
环境规制中地方政府与中央政府的演化博弈分析
2015-07-07 15:28潘峰,西宝,王琳
运筹与管理 2015年3期
潘 峰, 西 宝, 王 琳
(1.哈尔滨工业大学 管理学院,黑龙江 哈尔滨 150001; 2.大连理工大学 公共管理与法学学院,辽宁 大连 116024)
环境规制中地方政府与中央政府的演化博弈分析
潘 峰1, 西 宝2, 王 琳1
(1.哈尔滨工业大学 管理学院,黑龙江 哈尔滨 150001; 2.大连理工大学 公共管理与法学学院,辽宁 大连 116024)
针对环境规制中地方政府与中央政府之间的行为互动,从演化博弈论的研究视角探讨了地方政府与中央政府的决策演化过程。通过建立地方政府与中央政府的非对称演化博弈模型,考察了环境规制中参与者的行为特征。根据复制动态方程得到了参与者的行为演化规律、分析了参与者的演化稳定策略及其影响因素。研究表明,环境规制系统的初始状态、地方政府的环境规制成本和环境规制收益、中央政府的监查成本以及中央政府对地方政府的处罚额都会影响地方政府与中央政府的演化稳定策略。降低中央政府的监查成本、加强中央政府对地方政府的监查力度和违规处罚力度,降低环境规制成本、提高环境规制收益,将有利于促使地方政府执行环境规制,从而达到改善环境质量的目的。
环境规制;演化稳定策略;演化博弈论;地方政府;中央政府
0 引言
环境规制是指政府或规制机构为应对经济活动的负外部性,对企业污染排放行为进行的限制和调节。环境规制的执行过程也是利益相关方的博弈过程,不同的博弈结果会带来不同的政策效果。为了提高环境治理效果,国内外众多学者就规制过程中相关主体的策略行为进行了研究。Moledina等构建了信息不对称条件下的动态博弈模型,研究发现企业会采取不同的策略行为应对不同的政策工具[1],邓峰通过分析政府与企业的互动关系也得到了与之类似的结论[2]。蒙肖莲等对环境污染管理过程进行了博弈分析,认为通过鼓励污染处理或就地污染最小化,能够达到对企业行为的理性控制[3]。杨林等基于完全理性假设,研究了监管部门和厂商之间的博弈与环境恶化之间的关系[4]。张学刚等在传统成本的基础上引入了声誉成本和政治成本,探讨了政府环境监管与企业污染治理的互动决策问题[5]。一些学者认为加强政府监管和违规处罚有助于环境质量的改善[6,7],而张倩等建立的动态博弈模型表明,政府监管强度并不能直接影响企业的排污水平[8]。此外,Barrett和Kennedy对不完全竞争市场下政府环境决策的非合作博弈进行了分析[9,10]。崔亚飞等研究了我国地方政府间的污染治理策略问题,朱平芳等则对地方政府为吸引FDI展开的环境政策博弈进行了理论和实证研究[11,12]。
通过回顾已有研究成果可知,在内容上,以往相关研究侧重于分析地方政府与企业以及地方政府之间的博弈关系,对地方政府与中央政府的行为互动研究还比较缺乏;在方法上,以往相关研究多以博弈方完全理性为基本假设,缺乏以有限理性为前提的博弈分析。我国的环境规制政策由中央政府统一制定,由地方政府负责执行,随着财政分权改革的不断深化,地方政府与中央政府的利益目标分离导致双方在规制政策的执行过程中存在博弈关系。针对地方政府与中央政府的环境规制策略研究,有助于探析我国环境污染问题的深层原因以及环境规制失灵的内在机理。由于现实中博弈主体并不具备完美的分析推理和准确决策的能力,而基于有限理性的理论分析会更加具有实际意义,因此,本文采用演化博弈工具研究环境规制执行过程中地方政府与中央政府的策略行为,分析博弈主体的行为演化规律和演化稳定策略,以期深化和拓展已有研究,为促进环境规制政策的高效执行提供理论依据。
1 问题描述与模型基本设定
财政分权改革打破了地方政府与中央政府一体化的权力结构,地方政府拥有了更多的自主决策权,并逐渐成为相对独立的利益主体。在环境污染的治理过程中,地方政府在贯彻中央政府的环境政策同时,也在不断以实际行动维护自身利益,地方政府与中央政府的关系表现为动态的重复博弈。首先对博弈模型做出如下基本假设:
1.1 博弈方及策略
假设博弈的一方为地方政府,博弈的另一方为中央政府。地方政府的策略选择有两种,执行环境规制和不执行环境规制,策略集为{执行,不执行};中央政府的策略选择有两种,监查地方政府的环境规制执行状况和不监查地方政府的环境规制执行状况,策略集为{监查,不监查}。
1.2 收益矩阵
假设只要中央政府对地方政府实施监查,就能发现地方政府是否执行了环境规制,若地方政府不执行环境规制,则对其进行处罚;如果中央政府不实施监查,则不能发现地方政府是否执行了环境规制,相应也就不存在处罚;地方政府执行环境规制可以约束企业排污行为、改善当地环境质量,但也会增大企业成本、阻碍地方经济发展,同时间接影响中央政府的收益水平;治理污染会使企业支付更多的成本却不会带来直接的收益,如果没有环境规制的约束,追逐利润最大化的排污企业并不会主动治理污染,因此地方政府不执行环境规制会导致地方环境质量下降,而地方环境质量下降也会对全国整体环境质量造成不利影响。
符号设定:Z为中央政府总收益水平;V为地方政府总收益水平;C1为地方政府环境规制执行成本;C2为中央政府监查成本;G为执行环境规制对地方经济造成的损失;F为中央政府对地方政府的处罚额;P为地方政府不执行环境规制所引致的地方环境污染损失;h为执行环境规制使得地方环境质量得到的改善;α为地方政府向中央政府的缴税比率(0<α<1);β为地方环境污染损失在全国环境污染总损失中的占比(0<β<1)。为简便并不失一般性,本文假定所有符号取值均大于零。根据上述基本设定,考虑2×2非对称重复博弈,其阶段博弈的支付矩阵如表1所示。

