
HD-SIS超高维数据稳健变量筛选
2016-08-01 06:13张景肖李向杰郭海明
统计与信息论坛 2016年4期
关键词:稳健性
张景肖,李向杰,郭海明
(1.中国人民大学 a.应用统计科学研究中心,b.统计学院,北京 100872;2.常州大学 商学院, 江苏 常州 213164)
HD-SIS超高维数据稳健变量筛选
张景肖1a,1b,李向杰1a,1b,郭海明2
(1.中国人民大学 a.应用统计科学研究中心,b.统计学院,北京 100872;2.常州大学 商学院, 江苏 常州 213164)
摘要:超高维变量筛选是统计研究的重要问题。提出一种新的变量筛选方法HD-SIS,该方法不需要模型假设,并且对异常值有很强的抵抗能力,具有很好的稳健性。在Monte Carlo模拟中,对5种方法进行了比较,即确保独立筛选法、确保独立秩筛选法、稳健秩相关系数筛选法、距离确保独立筛选法和鞅差相关系数确保独立筛选法。模拟结果显示HD-SIS有更优良的表现。
关键词:超高维数据;稳健性;模型释放;变量筛选
一、引言
超高维数据分析是现代统计学研究的热点和难点,主要由于超高维数据的样本量远小于变量个数。为此,Fan等基于Pearson相关系数提出确保独立筛选法(Sure Independence Screening,SIS)解决这一问题[1]。但是,SIS也存在一些问题,如:不能发现非线性关系,对于异常值比较敏感。为此,很多学者进行了进一步的研究,例如:Hall等提出利用广义经验相关系数进行超高维变量筛选[2],但其对异常值较敏感;Fan等利用边际回归研究了非线性模型的变量筛选[3];Fan等利用边际回归研究了广义线性模型的变量筛选[4],而这两种方法需要具体的模型假设,当模型假设错误时就会造成较大的筛选误差;Zhu等提出确保独立秩筛选法(Sure Independent Ranking and Screening,SIRS),研究了模型释放的超高维数据变量筛选[5];Li等基于Kendall相关系数提出稳健秩相关系数筛选法(Robust Rank Correlation Screening,RRCS)[6];Li等基于距离相关系数提出距离确保独立筛选法(Distance Correlation Sure Independence Screening,DC-SIS)[7];Shao等基于鞅差相关系数提出鞅差相关系数确保独立筛选法(Martingale Difference Correlation Sure Independence Screening,MDC-SIS)[8];Fan等利用边际回归和样条展开技术研究可加模型和变系数模型的超高维变量筛选[9-10];Liu等基于条件相关系数研究超高维变系数模型变量筛选[11];马学俊提出组确保独立筛选法[12],该方法是SIS和边际回归的延拓,它可以解决组变量的变量筛选问题。
本文主要研究模型释放的超高维变量筛选方法。所谓模型释放是指不需要对模型进行假设,但是这并不意味着它能适合所有统计模型。关于模型释放的研究主要有RRCS、SIRS、DC-SIS和MDC-SIS等,其中RRCS 利用的是Kendall tau相关系数,该方法只利用自变量和因变量的联合排序信息,而没有利用它们各自的排序信息。另外,RRCS中的单调相关性条件比较强。SIRS主要利用因变量秩的信息将其转换成为多个虚拟变量(Dummy Variable),然后计算这些虚拟变量与自变量的Pearson相关系数,最后将这些相关系数的平方相加。但是,SIRS假设自变量通过其线性组合来影响因变量,这个线性假设比较强。DC-SIS和MDC-SIS分别是利用距离相关系数和鞅差相关系数筛选变量,而距离相关系数和鞅差相关系数对于异常值比较敏感,所以DC-SIS和MDC-SIS对于异常值不稳健。
