
基于分层增长语音活动检测的鲁棒性说话人识别
2012-12-23 06:00解焱陆张劲松刘明辉黄中伟
深圳大学学报(理工版) 2012年4期
解焱陆,张劲松,刘明辉,黄中伟
1)北京语言大学信息科学学院,北京100083;2)深圳大学语音实验室,深圳518060
随着移动互联网的普及,以及说话人识别系统逐步走向实用,对该系统的鲁棒性也提出了更高的要求. 现有的应用于移动设备的语音识别和说话人识别系统常采用分布式架构,即在终端提取语音参数,在服务器存储说话人模型并进行识别. 如Nuance 的Dragon Dictation、科大讯飞的云计算语音输入法、欧洲电信标准化协会(European Telecommunications Standards Institute,ETSI)颁布的分布式语音识别(Distributed Speech Recognition ,DSR)前端标准(Advanced Front-End,AFE)[1](以下简称ETSI-DSR-AFE)等.
DSR 可避免语音压缩所带来的损失,大量减少传输的数据量,同时在特征参数的传输过程中可加入更复杂的检错和纠错功能. 然而,DSR 传感器终端通常是电话或手机,易受背景噪声的干扰. 目前,语音信号鲁棒性方法大致可分为两类. 一类是对语音模型进行变换和处理,如模型补偿算法(parallel model combination,PMC)[2]、基于通道信息的特征映射方法[3]、最大后验估计(maximum a posterior,MAP)[4]和最大似然回归(maximum likelihood linear regression,MLLR)及其改进算法[5-6]等. 基于语音模型的方法在近年取得了较大进展,然而这些方法在实际应用中仍面临各种问题,如需事先得到噪声模型和噪声信息、需根据噪声情况修正模型、计算量较大等. 另一类语音处理的鲁棒性方法是特征域的,主要对语音信号和语音参数进行处理得到鲁棒性的参数. 方法主要有:矩规整方法,如一阶矩规整(cepstral mean subtraction,CMS)[7]和改进的CMS 方法[8]等,这些方法实现简单、表现稳定,但性能提升空间有限,不适于复杂噪声环境;参数级的空间变换方法,如线性区分性分析(linear discriminant analysis,LDA)和异方差线性区分性分析(heteroscedastic linear discriminant analysis,HLDA)等[9-10],这些方法在性能和复杂度指标上一般劣于模型级方法;滤波方法,如相对谱滤波RASTA(relative spectral)、维纳滤波和卡尔曼滤波等[11-12],这些方法计算简单、物理意义明确,多用于语音增强. 在语音识别和说话人识别中使用滤波方法滤除了一些在听觉上不重要的,但在识别中比较关键的信息,这往往是因为滤波器的设计和语音活动检测(voice activity detection,VAD)效果不佳造成的. 从分布式语音识别的角度考虑,滤波方法具有实时性高、处理方便的特点,因此在ETSIAFE 中的前端处理还是基于两级维纳滤波的,但AFE 在部分噪声条件下性能欠佳.本研究针对ETSIAFE 的特点,提出基于分层增长(level-building)的改进算法,提高了复杂噪声环境下VAD 效果和说话人识别系统识别率.
1 基于ETSI-DSR-AFE 的维纳滤波
1.1 ETSI DSR 标准概况
2007 年,ETSI 发布了ETSI ES 202 050 V1.1.5标准[1]. 从已知的实验结果来看,AFE 是当前性能最好的噪声鲁棒性算法之一. 2011 年,DSR 标准输出到3gpp 的TS 26.243 中,正式成为语音激活业务(Speech Enabled Services,SES)的编码标准[13].
ETSI 分布式语音识别系统分为前端(传感器终端部分)和后端(服务器部分)两部分. 前端主要是参数提取,包括维纳滤波降噪[14];后端主要是对从信道接收到的信号解码和解压缩.
1.2 ETSI-DSR-AFE 标准中的维纳滤波降噪
图1 是维纳滤波降噪模块的结构框图[13]. 由图1 可见,该模块由两个结构基本相同的部分级联而成. 第1 级的维纳滤波是对非白噪声进行白化处理,而第2 级是为了去除残留的白噪声.

