
基于滤波器的聚类算法
2010-08-01 09:07吴腾飞
天津大学学报(自然科学与工程技术版) 2010年10期
张 强,李 成,吴腾飞
(天津大学精密测试技术及仪器国家重点实验室,天津 300072)
聚类分析是一种重要的无指导学习方法,有着广泛的应用领域.在图像处理方面,聚类被用来实现图像的自动分割、人脸的自动识别.在地球物理方面,聚类被用来处理卫星遥感信息.在生物医学方面,聚类被用来分析基因表达的关系.在文本处理方面,聚类被用来实现因特网中文本的自动分类.
当前的聚类算法主要有 4类:①划分方法,如文献[1-2]等,其缺点是确定参数 K困难,算法对噪声敏感;②层次方法,如文献[3-5]等,其缺陷是聚类质量较低;③密度方法,如文献[6-7]等,其缺点是计算量过大,不适合处理大量数据,对参数过分敏感;④网格的方法,如 CLUGD[8-9]等,其缺点是对网格大小过于敏感,生成的簇的形状不是水平的就是垂直的,结果精度低.
针对以上问题,笔者提出了基于滤波器的聚类算法 (filter-based clustering algorithm,FBCLUS).其主要贡献是:①利用卷积定理和傅里叶变换,提出了频率滤波法来消除噪声的干扰;②提出了单阈值、多阈值幅度滤波法消除噪声和提取不同密度的感兴趣区域(可能包含聚类簇的区域);③提出了一个新的数学形态学算子,从感兴趣区域中提取聚类簇.
FBCLUS算法的特点有:①能够发现任意形状的聚类;②计算复杂度与数据量呈线性关系;③能够区分不同密度性质的聚类簇;④抗噪声能力强;⑤对网格大小有一定的适应性;⑥聚类结果与数据输入顺序无关.
1 FBCLUS聚类算法
FBCLUS算法在思想上借鉴了数字信号处理的原理:提出聚类滤波方法降低噪声水平,通过数学形态学方法提取聚类簇.FBCLUS分为 3步:①将数据空间网格化;②进行频率滤波和幅度滤波;③以数学形态学方法发现聚类簇.
FBCLUS的第 1步是将数据空间划分为等间距的网格,每个网格保存着其包含数据对象的个数.如果将数据集看作多维度信号,那么网格中数据对象的个数就标志着该网格处信号的强弱,通过信号的滤波和数学形态学处理,最终得到聚类簇.数据空间网格化的目的是浓缩信息,提高后续处理的速度.确定合理的网格大小(或者疏密)对后续处理有重要影响,目前提出的网格聚类算法对网格大小十分敏感,网格大小的变化对聚类结果有严重的影响.笔者提出的FBCLUS算法由于采用了模板滤波和数学形态学聚类,所以对网格的大小有一定的适应性.
1.1 频率滤波
实际应用中获得的数据通常含有大量的噪声对象,它们不但影响聚类的精度,同时也加大了计算量,所以有必要将它们滤除.如果将数据集视为多维度信号,那么聚类簇和噪声所在区域表现为不同的特征[10]:聚类簇所在的区域信号以低频为主,信号的幅度大,信号的能量高;噪声所在的区域信号以高频为主,信号的幅度小,能量低.
文中提出了使用频率和幅度两种滤波器过滤数据集的方法,以提高聚类处理的精度.首先,使用频率低通滤波器去除噪声所对应的高频信号;然后,使用幅度滤波器滤除残存的小幅度噪声信号.经过两次滤波处理后,噪声水平明显降低,为提高聚类簇的质量提供了保证.为了降低频率滤波的计算复杂度,提出了时域和频域的综合滤波法,避免了对整个空间的变换和反变换.实验表明,该方法有很好的精度和效率.
频率滤波可以直接施加于信号,也可以先对信号做变换(如傅里叶变换、小波变换等),然后对变换后的结果进行滤波.前者称为时域滤波,因为信号所处的空间是时域空间;后者称为频域滤波,因为变换后的空间是频域空间.在时域中进行频率滤波的优点是计算量低,因为它不需要进行空间变换.但是在时域中信号的频率特性没有被明显展示,所以频率滤波器设计困难.在频域中进行频率滤波的优点是滤波器设计简单直观,因为信号直接表现为频率的函数.但是频域滤波需要对数据集进行变换,计算量大.
文献[11]在聚类中采用了频域滤波,使用小波变换实现时域到频域的变换,在频域中使用低通滤波器实现过滤.文献[11]只考虑了不同区域的频率特性而没有考虑幅度特性.其算法优点是抗噪声强、精度高;缺点是需要对整个数据空间做小波变换和反变换,计算量大.
笔者提出的频率滤波方法综合了时域和频域滤波的优点,避免了各自的缺点,不但精度高而且减小了计算量.其核心思想是:在频域中设计低通滤波器;根据卷积定理,使用傅里叶反变换得到时域空间中对应的低通滤波器;在时域中完成滤波.其优点是:①在频域中能够方便地设计出高质量的滤波器,通过傅里叶反变换在时域中得到的对应滤波器具有频域中相同的性能,这是由卷积定理保证的;②使用时域滤波器直接滤波避免了空间的傅里叶变换和傅里叶反变换,减少了计算量.
下面详细讨论频域中低通滤波器的设计和时域中对应滤波器的获得以及时域中滤波的处理.
频域中频率滤波的数学模型为

