
异质网中基于张量表示的动态离群点检测方法
2016-08-31 04:35左万利
计算机研究与发展 2016年8期
刘 露 左万利,2 彭 涛,2
1(吉林大学计算机科学与技术学院 长春 130012)2 (符号计算与知识工程教育部重点实验室(吉林大学) 长春 130012)
异质网中基于张量表示的动态离群点检测方法
刘露1左万利1,2彭涛1,2
1(吉林大学计算机科学与技术学院长春130012)2(符号计算与知识工程教育部重点实验室(吉林大学)长春130012)
(liulu12@mails.jlu.edu.cn)
挖掘隐藏在异质信息网络中丰富的语义信息是数据挖掘的重要任务之一.离群点在值、数据分布、和产生机制上都明显不同于正常数据对象.检测离群点并分析其不同的产生机制,最终消除离群点具有重要的现实意义.目前,针对异质信息网络动态离群点检测的研究工作相对较少,还有很多问题有待解决.由于异质信息网络的动态性,随着时间的变化,正常数据对象也可能转变为离群点.针对异质网络提出一种基于张量表示的动态离群点检测方法(TRBOutlier),并根据张量表示的高阶数据构建张量索引树.通过搜索张量索引树,将特征加入到直接项集和间接项集中.同时,根据基于短文本相关性的聚类方法来判断数据集中的数据对象是否偏离其原聚簇来动态检测网络中的离群点.该模型能够在充分降低时间和空间复杂度的条件下保留异质网络中的语义信息.实验结果表明:该方法能够快速有效地进行异质网络环境下的动态离群点检测.
动态离群点检测;异质信息网络;张量表示;张量索引树;聚类
异质信息网络代表一个现实世界的抽象,专注于多种类型的对象以及对象之间的相互关系.异质网络中经常存在许多不同于正常对象的离群点.作为数据挖掘领域的一个重要分支,离群点检测可以预测数据对象行为和发展趋势,具有很重要的现实意义.离群点检测有着广泛的应用,例如,异常天气检测[1]、信用卡欺诈检测[2]、心电图分析[3]、异常GPS追踪[4]、文本挖掘中异常的主题检测[5]等.
随着时间及网络上下文的变化,正常数据对象可能由于其不同的发展趋势在未来某一时刻转变成离群点.也就是说,在时刻time1不是离群点的数据不一定在时刻time2仍然不是离群点.例如,一个作者在2010—2014年发表的论文大多和数据挖掘、机器学习方向相关.然而,他在2015年发表的论文却和分布式学习相关.此时,该作者可以被视为离群点.这种离群点可能意味着其研究方向的转变,也可能说明该作者和某个分布式学习方向的学者有着某种合作.同样,我们可以通过动态离群点检测来分析演员出演电影或电视剧的类型是否发生变化,帮助导演挑选合适的演员.也可以通过分析用户在超市购买商品的记录来预测其职业,从而进行合理的商品推荐.不仅如此,网络中的数据还存在多种语义关系,同质网络中的分类或聚类方法都很难直接应用到异质网络当中.这是因为不同类型实体的异质链接负载着不同的语义,而且,异质网络通常会得到更加丰富的信息.通过投影异质网络得到的同质网络往往会失去很多重要的信息.例如,通过对文献信息网络的合作者信息投影得到1个合作者网络,这样的1个投影操作会丢失文献主题等相关信息.综上所述,如何在保留语义关系的同时进行高效数据分析是我们需要考虑的问题.所以,异质网络中动态离群点的检测相对于同质网络有很大不同,会有很多新的原理、方法有待我们去探索和研究.
本文提出了一种基于张量表示的异质网络动态离群点检测方法.张量是矢量概念的推广,其多用于力学分析[6-7]、人脸识别[8-9]等领域.张量在同质网络中进行高维数据的处理已有很好的效果,张量在异质网络中却少有成果.本文将不同类型的数据用高阶张量进行表示,按数据的类型构建张量索引树.张量索引树既避免了张量矢量化带来的维数灾难问题,也解决了张量分解过程中出现的稀疏性问题.在进行聚类时,通过搜索张量索引树将特征加入到直接项集和间接项集中加以区分,聚类特征权值计算充分考虑了特征之间存在的语义关系.该方法引入了时序概念,综合了数据集中存在的时序数据.我们通过判断实体在不同时刻所在聚簇是否发生变化来判断其是否为离群点.另外,我们采用了2个不同的数据集(AMiner[10]和Yahoo!Movies[11])作为标准测试数据集来展示张量表示和短文本相关性聚类方法应用于离群点检测的出色效果.实验结果表明,TRBOutlier可以准确识别出标记的离群数据,张量索引树的构建也大大降低了算法的时间和空间复杂度.
本文的主要贡献如下:
1) 提出了一种基于张量表示的异质网络动态离群点检测方法TRBOutlier,通过分析网络中数据变化趋势判断其是否为离群点;
2) 张量表示方法被应用到异质网络中来处理不同类型的数据,张量索引树的构建解决了数据稀疏性问题,同时保留了数据的语义关系;
3) 在张量索引树的基础上对网络中出现的短文本进行相关性分析,并依据短文本的相关性对异质网络中的实体进行聚类;
4) 应用不同数据集的实验验证我们提出的离群点检测算法可以有效发现异质网络中存在的动态离群点.
1 相关工作
离群点检测不论在同质网络中还是在异质网络中都发挥着重要的作用.静态离群点和动态离群点检测在不同的背景下也都有着广泛的应用和重要的研究意义.接下来,我们概述已有的部分离群点检测工作以及在不同条件下的应用.
关于离群点检测的研究有很多,但大多数都是针对同质信息网络的研究[12-13].文献[14]提出了一种基于密度的局部离群点检测算法.该方法通过引入信息熵来发现网络中存在的局部离群点.文献[15]提出了一种使用后缀树的离群点检测方法.该方法认为离群点稀少,出现的次数也相对较少,比一些周期性出现且出现次数频繁的正常点更加重要.其主要用于处理数值或者字符,因此被应用于同质信息网络.
