
医疗数据的清洗以及知识挖掘
2016-04-11 12:56:44吴辰文朱建东
安徽大学学报(自然科学版) 2016年1期
关键词:贝叶斯网络
吴辰文,郑 恒,张 烨,朱建东
(兰州交通大学电子与信息工程学院,甘肃兰州730070)
医疗数据的清洗以及知识挖掘
吴辰文,郑恒,张烨,朱建东
(兰州交通大学电子与信息工程学院,甘肃兰州730070)
摘 要:数据挖掘或数据分析在生物医学中与其他调查领域不同,因为在生物医学领域这些数据很复杂,他们资源不同,且每一个医师对同一个诊断记录都有他们自己的解释.分析医疗数据的特征,研究数据的清洗,目的是为了挖掘有价值的知识.实验显示,所提出的方法比朴素贝叶斯网络模式更有效.
关键词:数据清理;医疗数据;知识挖掘;贝叶斯网络
由于医疗机制的改革,医疗记录存在的一些问题如病人隐私信息的泄露,已经不能满足医疗事业的需求了.医疗机构应该想出一个隐私保护措施来保护病人的隐私,再研究基于法律和规则的相关技术[1-2].
论文提出一种新的数据挖掘方法,其安全性和可行性都很高.有越多的数据,就会有越多的有效知识.数据挖掘是信息化的过程,是在海量数据源中提取可信和有效知识的形式,其目的是从大量的、随机的数据中提取未知的但有用的知识,并解决传统的统计方法无法处理的效率问题.数据挖掘的方法主要包括关联分析、分类分析、聚类分析、统计分析、时间序列模式和偏差分析.经典的数据挖掘过程包括了解业务、理解数据、准备数据、建模和分析、模型评估和模型部署.
1 相关工作
1.1 知识管理
MYCIN[3]系统开发于20世纪70年代,可以用来支持咨询或决策.在生物医学领域,许多人工智能的方法已被应用于数据挖掘.在生物医学方面,相关研究者采用了基于人工智能的专家知识推理规则,并提供了医疗知识管理,这就要求在生物医学领域出现新的方法或技术.这些系统不仅可以代替人类诊断,而且还可以辅助生物医学决策.在医疗领域,病人管理系统正在高速的发展[4].这些对于医生来说是一个重要的信息[5],可以掌握非常庞大的数据[6],同时把它们分为两大类,即病人的健康信息和从海量信息中统计的信息.这种分类法已被大多数研究人员接受.另外,随着信息技术的不断进步和发展,这两种信息也正在快速地发展.在医疗数据集成中,由于生物现象非常复杂,整合这些数据要面对许多种挑战[7].Chen等[8]提出一种应用于生物医学领域中的异构数据库集成框架,该框架采用查询翻译技术为医疗数据集成一个统一的概念模式.MedBlast[9]系统是根据给定的关键字序列,让研究人员能够找到相关的文章.
1.2 数据和文本挖掘
经典的数据挖掘技术已经被广泛应用,研究人员用其来发现在生物医学卫生领域中的新模式或者是新知识.数据挖掘技术可以用来从医疗保健数据和临床诊断中提取生产规则.研究人员已经在生存数据中运用数据挖掘技术提取出了诊断规则[10].运用数据挖掘的技术提取的有关规则与那些由专家手工生成的规则很是类似.因此,数据挖掘的结果可以很容易地由该领域的专家验证.另外,数据挖掘技术也可以应用在医疗数据库中,目的是寻找新的医疗知识[11].在生物医学领域中分类算法用的是最普遍的数据挖掘技术.Chen等[8]应用SVM(support vevtor machine)插入模型来自动检测峰值信号,并且其结果可以应用在与癫痫有关的神经性疾病中.Hpipcsak等[12]使用模糊C-均值算法来分割乳房和脑部磁共振图像,并且他们的方法是有效的和自动的.
