
基于AFSA-LSSVM的视频字幕定位模型
2014-11-20 08:18陈燕升任江涛黄达峰
电视技术 2014年5期
陈燕升,任江涛,黄达峰
(1.广东轻工职业技术学院 a.环境工程系;b.计算机工程系,广东广州510300;2.中山大学软件学院,广东广州510275)
随着网络技术发展,视频流剧增,不良的网络视频图像对社会的稳定和人们的身心健康产生不利影响,通过对视频信息的字幕进行定位,有利于对后续视频内容进行安全分析和检测,因此建立精确、高效的视频字幕定位模型成为了当前研究的热点[1]。
视频字幕定位实质上是模式识别中的二分类问题,即指将字幕块定义为“+l”,非字幕块定义为“-l”,对于每一个输入,如果其输出为正,则表示为字幕块;若为负,则为非字幕块。视频字幕定位主要包括视频字幕特征自动提取和选择、视频字幕分类器设计等步骤[2]。特征选择是视频字幕定位的基础,原始视频字幕特征包含大量冗余信息和对定位结果起“反作用”的噪声特征,若对视频字幕特征不加选择直接使用,不仅大大削弱了视频字幕分类器的分类性能,而且增加“维数灾难”出现概率,对视频字幕定位结果产生不利影响[4]。当前视频字幕特征选择算法主要有:主成分分析、穷举算法、遗传算法、粒子群优化算法、免疫算法以及相关的改进算法[5]。穷举算法计算量大、搜索效率低,不能满足视频字幕定位的实时性;主成分分析可以进行视频字幕特征降维,但是可解释性差;遗传算法、粒子群优化算法、免疫算法等均存在收敛速度慢、极易陷入局部极值等缺陷,难以找到全局最优的视频字幕特征[6]。人工鱼群算法(Artificial Fish Swarm Algorithm,AFSA)是一种模拟鱼群觅食行为的群智能算法,具有鲁棒性强、简单、易实现等优点,在组合优化领域取得了不错的应用效果[7]。视频字幕特征选择是一个大规模空间搜索的组合优化问题,因此可借助于AFSA进行求解。当前视频字幕分类器主要基于机器学习算法进行设计,主要有神经网络、支持向量机等[8]。神经网络基于经验风险最小化原则和“大样本”理论,当不能满足“大样本”要求时,易出现过拟合、分类能力差等缺陷。最小二乘支持向量机(Least Square Support Vector Machine,LSSVM)是一种解决高维、非线性分类问题的机器学习,较好地克服了神经网络泛化推广能力差、支持向量机训练时间长等缺陷,泛化能力优异[9]。因此本研究选择LSSVM建立视频字幕定位的分类器。
为了提高视频字幕定位精度,针对视频字幕定位特征选择问题,提出一种AFSA和LSSVM相融合的视频字幕定位型(AFSA-LSSVM)。首先用近邻传播聚类算法对视频帧进行分解,并用图像投影方法进行定位得到一个备选字幕区域集,然后提取备选字幕区域的特征参数,并采用AFSA选择最优的特征子集,最后将最优特征子集输入到LSSVM进行学习和分类,得到视频字幕定位的结果。仿真结果表明,AFSA-LSSVM提高了视频字幕定位精度和效率。
