
基于Lucene的校园信息搜索引擎的设计与实现
2013-12-22 12:21杨单
中南民族大学学报(自然科学版) 2013年4期
杨 单
(中南民族大学 管理学院,武汉430074)
当前,校园网内部信息的数量在高速增长,如何让校园师生们更快速、更准确地获取校内信息,单纯依靠传统Internet上的大型搜索引擎有时候不一定特别奏效,因为通用搜索引擎根据自身的策略不可能覆盖某一学校的局域网内所有的网页,存在信息覆盖率不高的问题,同时由于网页的重要性问题,信息的更新会比较慢.例如Google在网页抓取策略方面使用的就是基于链接评价的搜索引擎[1],它独创的“链接评价体系”认为一个网页的重要性取决于它被其它网页链接的数量,特别是一些已经被认定是“重要”的网页的链接数量,这样对于局域网内相关信息搜索的准确率就不会很高,而校园网上用户对于校园内部信息的查准率的要求要高于查全率.基于此种需求,本系统的主要目的是探索实现针对校内信息的搜索引擎,着眼于学校内部信息的收集与处理,使相关用户更快捷地找到所关注的信息.
1 Lucene技术的特点
Apache Lucene 是一个开放源程序的、用 Java 写的全文检索引擎工具包,利用它可以轻易地为 Java 软件加入全文搜索功能,用户可以基于它开发出各种全文搜索的应用.作为一种全文检索引擎的架构,Lucene提供了完整的查询引擎、索引引擎及部分文本分析引擎[2].
Lucene关注文本的索引和搜索,并为数据访问和管理提供简单的函数调用接口,可以方便地嵌入到各种应用中实现针对应用的全文索引、检索功能[3].Lucene 作为一个优秀的全文搜索引擎的架构,其系统结构运用了大量面向对象的编程思想,定义了一个与平台无关的索引文件格式,通过抽象将系统的核心组成部分设计为抽象类,并将与具体平台相关的部分也封装为类,经过层层面向对象编程的处理,最终达成一个低耦合、高效率、容易二次开发的搜索引擎系统[4].作为一个开放源代码项目,Lucene 以其优异的索引结构、良好的系统架构获得了越来越多的应用.
2 系统总体设计
按照相关功能,系统分为两大部分:网页资源采集与索引、检索与展示.网页资源采集和索引部分包括了网页资源采集、资源处理与索引两大模块,检索与展示部分包括数据检索、网页快照、关键字过滤三大模块,如图1所示.
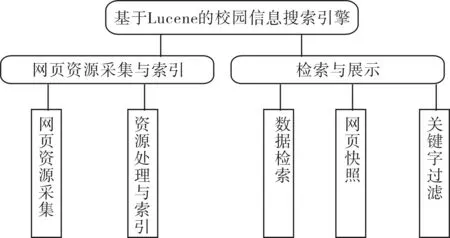
图1 系统模块设计图
本系统结构由3个部分组成:数据库服务器,搜索引擎核心服务器,Tomcat Web服务器,各部分既分工明确又相互合作.数据库服务器记录资源抓取情况、索引情况,它与搜索引擎核心服务器协作完成资源的下载更新与索引,同时通过记录网页的抓取历史,使网络爬虫具备了自动学习的功能,即根据网页的更新频率来调整自身的抓取频率.Tomcat服务器比较独立,与其他部分没有交互,但是它的数据来源于前面索引好的索引文件,同时其网页快照功能实现也是以网络爬虫抓取的原始网页文件为基础的.
整个系统运行的数据流程如图2所示:第一阶段网络爬虫从数据库中获取需要抓取的网页信息,进行网页的下载,下载后需要将下载时间、文件存放路径等信息记录到数据库中,同时将下载的文件存放在硬盘上;第二阶段是Lucene建立索引阶段,先从数据库中取得需要建立索引的任务,然后进行处理,并将索引结构写入到索引文件中;第三阶段是检索阶段,系统检索建立好的索引文件,并且将查询到的结果返回给用户.