如今,异质网络无处不在,网络中实体的类型不同,实体之间的链接关系也多种多样,使得原本适用于同质信息网络的离群点检测方法不能完全胜任.因此,异质网络中的离群点检测方法应运而生.Gupta等人在文献[16]中提出了一种应用于异质网络的基于社区分布的离群点检测方法(CDOutlier).该方法利用非负矩阵分解来判断所在社区的分布是否跟大部分社区分布变化模式相似来检测离群点,他们还在文献[17]中对关于时序数据的离群点检测方法进行了综述.
不论异质网络还是同质网络中的数据都不是一成不变的.我们将离群点检测也分为静态离群点检测方法和动态离群点检测方法.在静态网络中,Liu等人在文献[18]中提出了一种基于支持向量数据描述的离群点检测方法.该方法对网络中的不确定数据进行了分析和处理.在进行离群点检测的同时降低了不确定数据对整个分类器的影响,从而提高了离群点检测的准确度.Perrozi等人在文献[19]中提出了在大规模的属性图中面向用户兴趣偏好的离群点检测方法.该方法使用主题聚类方法体现了在大规模社交网络中推测用户兴趣偏好的成果,并检测出其中的离群点.在动态网络中,张净等人在文献[20]中提出了一种增量式的离群点检测方法.该方法利用网格七元组对数据进行降维,通过分析数据的变化部分来达到减少计算量和降低时间复杂度的目的.但该方法也仅应用于同质信息网络,并不能对多类型节点进行处理.文献[21]描述了一个虚拟机在云端动态迁移时的离群点检测方法.该方法通过定义维数推理规则,扩展了使用传统局部离群因子来进行离群点检测,从而弥补了不能检测出虚拟机移动到新主机过程中出现离群点的缺陷.胡云等人在文献[22]中提出了一种演化离群点检测方法.该方法采用稳健回归M-估计方法检测重要成员的异常演化行为,它是一种在同质网络下的动态离群点检测方法.
国内外的研究人员针对离群点检测做了许多探索和尝试,也取得了一些研究成果,但其中很少有针对异质网络的动态离群点检测方法.本文提出的基于张量表示的动态离群点检测方法,将网络中的异质数据进行动态分析.不仅解决了数据的稀疏性问题,也很大程度上保留了数据之间的语义关系.该方法可以根据异质数据所在聚簇是否发生变化来判断网络中的数据是否为离群数据,也可以根据离群数据来分析其产生机制并进行相应的处理.
2 异质信息网络中的张量表示方法
在本节中,我们主要介绍张量表示方法在异质信息网络中的应用,并且将类型的概念引入张量中.
2.1基本定义
对同质网络进行离群点检测时, 通常用数值或向量来表示网络中的实体.例如,在异常天气检测中,气温用数值进行记录,1周或1个月的气温值可以存储在1个向量之中.在对文本主题异常检测时,文本中的特征权值通常用向量表示.不论气温还是文本,数值中和向量中存储的都是同一类别的实体,即数值和向量的定义域是相同的.然而,在异质信息网络中存在着不同类型的实体和链接,将所有实体各自表示成向量进行相似或离群的计算往往不能得到满意的结果.因此,在本节中,我们提出了一种张量表示方法来处理异质网络中的实体.将张量矢量化处理很可能引起维数灾难并破坏了原本高维数据之间的结构关系.为了解决张量矢量化带来的问题,研究者提出了一些张量分解模型.典型的张量分解方法,如PARAFAC分解和TUCKER分解[23],虽然能一定程度上解决维数灾难问题,但却不能有效分析张量内在的模式和结构特点.张量是矢量的推广,1阶张量是向量,2阶张量是矩阵,3阶张量是矩体,3阶或3阶以上的张量被称为高阶张量.将张量表示用于异质离群点检测是一种新的尝试.在详细描述离群点检测算法之前,我们先给出一些基本的符号解释和定义.
定义1. 异质信息网络[24].给定一个有向图G=(V,E;τ,φ;A,R).V代表节点集,E代表边集.τ表示对象类型映射函数.φ表示关系类型映射函数.τ(v)∈A表示每个对象v∈V都属于一个特定的对象类.φ(e)∈R表示每个关系e∈E都属于一种特定的关系类.当节点类型数量|A|>1或边的类型数量|R|>1时,这样的信息网络被称为异质信息网络.反之为同质信息网络.
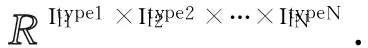
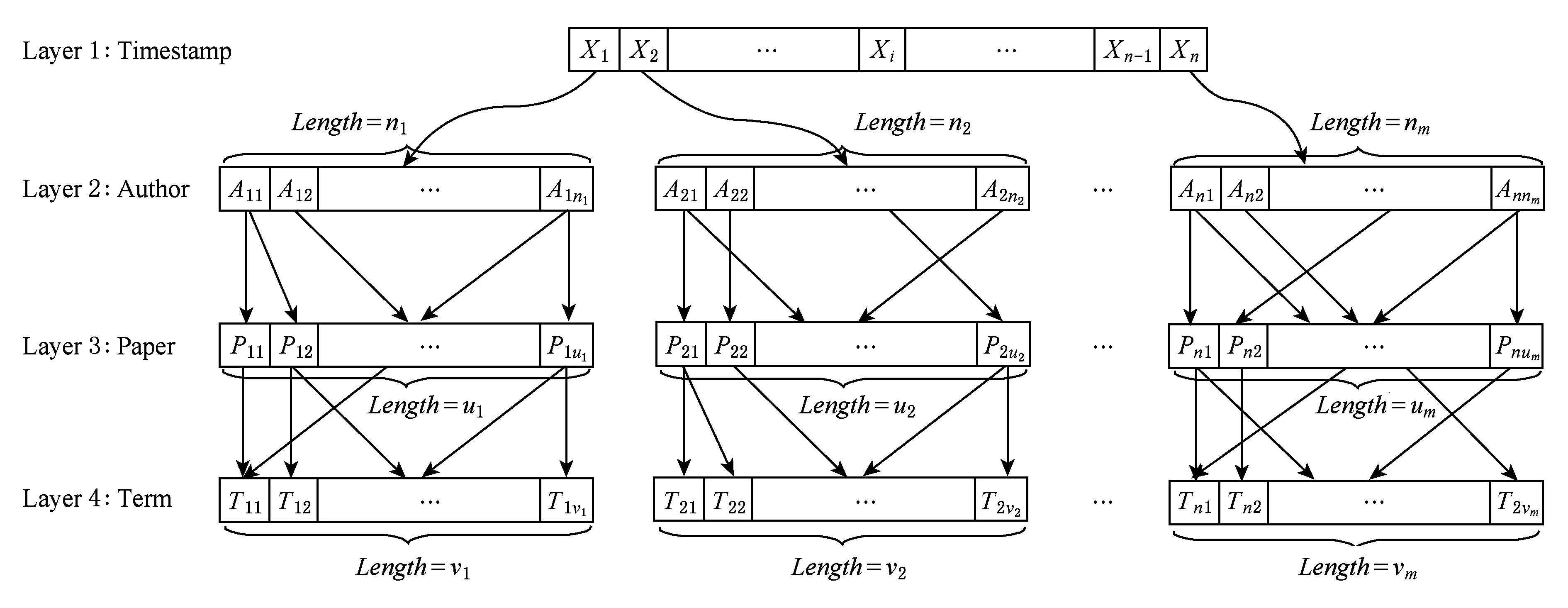
Fig. 1 The tensor index tree constructed by a third order tensor in bibliographic network.图1 文献网络中由3阶张量所构建的张量索引树
定义3. 张量索引树.张量索引树是包含n(n≥1)个节点且满足5个条件的有限集合:
1) 张量索引树中的每一个节点都由1个 N(N≥1)维向量组成.