1 视频字幕定位模型
1.1 获取备选字幕区域
采用近邻传播聚类算法把视频图像帧中的边缘分解到若干个子图当中,将具有不同颜色的字幕边缘和背景边缘分开。通常情况下,字幕区域的边缘信息比较密集,同时也含有丰富的笔划信息,可以通过文献[10]的方法对边缘子图进行水平和垂直投影来寻找包含字幕的备选字幕区域,然而这样检测到的字幕区域中还包含了一些错误的字幕区域,所以需要后续步骤对字幕区域作进一步的识别。视频帧的分解结果如图1所示。

图1 视频帧的分解结果
1.2 提取备选字幕区域的特征
1)对备选字幕区域进行边缘检测,得到 0°,30°,60°,90°,120°以及 150°方向的边缘图,共得到 6 个方向的边缘图。
2)分别计算6个边缘图的均值、方差、能量、熵、惯性矩以及非相似性这6个统计特征,共得到36个特征参数。
设边缘图的灰度图像的大小是M×N,点(i,j)的灰度值为f(i,j),则字幕区域均值ξ和方差δ2为

采用灰度共生矩阵可以描述在角度θ方向上,相距为s、灰度分别为i和j的两个像素,它们的频率相关矩阵pij(s,θ)的 θ选择为 6 个离散的方向 0°,30°,60°,90°,120°,150°,而s可以取从 1 到图像大小的值N。能量(E)、熵(I)、惯性矩(J)、非相似性(D)定义为

1.3 AFSA选择最优字幕特征
按照上文所述提取了36个字幕特征,这些特征可能包含大量冗余信息和对定位结果起“反作用”的噪声特征,若对这些视频字幕特征不加选择直接作为分类器的输入,不仅大大削弱了视频字幕分类器的分类性能,而且增加“维数灾难”出现概率,对视频字幕定位精度和效率产生不利影响,因此本文采用AFSA进行视频字幕特征选择。
1.3.1 人工鱼群算法
人工鱼群算法(AFSA)模仿鱼群的觅食和追尾行为,搜索能力强,且搜索速度快,几种典型行为如下:
1)觅食行为的数学表达式为

式中:X i为人工鱼当前状态;Yi为食物密度;Rand()为(0,1)范围内的随机数;Step为移动步长。
2)聚群行为的数学表达式为
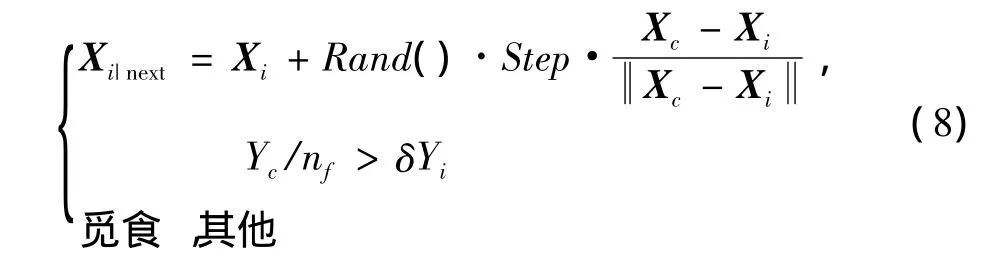
式中:δ为拥挤度因子;nf为伙伴数目;X c为中心位置。
3)追尾行为的数学表达式为
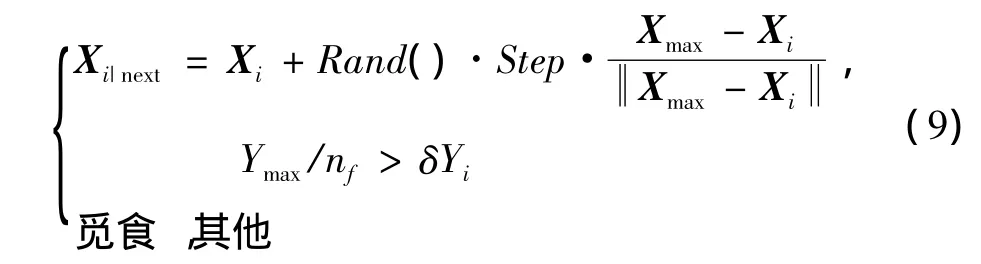
式中,Xmax表示食物浓度最高Yj的人工鱼位置。
4)公告板。公告牌是用于记录最优人工鱼的状态。
1)收集视频字幕数据,采用近邻传播聚类算法对视频帧进行分解,并用图像投影方法进行定位得到一个备选字幕区域集。
2)提取备选字幕区域的36个特征参数,并对特征进行归一化处理

式中,xi和分别为原始特征值和归一化后的特征值。