图1 维纳滤波降噪模块的结构框图Fig.1 Wiener filter noise reduction block diagram
维纳滤波方法寻求一个线性滤波器,从加性噪声的干扰序列中恢复目标信号,设Sden为减去噪声的信号功率谱,Snn为噪声功率谱,时变信噪比RSN(f,t)= Sden(f,t)/Snn(f,t),则维纳滤波为

从式(1)可见,滤波的关键在于计算信噪比,而信噪比又取决于VAD 的效果,找出非语音帧来对噪声进行谱估计.
在第1 级维纳滤波中,根据VAD 检测结果,用非语音帧的功率谱估计可获得并更新噪声谱估计. 检测过程为:
①计算当前帧(80 个采样点)的对数能量值

其中,S(n)为输入的语音信号.
②根据Ef更新非语音帧对数能量平均值Em.Em可以看作是判决有无语音的对数能量门限.
③依据Ef、Em和对之前各帧的判决结果,以及相应设定的信噪比阈值,判决是否噪声帧.
在第2 级维纳滤波中,可根据各帧SNR 的估计值更新噪声功率谱估计.
2 基于level-building 的VAD
2.1 ETSI-DSR-AFE 标准中VAD 的问题
维纳滤波VAD 检测方法是AFE 标准的关键之一. 然而,大部分基于能量和基于过零率的VAD方法效果都未尽人意. 近年来,许多学者陆续提出改进的VAD 算法,如利用高阶统计量、长时谱信息、建立信号和噪声统计模型的方法等[15-16],它们针对某些特定条件都取得了一定的效果. 但这些方法都不适合普遍的噪声环境,这主要是由于背景噪声复杂多变造成的,而降噪算法又是为了减少这些干扰,这就变成了一个先有鸡还是先有蛋的问题.构造一个鲁棒性较好、较小受背景干扰的VAD 算法就成了解决该问题的关键.
2.2 基于level-building 的VAD
如图2,VAD 的本质是对一个N 帧语音序列{x1,x2,…,xN},找出其每个静音和语音交界处的语音帧的编号.

图2 将语音帧{x1,x2,…,xN}分割为N 段的示意图Fig.2 Divided {x1,x2,…,xN}into N section
设一条语音被分为m 段,其第i 段开始帧的编号为bi-1+1,结束帧的编号为bi,则VAD 的目标就变成了寻找边界的编号{b0,b1,…,bm},其中b0=0,bm= N,找到边界的编号就可将语音段和非语音段区分开. 为求得边界编号,可利用模板匹配的方法,根据语音和噪声特性的差异分别训练相应的模型进行匹配,但这又需用到噪声的先验知识. 实际应用时,噪声的特性往往是未知的,因此,本研究提出一种无监督分割方法,只利用本段语音的信息进行聚类,不考虑先验的噪声情况.
语音信号是一种准平稳信号,对于语音参数而言,每段语音的区别在于其统计特性不同. 若考虑到语音之间的静音部分,其统计特性和语音信号的差别就更明显,这是本研究的出发点. 因此,分割问题可转化为求最小统计特性总偏差的问题,即对给定边界{b0,b1,…,bm},使式(3)最小.

其中,ci是语音的第i 段的频谱序列{X(bi+ 1),X(bi+ 2),…,X(bi+1)}在某种距离测度定义下的广义的类心. 也就是说,需找到一个码本数为m 的矢量量化方法,对语音序列聚类,将其分类成m 个连续但不重叠的小段. 为解式(3),需解决语音频谱序列的距离度量问题和聚类过程中的优化问题.


其中,α = [1,α1,α2,…,αp]T,是描述频谱xn形状的线性预测逆滤波器多项式A(z)的系数,本研究采用Mel 频率倒谱系数(Mel-frequenly Ceptral coefficients,MFCC);Rn是xn的协方差矩阵;C 是用于规整的经验常数. 假设有N 帧互相独立的观测数据{x1,x2,…,xN},其联合概率密度函数为
将式(5)作为距离测度,代入式(3)可得到在似然测度下进行分割的似然函数
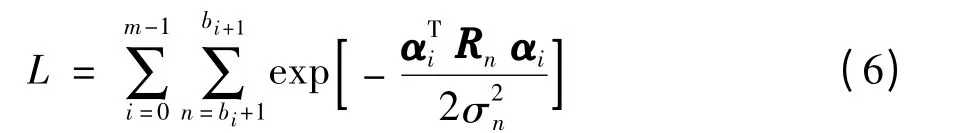
为优化聚类过程,对式(6)取对数,得

