
基于语义一致性的集成实体链接算法
2016-08-31 03:49吴祖峰秦志光
计算机研究与发展 2016年8期
刘 峤 钟 云 刘 瑶 吴祖峰 秦志光
(电子科技大学信息与软件工程学院 成都 610054)
基于语义一致性的集成实体链接算法
刘峤钟云刘瑶吴祖峰秦志光
(电子科技大学信息与软件工程学院成都610054)
(qliu@uestc.edu.cn)
实体链接任务的目标是将从文本中抽取得到的实体指称项正确地链接到知识库中的对应实体对象上.当前主流的实体链接算法大致可分为2类:基于上下文相似度的实体链接算法和基于图的集成实体链接算法.这2类算法各自存在一些优点和不足.前者有利于从上下文语义的角度对实体进行区分,但难以充分利用知识库中已有的知识体系辅助决策;后者能够更好地利用知识库中实体间的语义关联关系,但在上下文信息不充分的情况下,较难区分概念相近的实体.提出一种基于语义一致性的集成实体链接算法,该算法能够更好地利用知识库中实体间的结构化语义关系,帮助提高算法对概念相似实体的区分度,实验结果表明:该算法能够有效提高实体链接结果的准确率和召回率,性能显著优于当前的主流算法,在对长、短文本的实体链接任务中性能表现稳定,具有良好的适应性和可推广性.
集成实体链接;信息抽取;知识库扩容;个性化PageRank;语义相关性
作为互联网时代的标志性技术,Web技术正处在快速发展和变革当中,从网页的链接(Web1.0)到数据的链接(linkeddata),再到知识图谱(knowledgegraph)技术,语义Web正在逐渐走向成熟[1].知识图谱是一种图结构的知识库,其中存储的知识元素以〈实体,关系,实体〉三元组的形式表达,也称为事实(facts)[2].知识图谱是目前智能互联网应用研究领域主要采用的知识库形式,本文主要研究知识图谱上的实体链接问题.
实体链接是知识库扩容(knowledgebasepopulation,KBP)研究领域关注的核心问题之一[3].开放域信息抽取技术的快速发展为知识库扩容带来了巨大的发展机遇,同时也带来许多挑战,其中一项关键挑战就是实体链接问题[3].实体链接任务的基本目标是将从文本中抽取得到的实体指称项正确地链接到知识库中对应的实体对象上[4].然而通过开放域信息抽取技术得到的知识元素间的关系是扁平化的(缺乏层次性和逻辑性),为将其正确融入到知识库中,必须首先解决实体链接问题.通过实体链接技术,可以消除知识元素在概念上的歧义,剔除冗余和错误的知识元素,从而确保知识的质量[3].
对实体链接问题的研究,当前面临的主要挑战是解决实体指称项的歧义性和多样性问题[5].所谓歧义性是指相同的实体指称项在不同的上下文环境中可能指代不同的实体对象.所谓多样性是指一个给定的实体对象可以与多个不同的实体指称项形成对应关系(如该实体的别名或缩写等).例如在如下2组语句样例中[6],就同时存在上述问题:
样例1.AfterhisdeparturefromBuffalo,SabanreturnedtocoachcollegefootballteamsincludingMiami,ArmyandUCF.
样例2.Saban,previouslyaheadcoachofNFL’sMiami,isnowcoachingCrimsonTide.Hisachieve-mentsincludeleadingLSUtotheBCSNationalChampionshiponceandAlabamathreetimes.
在上述2组语境中出现的实体指称项Saban具有歧义性,虽然两者都是美国大学橄榄球队的教练,但前者为LouSaban,后者则是NickSaban,分别对应知识库中不同的实体对象.此外,样例2中的CrimsonTide和Alabama是2个不同的实体指称项,但实际上它们指代的是同一实体对象,即AlabamaCrimsonTide橄榄球队.如何将上述样例中的实体指称项Saban和CrimsonTide正确地链接到知识库中的实体对象上,即解决“实体消歧”和“共指消解”问题,是实体链接研究领域当前关注的主要问题.
关于实体链接方法当前主要有2种研究思路[7]:1)根据文本中每个单一实体的上下文信息,通过与知识库中实体对象的已知上下文信息进行比较,选出上下文相似度高的实体对象进行链接[8-9];2)针对文本中出现的实体指称项集合,结合知识库中的已有知识构造实体相关图,批量地将其链接到知识库中.由于前者未能有效利用文本中的共现实体之间存在的天然语义相关性,因此后一种思路在近年来受到了学术界的重视,被称为集成实体链接方法[10-11].
本文提出一种新的集成实体链接算法,称为基于语义一致性的集成实体链接算法(consistentcollectiveentitylinkingalgorithm,CCEL).与相关工作相比,本文的贡献主要体现在以下3点:
1) 提出了一种新的实体相关图构造方法,能够充分利用知识库中已有的知识,补全候选实体的关联关系,提高实体相关度计算结果的准确性.
2) 设计了一种候选实体与输入文本语义相关性的计算方法,能有效降低错误候选实体带来的噪音影响,提高算法对概念相近的实体的区分度.
3) 提出了一种基于语义一致性的集成实体链接算法原型,实验表明该算法的准确率和召回率均显著优于当前主流的相关工作.
1 相关工作
早期的实体链接研究思想是基于实体的上下文相似度进行链接消歧,即通过计算实体指称项所在文本与其相应候选实体的上下文相似度,选择相似度最大的候选实体作为目标链接对象.基本思路是首先在知识库中查找出与该指称项同名的所有实体对象,构成候选实体集合,然后使用词袋模型计算待处理文本和候选实体所在的维基百科页面之间的相似度,选择相似度最高的候选实体作为链接对象[8].研究表明,除文本内容之外,实体的类别相关性和百科页面的锚文本、重定向页面等结构信息,对于提高实体链接算法的准确性有较大帮助[9,12].基于上下文相似度的链接算法其准确性容易受到上下文信息不足的影响,当前主要的解决方案是借助第三方知识库对候选实体的特征进行扩展,以提高候选实体之间的区分度[13],或者改为采用其他的测度(如维基概念)进行相似度计算[14].基于上下文相似度的实体链接方法的主要缺点是忽视了共现实体间天然的语义相关性,而这种语义相关性对于区分有歧义的实体通常具有帮助[15].
除了基于相似度计算的方法外,一些学者还尝试将统计机器学习方法引入到实体链接工作当中.例如,Zuo等人提出了一个投票模型,思路是将奇数个实体链接方法作为分类器,在链接时分别对每个候选实体进行01判定,获得半数以上选票的候选实体将成为最终的目标链接对象[16];Greg等人基于结构化条件随机场算法提出了一个实体分析的联合模型,可同时用于实体识别、实体消歧和共指消解;在ACE2005和OntoNotes等基准数据上进行了实验,取得了不错的实验效果[17].统计机器学习方法的主要缺点是算法的性能效果受制于训练语料的质量和范围,方法的移植性较差.因此,为了克服基于上下文相似度方法和统计机器学习方法的不足,Kulkarni等学者提出了集成实体链接的算法设计思想[10].
集成实体链接方法一次性批量处理文本中所有实体指称项的链接问题,基本的思路是根据候选实体维基页面间的指向关系,建立候选实体间的语义相关图进行推理[10].常用的推理方法是采用随机游走模型,得到候选实体的排序,选择排名最高的实体作为链接对象[11,18].此外,也有学者将批量实体链接的推理问题视为图的搜索问题,通过在实体相关图上搜索包含所有实体指称项和其相应候选实体s的最小密集子图实现批量实体链接[19].与基于上下文相似度的链接方法类似,集成实体链接方法的性能同样易受上下文信息的影响[20].为解决该问题,Ferragina等人通过引入概率化链接的思想,提出了一个面向短文本的集成实体链接算法Tagme[21].
从算法性能的角度来看,Shen等人提出的LINDEN算法在构造语义相关图时,综合考虑了实体所对应的维基页面间的关联关系和实体间的语义相似性,在YAGO知识库的支持下,LINDEN算法在TAC2009数据集上实现了高达84.32%的实体链接准确率[22].在此基础上,Alhelbawy等人在基于实体相关图进行推理时,基于推理结果采用一种动态选择算法对候选实体进行选择,所提出的算法在AIDA数据集上实现了87.59%的链接准确率,是目前性能表现最好的集成链接算法之一[23].
通过以上讨论可以看出,语义相关图和推理算法的质量是影响集成实体链接算法性能的主要因素.本文提出的CCEL算法正是从这2个关键环节入手进行改进:1)在构造语义相关图时,增加了对实体间语义相关度强弱的考量;2)在推理阶段,综合考虑了候选实体与待消歧文本的语义相关性.因此,CCEL算法能够最大程度地降低错误候选所产生的噪音影响,提高算法对概念相近实体的区分度,从而显著提高实体链接的准确率和召回率.同时,与相关工作相比,CCEL算法具有良好的适应性和推广性.
2 集成实体链接算法
CCEL算法由3个步骤组成,分别是生成候选实体集合、构造实体相关图和实现集成实体链接.该算法的逻辑框架如图1所示.
