主题的权值高低依次选取子主题内权值最高的句子;
③ 检查候选文摘句与已选文摘句话题和谓词是否一致,如果一致,候选文摘句换为该子主题中的下一个候选句子,如果不相同则转步骤④;
④ 检查是否满足文摘压缩比要求,如果没有达到压缩比要求转步骤②,如果满足压缩比要求转步骤⑤;
⑤ 停止选取句子,输出初始文摘进行后处理.
得到初始文摘后首先进行句子排序,然后进行指代消解和平滑润色,本文根据文献[14]所述方法进行了文摘句的后处理,进一步提高文摘的可读性.
3 实验及结果分析
3.1 实验数据源
实验数据来自北京理工大学信息系统及安全对抗实验中心多文档摘要语料库(Beijing forest studio-multi-document summarization,BFS-MDS). 该语料库主要来自2009年热点新闻事件的网络新闻报道,包括90个主题,每个主题包含20~50篇不等数量的新闻语料,每篇新闻语料包含20~80个句子,同时每个主题包含压缩比为5%,10%,15%的3篇标准摘要.
本文从语料库中随机选取6个话题进行实验.
3.2 评价方法
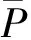
3.3 结果及分析
为了验证本文提出的多文档自动摘要系统的有效性,依据当前多文档自动摘要研究方法,建立了两个对照系统与本文方法进行对比实验.
第1个对照系统是基于事件抽取的网络新闻多文档自动摘要系统(multi-document summarization based on event extraction,MSBEE)[15],该系统引入事件抽取技术,通过主旨事件抽取及后续处理生成摘要. 本文系统与MSBEE系统对比结果如表3所示.
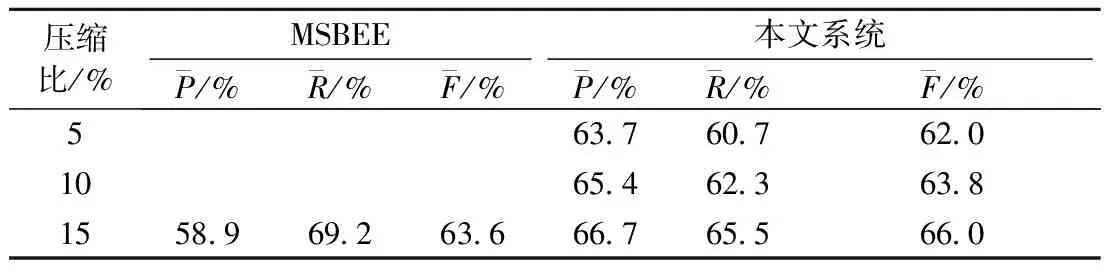
表3 本文系统与MSBEE系统对比结果
第2个对照系统是基于统计特征的多文档自动摘要系统(multi-document summarization based on statistical features,MSBSF)[16],该系统通过聚类进行子主题划分,然后对子主题内句子进行加权求和,根据句子的权值大小进行文摘句抽取. 本文系统与MSBSF系统对比结果如表4所示.
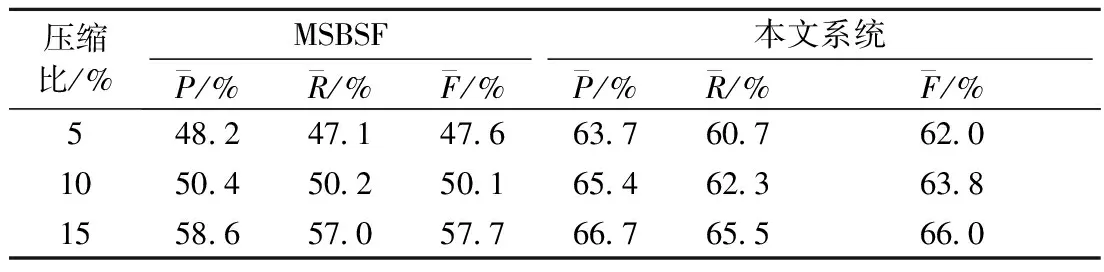
表4 本文系统与MSBSF系统对比结果
由本文系统和MSBSF系统在不同压缩比下的效果可知,在一定范围内压缩比越大系统的性能越好,原因在于人工抽取标准摘要的随机性比较大,而压缩比提高、数据量变大在一定程度上克服了这种随机性,使得最终得到的摘要更加合理而使评价效果有所提高.
4 结 论
目前,信息社会对多文档自动摘要技术有着迫切的需求,它能对文本形式自然语言进行深层次知识挖掘,通过阅读其生成的摘要可以在短时间内了解事件的发生、发展和结束的全过程,同时有效地解决了数据的冗余问题,具有重要的现实意义.
针对当前多文档自动摘要方法中句子特征选取的局限性,提出一种融合句义特征的多文档自动摘要方法,该方法在传统句子统计特征的基础上加入句义特征,增加了句子的分析深度,使特征向量更能表达句子的含义,使抽取的文摘句更能体现主题含义,实验结果表明本文提出的文摘方法比MSBEE系统和MSBSF系统的综合性能更加优良,在平衡准确率和召回率方面更加优秀. 综上,句义结构模型在多文档自动摘要中的应用是有效的,为多文档文摘提出了一种新的思路和方向. 下一步研究的重点是构建基于句义结构模型的篇章语义表达,通过篇章结构得到文摘的语义结构,从而改善文摘的逻辑性和可读性,从而生成更高质量的文本摘要.
[1] Wang D, Li T. Weighted consensus multi-document summarization[J]. Information Processing & Management, 2012,48(3):513-523.