3)初始化人工鱼参数,主要有位置、移动步长Step、种群规模n、拥挤度因子 δ、最大迭代次数max_iterate等。
4)在可行域范围内随机生成n条人工鱼,并设置初始迭代次数max_iterate=0。
5)对初始鱼群的个体当前位置食物浓度值(FC)进行计算,然后对它们进行排序,选择FC值最大的人工鱼个体进入公告板。
由此看来,在分析新闻语篇时,光注重语篇内部衔接是远远不够的,应把语篇置于社会语境中加以人际意义的分析注解,这样才能完全吃透文本。
6)评价某条人工鱼的觅食、追尾和聚群行为所得的结果,若执行某个行为后,人工鱼的状态优于当前状态,则该人工鱼向此方向前进一步,接着转到步骤8)执行。
7)产生一个随机数r,若r<Pfb,则人工鱼执行随机行为,否则执行反馈行为,向公告牌中最优方向移动一步,并得到当前解域范围内的最好的人工鱼状态。
8)更新公告牌,将步骤7)中得到的最好人工鱼状态记入公告牌。
9)判断算法结束条件,如果达到最大迭代次数,则结束算法,并输出公告牌中的人工鱼状态,即为最优视频字幕特征子集,否则passed_iterate=passed_iterate+1,转向步骤6)执行。
10)根据最优视频字幕特征子集对最优视频字幕训练集和测试集进行特征约简,得到约简后的训练集和测试集。
11)将特征约简后的最优视频字幕训练集送到LSSVM进行训练,建立最优视频字幕定位模型。
12)将约简后的测试集输入到已建立的最优视频字幕定位模型进行测试,以验证模型的性能。
1.4 视频字幕的定位流程
基于AFSA-LSSVM的视频字幕定位流程为:首先对视频字幕定位训练集数据进行预处理并提取原始特征,利用LSSVM建立视频字幕定位分类器对原始特征子集进行评估,然后通过鱼群的觅食、聚群及追尾行为,快速找到最优特征子集,并根据选择的最优特征子集对训练集和测试集进行特征约简,最后将特征约简后的训练集送到LSSVM进行训练,建立视频字幕定位模型,并对特征约简后的视频字幕进行定位检测。AFSA-LSSVM的视频字幕定位框架如图2所示。
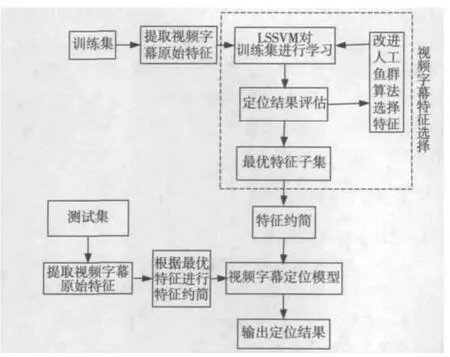
图2 AFSA-LSSVM的视频字幕定位框架
2 仿真实验
2.1 数据来源
从中央电视台选取了1 000帧不同的视频节目图像,包括主持人画面、体育新闻、广告和比赛画面,选取800帧组成训练集,用于建立视频字幕定位模型,其余200帧作为测试集,用于测试视频字幕定位模型的有效性。在PIV双核 CPU 3.0 GHz、2 Gbyte RAM,操作系统为 Windows XP,MATLAB 2012平台下进行仿真测试。
2.2 对比模型及评价标准
为了让AFSA-LSSVM模型的定位结果具有可比性,选择表1中的几种模型进行对比实验。模型性能评价标准为:视频字幕定位的正确率、误判率和定位时间。