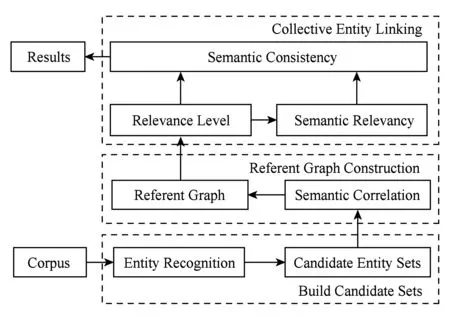
Fig. 1 The framework of the consistent collective entity linking algorithm.图1 基于语义一致性的集成实体链接算法框架
2.1生成候选实体集合
对于任意给定文本Di中出现的实体指称项,生成相应的候选实体集合,是实体链接的第1步.本文采用StanfordNER*http://nlp.stanford.edu//software//CRF-NER.shtml对给定文本进行实体识别,并使用基于规则的方法进行共指处理,得到该文本的实体指称项集合Mi={mi1,mi2,…,mi s,…}.然后,根据Mi查找本地知识库,得到与Mi中元素相对应的候选实体集合Ni.本地知识库基于英文版维基百科*http://download.wikipedia.org(2015-08-05打包发布版本)构造,其中包含400多万个实体页面和3 000多万条链接关系.
由于维基百科知识库中包含大量已经过人工消歧处理的同名实体,为利用这些信息,减少实体链接时候选实体的干扰项数量,首先利用维基百科的实体页面(entitypages)、消歧页面(disambiguationpages)和重定向页面(redirectpages)构造一个同名实体对象字典[22],其格式如表1所示:
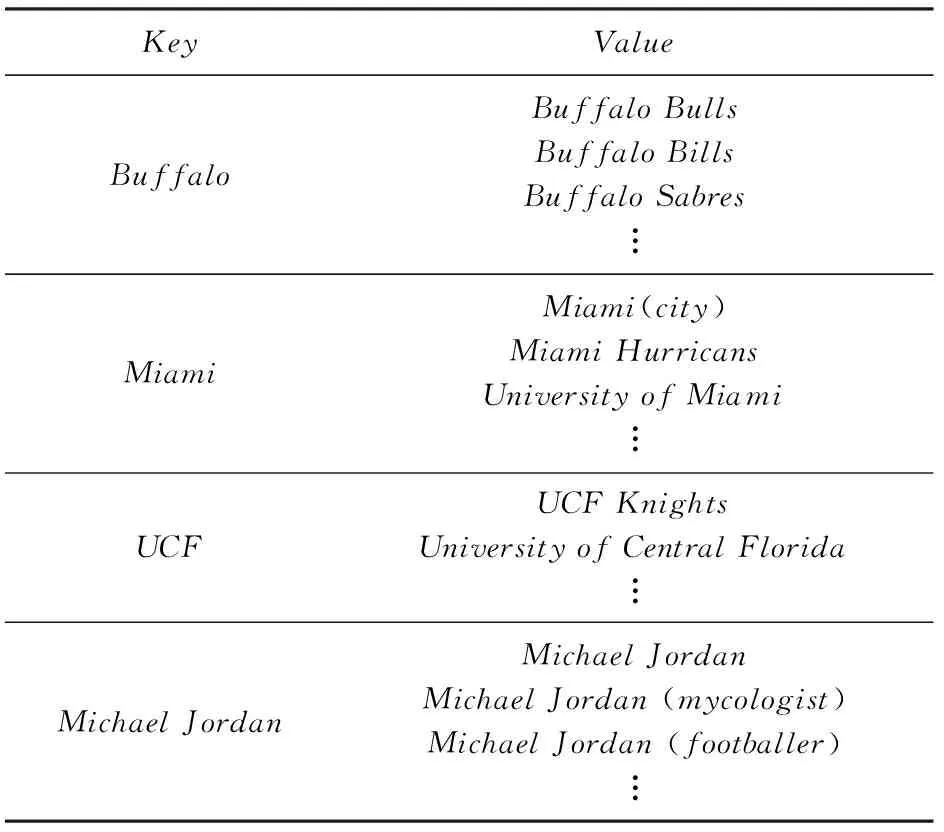
Table 1 Example of Entity Dictionary表1 同名实体对象字典示例
字典中键值对(key-value)的构造方法为:首先利用JPWL*https://dkpro.github.io//dkpro-jwpl//JwplTutorial//工具对维基百科知识库中的所有实体页面和重定向页面进行遍历,以实体页面和重定向页面的页名(pagetitle)作为字典的键(key),以相应的消歧页面中包含该页名的所有锚文本以及重定向页面所指向的页名作为与该键对应的值(value).
需要说明的是,由于字典中的键由所有实体页名和重定向页名共同组成,而字典中的值实际上对应的也是实体页名,所以在所构造的同名实体对象字典中,一个键所对应的值同时也可能是另外一个键.例如:键Jordan所对应的值包括MichaelJordan,BennJordan等,但MichaelJordan同时也是字典的键,与之对应的值包括MichaelJordan(basketball),MichaelJordan(mycologist)以及MichaelJordan(footballer)等.
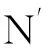
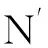
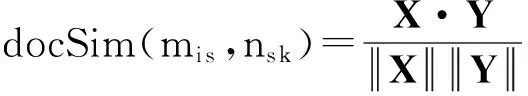
(1)

2.2构造实体相关图
CCEL算法对每篇输入文本构造一张实体相关图并据此进行实体链接,基本思路是利用共现实体间的语义相关性帮助提高实体链接的准确性并实现批量实体链接,因此,实体相关图的质量对于整个实体链接算法的性能具有关键性影响[15].本文采用无向图G=(V, E)表达实体相关图,其中,符号V表示顶点集合,顶点元素为集合Ni中的候选实体;E表示边集合,边元素表示顶点间的语义相关性.实体相关图的构造过程由2部分组成:顶点集合的构造和边集合的构造.首先介绍顶点集合的构造过程.
2.2.1构造顶点集合
实体相关图中的顶点集合定义为:与给定文本Di中出现的实体指称项相关的所有候选实体集合.考虑到不同指称项对应的候选实体可能存在同名的情况,为严格区分候选实体,本文采用(mi s,ns k)实体对来表示实体相关图G中的顶点,其中mi s为Di中的第s个实体指称项,ns k表示与mi s相对应的第k个候选实体.顶点集合的数学定义为:
V={(mi s,ns k)|mi s∈Di,ns k∈Ni}.
(2)
为了利用实体指称项和候选实体的已知上下文信息,我们为图G中的每个顶点赋予一个先验置信度(priorconfidencelevel,PCL).以顶点(mi s,ns k)为例,PCL(mi s,ns k)表示实体指称项mi s指向候选实体ns k的可能性.相关工作中常用的先验置信度定义方式包括文本相似度、名字相似度和实体流行度等[11].本文3.3节将分别采用这3种定义进行实验,结合实验结果选择对CCEL算法最有效的定义方式.
文本相似度(docSim)的计算方法如2.1节的式(1)所示.以docSim作为先验置信度的含义是:实体指称项mi s所在的文本Di与候选实体ns k所在的维基百科页面相比,二者的上下文越相似,则mi s与ns k直接关联的可能性越大.
名字相似度(namSim)的计算方法为
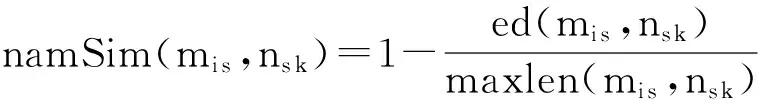
(3)
其中,ed(mi s,ns k)表示实体指称项mi s与候选实体ns k的名字间的编辑距离(editdistance),即从字符串mi s出发,通过字符替换转化成ns k所需的最少编辑操作次数.maxlen(mi s,ns k)表示在字符串mi s和ns k的长度中取较长者.以namSim作为先验置信度的含义是:实体指称项mi s与候选实体ns k的名字相似度越大,则二者直接关联的可能性越大.
实体流行度(popSim)的计算方法为
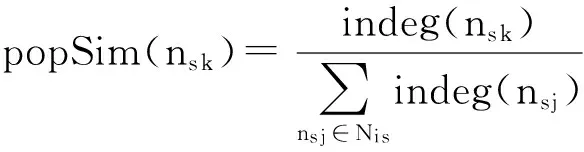
(4)
其中,Ni s表示实体指称项mi s的候选实体集合,ns k表示mi s对应的第k个候选实体对象,indeg(ns k)表示维基百科中指向ns k且锚文本内容为mi s的超链接数目.实体流行度是与语料无关的测度,以popSim作为先验置信度的含义是:候选实体的(实体)流行度越大,则其作为目标链接对象的可能性越大.
对于输入语料中无歧义的实体指称项,本文将其对应的候选实体的先验置信度置为1.完成顶点集合的先验置信度赋值计算后,将同一实体指称项对应的所有候选实体的先验置信度进行归一化处理.
2.2.2构造边集合
实体相关图中边的构造(即建立图G中顶点间的关联关系)是算法的重要组成部分.当前建立实体(顶点)关联关系的方法主要有2种思路:1)基于实体对应的维基百科页面之间的超链接指向关系来定义实体间的语义相关性[10,18,23];2)采用实体间的谷歌距离(Googledistance)作为其语义相关性的测度[11,19,22].
