
无回答频次的影响因素研究及追踪措施探讨
2016-11-14 07:40齐嘉楠
西北人口 2016年6期
齐嘉楠
(中国人口与发展研究中心,北京100081)
无回答频次的影响因素研究及追踪措施探讨
齐嘉楠
(中国人口与发展研究中心,北京100081)
本文以2014年中国家庭追踪调查首轮并行数据为基础,采用多水平泊松回归模型,对无回答频次的影响因素进行了研究。研究结果表明,调查员的年龄、调查点发达程度以及居住环境对无回答次数有着重要影响,宏观和中观地区因素对无回答次数存在显著影响。泊松多水平回归在无回答研究的应用效果较好。最后,从技术和机制两个层面,探讨了有关追踪的建议和对策。
无回答频次;多水平泊松回归;追踪措施
一、引言
随着我国社会、经济快速发展,各界对调查的需求日益增多。在各类调查实施中,绝大多数会遭遇到无回答的困扰。无回答而产生的后果主要在两个方面,一是减少样本量,导致调查精度降低;另一方面在某种情况下后果更为严重,即带来偏倚,使得在相关指标的预测时发生偏差。这促使调查设计的研究者们对无回答的特征、影响因素、对调查结果的影响、如何控制无回答等多个研究领域进行深入的探索,以解决或缓解因无回答导致的误差发生。
通过对无回答对象的特征描述,可以加深调查设计者对无回答现象的了解,并有针对性地采取相应措施,可以有效的降低无回答的发生。贺飞燕[1]利用国家统计局和加拿大统计局社会统计项目的数据,发现无回答者存在城乡差异,一宅多户的住户无回答率较高。孙妍等[2]通过对拒访对象进行追访,发现中外调查拒访的特点和模式基本一致,受住户家庭的主事者社会经济特征、参访经历等因素影响,认为拒访行为是可预测的。
无回答受多方面因素影响,了解并对这些影响因素加以有效利用,可降低无回答的发生几率。Jelke[3]认为,无回答受调查的主题、目标人群、调查时间、问卷长度、调查员的水平以及现场组织情况等多因素影响,且不同经济发展水平的地区间存在较大差异,农村地区比城市地区回答率高,大城市比小城镇回答率低,较低的社会经济状况地区回答率较低。王华等[4]通过对台湾民意电话调查数据分析后发现,调查员的性别、年龄、语言及语音特征对单元无回答存在显著影响,但部分影响模式还需进一步确认。胡顺奇[5]则认为,不应把无回答的主要原因归咎于被调查者,在调查过程中存在的隐瞒调查真相,误导被调查者,泄露被调查者个人隐私以及诱导或胁迫被调查者等伦理问题,导致了无回答的产生,因此应重视调查过程中伦理的因素对无回答的影响,确保研究主题的确定、问题设计、调查方法到数据保存、统计分析、结论报告等各环节遵循潜在的伦理要求。
在应用调查数据时,如何应对无回答带来的偏差一直以来都是众多研究者关注的重点。对无回答误差的调整方案会直接影响调查的结果。目前对无回答的调整主要包括两种方式,即权数调整法和样本替代法。张喆等[6]依据不同的数据缺失机制,提出了两种不同的计算回答率的方式,并推断出不同取值对估计效果的影响。Jelke[3]通过对无回答对象回访调查或填写主要指标问题的形式对无回答造成的偏倚予以纠正,也属于权数调整法的一种形式。风笑天[7]认为,在实地调查的过程中,应尽量采取措施,在转化和减少无回答数量上下工夫,最大限度地对由无接触和拒绝回答等原因造成的无回答现象进行转化,以此来保证足够的回答率,而不应采用样本替换的方法来补充样本。王玉梅等[8]对无回答误差分析了预防措施,通过样本替代法和加权调整法对无回答误差进行调整,同时提出,样本替换易对结果造成严重偏倚,需要事先确定替换原则才能有效控制样本替换对数据误差的影响。贺建风等[9]认为,可以通过事前预防和事后补救的措施来对无回答误差进行调整,通常的做法是在抽样设计阶段采用二重抽样的方式获得无回答单元的信息,或对回答单位数据使用加权因子,将无回答单位的设计权数在回答单位中重新分配加以解决。
