
基于可拓数据挖掘的用户需求获取研究
2011-06-05 03:20王景华李献会
合肥工业大学学报(自然科学版) 2011年12期
刘 斌, 朱 明, 王景华, 张 利, 李献会
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.齐鲁师范学院 计算机系,山东 济南 250002;3.合肥工业大学 机械与汽车工程学院,安徽 合肥 230009;4.洛阳轴研科技股份有限公司,河南 洛阳 471039)
0 引言
用户需求获取作为产品概念设计最前端过程,是概念设计所要满足的设计目标的直接来源,对于新产品开发能否成功有着至关重要的影响。国内外对用户需求获取进行了相关研究。文献[1-5]通过QFD技术进行需求分析,为研究用户需求提供了通用框架。文献[6]采用Apriori算法挖掘用户需求信息,实现了对关联规则的有效提取。文献[7]运用规则挖掘和模糊聚类的方法,完成了用户需求与专家知识间的相互转换。上述研究分别从不同角度利用不同工具研究需求信息,但是,如何将用户需求中潜在的、变换的需求信息进行有效的提取、转化,没有得到很好的解决。
数据挖掘是一个从数据中找出某些模式的过程,这个过程必须是自动或是半自动的,而找出的模式应能够解释数据中的某些现象。在数据挖掘中,关联规则挖掘是一个重要的研究方向。企业通过挖掘用户需求信息中的关联规则,可以发现历史数据库中暗含的设计知识,以显式形式表达出来。本文结合数据挖掘和可拓变换,通过粒子群算法挖掘用户需求的关联规则知识;利用可拓变换方法生成新的可拓变换知识,以使工程师更好地理解、预测用户的潜在需求,设计出用户真正想要的产品。
1 用户需求信息中的关联规则
1.1 关联规则概念
关联规则挖掘是由文献[8]对购物篮分析时首先提出的,用以发现商品销售中的顾客购买模式。
用户需求信息中的关联规则挖掘意味着生成一系列有价值的IF-THEN规则,将用户需求信息数据分为若干属性的集合,确定出条件属性集合和结论属性集合,则每个规则由来自用户需求信息数据库的条件属性和结论属性组成。例如,以摩托车产品为例,一条关联规则可以是:IF(摩托车颜色为蓝色)THEN(摩托车的价格比较便宜)。这条关联规则可以帮助工程师理解客户需求,在设计定制化产品时作为参考。
条件属性集为C=(c1,c2,…,cm),每个ci表示一个条件属性;结论属性集D=(d1,d2,…,dn),每个di表示一个结论属性;这里对于条件属性cm的属性值取值范围为区间[1,Jm]任一整数,{1,2,…,Jm}对应于条件属性cm的所有可选项同理,结论属性dn的属性值所有记录为为历史记录的数量。
综上所述,基于用户需求信息的一条关联规则可以表示为:

1.2 评价准则
支持度与置信度是描述关联规则的2个主要指标。对于数据库T中一条关联规则,描述为IFETHENF,其中E包括了若干条件属性,F包含了若干结论属性。由此给出支持度sp与置信度cn的计算公式:取值范围为区间[1,Jn]中的任一整数。数据库中

其中,|T|为数据库中记录的数量;T(E&F)为记录中同时出现E、F的样本数目;T(E)为记录中出现E的样本数目。支持度描述了关联规则普遍性,置信度用以衡量关联规则的准确性。
本研究通过设定支持度和置信度阈值来选取关联规则。