式中: (,)F u v为数据集 (,)f x y在频域的傅里叶变换,也就是要被滤波的对象; (,)H u v是频域中滤波器函数,完成对信号的滤波; (,)G u v是对 (,)F u v滤波后的结果.问题的关键是如何确定频率滤波器 (,)H u v.以原型法设计频率滤波器,确定滤波器的类型,再确定滤波器的参数.采用原型法的最大好处是现有的滤波器理论成熟,可以很容易地设计出符合要求的滤波器.主要考虑理想低通滤波器、巴特沃思低通滤波器和高斯低通滤波器[12].以这 3种滤波器为设计原型是因为它们的频率特性曲线涵盖了从尖锐陡峭(理想低通滤波器)到圆滑平缓(高斯低通滤波器)的整个范围.理想低通和高斯低通滤波器是两个极端,巴特沃思低通滤波器则介于二者之间,为过渡类型.
在频域中完成滤波器的设计之后需要将它变换到时域中,进而完成滤波.卷积定理提供了理论依据,即频域的乘积对应于时域的卷积


由卷积定理和傅里叶反变换就可以获得需要的时域滤波器 (,)h x y,从而可以直接对时域中的数据滤波.现在时域空间是大小为R T×的网格,应采用离散形式的卷积运算,即式中:(,)h x y的大小(作用范围)是R T×个网格.为了提高处理速度需要将 (,)h x y做得小一些,文献[12] 指出以小尺寸的 (,)h x y在时域滤波的效率高于频域滤波,同时有很好的滤波效果.下面采用大小为rt×的滤波器,并用模板实现与网格的卷积,即
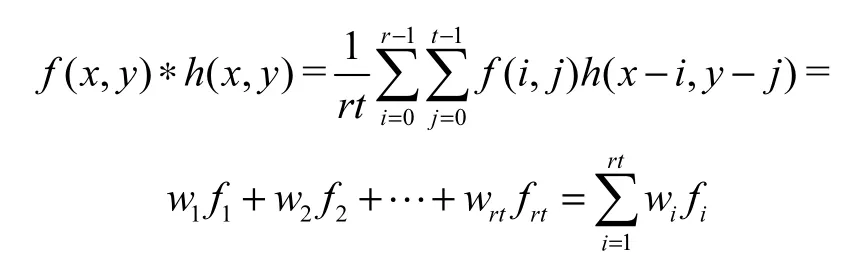
式中:iw为掩模的系数;if是与该系数对应的网格信号强度(即网格中含有数据对象的个数).
以模板计算卷积的过程是在网格中逐个网格地移动模板,在每一个网格(x,y)处滤波器的响应由模板的掩模系数与相应网格乘积之和给出.对于一个3 3×的模板(见图1),在网格(x,y)处卷积结果为

计算中要求网格(x,y)与模板中心0,0w 对应.对于rt×的模板,r和t都要求是奇数.