图2 系统数据流程图
3 系统详细设计
3.1 网页资源采集模块
网页资源采集模块主要负责从网络上抓取相关网页信息,即通常所说的网络爬虫Spider.网络爬虫采用多线程,多个线程(SpiderWorker)同时下载网页资源.而下载的网页和需要下载的网页的相关信息存储在数据库中,并且网页需要更新.基于以上考虑,Spider的功能实现主要从以下几个方面进行.
(1) 多线程的控制.在有多个任务时,多个工作者线程(SpiderWorker)在取得爬行任务后,往任务队列中添加新发现的任务.在没有任务时,多个线程只剩下一个,监视是否有任务需要执行,如果有任务且不止一个,它就会唤醒另一个睡眠的线程,而其他线程在没有任务时就会进入睡眠状态.基于以上考虑,所有的工作者线程都由某个线程(Spider)掌管,通过该线程(Spider)可以控制网络爬虫的运行或停止;
(2) 由于工作者线程不能下载相同的网页(已经下载过的),所以必须将已经下载过的网页的相关信息(地址、下载时间等)进行保存,鉴于要处理的网页较多,所以采用数据库对网页的相关信息进行存储.所以此部分主要涉及对数据库的相关操作;
(3) 工作者线程的工作主要是从网页上下载网页,并对网页进行解析,所以该部分主要工作是利用socket取得网页文件,并对网页内容进行解析,将网页中找到的网页地址的相关信息存储到数据库中;
(4) 由于当工作者线程在解析一个网页时,在这个网页中可能发现多个网页地址(本站点或其他站点的),所以在设计时可以根据实际需要确定是否将在本站点发现的外部站点链接加入到工作者队列中,如果添加还可对其深度进行控制.如只抓取在本站点发现的该外部链接,该外部链接上发现的链接不予处理,即其抓取外部链接的深度为1.
网络爬虫数据处理流程图如图3所示.
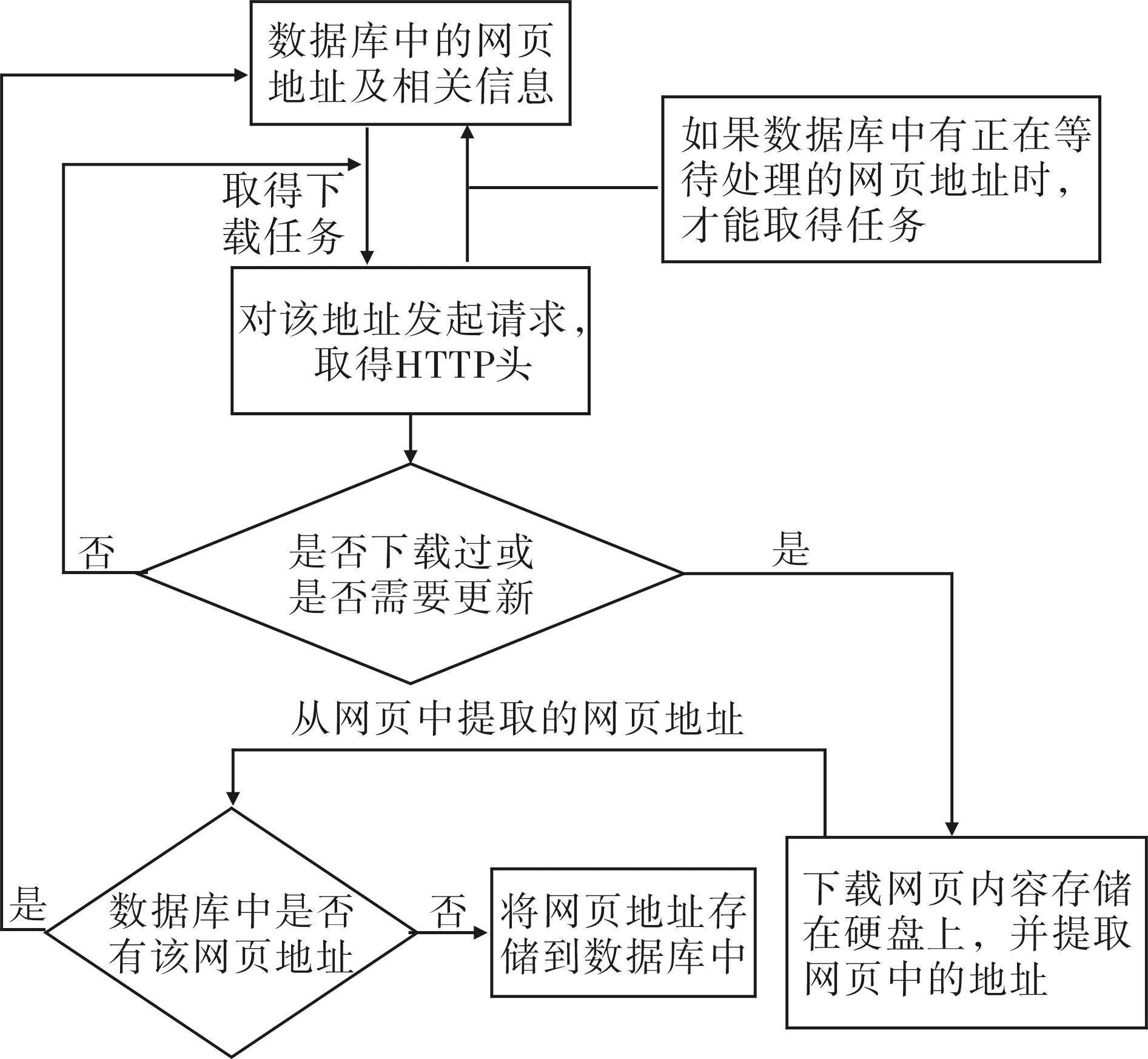
图3 网络爬虫数据处理流程图
3.2 资源处理与索引模块
Lucene建立索引采用的也是多线程的实现方式,基本上实现方式与WEB采集、FTP采集类似,目前主要可以对文本类文件(txt、html、shtml、xml)、word文档、excel文档、pdf文档、数据库中的记录等建立索引[5].