式(7)的中括号内即第i 帧语音参数和其对应的MFCC 矢量的类心ai在似然测度下的偏离值. 为求解分割的边界{b0,b1,…,bm},必须找到所有语音段和语音参数序列的最小似然偏离值,直接计算的话需先统计所有分割情况下的似然偏离值,再计算并比较总的似然偏离情况. 显然计算量过大,为减少计算量,本研究提出level-building 算法.
假设某条语音经分割后,其中第i 段的数据所有语音帧总的似然比偏离值
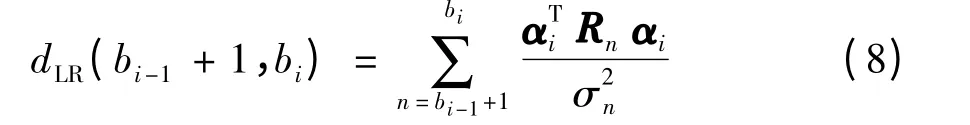
定义该条语音在分成i 段时的累计总偏差为D(i,bi),则分成i +1 段时的累计总偏差为D(i +1,bi). D(i+1,bi+1)取决于D(i,bi)与第i+1 段(结束点在第bi+1帧)的偏差dLR(bi+1,bi+1),即

式(9)中D(i +1,bi+1)的求解转换为求取对所有可能的bi+1中的D(i +1,bi+1)的最小值.
图3 是一个16 帧语音level-building 过程示意,它最后增至第9 个level,即被分成9 小段. 对于m段的分割而言,获得最小LR-distortion 即找到合适的D(m,N). 边界{b0,b1,…,bm}可通过回溯查找到. 找到语音和静音数据间的边界即完成VAD 过程.
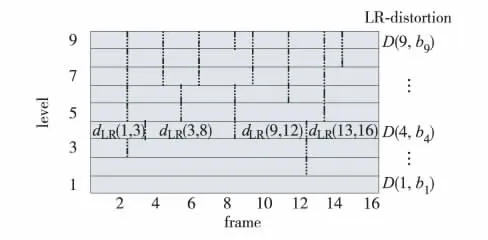
图3 语音分层增长分割过程Fig.3 Level-building process of speech
2.3 Level-building 的VAD 性能
为验证本研究提出的level-building VAD 算法的效果和鲁棒性,对一段干净语音及加了噪声的情况进行level-building 分割实验. 语音叠加的噪声分别为10、5、0 dB 的高斯白噪声和babble 噪声. 图4是对语音的分割结果,每种情况的第1 个图为语音波形图(横坐标为语音点数),第2 个图为无监督分割VAD 方法求得的语音和静音的边界,进行能量排序后,深色的表示语音数据(横坐标为语音帧数),第3 个图为语音能量.
由图4 可见,level-building 方法对干净语音可很好地求得静音数据和语音数据的边界点,对带噪语音数据仍能很好地求得边界点,即使信噪比为0时,对高斯白噪声和babble 噪声仍有效. 这是因为采用基于最大似然距离的聚类,受能量干扰较小.
3 说话人识别实验结果及分析
为验证ETSI-AFE 两级维纳滤波方法及本研究所提出的改进方法对鲁棒性说话人识别的效果,采用叠加了加性噪声的微软中文普通话数据库MSdata进行说话人辨认实验.
MSdata 在安静的办公室环境下,以16 kHz 采样率,16 bit 量化,使用麦克风及Soundblaster 采集卡录制,几乎不存在背景噪声对数据干扰的情况.MSdata 数据库共有100 个男性说话人,其中每人各有200 条不同文本内容的语音. 每条语音长度为3~19 s,平均长度为6 s. 说话人辨认实验中,随机选取每人200 条语音中的20 条作为训练集,总长度约为120 s. 测试集随机选取每人200 条语音中与训练集不相交的50 条,即100 ×50 条测试语音.测试时以1 条语音作为1 次测试.
分别对语音信号叠加不同幅度和不同类型的噪声信号,说话人辨认实验结果如图5 和图6. 噪声数据库源自Rice 大学信息处理中心提供的标准噪声库(http://spib.rice.edu/spib/select_noise.html).
图5 和图6 中MFCC 基准系统的参数包括静态MFCC 参数 (13 维)及其1 阶和2 阶动态参数ΔMFCC、ΔΔMFCC (各13 维),包含第0 阶参数,共39 维参数. ETSI-AFE 系统的特征参数按照ETSI-DSR-AFE 标准提取. LB-AFE 系统使用levelbuilding 方法对ETSI-AFE 标准第1 级维纳滤波中的用于噪声谱估计的VAD 模块进行替换. CMS +RASTA 系统采用一阶矩规整加上相对谱滤波进行噪声处理,说话人辨认模型为GMM 模型[17],模型混合度为64.

