
多层面Rasch模型在语言评估中的应用研究述评
2014-04-20 10:23陈艳君
教育测量与评价 2014年6期
陈艳君
一、Rasch模型简介
Rasch模型是一种单参数项目反应理论模型,最早由丹麦统计学家GeorgeRasch于1960年提出,最初主要用于统计学、心理学领域,经过半个多世纪的发展,现已广泛应用于教育、医学、体育等领域的科学研究中。近二十年来,随着项目反应理论的飞速发展,Rasch模型在语言测试与评估中的应用研究也逐渐丰富起来,计算机自适应测验(CAT)就是基于Rasch模型而发展起来的。CAT突破了传统考试中所有考生完成同一套试题的局限,可以根据考生的答题情况,提供不同的题目,从而测定出考生的不同能力水平。
Rasch模型的基本理念是考生答对某一道题的概率不仅取决于考生的能力,也取决于该题的难度。Rasch模型一般用来分析多项选择等客观题型的试题难度和考生能力。但是,在主观题型的评估中,除了考生能力和试题难度,题目的评分标准、评分员的主观判断等因素也是影响考生能力评估的重要因素,由此,多层面Rasch模型(Multi-facetRaschModel,MFRM)[1]得以延伸出来。MFRM实现了在同一个量尺下分析考生能力、主观题难度、评分标准、评分员严厉度等因素以及它们之间的交互作用,为评估主观题型提供了丰富而有力的信效度方面的理据。而在交际语言测试观飞速发展的今天,仅仅局限于客观选择的测试已经远远不能满足需要。如今,能够真实准确地评估考生语言交际的能力的测试大部分都是通过主观题来实现的,由此,MFRM成为了一个重要的理论模型和强大的分析工具。
二、MFRM的数学表述与分析软件
MFRM的数学模型可以将考生能力、任务整体难度、项目难度、评分员严厉度等因素参数化,统一到同一个测量尺度(logitscale)上,并作为影响因子,决定考生取得某一分值的概率大小。其基本的数学表达式如下:
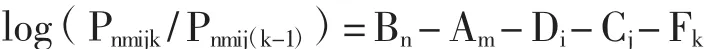
其中,Bn表示考生n的能力,Am表示任务m的整体难度,Di表示项目i的难度,Cj表示评分员j的严厉程度,Fk则表示在项目i上取得k分数段的难度,Pnmijk表示评分员j在任务m的项目i上给考生n打k分数段的概率,Pnmij(k-1)则表示评分员j在任务m的项目i上给考生n打(k-1)分数段的概率。
目前,基于MFRM的数学运算,主要是通过FACETS统计分析软件进行的。FACETS采用非条件极大似然法(UnconditionalMaximumLikelihood)对MFRM中的各个参数进行估计。通过FACETS分析,研究者可以将项目难度、考生能力、评分员的严厉程度以及评分量表各等级难度的度量值,转化为以洛基量表(logitscale)为单位的统一度量值,从而检测出在同一个单位量尺上各个因素之间是否存在显著差异(如项目难度之间的差异、评分员的严厉度差异等)。与此同时,FACETS还为每个因素提供拟合值,并对每个因素与Rasch model的拟合程度进行分析。此外,通过FACETS中的偏差分析(bias analysis),研究者可以进一步找到各个因素之间的交互作用。
三、MFRM的应用研究
由于MFRM在分析主观题型测试方面的强大功能,从20世纪90年代起,以McNamara[2]为代表的学者们开始将它运用到口语和写作测试评估中,对整体性评分标准的效度、二语口语测试的开发、写作测试中的评分员偏见等问题进行了广泛研究,[3][4][5]并在主观题型测试的开发、实施和评估方面提出了切实的方案和宝贵的经验。而在国内,将MFRM应用于语言测试与评估中的相关研究才刚刚起步,虽然如此,但也产生了一系列有价值的研究成果。笔者在中国知网上以“Rasch”为主题词,以SCI,CSSCI,EI以及核心期刊为来源刊,检索了2003~2013年10年间有关Rasch模型在教育测试与评估中的应用研究,共检索出45篇文献。45篇文献中,基于MFRM对于语言测试进行研究的共27篇,发表时间集中在2005~2013年(参见表1),研究类型主要集中在试题信效度验证、评分员效应研究和评分方法研究三个方面,其中试题信效度验证与评分员效应研究是MFRM应用研究的主流,共有22篇文章发表,占总量的82%,另外5篇(18%)则侧重于运用MFRM检验各种评分方法对测试结果的影响。