图1 3×3的模板Fig.1 3×3 mask
经过频率滤波之后高频噪声被大幅度衰减,但还会有些残存,笔者采用幅度滤波法以进一步降低噪声水平.
1.2 幅度滤波
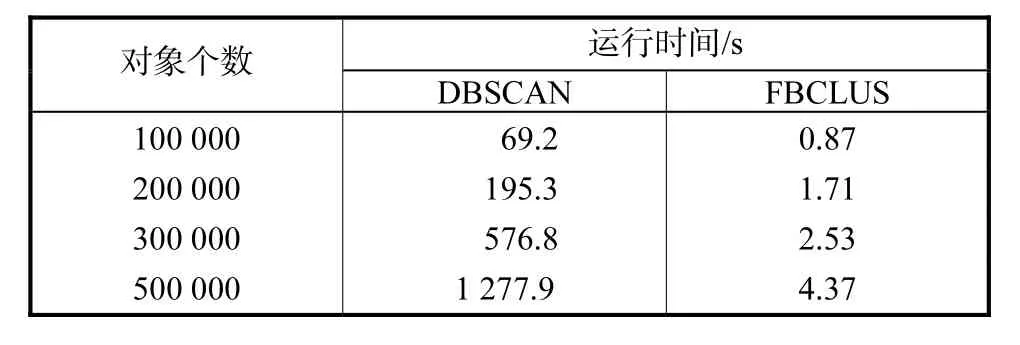
表1 DBSCAN和FBCLUS的运行时间Tab.1 Run time of DBSCAN and FBCLUS
表1为DBSCAN和FBCLUS的运行时间.从表1可知,噪声区域的信号强度明显小于聚类簇区域,所以文中提出通过信号幅度的差异来进一步滤除噪声.幅度滤波的思想是确定一个幅度阈值ξ,所有幅度小于ξ的区域都视为噪声加以滤除,其数学表达为
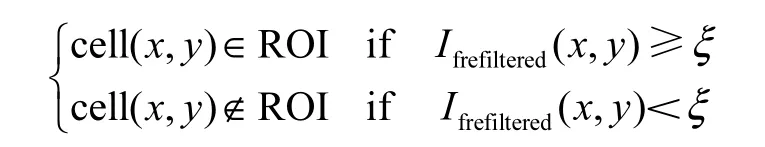
式中cell(x, y)为中心坐标为(x,y)的网格,Ifrefiltered(x, y )为网格cell(x, y)经过频率滤波后的信号强度;ROI(regions of interest)表示后续聚类处理的感兴趣区域.如果网格(x,y)的信号强度高于幅度阈值ξ,则表明该网格可能属于某个聚类簇,需要算法进一步分析处理;反之,表明该网格信号强度太小,则属于噪声,要加以滤除.
幅度滤波的关键是如何确定合理的幅度阈值ξ,笔者以直方图方式选择幅度阈值.通常情况下,经过频率滤波后的信号幅度是非负的实数,呈现为连续分布.为了构建直方图,需要对其离散化,采用均匀量化,将信号幅度转化为非负整数.然后分别计算各个幅度值对应网格数量的百分数,其数学处理方法是:设非空网格的总数为 M,幅度值为 i的网格数量是则幅度值为 i的网格数量百分比为以幅度值 I为横轴,以iP为纵轴生成幅度直方图.幅度直方图一般呈多峰、谷分布,因为噪声信号的强度很低,所以选取第一个明显的谷底对应的幅度值作为阈值ξ即可.通过以上的幅度滤波,整个空间被分为 ROI区域(可能属于某个聚类簇)和噪声区域,所以这种幅度滤波也可以看作是一种二值划分问题.
为了进一步提高聚类分析的精确性,又提出了多阈值的幅度滤波方法,它对应于多值划分问题,其核心思想是:呈多峰、谷分布的幅度直方图中每一个峰及其附近隆起部分都反映某一种特定的信号强度分布,同时也对应于特定的数据点密度分布.而两个峰之间的谷底则是两种不同密度分布的分割点,选取这些谷底对应的幅度值作为幅度阈值,就可以将数据空间划分为不同密度的区域,每一种密度区域都可能对应不同的物理性质.多幅度阈值的数学表达为

1.3 数学形态学聚类
经过频率和幅度滤波之后,得到 ROI区域,对于二值幅度滤波,ROI区域只有一个,而对于多值幅度滤波,ROI区域有多个,每一个 ROI对应的区域密度不同,需要分别处理.下面任务是从每个ROI区域中提取由相连网格构成的聚类簇.
笔者提出了一个数学形态学算子完成聚类簇的搜索,其伪代码见算法,其中⊕代表膨胀运算,Δ为膨胀运算的结构元素.算子处理过程:第 1步,以 ROI区域作为种子集合 seeds,并从中任意取出一个没有被处理的网格p作为起始点 Xi进行第i轮迭代.第2
0步,以起始点为中心进行膨胀,并将膨胀后新得到的网格作为中心继续膨胀,直到没有发现新的网格为止.为了保证膨胀不会超出 ROI区域,需要将新得到的网格与seeds取交.第3步,将上面膨胀得到的结果归属于一个新的聚类簇 Ci,并从种子集合中去除已经处理过的部分,如果种子集合不为空,则返回第1步继续第 i+1轮迭代.此外,这一步还滤除了体积过小的聚类簇.第4步,当迭代结束后输出得到的聚类簇.