2 基于粒子群算法的关联规则挖掘
当前,进化型算法(Evolutionary algorithms,简称EAs)应用于关联规则挖掘的方法被广泛应用于各个领域[9-10]。应用粒子群算法挖掘关联规则尚不多见,比较其他进化型算法,粒子群算法具有简单、易实现、计算过程中需调整的参数较少等优点。
2.1 粒子群算法
在粒子群算法中,每一个粒子即是算法的一个候选解。粒子i的当前位置可以表示为:xi=(xi1,xi2,xi3,…,xid),其飞行速度为:vi=(vi1,vi2,vi3,…,vid);飞行历史中的最优位置为pi=(pi1,pi2,pi3,…,pid);所有粒子的全局最优位置pg=(pg1,pg2,pg3,…,pgd)。速度和位置分别按(3)式、(4)式更新,即

其中,ω为惯性权重,较大时适合于对解空间进行大范围搜索,较小时适合于进行局部搜索;c1,c2为加速常数;r1,r2为[0,1]之间的随机数;t为当前迭代次数;ωstart为惯性权重的起始值;ωend为惯性权重的终止值。
2.2 用户需求信息关联规则的编码
对企业数据库中的用户需求信息数据属性进行转换,得到符合数据挖掘的数据模式。关联规则挖掘是在条件属性和结论属性之间进行的,对于粒子群算法编码,需完成将关联规则转化为粒子。一条关联规则向量S的编码为:S=(s1,s2,…,sm,sm+1,sm+2,…,sm+n),向量的前m项对应于C= (c1,c2,…,cm),向 量 的 后n项 对 应于D=(d1,d2,…,dn)。
其中,si为区间(1,Ji+1)上均匀分布的随机数;Ji为i位对应属性的最大属性值;[si]表示si所对应属性值([*]表示取下整数)。
每个粒子前件项对应于条件属性,后件项对应于结论属性。条件属性集中每个属性ci及结论属性集中每个属性di都对应着粒子中的一个数据位,粒子为m+n维向量。
2.3 适应度函数
适应度函数用于评价粒子的优劣,通过适应度函数评价,可以选出较优的候选解集。适应度的大小显示了粒子对于目标函数的适合程度,是用以评价粒子好坏的唯一标准。
为了得到支持度与置信度都较为满意的关联规则,本文采用对支持度与置信度分别设置阈值,并要求同时满足的方法对挖掘出来的关联规则进行评价,即选用支持度与置信度函数作为候选解的适应度评价函数。
2.4 算法流程
(1)将数据库中需求信息编码,随机产生初始种群,并初始化各参数。
(2)取出粒子,对该粒子进行处理,得到一条规则;对规则中的每个属性排列组合产生潜在规则集P,计算规则集P中每个规则的适应度值,删除小于阈值的规则,余下规则存储于规则库G中,并且记下P中适应度最高的规则比较个体历史最优和种群全局最优,并更新个体历史最优和种群全局历史最优;更新粒子的速度和位置。
(3)判断是否满足终止条件,若满足,算法结束;若不满足,则返回步骤(2)继续执行。
(4)将规则库G中的数字化规则进行解码,转化为用户识别的关联规则。
3 基于可拓变换的新规则生成
对于上述挖掘出的IF-THEN规则知识,分别对前件E和后件F寻求可拓变换,形成新的可拓变换规则知识[11]。
定理1 给定规则E1⇒F1,E2⇒F2。若存在条件的可拓变换φE1=E2,一定存在变换φ′,使φ′F1=F2,则存在规则:
