
多类支持向量机分类技术及实证
2015-02-18 04:56韩兆洲林少萍郑博儒
统计与决策 2015年19期
韩兆洲,林少萍,郑博儒
(暨南大学 经济学院统计学系,广州 510632)
0 引言
支持向量机(Support Vector Machine,简称SVM)是由Vapnik与其领导的贝尔实验室研究小组开发研究的一种新的机器学习技术,诞生于20世纪60年代,成熟于90年代中期,成为机器学习领域新的研究热点,已被广泛运用于航空、医疗、水利、金融等相关领域。支持向量机模式识别准确率与预测精确度均高于聚类分析、判别分析、神经网络等方法。支持向量机的技术特色,通过核函数实现特征空间映射,有效地解决了分类中普遍存在的小样本、非线性、高维数和局部极小点等问题。目前支持向量机在处理分类和回归问题上已相对成熟,知识架构纵深拓展,适用于各种研究领域,但在多类问题上尚未被广泛应用,算法设计与实证分析仍然鲜见。
我国中小企业已经成为社会经济发展的重要支柱之一。据统计,我国中小企业已占企业总数的99%以上,实现工业总产值比重为60%。中小企业的生产经营方式契合了人类自身的多样化需求,具有分散性、家庭化等特色,在可持续发展模式下的中国经济市场,中小企业快速健康发展,能有效解决就业,促进科技进步,实现社会稳定。然而,融资难题一直成为制约中小企业发展的瓶颈。政府对中小企业的资金支持有限,如何完善中小企业信用担保体制,建立银企信贷支持系统仍是解决融资难题的关键。
本文创新性地应用多类支持向量机技术,通过对中小企业信用风险的综合评价实例,从多类角度识别企业的信用归类,不仅为政府部门和银行机构提供信贷依据,同时,也将促进企业健康发展,营造符合自身的发展模式。
1 多类支持向量机分类技术理论依据
目前支持向量机在多类问题应用上以及算法设计上仍然鲜见。如何将支持向量机技术从二类识别拓展到多类识别,这不仅具有重要的理论研究意义,更具有重要的实践操作价值。本文认为解决该难题,有两种方法可以考虑:一是在最优化问题中考虑多类识别,如1998年Weston提出的全局优化法,该方法成倍地增加了计算的复杂度,可行性较低;二是将多类问题转化为多个二类问题,该方法虽然加大了程序的运算量,但没有方法上的限制,实用性较强。本文将采用第二种方法将二类拓展到多类,属于方法上的创新,并将研究对象深入到具有代表性的中小企业,使研究更富针对性。
1.1 二类支持向量机(B-SVM)
构造序列(x1,x2,…,xN),N为训练样本数,其中,因素xi为第i个样本的各指标值,表示为xi=(xi1,xi2,…,xiM),其中M为指标总数,假定训练样本的分类结果为Y=(y1,y2,…,yN),其中,yi=1或 -1,表示每个样本的二类分类结果。二类支持向量机的基本思想是获取超平面w·x+b=0将多维特征空间X精确划分,其中满足方程w·x+b=±1的向量x称为支持向量。当超平面对特征空间不完全可分时,通过添加松弛项ξi≥0,使特征空间在ξi的误差范围内完全可分,并建立约束条件:

为了获取最优超平面,必须使得二类间距最大。已知支持向量间距为2‖w‖,因此,最优化目标等价于求的最小值。另外,由于增加了松弛项ξi,折衷考虑最小错分样本和最大分类间隔,引入常数C对错分样本进行惩罚,归结出最优化目标:

求解上述最优化问题,引入Lagrange乘子αi≥0,i=1,…,N,满足0≤αi≤C,运用对偶原理,求得最优化分类函数为:


结合训练结果,将测试样本值输入式子(4)得出预测结果,并于初始分类进行对比分析,可得出支持向量机分类技术的预测准确度。
1.2 多类支持向量机(M-SVM)
一般而言,二类支持向量机技术广泛适用于模式识别领域,但对于信用综合评价问题,二类方法却远远不足,有必要向多类方向拓展。在统计学习领域,多类分类器的设计已然成为新的研究热点,而目前较为成熟的设计方法有二类组合法、导向无环图、二叉树、纠错输出编译法。本文主要运用二类组合法对中小企业进行信用评级分类,其分为“一对多”和“一对一”两种。
(1)“一对多”法,简称OAA(one against all)。是指对于M类问题,构造M个BSVM,在第i个BSVM中将第i类的训练样本归为一类,其他训练样本归为另一类,训练得出M个决策函数的方法。该方法对样本进行测试时,将指标值输入,可得到M个输出结果,若在其中的第k个BSVM输出“+1”,则该样本属于第k类;若输出结果中均没有出现“+1”或者不止出现一个“+1”,则找出其中g(x)的最大输出值,对应的BSVM则为该测试样本所属的类,因此,该方法存在一定的决策盲区。
以四类分类器为例,如图1(a)所示,区域G1、G3、G7、G9的判别结果中包括两个“+1”,需根据正值大小进行类型识别;区域G2、G4、G6、G8的判别结果中只有一个“+1”,分别归属于D、A、B、C类;区域G5的判别结果中不存在“+1”,即所谓的决策盲区,需根据负值大小进行识别。
(2)“一对一”法。是指对于N类问题,将训练样本中任意两类抽出构造BSVM,以此计算,总共构造M(M-1)/2个BSVM,整合全部则为一对一多类支持向量机的方法。其中,对于每个BSVM,通过最优化理论计算决策函数,即总共有M(M-1)/2个决策函数。将要测试的样本数据输入这些函数,得出M(M-1)/2个结果。结果中出现频率最高的类即为该样本所属的类。
以四类分类器为例,如图1(b)所示,利用六条直线表示表示6个BSVM的决策函数,判别结果显示,区域G1、G2、G3、G4、G17、G18属于D类;区域G5、G6、G7属于C类;区域G8、G9、G13、G14、G15、G16属于B类;区域G10、G11、G12属于A类,不存在决策盲区。
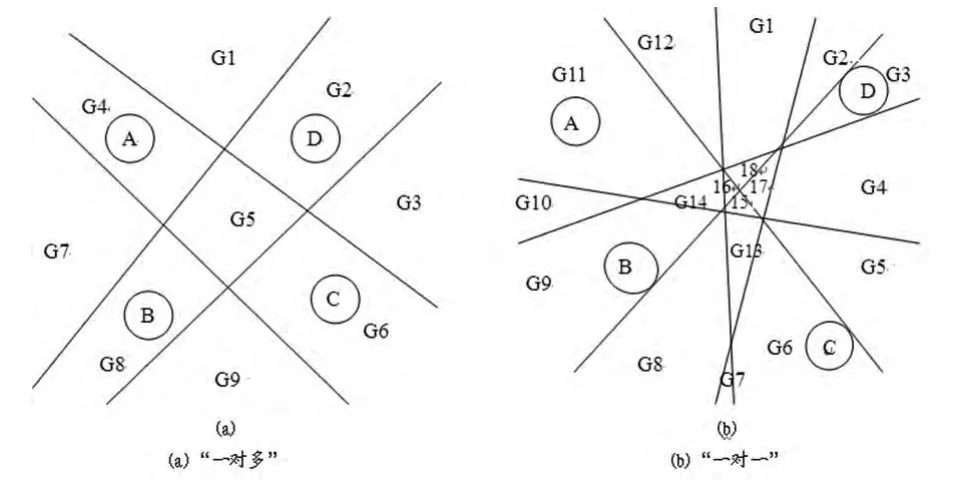
图1 支持向量机四类分类器区域划分情况
2 多类支持向量机实证基础
2.1 构建中小企业信用风险评价指标
