
“大数据”概念在文言文教学评价体系中的运用
2016-04-18 07:38:58许佳家
现代基础教育研究 2016年1期
许佳家
(上海市世界外国语中学,上海 200233)
“大数据”概念在文言文教学评价体系中的运用
许佳家
(上海市世界外国语中学,上海 200233)
摘要:我国教育评价模式正经历着由“结果导向制”到“结果-过程”相结合的评价模式的转变。文章通过引入“大数据”概念,以初中语文“文言文”为例,初步探讨了“大数据”在语文评价体系中的运用和作用。文章拟运用模式化的数据分析,合理引导过程性评价,以最终达到“结果-过程”评价相匹配的效果。
关键词:大数据;评价模式;语文;文言文
一、“大数据”与教育评价模式
1.何谓“大数据”?
“大数据”是指“需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产”。这个定义明确指出,“大数据”是一种信息资产。其价值并不仅在于它本身信息量的庞大,更在于这些信息量背后所蕴含的价值。简而言之,“大数据”正是通过对大量信息数据的解析而创造出某种价值,并把这种价值转化为资产。
2.教育评价模式
我国教育评价模式经历了间续期、理论期和持续期,现正处于转型期。顾志跃提到“我国的中小学教育评价经历了从记分册到学生素质综合评价手册后,正面临着全面更新的第二次转型”。[1]这就意味着,我国教育的评价模式已经由“结果导向制”转向“结果-过程”相结合的评价模式,从一味地注重学业成绩转向更关注学习过程的评价模式,从而以针对性的教学改进措施,全方面提高学生的综合素养,提升学生的综合能力。这是教育的内在驱动力对教育评价模式的转变提出的新要求。
3.现状与问题的提出
现今的评价模式面临几大难点:(1)评价主体的多元化问题;(2)评价内容的全面性和效度问题;(3)量化评价与质性评价的矛盾。刘五驹提到,在“第四代评估”理论提出后,建立了多元评估主体共同建构的评估模式,但同时也把评价中的科学性与人文性这对矛盾提了出来。[2]
因此,在这样的背景下,结合评价模式与实际教学,我们的疑问是:(1)在总结性评价中,如何体现评估的全面性与效度。(2)在过程性评价中,如何多元化地平衡“质”与“量”的矛盾、科学性与人文性的矛盾?(3)面对教育模式转型,如何形成并体现“结果—过程”相结合的评价模式?
4.研究目的及意义
本文拟引入“大数据”概念,将其体现的价值运用到教学中,通过教师对出题预设的达成度以及学生学习现状的指数分析,双层面、多元化给教育教学提供一定的数据支持,从而提高评估的效度,实现由量化推动到质化,由科学性带动人文性的变革。
二、近年上海市中考试卷的文言文分析
在实际评价过程中,如何运用“大数据”这个概念呢?我们先以“小数据”为例,探索其数据背后的价值。中考一直被视为是九年制义务教育评价的方向标,我们先对中考试卷进行简单地剖析。
1.近年语文中考结构比例
我们归纳了近年中考语文试卷的评价结构,以考核的内容进行分块,具体如表1所示:
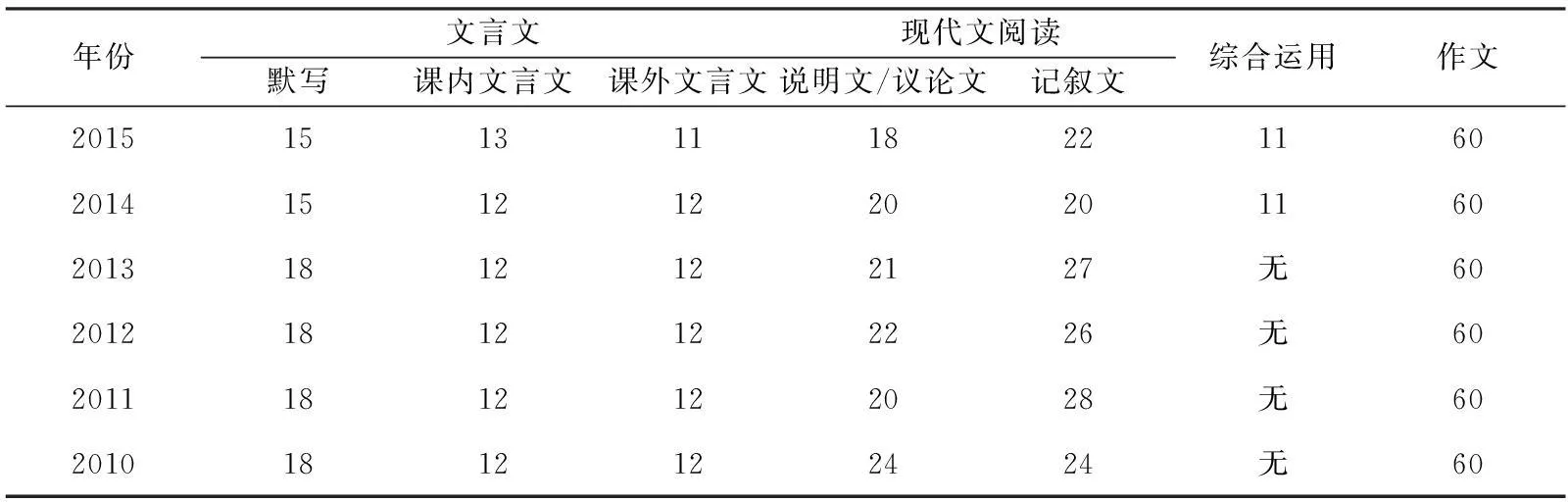
表1 2010—2015年上海市语文中考各项比例
从表1中我们可以看出:
(1)作文占试卷的整体比重多年未变。
(2)除2014年、2015年外,其余4年中考的文言文占试卷整体比重的28%,其中默写占12%,课内文言文和课外文言文均占8%,默写部分占文言文总分的43%。近两年试卷中增加了综合运用部分,尽管如此,文言文占试卷整体的比重依然保持在26%,由此可见中考对文言文的重视。
(3)除2014年、2015年外,其余4年中考的白话文占试卷整体比重的32%,看似高于文言文,但当扣除了一些常规基础题后,实际关于文本的比重并未那么高。而近两年,白话文的比重直接降到了27%,并把相应的比重放到了综合运用题上。
(4)近两年,新增了“综合运用”题型。
由此可以看出,语文的评价模式正经历着一种“变中求稳”的转型。综合运用的加入旨在使学生拓宽视野,能够联系实际生活,提高实际运用能力和综合素养。而对于传统中国文化的精髓部分依然求稳,地位不可撼动。
2.近年中考文言文分值分布
文言文试题按内容可进一步分为诗词鉴赏、课内文言文及课外文言文。三大版块看似各司其职、各自为阵,实则条理清晰、分工明确。我们打乱三部分的排列顺序,按照考点重新分配分值,可以得到以下这张考点分布表,见表2。