在本文中,利用Hoeffding’s D统计量,给出了一种新的稳健模型释放筛选方法,即Hoeffding’s D确保独立筛选法,简称HD-SIS。它不仅可以发现非线性关系,还对异常值有一定抵抗力。与RRCS相比,HD-SIS不仅利用了自变量和因变量的秩的信息,也利用了它们组合秩的信息,从而利用信息更加充分。与SIRS相比,HD-SIS利用的是自变量的秩的信息,从而更加稳健。与DC-SIS和MDC-SIS相比,HD-SIS只是利用秩的信息,没有涉及到均值计算,从而更加稳健。
二、研究方法
(一)Hoeffding’s D
Hoeffding’s D是Hoeffding于1948年提出的[13]。令U和V是随机变量,它们的联合分布函数是F(u,v),边际分布分别是F(u,+∞)和F(+∞,v)。Hoeffding’s D统计量是衡量联合分布函数和边际分布函数乘积的差,即:
D(u,v)=F(u,v)-F(u,+∞)F(+∞,v)
从D的定义可以看出,两个随机变量独立的充要条件是D等于0。D的绝对值越大,变量越相关。
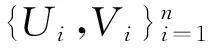
其中:

D的估计是:
其中:
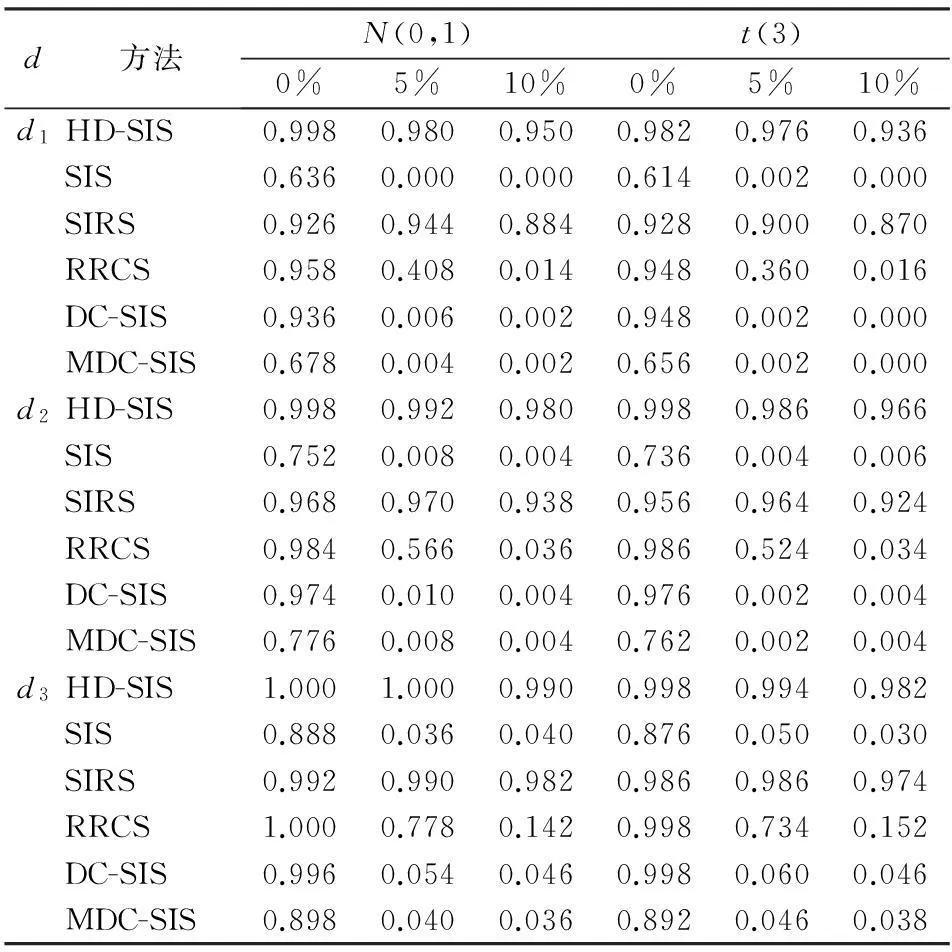
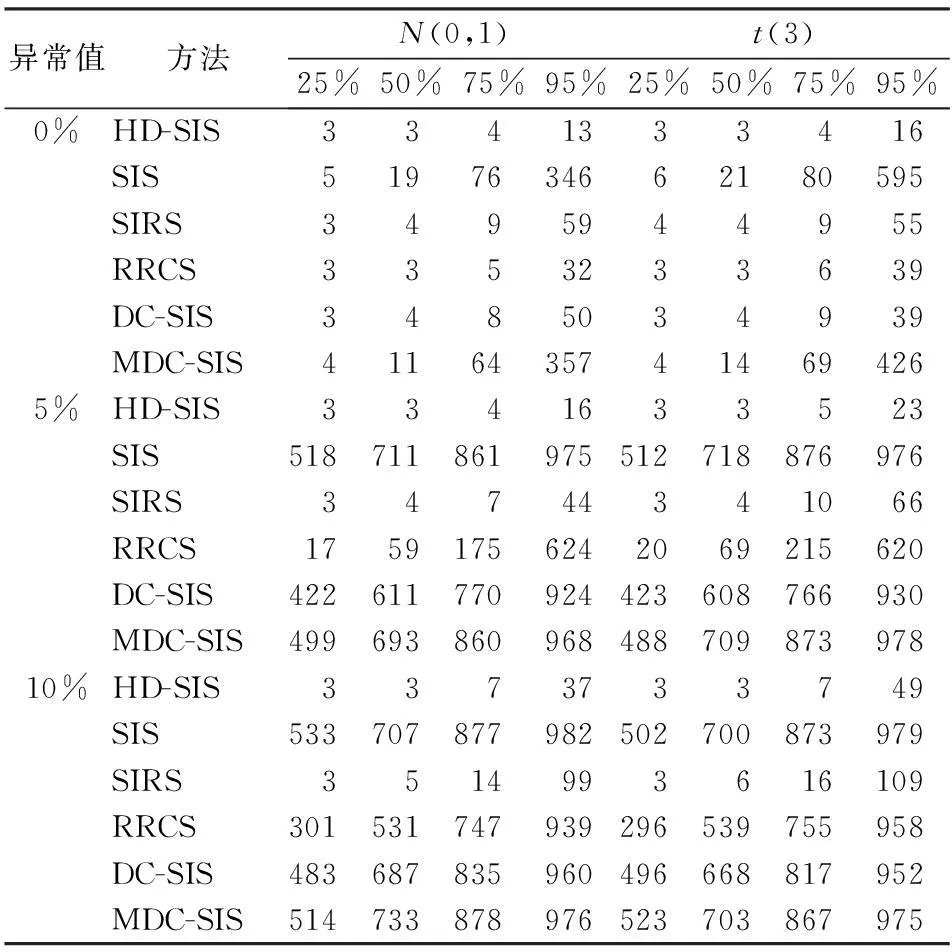
从上面公式可以看出,Ci是满足Ut (二)HD-SIS筛选方法 本文利用Hoeffding’s D对超高维数据进行变量筛选,即HD-SIS。Hoeffding’s D可以度量两个变量之间的关系,并且这种关系不仅可以是线性的,还可以是非线性的,所以HD-SIS不涉及具体模型假设,是一种模型释放的变量筛选方法。从D的估计可以看出,它利用数据的秩信息,从而对于异常值有一定的抵抗力,所以HD-SIS对异常值具有稳健性。综上两个原因,HD-SIS是稳健的模型释放方法。 设Y是因变量,X=(X1,X2,…,Xp)T是p维的自变量向量。HD-SIS是计算Y与每一个Xk(k=1,2,…,p)的Hoeffding’s D,即: wk=|D(Xk,Y)| 超高维变量筛选的目的是选择一个规模适中的子集,即: Μ={1≤k≤n:Xk对Y有影响} 对于HD-SIS,令这个子集的估计是: d的取法没有比较统一的方法。一般来说,d取[n/log(n)]或n-1。 三、Monte Carlo模拟 下面将进行Monte Carlo模拟,并且将提出的方法与目前已有的5种方法进行比较,即SIS、SIRS、RRCS、DC-SIS和MDC-SIS。考虑如下模型: Y=4X1(X1-1)+3X2+(3X3-1)2+ε其中X={X1,X2,…,Xp}′~N(0,I),I是p×p单位矩阵,误差项ε来自于标准正态分布N(0,1)和t(3)。 为了分析各种方法对异常值的影响,在X1随机添加自由度为1 000的卡方分布的0%,5%,10%的异常值。重复模拟500次。样本量n设置为200,自变量个数p为1 000。本文采用两种准则来评价方法的优劣:其一,r:给定d全部非零自变量被正确选出的比例,其中d1=[n/log(n)],d2=2d1和d3=n-1;其二,S:包含全部非零自变量的最小模型大小。 结果如表1和表2所示,SIS不能有效地识别非线性关系,并且对异常值比较敏感。