2) 存在唯一一个向量节点X0,它是由一系列时序数据组成的向量,称为张量索引树的根节点.
3) 张量索引树同一层的节点可以包含不同类型的数据.但同一类型的数据都处于张量索引树的同一层中.
4) 除根节点的后继节点为向量本身外,其余非叶子节点向量中的数据均可独立作为后继节点并放置在所在类型的向量之中.
5) 若1个向量节点中的数据均无后继节点,则称该向量节点为张量索引树的叶子节点.
2.2张量索引树的构建
第1节已叙述张量矢量化可能破坏各阶中数据之间的关系.在大数据环境下,不可避免地会引起维数灾难.而对于异质网络中的数据,如何进行高阶统计也是我们需要考虑的问题.应用张量分解方法,例如构建邻接矩阵,处理数据集中的样本会出现严重的数据稀疏性问题.在本节中,我们提出了一种构建张量索引树的方法来处理异质信息网络中用张量表示的数据,进而动态发现网络中存在的离群点.
我们首先描述张量索引树的构建过程.由于本文主要解决动态离群点发现的问题,因此,张量索引树的根节点为时序数据组成的向量X=(X1,X2,…,Xn) ,如图1中Layer1所示.在本节中,我们使用文献网络中的3阶张量模型来说明构建过程.在时间点X1中,顺序遍历N(N=3)阶张量中的第1阶张量.将属于type1类型的实体(作者名)加入Layer2向量节点中.同时,将该作者发表的论文依次加入Layer3向量节点中.Layer3向量节点中的论文题目作为Layer2向量节点中作者名的后继节点.大部分情况下,1篇论文是由若干作者合作完成的.因此,形成Layer3向量节点之后需进行去重.同样,第2阶张量和第3阶张量之间也被加入索引.第3阶张量中的实体(关键词)作为第4层节点被加入到张量索引树当中.在图1张量索引树中的Layer2,Layer3向量节点都只有1个后继向量节点.但在实际应用中,一个类型的实体可能拥有不同类型的后继节点.例如,在文献网络中,论文不仅有关键词一个属性,而且论文发表的期刊名或会议名也应该在数据分析的范围之内.图1中的Layer4也应加入期刊名或会议名所构成的向量节点.同样,在电影网络分析过程中,我们也需要考虑电影所属的类型、配音使用的语种等属性.本文将用3阶张量构成单后继节点的4层张量索引树来进行构建过程说明.
张量索引树的构建不仅可以加快离群点检测的速度,而且可以有效解决在使用邻接矩阵进行计算时出现的数据稀疏性问题.
3 基于张量表示的聚类过程
在本节中,我们详细介绍如何根据给定的入口entry(source,target)搜索张量索引树,进而使用聚类方法发现异质网络中存在的离群点(即源节点相对于目标类别是否离群).张量索引树可以根据给定入口快速定位相关的异质信息.例如,给定作者a1,只需通过遍历其所有前驱结点和后继节点就可以找出与之相关的论文、期刊、会议、研究方向等相关信息.我们把作者名、期刊名、研究方向和其他异质信息网络中出现的例如电影名、电影类别、语种等都称为短文本.然而,我们知道1个作者发表的1篇论文中只有4~5个关键词,1个演员出演的1部电影可能也只有1~3个类别.不论是论文的关键词还是电影所属的类别都不是完全无关的.假设我们要进行作者相对于“textmining”这个研究方向离群程度的计算.仅定位与“textmining”在同一路径上的作者类型节点是不够准确的、不全面的.短文本之间的相似性也应被充分考虑.与“textmining”在语义上相似的短文本如“webmining”,“textclassification”等,也应被加入到特征权值分析中.在进行基于张量的短文本聚类之前,我们先描述短文本特征权值计算过程和如何处理数据分布的不一致性.
首先,提取索引树中源节点至目标类别路径上直接关联的数据,将其放入直接项集(directitemset, DIS)中,如图2表格中的Paper1~Paper3.根据频繁项集的思想,将包含直接项集中目标类型节点2项以上的前驱节点及其相应路径上的直接关联信息加入到间接项集(indirectitemset, IIS)中,如图2表格中的Paper4~Paper10.从表格中可以看到,Paper4中的关键词outlierdetection和heterogeneousnetwork在Paper1~Paper3中出现过,因此,Paper4被加入间接项集中.得到直接项集和间接项集后,项集中目标类别的特征被加入到1维向量词典中,记为Dic1=(st1:stw1,st2:stw2,…,stN:stwN).其中,st表示短文本特征,stw表示短文本特征权值.式(1)中给出了短文本权值的定义.