表2 2010—2015年上海市语文中考文言文部分考点比例
从表2中我们可以看出:
(1)2010年和2011年,考点分布值较为均匀,翻译、解释占同比,内容理解占比较大,文学常识占比最小。
(2)2012年和2013年,各考点占比顺序与前两年一致,但解释部分移动了两分加在内容理解上。
(3)2014年和2015年,各部分占比略有调整。但整体来看,解释、翻译部分总分几乎持平,文学常识比重不变,内容理解分值持续增加。
从以上这张表,我们可以看出,近6年中考大致可以分为三个阶段,每两年为一个阶段。2010—2011年是基础巩固阶段。这与当时的历史背景相关,2009年是中考在三套教材分叉考试后,首次统一使用二期课改教材进行考试。当年试卷加大了文言诗文的比重和记诵量,意在引导学生加深文化积淀。2010年是统一教材的第二年,故考试内容依然遵循2009年的基调,稳扎稳打,文言文部分紧扣教材,注重基础知识和技能。2012—2013年是基能双行阶段。该阶段稳中求变,在夯实基础的前提下,慢慢将重心由记忆背诵转移到内容理解,为下一阶段作铺垫。因此我们发现,虽然各考点占比略有变动,但是变动比重不大。2014—2015年是能力运用阶段。对比基础巩固阶段,我们明显发现,内容理解的分值大大增加。这说明现今的考试并不单一考察记忆能力,更注重考察学生的分析理解能力、知识运用能力、课内外的迁移能力。
若是如此,是否文言文考试就完全无据可循、学习复习起来就毫无章法了呢?恰恰相反,就上文的分析而言,无论考点比重如何变动,考点本身并未改变。我们可以通过夯实考点本身来不断提高学生的综合能力。
如果把中考视为一种总结性评价方式,那么平日的练习、小测验就可以视为过程性评价方式。我们可以通过平时有针对性的过程性评价来调控总结性评价的结果。
三、“大数据”概念在语文评价体系中的运用
1.两种评价体系
评价体系基本可分为过程性评价和总结性评价。
过程性评价指的是“在课程实施的过程中对学生的学习进行评价的方式”。[3]这种评价方式可以综合衡量一个学生的学习态度、动机、方法等,其目的是让学生在学习的整个过程中及时认识自我,查漏补缺。一般而言,学生的自评、互评、课堂表现、日常小测验等都可以视为过程性评价。
结果性评价指的是“在教育活动结束后为判断其有效果而进行的评价”,[4]这种评价方式可以是一个单元、一个学期或是一个学年结束后对学生的学习成果进行的最终评价。一般情况下,传统意义上的期中期末大考、结业考试、毕业考试都属于结果性评价。
由此看来,过程性评价“既重视学习成果的价值,同时也注意到学习的过程也是反映学习质量水平的重要方面”,因此“采取过程性与目标性并重的取向”。[5]而结果性评价更侧重最后的“量化”效果,即一般意义上的标准化考试。
“大数据”系统就是尽可能地让“过程-结果”这一矛盾体达到统一的效果,让过程推导结果,让结果体现过程,两者合二为一。
2.建立文言文大数据模型
本文现引入“大数据”概念①,以文言文为抓手,探讨两种评价模式相结合的可操作性。下文将从“细分知识点”、“确定难易系数”、“建立模型”三大方面具体解析其操作步骤及其相互关系。
(1)细分知识点
考点即知识点,我们首先要细化知识点,这里的知识点指的是常用的、可控的、固化的知识点。依上文所述,文言文的考核部分首先可以细化为:加点字解释、文学常识、句子翻译以及内容理解四大类。其中,加点字解释根据其难易程度可以分为:普通加点字、一词多义、词类活用、使动用法、意动用法、通假字、古今异义等,如图1所示:

图1 细化知识点示例
我们根据这种难易程度,为该加点字确定不同的难度系数。如对于普通加点字,学生只需要进行解释即可;而对于通假字,学生不仅需要解释该字的意思,还需要写出本字。显而易见,其难易程度必然不同,后者高于前者。假设前者的难度系数是1,那后者的难度系数就可以定为2。如表3和表4所示:

表3 普通加点字及其难度系数

表4 通假字及其难度系数
其他加点字现象也可以根据这样的标准,对难度系数进行评定和分类。文学常识等也可以按照这样的方法进行分类,如表5所示:

表5 文学常识的难度系数
这样可以很清楚地知道学生对某个知识点掌握的程度,以备查漏补缺。另外,当学生对某一知识点或某篇文章掌握得不够牢固时,我们也可以根据难度系数和类型,给学生提供针对性训练。
(2)综合确定整体难度系数
在前一点的基础上,我们可以根据分类难度系数,算出本次考试的整体难度系数。比如上文所示的加点字解释的题目,如果该试卷出了一道普通加点字解释的题目,一道通假字解释的题目,那么该试卷加点字解释部分的难度系数和就是“1+2=3”,难度系数平均数就是“(1+2)/2=1.5”。如果再细致一点,我们可以对难度系数出现的比例进行分析。比如难度系数平均数同样为4的两道题目,它既可以由两个难度系数为4的题目组成,也可以由一个难度系数为1和一个难度系数为7的题目组成。但是我们知道,难度系数为1,说明该题目偏容易,绝大多数学生都可以掌握得分;而难度系数为7时,可能只有中等偏上的学生可以掌握,而其他学生就容易失分,所以这是拉分题。而相对于两道难度系数为4的题目,可能多数学生都可以掌握得分。所以,虽然题目的难度系数平均数一致,但实际上,“1+7”模式难于“4+4”模式(假设难度系数由易至难分为10个等级,1为最容易,10为最难)。
综合确定难度系数有利于教师对学生预期的整体把握。题目和题型是可变的、动态的,需要体现一定的时代性。但是知识点是稳定的、静态的,需要体现的是稳固性。我们牢牢把握知识点,通过对稳固性的知识点的把握来处理万变的题型,以不变应万变。就一份试卷而言,对同一题型按照难度系数进行分类,可以有效地客观判断本次评价的整体难易度,防止评价结果出现大幅度提升或下降,是对预期结果的一种预判,以过程性评价为依据合理规划总结性评价,使之始终能够运行在既定合理的轨道上。
在现行模式下,我们并不会“一考定终身”,而是由多次考试结果形成总结性评价。所以对多份试卷而言,这样做也可以超越时间上的某种限定,把历时上的试卷放在一个共时的层面进行讨论分析,即我们分析的并不是所谓的“一个平均分”的分数,而是“多个平均分”背后的意义。例如:试卷出难点,难到什么程度是合适的?什么样的难度是在合理范围之内的?这次分数考得很好,是因为学生学得扎实还是试卷本身难度降低了?学生经过一个学期的学习,是否在原有的基础上有所提高?通过难易系数的综合分析,我们可以从这些数据中找出实践证据和理论依据。
(3)建立模型
前两步是基础,接下来就是试卷的生成与分析。教师可根据教学的实际情况,选定相应的考察内容和难度系数(如图2所示),并确立小分,生成试卷(如表6所示)。