笔者提出的数学形态学算子本身具有一定的降噪能力,它主要消除那些体积过小相互集聚的网格,如图 2所示.图 2(a)中小黑点是一些高密度网格的聚集体,数学形态学算子能够将它们滤除(见图2(b).图 2(a)中小黑点出现的原因是:为了提高效率,对频率和幅度滤波均采用小尺寸的模板,从而导致抗局部高密度噪声能力的下降.但是,数学形态学算子只能区分体积大小的不同,而不能区分密度的疏密,所以必须与频率和幅度滤波相结合才能取得较好的效果.

图2 新的数学形态学算子的降噪效果Fig.2 Filtering effect of new mathematical morphological operator
1.4 算法参数的选择
滤波器模板的大小对算法的计算复杂度有很大的影响,模板越大,计算量越大,文献[12]指出在使用小模板的情况下,卷积的计算量会明显小于傅里叶变换.通常模板大小需要由实验决定,经验表明:在数据点密集区域模板中能够包含10个以上的数据点就能基本满足要求.在某些情况下,小尺寸模板会导致局部高密度噪声的滤除不净(见图 2),这可以由提出的数学形态学算子解决.
膨胀运算结构元素的大小决定了算法对提取聚类簇时的黏合性的强弱.当网格划分过密时,聚类区域相对分散,要采用较大的结构元素;反之,当网格划分稀疏时,聚类簇区域相对集中,要采用较小的结构元素.可以通过试探法决定结构元素的大小:首先结构元素的大小取一个较小的值,然后逐步增大结构元素的大小,此时得到的聚类簇个数会逐步减小,当增加结构元素的大小而聚类簇个数变化不大的时候,就找到了合适的大小.
对于多阈值幅度滤波得到的多个 ROI区域,由于不同类聚类簇的密度差异较大,需要分别确定结构元素的大小,然后再提取聚类簇,这样就能够保证类内样本较为稀疏的时候,算法判别正确.
滤波器模板和膨胀运算结构元素的形状在低维度下选择矩形,以保证高的聚类质量;在高维度下选择十字形,以减少计算量.因为矩形的模板或者运算结构中包含网格的数目与维度呈指数增长,而十字形中包含网格的数目与维度呈线性增长,所以十字结构可以降低高维度处理的计算量.
1.5 算法性能分析
为了讨论方便,规定数据集中对象的个数为 N,非空网格的数目为 M,滤波模板中网格的数量为 W,滤波得到的ROI网格的总数目为R,膨胀结构元素中网格的数量为D,FBCLUS算法第1步空间网格化的计算复杂度为 O(N),第 2步空间过滤的计算复杂度为 O(MW),第 3步数学形态学的计算复杂度为O(RD),整体复杂度为 O(N+MW+RD).通常 MW<N,RD<N,整体复杂度近似为 O(N),与数据量呈线性关系.
2 实验测试
2.1 精度测试
测试算法发现任意形状聚类簇的能力和抗噪声性能.测试数据集和聚类结果如图 3所示,其中数据集含有噪声对象.

图3 精度测试的数据集和聚类结果Fig.3 Data set and clustering result of accuracy test
2.2 网格适应性测试
测试算法对网格尺寸的适应性.测试数据集如图4(a)所示,使用两种网格进行聚类.第1种网格是50×50,第 2种网格是 1,000×1,000,网格边长相差20倍.目前提出的网格聚类算法一般只能在50×50的网格中正常工作,例如 CLUGD[8]算法在提取聚类簇时只考虑相邻网格的联通性,当网格划分过于密集时,高密度网格之间被空网格分割开来,其连通性遭到破坏,从而导致算法不能正常工作.而 FBCLUS算法在两种网格下均能得到图4(b)的聚类结果.

