
融入双语最大名词组块的树-串统计机器翻译模型
2015-04-18 07:18李业刚
山东理工大学学报(自然科学版) 2015年6期
李业刚,解 红,周 洁,李 艳
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
融入双语最大名词组块的树-串统计机器翻译模型
李业刚,解 红,周 洁,李 艳
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
在统计机器翻译中融入语言学知识具有重要的理论研究和应用价值.在考察了具有丰富的句法和语义信息的双语最大名词组块后,提出和实现了在树-串统计翻译模型中融入双语最大名词短语的统计机器翻译框架.通过在汉-英测试集的实验证明:相比基线模型,采用所述框架的翻译模型的BLEU值提高了1.66%,而且翻译速度也得到了提高.
统计机器翻译;树-串翻译模型;双语最大名词组块;句子骨架
树-串统计机器翻译模型在源语言中引入句法结构,以此限制翻译路径,约束词语的活动范围.但是完全句法分析也是一个复杂度很高的自然语言处理任务,自身远远没有达到完美的程度.以汉语为例,在宾州中文树库上,采用自动词性标注结果,汉语的分析精度达不到80%.这是基于语言学语法的翻译系统性能提升的最大瓶颈.虽然N-BEST[1]、句法森林[2-3]等[4-5]方法通过扩大搜索空间,增强了对句法知识的容错能力,但是翻译模型要通过计算机实现.随着语料库的规模越来越大,更大的搜索空间,更高的计算复杂性,最终将造成翻译时间越来越长,翻译性能提高的代价是翻译时间倍增.因此,保证树-串统计机器翻译系统对句法知识的容错能力,有效地融入合适的句法知识,就成了统计翻译模型要解决的主要问题.
为了句子中的降句法分析中嵌套短语带来的干扰,提高句法分析的性能,从而提高机器翻译的译文质量.本文提出了一种分而治之的策略,利用一体化的BMNC识别对齐算法获取高质量的BMNC,在此基础上,把翻译模型分成双语最大名词组块(bilingual maximal length noun chunk,BMNC)翻译子模型和句子骨架(Skeleton)翻译子模型.
1 BMNC的定义及特性
最大名词短语[6](Maximal-length Noun Phrase, MNP)指的是不被其它任何名词短语所包含的名词短语,如果能够高质量的识别出句子中的MNP,可以剔除MNP中的嵌套短语等复杂结构给句子结构分析带来的结构歧义,有利于更好的把握句子结构.
在汉英平行语料中,汉英MNP经常会存在不完全互译的情况,例如:
上海浦东开发与法制建设同步.
The development of Shanghai 's Pudong is in step with the establishment of its legal system.
在汉语句子中,“上海 浦东 开发 与 法制 建设”被识别为一个最大名词短语,而其互译的成分,在英语句子中识别为“The development of Shanghai 's Pudong”和“the establishment of its legal system”两个不连续的名词短语.
在这种情况,传统定义的MNP在双语中出现了偏差,不完全互译,无法满足机器翻译的需求.因此我们在传统MNP定义的基础上,提出了双语最大名词组块(Bilingual Maximal-length Noun Chunks, BMNC),它不仅具备传统MNP的特性:是一个完整的句法单元和语义单元,有稳定的外部修饰结构,而且要具备双语间的互译性和识别的一致性.因此,BMNC不同于传统的MNP,在单语句子中它有可能被其它名词短语包含,但是它不能被可互译的其它名词短语所包含.定义1描述了汉英BMNC的形式化定义.