无回答误差无法避免,但可以通过在调查实施的不同阶段采取应对措施对其加以控制。鲁志贤[10]、王有刚[11]等学者均认为纠正无回答偏倚的根本途径在于降低无回答率,可以对无回答进行有效地预防,相关措施包括加强调查的组织管理,设计优良的问卷,加强访员的培训和管理及访问技巧,加强公共关系以及与被访者的沟通等。贺飞燕[1]则建议通过简化任务控制表、严格的数据控制流程以及提高访问员素质等途径来解决。牛成英等[12]构建由无回答误差引起的非抽样误差函数后发现,使用增大样本量的方法在有些场合下有效,有些场合下不太有效。当回答率、回答群中单元间变异程度以及实际调查的总体变异程度固定时,增大样本量可以减小估计量方差,但能否减小估计量偏差,则主要取决于回答群和无回答群之间的差异。
研究无回答发生的次数,有助于研究者在辨识影响无回答的风险因素之外,进一步了解这些风险因素可能产生的误差偏倚程度,也正是本文研究的核心问题。此外,目前国内已有的研究对宏观(如区域、省份)、中观(如县、市、区)等背景因素如何影响无回答的情况投入的关注不足,而不同区域、省份的社会、经济状况存在的客观差异,必定会对在区域内的无回答状况产生差异化的区别,即使在同一区域、省份内,不同的县(市、区)也会存在着较为显著的差异,这类差异可从行政建制、经济发展水平等多方面体现出来,并最终反映到调查的无回答差异上来,这使得本文在此方面的研究有了一定的理论意义。得益于调查技术的快速发展,以往很多调查研究者无法或不易获得的并行数据,逐步应用到调查的分析中来,本研究对调查员相关信息(性别、年龄、受教育程度)与无回答次数间的关系进行了分析,为未来选配合适的调查员提供参考依据。
本文对下一轮的追踪措施进行了初步的探讨,提出政策建议,期望通过采取多种方式,预防并降低无回答的发生,提高追踪的成功率。
二、数据来源与方法
(一)数据来源
本研究所采用的数据来自于国家卫计委在2014年开展的一项追踪调查项目——中国计划生育家庭发展追踪调查,2014年10月开始执行第一轮调查,每两年进行一次追踪调查。
该调查样本涵盖中国大陆所有省份,涉及31个省(区、市)、233个地(市)、321个县(市、区)、1560个乡(镇、街道)的1625个样本村(居)。设计样本为32500个家庭,其中,安徽、山东、河南、广东四省样本分别为2000个家庭,河北、辽宁、江苏、四川四省样本分别为1500个家庭,北京、上海、江西、海南、贵州五省(市)样本分别为1200个家庭,黑龙江、浙江、湖北、湖南、广西、云南六省(区)样本分别为1000个家庭,其他省份样本数均在1000个以下。
调查目标总体为常住人口家庭:包括户籍人口家庭和流入人口家庭两部分。调查对象涵盖抽中样本家庭中的户主、配偶及他们现住本户的亲属,包括儿童、青少年、成年人和老年人。
调查采用结构式问卷的方式进行,调查问卷共分三类,即住户问卷、个人问卷(0-5岁儿童、6-17岁青少年、18-59岁成年人、60岁及以上老年人)、社区问卷(居委会和村委会),共七种问卷。其中,村/居问卷主要了解村/居的人口状况、背景条件及包括卫生计生服务管理在内的社区发展情况。
抽样采取分层多阶段与规模成比例(PPS)方法。全国31个省(区、市),每个省级单位为独立子总体。省内为三阶段PPS抽样,初级抽样单元为县(市、区),二级抽样单位为居/村委会,每个样本县(区、市)包括5个样本居/村委会(下文中,样本点均指居委会或村委会),最终抽样单位为家庭户,每个样本居/村民委员会抽取20个家庭户。
住户和个人调查采用面对面的调查方式,由调查员手持笔记本电脑或PAD利用计算机辅助调查系统(CAPI)进行,每个样本点配备一名接受过国家一级培训的调查员。
本研究利用该调查获得的并行和调查数据,对样本点级无回答发生次数情况进行分析。无回答包括以下四种情况:家庭成员全部外出、家庭成员全部拒访、家庭在样本点内有多处住宅而被重复抽中以及其他无法进行调查的情况。有一个观测由于未调查社区问卷,因此在涉及社区的微观层面数据存在缺失,对其进行插补处理。数据的基本情况如下:分析样本量为1625个观测。在调查员中,男性占33.4%,女性占66.6%;平均年龄33.7岁,其中,30岁以下组占31.5%,30-39岁组占48.4%,40岁及以上组占20.1%;受教育程度为高中的占15.1%,大专占44.6%,本科及以上占40.3%。无回答平均次数为2.38次。
(二)估计方法