指标构建是综合评价的基本前提,本文以企业整体经营规模、财务状况、现金流量为主,按照指标体系构建的适应性、针对性、可测性、全面性和非相关性等原则,参考国际权威投资信用评估机构——穆迪投资者服务公司(Moody's Investors Service)企业资信财务评估指标,初选了经济实力、偿债能力、营运能力、盈利能力、成长能力、现金流量等6大项20个财务指标。并从财经网站上获取评估对象(深证交易所中小企业板块信息技术行业50家企业)的财务数据,通过数据的预处理,其结果显示,流动比率和速动比率的相关系数为0.996,流动比率和现金比率的相关系数为0.985,速动比率和现金比率的相关系数为0.994,流动资产周转率和总资产周转率的相关系数为0.971,销售净利率和成本费用利润率的相关系数为0.983,经营现金净流量对负债比率和现金流量比率的相关系数为0.998,具体结果限于篇幅略去。为了评价结果的精确性,剔除相关程度高的累赘指标,如流动比率、现金比率、总资产周转率、成本费用利润率、经营现金净流量对负债比率等5个指标。最终确定中小企业6大项15个信用风险指标体系如下:
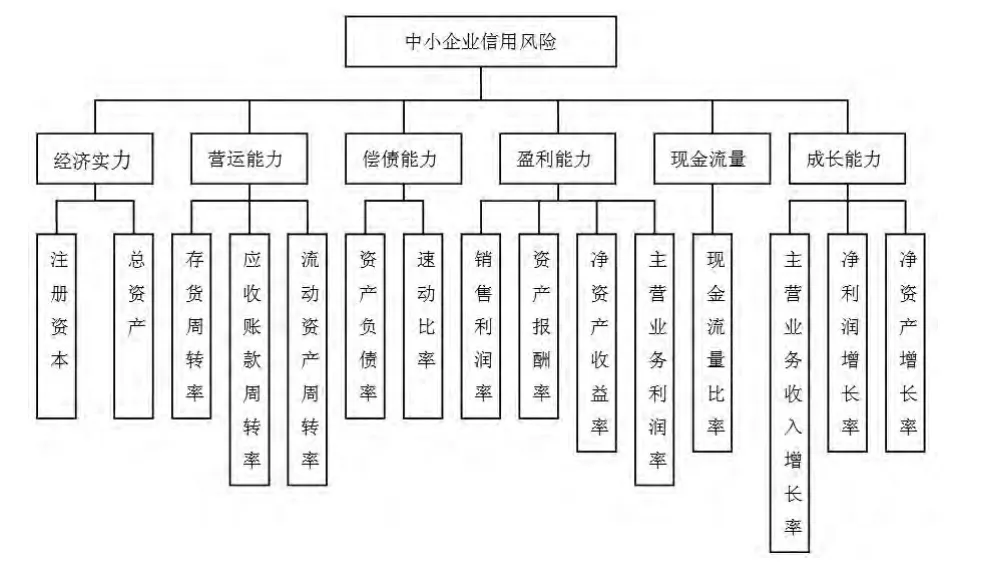
图2 中小企业信用风险评价指标体系
2.2 中小企业信用水平的初步评估
本文考察对象为深圳证券交易所中小企业板块信息技术行业中50个企业,数据取自2010年年度财务报表。经查阅,还没有相关机构对以上企业进行信用评估,企业的信用水平排名也没有得到初步认证。根据支持向量机多类分类的算法要求,训练样本必须事先归类,为此,必须先对上述企业的信用水平进行初步排名。为使初评结果更具合理性,下面综合了主成分分析法、因子分析法、层次分析法、专家评估法等四种方法,并对结果进行组合评价,得出企业综合排名如下表,并以30%、30%、30%、10%的比重将企业分为四类,即信用水平高、中、低、差(即A、B、C、D)。
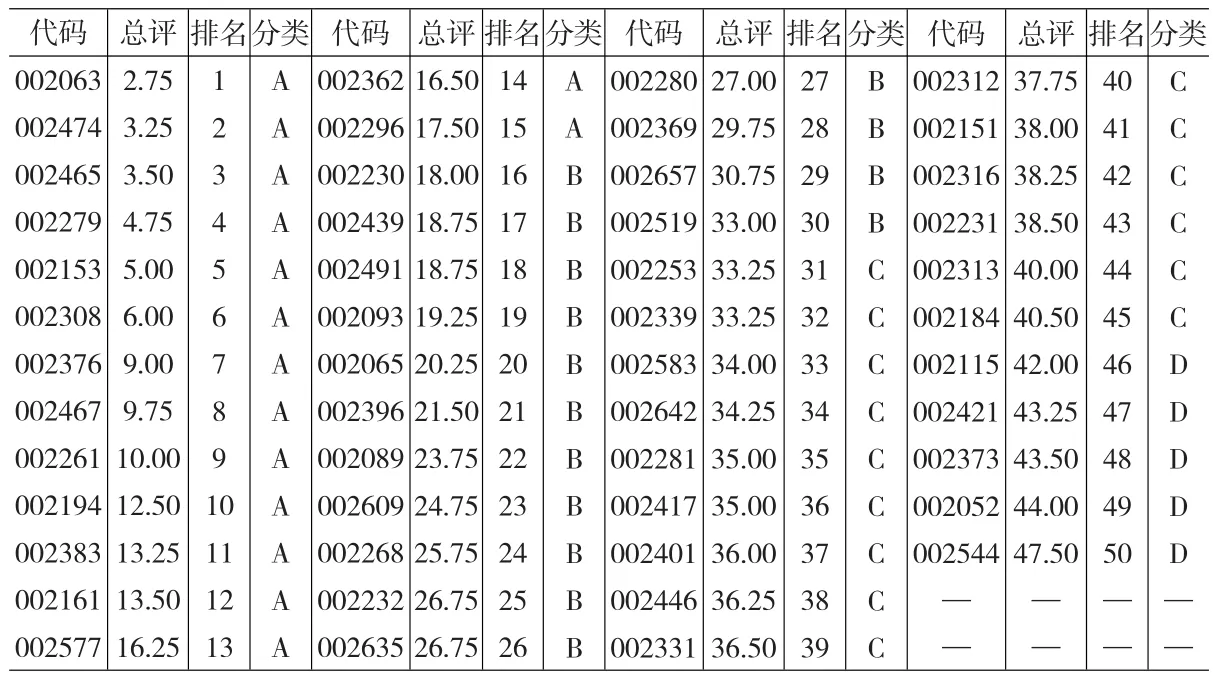
表1 研究样本的初始分类结果(组合评价法)
3 多类支持向量机算法设计
3.1 样本选取和数据再处理
针对本数据样本的特点,若以规格化后数据为输入值,即为50×15的矩阵,列数太多,通过支持向量机算法运行,极有可能出现过度拟合现象,即不管数据质量如何,分类结果正确率均达到100%。为了满足算法的可行性,对数据进行第二次处理,将6大项的各个小项数值加权(权重以层次分析法方案层权重为准),合计各大项的得分,将矩阵进行降维,变成50×6的矩阵。随机选择35个样本作为训练样本,包括10个A类、10个B类、12个C类、3个D类;另外的15个样本作为测试样本。
3.2 算法步骤

表2 “一对多”多类分类器输出结果
(1)“一对多”法:建立4个BSVM,分别为[A Vs(B,C,D)],[B Vs(A,C,D)],[C Vs(A,B,D)],[D Vs(A,B,C)]。得出各自的分类决策函数,当采用线性方法时,其中φ(xj)=xj。将测试样本数据作为输入值,以各决策函数输出结果作为测试企业信用评价的依据。
(2)“一对一”法:建立4×(4 -1) 2=6个BSVM,分别为(A Vs B),(A Vs C),(A Vs D),(B Vs C),(B Vs D),(C Vs D),求出各自的决策函数,将测试样本数据输入各决策函数,判别输出结果中各类的频率,频率最大的则为该企业的归类。本文运用Markway软件中支持向量机功能模块,计算相应的输出值与分类结果如表2和表3。
