
基于倒排索引的答疑系统知识库文本研究
2010-10-26 09:06宁可为
湖北开放大学学报 2010年6期
宁可为,王 炜
(新疆师范大学 教育科学学院,新疆 乌鲁木齐 830054)
基于倒排索引的答疑系统知识库文本研究
宁可为,王 炜
(新疆师范大学 教育科学学院,新疆 乌鲁木齐 830054)
通过对自动答疑系统的知识库存储及检索方式进行分析,提出了以倒排索引方式对答疑系统知识库文本进行重构,实现了知识库文本预处理和建立倒排索引功能,该系统的建立提高了文本内容的检索的准确率和查全率,使用户获得更好的体验。
知识库;倒排索引;文本;答疑系统
一、引言
在面向某学科的自动答疑系统中,我们把一些常用知识点(概念)作为的答疑系统中问句答案进行存储,而学科分类中,有几十个学科,每个学科至少有几十门课程,每门课程中至少有若干个知识点,而每个知识点又对应若干个问句答案。这样,知识库中的知识(问句答案)中就存在上千万条数据。知识库组织关系到知识查询的效率及用户的体验,如果单纯的数据库查询,在海量知识文本中查找用户所需的问句答案其查询时间是非常可观的。如此巨大的知识库文本如何存储,并且如何在几秒内返回搜索结果确实是一项挑战。基于以上分析,答疑系统中的知识库不能简单是数据库中几张表,而是一个复杂的数据结构,本文根据自动答疑系统的检索特性提出一个良好的数据存储结构——索引,极大地提高了系统的检索效率。
二、知识库文本的预处理
1.文本的归一处理
答疑系统与搜索引擎的功能有一定区别,也导致处理文档也有不同区别。根据答疑系统检索的特点,一般一个问题对一个文档中的某一段进行搜索,抽取其中的答案返回给用户,用户也不必浏览知识库源文档。因此对于大文档必须以一个固定的量为单位及以段落为分割点切分为多个小较少的文档,并以统一的.txt文件进行存储。检索时面对统一格式文档能提高文档的加载及检索速度。
2.索引关键词提取
在信息检索中,常常用文本中含有一些关键词代表了语句的主体含义,在建立索引时文本中的关键词是索引项一部分,因此,从文本中提取索引项就是从给定文本的连续字符中找出完整的单词。英语,法语等语言词与词有天然的分隔符空格,单词确定较为容易,对于汉语要在句子中确定单词就极为困难,为了能正确提取单词一般先对句子进行词法分析并采用基于词库和 N元组为索引单位的混合方式切分出索引关键词。现在流行的分词系统如中科院的ICTCLAS分词系统及JE分词系统,本文采用的是ICTCLAS分词,它能高效地在句子切分出单词,“分词正确率高达97.58%”[1]。根据分词系统可以把整编文档切分成一个个离散的单词,但并不是所有单词都可以作为关键词,还应该对单词集进行过滤去掉无用词。
根据自然语言词性特征将单词分为内容词(Content word)功能词(Function word)两类[2]。其中内容词表示某个特定的概念的词。如汉语中的名词,动词等。功能词表示词与词之间的关系,如汉语中的助词,连词,语气词等等。经过大量统计发现它们频繁出现在文本中,其表义值非常低,选择索引词条时应该被过滤掉。去停用词方法是把无用词构建成一张停用词表(stop list),凡是这张表中出现的词都将被过滤掉。
三、知识库的索引
对知识库文本建立索引方式常用的有 3种,分别是倒排,后缀数组和签名文件。倒排索引被当前主流搜索引擎所广泛使用,它对关键词的检索非常有效。在倒排索引中,无论多大数量的文本数据库,总能够规范出一个关键词表,所有关键词的数量不会随文本内容的增长而线性增长。据统计对于1GB的文本信息,倒排文档的关键词表的大小在5MB左右[3]。由于倒排文档的组成特点,使得许多数学检索模型(如布尔模型,集合运算等)能够方便地用于信息检索中。因此本文采用倒排索引结构。
1.倒排索引结构
本文将知识库索引结构如图 1所示,具体分如下几部分:主文件索引MX(Master File Index),主要为知识库源文档提供一个顺排文件。MX结构:文档号,文档分值,地址指针。其中文档号是对应知识库源文档的编号,可通过折半找查定位到该源文件,分值是根据文档激励因子及长度因子计算出的文档得分。

图1 索引结构