对于计数类型的数据,较符合泊松分布的特征,因此本文采用泊松回归对数据进行分析。泊松回归在社会生活中已经有了较多的应用,谢元博等[13]、郭志刚等[14]、杜兴强等[15]分别在健康风险、生育率和公司治理等领域进行了有益的探索。泊松分布的密度函数为:
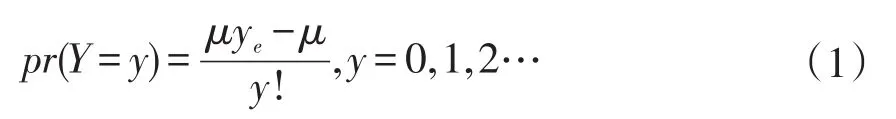
为获得一个可估计的回归形式,将计数值与解释变量联系起来,通常的表达形式是:

其中,tij为补偿系数,x′ij为解释变量,β为估计系数。
由于不同省份、区县间存在客观差异,本文拟采用多水平泊松分析,Rasbash等(2012)[16]在一个三层结构的多水平泊松回归中,表达形式为:
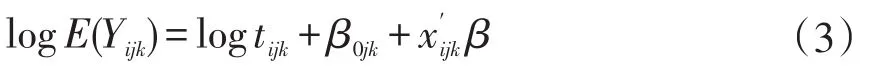
其中,β0jk=β0+v0k+vojk,v0k为省级随机效应系数,vojk为县级随机效应系数。
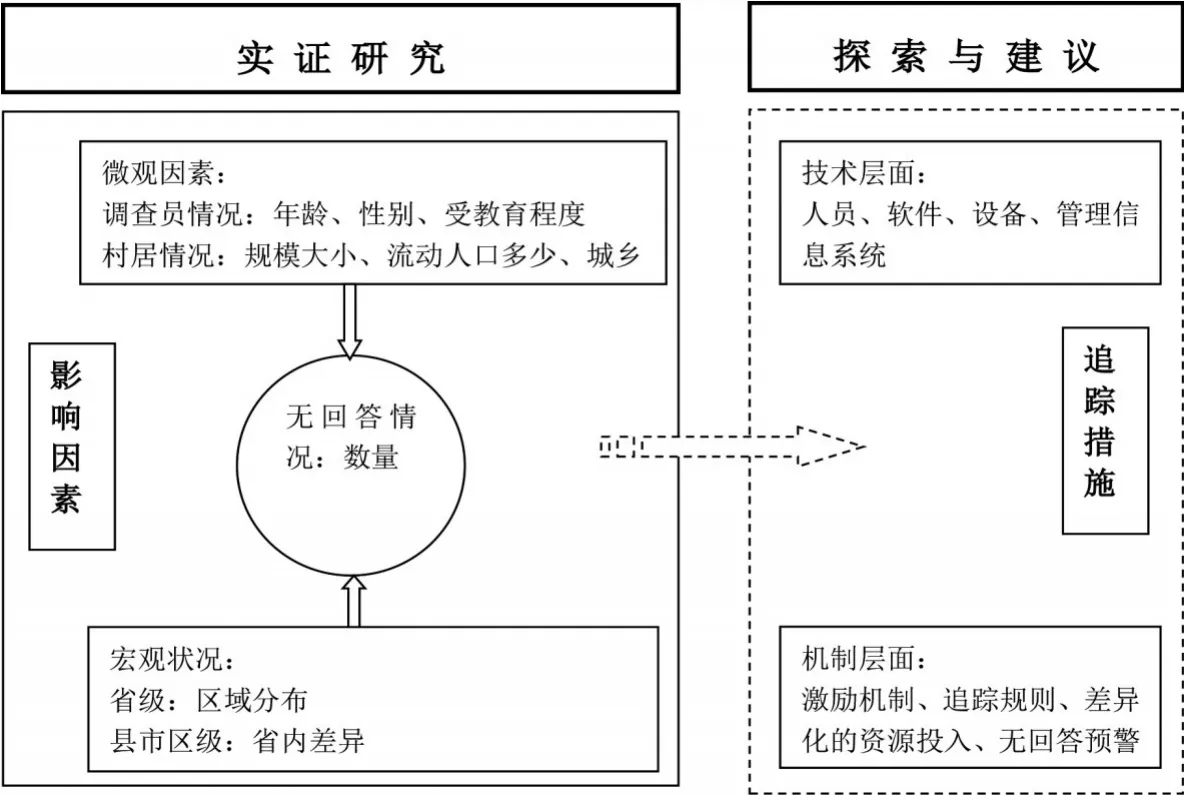
图1 无回答研究框架图
(三)研究框架
本研究认为,无回答数量主要受微观以及宏观状况等两个方面的因素的影响,拟通过实证研究对其加以验证。在微观层面,调查员方面,年龄大往往代表着阅历较多,可能更了解调查对象的基本情况,熟悉周边状况;女性调查员与男性相比,可能会更具有亲和力,给调查对象以安全感,而男性给人的感觉侵略性较强,使被拒绝的风险增大;受教育程度反映了调查员的素质,对调查的理解能力更强。不同特质的调查员,面对潜在的调查对象时反应会有所不同,面对的是否接受调查的结果也不相同。在社区层面,村居规模的大小,流动人口的多少都会影响居住在社区里的居民接受调查的意愿,社区规模较大,流动人口居住较多的社区,居民之间熟悉的程度相对较低,防范的心理更浓重,拒绝接受调查的可能便更大。
宏观状况方面,在省级层面,不但东部、中部和西部地区之间存在着经济、文化差异,即使是区域内部,不同省份之间也存在着显著差异;省内受地形地貌、经济发展、产业布局等影响,县、市、区之间同样存在着差距。这些经济、文化层面的差异客观存在,会在一定程度上影响受访者接受调查的意愿,进而影响无回答的数量。
此外,由于本研究中采用的数据从复杂抽样设计获得,因此,在进行分析时也需要将权重的影响加以考虑,将各省家庭户数也纳入模型。
本研究采用的是基于一项家庭追踪调查首轮的无回答数据,对影响因素进行分析。对无回答的研究不应局限于首轮的影响,还应对其对未来追踪的影响加以深入探讨,并拟定相关建议。因此,如何确保未来追踪成功,也是本研究期待解决的问题之一。此处假设首轮无回答数量与之后的追踪无回答间存在着一定的相关关系,本研究试图通过对首轮无回答的研究,对追踪技术和机制提出相关建议,以改进追踪的效果。在技术层面,探讨人员、软件、设备、管理信息系统等因素在追踪中起到的作用。在机制层面,分析激励机制、追踪规则、差异化的资源投入以及无回答预警等多种因素对追踪带来可能的影响。
三、实证分析
(一)描述性统计
调查员的受教育程度对无回答次数的影响没有明显的差异,性别和年龄因素发挥了某种作用。研究发现,男性调查员的平均无回答次数为2.24次,比女性调查员平均低了约0.2次。将年龄进行了三段分组,分为30岁以下组、30~39岁组和40岁及以上组,发现30~39岁这一中间年龄段组的平均无回答次数最低,为2.26次,40岁及以上组和30岁以下组的平均无回答次数分别为2.33和2.59次。
从宏观和中观层面来看,无回答次数存在着较为显著的差异。不同的地区无回答差异明显,东部地区的平均无回答次数最高,为2.72次,中部地区的相应次数最低,为1.95次,西部地区与全国平均水平接近,为2.28次。在中观层面上,调查地域所属的区县类型,其平均无回答次数也存在着差异,区的平均无回答次数最高,为2.64次;县级市的相应次数其次,为2.25次;县的相应次数最低,为2.14次。