图4 对语音进行无监督分割Fig.4 Unsupervised Segmentation of Speech
图5 验证了在pink 噪声下各种说话人辨认系统的性能,在不同信噪比情况下,CMS +RASTA 方法都能提高系统的识别性能,ETSI-AFE 和level-building AFE 明显优于CMS +RASTA,level-building AFE略好于ETSI-AFE. 为进一步验证level-building AFE的鲁棒性,在噪声库中选取babble、factory1、factory2、F-16,white、pink 和Hfnoise 7 种不同的噪声,分别进行说话人辨认实验,结果如图6.

图5 粉红噪声环境下说话人辨认性能比较Fig.5 Speaker identification performance in pink noise
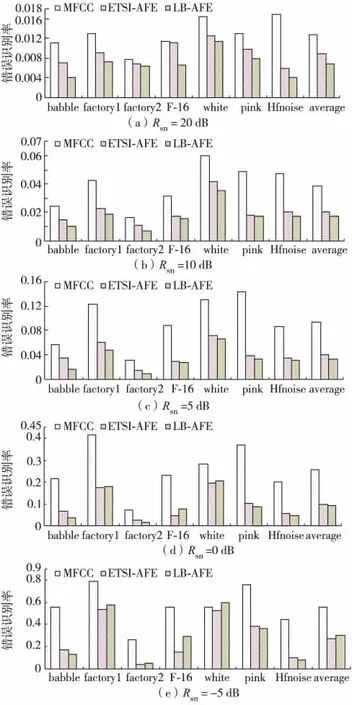
图6 不同噪声环境下说话人辨认性能比较Fig.6 Speaker identification performance in different noise environments
由图6 可见,ETSI-DSR-AFE 能大幅提高说话人辨认系统的鲁棒性,其中的两级维纳滤波能降低多种加性噪声的影响. 在各种信噪比情况下,错误识别率都有明显减少. 以babble 噪声为例,从-5~20 dB,ETSI-AFE 系统性能相对MFCC 改进分别为36.4%、40.8%、37.5%、69.1%、70.0%. 在其他6 种噪声情况下也有类似结果. 表明ETSI-AFE在各种噪声情况下都能取得较好的识别性能.
Level-building 方法对于ETSI-AFE 有进一步的改善. 仍以babble 噪声为例,从-5 ~20 dB,levelbuilding AFE 系统性能的相对ETSI-AFE 改进分别为42.9%、29.0%、54.9%、45.4%、22.8%. 但对其他6 种噪声情况并非所有信噪比条件下levelbuilding AFE 都优于ETSI-AFE. 从图6 可见,在5~20 dB 的常见信噪比情况下,level-building AFE都优于ETSI-AFE,在信噪比为0 dB 时,除F-16 噪声外,level-building AFE 也基本优于ETSI-AFE,但在-5 dB 时,3 种噪声环境中level-building AFE 优于ETSI-AFE,另外4 种level-building AFE 较差. 这主要是因为在信噪比非常恶劣时,语音信号已不符合高斯过程,采用似然偏离的情况,在距离测度上就难以区分语音和噪声,难以找出语音小段之间正确边界. 另外在分出语音和静音的边界后,再使用能量来判断语音和静音段,也可能会在低信噪比下判断不准,从而导致滤波和识别效果较差.
表1 列出了在5 ~20 dB 情况下7 种不同噪声的平均误识率. 由表1 可见,ETSI-AFE 系统性能较MFCC 改进了51.6%,level-building AFE 系统性能较MFCC 改进了60.7%,较ETSI-AFE 又改进了18.9%. 其中,babble 噪声的改进最明显,levelbuilding AFE 系统性能较ETSI-AFE 改进了38.2%.