低成本的存储和相应的测序技术使其非常易于保存生物医学数据,根据发达的互联网,这些生物医学数据可以很容易地被研究者访问.因为这些数据有大量的注释和数据架构.因此,在这种类型的数据中,数据挖掘是必要的.在各种数据挖掘算法中,聚类[13]和分类[14]算法被广泛地用于生物医学数据.
1.3 机器学习和数据分析的范式
原始数据的分析和挖掘技术如概率和统计分析,它们有很长的历史[15-18].在所有这些概率分析模型中,贝叶斯模型是最流行的,它是用于分析海量数据的强有力的理论依据[19].考虑到一个新进的实例,根据预先计算的概率,运用贝叶斯模型将它分类[20].在原有贝叶斯模型的基础上,研究人员提出了朴素贝叶斯模型.朴素贝叶斯模型的主要思路是:假设一个类有许多功能,但这些功能是相互独立的.朴素贝叶斯模型简化了原有的贝叶斯模型,并已在许多研究领域中得到应用[21].近年来,在机器学习研究中,SVM模式得到了越来越多的认可.SVM模型也是根据统计学习理论得到的,其目的是要找到一个超平面,使得该超平面能够把数据空间划分成若干类.SVM模型也已应用在许多医疗分类设置中,如医生根据临床记录诊断和根据基因数据疾病特征进行分类[21].
2 医疗数据清洗
2.1 数据清洗的框架
数据清洗对于数据分析很重要,并且它是使用数据挖掘算法之前对数据集的预处理.目前,对数据清洗并没有一个共同的协议,因为不同的数据清洗可能有不同的要求.具体数据清洗过程是从领域到领域、主题到主题、项目到项目.然而,数据清洗的共同理解是处理不合理、不完整、不准确数据的过程.在数据清洗的过程中,要能够正确地检测到错误,并对缺少的特征添加默认值,以提高数据质量.
图1给出了对数据清洗的框架,这是适合于不同用途的框架.该框架不包含任何数据挖掘算法,并给出了规划整个数据挖掘过程的数据挖掘研究的指南.一些数据清理算法将适用于数据清洗处理的具体工作.此框架允许用户与通过选择合适的算法框架,但是它要求用户必须清楚地知道数据清洗的每个步骤,因此这在处理噪声数据将是有效的.
数据挖掘框架的基本原则如下:
(1)从原始数据中,使用预加工技术来选择合适的属性的过程;
(2)基于聚类的关键,通过选择合适的聚类算法或分类的方法来分组记录;
(3)利用数据挖掘技术,如聚类算法和关联规则,通过相似度计算来挖掘有价值的知识.