[3] Erkan G, Radev D R. Lexpagerank: prestige in multi-document text summarization[C]∥Proceedings of EMNLP.[S.l.]: EMNLP, 2004:365-371.
[4] Arora R, Ravindran B. Latent dirichlet allocation based multi-document summarization[C]∥Proceedings of the Second Workshop on Analytics for Noisy Unstructured Text Data. [S.l.]: ACM, 2008:91-97.
[5] 徐永东,徐志明,王晓龙.基于信息融合的多文档自动文摘技术[J].计算机学报,2007,30(11):2048-2054.
Xu Yongdong, Xu Zhiming, Wang Xiaolong. Multi-document automatic summarization technique based on information fusion[J]. Chinese Journal of Computers, 2007,30(11):2048-2054. (in Chinese)
[6] 杨潇,马军,杨同峰,等.主题模型LDA的多文档自动文摘[J].智能系统学报,2010,5(2):169-176.
Yang Xiao, Ma Jun, Yang Tongfeng, et al. Automatic multi-document summarization based on the latent Dirichlet topic allocation model[J]. Caai Transactions on Intelligent Systems, 2010,5(2):169-176. (in Chinese)
[7] Carbonell J, Goldstein J. The use of MMR, diversity-based reranking for reordering documents and producing summaries[C]∥Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. [S.l.]: ACM, 1998:335-336.
[8] 冯扬.汉语句义模型构建及若干关键技术研究[D].北京:北京理工大学,2010.
Feng Yang. Research on Chinese sentential semantic mode and some key problems[D]. Beijing: Beijing Institute of Technology, 2010. (in Chinese)
[9] 罗森林,刘盈盈,冯扬,等.BFS-CTC汉语句义结构标注语料库构建方法[J].北京理工大学学报,2012,32(3):311-315.
Luo Senlin, Liu Yingying, Feng Yang, et al. Method of building BFS-CTC a Chinese tagged corpus of sentential semantic structure[J]. Journal of Beijing Institute of Technology, 2012,32(3):311-315. (in Chinese)
[10] 苏凯.中文文本关键词提取与自动摘要技术研究[D].北京:北京理工大学,2008.
Su Kai. Chinese text keyword extraction and automatic summarization technology[D]. Beijing: Beijing Institute of Technology, 2008. (in Chinese)
[11] 罗森林,韩磊,潘丽敏,等.汉语句义结构模型及其验证[J].北京理工大学学报,2013,33(2):166-171.
Luo Senlin, Han Lei, Pan Limin, et al. Chinese sentential semantic mode and verification[J]. Beijing Institute of Technology, 2013,33(2):166-171. (in Chinese)
[12] Saaty T L. Decision making with the analytic hierarchy process[J]. International Journal of Services Sciences, 2008,1(1):83-98.
[13] He R, Qin B, Liu T. A novel approach to update summarization using evolutionary manifold-ranking and spectral clustering[J]. Expert Systems with Applications, 2012,39(3):2375-2384.
[14] Heu J U, Jeong J W, Qasim I, et al. Multi-document summarization exploiting semantic analysis based on tag cluster[M]. Advances in Multimedia Modeling. Heidelberg Berlin:Springer, 2013:479-489.
[15] 韩永峰,许旭阳,李弼程,等.基于事件抽取的网络新闻多文档自动摘要[J].中文信息学报,2012(1):58-66.
Han Yongfeng, Xu Xuyang, LI Bicheng, et al. Web news multi-document summarization based on event extraction[J]. Journal of Chinese Information Processing, 2012 (1):58-66. (in Chinese)
[16] 熊颖.中文多文档摘要关键技术研究[D].北京:北京邮电大学,2011.
Xiong Ying. Research on key technologies of Chinese multi-document summarization[D]. Beijing: Beijing University of Posts and Telecommunications, 2011. (in Chinese)
(责任编辑:李兵)
Research on Multi-Document Summarization Merging the Sentential Semantic Features
LUO Shen-lin, BAI Jian-min, PAN Li-min, HAN Lei, MENG Qiang
(School of Information and Electronics, Beijing Institute of Technology, Beijing 100081, China)
Multi-document summarization (MDS) is one of the key issues in the field of natural language processing. In order to extract compendious sentences to reflect more accurate theme of the multi-document, a new method was proposed to retrieve terse sentences. At first, some sentential semantic features (SSF), for example topic and predicate, were extracted based on a sentential semantic model (SSM). Then the sentence weight was calculated by building feature vector merging statistical features and SSF. Finally, sentences were extracted according to the feature weighting and maximal marginal relevance (MMR). A set of experiment show that the new method is effective, the average precision rate of summary can reach 66.7%, and the average recall rate can reach 65.5% when the compression ratio of summary is 15%. The results of experiments show that the SSF are effective on upgrading the affection of MDS.
multi-document summarization; sentential semantic model; sentential semantic feature; natural language processing
2013-04-11
国家“二四二”资助项目(2005C48);北京理工大学科技创新计划重大项目培育专项资助项目(2011CX01015)
罗森林(1968—),男,教授,博士生导师,E-mail:luosenlin@bit.edu.cn.
TP 391; TP 18
A
1001-0645(2016)10-1059-06
10.15918/j.tbit1001-0645.2016.10.014
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
客联(2022年3期)2022-05-31
保定学院学报(2022年2期)2022-04-07
中国新闻周刊(2021年26期)2021-07-27
数学学习与研究(2018年15期)2018-11-12
电脑爱好者(2017年7期)2017-05-06
中学数学研究(2008年11期)2008-01-05
祝您健康(1988年5期)1988-12-30
祝您健康(1988年4期)1988-12-30