研究表明,上述的2种关系定义方式各有利弊,前者可以准确地反映实体间的语义相关性,但通常得到的关系并不完整[24];后者虽然能够提供更全面的关系定义,但由此建立的关系只是统计意义上的,并不能准确反映实体间真正的语义关联以及强度[25].因此,本文提出一种新的实体相关图构造方法,基本思路是将上述2种实体关系定义方法进行融合,以结合二者的优点,避免各自的不足.具体方法描述如下:
1) 根据顶点集合V中的顶点(实体)在本地知识库中的直接关联关系进行加边处理,如果集合V中的顶点va和vb所代表的候选实体在维基百科页面(即本地知识库)具有超链接直接指向关系,则在这2个顶点间添加一条无向边,边的权重wa b置为1;
2) 根据顶点(实体)间的间接关联关系进行加边处理,方法是若集合V中的顶点va和vb所代表的候选实体在本地知识库中均与一个以上的第三方实体存在超链接直接指向关系,则在这2个顶点间添加一条无向边,边的权重wa b由实体间的谷歌距离做简单的线性变换得到:
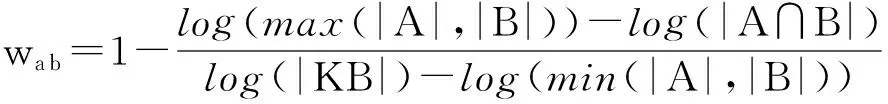
(5)
符号A和B分别表示知识库中与顶点va和vb所表示的候选实体存在超链接指向关系的实体集合,KB表示整个知识库的实体集合,|A|表示集合A中的元素个数.wa b的取值范围是(-∞,1] ,当wa b的取值为负数时,设定wa b的值为0,表示顶点va和vb间不具有语义关联关系;当集合A与B相等时,wa b取最大值1,表示va和vb的关联实体重合度最高.
需要特别说明的是,在构造实体相关图的过程中,当顶点间存在直接关联关系时,则不考虑其间接关联关系,只有在顶点间不存在直接关联关系时,才进一步考虑其间接关联关系.此外,对于同一实体指称项对应的多个候选实体(顶点),不考虑其相互之间的关联关系,即实体相关图中同一实体指称项所对应的候选实体顶点间不存在关系边.图2展示了根据引言中样例1生成的实体相关图.
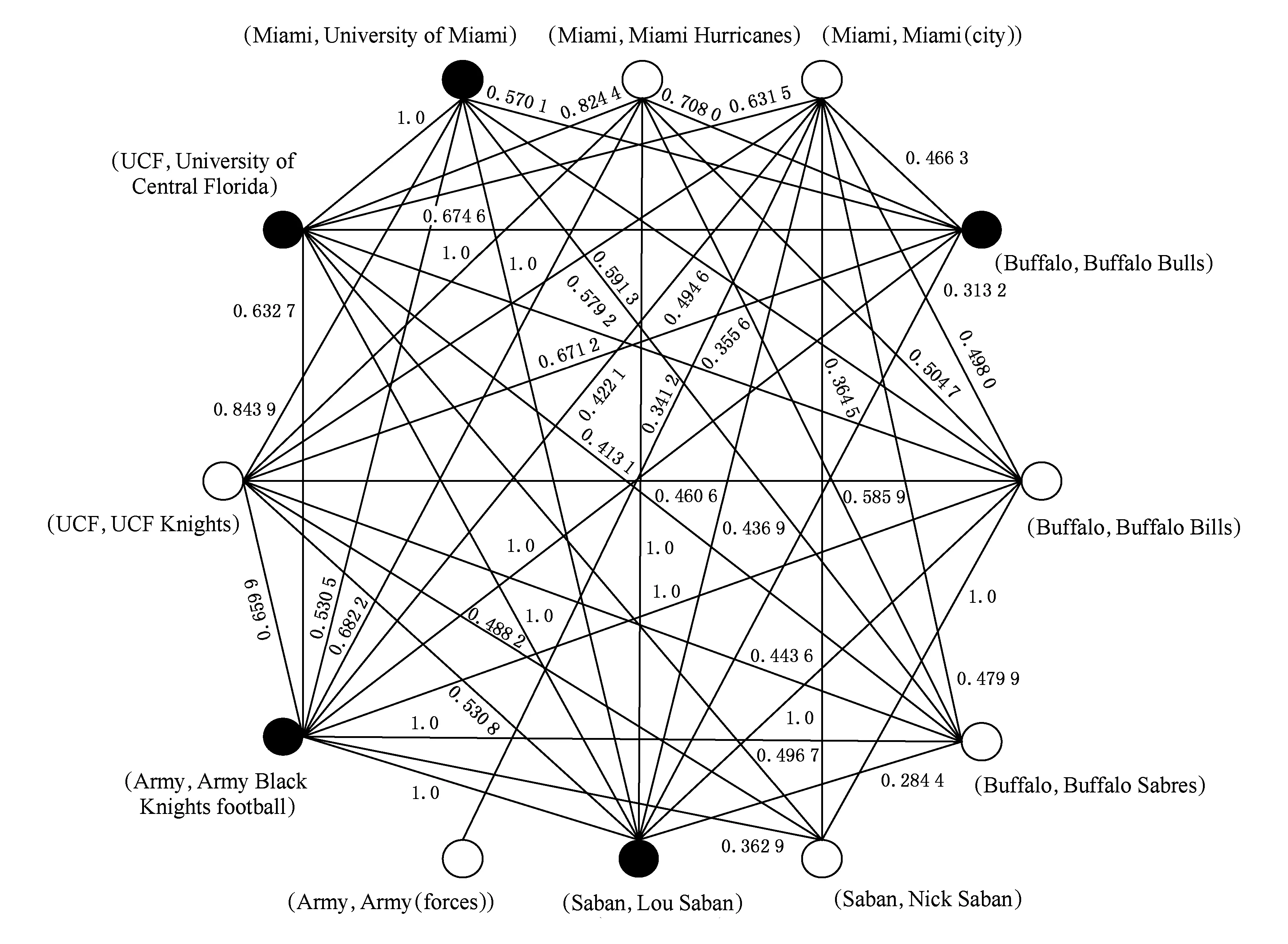
Fig. 2 The referent graph of example 1 in introduction.图2 样例1的实体相关图范例
2.3基于语义一致性的集成实体链接
在完成实体相关图的构造之后,即可针对给定文本Di进行实体链接的推理运算.本文提出一种新的推理判据,称为语义一致性判据(semanticcon-sistencycriterion,SCC).该判据由候选实体的相关度(relevancelevel,RL)和候选实体与输入文本Di间的语义相关性(semanticrelevancy,SR)2部分组成.其中,候选实体的相关度表达的是该实体与相应实体指称项之间的语义关联证据的强度,可采用本文提出的相关度排序算法进行计算;候选实体与输入文本Di间的语义相关性则采用本文提出的语义相关性计算方法得到.
2.3.1计算候选实体的相关度
在构造实体相关图的过程中,我们为每个候选实体(顶点)赋予了一个先验置信度PCL,然而通过观察2.2.1节给出的3种PCL定义方式,可以看出这些建模的方式均存在一定的片面性,均不适合直接用作实体链接的判据.例如:1)docSim的准确性依赖于文本Di与候选实体ns k所在的维基百科页面的内容质量,如果相应文本较短或包含的有效信息较少,则docSim的值会比正常情况偏低;2)如果以namSim作为先验置信度并据此进行实体链接操作,我们也很容易举出反例证明其局限性,例如给定实体指称项为“广电”,假设有2个候选实体分别为“广播电视总局”和“广州电视总局”,根据式(3)可知这2个候选实体与给定实体指称项的namSim值是相等的;3)popSim的取值虽然与待处理的语料Di无关,其质量仅取决于知识库的知识完备性,然而仅根据实体的流行度作为实体链接的判据显然是不合理的.因此,为提高实体链接的准确性,还需参考其他的已知信息,提出更有效的判据.
相关研究表明,采用实体相关图中顶点的PageRank值,对该顶点与相应实体指称项的余弦相似度进行加权,可以得到更好的实体链接效果[18].该结果表明实体相关图的拓扑结构对于确定候选实体的相对重要性具有积极意义.受其启发,本文提出一种新的候选实体相关度计算方法,称为相关度排序(relevancerank,RR)算法,以更好地发掘和利用实体相关图的拓扑结构信息在实体链接任务中的价值.RR算法的数学公式如下:
RR(va)=(1-α)docSim(va)+
(6)
其中,docSim(va)表示候选实体顶点va所表示候选实体与输入文本的上下文相似度,可根据式(1)计算得到,RR(va)表示候选实体顶点va与相应实体指称项在当前上下文(图G)中的相关度,其初始值为顶点va的先验置信度.T(b,a)表示在实体相关图G中从顶点vb到顶点va的带权转移概率:
(7)
其中,wb a表示图G中边(vb, va)的权重,Nh(vb)表示顶点vb的邻域(neighbourhood),即图G中直接与vb相邻的顶点集合.式(6)中的α为阻尼因子,按照PageRank算法的一般惯例取值为0.85.