在微观层面上,城乡属性、社区规模和流动人口占比等因素内部各组间的平均无回答次数存在着显著的差异。居委会的平均无回答次数高于村委会,两者分别为2.88次和1.99次。社区规模越大,平均无回答次数越高,5000人以上户籍人口的社区平均无回答次数为2.71,2500~5000人规模的社区相应次数为2.40,2500人以下规模的社区平均无回答次数最少,为2.12次。社区内流动人口比例越高,平均无回答次数也越高。社区内流动人口占比在20%以上的,平均无回答次数为2.95,流动人口占比在3%~20%之间的,相应次数为2.35次,流动人口占比在3%及以下的平均无回答次数最少,为2.18次。
(二)影响因素分析
描述性统计只能大致看出自变量与因变量间是否存在相关关系,如要深入了解各自变量发生作用的程度,则需要进行回归分析加以确定。本文中因变量选择为无回答次数,补偿系数则选择为为完成每个样本点20户的样本量而总共入户访问的家庭数,因此,泊松回归拟合的结果经指数化后,可视为每个样本点的无回答率。
在本文的多水平泊松回归建模过程中,首先选择调查员的年龄作为基础自变量,纳入到多水平的分析中。模型一显示,在多水平的构架中,区县级和省级两个水平的方差均显著,说明在无回答发生次数的研究中,宏观和中观的背景影响确实存在。只看年龄的影响,可知30岁以下的调查员无回答率为截距项的系数的指数(exp(-2.541)= 0.079),同理可知30~39岁和40岁及以上的调查员无回答率分别为0.074和0.067。与30岁以下的调查员相比,40岁及以上的调查员的无回答率比之低14.5%,30~39岁组比之低5.6%(不显著)。此时,模型一中各年龄组的系数中还包含着其他各种影响因素的共同作用,需要继续增加其他自变量以使模型对数据进行更好的拟合。
在模型一的基础之上,本文先后增加了调查员层面的相关变量(调查员性别、调查员受教育程度)以及微观层面相关变量(城乡属性、社区规模、流动人口占比)等变量,最终对模型解释能力提高有显著效果的只保留了城乡属性、流动人口占比两个自变量。模型二中,在控制了其他影响因素后,居委会的无回答率相对于村委会高出41.6%。与流动人口占比在3%及以下的社区相比,流动人口占比在3%至20%之间的社区无回答率低12.3%,而流动人口占比超过20%以上的社区与之相比则差异不显著。
模型三是在模型二的基础上,增加了对宏观、中观背景变量以及自变量中变系数的影响。首先增加了宏观背景变量(地区)和中观背景变量(县市区类型),结果显示均不显著。将模型中自变量(城乡属性)的系数由固定变为区县级和省级两个水平上随机系数,结果显示城乡变量的系数、方差以及与区县级的协方差均显著,而在省级水平上方差不显著。在最终构建的模型三中,调查员年龄为30~39岁之间、40岁及以上的无回答率与30岁以下组相比分别低8.9%和13.5%。居委会的样本点无回答率比村委会相应比例高45.2%。流动人口占比在3%至20%之间的社区无回答率比流动人口占比在3%及以下的社区低10.7%(p值为0.064),而流动人口占比在20%以上的社区的无回答率则与3%及以下的社区相比没有显著性的差异。此外,权重的影响因素在模型中也不显著。在模型三的随机部分,方差来源主要来自三部分,省级水平、区县级水平和城乡。其中,城乡变量的系数变动存在着差异,村委会的区县级水平的方差是省级水平方差的7.3倍,而居委会的波动性较小一些,区县级水平的方差与省级水平方差之比为5.6。利用模型三对无回答率进行推断,并还原到无回答次数,与各省实际平均无回答水平进行比较,显示拟合效果较好(详见图2)。对模型3的预测值与实际值进行Pearson相关分析,相关系数为0.855。计算模型3获得的均方误差为3.476,与模型1、模型2相比最小。
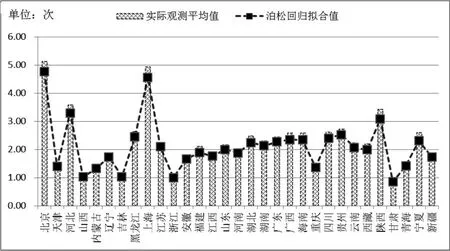
图2 分省平均无回答次数实际观测平均值与泊松回归拟合值分布
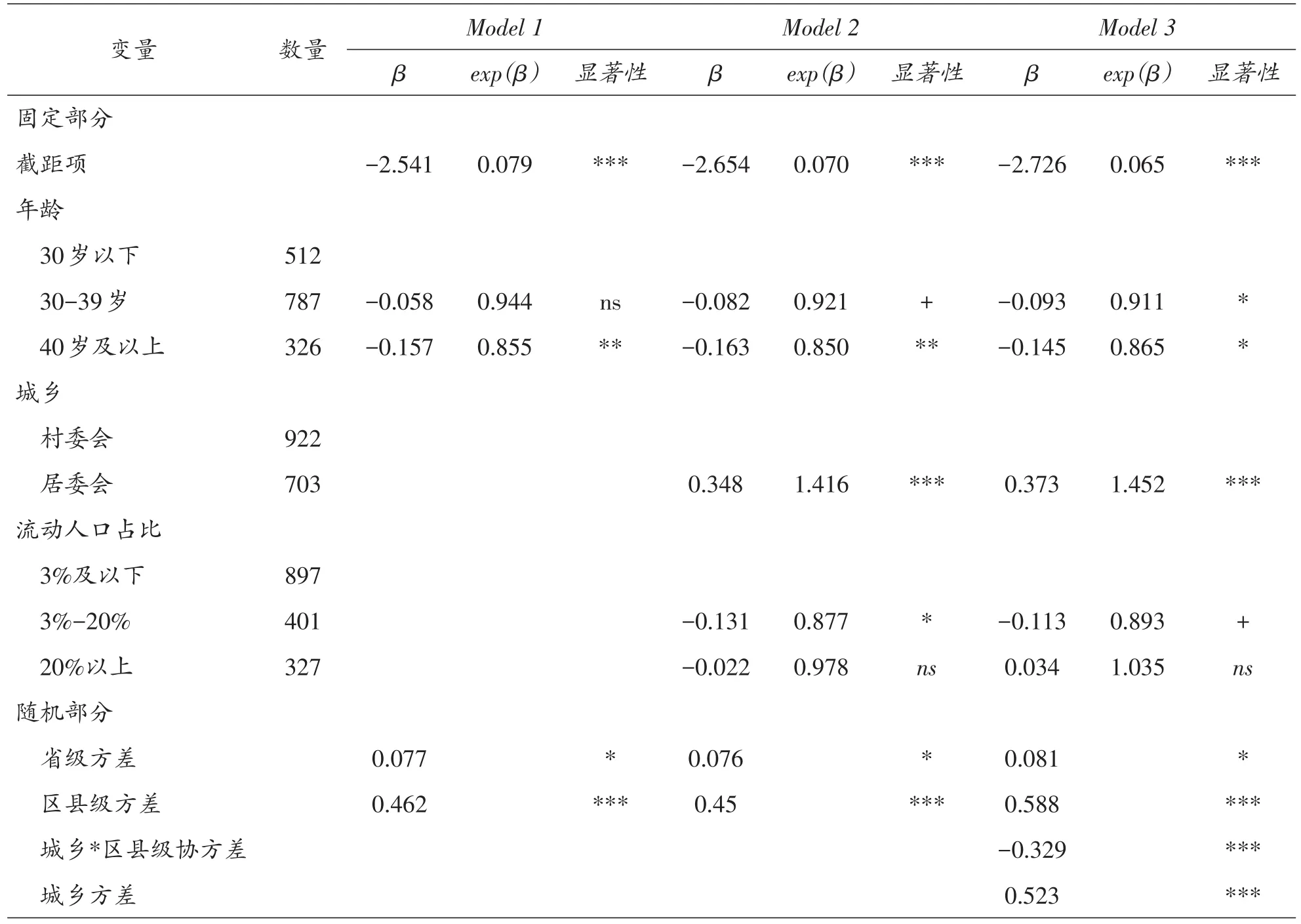
表1 多水平泊松回归系数、Odds Ratio及随机项方差估计表
四、结论和讨论