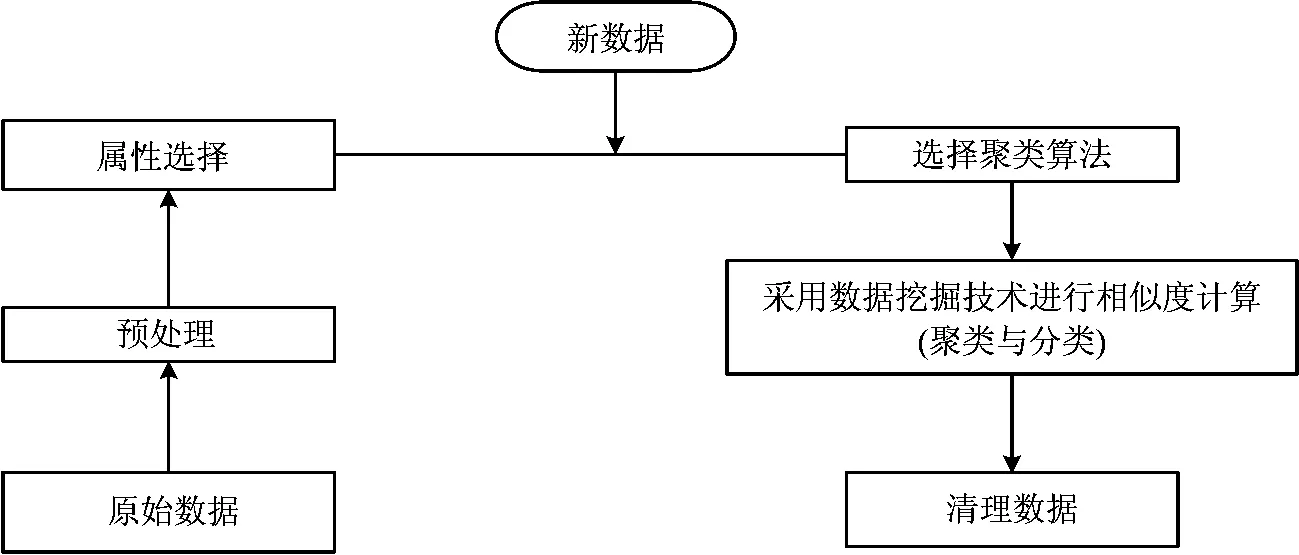
图1 数据清理框架Fig.1 Framework for data cleaning
2.2 数据清洗
在数据清理过程中检测出的不一致和错误,要手动或自动校正它们,以提高数据的质量.一些商业工具已经提供了一些数据清洗的功能,但它们是不完全的.根据以上的情况,一些研究者提出了数据清洗的系统框架.数据清洗的目的是为数据仓库或数据挖掘提供工具,然后运用数据仓库和数据挖掘技术,可以发现在数据集中的模式或映射.
然而,为了自动地处理数据清洗和解决数据记录的复制问题,作者提供了一种无监督步进式的学习算法.在无监督步进式的学习方法中可以自动进行聚类数据记录,以及处理大量的和未被标记的数据记录.聚类算法的目的是生成一些集群,并在相同簇中的记录是尽可能相似的,在不同的簇中尽可能是不同的.
2.3 一种基于无监督的步进式的学习方法
在无监督学习的过程中没有外部教师或评论者去监视学习的过程,如图2所示.

图2 无监督学习的块图表Fig.2 Block of diagram of supervised learning
无监督机器学习包括两种学习方法:强化学习和竞争学习.强化学习方法是基于评估的,并增强外部环境的学习能力.竞争学习是由彼此相互竞争的中性细胞组成的,并且这些竞争的中性细胞可以从输入的数据中得到知识.作者基于经典的无监督的机器学习算法,提高了Hebbian规则,并根据记录提出了竞争学习算法,目的就是为了解决该问题.
根据Hebbian等人的假设,可以用一个函数来表示中性细胞的规则

其中:w是权重向量参数,x是输入样本向量参数,Φ(·)是可微函数,a≥0是遗忘系数.
中性细胞的输出为


其中:u>0是一种学习速度系数,因此梯度是
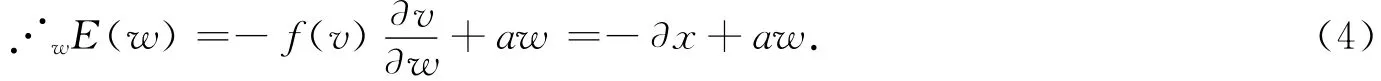
可以得到中性细胞的学习规则为

离散的学习规则为
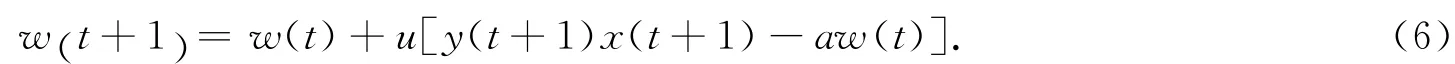
如果遗忘系数是a=1,并且奖惩系数是Y,那么当中性细胞被激活,i-th中性细胞的学习规则为
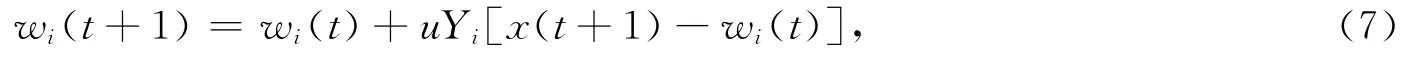
其中
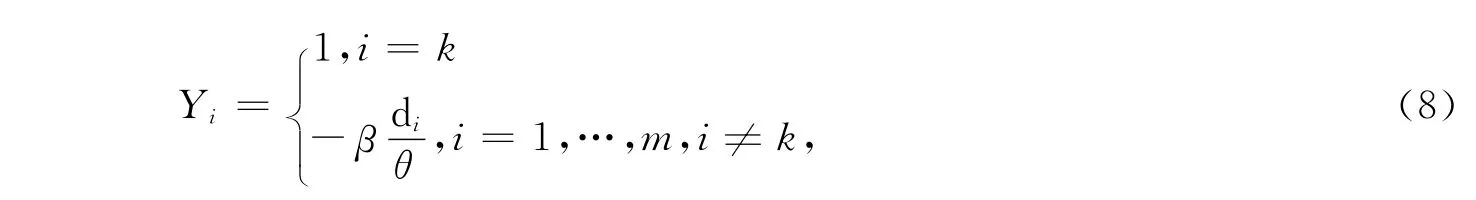