由式(6)可见,当算法收敛到稳态时RR(va)的物理意义是:在每一轮迭代过程中,随机漫步者选择当前顶点va的概率由2部分组成:一部分由顶点va与输入文本的上下文相似度docSim(va)贡献,所占权重为(1-α);另一部分由与va相邻的顶点所贡献,所占权重为α,其中每个相邻顶点vb的贡献为T(b,a)×RR(vb),即把vb自身的相关度按照与之相邻的边的权重进行分配.由此可见,式(6)对文本Di的上下文环境(主要体现在相似度计算中)和实体间的关系(主要体现在图G的拓扑结构中)进行了综合考虑,通过迭代求解式(6),实现先验置信度在各顶点间的再分配,使得在当前语境下拥有较多关联证据的顶点的相关度得到强化,同时削弱拥有较少关联证据的顶点的影响.
如本节开始部分所述,当前已有的先验置信度计算方法都具有一定的片面性.通过实验我们发现,RR算法虽然能够借助候选实体在当前上下文环境中的关联信息对其结果进行纠偏,但当Di的上下文信息不足时,仍无法完全克服先入为主的偏见产生的影响.例如,在图2给出的样例中,黑色顶点表示在图中运行RR算法之后,每个实体指称项的候选实体集合中相关度最高的顶点.其中,候选实体BuffaloBulls(Buffalo大学橄榄球队)虽然是实体指称项Buffalo的候选实体集合中具有最高相关度的顶点,但实际上正确的链接对象应为BuffaloBills(美国职业橄榄球队).经过分析,导致这种情况出现的原因是二者的概念相近,因此在同一上下文环境下与相关实体的关联关系也相近,导致RR算法对二者的区分度不高,为此本文进一步考虑从候选实体与文本Di的语义相关性的角度对链接对象做进一步区分.
2.3.2计算候选实体的语义相关性
候选实体(顶点)va的语义相关性是指va与给定文本Di在语义上相关的强度.由于图G仅由候选实体构成,因此本文采用Di中的每个实体指称项对应的候选集合中相关度最高的候选实体构成子集来表示文本Di,该子集简记为NmaxR.定义候选实体顶点va与给定文档Di的语义相关性如下:
(8)
其中,wa k表示图G中边(va, vk)的权重.如2.3.1节所述,CCEL算法引入候选实体的语义相关性定义的目的是帮助解决RR算法对某些概念相近的候选实体的区分度不高的问题,由式(8)可见,SR(va,Di)实际上是NmaxR集合中所有候选实体(顶点)vk的相关度的加权和,权重因子wa k为实体(顶点)va和vk之间边(va, vk)的权重.由2.2.2节可知,va和vk的语义关联越少,则权重值越低.
仍然以图2中的指称项Buffalo为例,尽管干扰项BuffaloBulls在相关度计算中获得了较高的值,但由于该实体与Di在语义上的关联强度弱于另一个(正确的)候选项BuffaloBills,因此在引入语义相关性计算之后,可以提高对这2个概念上相近的实体的区分度,从而实现正确的实体链接.
2.3.3语义一致性判据与实体链接
考虑如何将候选实体的相关度和语义相关性结合起来得到一个实体链接的标准,本文提出语义一致性判据:
(9)
其中,vs k是图G中与候选实体ns k相应的顶点,Vi s表示由实体指称项mi s的所有候选实体所构成的顶点集合.由式(9)可知,SCC判据的取值范围是(0,1),SCC值越大,表明候选实体ns k的语义一致性越高.由此可以得到实体链接的判据如下:
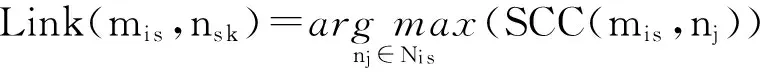
(10)
其中,Ni s表示由实体指称项mi s的所有候选实体所构成的集合.式(10)的含义为,将文本Di中的实体指称项mi s链接到本地知识库中具有最高SCC值的候选实体ns k之上.
2.3.4语义一致性判据的有效性
在2.3.1和2.3.2节的方法介绍过程中,我们多次引用了样例1的实验结果,但并未给出具体的数值计算结果.本节以样例1中的实体指称项Buffalo和Miami为例,用具体的数据辅助说明所提出的CCEL算法的设计依据,并初步验证本文提出的SCC判据的有效性.已知实体指称项Buffalo应链接到本地知识库中的BuffaloBills对象上(美国职业橄榄球队),实体指称项Miami应链接到本地的MiamiHurricanes对象上(美国职业橄榄球队),经归一化处理后的计算结果如表2所示:
Table2TheRelevanceandSemanticConsistencyofCandidateinExample1
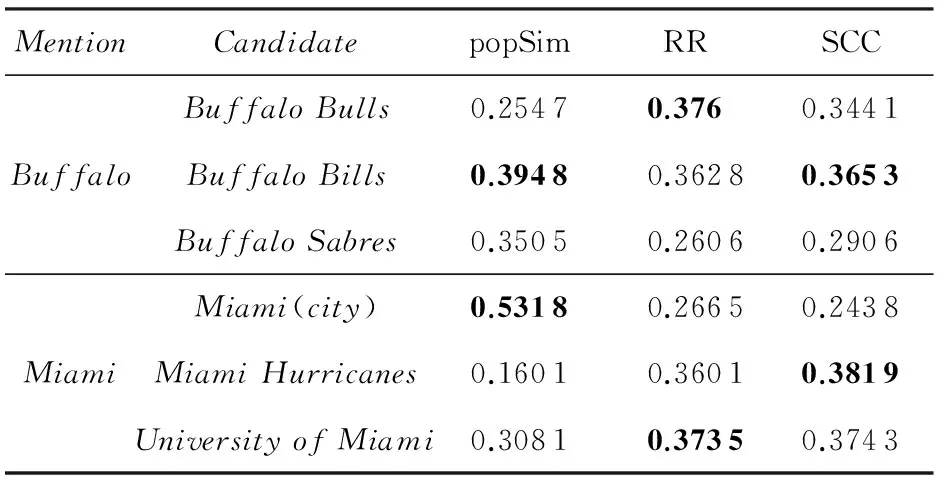
表2 样例1中候选实体的相关度与语义一致性
表2的第3列给出的是以实体流行度为测度的实体相关图中顶点的先验置信度(PCL),可以看出,如果仅参照流行度指标,Buffalo可实现正确链接,而Miami则会被链接到更为流行的Miami(city) 对象上.表2的第4列给出了经过RR算法修正的候选实体相关度计算结果,可以看出经过修正后的结果极差变小,特别是对于Miami的候选实体而言,正确的链接对象MiamiHurricanes的相关度得到了显著提升,该结果表明本文提出的相关度排序算法能够利用实体相关图拓扑结构中包含的实体关联信息,对实体先验置信度进行平滑修正,且修正的结果有利于降低干扰项的影响程度.同时也可以看出,单纯使用实体相关度作为链接判据并不可行,原因是RR算法对实体相关度的平滑效应会导致噪音放大,对实体链接的准确性造成干扰.因此有必要引入新的信息辅助判断.
表2的最后一列给出的是按照式(9)计算得到的语义一致性判据,可见根据该判据能够有效识别出正确的候选实体.进一步对比各候选实体的RR值与SCC值,可以看出单凭候选实体的语义相关性(SR=SCC-RR)无法实现准确链接,由此进一步证明了本文提出的语义一致性判据的有效性.
3 实验结果分析
3.1实验数据
为充分检验所提出的基于语义一致性的集成实体链接算法的有效性,本文采用2组近期发布的公开测试语料进行测试,数据详情如表3所示:
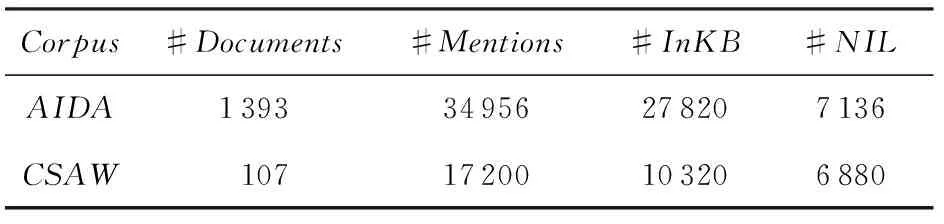
Table 3 Statistics of the Corpus表3 实验数据统计情况
第1组是由马克斯-普朗克研究所(MaxPlanckInstitute)的YAGO实验室发布的AIDA数据集*http://www.mpi-inf.mpg.de//yago-naga//aida//,该数据集包括一个训练集(train)和2个测试集(testA,testB),共1 393篇文档(平均长度为216个字符)和34 956个实体指称项(mentions).数据集中的所有实体指称项均通过人工标注,准确链接到了维基百科(即本地知识库)对应的实体对象上.其中在维基百科中存在对应实体对象的实体指称项共27 820个(称为InKB实体),在维基百科中无对应实体对象的实体指称项共7 136个(称为NIL实体)[19].