在执行调查的过程中,目前存在多种调查模式,无论是面对面式调查或是电话调查,调查员的作用均很重要。雇用或选配什么样的调查员,对控制无回答、调查员误差等非抽样误差至关重要。具体到本文研究的无回答误差,调查员的性别、受教育程度等均非重要的影响因素,只有年龄因素与无回答的次数存在着显著的相关关系。年龄通常代表了经验,与人交往的能力和丰富的人生阅历,给人以安全感而不是侵略性,这些因素在入户调查过程中,对受访者放松心情和警惕心理较为重要。但在目前很多调查采取计算机辅助调查的模式下,年龄较大有时并不是一件优势,因为年纪大的调查员往往不易接受新鲜事物,需要投入更多的精力和经费对其电脑操作进行充分的培训,这无疑增加了调查的成本。此外,调查员的性别、受教育程度虽对无回答的影响较小,但在招募调查员时,同样有重要的意义。因为,男性调查员的自身安全性有较高的保障,更易于承担夜晚、复杂地形地貌、混杂的居住环境等较为特殊场合的调查任务。通常受教育程度越高,对问卷的理解能力越强,调查的效率越高,有利于降低调查员误差。所以,在调查员的招募过程中,年龄、性别、受教育程度等需要通盘加以考虑。
调查的微观背景对无回答次数有着重要影响。本文选取的微观层次的变量有三个:城乡属性、社区规模和流动人口占比,分别代表了所处发达程度、规模和居住环境,只有所处发达程度以及居住环境对无回答次数有着重要影响,而规模因素对无回答的影响较小。居委会相比村委会,受访者对调查员并不熟悉,对陌生人警惕性较高,即使有居委会的同志进行配合,也往往不愿意接受调查。而在村里进行调查时,很多情况下属于熟人熟户,村委会的调查员甚至跟调查对象沾亲带故,这都使得受访者更易接受调查。此外,城市中的受访者往往都需要白天工作,不像农村地区只要不是农忙季节,在家中容易遇到或者联系到,这些因素均影响了城市的无回答次数要高于农村。居住环境对无回答次数有一定影响,但该影响没有城乡属性带来的影响大,此外,本文意外发现流动人口占比并非越高无回答率也越高,而是呈现出一种“U”型的分布,这与本文的初始假设存在一定的矛盾,由于模型结果的统计检验出现了弱显著性,因此,对该指标的影响还需在未来的研究中进一步加以确认。
宏观和中观地区因素对无回答次数存在影响。虽然有一些背景变量(地区、县市区类型)未纳入最终的多水平模型,但并不意味着宏观和中观的影响不存在,只是这种影响被纳入到了多水平泊松模型的随机部分中。本文研究者本以为无回答率的差异会主要发生省级水平,其次才是县市区级水平,但实际的拟合结果显示,差异的来源与原来的预期完全相反,无回答率差异的主要来源来自县市区级,且城乡间还存在着明显的差异。若从这一结果进行趋势推演,对无回答率的重要影响可能来自于更微观的层面,即受访者的个体差异对无回答的影响,这是未来应继续深入研究的方向。
泊松多水平回归在无回答研究的应用效果较好。无论从拟合的效果还是影响因素的比较,泊松多水平回归的应用都较成功。通过选取合适的补偿项,可直接输出各样本点的无回答率,方便分析拟合效果及相互比较。此外,泊松多水平回归模型还可以容纳较多的自变量,而不必担心常规模型在数据量较少的情况下,必须考虑的自由度问题。虽然泊松多水平回归模型有很多优点,但也存在数据处理较为复杂、需要使用特定的软件(本文多水平分析使用了MLwiN2.26[16])以及模型需要专业的解释等困难。
在研究过程中,发现无回答的次数和方差并不相等,方差大于均值,此时泊松分布的性质出现矛盾,该现象并不影响泊松分布的应用。这种现象在许多研究中多有发现,Breslow[17]、Morton[18]等对此有较为深入的研究。此外,本研究未对时间因素如何影响无回答次数进行分析,由于本文采用一项追踪调查的首轮调查数据,调查时间为2014年10月,因此无法对不同调查时间点的影响加以研究,未来可在收集更多调查数据资料的基础上对其进行进一步分析。
五、有关追踪的建议
本研究所采用数据来源于中国家庭追踪调查2014年首轮调查,对无回答次数的研究虽仅围绕首轮调查时展开,但对于一项追踪研究而言,不应局限于首轮,而更应着眼未来在追踪过程中,如何确保将调查对象追踪、调查到。因此,本文在以下部分将从技术和机制两个层面,探讨有关追踪的建议和对策。
