
城乡个人收入差距的分位数因果效应估计
2015-05-30 21:44韩开山黄群周晓华
现代管理科学 2015年2期
关键词:分位数回归
韩开山 黄群 周晓华

摘要:文章深入研究了中国健康和营养调查数据库(CHNS)中的成人调查数据,发现影响城乡收入的协变量存在不平衡。文章提出利用倾向值方法对数据加权,使得数据平衡,利用加权分位数因果效应方法和改进的加权分位数因果效应方法估计城乡收入差距。研究表明,城乡个人收入存在较大差距,同时随着收入水平的提升,这种差距有增大的趋势,但城乡个人收入的相对差距随着收入水平的提升变化并不显著。特困人群中,城乡个人收入的相对差距为33.3%,中等收入以下群体,相对差距小于20%,中等收入以上群体,相对差距介于25%~36%之间。
关键词:倾向值;分位数回归;分位数因果效应
一、 引言
我国是典型的城乡二元经济结构,从1993年~2012年,农村居民家庭人均总收入由1 333.82提高到10 990.67元,增长了近8.24倍,城镇居民家庭人均总收入由2 583.16提高到26 958.99元,增长了近10.44倍[中经网统计数据库]。城乡居民家庭人均收入比从1.94∶1扩大到2.45∶1,城乡居民人均收入的差距没有递减的趋势。城乡二元经济结构对家庭人均收入的影响,国内外学者已经进行了大量的研究。郭剑熊认为低人力资本积累率和高生育率是造成城乡收入不平等的主要原因。姚先国等分析了城乡居民收入不平等主要是由人力资本水平差异和就业差异造成的。段景辉等利用分位数回归分别对影响城乡家庭人均收入的因素进行了分析,并利用Rubin的反事实理论和Machado和Mata的分位数分解方法对城乡收入差距进行了分解,说明劳动力教育水平、工作年限等是造成差距的主要原因。陈建宝等利用分位数回归分析的方法对中国性别工资差距进行了分析,找出影响性别工资的因素。但这些文献数据都是一个非随机化试验,两类人员的协变量分布是很不平衡的,按照随机试验的方法做分位数回归处理具有一定的偏差,即容易产生内生性问题。
强可忽略假设是研究处理效果时广泛使用的基本假设。Hahn基于这个假设和非参数估计两条件回归函数提出了一种估计量,并给出了其有效界。由于Rosenbaum和Rubin所作的工作,越来越多的人避免直接调节协变量,而改用估计倾向值来调节估计方法,其中一个主要的方法就是利用倾向度对观测数据进行加权,以使得处理组和对照组达到平衡。
Firpo提出先利用半参的方法估计出倾向值,再利用加权倾向值估计分位数处理效应,并证明了这种方法为是一致收敛、近似正态,能取到半参有效界,Fr?觟lich和Melly证明了利用Logistic回归计算倾向值,并能取到利用半参的估计方法相同的性质,即该方法是一致收敛、近似正态,能取到半参有效界,本文在计算倾向值时采用了Logistic回归方法。
本文在前人的研究成果的基础上,利用中国健康和营养调查数据库(CHNS)中的2006年成人调查数据表的微观数据,利用加权分位数因果效应方法和改进的加权分位数因果效应方法对城乡个人收入差距进行深入分析,找到影响城乡个人收入差距的因素、城乡个人收入差距和城乡个人收入相对差距在不同收入阶层的分布特征。
二、 数据分析
本文数据取自中国健康和营养调查数据库(CHNS)2006年成人调查数据,该数据采用多层次随机抽样方法得到,选取东部(辽宁、江苏、山东、广西)、中部(河南、湖南、湖北)、西部(贵州)八个省份进行抽查。农村样本6 428个,城市样本3 360个,但由于收入数据的很大缺失,本文所采用的数据时剔除掉缺失数据后的农村样本915个,城市样本798个。本文研究的目的是了解不同收入层次上城乡个人收入的差距,以及差距的分布特征。
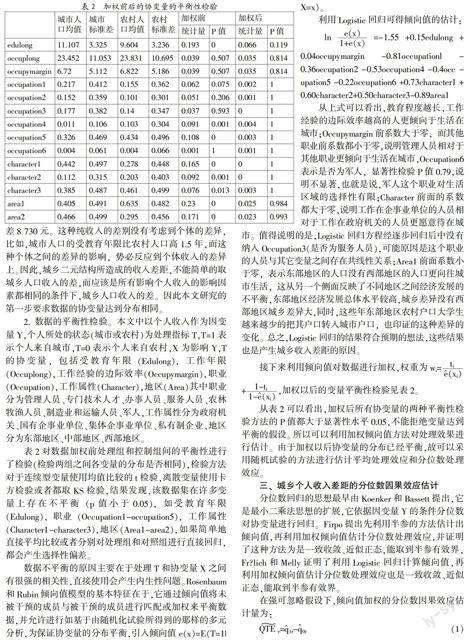
1. 数据描述。依据抽样调查数据,分别计算以农村、城市为调查对象的年龄、受教育年限、工作年限、收入的均值、中值、标准差、并做正态性检验,结果发现,农村和城市人口在年龄、工作年限上没有显著差异,农村的教育年限平均要比城市的受教育年限低1.5年,农村人口的年平均收入比城市人口的年平均收入低4 803.54元。从正态性检验看,这几个变量都不服从正态分布。下表计算不同收入水平下城乡收入的差异。