第2组数据集是由印度理工学院Chakrabarti教授领导的CSAW项目发布的Annotationdata(简称CSAW数据集)*https://www.cse.iitb.ac.in//~soumen//doc//CSAW//.该数据集中所有的实体指称项均被人工消歧,其中包含107篇文档(平均长度为623个字符)和17 200个实体指称项,InKB实体个数为10 320,NIL实体个数为6 880[10].CSAW数据主要用于验证CCEL算法在处理短文本实体链接任务时的性能,为便于与相关工作进行比较,我们采用文献[21]介绍的方法对CSAW数据进行了切分,使得每篇文档的长度不超过30个字符.
3.2实验方法与评估
为验证CCEL算法的有效性,本文从近年来的相关工作中选择了7个具有代表性的算法进行实验对比,相关算法的名称及简介请参见表4前7行,对相关算法细节的介绍和讨论请分别参见本文第1节和3.3.1节.除与相关工作进行比较外,本文还针对所提出的CCEL算法设计了4组对比实验(参见表4后4行),这4组实验用于讨论本文提出的实体相关图构造方法,候选实体(与输入文本)的语义相关性计算方法对于算法整体性能的影响以及进一步验证CCEL算法的有效性.

Table 4 Experimental Comparison Method表4 参与实验比较的实验方法一览
本文采用准确率(Precision)、召回率(Recall)和F1值等指标对算法性能进行评估.其中,准确率的含义是正确链接的实体数量占算法输出的链接总数的百分比,即算法的精确性;召回率的含义是正确链接的实体数量占测试集中已知事实总数的百分比,即算法的查全率.F1值的定义如下:
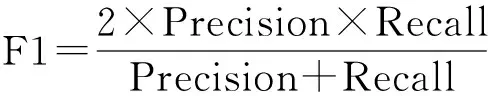
(11)
F1值受准确率和召回率的共同影响,当二者均趋近于1时,F1值也趋近于最大值1.F1值越大,说明算法执行实体链接任务的综合性能越好.
在统计实验结果时,仅考虑InKB实体指称项,以便与相关工作保持一致[10,11,18-19,23].对于mi s所指代的实体对象不在本地知识库中(即mi s为NIL实体)的情况,CCEL算法的处理方式如下:1)若实体指称项mi s的候选实体集合为空集,则判定其为NIL实体;2)若mi s与所有候选实体的语义一致性均低于预设的阈值λ,则判定其为NIL实体.
CCEL算法中包含2个经验参数:用于限定候选实体集合大小的阈值δ(定义参见2.1节)和用于判定实体指称项是否对应于NIL实体的阈值λ.为确定这2个参数,采用AIDA数据集中的testA作为参数验证数据集(其中包含216篇文档共4 791个实体指称项),得到CCEL算法的F1值与δ和λ的关系分别如图3和图4所示.由图3可见,当δ=6时CCEL算法的F1值最优,δ=5时的表现与之相当,考虑到算法的计算效率,本文取δ=5.由图4可见,当λ≤0.2时,CCEL算法的F1值最优,之后随λ增大而快速下降,因此本文取λ=0.2.
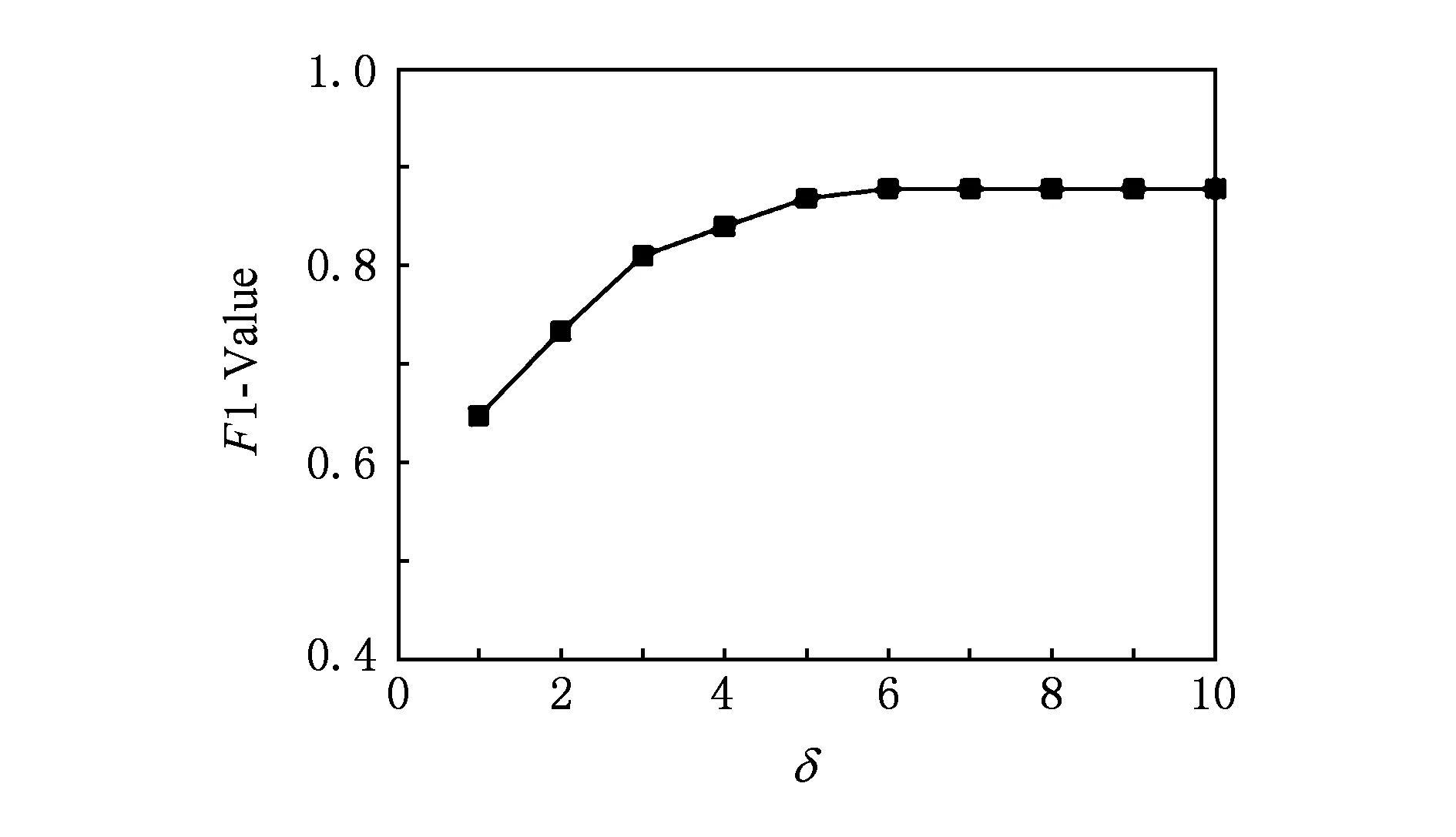
Fig. 3 F1-value under different δ on train corpus.图3 参数δ的取值对算法性能的影响
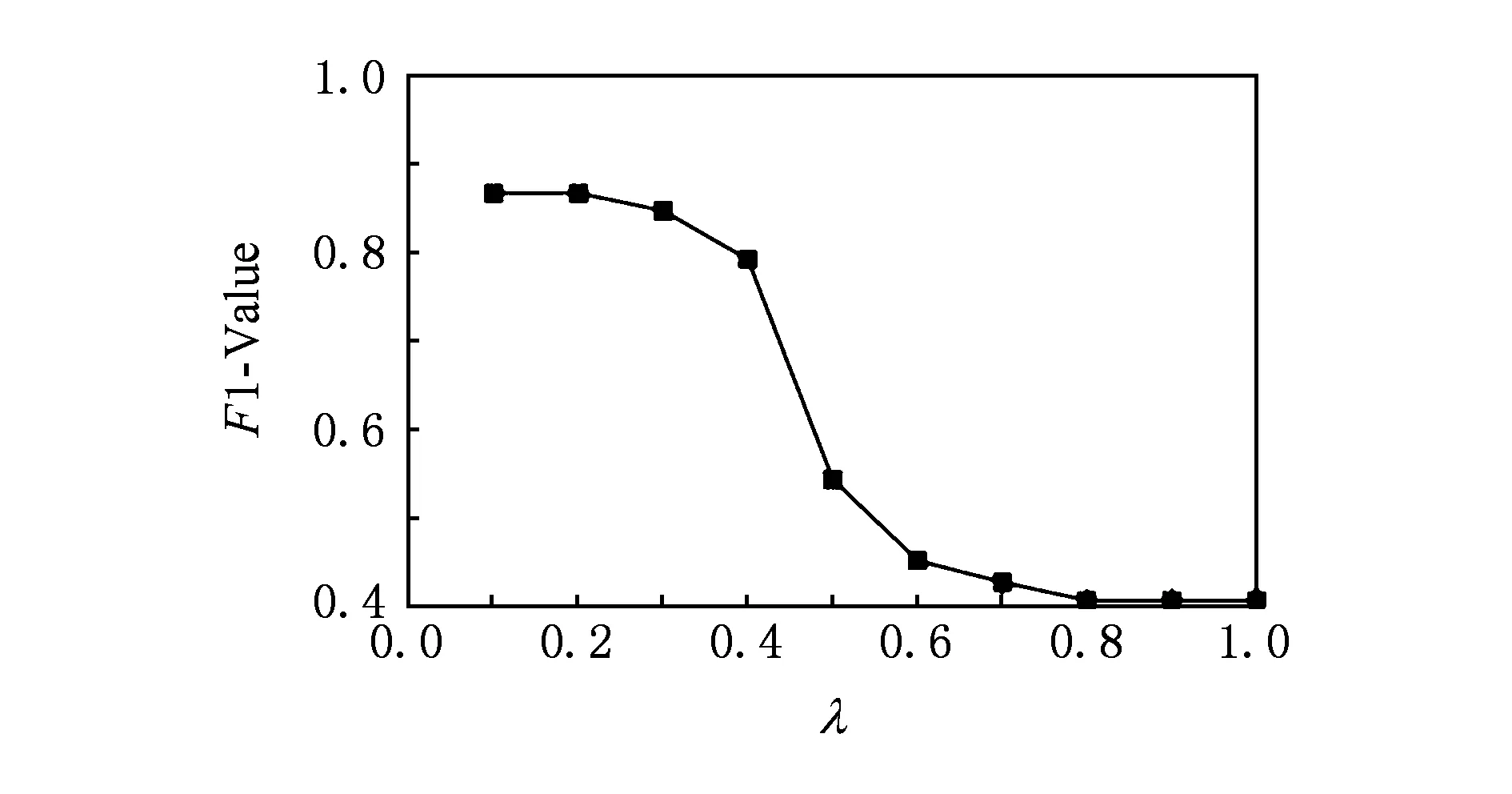
Fig. 4 F1-value under different λ on train corpus.图4 F1值与参数λ在训练集上的关系
3.3实验结果与讨论