其中:β是一种惩罚系数,θ表示的是一种相似度的门槛,di是i-th中性细胞的相似值,并且

其中:xi和yi是向量x和y的i-th元素,i=1,…,l;wi是权重系数.
根据上文的描述,总结出以下学习算法:
(1)初始的学习速度系数u,惩罚系数β,和相似度门槛θ;
(2)接受第一个样本向量x,添加第一个中性细胞w0,并且初始化为x;
(3)判断学习是否结束,如果是,转到第(5)步,否则,从样本空间接受样本向量,并且根据等式(9)计算相似度的值;
(4)根据竞争力的能力,判断出胜利的中性细胞,如果di>θ,添加一个新的中性细胞并设置为x,然后返回第(3)步;
(5)根据等式(8)计算惩罚系数;
(6)根据等式(7)更新权重,然后返回第(3)步.
2.4 归一化式的距离压缩(normalized compression distance,简称NCD)
NCD是使用K(y)近似法使两个数据之间的距离度量的,其中C(y)=K(y)+k .通过无损压缩机C加上未知常量k可以获得压缩版本的长度.NCD的计算方法为
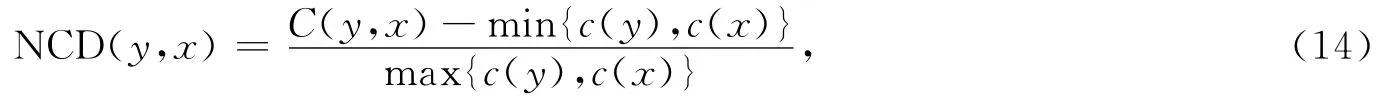
其中:C(y,x)表示通过y和x串联获得被压缩文件的大小.NCD代表了不同的两个文件,便于利用这一结果为各种应用注入无参数的方法,随着程序的修补,使用NCD能够计算它们之间的距离矩阵.
3 实验评价
根据合成数据集和真实数据集,评估所提出的数据清洗算法的质量和准确度.
3.1 基准模型
首先,把实验提出的算法与正确的贝叶斯网络模型相比较.在实验中,提出的方法包含两个条件概率分布(conditional probability distribution,简称CPDs),分别是P(I.b|M.b,F.b)和P(I.d|I.b).编码这两个CPDs中,为每个变量(I.d和I.b)的数据集的概率值都能够产生一个后验概率分布(M.b,F.b和I.b).同时,根据从数据中收集的案例,创建了两个CPDs.例如,通过下面的SQL语句查询,可以得到P(I.d|I.b):
SELECT death,birth,count(*)
FROM person
GROUP BY death,birth;
由于同样的原因,可以根据相同的SQL查询构建先验分布P(I.b).对于每一个构建的CPDs,都可以标准化原始计数,以便通过返回的结果得到概率密度.