表1 地方政府与中央政府博弈的支付矩阵
2 地方政府与中央政府的演化博弈分析
在地方政府与中央政府的环境规制博弈中,中央政府对地方政府执行环境规制的意愿缺乏了解,地方政府对中央政府的政策决心和监查力度所掌握的信息也十分有限,博弈双方的理性程度较低,其行为策略都是基于有限理性而做出的。因此,地方政府与中央政府都不是一次博弈就能找到最优策略,而是通过试错、总结和模仿,不断寻找较优策略,最终形成稳定策略。在这种情况下,静态博弈下的纳什均衡并不能对地方政府与中央政府的行为特征做出真实的描述,而基于演化博弈理论的地方政府与中央政府的行为策略研究则会更加符合实际。
演化博弈理论放松了完全理性的假设,能够更加贴近现实地解释经济现象。该理论中最基本的均衡概念为演化稳定策略(Evolutionarily Stable Strategy,ESS),它是指当群体达到能够消除任何小的突变的状态时所选择的策略[13]。其含义在于,重复博弈中的有限理性个体不断调整策略以追求自身收益的改善,最终达到一种动态平衡。在这种平衡状态下,任何个体都会趋于某个稳定策略而不愿再改变,即便在受到少量错误干扰后仍能恢复均衡。而“复制动态”(Replicator Dynamics)则是模拟有限理性个体策略调整过程的最主要的动态机制,其核心思想是群体中采用某策略的比例的变化率与该策略被采用的比例成正比,与该策略的期望收益大于群体平均收益的幅度成正比,高于群体平均收益的策略会被学习、模仿和发展,而低于群体平均收益的策略则将被逐渐淘汰[14]。考虑到地方政府与中央政府的有限理性及其策略调整过程的渐进性,本文使用复制动态机制模拟双方的重复博弈过程。
令地方政府选择执行环境规制策略的比例为x,则选择不执行环境规制策略的比例为1-x;中央政府选择监查策略的比例为y,则选择不监查策略的比例为1-y。
在地方政府方面,执行环境规制的期望收益为:
U1=y(V-C1-G+h)+(1-y)(V-C1-G+h)
不执行环境规制的期望收益为:
U2=y(V-F-P)+(1-y)(V-P)
地方政府的平均收益为:
则地方政府选择执行环境规制策略的复制动态方程为:

将U1和U2代入到复制动态方程,可以得到:
(1)
在中央政府方面,选择监查策略的期望收益为:
U3=x(Z-C2-αG+βh)+(1-x)(Z-C2+F-βP)
选择不监查策略的期望收益为:
U4=x(Z-αG+βh)+(1-x)(Z-βP)
中央政府的平均收益为:
则中央政府选择监查策略的复制动态方程为:
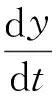
将U3和U4代入到复制动态方程,可以得到:
(2)
将式(1)和式(2)联立,可以得到地方政府和中央政府的复制动态系统:
(3)
复制动态系统(3)的均衡点所对应的策略组合为演化博弈的一个均衡,简称为演化均衡[15]。如果从系统中某均衡点的任意小邻域内出发的轨线最终都演化趋向于该均衡点,则称该均衡点是局部渐近稳定的,即演化稳定点[16]。利用雅可比矩阵的局部稳定分析方法可以分析均衡点的局部渐进稳定性,并由此得到演化稳定点及其对应的演化稳定策略(ESS)。对系统中的复制动态方程分别求关于和的偏导数,则其雅可比矩阵为[17]:
矩阵J的行列式为:
detJ=(1-2x)(yF-C1-G+h+P)(1-2y)(F-C2-xF)-F(1-x)xF(y-1)y
矩阵J的迹为:
trJ=(1-2x)(yF-C1-G+h+P)+(1-2y)(F-C2-xF)
依据演化博弈理论,满足detJ>0,trJ<0的均衡点为系统的演化稳定点,于是进行以下分析。
分析1 当P+h-C1-G>0,F-C2>0时,由方程组(3)可以得到复制动态系统的四个均衡点,即O(0,0),A(1,0),B(1,1),C(0,1),则它们对应的雅可比矩阵行列式与迹符号分析如表2所示。

表2 行列式与迹符号分析(P+h-C1-G>0,F-C2>0)
在条件表达式中,P+h为地方政府选择执行环境规制时获得的环境质量改善与所避免的环境污染损失(选择“执行”策略则可以避免“不执行”策略所带来的损失)之和,亦即地方政府执行环境规制的总收益;C1+G为地方政府执行环境规制对地方经济造成的损失与环境规制执行成本之和,亦即地方政府执行环境规制的总成本。因此P+h-C1-G表示地方政府执行环境规制的净收益。由表2可知,当环境规制净收益为正,同时中央政府的处罚额大于其监查成本时,博弈的均衡点中A(1,0)为演化稳定点,其对应的演化稳定策略为(执行,不监查),即地方政府倾向于选择执行环境规制策略,中央政府倾向于选择不监查策略。
分析2 当P+h-C1-G>0,F-C2<0时,由方程组(3)可以得到复制动态系统的四个均衡点,即O(0,0),A(1,0),B(1,1),C(0,1),则它们对应的雅可比矩阵行列式与迹符号分析如表3所示。

表3 行列式与迹符号分析(P+h-C1-G>0,F-C2<0)
由表3可知,当环境规制净收益为正,同时中央政府的处罚额小于其监查成本时,博弈的均衡点中A(1,0)为演化稳定点,其对应的演化稳定策略为(执行,不监查),即地方政府倾向于选择执行环境规制策略,中央政府倾向于选择不监查策略。
分析3 当P+h-C1-G<0,F-C2<0,F+P+h-C1-G<0时,由方程组(3)可以得到复制动态系统的四个均衡点,即O(0,0),A(1,0),B(1,1),C(0,1),则它们对应的雅可比矩阵行列式与迹符号分析如表4所示。

表4 行列式与迹符号分析(P+h-C1-G<0,F-C2<0,F+P+h-C1-G<0)
由表4可知,当环境规制净收益为负,中央政府的处罚额小于其监查成本,同时环境规制净收益与处罚额之和为负时,博弈的均衡点中O(0,0)为演化稳定点,其对应的演化稳定策略为(不执行,不监查),即地方政府倾向于选择不执行环境规制策略,中央政府倾向于选择不监查策略。
分析4 当P+h-C1-G<0,F-C2<0,F+P+h-C1-G>0时,由方程组(3)可以得到复制动态系统的四个均衡点,即O(0,0),A(1,0),B(1,1),C(0,1),则它们对应的雅可比矩阵行列式与迹符号分析如表5所示。

表5 行列式与迹符号分析(P+h-C1-G<0,F-C2<0,F+P+h-C1-G>0)
由表5可知,当环境规制净收益为负,中央政府的处罚额小于其监查成本,同时环境规制净收益与处罚额之和为正时,博弈的均衡点中O(0,0)为演化稳定点,其对应的演化稳定策略为(不执行,不监查),即地方政府倾向于选择不执行环境规制策略,中央政府倾向于选择不监查策略。
分析5 当P+h-C1-G<0,F-C2>0,F+P+h-C1-G<0时,由方程组(3)可以得到复制动态系统的四个均衡点,即O(0,0),A(1,0),B(1,1),C(0,1),则它们对应的雅可比矩阵行列式与迹符号分析如表6所示。