纯文本类文件处理:对于文本类文件的处理没有使用Lucene内置的类,而是直接使用java.io.BufferedReader和java.io.FileReader,通过它们读取文件,并且将空格去掉.
Word文档处理:使用 org.textmining.text.extraction.WordExtractor进行处理,它是apache下解析word文件的一个类.
Excel文档处理:使用jxl包里面的 jxl.Cell、jxl.Sheet、jxl.Workbook三个类进行信息的抽取;jxl是一个开源的操作Excel的Java包.
PDF文档的处理:使用PDFBox包里面的org.pdfbox.pdmodel.PDDocument、org.pdfbox.util.PDFTextStripper两个类,PDFBox是Java实现的PDF文档协作类库,提供PDF文档的创建、处理以及文档内容提取功能,也包含了一些命令行实用工具.主要特性包括:从PDF提取文本,合并PDF文档,PDF 文档加密与解密,与Lucene搜索引擎的集成,填充PDF/XFDF表单数据,打印PDF文档等.
Lucene建立索引阶段,先从数据库中取得需要建立索引的任务,然后进行处理,并将索引结构写入到索引文件中.
3.3 检索模块
用户输入关键字后,系统会对关键字进行分析,判断关键字是否为敏感词汇,如果为敏感词直接返回,并提示用户系统对该关键字进行过滤;如果不是敏感词,则系统检索已经建立好的索引文件,并对检索结果进行分页处理,最后将合适的结果返回给用户.
该处提到的判断关键字是否为敏感词汇的方法是采取建立敏感词库的方式,不断将某些词汇添加到该词库,在具体的检索时,将用户输入的关键字进行分词,在敏感词库中进行检索,如果关键字存在敏感词汇,将直接返回,不再进行检索.
3.4 数据库设计
在本系统中,需要利用数据库记录网络资源采集的相关信息,资源采集包括Web网页采集、FTP采集、数据库采集,具体涉及到以下几个表.