倒排文件索引IX(Inverted File Index)保存关键词和其文档集合之间关系映射,能快速找出要检索的关键词所在的文档号集合。IX结构:关键词序列,目长(含有该关键词的记录的条数),文本号向量,IF地址指针。本文新增“文本号向量”元素取代传统倒排文件的“记录号集合”[4]元素,文本号向量从左边第一位起对应该着所有文档号。通常,计算包括两个查询词的文档集合的交集时间复杂度为 O(m*n),通过文本号向量计算其交集时间复杂度为O(1)。检索系统给出复数个查询词时,仅需要进行文本号向量间的逻辑运算能就高速检索出所有关键词共同所对应的文档号。
倒排文件IF(Inverted file)为降低IX文件所占用的内存容量把IX中与关键词相关的文档号及关键词相关信息转存到IF中。IF结构:文档号,位置信息。其中位置信息是关键词在本文档中出的位置。
专用词表RT(Related Terms)是为面向特定领域的答疑系统设计的词表。RT的构成以IX为基础,加入词间关系的指针,帮助用户选准主题词,扩大检索途径,提高查全率与查准率。
2.倒排索引的建立
建立倒排索引就如同写一本书的目录一样,目录是章节标题对应页码,对全文搜索来讲,倒排索引就是词对应该文档编号。通过分词后普通文档的存在形式为:
Doc1 KeyWord1,KeyWord2,KeyWord4,KeyWord5(形式1 )
Doc2 KeyWord1,KeyWord2,KeyWord3
Doc3 KeyWord1,KeyWord4
Doc4 KeyWord3,KeyWord4
Doc5 KeyWord3,KeyWord5
建立倒排索引就是将此过程翻转过来,如下:
keyWord1,keyWord2,KeyWord4,KeyWord5 Doc1(形式2)
KeyWord5,KeyWord3 Doc5
在知识库建索引时,把形式 1转化形式 2并且把KeyWord 与Doc 进行归并,消去重复的DocID,计算出每个文档的得分和关键词出现在文档的位置信息以升序方式排列存储,并将文本号向量代替文档号消去文档号(如表1所示)。
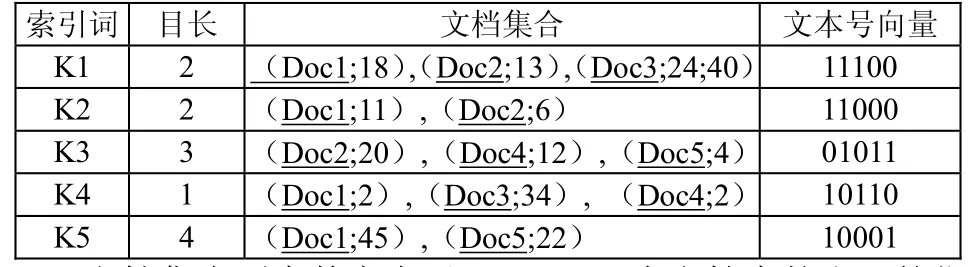
表1 归并后的索引
文档集合列中数字表示KeyWrod在文档中的出现的位置,并按出位置升序排列。Doc(i)不存储在文件中。实际应用中对KeyWord进行排序并对其进行折半查找可以提高关键词的检索速度并能达到高速的数据插入。
当知识库有大量数据时,倒排表会变得非常庞大,为了提高检索速度检索系统必须将倒排表载入内存,就可能导致内存溢出,系统的性能瞬间降到为零。本文采取一种倒排索引重组的方法,拿关键词部分到内存中的词典项中过行Hash查找,将倒排索引(IX)的右部存在倒排文件(IF)中,并将原先的右部改成在IF文件中的偏移地址,形成对应的指针项读取指定的文件中倒排表。例如:
K1 (18),(13),(24;40),11100
K2 (11),(6), 11000
经过处理在内存中的倒排表便为以下形式
K1 File1,3,StartPos1,Len1,11100
K2 File1,2,StartPos+Len1,Len2,11000
File1∶ (18),(13),(24;40), (11),(6)
上面File1是指倒排文件(IF) 的文件名,StartPos 是指倒排表右部在索引文件中的偏移位置,Len是指倒排表右部在索引文件中的长度。
另外为了提高检索速度,在建立索引时把知识库中的源文档信息以记录形式按升序编号形成主键 DocID存储存在 MX文件中。当检索系统通过文本向量号逻辑运算后会得关键词所属的DOC的集合{doc1,doc2,…},我们要找原始文档,只要通过对MX进行折半查找便可得出DOC的集合所对应的原文档信息。
3.文档的分值(score)计算
当检索系统对用户所提的问题进入一次预查找时,可能返回一系列与关键词相关文档,要做到检索的结果精确,降低答案相似度计算量,应该优先将与问题最相关的文本优先送出,然后与优先送出的文档集合进行相似度计算。本文对检索到的文本增加一个分值属性(文档分值),根据分值进行排序,文档的得分越高,就与用户所提的问题越接近。分值一部分由检索时根据关键词的“词条频率 TF(Term Frequency)*反转文档频率 IDF(Inversed Document Frequency)公式”[2]临时计算得出,另一部分由如下两个因子得出并存储在MX文件中。