因为不同d的r比较小,75%和95%的S比较大。RRCS、DC-SIS和MDC-SIS虽然是模型释放方法,但是对于该模拟表现不佳,其中DC-SIS和MDC-SIS对于异常值比较敏感。SIRS表现还可以,但仍不及HD-SIS。因为SIRS的95%的S是HD-SIS的2倍多。综上所述,HD-SIS表现最好,并且对异常值有很强的抵抗力。本文建议d取[n/log(n)],因为从表1可以看出,它可以保证至少93%的概率包含真实的模型。 表1 不同d的r模拟结果表 表2 S的25%、50%、75%和95%的模拟结果表 四、实例分析 下面将HD-SIS方法应用于实际数据分析,该数据是研究小鼠的基因对扩张心肌病的影响。这组数据由对30个小鼠的观测值构成,其中包含6 319个自变量(基因)和1个因变量。由于每个基因的观测值的量纲有所差别,所以在计算之前为了消除量纲的影响,需要对原始自变量进行标准化。经过简单的计算,发现有1 351个自变量存在数据点大于3倍的标准差,180个自变量存在数据点大于4倍的标准差。由于自变量个数太多,很难一一对它们的描述统计分析结果给出展示。本文通过对数据进行标准化处理,将30行6 319列的数据矩阵拉直成为一个189 570行1列数据向量进行描述,其最小值是-5.241,最大值是 5.057。从图1可以看出,数据存在大量的异常值。 图1 数据向量的箱线图 由于数据的维度(基因个数)p远远大于样本量n,所以研究该实例的目的是试图找出哪一个基因或者哪一些基因对G蛋白偶联受体的影响较大,Segal等基于微阵列分析方法得到了影响最大的前几个基因[15]。Li R等用DC-SIS方法也得到了影响最大的前几个基因[7],结果见表3。 表3 不同方法对心肌病数据研究的结果表 表3给出了不同方法对心肌病数据研究的结果。从表3中可以看出,对于基因Msa.2877.0和基因Msa.2134.0都可以很好地被选择出来,并且HD-SIS方法和DC-SIS方法筛选出的结果也有很多重合,Li R等已经论证了DC-SIS的合理性,这也就验证了HD-SIS的合理性。 五、结论 本文基于Hoeffding’s D统计量提出了一种新的稳健的模型释放变量筛选方法HD-SIS,该方法不需要对模型进行假设,并且对异常值有很强的抵抗性,相比SIS、SIRS、RRCS、DC-SIS和MDC-SIS,具有一定的优势。模拟结果显示HD-SIS优于上面的5种方法,根据Monte Carlo模拟的结果,我们建议d取[n/log(n)]。 参考文献: [1]Fan J,Lv J.Sure Independence Screening for Ultrahigh Dimensional Feature Space[J].Journal of the Royal Statistical Society,Ser.B,2008,70(5). [2]Hall P,Miller H.Using Generalized Correlation to Effect Variable Selection in very High Dimensional Problems[J].Journal of Computational and Graphical Statistics,2009,18(3). [3]Fan J,Samworth R,Wu Y.Ultrahigh Dimensional Feature Selection:Beyond the Linear Model[J].Journal of Machine