表1 对比模型及说明
2.3 实验结果分析
2.3.1 各模型选择的特征子集
采用 LSSVM,GA-LSSVM,PSO-LSSVM,AFSA-LSSVM进行特征子集选择,得到最优特征子集见表2。从表2可知,采用特征选择方法,有效消除了冗余或无用特征,可以降低特征维数,大大地压缩了特征空间,因此在训练集和测试集输入到分类器进行学习之前,对特征进行选择是必须的。
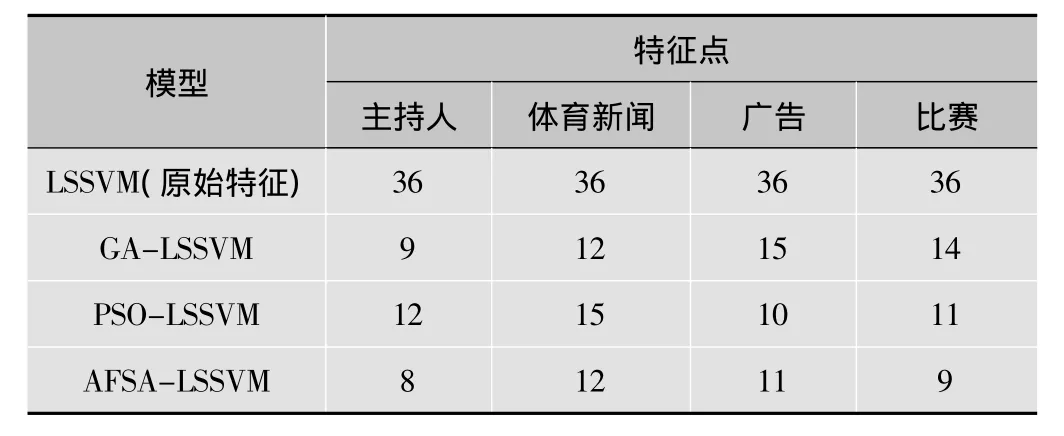
表2 各模型对不同类型视频字幕选择的特征数
2.3.2 视频字幕的定位性能对比
根据选择最优视频字幕特征子集分别对训练集和测试集进行视频字幕特征约简处理,然后将训练集输入到LSSVM进行学习和建模,最后采用建立的视频字幕定位模型对测试集进行测试,定位结果的正确率和误判率如图3和图4所示。
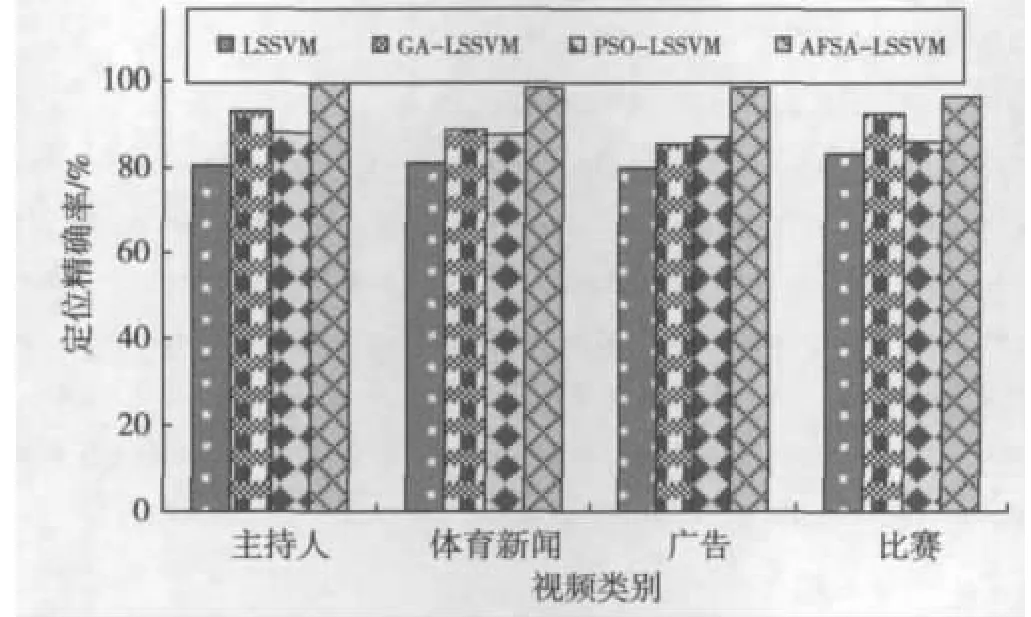
图3 各模型的定位正确率对比

图4 各模型的误判率对比
从图3和图4可知,相对于没有进行特征选择的视频字幕定位模型(LSSVM),GA-LSSVM、PSO-LSSVM、AFSA-LSSVM均不同程度地提高了视频字幕定位的正确率,同时降低了误判率,主要是因为特征选择可以剔除冗余和不重要的视频字幕特征,获得有利于提高视频字幕定位结果的视频字幕特征。
同时从图3和4可以看出,相对于GA-LSSVM和POS-LSSVM模型,AFSA-LSSVM的视频字幕定位正确率更高,误判率进一步降低,这有效地表明了AFSA获得的特征子集可以更加准确地描述视频字幕区域,AFSA-LSSVM可以获得更优的视频字幕定位结果。
2.3.3 训练和测试时间比较
对于大规模的视频字幕定位问题,定位速度至关重要,采用tic和toc命令记录每一个模型的平均训练时间和平均测试时间,结果见表3。从表3可知,在所有模型中,AFSA-LSSVM的训练时间和测试时间最短,定位速度最快,对比结果表明采用AFSA对视频字幕进行选择后,降低了分类器输入维数,计算复杂度降低,加快了定位收敛速度,AFSA-LSSVM可以满足大规模的视频字幕定位实时性要求。
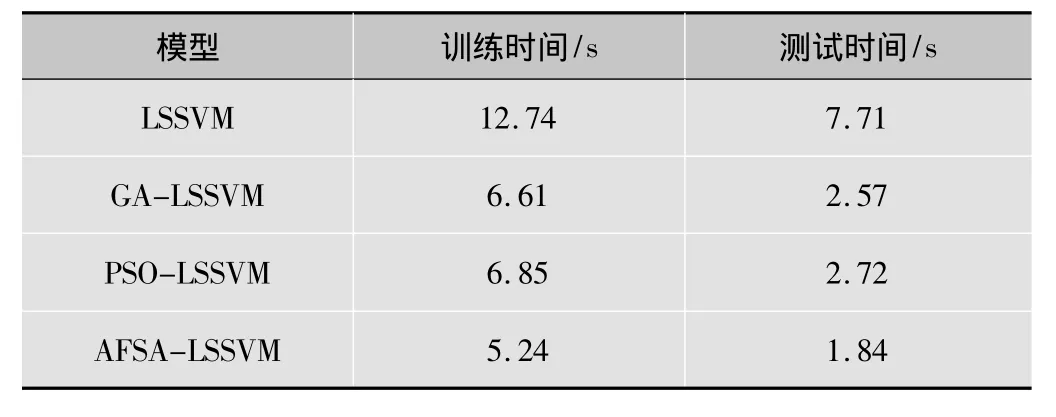
表3 不同模型的训练时间和测试时间对比
3 结束语
针对视频字幕的定位问题,提出了一种采用AFSA选择特征和LSSVM定位相结合的视频字幕定位模型,仿真实验结果表明,AFSA-LSSVM提高了视频字幕定位的效率与正确率。备选字幕区域的选取优化是一下步将要进行的研究工作,以进一步提高字幕的定位正确率。