图2 难度系数的确定

题号一、默写二、基础知识三、古诗文四、阅读理解总分分值8分5分20分17分50分
该试卷的综合难度系数,理论上应与实际评价的分布一致(如图3所示)。教师也可以根据实际情况进行倒推,如果需要设计一份正态分布的试卷,亦可选择相应难度的试题。

图3 考试成绩分布图
评价结束后,教师可以根据每一部分的小分来确定学生的整体情况,为下一阶段的教学工作开展作准备。
模型的建立是试卷整体水平的综合反映,而试卷的具体内容可由任课教师自行调节,如考课内的背诵能力还是考课外的迁移能力?考课文理解还是考实际运用?都可以在模型框架内进行操作。
这时候的总分及平均分的含义并不仅限于数字意义,而是这个数字背后的分析价值。通过这些数字背后的意义,我们尽可能最大程度上还原学生近阶段知识掌握的程度。
(4)三者关系
以上三个步骤,前两个是前提和基础,第三个是结果,依次展开进行,在实施的过程中环环相扣。就学生整体而言,只有在知识点明确、难度值适切的前提和基础下,才能推导出预期的结果,以此来判断学生的整体能力水平,检测是否达到教学目标,以备下一阶段的有效教学。就学生个体而言,也可以通过对每位学生小分的判断,为他建立个人档案,进行实时跟踪,从而从历时角度观察该学生学习能力的变化。另一方面,从数据结果的统计来看,也可以根据学生实际学情的不同来适当调整难度值,设立标准难度值和适配难度值,提高试卷的针对性和有效性。
3.案例举隅
根据上述三大步骤,下面我们将构建一个“理想化”案例②模型。
测试对象:某中等学校平行班
测试内容:《岳阳楼记》中的加点字解释
题量:10题
具体操作步骤如下:
(1)根据题型,选择题目、题量及难度,如表7所示:

表7 《岳阳楼记》加点字解释
(2)适当调整难度分布
图4为随机添加10道题目的效果,这样的试卷可能难度值分配不够均匀。如图4所示,该考卷总体难度就偏低。

图4 随机题目难度值

图5 正态分布的难度值
此时,我们需要对该难度进行必要的调整。图5为调整后的效果,我们尽可能地让试卷的难度值形成正态分布的效果,这样有助于区分班级整体水平及学生个人能力水平。
(3)生成试卷及答案
根据这份试卷的难度分布,我们基本可以判断这是一份中等难度的试卷,如果以100分为满分,平均分理论上可以控制在70分左右,这也是我们的预估值。如果平均分高于70,则表示学生水平整体较好,对知识点的掌握较为牢固。而低于70,则表示下一阶段的教学中还必须加强训练。
(4)试卷分析与反馈
理论上而言,在做试卷分析时,学生平均分应与预估分较为接近,而学生成绩的人数分布图应与难度系数图具有一致性。我们可对比图6及图7。如前后两张图出现不一致性,在学情不变的前提下,则表示难度设置存疑,需要进行及时调整。