3.3.1CCEL算法的有效性验证
为验证CCEL算法的有效性,首先与相关工作进行横向比较.实验分为3组:第1组在AIDA数据集进行测试,参与性能比较的算法主要是Baseline(以先验置信度作为判据进行实体链接,选择先验置信度最大的候选实体作为链接对象),实体结果如表5所示;第2组同样是在AIDA数据集上进行测试,参与性能比较的算法主要是当前在该数据集上性能表现最好的Alhelbawy算法和其他4种综合性能表现较好的算法,实验结果如表6所示;第3组在CSAW数据集上测试,目的是客观评价CCEL算法在处理短文本实体链接任务时的性能,参与比较的工作主要是在短文本实体链接中性能表现最好的Tagme算法,和其他3种在该数据集上性能表现最好的算法,实验结果如表7所示,其中,Han,Kulkarni和Tagme等算法的实验结果引自原文,Alhelbawy
Table5ExperimentalResultonAIDAwithBaseline
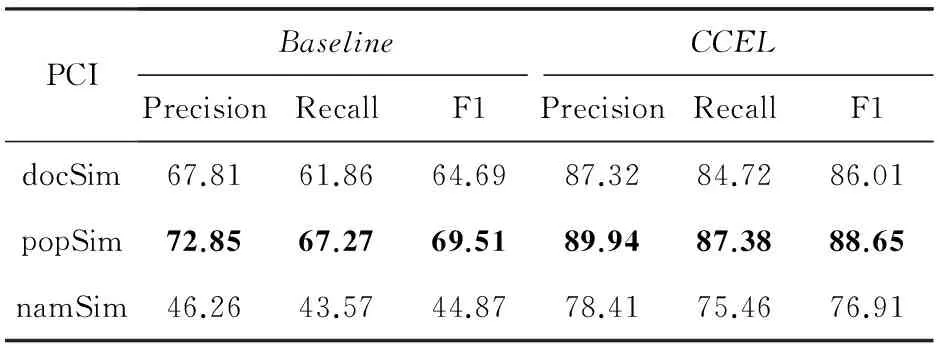
表5 CCEL与Baseline在AIDA数据集上的实验结果 %
Table6ExperimentalResultonAIDA
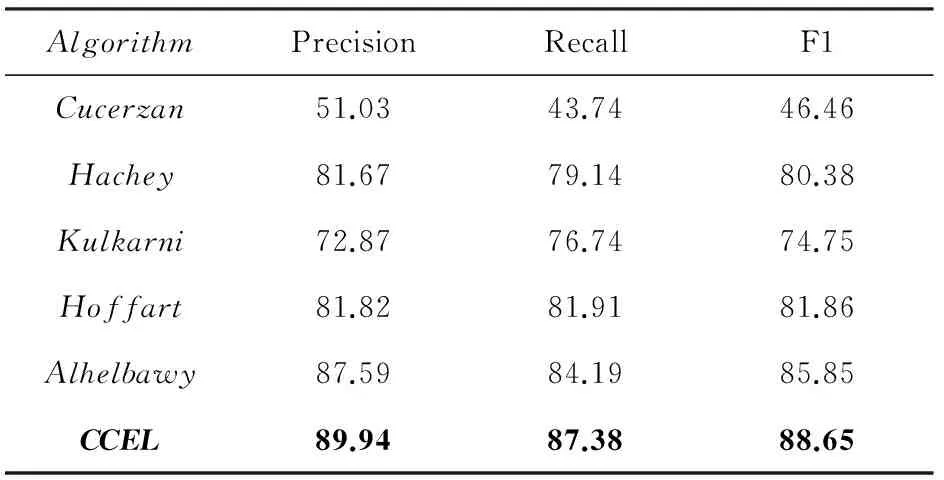
表6 CCEL与相关算法在AIDA数据集上的实验结果 %
Table7ExperimentalResultonCSAW
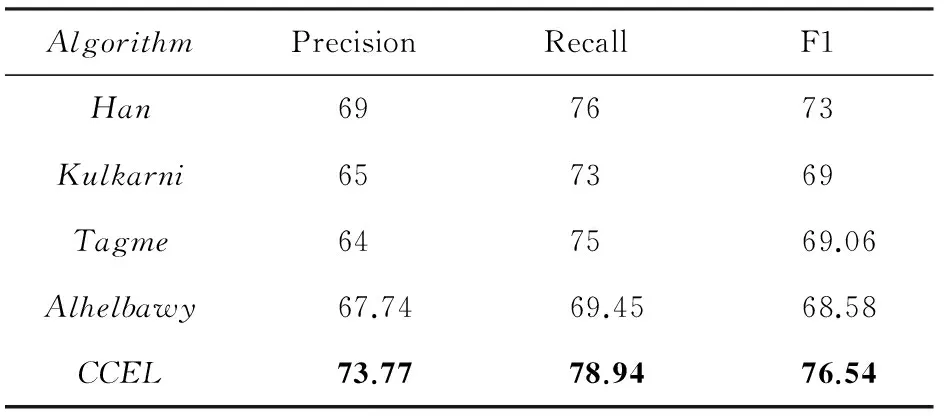
表7 CCEL与相关算法在CSAW数据集上的实验结果 %
算法的实验结果来自对原文方法的重现,由于该算法采用实体流行度作为初始置信度的实验结果最优,所以本文在重现实验时采用实体流行度作为候选节点的初始置信度.
从表5可以看出,以实体流行度作为初始置信度的CCEL算法性能表现最优,F1值达到88.85%,在Baseline方法中,以实体流行度(popSim)作为判据的链接算法性能表现最佳,F1值为69.51%.该结果表明,以先验置信度作为判据的实体链接算法并不能有效地解决实体链接问题,而且对于不同的数据集,该类算法的性能表现会有较大的差异性.而本文提出的CCEL算法通过融合实体间的语义相关度,可以有效地克服前者的不足,大幅度地提升实体链接的性能,与Baseline中表现最好的popSim算法相比,本文提出的以namSim,docSim,popSim作为PCL值的CCEL算法的F1值分别提高了10.64%,23.73%,27.53%.由于以实体流行度作为先验置信度的CCEL算法性能表现最佳,所以在本文下述实验部分,CCEL算法均以实体流行度作为先验置信度.
从表6可以看出,CCEL算法在所有性能指标上的表现均优于相关工作.与基于PageRank的集成实体链接算法Alhelbawy和Hachey相比,CCEL算法在AIDA测试集上的F1值分别提高了3.26%和10.29%.该结果表明,通过引入候选实体与输入文本的语义相关性,可以提高对概念上相近的实体的区分度,克服其中错误候选实体所产生的噪音影响,从而实现正确的实体链接.
与采用谷歌距离作为实体语义相关性测度构造实体相关图的算法Hoffart和利用实体维基页面间的超链接指向关系构造实体相关图的算法Kulkarni相比,CCEL算法在AIDA测试集上的F1值分别提高了8.29%和18.60%,该结果表明,通过对实体间的直接和间接语义关系进行区分,能够在确保实体关系完整性的同时,进一步修正实体间相关性的强度,从而显著提高实体链接准确率.