技术在此处的含义较为广泛,包括人员、软件、硬件以及管理信息系统等具体的内容。在不改变调查模式的前提下,调查员的存在对降低调查的无回答率具有显著的意义。在雇佣过程中,关注调查员一些背景信息(如性别、年龄、受教育程度)的同时,往往容易忽略一些更为简单的事实,即调查员本身是否对调查充满热情,他(或她)对付出的努力得到的回报是否满意,以及是否具备以往的调查经验。热情代表了调查员对追踪的正面、积极的看法,这会使其在定位、联系以及获得受访者配合的过程中,做出正面的反馈,确保不轻易丢失任何一位受访对象。可结合实际工作,有目的地开发出一套量表工具,以在调查员招募时测量他(或她)是否对调查充满热情。公平、合理地确定调查员的薪酬,体现出调查员工作的难易程度和地区差异。在城市发达地区,调查成功的成本通常远高于农村地区。在制定调查员薪酬时,应对地区差异、访问成本加以通盘考虑,而不仅仅依靠成功调查的数量进行一刀切,可考虑按无回答率进行加权,无回答率高的地区,适当增加调查员的补贴。追踪调查中,不但受访者存在连续性,调查员的连续性也需得到应有的重视。国内目前的追踪调查,往往使用在校学生作为调查员,他们的优点在于素质高,受过统一的培训,对问题的理解能力较强,但硬币的另一面是学生的流动性较大,往往参加过一次调查之后,受各种原因影响,不会继续参加下一次的追踪,这便导致每轮追踪时,调查对象遇到的都是新的调查员,调查员与受访者之间不易建立某种稳定的联系。因此,在家庭追踪调查中,最好在调查地点当地进行招募,且优先招募曾参加过首轮调查的调查员,这样的调查员对当地情况更为熟悉,更易于与追踪对象家庭建立联系,有利于进行定位、追踪与联络。
追踪调查不同于一般的横断面调查,在执行过程中,需要对调查过程进行质量监控,在后续的追踪调查中,需要回置数据,以便对前面的调查结果进行检查与校正,这都决定了追踪调查不能简单的采用纸质问卷的调查模式,而需要借助计算机辅助调查技术。当前比较主流的追踪软件分为两类,一类是应用国外已有的商业化模块化软件系统,另一类是自主开发定制化的软件系统平台,两类软件各有优缺点。国外已有软件优点是技术成熟,模块化系统较为规范,后台技术团队经验丰富,不利之处在于与国内调查环境存在差异,遇到一些有本地特色的问题无法提供及时的解决方案,此外,汉化程度不够以及成本较高也是存在的劣势之一。自主开发定制化的软件平台优点在于灵活性较高,能够针对遇到的具体问题及时给出解决方案,不利之处主要集中在开发经验不足,开发的成功与否与调查执行人员的经验与配合有直接联系。考虑到追踪调查的复杂性与多样性,软件开发的灵活性更应得到重视,自主开发定制化的软件平台是家庭追踪调查的一项权衡后的选择。
在首轮调查时,调查终端采用了笔记本电脑和pad两种设备进行辅助调查。在实际调查时,有调查员反映需要携带的调查材料较多,笔记本电脑感觉过于沉重而不便于携带。但另一方面,笔记本电脑的分辨率较高,可视化界面较大,对于一些视力不好的调查员,或是较为复杂的表格可以一目了然的读出题目的内容。因此,在未来的追踪调查中,仍需保留笔记本电脑和pad两种终端模式,随着智能手机的普及,进一步开发智能手机的应用模式。
管理信息系统属于软件平台的一部分,在追踪调查中发挥着重要作用。一个好的管理信息系统不仅是包括调查员、受访者信息的数据库,还应包含抽样过程中附带的地理信息。定位对于追踪而言是首要问题,应将首轮调查时调查对象的社区、网格、住宅地址等信息以可视化的形式标注在电子地图上,供调查员在追踪时参考。相对于传统的绘制纸质调查地图的形式,包含了调查对象地理位置信息的管理系统更容易保存,不易丢失,方便追踪时调用。此外,如能与社会管理数据(如普查数据、公安管理数据或民政、社保数据)进行关联,无疑会对追踪的效果起到关键作用,但如何获取此类数据以及与微观数据库进行关联是难点。