表1 平均误识率5 ~20 dBTable 1 Average error rate 5 ~20 dB 单位:%
结果证明,level-building AFE 有效,在噪声不是极端恶劣时提高鲁棒性的效果更明显,而实际使用的场合信噪比一般在5 ~20 dB,level-building AFE 更有实际意义.
结 语
针对分布式说话人识别噪声鲁棒性问题,本文研究了业界在噪声鲁棒性语音识别方面有着较高水准的ETSI_DSR_AFE 标准的两级维纳滤波降噪方法. 在该标准的基础上,针对维纳滤波的VAD 模块,提出了一种基于似然距离的聚类方法对语音信号进行level-building 的逐层分割,找出语音和静音的边界点. 实验表明,这种方法具有很好的噪声鲁棒性,能够准确的找到语音和静音的边界. 当用其替代ETSI_DSR_AFE 标准中维纳滤波的噪声谱估计VAD 模块时,信噪比在大于0 dB 时,说话人辨认系统性能的相对改进达到了18.9%. 本研究提高了在复杂噪声环境下的VAD 效果和说话人识别系统识别率,有助于说话人识别进一步走向实用.
/References:
[1]ETSI ES 202 050 V1.1.5. Speech Processing,Transmission and Quality Aspects (STQ);Distributed speech recognition;Advanced front-end feature extraction algorithm;Compression Algorithms. Sophia Antipolis Cedex-FRANCE [S].
[2]Gales M J F. Model-Based Techniques Fornoise Robust Speech Recognition [D]. Cambridge:Dissertation University of Cambridge,1995.
[3]Reynolds D A. Channel robust speaker verification via feature mapping [C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. Hong Kong:IEEE 民Press,2003,2:53-56.
[4]ZHANG Xiang,WANG Hai-peng,XIAO Xiang,et al.Maximum a posteriori linear regression for speaker recognition [C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. Dallas(USA):IEEE Press,2010:4542-4545.
[5]Kim D K,Gales M J F. Noisy constrained maximumlikelihood linear regression for noise-robust speech recognition [J]. IEEE Transactions on Audio,Speech,and Language Processing,2011,19 (2):315-325.
[6]LU Yong,WU Zheng-yang. Maximum likelihood polynomial regression for robust speech recognition [J]ACTA Acustica,2010,35 (1):88-96. (in Chinese)吕 勇,吴镇扬. 基于最大似然多项式回归的鲁棒语音识别[J]. 声学学报,2010,35 (1):88-96.
[7] Garcia A A,Mammone R J. Channel-robust speaker identification using modified-mean cepstral mean normalization with frequency warping [C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. Arizona (USA):IEEE,1999:325-328.
[8]Sturim D,Campbell W,Dehak N,et al. The MIT LL 2010 speaker recognition evaluation system:scalable language-independent speaker recognition[C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. Prague:IEEE Press,2011:5272-5275.
[9] McLaren M,Van Leeuwen D. Source-normalised-andweighted LDA for robust speaker recognition using i-vectors [C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing.Prague:IEEE Press,2011:5456-5459.
[10]ZHANG Wei-qiang,LIU Jia. An equalized heteroscedastic linear discriminant analysis algorithm [J]. IEEE Signal Processing Letters,2008,15:585-588.
[11]Islam M R,Rahman M F,Khan M A G. Improvement of speech enhancement techniques for robust speaker identification in noise [C]// The 12th International Conference on Computers and Information Technology. Dhaka:IEEE,2009:255-260.
[12]CAI Yu,YUAN Jian-ping,HOU Chao-huan. Harmonic enhancement of speech signal using comb filtering [J]Chinese Journal of Scientific Instrument,2010,31(1):26-31.(in Chinese)蔡 宇,原建平,侯朝焕. 基于两级梳状滤波的语音谐波增强[J]. 仪器仪表学报,2010,31(1):26-31.
[13]ETSI TS 126 243 V10.0.0. Digital Cellular Telecommunications System (phase 2 +);Universal Mobile Telecommunications System (UMTS);LTE;ANSI C Code for the Fixed-point Distributed Speech Recognition Extended Advanced Front-end (3GPP TS 26.243 Version 10.0.0 Release 10)[S].
[14]Dusan Macho,Yan Ming Cheng. SNR-dependent waveform processing for improving the robustness of ASR frontend [C]// Proceedings of the IEEE International Conference on Acoustics,Speech,and Signal Processing. Utah(USA):IEEE,2001,1:305-308.
[15]Ghosh P K,Tsiartas A,Narayanan S. Robust voice activity detection using long-tterm signal variability [J]IEEE Trans SAP,2011,19(3):600-613.
[16]XIE Yan-lu,LIU Ming-hui,YAO Zhi-qiang,et al. Improved two-stage wiener filter for robust speaker identification [C]// The 18th International Conference on Pattern Recognition. Hong Kong:IEEE,2006,4:310-313.
[17]Reynolds D A,Rose R C. Robust text-independent speaker identification using Gaussian mixture speaker models [J].IEEE Transactions on Speech and Audio Processing,1995,32(1):72-83.
猜你喜欢
橡胶科技(2022年11期)2022-03-01
石油沥青(2021年3期)2021-08-05
电脑报(2020年50期)2020-03-10
农业机械学报(2020年2期)2020-03-09
舰船电子对抗(2019年4期)2019-09-10
中华建设(2019年7期)2019-08-27
太原科技大学学报(2019年3期)2019-08-05
计算机应用与软件(2017年3期)2017-04-14
洛阳师范学院学报(2017年2期)2017-03-12
发明与创新(2016年34期)2016-08-22