Learning Research,2009(10). [4]Fan J,Song R.Sure Independence Screening in Generalized Linear Models with NP-Dimensionality[J].The Annals of Statistics,2010,38(6). [5]Zhu L,Li L,Li R,Zhu L.Model-Free Feature Screening for Ultrahigh Dimensional Data[J].Journal of the American Statistical Association,2011,106(496). [6]Li G R,Peng H,Zhang J,Zhu L X.Robust Rank Correlation Based Screening[J].The Annals of Statistics,2012,40(3). [7]Li R,Wei Z,Zhu L.Feature Screening via Distance Correlation Learning[J],Journal of the American Statistical Association,2012,107(499). [8]Shao X,Zhang J.Martingale Difference Correlation and Its Use in High-Dimensional Variable Screening[J].Journal of the American Statistical Association,2014,109(507). [9]Fan J,Feng Y,Song R.Nonparametric Independence Screening in Sparse Ultra-high-dimensional Additive Models[J].Journal of the American Statistical Association,2011,106(494). [10]Fan J,Ma Y,Dai W.Nonparametric Independence Screening in Sparse Ultra-high-dimensional Varying Coefficient Models[J].Journal of the American Statistical Association,2014,109(507). [11]Liu J,Li R,Wu S.Feature Selection for Varying Coefficient Models with Ultrahigh-dimensional Covariates[J].Journal of the American Statistical Association,2014,109(505). [12]马学俊.GSIS超高维变量选择[J].