3.2 结 果
首先,对于每个实验,通过复制和改变原始数据集(合成的或真实的数据集)构造原始数据库的子集.然后随机注入一些错误的信息进入数据库的子集,并删除了一些有价值的数据,产生了一些缺失的信息,并在完成这些之后,试图找到所有缺失值,使它们变成马尔科夫毛毯模型.其原因是,未被观察到的所有的相关的项目将结束在相同的毛毯模型上.根据底层的图形模型的性质,很容易解决这些马尔可夫毛毯.例如,马尔科夫毛毯的每个产品上可能都有出生年份,但其每年的死亡年份可能会丢失.在实验中,只考虑使用不少于5种未被观察到的值的毛毯.此外,为了尽量减少在边界情况下推出的偏见,删除在1850—2013年之外的未被观测到的一些毛毯.
接下来,学习从每一个数据集中推理出算法的参数.这可以通过朴素贝叶斯模型的“count group by”SQL语句查询和在模型中的“histogram scan”SQL语句查询来实现.因为论文所提出的方法是一种数据驱动的算法,这一步返回的是一个新的数据集而不是从原始数据集中构建的子数据集.
为了公平,在对损坏的数据集的实验中,当为两个算法构造模型的时候,运用的是粗糙的清洗方法.即限制数据的值包括最大值之和最小值,也即CPDs,min(DA)<I.d-I.b<max(DA).对于生活中的人的定义,用介于0~95岁的年龄来表示;对于这个区间之外的任何值,假设他或她已经死了.此外,假定父母的年龄从18~50岁.精确的推理应用主要领域的知识,这需要CPDs跨越一定范围的值.然而,近似推理方法不是基于有限的实际值,因此具有更好的推理能力.
3.21 丢失的数据
由于预计CPDs的值I.b,M.b,F.b都是非常稀疏的,通过比较,BayesNet算法比ERACER算法有两倍以上的误差.至于这两种算法的准确度的比较,通过实现BayesNet收缩扩展.在实验设置中,使用实施收缩技术来仿真基于年龄的ERACER算法.
在BayesNet模型,CPDs的每个毛毯,选择与同年龄差异的所有记录,并且将它们计数在一起,而不是通过计算特定出生/死亡年,如
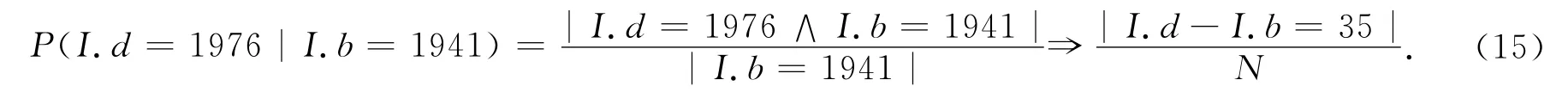
该实验的结果如图3所示.图中(a),(b),(c)是精确度对比;(d),(e),(f)是质量对比.图3中(a)、(d)说明了这两个数据清洗的算法,这里的贝叶斯网络模型使用上述热收缩技术的准确度(顶部)和质量(底部).这两种算法可以与实际值进行比较,有三至七年的错误缺失值.从图文可以看到,提出ERACER算法比BayesNet算法更准确,原因是在算法中和模型中的数据与网络具有依赖性,并且该网络可以增加弹性以此来增加算法的准确性.然而,BayesNet算法与ERACER算法在质量上较为一致. 在BayesNet算法,随着边缘不确定性增加,数据的丢失量也在增加.然而,ERACER算法依赖于所提出的参数模型,并且在该实验中使用卷积,提高个实验的准确性.
3.22 损坏的数据
图3(b)、(e)中显示出的精确度(顶部)和质量(底部)包含了两种算法.
从图中可以看到,BayesNet算法对被破坏的数据值更有抵抗力.其原因在于,BayesNet算法推断自始至终与马尔可夫毛毯是联合的.然而,BayesNet算法推断方差的方法比ERACER算法更高,但是这些都是不确定的,因为在数据集中有相互矛盾的证据.论文提出的算法与BayesNet算法在损坏的数据的较低水平几乎是一样的,但是对总体误差更敏感.