良好的机制构建是顺利追踪的保障。本研究拟从受访者的激励、追踪规则、差异化的资源投入和无回答预警四个方面探讨机制对追踪的影响。对受访者的激励从类型来看,可分为纪念品型、实物奖励型和现金激励型,此外还有不提供任何激励的情况。从激励提供的时间来看,又分为事先激励、事后马上激励和事后延迟激励等类型。从激励的分配来看,分为均匀分配型激励、累加分配型激励和递减分配型激励。目前国内对激励机制与追踪成功率的研究较少,从家庭追踪调查的实践来看,不同地区存在不同的应用案例。总体来看,以现金激励为主,以实物奖励为辅。在未来追踪时,可考虑制定统一标识的纪念品,发放给受访者家庭,以提高受访者对家庭追踪调查的认同感与社会知名度,此外,还可考虑采用发放虚拟充值卡的方式提供激励。从激励的时间来看,以事后马上激励为主,即接受完调查之后支付相应的激励措施。未来也可考虑事前激励的方式,比如在两轮追踪调查之间,进行维护性跟踪时,可适当提供激励,以维持于受访者的联系,使其更愿意在未来进行正式的追踪调查时,接受调查员的入户访问。此外,可将数据的质量与提供激励进行联系,事先将激励的一部分留作事后奖励基金,如数据质量较差,空填项过多,可扣除该户的事后奖励基金,否则将事后奖励基金补偿给调查对象,以此进行事后延迟激励的尝试。随着通货膨胀以及追踪人员的扩充,可尝试在不同轮的追踪调查中,采用累加分配型的激励机制。
追踪规则对于一项追踪调查而言至关重要。只有明确了追踪的规则,确定了追踪的对象,才能制定具体的追踪方案,并培训调查员对需追踪的对象进行定位、联络、确认配合及登门调查。根据追踪的难易程度或样本的稳定性,追踪的规则分为以下几种类型:1.只对抽取样本所在地址进行追踪。离开样本所在地址的家庭成员放弃追踪,新进入样本所在地址的成员加入追踪。2.初始样本的追踪。只对首次进入样本的家庭成员进行追踪,只有死亡后才退出追踪,新增的家庭成员(比如嫁进的媳妇或新出生的婴儿)都不追踪。3.初始样本加上当前与初始样本有同居关系者及初始样本的后代,这样更能反映出不同轮次调查时家庭的结构和演变情况。4.初始样本加上当前与其有某种联系的对象,该类型在类型3的基础上不但包含了姻缘和血缘关系,还包含了经济、社会联系,更能反映出当前的横断面调查特征与现状。5.初始样本加上历次追踪纳入的新对象,该类型包含了不同时间点上的全部横断面调查对象,必须处理好可能存在较多缺失值的问题。选择何种追踪规则不仅关系到追踪调查的成本,更与追踪调查的研究目的息息相关,需要调查的设计者慎重加以考虑。
在一个静态的系统中,差异化的资源投入主要指在分配资源时应考虑无回答率的地区间差异,以及调查员水平的差异。但在一个动态系统中,则主要指流动的因素对无回答带来的影响。追踪调查就好比是一个动态系统,在不同轮次间调查的对象可能由于各种原则发生流动的现象,而流动的范围分为乡镇街道内流动、县内流动、市内流动、省内流动、跨省流动以及跨国流动等多个层次,追踪的成本随流动范围的扩大而增加,在确定追踪规则后,流动的追踪对象与留在原调查地点的追踪对象相比,投入的追踪资源必然存在巨大的差异。这在客观上要求调查的执行者采用差异化的资源投入针对不同类型的追踪对象。在家庭追踪调查首轮调查中,遇到外出流动的调查对象,则采取了电话调查的方式,对主要的问题进行了简要调查。在未来的追踪过程中,可考虑采用不同的调查模式(电话调查、邮寄问卷调查、网络调查等)对外出对象进行追踪,但由于调查模式和问卷内容的改变,会对研究的目的产生潜在的影响,因此需要慎重选择。此外,调查成本也是需要考虑的一个方面,如经费不允许,则可对流动范围过大的追踪对象进行缺失处理,比如对流动范围超出县界的追踪对象予以放弃,在下轮追踪时如已返回则继续调查。如经费有保障,则可放宽对流动范围的控制,对外出流动的追踪对象尽可能多的进行调查。
建议无回答预警机制有助于提前对可能的追踪失败案例做出预判,以采取措施进行补救或纠正。家庭追踪调查的周期为两年,在两年期间为维护样本,需要定期回访被访者家庭,如有变动,需及时更新被访者家庭的地址、人员和通讯等信息。或者通过事先邮寄邮件、发短息或打电话的方式,询问被访者家庭是否有信息需要更新,在通过多种方式询问时,可获取该家庭中更多人的联系方式,以及是否近期家庭成员有外出的打算,这些信息都有助于调查组织者掌握被访者的居留稳定情况。根据回访或反馈的结果,由专家对在下轮正式调查时可能失访的家庭及人员进行建模。Couper等[19]认为建模时需要考虑的信息包括大致可分为个人和社会两个层面。个人信息主要包括年龄、生活方式、家庭环境、就业情况以及房屋情况等;社会信息则应包含迁移流动率、城市化水平以及常住人口情况等。✿
[1]贺飞燕.住户调查中无回答误差分析与调整方法研究[J].统计研究,2015(2):109-110.