与基于上下文相似度的Cucerzan算法相比,CCEL算法在AIDA测试集上的F1值提高了90.91%,该结果表明,基于语义一致性的CCEL算法能够充分利用知识库中已有的知识结构,推理出实体间的语义相关性,从而有效弥补了基于上下文相似性的实体链接算法受到上下文信息完整性制约的缺陷,大幅度地提升了实体链接的准确性.
从表7可以看出,CCEL算法在CSAW测试集上的所有性能指标同样一致地优于相关工作.与基于图的算法Kulkarni,Alhelbawy及基于随机游走模型的算法Han相比,CCEL算法在CSAW测试集上的F1值分别提高了10.92%,11.61%和4.85%,该结果表明CCEL算法能够有效解决现有集成链接方法在处理短文本时,由于上下文信息不足而导致的算法性能恶化问题,因此CCEL算法具有良好的适应性和推广性.
与相关工作中对短文本性能表现最优的Tagme算法相比,CCEL算法在CSAW测试集上的准确率和召回率分别提高了15.27%和5.25%.通过对Tagme的性能进行分析,我们发现问题的主要原因在于Tagme过度依赖于实体流行度和候选实体间相关性的计算准确性,当两者之一出现偏差时,算法的性能会恶化.例如,对于引言中提到的样例1,由于受实体流行度计算结果的影响,Tagme算法会将实体指称项Miami错误地链接到其最知名的候选实体Miami(city),而非实际所指对象MiamiHurricanes.以上结果表明,CCEL算法通过在语义一致性算法中对实体相关度和实体流行度等信息进行综合考量,从而避免了对局部信息的过分倚重,显著提高了算法的整体性能.该实验结果同时也为证明本文提出的实体相关图构造方法和候选实体(与输入文本)的语义相关性计算方法的有效性提供了有力证据.
为进一步评估本文提出的实体相关图构造方法和候选实体的语义相关性计算方法的有效性,本文将CCEL算法与3种基准实验方法(表4中的DWR,NGD和NoSR)进行比较,实验结果如表8所示:
Table8ExperimentalResultonAIDAandCSAW
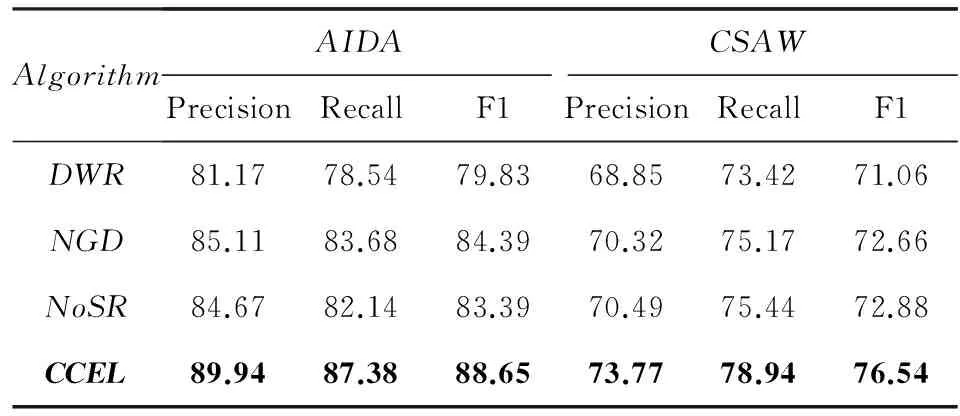
表8 CCEL与相关算法在公开数据集上的实验结果 %
从表8可以看出,CCEL算法在AIDA测试集和CSAW测试集上的所有性能指标均优于参与比较的实验方法.与DWR和NGD算法相比,CCEL算法在AIDA测试集上的F1值分别提高了11.05%和5.05%,在CSAW测试集上的F1值分别提高了7.71%和5.34%.该实验结果表明,通过充分利用知识库的结构化语义关系(直接语义关系和间接语义关系)并且融合当前主流相关性计算方法的实体相关图构造方法(参见本文2.2.2节),能够在一定程度上弥补因实体相关图不完整或实体相关性不准确对实体链接算法所造成的负面影响,从而提高实体链接算法的准确率.与NoSR算法相比,CCEL算法在AIDA测试集和CSAW测试集上的F1值分别提高了6.31%和5.02%.该实验结果表明,通过引入候选实体与输入文本的语义相关性,能够对NoSR的实验结果进一步修正,降低噪音影响,提高算法对概念上相近的实体的区分度,从而实现正确的链接.
3.3.2CCEL算法的错误分析
为了客观评价CCEL算法的性能,我们对CCEL算法输出结果中发生错误实体链接的部分进行了统计和人工分析,归纳出3种出错的场景.
错误Ⅰ. 若实体指称项mi s所对应的正确候选不在本地知识库中,CCEL将选择与mi s具有最大语义一致性的候选实体作为链接对象(前提是SCC的计算结果超过阈值λ).例如,对于文本“IjazAhmedisaretiredPakistanicrickter….”,由于指称项Ijaz所指的实体对象IjazAhmed(cricketer)不在本地知识库中,且它与候选实体IjazAhmed(wushu)具有较强的语义一致性,导致CCEL将后者视为正确的链接目标.此类错误是当前实体链接研究工作面临的共性问题,也是本文下一步工作拟重点研究解决的问题之一.
错误Ⅱ. 由于本地知识库知识的不完整(如部分实体间的关系缺失)而导致的实体链接错误.例如对于测试集中的文本“TianLiangandZhangLianghaveparticipatedintheprogram….”,由于文中的实体指称项ZhangLiang所指的实际实体对象ZhangLiang(model)与文中的实体指称项TianLiang在本地知识库中的候选实体之间不存在任何直接和间接的关联关系,导致CCEL算法错误地将实体指称项ZhangLiang链接到了具有实体流行度的实体对象ZhangLiang(westernhan)上.由于这种错误受到SCC计算结果的制约,因此出错的概率较低,在当前算法版本中对这种情况并未做专门考虑,在下一步工作中,我们将对该问题进行深入研究.
错误Ⅲ. 若候选集合中有多个候选实体与正确候选具有相同的上下文相似度,CCEL算法从中随机选择前5个候选实体时(即阈值δ=5),有可能遗漏正确的候选实体.例如,对于文本“MichaelJordanwonhisSecondMVPawardafter….”,由于实体指称项MVP对应的候选集合中,有多个候选实体与正确的候选实体(mostvaluableplayer)具有相同的上下文相似度,例如MVP(TVshow),MVP(song),MVP(album),MVP(group),和MontelVontaviousPorter,从而可能导致正确的候选实体被漏选.此类错误是由于CCEL算法的设计方式导致的,可以通过调整随机筛选的策略进行修正(如提高阈值δ),但综合考虑到算法的计算效率和准确率,本文阈值取δ=5作为筛选标准.
4 结束语
本文研究了知识图谱上的实体链接问题,发现了现有集成实体链接方法的不足,并提出一种基于语义一致性的集成实体链接算法CCEL.该算法充分利用了知识库中的结构化语义关系(直接语义关系和间接语义关系),提高了算法对概念上相近的实体的区分度.实验表明,CCEL算法在AIDA和CSAW等公开数据集的性能表现一致且优于本领域的代表性工作.
论文的主要贡献包括3个方面:1)通过实验证明了本文提出的基于语义一致性的集成实体链接算法在性能上一致优于当前主流的集成链接方法,且具有较好的适应性和扩展性;2)实验表明了本文提出的实体相关图构造方法通过充分利用知识库知识,能够在一定程度上弥补因实体相关图不完整或者实体相关性不准确对实体链接算法所造成的负面影响;3)实验表明了本文提出的语义相关性(候选实体与输入文本)计算方法能够降低错误候选所产生的噪音影响,提高算法对概念上相近的实体的区分度,达成精确的实体链接.
针对CCEL算法产生错误的原因,我们后续的工作将主要围绕2个方面展开:1)改进候选实体生成方法,将实体指称项和候选实体的类别信息考虑进来,以提高候选实体召回率和算法的执行效率;2)继续丰富完善本地知识库的规模和知识结构,以进一步提高实体链接操作的准确率.