以上的结果与预期是一样的,对于每个边缘都是独立的,并且它依赖于大多数实例的投票.在该数据集中,当大多数相关的数据是错误的,该错误可以传播到马尔可夫毛毯,而这将会导致与推断的正确的数据不同.然而,论文所提出的方法是在许多应用中都是有效的,因为这些应用程序没有这么多的错误,并且这个方法可以很容易地处理它们.论文提出的算法完成了95%,这比朴素贝叶斯网络模型更好,其精度只有77%.总之,在数据清洗的过程中,论文提出的算法比贝叶斯模型更好.
3.23 PRF数据
在PRF数据集的实验中,因为脉冲重复频率数据集是一个真正的数据集(没有在此数据集中注射错误),并且错误出现在那里,因此实验评价有点复杂.对这个数据集运用的数据清洗算法,并尝试识别个人的出生年份和死亡年份.算法完成五轮之后,确定了错误的个人出生年份和死亡年份.在图3(b)、(e)中,显示了两种算法的准确性(顶部)和质量(底部).从这两个数字可以看出,论文实验所提出的数据清洗算法比贝叶斯网络模型更加有效.
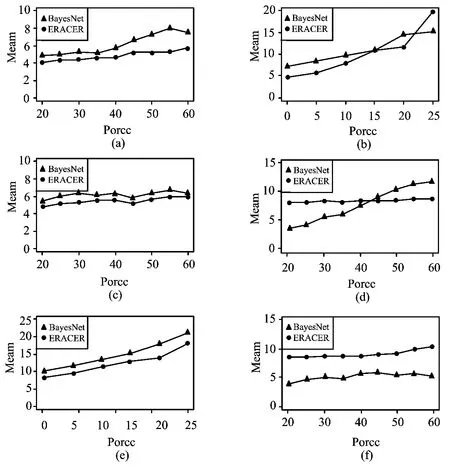
图3 ERACER算法与BayesNet算法的对比Fig.3 The comparison of ERACE algorithm and BayesNet algorithm
4 结束语
在生物医学数据分析领域,医疗数据来自不同的数据资源,因此它们将具有不同的数据结构或数据模式.此外,不同的医生对相同的临床记录的解释可以得出不同结论.此外,为了保护患者隐私,许多个人的一些特征被省略.为了挖掘这些庞大的生物医学数据,使用之前一定要清洗它们,并将它们整合在一起,以获得具有精确特征的结构化的数据集.在论文中,分析医疗数据的特征,并对这些数据进行数据清洗,来挖掘出有价值的知识.根据实验的结果以及对结果的分析可以知道,该实验提出的方法比朴素贝叶斯网络模型更加有效.
参考文献:
[1] WEIKUN G.Foundations of statistical natural language processing[J].Acm Sigmod Record,2002,31(3):37-38.
[2] CEUSTERS W.Medical natural language understanding as a supporting technology for data mining in healthcare[J].Studies in Fuzziness and Soft Computing,2001,14(5):41-71.
[3] NARAIN S.Mycin:implement the expert system in loglisp[J].Software,IEEE,1985,1(2):83-89.
[4] GUPTILLl J.Knowledge management in health care[J].Health Care Finance,2005,31(3):10-14.
[5] DAWES M,SAMPSON U.Knowledge management in clinical practice:a systematic review of information seeking behavior in physicians[J].International Journal of Medical Informatics,2003,71(1):9-15.
[6] SUNDARAM A.Information retrieval:a health care perspective[J].Bulletin of the Medical Library Association,1996,84(4):59-61.
[7] FULLER S S,REVERE D,BUGNI P F,et al.A knowledgebase system to enhance scientific discovery:telemakus[J].Biome Dical Digital Libraries,2004(1):2-10.
[8] CHEN H,LALLY A M,ZHU B,et al.HelpfulMed:intelligent searching for medical information over the internet[J].Journal of the American Society for Information Science and Technology,2003,54(7):683-694.