(1)
其中,NDIS和NIIS分别为直接项集和间接项集中项的数量(1条路径中的数据集合称为1条项集,也称记录).tk i表示特征i在直接项集记录k中出现的次数. tl i表示特征i在间接项集记录l中出现的次数.α为调节因子.本文中,设α=0.5.由于直接项集中的记录和源节点的相关程度将高于间接项集中的记录与源节点的相关程度,因此,调节因子起到调节特征在直接项集和间接项集中重要程度的作用.

Fig. 2 Direct item set and indirect item set.图2 直接项集与间接项集
根据上述特征权值计算过程,我们可以得到源节点相对于目标类别的特征表示,根据特征相似度判断对象是否属于一个聚簇当中.但是,不同的源节点对应的目标类别节点大不相同,需在聚类之前解决数据分布不一致的问题.首先构建一个包含目标类别所有特征的词典DIC,每个源节点关于目标节点的特征表示为Dici,1≤i≤Nsum其中,Nsum为目标类别特征总数.每个Dici中的特征均为DIC的一部分.计算短文本特征权值的算法在算法1中给出.由于之前已经得到源节点相对于目标类别节点的特征表示,对于所有DIC中的特征,如果未在Dici出现过,则该特征的权值设为0.该方法可以解决聚类过程中出现的数据分布不一致问题.
异质网络中的节点及链接关系存在异质性、多样性,采用单一对象类别标注方法会失去很多语义信息.因此,我们提出一种基于张量表示的短文本聚类的方法来进行离群点的检测.式(2)给出了2个特征向量进行相似度计算的方法[25].
(2)
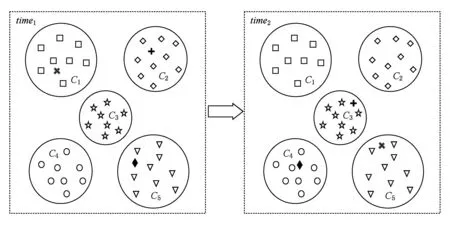
Fig. 3 A model that illustrates how the outliers change based on clustering from time1to time2.图3 时刻time1到时刻time2基于聚类方法的离群点变化模型
其中,向量(stwi1,stwi2,…,stwi Nsum)和向量(stwj1,stwj2,…,stwj Nsum)分别是源节点i和源节点j的Nsum维特征表示,代表Dici和Dicj.Sim(Dici,Dicj) 的取值范围为[0,1].式(3)定义了一个0,1变量CV(comparisonvariation)[25]来判断2个聚类能否合并或分裂.
(3)
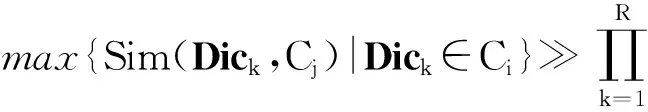
算法1. 短文本特征权值计算算法.
输入:张量索引树TI-tree、 源节点s、目标类型t、直接项集DIS、间接项集IIS;
输出:源节点相对于目标类型的特征表示Dics.
① BreadthFirstSearch(TI-tree,s);
②foreach包含s的路径
④endfor
⑥if任意结点p是集合C中至少两个结点的父结点
⑦ 将路径p中所有结点加入集合IIS中;
⑨endif
⑩ 用式(1)计算每个源结点s的特征表示Dics.
4 基于张量表示的离群点检测方法
离群点和正常数据对象的产生机制不同,以致于出现了不同于正常点的数值或数据分布等现象.而且,正常数据对象也可能在未来某时刻成为离群点.也就是说,某些数据在正常对象和离群点之间是动态变化的.基于这个思想,在本节中我们提出了一种基于张量表示的动态离群点检测方法.
首先,我们将带有时序特征的数据按张量表示法添加到张量索引树当中.树中的根节点即为时序数据.再通过对每个时间点下的子节点进行聚类,分析每个对象所在的聚簇是否变化和变化的程度,即可判断节点所对应的对象是否为离群点.如图3所示,时刻time1网络中存在5个聚簇,其中3个标记的对象分别在 C1,C2,C5中.然而,时刻time2三个标记的对象分别变化到了C5,C3,C4中.由于3个标记对象的变化趋势与其所在聚簇内节点的变化趋势不同.因此,我们将这3个标记对象视为网络中的离群点.
在真实的网络环境中,我们可以将数据分为N个时刻进行数据分析.不仅可以判断对象所在的聚簇是否发生变化,而且可以统计变化的次数以达到数据分析的目的.图4给出了基于张量表示的动态离群点检测方法的整体框架.
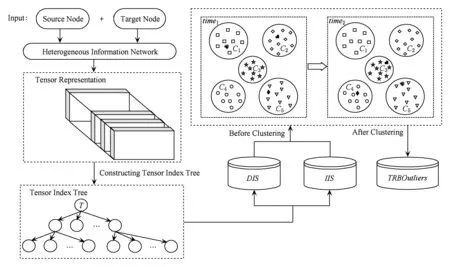
Fig. 4 The overall framework of tensor representation based dynamic outlier detection method.图4 基于张量表示的动态离群点检测方法的整体框架
5 实验与结果
在本节中,我们使用本文提出的技术构建了一个面向异质网络的动态离群点检测模型,并且在2个数据集(AMiner[10]和Yahoo!Movies[11])上测试了我们的方法.
5.1度量标准
离群点的判断标准一般分为2种:1)用二进制数0,1来判断数据是否为离群点.若为1则是离群点,反之则不是离群点;2)用离群分数来度量数据的离群程度,若离群分数达到规定的阈值,则认为其是离群点,反之则不是离群点.本文选用第1种方法来进行离群点的判断.由于已有数据集中很少存在标记的离群数据,异质网络中也几乎没有办法统一标记实体的类别.因此,我们在数据集中手动加入离群数据.若数据对象所属的聚簇发生了变化,则该对象被识别为离群点.我们用精确率和召回率来反映离群点检测系统的性能.离群点检测系统中的精确率是被正确识别为离群点的数据占被识别为离群点数据的比例.召回率,也称查全率,是被正确检测出的离群点数据占实际离群点数据的比例.这2个度量标准分别反映了模型找对和找全离群点的能力.我们定义精确率和召回率公式如下.