表6 行列式与迹符号分析(P+h-C1-G<0,F-C2>0,F+P+h-C1-G<0)
由表6可知,当环境规制净收益为负,中央政府的处罚额大于其监查成本,同时环境规制净收益与处罚额之和为负时,博弈的均衡点中C(0,1)为演化稳定点,其对应的演化稳定策略为(不执行,监查),即地方政府倾向于选择不执行环境规制策略,中央政府倾向于选择监查策略。
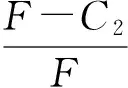

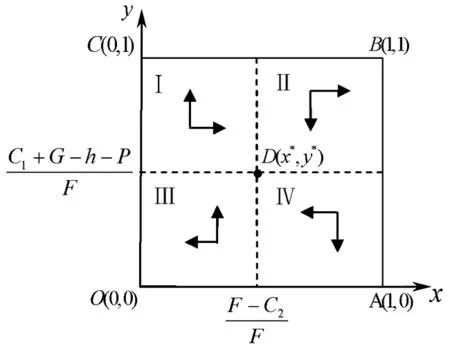
表7 行列式与迹符号分析(P+h-C1-G<0,F-C2>0,F+P+h-C1-G>0)
由表7可知,当环境规制净收益为负,中央政府的处罚额大于其监查成本,同时环境规制净收益与处罚额之和为正时,点O(0,0)、A(1,0)、B(1,1)、C(0,1)均为鞍点,点D(x*,y*)为中心点,没有演化稳定策略(ESS)。在此种情形下,对于地方政府,令F(x)=x(1-x)(yF-C1-G+h+P)=0,得到的两个稳定态为x=0,x=1。如果初始状态水平y=y*,则所有x水平都是稳定态。即当中央政府选择监查策略的比例为y*(监查比例临界值)时,则任何水平的地方政府环境规制执行比例都可以达到稳定状态。如果初始状态水平y>y*,则有F(x)>0,F′(0)>0,F′(1)<0,根据微分方程的稳定性定理可知,此时x=1是稳定态。如图1所示:初始状态下,当中央政府选择监查策略的比例大于y*时,则地方政府选择执行环境规制策略的比例会逐渐升高,直至地方政府完全选择执行环境规制而达到稳定状态。如果初始状态水平y

图1 地方政府演化相位图(y>y*)