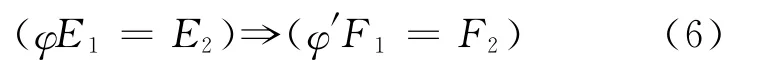
定理2 给定规则E1⇒F1,E2&E3⇒F1。若存在条件的可拓变换φE2=E1,则存在规则:

上述定理用于对规则进行推理,以形成可拓变换规则。
4 实例验证
以某企业摩托车产品需求信息为例。假定数据库需求信息有车型、颜色、体积、外观、安全性、舒适性、价格、满意度8个属性,共有10条用户交易记录,见表1所列。
表1中第1列是用户需求的相关属性名称,每一行代表一条交易记录,因用户需求多以语言形式表述,需将属性数字化。
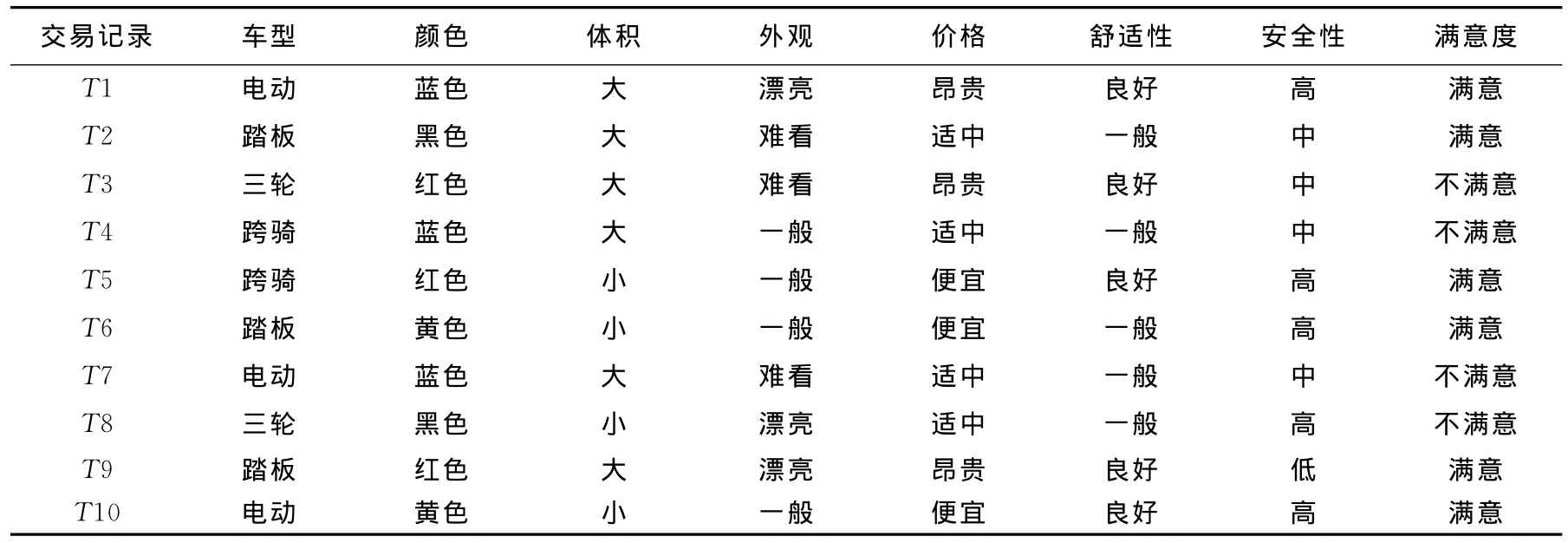
表1 用户交易记录
由表1可见,根据实际需要将属性分为条件属性集C和结论属性集D,并用区间[1,Jm+n]中任意整数表示需求属性不同等级,即属性值,见表2所列。
算法参数设置如下:种群规模N=20,最大迭代次数M=200,ωstart=0.9,ωend=0.4,加速常数c1=c2=2,vmin=-1,vmax=1,支持度和置信度阈值分别为sp*=0.25,cn*=0.60。
根据以上建立的数学模型与设计的算法,利用MATLAB7.0编程进行关联规则的挖掘,最终得到满足适应度函数的关联规则集,都具有较高的支持度和置信度,见表3所列,得到了13条关联规则及其2个指标值。
从表3中可以看出,挖掘出关联规则前件项最多包含2个属性,后件项仅含1个属性,这样的规则易于理解与分析。
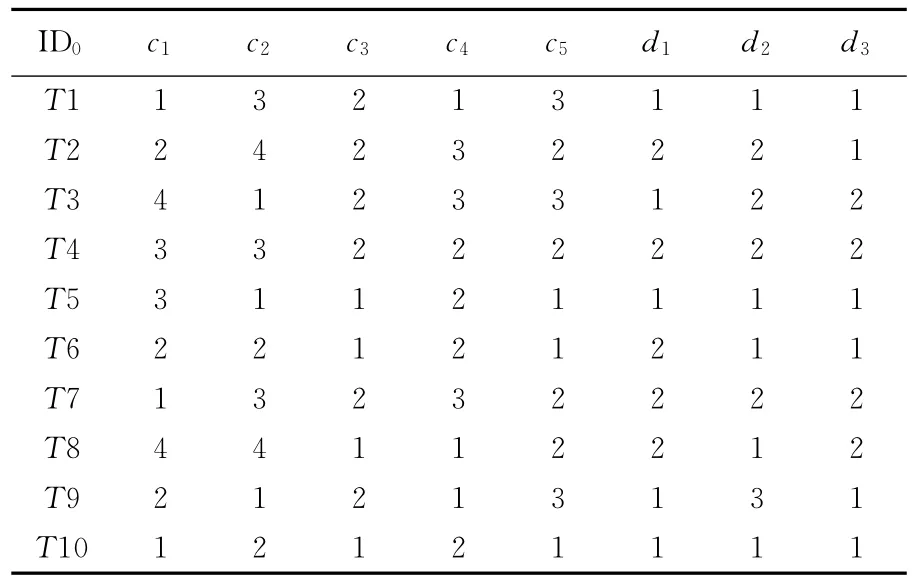
表2 交易记录数字化
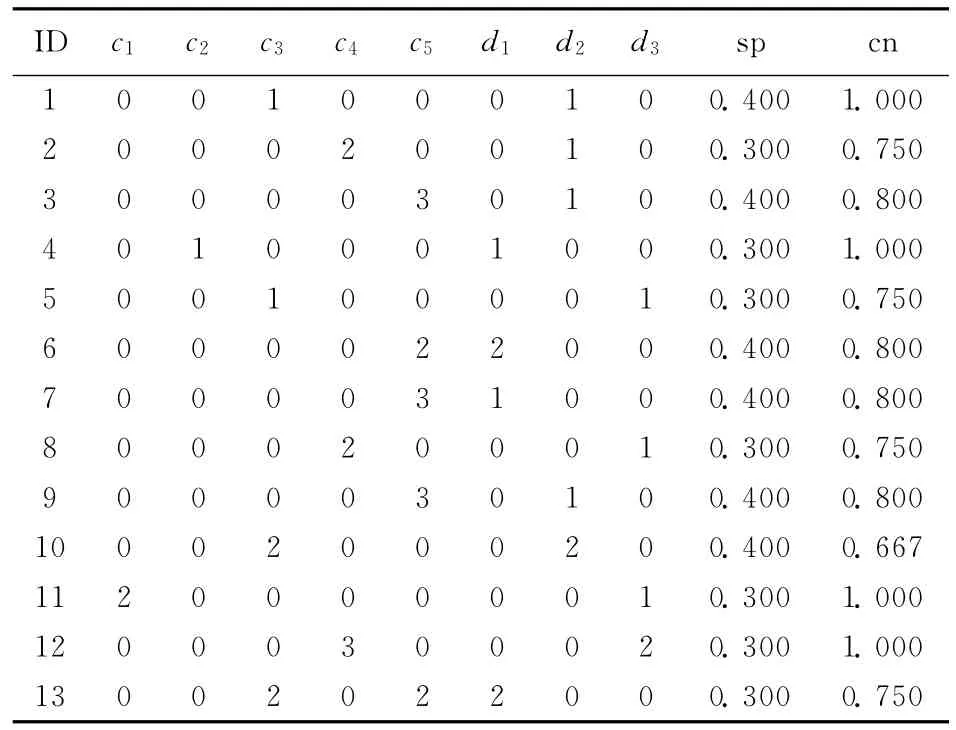
表3 挖掘出的关联规则
参照表1对表3中的规则加以解码,并分别对前件和后件进行可拓变换,再运用(7)式和(8)式推理出可拓规则知识。因规则较多,这里仅以个例说明推理过程。
例如对第7条和第13条规则解码,得到以下关联规则。
第7条规则:IF(车价格昂贵)THEN(舒适性良好);第13条规则:IF(车体积较大&价格适中)THEN(舒适性一般)。
对上述解码后的关联规则存在可拓变换φ和φ′使得:

由(7)式得到可拓变换规则:

5 结束语
基于数据挖掘和可拓变换的需求获取方法,将粒子群算法用于关联规则数据挖掘,通过设定支持度和置信度阈值寻取规则知识,实现了挖掘用户需求可拓规则知识的功能。因阈值选取通常依据设计者经验进行决策,主观性较强,故阈值大小的选取方法是下一阶段重点研究的问题。
[1]许永平,石福丽,杨 峰,等.基于QFD与作战仿真的舰艇装备需求分析方法[J].系统工程理论与实践,2010,30(1):167-172.
[2]熊 伟,王晓暾.基于质量功能展开的可信软件需求映射方 法 [J].浙 江 大 学 学 报:自 然 科 学 版,2010,44(5):881-886.
[3]王晓暾,熊 伟.质量功能展开中顾客需求重要度确定的粗糙层 次 分 析 法 [J].计 算 机 集 成 制 造 系 统,2010,16(4):763-770.
[4]宋 欣,郭 伟,刘建琴.QFD中用户需求到技术特性的映射方 法 [J].天 津 大 学 学 报:自 然 科 学 版,2010,43(02):174-179.