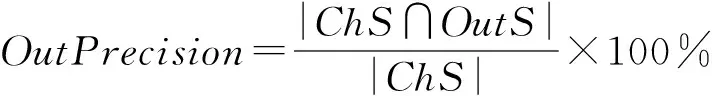
(4)
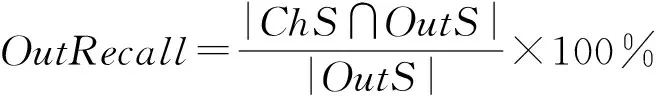
(5)
其中,ChS表示聚类过程中所在聚簇发生变化的数据集.OutS表示聚类前被标记为离群点的数据集.
随着召回率的增加,精确率很可能呈下降趋势.通过调节精确率和召回率的重要程度,我们采用精确率和召回率的调和平均值F-Measure[26]来作为评估离群点检测模型的1个标准.F-Measure的计算公式定义如下:
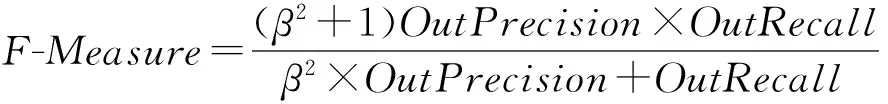
(6)
β作为调节精确率和召回率的权值,在实验中被设置为1.然而,仅用精确率和召回率评价系统的性能是不够的.本文还使用准确度Accuracy作为度量标准来衡量所有数据是否和真实类别一致,即衡量模型作出正确决定的能力.我们将数据集中的数据分成四大类:1)被判断为离群点的离群数据,记作TP(true positive);2)被判断为离群点的正常数据,记作FP(false positive);3)被判断为正常点的正常数据,记作TN(true negative);4)被判断为正常点的离群数据,记作FN(false negative).AllN表示数据集中所有记录的总数.Accuracy的公式定义如下:
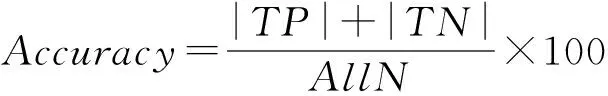
(7)
5.2数据集
本文将在AMiner和Yahoo!Movies两个数据集上测试我们提出的方法.下面我们从数据集大小和数据特点等方面分别介绍这2个数据集.
1) AMiner数据集是一个异质的文献信息网络.它由3个部分构成,分别是AMiner-Author, AMiner-Paper, AMiner-Coauthor.这3部分共包括1 712 433个作者和2 092 356篇论文的信息,这些节点和节点之间的关系构成了涵盖计算机不同领域的异质信息网络.我们提取其中20 000个作者及其相关信息构成本文实验数据集,并手动添加200个记录作为离群点进行检测.
2) Yahoo!Movies数据集作为Yahoo!数据集评分和分类数据的一部分,可以被应用到各种数据挖掘算法当中.这个数据集包含6个文件,共23 MB,描述了电影网络中各个节点的信息和节点之间的关系.我们从中选取5 000个演员和其相应的电影信息,包括电影名、电影类型的相关信息进行实验.并手动添加100个记录作为离群点进行识别.在AMiner和Yahoo!Movies两个数据集中均构建3阶张量进行实验.
5.3实验和结果
本节用4个实验来验证我们提出的离群点检测模型的可行性和高效性.实验1是通过变化λ的取值判断其取何值时精确率率和召回率可以达到最大值.从表1可以看出,λ越小,聚类的标准越高,数据点特征稍有变化就可能被视为离群点.反之,λ越大,聚类的标准越低,此时可以尽量找全离群点,但精确率会有所降低.同时,λ过高或过低也会影响着准确度的大小.在AMiner数据集中,λ=3时F-Measure和Accuracy的取值达到峰值.在Yahoo!Movies数据集中,λ=2时F-Measure和Accuracy的取值达到峰值.在之后的3个实验中,λ在AMiner和Yahoo!Movies数据集中分别取3和2.
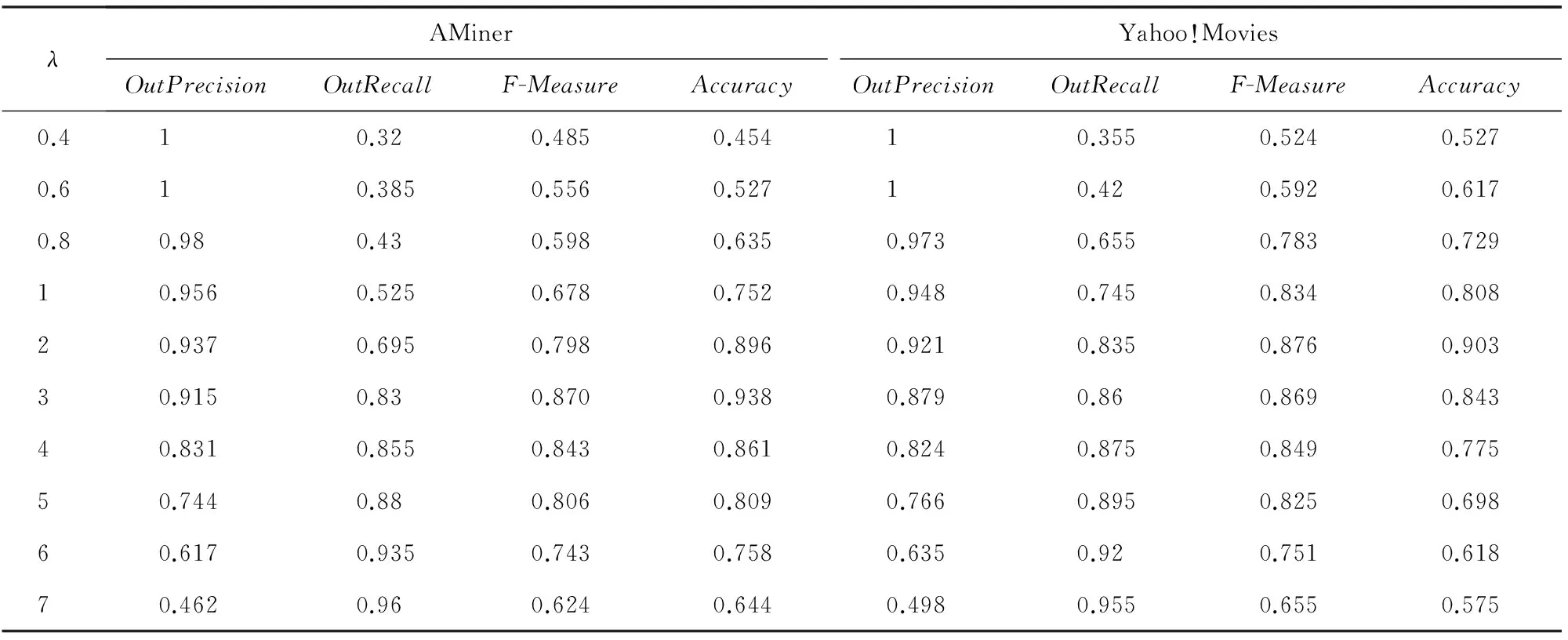
Table 1 The Performance of TRBOutlier on AMiner and Yahoo!Movies with Different λ表1 TRBOutlier方法在AMiner和Yahoo!Movies数据集中λ变化时的性能
在实验2中,我们将提出的基于张量表示的动态离群点检测算法和2个基线算法进行F-Measure和Accuracy的比较.由于目前还没有基于张量表示的离群点检测方法,我们在实验部分使用基于实体的社团离群点检测方法(entity based clique outlier detection, EBC[27])和基于社区分布的离群点检测方法(community distribution based outlier detection, CDOutlier[16]). EBC将每个实体的属性单独聚类,当实体的属性变化异常时,该实体就被识别为离群点.将实体的属性单独聚类很可能忽略了异质网络之间的结构关系.CDOutlier使用非负矩阵分解的方法判断社区分布的变化情况.非负矩阵虽然可以很好地保留对象之间的结构关系,但不能很好地解决数据稀疏性的问题,很大程度上造成了时间和空间的浪费.从实验结果可以看出,TRBOutlier的离群点检测性能要高于EBC和CDOutlier(如图5所示).
在实验3中,我们验证离群点检测方法的可扩展性,即随着节点数量的增长,运行时间成线性还是指数型增长.从图6可以看出,在同一数据集中,当数据量增加时,运行时间也呈线性增长趋势.当处理器数量增加时,运行时间也稳步下降.
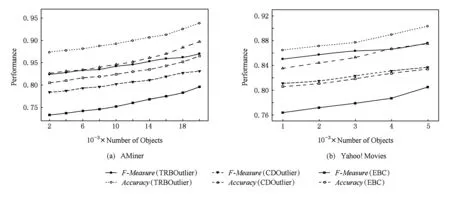
Fig. 5 Performance comparison of three outlier detection methods on AMiner and Yahoo!Movies datasets.图5 3种离群点检测方法在AMiner和Yahoo!Movies数据集中的性能比较
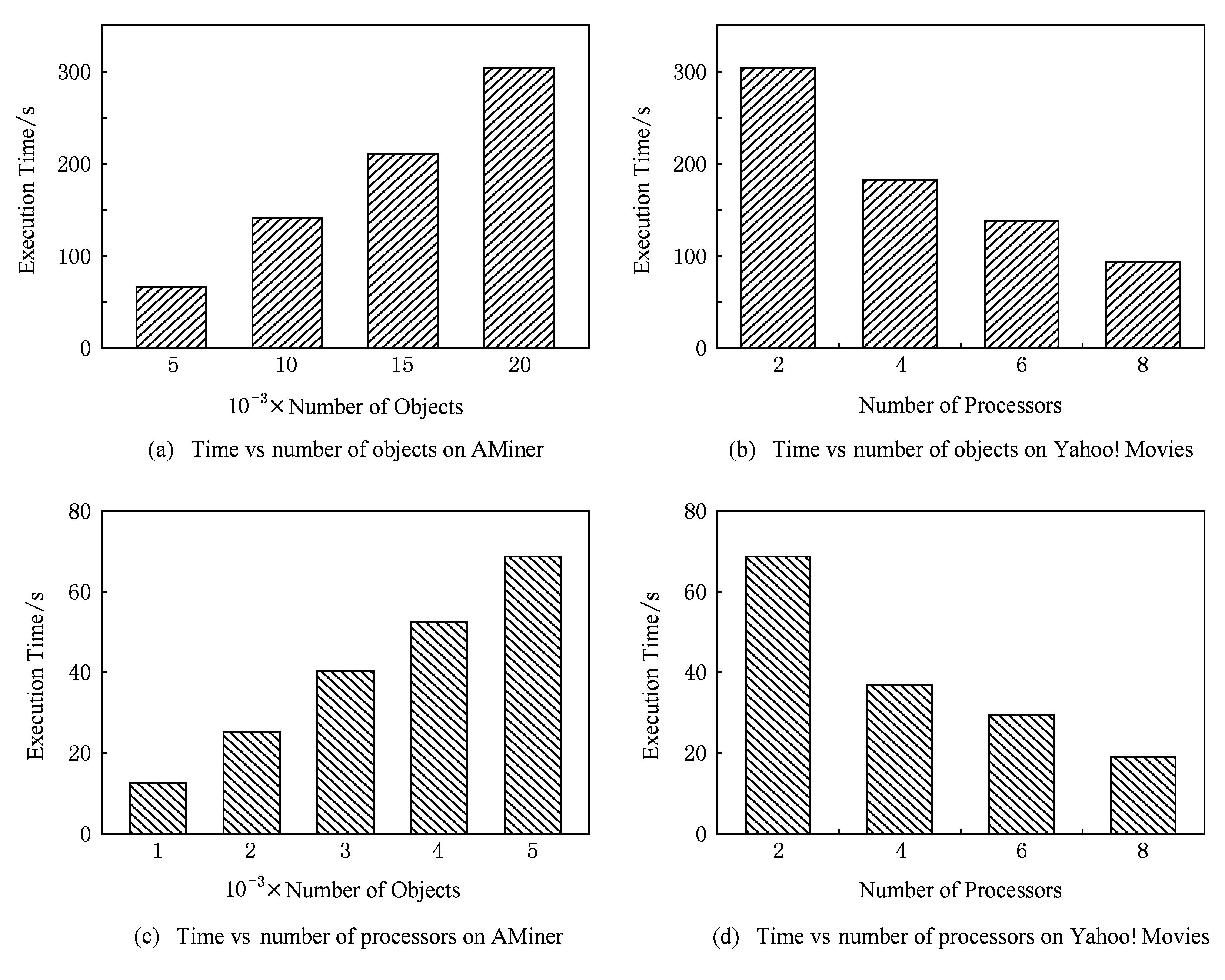
Fig. 6 Execution time comparison of TRBOutlier over AMiner and Yahoo!Movies datasets.图6 TRBOutlier在AMiner和Yahoo!Movies数据集中运行时间比较
在实验4中,我们将提出的TRBOutlier与其他基线算法进行效率的比较.从运行的时间上可以看出,TRBOutlier的效率明显高于2个基线算法.张量索引树的构建可以起到降低时间复杂度的效果,如图7所示:
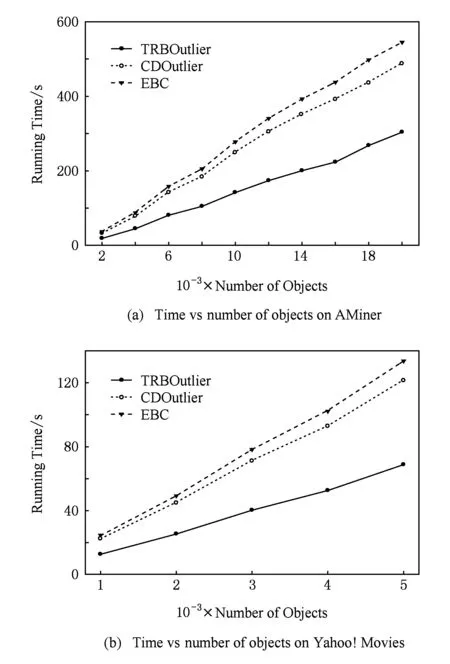