(1) 表DownLoaderWorkload.
该表存储是FTP文档采集的文件信息,FTP文档采集时有两种线程:一种是文件发现线程(FileFinder),另一种是文件下载线程(DownLoader),FileFinder将发现的文件信息存储在DownLoaderWorkload表中,而DownLoader从DownLoaderWorkload表取得需要下载的文件的信息进行下载.
(2) 表SpiderWorkload.
该表用于记录Web网页采集信息,与DownLoaderWorkload表功能类似.
(3) 表IndexSource.
该表用于记录从数据库中采集的信息.
(4) 视图IndexResource.
该视图用于将不同来源的数据以相同的结构呈现给Lucene索引.
4 系统实现
4.1 网络爬虫的相关实现
网络爬虫的实现包括3个层次:网页访问与抓取层、多线程控制及网页解析提取链接层、数据库交互层.网页访问与抓取层使用多线程并行处理,在数据库交互层进行同步控制,防止各线程互锁资源造成死锁.3个部分分别对应4个主要类HTTPSocket、SpiderWorker、Spider、SpiderSQLWorkload.
(1) 网页访问与抓取层实现.
整个网络爬虫是由Spider控制的,SpiderWorker类的功能是访问网页并下载网页,它是个多线程类,采用extend方式实现.HTTPSocket完成了网页访问与抓取的全部工作.
该网络爬虫的实现参考了Jeff Heaton的爬虫模型[6],对其进行了适度地改进以满足自身的需求,主要的改进体现在以下方面.
(a) 在数据库中增加了网页抓取记录,同时使爬虫增加了对更新后的网页重新抓取的功能;
(b) 在网络爬虫的多线程控制方面:原网络爬虫在所有的任务完成后,所有的线程全部停止退出,修改后,没有任务时只留下一个线程监视是否有新的任务,其他线程进入睡眠状态,当有新的任务时,活跃的一个线程负责唤醒其他睡眠的线程继续作业.该改进主要是为了实现网络爬虫抓取的自动化.
(2) 多线程控制及网页解析提取链接层实现.
(a) 多线程控制. 该系统的多线程的控制是用wait()与notify()实现的,整个网络爬虫线程的数量是由参数文件控制的,例如启动了100个线程同时采集网页,当资源队列中的网页采集完成后,其余的99个线程进入睡眠状态,保留一个线程处于活跃状态,它的主要作用是查询资源队列需要采集的任务,当任务数大于1时,它会按照任务量唤醒一定数量的线程继续工作.图4是该部分功能实现的流程图.
(b) 网页解析提取链接层. 网页解析工作是由SpiderWorker承担的,而且网页的更新也是由其判断HTTP头信息来判断网页是否更新过.根据HTTP头信息里面的Last-Modified属性确定网页的最新更新时间,将这个时间和数据库中上次抓取的时间进行比较,如果更新时间晚于上次抓取时间,即再次抓取.processWorkload()方法实现了大部分功能,包括解析网页、提取链接、保存网页等.

图4 多线程控制流程图
(3) 数据库交互层实现.
数据库交互层实现主要类为SpiderSQLWorkload,它的assignWorkload()、addWorkload(String url)等方法完成了与数据库交互的大部分工作,assignWorkload方法的作用是为网络爬虫分配爬行任务,addWorkload方法的作用是将网络爬虫解析网页发现的链接加入到资源队列中,该链接是经过去重等一系列处理的,保证其在资源队列中的唯一性.
4.2 Lucene索引相关实现
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎[7].
本系统使用Lucene Smartcn进行中文分词,并且支持多种资源的索引,如doc、xls、pdf、html、shtml、htm、xml、txt等类型的资源,针对每种资源其索引方法都不相同,针对此问题,系统充分利用了JAVA语言多态的特性进行处理,即所有的资源类型都统一实现IndexResource接口的buildIndex()方法,但是每种资源的实现方法各异.如ExcelResource、PDFResource、TextResource、WordResource都实现了IndexResource,但是它们buildIndex方法的实现是不同的,这样使得异构的资源最后都被索引成相同结构的结构性索引文件,如图5所示.