从表1看,在不同收入水平下,城市人口的收入都大于农村人口的收入,并且从收入的差可以看出,随收入水平的增高,城市和农村收入的差也相应的提高,从低收入人群(5%)的收入差1 200元,到高收入人群(95%)的收入差8 730元。这种纯收入的差别没有考虑到个体的差异,比如,城市人口的受教育年限比农村人口高1.5年,而这种个体之间的差异的影响,势必反应到个体收入的差异上。因此,城乡二元结构所造成的收入差距,不能简单的取城乡人口收入的差,而应该是所有影响个人收入的影响因素都相同的条件下,城乡人口收入的差。因此本文研究的第一步要求数据的协变量达到分布相同。
2. 数据的平衡性检验。本文中以个人收入作为因变量Y,个人所处的状态(城市或农村)为处理指标T,T=1表示个人来自城市,T=0表示个人来自农村,X为影响Y,T的协变量,包括受教育年限(Edulong),工作年限(Occuplong),工作经验的边际效率(Occupymargin),职业(Occupation),工作属性(Character),地区(Area)其中职业分为管理人员、专门技术人才、办事人员、服务人员、农林牧渔人员、制造业和运输人员、军人,工作属性分为政府机关、国有企事业单位、集体企事业单位、私有制企业,地区分为东部地区、中部地区、西部地区。
表2对数据加权前处理组和控制组间的平衡性进行了检验(检验两组之间各变量的分布是否相同),检验方法对于连续型变量使用均值比较的t检验,离散变量使用卡方检验或者都取KS检验,结果发现,该数据集在许多变量上存在不平衡(p值小于0.05),如受教育年限(Edulong),职业(Occupation1-occupation5),工作属性(Character1-character3),地区(Area1-area2),如果简单地直接平均比较或者分别对处理组和对照组进行直接回归,都会产生选择性偏差。
数据不平衡的原因主要在于处理T和协变量X之间有很强的相关性,直接使用会产生内生性问题。Rosenbaum和Rubin倾向值模型的基本特征在于,它通过倾向值将未被干预的成员与被干预的成员进行匹配或加权来平衡数据,并允许进行如基于由随机化试验所得到的那样的多元分析,为保证协变量的分布平衡,引入倾向值e(x)=E(T=1|X=x)。
利用Logistic回归可得倾向值的估计:
ln■=-1.55+0.15edulong+0.04occupymargin-0.81occupationl-0.36occupation2-0.53occupation4-0.4occ-upation5-0.22occupation6+0.73character1+0.60character2+0.50character3-0.89area1
从上式可以看出,教育程度越长,工作经验的边际效率越高的人更倾向于生活在城市;Occupymargin前系数大于零,而其他职业前系数都小于零,说明管理人员相对于其他职业更倾向于生活在城市,Occupation6表示是否为军人,显著性检验P值0.79,说明不显著,也就是说,军人这个职业对生活区域的选择性有限;Character前面的系数都大于零,说明工作在企事业单位的人员相对于工作在政府机关的人员更愿意待在城市。值得说明的是,Logistic回归方程经逐步回归后中没有纳入Occupation3(是否为服务人员),可能原因是这个职业的人员与其它变量之间存在共线性关系;Area1前面系数小于零,表示东部地区的人口没有西部地区的人口更向往城市生活,这从另一个侧面反映了不同地区之间经济发展的不平衡,东部地区经济发展总体水平较高,城乡差异没有西部地区城乡差异大,同时,这些年东部地区农村户口大学生越来越少的把其户口转入城市户口,也印证的这种差异的变化。总之,Logistic回归的结果符合预期的想法,这些结果也是产生城乡收入差距的原因。
接下来利用倾向值对数据进行加权,权重为wi=■+■,加权以后的变量平衡性检验见表2。
从表2可以看出,加权后所有协变量的两种平衡性检验方法的P值都大于显著性水平0.05,不能拒绝变量达到平衡的假设。所以可以利用加权倾向值方法对处理效果进行估计。由于加权以后协变量的分布已经平衡,故可以采用随机试验的方法进行估计平均处理效应和分位数处理效应。