图6 题目难度分布图
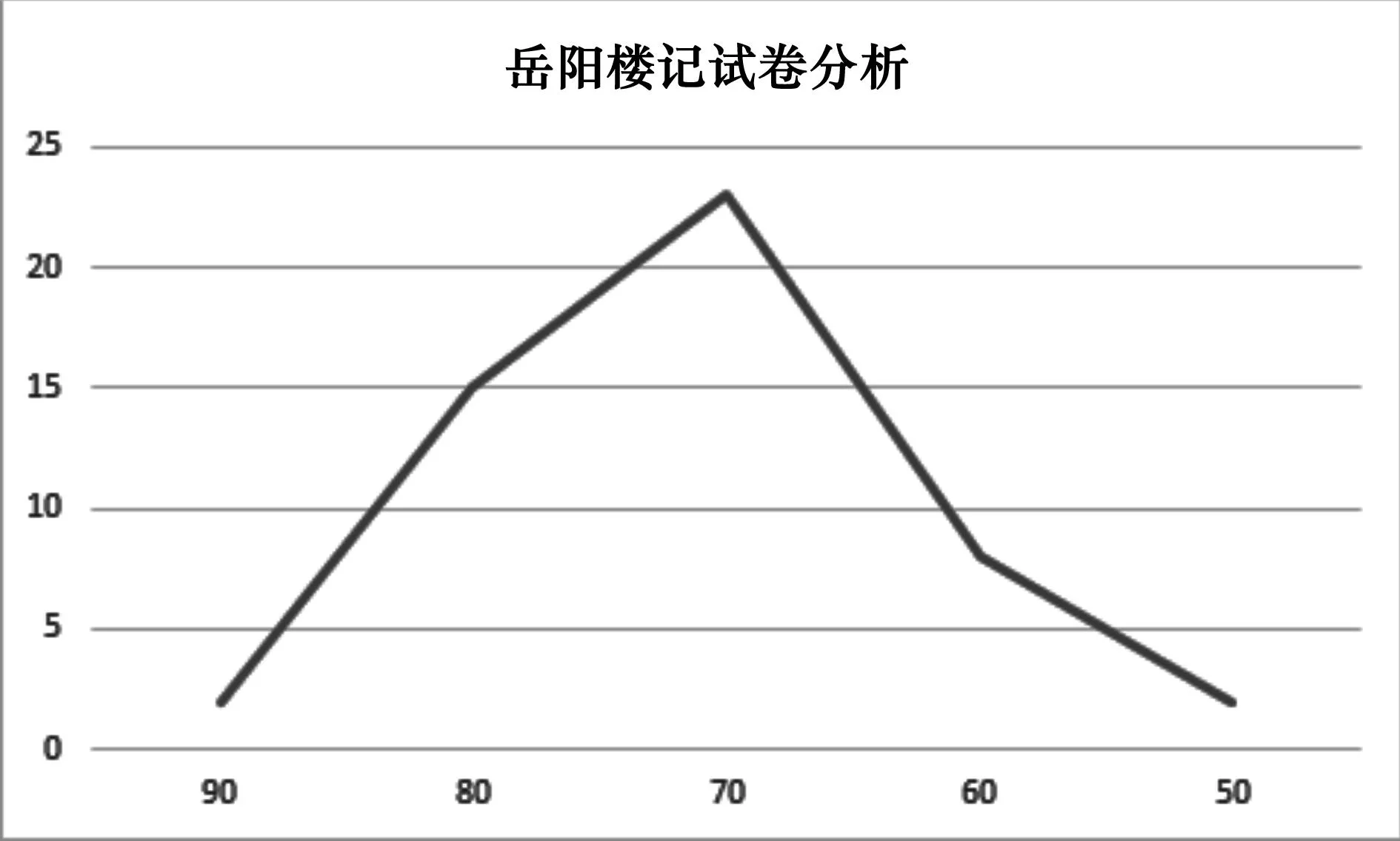
图7 班级得分人数分布图
“大数据”模型检测不仅可以针对教师的日常性教学,也可以用于学生的自评和互评工作,让学生对评价的标准有一个较为整体、直观及量化的体验,能明确自身在学习过程中的薄弱环节,以便有效地进行改进。
文言文的“大数据”运用价值,还体现在提高出卷效率上。这种效率体现在以下几方面:其一,可大量自动生成试卷,缩短出卷时间;其二,试卷可根据出题者需要,调节难度系数;其三,考试前,对试卷各部分分值比例有整体上的精细化分配,明确出卷意图;其四,考试后,对于学生的错误类型有合理的归因,便于试卷分析。总之,笔者希望以这样的方式,把“教学目标的适切性、内容的恰当性、过程的合理性、结果的有效性”[6]这四种性质有机地结合在一起,提高教育教学质量。
四、困难及展望
1.困难与挑战
“大数据”模式会给教学工作带来许多便利,但也存在一定的困难与挑战。
(1)“大数据”之所以有这样的名称,首先其数据量要“大”,即在前期需要进行大量的资料搜集与积累。非但如此,“大数据”还在于数据的多样性,不仅线性文本式可以纳入此范围,而且图片、表格等非线性数据亦可纳入其中。将来,“大数据”的采集还可以涉及使用者的互交性(如慕课、iBook等软件工具),通过学生和教师的互动来搜集收据。但是由于数据量的庞大及种类繁多,处理时就必须分类整理问题,这用什么标准去做?如何找出数据背后的相关性,找出其内在价值?这个过程需要大量的时间与精力。以上图示是我们根据教学经验总结出的一种分类方法,但未必是最佳的。教师可以根据自己的实际教学经验进行不同的分类和总结。
(2)题目依靠难度系数作为标准。那难度系数的确定标准又是什么?是一个经验值还是一个标准值?这是需要我们思考和研究的问题。
(3)文言文由于范围较小,这样做可以提高效率。但是白话文一定要根据文本进行分析,这要如何操作?这个问题有待进一步讨论。
2.展望与发展
(1)通过“大数据”的建立,我们一方面希望可以提高评价模式的客观性,另一方面希望提高评价的效度和信度,使得评价的质和量达到统一,科学性与人文性达到平衡,最终可以形成“结果—过程”相结合的模式参考值。
(2)“大数据”的建立,虽然其初衷是为了检验教师的教学教育质量,但教学的目的更应该由教转化到学,再转化到运用的过程中去。所以,这种“评价-归纳”模式并不是只适用于教师,学生也可自主去创造并建立适合于自己的数据库,真正实现过程性评价的理念。这样会更有针对性,具有学生自身的个性色彩,可帮助学生提高归纳能力,实现评价主体的多元化。
注释:
①本文的“大数据”概念在基于前文的基础上,进行了内涵化的处理。下文中的“大数据”主要指的是文言文测试中,学生成绩所反映的学生能力的信息数据。
②所谓“理想化”案例是指通过标准化设置及生成达到我们的预设效果,但是在现实操作过程中,可能会由于学情、教学重难点等各种原因而造成偏差。
参考文献:
[1]顾志跃.积极参与教育评价新探索[J].上海教育科研,2014,(3).
[2]刘五驹.评价标准:科学性还是人文性——“第四代评估”难题破析[J].教育理论与实践,2014,(16).