定义1 存在汉英句对SP=
{
ws0,ws1,…,wsm,MNCe=wt0,wt1,…,wtn;
MNCc↔MNCe;m (1)非空.MNCc≠null,MNCe≠null (2)互译.MNCc↔MNCe,MNCe和MNCc在翻译上的具有充分转换性. (3)继承.MNCc和MNCe的语义核心均有一个名词或者名词短语组成,且其成分特征决定了MNCc和MNCe短语结构的特征. 根据BMNC定义,汉语句子“上海 浦东 开发 与 法制 建设”中,“上海 浦东 开发”(对应英语BMNC“The development of Shanghai 's Pudong”)和“法制 建设”(对应英语BMNC“the establishment of its legal system”)被识别为两个双语对齐的BMNC. 在树-串统计机器翻译模型中,句法分析错误会传递到解码过程,影响译文的质量.为了降低句法分析错误对译文质量的影响,我们提出了融入BMNC的树-串统计翻译模型(BMNC & Skeleton),模型框架如图1所示.该模型把句子翻译转化为BMNC翻译和句子骨架(Skeleton)翻译.首先,在源语言端进行BMNC识别,把所有BMNC抽取出来组成BMNC集合;在原来的句子中用BMNC的中心词或者词性来代替BMNC短语整体,形成Skeleton.然后分别训练翻译模型,把BMNC集合和Skeleton翻译成目标语言.最后,在目标语言端,组合独立翻译的BMNC和Skeleton,形成最终的翻译结果. 图1 融入MNC的翻译框架 用中心词来代替短语整体要满足两个约束条件:其一,源语言端和目标语言端语义上相对应的两个短语是句法独立的,不存在一端短语连续,另一端不连续的现象;其二,在各自的句子中句法功能相同,一端是名词短语,另一端也应具有名词的功能.因为不同语言之间存在结构差异,这一前提不一定能够满足.为此,我们统计分析了双语对照树库CTB1.0(English Chinese Translation Treebank)的4175个句子.分析发现,BMNC具有较好的稳定性,98%以上的BMNC都符合上述约束. 我们统计了CTB5.0《新华日报》语料中所有的9,493汉语句子,共含有24,436个BMNC,占所有词的57.4%.BMNC的平均长度5.4词,其中,长度大于7的占了22.9%.把BMNC用中心词代替后,汉语句子的平均长度降低将近一半,由24.2个词缩减到12.9个词.在树-串翻译中,翻译时间主要包含解码时间和源语言句法分析耗费的时间,翻译时间复杂度是句子长度的三次方,显而易见,用中心词代替BMNC,将大幅度的降低翻译时间耗费. 在识别出MNC后,把句子中的BMNC用其中心词代替,形成句子骨架,可以有效降低翻译时间.但是,实际情况中,汉语词和英语单词并不是完全一一对齐的,还会存在一对多、多对一,甚至是多对多的情况.也就是说中心词会存在不完全互译的情况,这就会造成句子骨架并不是充分互译的.例如: [新区/n BS 管委会/ n IH] [the/DT BS new/JJ IS region/NN IS 's/POS IS management/NN IS committee/NN IH] 汉语端BMNC的中心词“管委会”对应的英语翻译是“management committee”,而不只是英语端的BMNC中心词“committee”,如果只是用中心词BMNC,就会形成两个并不是完全互译的英汉句子骨架,给后续的翻译带来衍生错误.为了避免这样的错误,我们的策略是用中心词的词性代替原来的中心词. BMNC对齐虽然是识别的后续过程,但对齐信息却能辅助BMNC的识别,修正已有的识别错误.因此,将对齐信息反馈给识别过程会提高识别的质量.针对汉英双语语料,我们建立起BMNC识别与对齐相结合的整体框架,提出一种汉英BMNC一体化识别对齐模型,使双语实体对齐具有修正识别的功能,实现二者性能的同时提高. Align_Conf(MNPci,MNPej)= (1) 式中:count(MNPci,MNPej)表示MNPci和MNPej之间对齐的词的数量,count(MNPci),count(MNPej)分别表示MNPci和MNPej中包含的词的数量. (2) (3) 其中,ti,ti-1,ti+1表示wi的词性,wi前一个词的词性和wi的后一个词的词性;count(*,*,*)表示词性组合出现的次数. (4) 我们采用词性组合共现、互为翻译和长度关联3个特征来对双语对齐置信度进行建模. 