三、 城乡个人收入差距的分位数因果效应估计
分位数回归的思想最早由Koenker和Bassett提出,它是最小二乘法思想的扩展,它依据因变量Y的条件分位数对协变量进行回归。Firpo提出先利用半参的方法估计出倾向值,再利用加权倾向值估计分位数处理效应,并证明了这种方法为是一致收敛、近似正态,能取到半参有效界,Fr?lich和Melly证明了利用Logistic回归计算倾向值,再利用加权倾向值估计分位数处理效应也是一致收敛、近似正态,能取到半参有效界。
在强可忽略假设下,倾向值加权的分位数因果效应估计量为:
■?子=q1?子-q0?子(1)
q1?子=infq■■■?叟?子,
q0?子=infq■■■?叟?子
从(1)式和(2)式可以看出,当样本容量有限,倾向值接近0或1时,该估计量不一定有效,也就是,当个体i接收处理组治疗的概率很小时,个体i在估计因果效果时提供了一个很大的权重。简单地一个改进方法是改进其权重,使得权重之和为1。
改进的权重为wwi=■■-1■+■■-1■(3)
改进的加权倾向值估计量:
■?子=q1?子-q0?子(4)
qw1?子=infq■■-1■■?叟?子,
qw0?子=infq■■-1■■?叟?子(5)
可以证明,在一些正则条件下,改进的加权倾向值估计方法是一致无偏的。同时,改进的加权倾向值的优点的是利用了倾向值,可以平衡数据,降低混杂变量的维数。
因果效应的算法如下:
步骤1 应用Logistic回归估计倾向值e(xi)。
步骤2利用倾向值e(xi)计算的权重wi=■+■对数据进行加权,此时,如果数据已经是平衡数据,故可以采用随机试验的方法进行估计平均处理效应和分位数处理效应,如果数据还不平衡,可以按照不平衡的变量对数据进行分层,在每一层内保证数据是平衡的,在每一层中采用随机试验的方法进行估计平均处理效应和分位数处理效应。本文加权以后数据已经平衡,所以没有采用分层的技术。
步骤3 利用ATE=■■-1■■-■■-1■■求得城乡收入差距的平均处理效应ATE。
利用公式(4)(5)计算■?子,即求得了在?子分位数下的分位数因果效应,即在?子分位数下的收入的差距,记为WQTE。
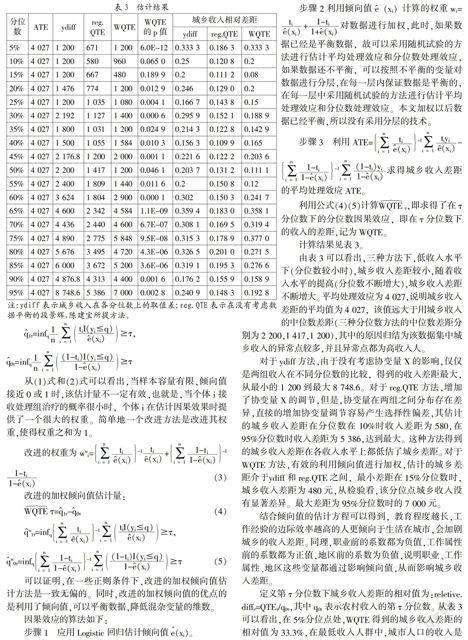
计算结果见表3。
由表3可以看出,三种方法下,低收入水平下(分位数较小时),城乡收入差距较小,随着收入水平的提高(分位数不断增大),城乡收入差距不断增大。平均处理效应为4 027,说明城乡收入差距的平均值为4 027,该值远大于用城乡收入的中位数差距(三种分位数方法的中位数差距分别为2 200,1 417,1 200),其中的原因归结为该数据集中城乡收入的异常点较多,并且异常点都为高收入人。
对于ydiff方法,由于没有考虑协变量X的影响,仅仅是两组收入在不同分位数的比较,得到的收入差距最大,从最小的1 200到最大8 748.6。对于reg.QTE方法,增加了协变量X的调节,但是,协变量在两组之间分布存在差异,直接的增加协变量调节容易产生选择性偏差,其估计的城乡收入差距在分位数在10%时收入差距为580,在95%分位数时收入差距为5 386,达到最大。这种方法得到的城乡收入差距在各收入水平上都低估了城乡差距。对于WQTE方法,有效的利用倾向值进行加权,估计的城乡差距介于ydiff和reg.QTE之间,最小差距在15%分位数时,城乡收入差距为480元,从检验看,该分位点城乡收入没有显著差异。最大差距为95%分位数时的7 000元。
结合倾向值的估计方程可以得到,教育程度越长,工作经验的边际效率越高的人更倾向于生活在城市,会加剧城乡的收入差距。同理,职业前的系数都为负值,工作属性前的系数都为正值,地区前的系数为负值,说明职业、工作属性、地区这些变量都通过影响倾向值,从而影响城乡收入差距。
定义第?子分位数下城乡收入差距的相对值为:reletive.diff?子=QTE?子/q0?子,其中q0?子表示农村收入的第?子分位数。从表3可以看出,在5%分位点处,WQTE得到的城乡收入差距的相对值为33.3%,在最低收入人群中,城市人口的收入是农村人口收入的1.333倍,这部分收入差距的原因是城市低保水平要比农村的低保水平高,维持人民生活的最低生活水平农村要比城市人口低很多。从10%到55%分位点之间,WQTE得到的城乡收入差距的相对值都小于等于20%。从60%到95%分位点之间,WQTE得到的城乡收入差距的相对值介于0.25%到36%之间,这一部分人群中,城乡收入差距的相对值稍有增大。整体来说,城乡收入差距的相对值没有随收入水平的增大产生显著的增大,只是有小幅的改变。