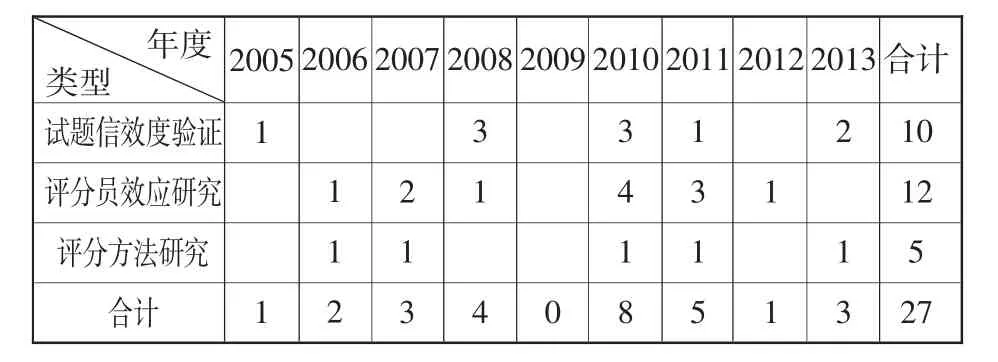
表1 MFRM在语言测试中的应用研究成果统计(2005~2013)
1.试题信效度验证
在过去十年间,国内运用MFRM对于试题信效度进行验证的研究主要集中在写作测试和口语测试上,这些研究大多从考生能力、任务难度、评分标准和量表、评分员严厉度等方面,对测试题型的信度与效度进行了综合的评估。[6][7][8][9]同时,通过MFRM的拟合分析与偏差分析,研究者们也发现一些高风险考试中存在题型任务设计上偏难、个别评分员评分误差较大等问题,这对于推动考试设计的科学性与公平性起到了建设性的推进作用,也充分体现了MFRM在分析语言运用测试上的强大功能。近几年来,研究者们除了将MFRM应用到口语与写作这两种主观题型测试,还尝试对其他题型进行了信效度验证。

篇章翻译各个层面的测量值①
以江进林、文秋芳[10]的研究为例,该研究运用MFRM对英语篇章翻译的测试效度进行验证,主要分析了考生与评分员的心理反应过程。两位研究者将考生、评分员和句子的评分项设置为三个“面”,并将评分员基于考生翻译文本的评分数据输入FACETS软件,进行了多层面Rasch模型分析,得到如上图所示的测量分布情况。上图中,第一纵列为洛基量尺,是后面所有纵列参照的共同标准。洛基单位是MFRM模型的测量尺度,通过它,研究者能够将考生的能力、评分员的严厉度、评分项目的难度等因素统一到同一个单位量尺上进行比较。以第二列为例,第二列反映的是考生能力的度量值,星号代表一定的考生人数,短线则代表考生数未达到该数值;符号出现的越多,代表达到该能力值的考生越多。上图中,考生能力值在-0.2至+0.4之间,-0.2能力值上的考生人数最多。同样的,基于同一个洛基单位,上图也自上而下地排列出了3位评分员的评分严厉程度、30个评分项的难度以及模型期望各个能力段的考生应得分数。
上图所呈现的是该研究中三个层面在模型测量中的总体分布情况。利用MFRM,研究者还可以对每个层面甚至是每一个个体做单独的统计分析,便于研究者检验各个层面以至于个体的表现是否符合模型的预期,从而为试题设计和评分过程提供科学、有效的反馈。以考生能力层面为例,FACETS会统计出每一位考生的答题情况数据,具体包括评分员给出的平均分(Observed Average)、Rasch模型拟合出的期望分数(Fair-MeanAverage)、考生能力值(Measure)、加权均方拟合统计量(InfitMnSq)、正态分布的标准拟合数据(ZStd,其绝对值若大于2,则为显著非拟合)等关键统计量,通过这些数据的拟合程度检验,研究者可以发现考生的答题行为是否真实反映了其在该题目上应该体现的实际能力。通过对考生层面的分析,江进林、文秋芳发现:有1/3的考生并未发挥出实际的翻译水平,考生的翻译能力与答题行为存在一定程度上的不一致。不过,文章并没有进一步解释不一致的原因何在,只是指出了这种不一致性需要对考生的答题行为进行如观察、访谈等的定性分析。这也说明了考生在翻译测试中的表现是值得研究者进一步探究的课题,特别是在一些高风险型考试中,翻译测试的信效度验证有待研究者深入探讨。
2.评分员效应研究
MFRM应用研究的另一类型就是对于评分员效应或评分质量的研究。这类研究可以视为试题信效度验证研究的一个部分,我们将其另归一类是因为这类研究的焦点在于评分员对测试结果的影响。这类研究主要从写作与口语两种题型入手,研究评分员的严厉度、评分一致性、评卷偏差等问题。[11][12][13]刘建达通过多层面Rasch模型中的偏差交互分析(biasinteractionanalysis),分析了口语考试中评分员与考生、评分标准等层面的偏差交互作用。表2显示了有显著偏差交互作用的情况。依据模型偏差分析的原则,如果某个交互作用的Z-score绝对值大于2,则为显著偏差。从表2中我们不难看出,两个有显著意义的偏差交互作用都出现在4号评分员上。该评分员在语言使用方面的评分较宽松,在语音方面的评分较严格。而在后续对评分标准各个层面的分析中,研究者进一步证实了4号评分员在语言使用方面评分时只给某一个分数的集中趋势明显,评分时没能很好地区分考生的语言能力。这一类评分员可能需要重新接受评分培训。