词性组合共现特征指的是组成BMNC的词的词性组合在整个语料库中的共现频率.具体计算如公式(5)所示. (5) (6) (7) 其中: count(x)表示x包含的字符数. 4.1 实验设置 实验使用了北京市海量语言信息处理与云计算应用工程技术研究中心提供的100,000句子级对齐的汉英平行语料作为树-串翻译模型的训练语料,东北大学NiuTrans开源统计机器翻译系统的训练语料作为最大熵特征参数训练语料.测试语料使用了2002 NIST机器翻译汉英测试集.我们用基于IBM models的GIZA++[8]获得了汉英和英汉两个方向的词对齐. 4.2 实验结果及分析 实验选用了东北大学开发的NiuTrans中的tree-to-string模型作为翻译基线模型.分别考察了金本位和自动识别的BMNC两种不同的情况在测试集的表现(表1).其中:Model1表示NiuTrans的tree-to-string模型,Model2表示金本位的BMNC识别的BMNC&Skeleton翻译模型,Model3表示自动识别的BMNC基础上的BMNC&Skeleton翻译模型. 表1 不同模型的翻译性能比较 模型MNPs正确率/%BLEU/%Model1-24.37Model210025.2Model382.124.64 从实验结果可以看出,基于金本位的BMNC识别的Model2的BLEU值比基线翻译模型Model1提高了0.83%.由于识别错误的累积,基于自动识别的BMNC翻译模型Model3的BLEU值虽然比Model1高了0.27%,但是相比Mode2,则低了0.56%.也就是说,BMNC的识别性能对翻译的结果是有影响的,进一步提高BMNC的质量可以提升机器翻译的性能. 为了进一步的探讨BMNC&Skeleton翻译模型的翻译性能,我们测试集上进行了进一步的实验,把整个测试集分为10词以下,10到20词和20词以上三个不同的测试集,分别进行翻译实验,实验结果如表2所示. 表2 不同句长测试集上的翻译性能比较 模型BLEU/%<10[10,20)≥20Model129.1224.8120.35Model328.9325.3822.01 从实验结果来看,虽然随着句子长度的增加,两个模型的翻译性能都表现除了降低的趋势,但是Model3降低的幅度要低于Model1,尤其是在句子长度超过20的测试集上,Model3的BLEU值比Model1提高了1.66%,这说明了我们提出的翻译框架是有效的.但是,我们也看到在10词以下的测试集中,Model3的表现差强人意,这可以归结为短句中含有BMNC的可能行比较小,这时Model3的优势无法体现. 树-串翻译模型的翻译时间主要有两大部分,源语言句法分析时间和翻译解码时间.对于翻译系统来说,翻译时间也是一个重要的衡量指标.不同句长的模型的翻译时间比较见表3.从表3可以看出,Model3的时间耗费远远低于Model1,在长句翻译中尤其明显. 表3 不同句长的翻译时间比较 模型句法分析时间/s·每句翻译解码时间/s·每句<10[10,20)≥20<10[10,20)≥20Model10.310.480.630.610.971.32Model30.290.390.490.590.750.98 本文提出了在树-串翻译模型中引入双语最大名词组块的统计机器翻译框架.首先利用BMNC识别对齐一体化模型从双语对齐语料中获取高质量的BMNC;然后采用分而治之的策略,把翻译分成BMNC翻译子模型和句子骨架翻译子模型,分别训练翻译模型,把BMNC集合和句子骨架翻译成目标语言;最后,在目标语言端,组合独立翻译的BMNC和句子骨架形成最终的翻译结果.实验结果表明,使用我们的方法,在测试集上提升了树-串翻译模型的BLEU值,在较长的句子中效果更明显.