[9] BARRERA J,CESAR-JR R M,FERREIRA J A,et al.An environment for knowledge discovery in biology [J].Computers in Biology and Medicine,2004,34(5):427-447.
[10] TU H Q,DING D.MedBlast:searching articles related to abological sequence[J].Bioinformatics,2004,20 (1):75-77.
[11] JANUROV A,BRIV S A.Nonparametric approach to medical survival data:Uncertainty in the context of risk in mortality analysis[J].Reliability Engineering &System Safety,2013,125:145-152.
[12] HRIPCSAK G,AUSTIN J H,ALDERSON P O,et al.Use of natural language processing to translate clinical information from a database of 889,921chest radiographic reports1[J].Radiology,2002,224(1):157-163.
[13] KANNAN S R,RAMATHILAGAM S,DEVI R,et al.Strong fuzzy c-means in medical image data analysis [J].Journal of Systems and Software,2012,85(11):2425-2438.
[14] WOOTEN E C,HUGGINS G S.Mind the dbgap:The application of data mining to identify biological mechanisms[J].Molecular Interventions,2011,11(2):95-102.
[15] HASAN M,HUAN J,CHEN J,et al.Biological knowledge discovery and data mining[J].Scientific Programming,2012,20(1):1-2.
[16] RAZA K.Application of data mining in bioinformatics[J].Indian Journal of Computer Science and Engineering,2010,1(2):114-118.
[17] ANANIADOU S,PYYSALO S,TSUJII J,et al.Event extraction for systems biology by text mining the literature[J].Trends in Biotechnology,2010,28(7):381-390.
[18] CHIEN Y.Pattern classification and scene analysis[J].Automatic Control,IEEE Transactions,1974,19 (4):462-463.
[19] MANTEL N,HAENSZEL W.Statistical aspects of the analysis of data from retrospective studies of disease [J].The Challenge of Epidemiology:Issues and Selected Readings,2004:533-553.
[20] WEBB G I,BOUGHTON J R,ZHENG F,et al.Learning by extrapolation from marginal to full-multivariate probability distributions:decreasingly na¨ive Bayesian classification[J].Machine Learning,2012,86(2):233-272.
[21] BHAVSAR H,PPNCHAL M H.A review on support vector machine for data classification[J]. International Journal of Advanced Research in Computer Engineering &Technology,2012,10(1):185-189.
(责任编辑 朱夜明)
Data cleaning of medical data and knowledge mining
WU Chenwen,ZHENG Heng,ZHANG Ye,ZHU Jiandong
(School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730070,China)
Abstract:Data mining or data analysis in biomedicine is different from other research fields,because the data in biomedical are heterogeneous,and they are from different sources. Moreover,each physician might have his own interpretation with the same clinical records. In this paper,we analyzed the features of medical data,and studied data cleaning for medical data in order to mine valuable knowledge.Experiments showed that the proposed method was more efficient than the baseline Bayesian network model.
Key words:data cleaning;medical data;knowledge mining;Bayesian network
doi:10.3969/j.issn.1000-2162.2016.01.005
作者简介:吴辰文(1964-),男,甘肃靖远人,兰州交通大学教授,硕士生导师.
基金项目:兰州市科技计划基金资助项目(2009-1-5);甘肃省自然科学基金资助项目(1308RJZA111)
收稿日期:2015-03-13
中图分类号:U416
文献标志码:A
文章编号:1000-2162(2016)01-0023-07
猜你喜欢
移动通信(2016年22期)2017-03-07 21:59:13
商情(2016年46期)2017-03-06 04:14:12
现代电子技术(2017年1期)2017-02-16 11:45:32
科技资讯(2016年25期)2016-12-27 16:22:32
南水北调与水利科技(2016年5期)2016-12-27 12:04:04
会计之友(2016年22期)2016-12-17 15:41:27
软件导刊(2016年9期)2016-11-07 17:50:19
新会计(2016年6期)2016-07-05 20:20:55
计算技术与自动化(2015年3期)2015-12-31 17:14:47
科技资讯(2015年20期)2015-10-15 19:08:14