表2 评卷人与考生、评分标准的偏差交互作用②
将MFRM应用到评分质量的研究结果说明了,该模型可以很好地帮助研究人员分析并发现评分员在阅卷过程中出现的问题和产生的偏差,从而对评分员的遴选以及培训提供建议与参照。同时,基于MFRM的分析结果,考试主管部门在后期的数据分析和汇报时可采取一定的补偿策略,将主观评分的误差尽可能降低,从而最大程度地保证主观题型的评阅质量和考试的公平性。
3.评分方法研究
这里所指的评分方法,包括评分方式(网络或者纸质)、评分量表以及评分标准。相对于前两种研究而言,应用MFRM对于不同评分方法的对比研究相对较少。王跃武、朱正才等[14]对网上评分与传统评分这两种评分方式进行了对比研究,通过MFRM分析发现网上评分信度高于传统评分。关丹丹、陈睿等[15]对比了小分制评分量表与大分制量表下评分员的评分效应,并根据MFRM的分析结果对写作量表的设置、写作成绩的报告等提出了建议。不过,在实验设计上,关丹丹等的对比评分选取的作文样本没有干扰卷,两种量表的评分时间间隔为一个星期,这对于评分员而言是否会产生一定的评分效应还有待商榷。另外,我们发现,在评分标准方面的研究,只有李清华、孔文[16]运用MFRM对于TEM-4写作新的分项式评分标准进行了研究,验证了使用新标准的评分结果的可靠性,但他们的研究并没有将新旧评分标准进行对比,这使得研究结果失去了对比的参照,一定程度上影响了研究结果的说服力。
四、MFRM的研究展望
本文回顾了MFRM在语言评估中的应用研究,不难看出:MFRM作为单参数Rasch模型的一种延伸,可以很好地检验主观题型的信效度,比较评分标准的差异,并对考试的评分质量进行一定的监控并做出适当的补偿,从而保证主观测试的公平与公正。基于MFRM在测量评估中的优势,结合语言评估的实践,笔者以为,MFRM的应用研究在以下几个方面依然具有广阔的发展空间和研究价值。
首先,运用MFRM可以对国内现有的考试进行进一步的实证分析研究。MFRM在主观题型的信效度检验上具有强大的功能,然而,通过过去十年的研究回顾我们不难发现,目前对于主观题测试的MFRM应用研究大部分集中在口语与写作测试上,对其他题型的研究相对较少。比如翻译测试,过去十年间的核心研究成果只有寥寥几篇,将MFRM应用于大规模、高风险的翻译测试的相关研究则几乎没有。这也说明了MFRM在主观题型的应用研究上仍然有很多的命题值得研究者们深入挖掘。
其次,进一步发挥MFRM在试题开发方面的作用。目前,国内运用MFRM的研究主要还是针对现有题型的信效度验证,涉及新的主观题型的设计与开发方面的研究较少。刘建达[17]运用MFRM对于话语填充测试的研究是对于题型开发研究的一次新的尝试,其测试目的是考察学生的中介语语用能力。此后,王初明、亓鲁霞[18]对于“读后续写”题型进行了开发研究。以上两项研究都是旨在考察学生的语言应用能力而在题型设计上做出的新尝试。目前,在更加注重学生语言应用能力培养的教学改革大背景下,需要更多这样的应用研究,这样才能让考试更加适应教学改革的需求。
再次,运用MFRM对于评分方法进行进一步的对比研究。主观题型设计的可靠性,除了试题内容本身,很大程度上取决于评分的操作和评分工具的质量。而评分工具的质量则取决于评分量表与评分标准的科学性。从目前国内的研究成果来看,运用MFRM对于不同评分标准的比较研究很少。因而,对于评分标准、评分方法的比较研究也是MFRM应用研究可以尝试的一个方向。
另外,除了上述的应用研究,研究者们还可以运用MFRM,对受试各种特征的分类数据进行分析处理,进而展开考试的公平性等研究。总之,MFRM在语言评估中的应用研究是十分广泛的。但我们在运用过程中必须注意的是:MFRM作为项目反应理论的一种模型,有着严格的前提假设,如个体作答行为真实性假设、局部独立性假设,等等。研究者在运用MFRM进行数据分析和推断之前,必须要对模型基于的假设是否成立进行检验,否则所有的命题和推论都是无法成立的。