另外,BMNC和句子骨架分治的思想对诸多依赖句法分析结果的自然语言处理任务都有一定的参考价值. [1] Xiao T, Zhu J B, Zhang H,etal. An empirical study of translation rule extraction with multiple parsers [C]// Huang C R, Dan Jurafsky. Proceedings of 23th InternationalConference on Computational Linguistics. Beijing, China: Coling 2010 Organizing Committee, 2010: 1345-1353. [2] Mi H T, Huang L, Liu Q. Forest-based translation[C]// Moore J D, Teufels, Allan J,etal. Proceedings of Association for Computational Linguistics. Columbus, Ohio: Association for Computational Linguistics, 2008:192-199. [3] Zhang H, Zhang M, Li H Z,etal. Forest-based tree sequence to string translation model[C]// Su K Y, Su J,Wiebe J,etal. Proceedings of Association for Computational Linguistics IJCNLP, Suntec. Singapore: Association for Computational Linguistics, 2009:172-180. [4] Zhu J B, Xiao T. Improving decoding generalization for tree-to-string translation[C]// Matsumoto Y, Mihalcea R. In Proceedings of Association for Computational Linguistics. Portland: Association for Computational Linguistics, 2011: 418-423. [5] Xiao T, Gispert Adrià de, Zhu J B,etal. Effective incorporation of source syntax into hierarchical phrase-based translation[C]// Tsujii, Jan Hajic. Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. Dublin Dublin City University and Association for Computational Linguistics, 2014: 2064-2074. [6] 周强,孙茂松,黄昌宁.汉语最长名词短语的自动识别[J].软件学报,2000,11(2):195-201. [7] Li Y G, Huang H Y. Automatic identifying of maximal length noun phrase[C]// Li E Y, Yang F C. Proceedings of 2nd IEEE CCIS. Hangzhou: Institute of Electrical and Electronics Engineers, Inc., 2012:1445-1448. [8] Och F J, Ney H. Improved statistical alignment models[C]// Brennan S E. Proceedings of the 38th Annual Meeting on Association for Computational Linguistics. Hong Kong: Association for Computational Linguistics, 2000: 440-447. (编辑:姚佳良) Tree-to-string model integrated with bilingual maximal-length noun chunk LI Ye-gang, XIE Hong, ZHOU Jie, LI Yan (School of Computer Science and Technology, Shangdong University of Technology, Zibo 255049, China) It has important