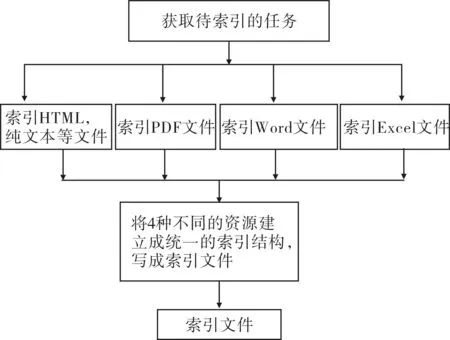
图5 Lucene索引工作流程图
5 系统测试
本系统针对校园网的特点改进了传统搜索引擎,以适应局域网对于数据查询准确性的要求,同时在某些方面进行了增强,如网页的更新方面和使网络爬虫具备了智能学习的功能,可以根据网页的更新频率,智能调整自身抓取频率.
传统的搜索引擎有两个重要参数:查全率和查准率[8].一般情况下,查全率很难比较,在衡量搜索引擎的性能时很少采用,而且本系统重点解决的是校园网信息搜索的查询准确率问题,所以本系统测试重点在于测试查准率.
以中南民族大学校园网作为测试对象,参照相关测评标准,对查询进行分类考虑,对于主题页面的查询,根据前10个结果中出现的相关页面数目来判断系统的性能,通常采用前10个结果的平均精确率(P@10)来评判;对于待定网页的查询,则以第一个相关页面出现位置的倒数平均值(MRR)为评判标准.根据P@10、MRR等参数对系统性能进行了测试和分析,结果见表1.

表1 系统性能测试数据统计结果比较
根据测试结果综合分析来看,本系统能在校园网内较好地执行搜索任务,系统的功能和性能都比较令人满意.但随着索引量的增加,系统的响应时间也会有所增长.而随着关键词的增加以及查询逻辑的复杂化,查询的准确率会有所下降.
6 结语
针对校园信息的特点,利用Lucene开源全文检索引擎工具包,设计并实现了一个适合于校园等局域网使用的小型搜索引擎,并对相关性能进行了优化,达到了较好的效果.该Lucene应用也可推广到许多其他的应用实例的设计与实现.当然系统还存在一些不足:如网络资源抓取的速度和效率、中文分词的准确率等,都需要做进一步的研究.
[1] 李晓明,闫宏飞,王继民. 搜索引擎——原理、技术与系统[M]. 2版.北京:科学出版社,2012.
[2] 郎小伟,王申康.基于Lucene的全文检索系统的研究与开发[J].计算机工程,2006,32(4):94-99.
[3] 梁 弼,王光琼,邓小清.基于Lucene的全文检索系统模型的研究及应用[J].微型机与应用,2011,30(1):44-46.
[4] 赵 珂,逯 鹏,李永强.基于Lucene的搜索引擎设计与实现[J].计算机工程,2011,37(16): 39-41.
[5] 郑榕增,林世平.基于 Lucene的中文倒排索引技术的研究[J].计算机技术与发展,2010,20(3):80-83.
[6] Heaton J.网络机器人Java编程指南[M]. 童兆丰,李 纯,刘润杰,译.北京:电子工业出版社,2002.
[7] 张 俊,李鲁群,周 熔.基于Lucene的搜索引擎的研究与应用[J].计算机技术与发展,2013,23(6): 230-232.
[8] Hawking D,Craswell N,Bailey P,et al.Measuring search engine quality[J].Information Retrieval,2001,4(1):33-59.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
计算机与网络(2022年2期)2022-03-17
山西电子技术(2021年3期)2021-06-28
现代信息科技(2021年21期)2021-05-07
疯狂英语·新阅版(2020年11期)2020-12-21
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
电子制作(2018年2期)2018-04-18
电子制作(2017年9期)2017-04-17
科学导报·学术论坛(2013年5期)2013-06-26