四、 结论
本文首先对中国健康和营养调查数据库(CHNS)2006年成人调查数据进行统计描述,发现影响收入结果的因素在城乡两组之间存在较大的分布不一致性,直接使用分位数回归方法会产生选择性偏差,故提出使用加权的分位数回归方法,并在假设1的条件下证明这种加权的分位数回归方法是无偏的。
通过倾向值对数据进行加权,再利用分位数回归的方法估计出了在不同分位点下城乡收入的差距。同时比较说明了y.diff方法、reg.QTE方法、WQTE方法的估计结果的区别。从调查数据中可以得到在在低收入阶层中,城乡收入差距较小,在高收入阶层中,城乡收入差距较大,并且随着收入水平的提高(分位数不断增大),城乡收入差距不断增大。通过城乡收入差距的相对值,知最低收入人群中,由于最低生活保障体制的不同,引起收入差距的相对值较大,其它收入阶层中,城乡收入差距的相对值变化只是有小幅改变。
现阶段,城乡收入达到绝对的公平是不太可能的,那么如何缩小城乡收入差距,我们应该按照影响城乡收入差距的原因及差距的具体特点入手:(1)教育机会不均等是导致城乡收入差距的一个关键因素,为缩小这种不平等,国家必须对农村地区增加教育投入,增加农村低收入人群接受教育的机会。同时实施农民工技能培训工程,逐步培养使用于现代科技进步的技工人才。(2)地区经济发展不平衡也是导致城乡收入差距的一个重要原因。针对中、西部地区经济发展水平和收入水平落后于东部地区的现状,各地政府应因地制宜发展具有地区特色的产业经济、农村经济。(3)提高农村最低生活保障水平,缩小城乡城乡保障制度的差别。
参考文献:
1. 郭剑熊.人力资本、生育率与城乡收入差距的收敛.中国社会科学,2005,(2):27-37.
2. 姚先国.中国劳资关系的城乡户籍差异.经济研究,2004,(7):82-90.
3. 段景辉,陈建宝.我国城乡家庭收入差异影响因素的分位数回归解析.经济学家,2009,(9):46-53.
4. Machado J, Mata J. Counterfactual Decomposition of Changes in Wage Distributions Using Quantile Regression.Journal of Applied Econometrics,2005,(20):445-465.
5. 陈建宝,段景辉.中国性别工资差异的分位数回归分析.数量经济技术经济研究,2009,(10):87-97.
6. Rubin D.Estimating Causal Effects of Tr- eatment in Randomized and Nonrandomized Studies. Journal of Educational Psychology,1974,(66):688- 701.
基金项目:国家自然科学基金资助项目(项目号:11226165)。
作者简介:周晓华(1963-),男,汉族,重庆市人,中国人民大学统计学院教授、博士生导师,研究方向为生物统计;韩开山(1978-),男,汉族,山西省夏县人,中北大学理学院讲师,中国人民大学统计学院博士生;黄群(1972-),女,汉族,四川省眉山市人,北京城市学院副教授,研究方向为经济统计。
收稿日期:2014-12-21。
猜你喜欢
商业经济研究(2017年2期)2017-02-28
商业经济研究(2016年23期)2017-01-10
商业经济研究(2016年22期)2016-12-27
西北农林科技大学学报(社会科学版)(2016年6期)2016-12-07
知音励志·社科版(2015年12期)2016-02-16
人口与经济(2015年5期)2015-09-24
中国人口·资源与环境(2015年9期)2015-09-19
人口与经济(2015年4期)2015-08-03
财经理论与实践(2015年2期)2015-04-16
软科学(2014年12期)2015-02-03