[2]孙妍,邹艳辉,丁华,严洁,顾佳峰,邱泽奇.跟踪调查中的拒访行为分析——以中国家庭动态跟踪调查为例[J].社会学研究,2011(2):167-181.
[3]Jelke Bethlehem.Applied Survey Methods-A Statistical Perspective[M].John Wiley&Sons,New Jersey,2009:209-245.
[4]王华,叶宏明.台湾地区民意调查中无回答的影响因素[J].台湾研究集刊,2012(3):53-63.
[5]胡顺奇.伦理视角下统计调查无回答问题探析[J].统计与信息论坛,2014(5):111-112.
[6]张喆,金勇进.无回答加权调整中的回答率模拟研究[J].统计与决策,2015(4):13-16.
[7]风笑天.社会调查中的无回答与样本替换[J].南京大学学报(哲学、人文科学、社会科学版),2010(5):102-111.
[8]王玉梅,王楠楠.抽样调查中无回答误差的分析与调整[J].广西财经学院学报,2011(5):38-41.
[9]贺建风,刘建平,舒晓惠.抽样调查中无回答误差控制的研究[J].统计与决策,2008(5):162-163.
[10]鲁志贤.抽样调查中无回答的影响及处理方法——兼对《调查技能教程》中无回答调整的方法与应用条件的扩展[J].统计研究,2002(12):43-47.
[11]王有刚.抽样调查中有效控制无回答误差的措施[J].统计与决策,2011(23):16-18.
[12]牛成英,庞智强.非抽样误差函数的构建——基于无回答误差的讨论[J].统计与决策,2014(20):23-25。
[13]谢元博,陈娟,李巍.雾霾重污染期间北京居民对高浓度PM2.5持续暴露的健康风险及其损害价值评估[J].环境科学,2014(1):1-8.
[14]郭志刚,巫锡炜.泊松回归在生育率研究中的应用[J].中国人口科学,2006(4):2-15.
[15]杜兴强,温日光.公司治理与会计信息质量:一项经验研究[J].财经研究,2007(1):122-133.
[16]Jon Rasbash,Fiona Steele,William J.Browne and Harvey Goldstein.A User’s Guide to MLwiN(Version 2.26)[M].University of Bristol,2012:183-192.
[17]Breslow.N.E.Extra-Poisson variation in log linear models[J].Applied Statistics,1984(33):38-44.
[18]Morton.R.A generalized linear model with nested strata of extra-Poisson variation[J].Biometrika,1987(74):247-257.
[19]Mick P.Couper,Mary Beth Ofstedal.Keeping in contact with mobile sample members[C].Methodology of longitudinal surveys,2009:185.
The Impact Effect of Non-Response Frequency and Discussion about the Tracking Strategy
QI Jia-nan
(China Population and Development Research Centre,Beijing 100081)
A multi-level Poisson regression is constructed and employed based on the parallel data,the first wave,of the 2014 China Family Panel Survey,to study the impact effect of non-response frequency.The results show that,under the background of macro and meso,the non-response frequency is impacted highly by the age of interviewer,as well as the developed degree and living environment of the interviewing place.Through application,the multi-level Poisson regression is good at the study of non-response.Finally,in the technology and mechanism views,there are discussions of the tracking strategy and suggestion.
Non-Response Frequency;Multi-level Poisson Regression;Tracking Strategy
C921.2
A
1007-0672(2016)06-0001-09
2016-05-12
本研究得到国家科技部“十二五”国家科技支撑计划项目“人口与发展数学模型与综合决策支持系统”(2012BAI40B01)和国家卫生计生委《中国家庭发展追踪》项目的资助。
齐嘉楠,男,河北石家庄人,中国人口与发展研究中心副研究员,研究方向:抽样方法与调查,流动人口公共服务均等化。
猜你喜欢
当代县域经济(2022年11期)2022-12-18
数学物理学报(2022年5期)2022-10-09
智能建筑电气技术(2022年2期)2022-02-06
数学物理学报(2021年6期)2021-12-21
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
数学物理学报(2020年6期)2021-01-14
中学生数理化·中考版(2017年12期)2017-04-18
法制博览(2017年25期)2017-01-28
郑州大学学报(理学版)(2014年2期)2014-03-01