[1]HeathT,MottaE.Easeofinteractionpluseaseofintegration:CombiningWeb2.0andtheSemanticWebinareviewingsite[J].WebSemantics:Science,ServicesandAgentsontheWorldWideWeb, 2008, 6(1): 76-83
[2]DongXinLuna,GabrilovichE,HeitzG,etal.Knowledgevault:AWeb-scaleapproachtoprobabilisticknowledgefusion[C] //Procofthe20thIntConfonKnowledgeDiscoveryandDataMining(KDD’14).NewYork:ACM, 2014: 601-610
[3]JiHeng,RalphG.Knowledgebasepopulation:Successfulapproachesandchallenges[C] //Procofthe49thAnnualMeetingoftheAssociationforComputationalLinguistics:HumanLanguageTechnologies(ACL’11).Stroudsburg,PA:ACL, 2011: 1148-1158
[4]HuaiBaoxing,BaoTengfei,ZhuHengshu,etal.Topicmodelingapproachtonamedentitylinking[J].JournalofSoftware, 2014, 9(14): 2076-2087 (inChinese)
(怀宝兴, 宝腾飞, 祝恒书. 一种基于概率主题模型的命名实体链接方法[J]. 软件学报, 2014, 9(14): 2076-2087)
[5]MarkD,PaulM,RaoD,etal.Entitydisambiguationforknowledgebasepopulation[C] //Procofthe23rdIntConfonComputationalLinguistic(COLING’10).Stroudsburg,PA:ACL, 2010: 277-285
[6]GuoZhaochen,BarbosaD.Robustentitylinkingviarandomwalks[C] //Procofthe23rdIntConfonInformationandKnowledgeManagement(CIKM’14).NewYork:ACM, 2014: 499-508
[7]DaiHongjie,WuChiyang,TsaiR,etal.Fromentityrecognitiontoentitylinking:Asurveyofadvancedentitylinkingtechniques[C] //Procofthe26thAnnualConfoftheJapaneseSocietyforArtificialIntelligence.Berlin:Springer, 2012: 1-10
[8]BunescuR,PascaM.Usingencyclopedicknowledgefornamedentitydisambiguation[C] //Procofthe11thConfoftheEuropeanChapteroftheAssociationforComputationalLinguistics(EACL’06).Stroudsburg,PA:ACL, 2006:9-16
[9]CucerzanS.Large-scalenamedentitydisambiguationbasedonWikipediadata[C] //Procof2007JointConfonEmpiricalMethodsinNaturalLanguageProcessingandComputationalNaturalLanguageLearning(EMNLP’07).Stroudsburg,PA:ACL, 2007: 708-716
[10]KulkarniS,SinghA,RamakrishnanG,etal.CollectiveannotationofWikipediaentitiesinWebtext[C] //Procofthe15thIntConfonKnowledgeDiscoveryandDataMining(KDD’09).NewYork:ACM, 2009: 457-466
[11]HanXianpei,SunLe,ZhaoJun.CollectiveentitylinkinginWebtext:Agraph-basedmethod[C] //Procofthe34thIntConfonResearchandDevelopmentinInformationRetrieval(SIGIR’11).NewYork:ACM, 2011: 765-774
[12]NguyenHT,CaoTH.ExploringWikipediaandtextfeaturesfornamedentitydisambiguation[C] //Procofthe2ndIntConfIntelligentInformationandDatabaseSystems.Berlin:Springer, 2010: 24-26
[13]ZengYi,WangDongsheng,ZhangTielin,etal.LinkingentitiesinshorttextsbasedonaChinesesemanticknowledgebase[C] //Procofthe2ndCCFConfonNaturalLanguageProcessingandChineseComputing.HongKong:Springer, 2013: 266-276
[14]ZhangTao,LiuKang,ZhaoJun.Agraph-basedsimilaritymeasurebetweenWikipediaconceptsanditsapplicationinentitylinkingsystem[J].JournalofChineseInformationProcessing, 2015, 29(2): 58-67 (inChinese)
(张涛, 刘康, 赵军. 一种基于图模型的维基概念相似度计算方法及其在实体链接系统中的应用[J]. 中文信息学报, 2015, 29(2): 58-67)
[15]GentileAL,ZhangZiqi,XiaLei,etal.Semanticsrelatednessapproachfornamedentitydisambiguation[C] //Procofthe6thItalianResearchConfonDigitalLibraries.Berlin:Springer, 2010:137-148
[16]ZuoZhe,GjergjiK,ToniG,etal.BEL:Baggingforentitylinking[C] //Procofthe25thIntConfonComputationalLinguistics:TechnicalPapers(COLING’14).Stroudsburg,PA:ACL, 2014: 2075-2086
[17]GregD,DanK.Ajointmodelforentityanalysis:Coreference,typing,andlinking[J] //TransoftheAssociationforComputationalLinguistics. 2014, 2(1): 477-490
[18]HacheyB,RadfordW,CurranJR.Graph-basednamedentitylinkingwithWikipedia[C] //ProcofIntConfonWebInformationSystemEngineering.Berlin:Springer, 2011: 213-226
[19]HoffartJ,MohamedAY,BordinoI,etal.Robustdisambiguationofnamedentitiesintext[C] //ProcoftheConfonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP’11).Stroudsburg,PA:ACL, 2011: 782-792
[20]GuoYuhang,QinBin,LiuTing,etal.Microblogentitylinkingbyleveragingextraposts[C] //Procofthe2013ConfonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP’13).Stroudsburg,PA:ACL, 2013: 863-868
[21]FerraginaP,ScaiellaU.Tagme:On-the-flyannotationofshorttextfragments(byWikipediaentities) [C] //Procofthe19thIntConfonInformationandKnowledgeManagement(CIKM’10).NewYork:ACM, 2010: 1625-1628
[22]ShenWei,WangJianyong,LuoPing,etal.Linkingnamedentitieswithknowledgebaseviasemanticknowledge[C] //Procofthe21stAnnualConfonWorldWideWeb(WWW’12).NewYork:ACM, 2012: 449-458
[23]AlhelbawyA,RobertG.Collectivenamedentitydisambiguationusinggraphrankingandcliquepartitioningapproaches[C] //Procofthe25thIntConfonComputationalLinguistics(COLING’14).Stroudsburg,PA:ACL, 2014: 1544-1555
[24]WittenI,MilneD.Aneffective,low-costmeasureofsemanticrelatednessobtainedfromWikipedialinks[C] //ProcofAAAIWorkshoponWikipediaandArtificialIntelligence:AnEvolvingSynergy(AAAI’08).MenloPark,CA:AAAI, 2008: 25-30
[25]HuangHongzhao,LarryH,JiHeng.Leveragingdeepneuralnetworksandknowledgegraphsforentitydisambiguation[DB//OL].Ithaca:ArXiv, [2015-04-28].http://arxiv.org//pdf//1504.07678v1.pdf

LiuQiao,bornin1974.PhDandassociateprofessor.MemberofChinaComputerFederation.Hismainresearchinterestsincludemachinelearninganddatamining,naturallanguageprocessing,andsocialnetworkanalysis.

ZhongYun,bornin1990.Master.StudentmemberofChinaComputerFederation.Hismainresearchinterestsincludenaturallanguageprocessing(NLP)andmachinelearning(zhongyunuestc@gmail.com).

LiuYao,bornin1978.PhDandlecturer.MemberofChinaComputerFederation.Hermainresearchinterestsincludesocialnetworkanalysis,machinelearning,datamining,andnetworkmeasurement(liuyao@uestc.edu.cn).

WuZufeng,bornin1978.PhDandengineer.MemberofChinaComputerFederation.Hismainresearchinterestsincludemachinelearning,datamining,andinformationsecurity(wuzufeng@uestc.edu.cn).

QinZhiguang,bornin1956.PhDandprofessor.SeniorMemberofChinaComputerFederation.Hismainresearchinterestsincludeinformationsecurity,socialnetworkanalysis,andmobilecomputing(qinzg@uestc.edu.cn).
ConsistentCollectiveEntityLinkingAlgorithm
LiuQiao,ZhongYun,LiuYao,WuZufeng,andQinZhiguang
(School of Information and Software Engineering, University of Electronic Science and Technology of China, Chengdu 610054)
Thegoalofentitylinkingistolinkentitymentionsinthedocumenttotheircorrespondingentityinaknowledgebase.Theprevalentapproachescanbedividedintotwocategories:thesimilarity-basedapproachesandthegraph-basedcollectiveapproaches.Eachofthemhassomeprosandcons.Thesimilarity-basedapproachesaregoodatdistinguishentitiesfromthesemanticperspective,butusuallysufferfromthedisadvantageofignoringrelationshipbetweenentities;whilethegraph-basedapproachescanmakebetteruseoftherelationbetweenentities,butusuallysufferfrombaddiscriminationonsimilarentities.Inthiswork,wepresentaconsistentcollectiveentitylinkingalgorithmthatcantakefulladvantageofthestructuredrelationshipbetweenentitiescontainedintheknowledgebase,toimprovethediscriminationcapabilityoftheproposedalgorithmonsimilarentities.Weextensivelyevaluatetheperformanceofourmethodontwopublicdatasets,andtheexperimentalresultsshowthatourmethodcanbeeffectiveatpromotingtheprecisionandrecalloftheentitylinkingresults.Theoverallperformanceoftheproposedalgorithmsignificantlyoutperformotherstate-of-the-artalgorithms.
collectiveentitylinking;informationretrieval;knowledgebasepopulation;personalizedPageRank;semanticcorrelation
2016-03-21;
2016-05-26
国家自然科学基金项目(61133016,61272527,61202445);国家自然科学基金青年项目(61502087);中央高校基本科研业务费专项资金项目(ZYGX2014J066)
TP391
ThisworkwassupportedbytheNationalNaturalScienceFoundationofChina(61133016, 61272527, 61202445),theNationalNaturalScienceFoundationforYoungScholarofChina(61502087),andtheFundamentalResearchFundsfortheCentralUniversities(ZYGX2014J066).
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
制造技术与机床(2019年6期)2019-06-25
计算机应用(2018年5期)2018-07-25
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
轴承(2015年2期)2015-07-25