Fig. 7 Running time comparison of three outlier detection methods.图7 3种离群点检测方法的运行时间比较
6 总 结
本文提出了一种基于张量表示的动态离群点检测方法.静态离群点检测方法可以发现1个时间点内的异常数据,然而网络中的数据是不断变化的.本文提出的离群点检测方法可以发现不断变化的异常点.将张量表示引入到离群点检测中是一个新的尝试,基于张量表示的异质网络数据可以在解决数据稀疏性的同时保留网络结构中的语义关系.通过构建张量索引树,将数据的特征表示分成直接项集和间接项集2种,并根据基于短文本相似度的聚类方法进行聚类.直接项集和间接项集考虑了和对象直接相关属性和间接相关属性之间的区别.根据对象所在聚簇是否发生了变换来对其进行动态离群判断.实验结果表明,本文提出的动态离群点检测方法在准确度和效率方面优于许多已有的离群点检测方法.因此,本文的方法是可行且高效的.
[1]Shepherd J M, Burian S J. Detection of urban-induced rainfall anomalies in a major coastal city[J]. Earth Interactions, 2003, 7(4): 1-17
[2]Beutel A, Faloutsos C. User behavior modeling and fraud detection[J]. IEEE Intelligent Systems, 2016, 31(2):84-86
[3]Jiang B C, Yang W H, Yang C Y. An SPC-based forward-backward algorithm for arrhythmic beat detection and classification[J]. Industrial Engineeering & Management Systems, 2013, 12(4): 380-388
[4]Chen C, Zhang D, Castro P S, et al. Real-time detection of anomalous taxi trajectories from GPS traces[M] //Mobile and Ubiquitous Systems: Computing, Networking, and Services. Berlin: Springer, 2011: 63-74
[5]Srivastava A, Zane-Ulman B. Discovering recurring anomalies in text reports regarding complex space systems[C] //Proc of IEEE Aerospace Conf. Piscataway, NJ: IEEE, 2005: 55-63
[6]Lebedev L P, Cloud M J, Eremeyev V A. Tensor Analysis with Applications in Mechanics[M]. Hackensack, NJ: World Scientific, 2010
[7]Schobeiri M T. Vector and tensor analysis, applications to fluid mechanics[G] //Fluid Mechanics for Engineers. Berlin: Springer, 2010: 11-29
[8]Hao N, Kilmer M E, Braman K, et al. Facial recognition using tensor-tensor decompositions[J]. SIAM Journal on Imaging Sciences, 2013, 6(1): 437-463
[9]Litaˇ L, Pelican E. A low-rank tensor-based algorithm for face recognition[J]. Applied Mathematical Modelling, 2015, 39(3): 1266-1274
[10]Tang J, Zhang J, Yao L, et al. Arnetminer: Extraction and mining of academic social networks[C] //Proc of the 14th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2008: 990-998
[11]Yahoo! Webscope Program. Yahoo! Movies user ratings and descriptive content information, v1.0[OL]. [2016-01-28] http://webscope.sandbox. yahoo.com
[12]Wu S, Wang S. Information-theoretic outlier detection for large-scale categorical data[J]. IEEE Trans on Knowledge and Data Engineering, 2013, 25(3): 589-602
[13]Akoglu L, Tong H, Koutra D. Graph based anomaly detection and description: A survey[J]. Data Mining and Knowledge Discovery, 2015, 29(3): 626-688
[14]Hu Caiping, Qin Xiaolin. A density-based local outlier detection algorithm[J]. Journal of Computer Research and Development, 2010, 47(12): 2110-2116 (in Chinese)