4 多类支持向量机实证分析
4.1 “一对多”法多类分类器运算结果分析
分类结果显示,测试的准确率为10/15=66.7%,误判的样本均为A或C类样本,且测试结果均为类别B。其中,[B Vs(A,C,D)],[C Vs(A,B,D)]两个BSVM的训练精度明显比其他两个差,这在一定程度上是由于多样本组合如(A,C,D)和(A,B,D)的空间不连贯性所致。为了消除这种因素的影响,下面进行“一对一”多类分类。
4.2 “一对一”法多类分类器运算结果分析
分类结果显示,测试的准确率为10/15=66.7%,其中两个D类样本均上升为C类,另外汉王科技与雷柏科技下降为B类,银河电子从B类将为C类。从组合评价排名中可以看出,这三家企业均排在该类别信用水平的末端,存在降级的危险,分类的结果没有存在显著差错。上述分析充分显示了“一对一”多类分类器具有准确度高,综合评价性能强的特征。

表3 “一对一”多类分类器输出结果
5 结论与展望
(1)综上所述,将多类支持向量机分类技术应用于中小企业信用评价,与原始分类结果进行对比,得知“一对多”、“一对一”两种方法的精确度相近,但“一对一”方法更具参考价值。由此体现支持向量机技术的优越性,克服其它综合评价方法的主观性、小样本问题等缺陷,具有较高预测精度。
(2)通过多类支持向量机技术识别中小企业信用水平,在加深对企业经营水平、经营模式的认识的同时,对加强企业管理体制改革,从而提高企业的良性竞争力,建立依托于中小企业体系的政府或银行资金支持系统,具有重要的现实意义。
(3)本文将支持向量机中的二类拓展到多类,属于方法上的创新,并将研究对象深入到具有代表性的中小企业,使研究结果更富针对性。
(4)由于中小企业自身的特点,对其进行信用综合评价时,可进一步量化包括企业体制规模、管理组织因素、信用记录在内的定性指标,结合财务指标进行综合分析,使评价结果更加全面化。
[1]薛宁静.多类支持向量机分类器对比研究[J].计算机工程与设计,2011,(5).
[2]姚奕,叶中行.基于支持向量机的银行客户信用评估系统研究[J].系统仿真学报,2004,(4).
[3]汪晓玲.支持向量机在银行客户信用评估中的应用[J].科学技术与工程,2007,(8).
[4]肖文兵,费奇.基于支持向量机的个人信用评估模型及最优参数选择研究[J].系统工程理论与实践,2006,(10).
[5]刘闽,林成德.基于支持向量机的商业银行信用风险评估模型[J].厦门大学学报,2005,(1).
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
科技创新与应用(2020年6期)2020-02-29
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
航天返回与遥感(2014年5期)2014-07-31