theoretical and application value to promote the statistical machine translation by integrating meaningful linguistic knowledge effectively. After inspected structural characteristics of maximal-length noun chunks with rich syntactic and semantic information, we proposed a statistical machine translation model which integrated with bilingual maximal-length noun chunks for improving an existing tree-to-string machine translation system. Under this scenario, we experimented on a Chinese-English corpus and achieved an improvement of 1.66 BLEU percentage point over a non-adapted state-of-the-art tree-to-string baseline system, and had a significant improvement over the baseline method on decoding speed in practice. statistical machine translation; tree-to-string translation model; bilingual maximal-length noun chunk; sentence skeleton 2014-12-07 国家重点基础研究发展计划(2013CB329303); 国家自然科学基金资助项目(61132009) 李业刚,男,lyg8256@bit.edu.cn 1672-6197(2015)06-0011-05 TP391 A2 BMNC&Skeleton翻译模型框架
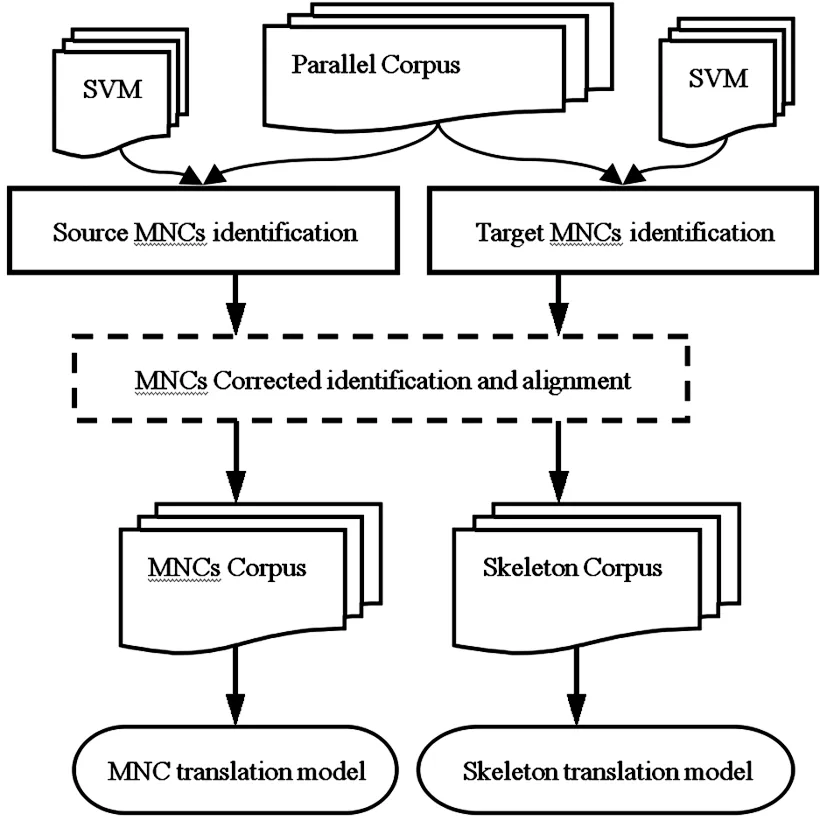
3 BMNC获取

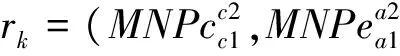
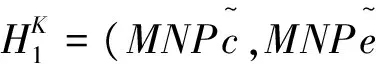
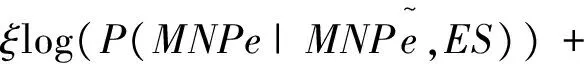
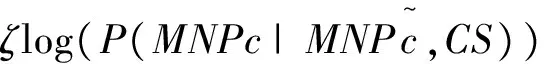
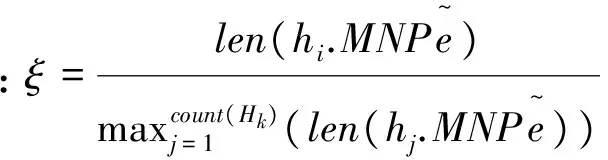
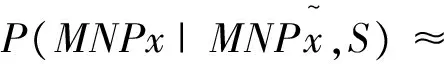
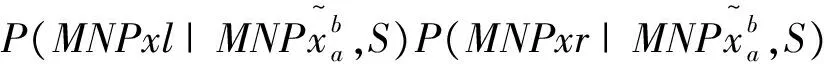
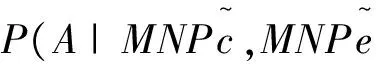
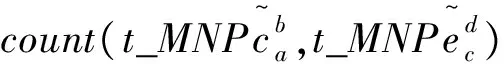
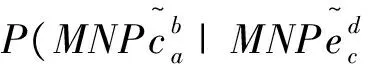
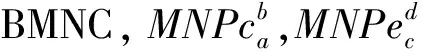
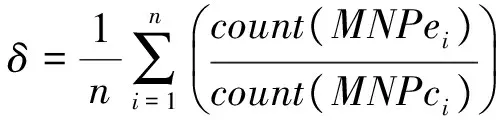
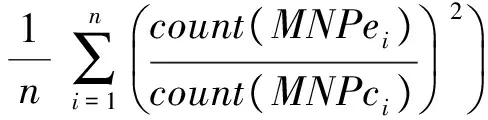
4 实验结果及分析



5 结束语
猜你喜欢
中国海上油气(2021年2期)2021-06-09
疯狂英语·新悦读(2020年2期)2020-04-29
中学课程辅导·教师通讯(2020年22期)2020-02-04
华北电力大学学报(社会科学版)(2016年4期)2016-12-01
外语教学理论与实践(2016年1期)2016-06-11
中国海上油气(2016年1期)2016-06-09
中文信息学报(2016年3期)2016-05-04
语言与翻译(2014年1期)2014-07-10
长春大学学报(2013年4期)2013-08-15
外语学刊(2011年4期)2011-01-22