(胡彩平, 秦小麟. 一种基于密度的局部离群点检测算法DLOF[J]. 计算机研究与发展, 2010, 47(12): 2110-2116)
[15]Rasheed F, Alhajj R. A framework for periodic outlier pattern detection in time-series sequences[J]. IEEE Trans on Cybernetics, 2014, 44(5): 569-582
[16]Gupta M, Gao J, Han J. Community distribution outlier detection in heterogeneous information networks[G] //Machine Learning and Knowledge Discovery in Databases. Berlin: Springer, 2010: 11-29
[17]Gupta M, Gao J, Aggarwal C C. Outlier detection for temporal data: A survey[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(9): 2250-2267
[18]Liu B, Xiao Y, Cao L, et al. SVDD-based outlier detection on uncertain data[J]. Knowledge and Information Systems, 2013, 34(3): 597-618
[19]Perozzi B, Akoglu L, Sánchez P I, et al. Focused clustering and outlier detection in large attributed graphs[C] //Proc of the 20th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2014: 1346-1355
[20]Zhang Jing, Sun Zhihui, Yang Ming, et al. Fast incremental outlier mining algorithm based on grid and capacity[J]. Journal of Computer Research and Development, 2011, 48(5): 823-830 (in Chinese)
(张净, 孙志挥, 杨明, 等. 基于网格和密度的海量数据增量式离群点挖掘算法[J]. 计算机研究与发展, 2011, 48(5): 823-830)
[21]Huang T, Zhu Y, Wu Y, et al. Anomaly detection and identification scheme for VM live migration in cloud infrastructure[J]. Future Generation Computer Systems, 2016, 56: 736-745
[22]Hu Yun, Wang Chongjun, Xie Junyuan, et al. Robust transition estimation for community evolution and evolutionary outlier detection[J]. Journal of Software, 2013, 24(11), 2710-2720 (in Chinese)
(胡云, 王崇骏, 谢俊元, 等. 社群演化的稳健迁移估计及演化离群点检测[J]. 软件学报, 2013, 24(11), 2710-2720)
[23]Kolda T G, Bader B W. Tensor decompositions and applications[J]. SIAM Review, 2009, 51(3): 455-500
[24]Sun Y, Han J, Yan X, et al. Pathsim: Meta path-based top-ksimilarity search in heterogeneous information networks[C] //Proc of VLDB’2011. Trondheim,Norway: VLDB Endowment, 2011:992-1003
[25]Peng T, Liu L. A novel incremental conceptual hierarchical text clustering method using CFu-tree[J]. Applied Soft Computing, 2015, 27: 269-278
[26]Croft W B, Metzler D, Strohman T. Search engines: Information retrieval in practice[M]. Reading: Addison-Wesley, 2010
[27]Gupta M, Gao J, Yan X, et al. On detecting association-based clique outliers in heterogeneous information networks[C] //Proc of IEEE//ACM Int Conf on Advances in Social Networks Analysis and Mining (ASONAM). Piscataway, NJ: IEEE, 2013: 108-115

Liu Lu, born in 1989. PhD. Her research interests include Web mining, information retrieval, machine learning.