(1)文档的长度因子
计算公式:1.0/SQR(numTerms)其中numTerms为单个文档词条总数。文档集合中一般含有长短不同的文本,长文本会出现同一个索引项被反复使用的倾向,且长文本中的索引项的种类也多,与查询出现的索引项相同的机会相应增加,这就使长文本的索引项有较大的权重,长文本与短文本相比长文本被检索的概率要高。为了消除文本长度带来的影响,本文采用计算文档的长度因子方式降低长文本的分值来达到最后文档得分的平衡。当被索引的文档中的词条数量越多,则其长度因子就越小。
(2)激励因子(boost) 在对某文档进行索引时,知识库构建者想人为增加某个文档相关度,使其在搜索结果中排在更靠前的位置上,可以通过增加boost值,其值越大其相关度越大,就越接近用户所提的问题。
四、结束语
自动答疑系统中进行问句答疑就是以毫秒级的速度对海量知识库文本进行关键字匹配找出得分最高的文本序列,然后根据用户问句与文本序列进行语义相似度计算得出最终结果。对于拥有海量数据的知识库来讲,知识库文本存储结构的优劣直接影响查询效率,实践证明对其知识文本采用倒排索引结构进行索引存储能极大地提高数据检索速度。
[1] 张辉丽. 计算机邻域中文自动问答系统的研究[D].天津大学,2006.
[2] 邰晓英.信息检索技术[M].科学出版社,2006.
[3] 邱哲,符滔滔.开发自己的搜索引擎――Lucene2.0+ Heritrix[M].人民邮电出版社,2007.
[4] 袁津生,赵传刚.搜索引擎与信息检索教程[M].中国水利水电出版社,2008.
[5] 卢亮,张博文.搜索引擎原理实践与应用[M].电子工业出版社,2007.
[6] 苏新宁.信息检索理论与技术[M].科学技术文献出版社,2004.
Research of Knowledge Database Document of Question Answering System based on the Inverted Index
NING Ke-wei,WANG Wei
The present study, by means of the analysis of Knowledge Database Document of Question Answering System (KDDQAS for short) and the Inverted Index, proposes the way of applying the Inverted Index to reconstruct the texts of KDDAQS, and then achieve the pre-management of knowledge database and the function of Inverted Index. The construction of this system can enhance the accuracy of query and the full use when indexing texts. Users on this occasion can have a better experience than before.
Knowledge database, Inverted index, Document, Question Answering System
G254.36
A
1008-7427(2010)06-0148-02
2010-04-02
新疆师范大学研究生科技创新项目基金,项目编号:20091106。
猜你喜欢
工会博览(2022年8期)2022-06-30
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
制造技术与机床(2019年6期)2019-06-25
新校长(2018年7期)2018-07-23
中国医疗保险(2018年3期)2018-07-14
信息安全研究(2016年4期)2016-12-01
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