统计与信息论坛,2015,30(8). [13]Hoeffding W.A Non-parametric Test of Independence[J].The Annals of Mathematical Statistics,1948,19(4). [14]Hollander M,Wolfe D.Nonparametric Statistical Methods[M].New York:Wiley,1973. [15]Segal M R,Dahlquist K D,Conklin B R.Regression Approach for Microarrary Data Analysis[J].Journal of Computational Biology,2003,10(6). (责任编辑:崔国平) 收稿日期:2015-09-25;修复日期:2015-11-19 基金项目:中国人民大学科学研究基金(中央高校基本科研业务费专项资金资助)项目(11XNI008) 作者简介:张景肖,女,河北保定人,理学博士,教授,博士生导师,研究方向: 高维变量选择; 中图分类号:O212∶F224.0 文献标志码:A 文章编号:1007-3116(2016)04-0009-04 Robust Variable Screening for Ultrahigh Dimensional ZHANG Jing-xiao1a,1b,LI Xiang-jie1a,1b,GUO Hai-ming2 (a.Center for Applied Statistics,b.School of Statistics,1.Renmin University of China,Beijing 100872,China;2.Business School,Changzhou University,Changzhou 213164,China) Abstract:Variable screening is a very important issue in statistics.In this paper,we propose a new screening,HD-SIS,which do not assume specific models,is robust against outliers.We compare with five methods:Sure Independence Screening,Sure Independent Ranking and Screening,Robust Rank Correlation Screening,Distance Correlation Sure Independence Screening and Martingale Difference Correlation Sure Independence Screening.Simulations indicate that the proposed procedure is significantly better than others. Key words:ultrahigh dimensional data; robustness; model-free; variable screening 李向杰,男,河南商丘人,硕士生,研究方向:高维变量选择; 郭海明,男,江苏常州人,理学博士,讲师,研究方向:信用风险,大数据。 【统计理论与方法】



猜你喜欢
新营销(2019年6期)2019-12-24
商情(2019年3期)2019-03-29
财讯(2018年22期)2018-05-14
会计之友(2018年1期)2018-01-21
西安航空学院学报(2017年4期)2017-12-30
大经贸(2017年7期)2017-08-21
现代商贸工业(2016年2期)2016-12-30
小品文选刊(2016年23期)2016-11-26
中国塑料(2016年3期)2016-06-15
现代商贸工业(2016年35期)2016-04-09