图2 地方政府演化相位图(y 对于中央政府,令F(y)=y(1-y)(F-C2-xF)=0,得到的两个稳定态为y=0,y=1。如果初始状态水平x=x*,则所有y水平都是稳定态。即当地方政府选择执行环境规制策略的比例为x*(环境规制执行比例临界值)时,则任何水平的中央政府监查比例都可以达到稳定状态。如果初始状态水平x>x*,则有F(y)<0,F′(0)<0,F′(1)>0,根据微分方程的稳定性定理可知,此时y=0是稳定态。如图3所示:初始状态下,当地方政府选择执行环境规制策略的比例大于x*时,则中央政府对地方政府的监查比例会逐渐降低,直到中央政府完全选择不监查而达到稳定状态。如果初始状态水平x 图3 中央政府演化相位图(x>x*) 图4 中央政府演化相位图(x 进一步,可以将地方政府与中央政府的复制动态关系更为直观地表示为图5。 图5 地方政府与中央政府的演化博弈相位图(分析6) 本文基于演化博弈理论建立了环境规制执行过程中地方政府与中央政府的演化博弈模型,分析了不同情形下地方政府与中央政府的演化稳定策略,研究结果表明: 因此,要促使地方政府高效地执行环境规制、改善环境质量,应努力降低中央政府的监查成本,加强中央政府对地方政府的监查强度和违规处罚力度。另外,从整个社会福利水平的角度来看,理想局面为地方政府主动执行环境规制、中央政府无需监查,即分析1和分析2中的演化稳定策略(执行,不监查)。所以,应当通过补贴等手段降低环境规制执行成本、降低环境规制对企业造成的经济损失,同时将环境质量改善程度纳入到地方政府政绩考核体系,以此提高地方政府执行环境规制的收益。 [1] Moledina A A, Coggins J S, Polasky S, et al. Dynamic environmental policy with strategic firms: prices versus quantities[J]. Journal of Environmental Economics and Management, 2003, 45(2): 356-76. [2] 邓峰.基于不完全执行污染排放管制的企业与政府博弈分析[J].预测,2008,27(1):67- 71. [3] 蒙肖莲,杜宽旗,蔡淑琴.环境政策问题分析模型研究[J].数量经济技术经济研究,2005,22(5):79- 88. [4] 杨林,高宏霞.基于经济视角下环境监管部门和厂商之间的博弈研究[J].统计与决策,2012,(21):51-55. [5] 张学刚,钟茂初.政府环境监管与企业污染的博弈分析及对策研究[J].中国人口·资源与环境,2011,21(2):31-35. [6] 王齐.政府管制与企业排污的博弈分析[J].中国人口·资源与环境,2004,14(3):119-122. [7] 卢方元.环境污染问题的演化博弈分析[J].系统工程理论与实践,2007,27(9):148-152. [8] 张倩,曲世友.环境规制下政府与企业环境行为的动态博弈与最优策略研究[J].预测,2013,32(4):35- 40. [9] Barrett S. Strategic environmental policy and international trade[J]. Journal of Public Economics, 1994, 54(3): 325-338. [10] Kennedy P W. Equilibrium pollution taxes in open economies with imperfect competition[J]. Journal of Environmental Economics and Management, 1994, 27(1): 49- 63. [11] 崔亚飞,刘小川.中国地方政府间环境污染治理策略的博弈分析——基于政府社会福利目标的视角[J].理论与改革,2009,(6):62- 65. [12] 朱平芳,张征宇,姜国麟.FDI与环境规制:基于地方分权视角的实证研究[J].经济研究,2011,(6):133-145. [13] Smith J M. The theory of games and the evolution of animal conflicts[J]. Journal of Theoretical Biology, 1974, 47(1): 209-221. [14] Taylor P D, Jonker L B. Evolutionarily stable strategies and game dynamics[J]. Mathematical Biosciences, 1978, 40(1): 145-156. [15] 孙庆文,陆柳,严广乐,等.不完全信息条件下演化博弈均衡的稳定性分析[J].系统工程理论与实践,2003,(7):11-16. [16] 易余胤,刘汉民.经济研究中的演化博弈理论[J].商业经济与管理,2005,166(8):8-13. [17] Friedman D. Evolutionary games in economics[J]. Econometrica, 1991, 59(3): 637- 666. Evolutionary Game Analysis of Local Government and Central Government in Environmental Regulation PAN Feng1, XI Bao2, WANG Lin1 (1.School of Management, Harbin Institute of Technology, Harbin 150001, China; 2.School of Public Administration and Law, Dalian University of Technology, Dalian 116024, China) For the interaction between local government and central government in environmental regulation, the evolutionary process of decision is discussed based on the evolutionary game theory. In this paper, an asymmetric evolutionary game model between local government and central government is established to study the behavioral characteristics of participants in environmental regulation. Behavioral evolutionary law of participants is found out according to the replicator dynamics equation, evolutionarily stable strategy is analyzed, and the related influencing factors are also considered. The results show that the evolutionarily stable strategy of local government and central government is affected by the initial states of environmental regulation system, the cost of environmental regulation of local government, the income of environmental regulation of local government, the cost of supervision of central government, the punishment of central government to local government. The implementation of environmental regulation of local government will be promoted by reducing the cost of supervision, strengthening supervision and punishment to local government, reducing the cost of environmental regulation, increasing the income of environmental regulation, which contributes to the improvement of environmental quality. environmental regulation; evolutionarily stable strategy; evolutionary game theory; local government; central government 2013- 08-18 国家社会科学基金重点项目(12AGL010);国家自然科学基金资助项目(61074133) 潘峰(1983-),男,吉林蛟河人,博士研究生,主要研究方向:环境规制;西宝(1970-),男,黑龙江富锦人,教授,博士生导师,主要研究方向:公共管理、管理科学与工程。 F224.32 A 1007-3221(2015)03- 0088- 06

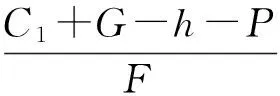
3 结论与政策建议
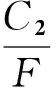 猜你喜欢
天津科技(2020年7期)2020-07-31中国管理信息化(2019年18期)2019-10-15环球时报(2019-06-26)2019-06-26商品与质量(2018年43期)2018-12-06物流科技(2017年9期)2017-10-31西藏研究(2017年3期)2017-09-05现代企业文化·理论版(2016年23期)2017-04-01西藏研究(2016年3期)2016-06-13华人时刊·中旬刊(2015年7期)2015-10-21山东工业技术(2014年21期)2014-12-24
猜你喜欢
天津科技(2020年7期)2020-07-31中国管理信息化(2019年18期)2019-10-15环球时报(2019-06-26)2019-06-26商品与质量(2018年43期)2018-12-06物流科技(2017年9期)2017-10-31西藏研究(2017年3期)2017-09-05现代企业文化·理论版(2016年23期)2017-04-01西藏研究(2016年3期)2016-06-13华人时刊·中旬刊(2015年7期)2015-10-21山东工业技术(2014年21期)2014-12-24