[1] TANG X,GAO X,LIU J.A spatial-temporal approach for video caption detection and recognition[J].IEEE Trans.Neural Networks,2002,13(4):961-971.
[2] LEFEVRE S,VINCENT N.Caption localization in video sequences by fusion of multiple detectors[C]//Proc.Eighth International Conference on Document Analysis and Recognition.[S.l.]:IEEE Press,2005:106-110.
[3]葛菲,史萍.基于内容的电视广告段落检测系统[J].电视技术,2010,34(9):106-109.
[4] ODOBEZ J,CHEN D.Video text recognition using sequential Monte Carlo and error voting methods[J].Pattern Recogn,Lett.,2005,26(9):1386-1403.
[5]葛菲,史萍,姚彬,等.广告段落分割系统中的字幕检测[J].电视技术,2010,34(2):25-29.
[6]王勇,燕继坤,郑辉,一种自适应的视频帧中字幕检测定位方法[J].计算机应用,2004,24(1):134-135.
[7]易剑,彭宇新,肖建国.基于颜色聚类和多帧融合的视频文字识别方法[J].软件学报,2011,22(12):2919-2933.
[8]刘骏伟,吴飞,庄越挺.基于SVM和ICA的视频帧字幕自动定位与提取[J].中国图象图形学报,2003,8(11):1331-1337.
[9]庄越挺,刘骏伟,吴飞.基于支持向量机的视频字幕自动定位与提取[J].计算机辅助设计与图形学学报,2002,14(8):750-0753.
[10] LIUM,SONG J,CAIM.A comprehensive method formultilingual video text detection,localization,and extraction[J].IEEE Trans.Circuits and Systems for Video Technology,2005,15(2):243-255.
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
北京广播电视报(2019年8期)2019-03-27
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
唐山文学(2016年11期)2016-03-20
人间(2015年22期)2016-01-04
语言与翻译(2015年4期)2015-07-18