[3]高凌飚.关于过程性评价的思考[J].课程·教材·教法,2004,(3).
[4]姜艳华.试论过程性评价与结果性评价的同一[J].当代教育论坛,2007,(4).
[5]秦岭.大数据时代的高中古典诗歌教学探索实践[J].现代基础教育研究,2014,(3).
[6]秦萍.二期课改背景下的初中文言文教学[D].华东师范大学硕士学位论文,2010.
[7]上海市教育委员会.上海市中小学语文课程标准[S].上海教育出版社,2005.
[8]李菀,王保兵,李芳.中学语文新课程课堂教学评价改革[J].四川教育学报,2005,(11).
[9]沈学珺.大数据对教育意味着什么[J].上海教育科研,2013,(9).
[10] 胡中锋,董标.教育评价:矛盾与分析[J].课程·教材·教法,2005,(8).
[11] 黎志华.教师教育评价研究[D].华东师范大学硕士学位论文,2011.
[12] 张燕南,赵中建.大数据时代思维方式对教育的启示[J].教育发展研究,2013,(21).
[13] 周馨.大数据时代教育数据价值挖掘[J].信息与电脑(理论版), 2013,(8).
The Application of Big Data to Classical Chinese Evaluation System
XU Jiajia
(Shanghai Foreign Language Middle School,Shanghai 200233)
Abstract:Nowadays our education evaluation system are transforming from result oriented to “result-process” system. This article is going to discuss the classical Chinese evaluation system by using big data. It will use the data to analyze the process evaluation and finally to match the result with the process.
Key words:big data, evaluation system, Chinese teaching, Classical Chinese
作者简介:许佳家,上海市人,上海市世界外国语中学二级教师,硕士,主要从事初中语文教学研究。
猜你喜欢
新世纪智能(语文备考)(2021年5期)2021-08-06 09:22:48
新世纪智能(语文备考)(2021年5期)2021-08-06 09:22:46
中国教育技术装备(2016年19期)2016-12-27 19:23:27
职业·下旬(2016年10期)2016-12-02 21:50:24
科技视界(2016年20期)2016-09-29 10:53:22
学周刊(2016年26期)2016-09-08 09:02:54
考试周刊(2016年15期)2016-03-25 03:19:37
考试周刊(2016年12期)2016-03-18 06:05:33
语文知识(2015年11期)2015-02-28 22:02:00