图4 网格适应性测试的数据集和聚类结果Fig.4 Data set and clustering result of grid size test
2.3 含障碍物聚类的测试
以含障碍物聚类为例测试算法功能的可扩展性,测试数据集和聚类结果如图5所示,它包含两个障碍物,聚类算法需要区分出被障碍物分割开的聚类簇.本测试将含有障碍物的网格标记为膨胀禁止区,为了防止禁止区的泄漏采用3 3×的十字形膨胀结构元素.聚类结果表明,算法区分出左侧被障碍物完全分割开的聚类簇.

图5 含障碍物的测试数据集和聚类结果Fig.5 Data set and clustering result of obstacle test
2.4 效率测试
测试算法的效率,数据集由随机数产生器生成:每个数据集含有 5个聚类簇和 10%的噪声.测试计算机为神舟承运 M715D,算法 FBCLUS和DBSCAN[13]使用 JAVA 语言编写,处理时间见表1.测试结果表明 FBCLUS的速度明显高于DBSCAN.
3 结 语
笔者设计的基于滤波器的聚类算法 FBCLUS提出以频率滤波器和幅度滤波器来消除噪声并获得感兴趣区域ROI,设计一个新的数学形态学算子从ROI中提取聚类簇.理论分析和测试结果表明,FBCLUS算法能够发现任意形状的聚类;计算复杂度与数据量呈线性关系;能够区分不同密度性质的聚类簇;抗噪声能力强;对网格大小有一定的适应性.
[1] Har-Peled S,Kushal A. Smaller corsets for k-median and k-means clustering[J]. Discrete and Computational Geometry,2007,37(1):3-19.
[2] Rosa La,Nehorai P S,Eswaran A,et al. Detection of uterine MMG contractions using a multiple change point estimator and the k-means cluster algorithm[J]. IEEE Transactions on Biomedical Engineering,2008,55(2):453-467.
[3] Loewenstein Y,Portugaly E,Fromer M,et al. Efficient algorithms for accurate hierarchical clustering of huge datasets:Tackling the entire protein space[J]. Bioinformatics,2008,24(13):i41-i49.
[4] Lee H. E,Park K H,Bien Z Z. Iterative fuzzy clustering algorithm with supervision to construct probabilistic fuzzy rule base from numerical data[J]. IEEE Transactions on Fuzzy Systems,2008,16(1):263-277.
[5] Santos J M,Sa de J M,Alexandre L A,et al. LEGClust:A clustering algorithm based on layered entropic subgraphs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2008,30(1):62-75.
[6] Duan Lian, Xu Lida,Guo Feng,et al. A local-density based spatial clustering algorithm with noise[J]. Information Systems,2007,32:978-986.
[7] Li Jianhua,Behjat L,Kennings A. Net cluster:A netreduction-based clustering preprocessing algorithm for partitioning and placement[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2007,26(4):669-679.
[8] Sun Zhiwei,Zhao Zheng. A fast clustering algorithm based on grid and density[C]//2005 Canadian Conference on Electrical and Computer Engineering. Saskatoon Sask,Canada:IEEE Press,2005:2276-2279.
[9] Rasheed,Tinku Javaid,Usman Meddour,et al. An efficient stable clustering algorithm for scalable mobile multi-hop networks[C]// 4th IEEE Consumer Communications and Networking Conference. Las Vegas,USA,2007:89-94
[10] Han Jiawei,Kamber M. Data Mining Concepts and Techniques[M]. 2nd ed. San Francisco,CA:Morgan Kaufmann Publishers,2006.
[11] 战立强,刘大昕,张健沛. 基于小波滤波的时间序列子序列聚类[J]. 计算机工程与应用,2007,43(10):4-7.Zhan Liqiang,Liu Daxin,Zhang Jianpei. Time series subsequence clustering based on wavelet filters[J]. Computer Engineering and Applications,2007,43(10):4-7(in Chinese).
[12] Gonzalez R C,Woods R E. Digital Image Processing[M]. 3th ed. New Jersey,USA:Pearson Prentice Hall,2008.
[13] Ester M,Kriegel H P,Sander J,et a1. A density-based algorithm for discovering clusters in large spatial databases [C]//Proceedings of 2nd International Conference on Knowledge Discovery and Data Mining. Poland:ACM Press,1996:226-231.
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
股市动态分析(2021年25期)2021-12-30
军事运筹与系统工程(2019年4期)2019-09-11
宇航计测技术(2018年3期)2018-09-08
雷达学报(2018年3期)2018-07-18
中国港湾建设(2017年11期)2017-12-19
北京航空航天大学学报(2017年3期)2017-11-23
制造业自动化(2017年2期)2017-03-20
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年1期)2016-02-06