注释:
①该图表基于江进林、文秋芳的研究数据,做了部分节选。
②笔者根据刘建达的研究,节选了部分数据并在呈现方式上做了适当调整。
[1]Linacre,J.M..Many-facet Rasch Measurement[M].MESAPress:Chicago,1994.
[2]McNamara,T.F..Measuring second language performance[M].London:Longman,1996.
[3]Tyndall,B.&Kenyon,D.M..Validation of a new holistic rating scale using Rasch multi-facted analysis.In Cumming,A.&Berwick,R.(eds.),Validation in language testing Clevedon,UK:Multilingual Matters,1996.
[4]Lynch B.&McNamara T.F..Using g-theory and many-facet Rasch measurement in the development of performance assessments of the ESL speaking skills of immigrants[J].LanguageTesting,1998(15):158~180.
[5]Kondo-Brown,K..AFACETSanalysisofraterbiasin measuring Japanese second language performance[J].LanguageTesting,2002,19(1):3~31.
[6][18]王初明,亓鲁霞.读后续写题型研究[J].外语教学与研究,2013(5):707~718,800.
[7]张新玲,曾用强,张洁.对大规模读写结合写作任务的效度验证[J].解放军外国语学院学报,2010(2):50~54,128.
[8]何莲珍,张洁.多层面Rasch模型下大学英语四、六级考试口语考试(CET-SET)信度研究[J].现代外语,2008(4):388~398,437.
[9]孙海洋.概化理论和多层面Rasch模型在建立“职前中学英语教师口语考试模型”中的应用[J].外语与外语教学,2011(5):57~62.
[10]江进林,文秋芳.基于Rasch模型的翻译测试效度研究[J].外语电化教学,2010(1):14~18.
[11]张艳莉,彭康洲.TEM8写作考试评分员差异性研究[J].外语电化教学,2012(1):42~46.
[12]刘建达.评卷人效应的多层面Rasch模型研究[J].现代外语,2010(2):185~193,220.
[13]戴朝晖,尤其达.大学英语计算机口语考试评分者偏差分析[J].外语界,2010(5):87~95.
[14]王跃武,朱正才,杨惠中.作文网上评分信度的多面Rasch测量分析[J].外语界,2006(1):69~76.
[15]关丹丹,陈睿,张开等.两种评分量表的评分效应比较研究[J].教育研究与实验,2011(4):92~96.
[16]李清华,孔文.TEM-4写作新分项式评分标准的多层面Rasch模型分析[J].外语电化教学,2010(1):19~25.
[17]刘建达.话语填充测试方法的多层面Rasch模型分析[J].现代外语,2005(2):157~169,220.
猜你喜欢
中国特种设备安全(2022年1期)2022-04-26
成都中医药大学学报(教育科学版)(2021年1期)2021-07-22
河池学院学报(2021年1期)2021-07-10
英语文摘(2019年2期)2019-03-30
中华手工(2018年6期)2018-07-17
优雅(2017年11期)2017-11-11
中学生英语·外语教学与研究(2016年12期)2017-01-03
文学教育(2016年33期)2016-08-22
中国卫生(2015年7期)2015-11-08
韩国语教学与研究(2015年1期)2015-10-19