Zuo Wanli, born in 1957. PhD, professor, PhD supervisor. Senior member of China Computer Federation. His research interests include database theory, data mining, Web mining, machine learning, and Web search engine.

Peng Tao, born in 1977. PhD, professor. Member of China Computer Federation. His research interests include Web mining, information retrieval, and machine learning.
TensorRepresentationBasedDynamicOutlierDetectionMethodinHeterogeneousNetwork
LiuLu1,ZuoWanli1,2,andPengTao1,2
1(College of Computer Science and Technology, Jilin University, Changchun 130012)2(Key Laboratory of Symbol Computation and Knowledge Engineering (Jilin University), Ministry of Education, Changchun 130012)
Miningrichsemanticinformationhiddeninheterogeneousinformationnetworkisanimportanttaskindatamining.Thevalue,datadistributionandgenerationmechanismofoutliersarealldifferentfromthatofnormaldata.Itisofgreatsignificanceofanalyzingitsgenerationmechanismoreveneliminatingoutliers.Outlierdetectioninhomogeneousinformationnetworkhasbeenstudiedandexploredforalongtime.However,fewofthemareaimingatdynamicoutlierdetectioninheterogeneousnetworks.Manyissuesneedtobesettled.Duetothedynamicsoftheheterogeneousinformationnetwork,normaldatamaybecomeoutliersovertime.Thispaperproposesadynamictensorrepresentationbasedoutlierdetectionmethod,calledTRBOutlier.Itconstructstensorindextreeaccordingtothehighorderdatarepresentedbytensor.Thefeaturesareaddedtodirectitemsetandindirectitemsetrespectivelywhensearchingthetensorindextree.Meanwhile,wedescribeaclusteringmethodbasedonthecorrelationofshorttextstojudgewhethertheobjectsindatasetschangetheiroriginalclustersandthendetectoutliersdynamically.Thismodelcankeepthesemanticrelationshipinheterogeneousnetworksasmuchaspossibleinthecaseoffullyreducingthetimeandspacecomplexity.Theexperimentalresultsshowthatourproposedmethodcandetectoutliersdynamicallyinheterogeneousinformationnetworkeffectivelyandefficiently.
dynamicoutlierdetection;heterogeneousinformationnetwork;tensorrepresentation;tensorindextree;clustering
2016-03-17;
2016-05-24
国家自然科学基金项目(60903098);吉林省工业技术研究和开发项目(JF2012c016-2);吉林大学研究生创新基金项目(2015040)
彭涛(tpeng@jlu.edu.cn)
TP391
ThisworkwassupportedbytheNationalNaturalScienceFoundationofChina(60903098),theProjectofJilinProvincialIndustrialTechnologyResearchandDevelopment(JF2012c016-2),andtheGraduateInnovationFundofJilinUniversity(2015040).
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
数学物理学报(2021年1期)2021-03-29
五邑大学学报(自然科学版)(2020年4期)2020-12-09
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
小型微型计算机系统(2018年8期)2018-09-07
中国房地产业(2016年9期)2016-03-01
云南师范大学学报(自然科学版)(2015年5期)2015-12-26
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
哈尔滨商业大学学报(自然科学版)(2015年1期)2015-03-09
物理实验(2015年10期)2015-02-28