[5]鲍 宏,刘光复,张 雷,等.面向绿色设计的客户需求转化方法研究[J].合肥工业大学学报:自然科学版,2010,33(4):481-486.
[6]Liao S S,Hsieh C,Huang Suiping.Mining product maps for new product development[J].International Journal of Production Research,2006,44(18):4027-4041.
[7]Jiao J,Zhang L,Zhang Y,et al.Association rule mining for product and process variety mapping[J].International Journal of Computer Integrated Manufacturing,2008,21(1):111-124.
[8]Avasere A,Omiecinski E,Navathe S.An efficient algorithm for mining association rules[C]//Proceedings of the AAAI Workshop on Knowledge Discovery in Databases,1994:181-192.
[9]Li Cunrong,Yang Mingzhong.Association rules data mining in manufacturing information system based on genetic algorithms[C]//3rd International Conference on Computational Electromagnetics and Its Applications,ICCEA 2004:153-156.
[10]Li Feng,Liu Ziyan.Effects of multi-objective genetic rule selection on short-term load forecasting for anomalous days[C]//2006IEEE Power Engineering Society General Meeting,PES,2006IEEE Power Engineering Society General Meeting,2006:10-100.
[11]陈文伟,杨春燕,黄金才.可拓知识与可拓知识推理[J].哈尔滨工业大学学报,2006,38(7):1094-1096.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
核科学与工程(2021年4期)2022-01-12
大众投资指南(2021年35期)2021-02-16
计算机应用(2018年5期)2018-07-25
郑州大学学报(工学版)(2018年2期)2018-04-13
电力与能源(2017年6期)2017-05-14
中国塑料(2016年11期)2016-04-16
信息通信技术(2015年6期)2015-12-26
轴承(2015年2期)2015-07-25
电子设计工程(2014年18期)2014-02-27
