
一种语义数据的核分类方法
2010-06-05 07:06李志华任秋英王士同
中文信息学报 2010年6期
李志华,任秋英,顾 言,王士同
(江南大学 信息工程学院,江苏 无锡 214122)
0 引言
分类算法大多依赖于样本间的相似性或相异性度量测度,如欧拉距离、内积等,但其中大部分只能针对连续属性样本,而不能实现语义数据的度量。语义数据的分布是无序的、分布不平衡[1],并且样本集中不同类之间的差异很微弱,甚至互相交错[2,4],要对其相异性进行度量比较困难。目前的主要度量方式有:交迭度量(Overlap Metric)[2]、值相异度量[3](Value Difference Metric,VDM)、自适应的相异性度量[4](Adaptive Dissimilarity Matrix,ADM)、 海明距离度量[5-6],但这些方法或多或少地存在一些不足,如文献[3,5-6]的度量方式都是基于这样的假设:若样本相异,则其相异程度相同,即要么为“0”要么为“1”,没有体现出样本间相异程度的不同;又如文献[4]的度量方式虽然体现了样本间相异的不同程度,但它同样是基于样本的属性是相互独立的假设,这不符合现实。另外,许多核聚类或核分类方法,如支撑向量机通过把输入空间中交错的样本映射到特征空间,从而拉开样本之间的距离,通过极大化分类间隔(margin)来提高分类器的分类能力,在处理小样本时具有很好的泛化能力[7],但同样无法实现语义数据的内积计算。
本文提出一种语义数据相异性度量测度的新定义,给出一种计算语义数据内积的简化方法,通过进一步研究核方法和支撑向量机中的核函数,提出一种语义数据的核分类方法(KNDC),并向语义数据和连续属性的异构数据集进行了拓展,能比较好地实现语义数据和异构数据的分类计算。
1 核方法及支撑向量机中的核函数简介
根据Mercer核理论可知,只要一种运算满足Mercer核条件, 那么这种运算就可以作为内积函数[8], 这一命题可以解决复杂的非线性分类问题, 并且计算复杂度基本不会增加,这是核方法的基本出发点。著名的支撑向量机(Support Vector Machine, SVM)是核方法的一个成功应用,SVM中的核函数主要分为两大类[10]:基于距离的核、基于内积的核。如,基于Euclid距离和基于Euclid内积的核分别具有如式(1)、式(2)的通用形式:
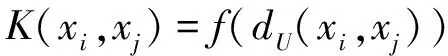
(1)
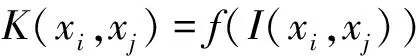
(2)
其中dU(xi,xj)、I(xi,xj)分别为向量xi,xj在输入空间中的Euclid距离和Euclid内积,f(·)是输入空间到特征空间的一个映射函数。
2 语义数据的核分类方法
语义数据中没有任何相似性的概念,甚至没有次序关系[11],如颜色“白”与“黑”,它们之间的区别再明确不过了,但在经典模式识别领域却很难找到一个“距离”去度量它们之间的相似性或相异性,即使语义数据从形式上看是离散的,由于非度量(nonmetric)性的客观存在[11-12],要进行语义数据分类依然是一个难点问题。本文提出一个广义度量距离,并从核的角度研究语义数据的分类问题。
2.1 样本的相异性度量
假设有样本集:xi∈X,xi=(xi1,xi2,…,xid,xi(d+1),…,xi(d+m))T,1≤i≤n,且前d维为语义属性,后m维为连续属性,即X为异构数据集。本文定义语义数据间的相异性度量测度dsymbolic如式(4)所示。
定义 语义数据的相异性度量测度:
(3)
(i≠j,1≤i≤n,1≤j≤n,1≤p≤l)
dsymbolic(xi,xj)=[dims-s(xi,xj)]/dims
(4)
其中dims是语义数据的维数。式(4)同文献[2-4]中的度量方法相比较,有以下明显好处:把语义数据的相异性度量成区间[0,1]之上的一个不确定性,克服了文献[2]中度量成非“0”即“1”的那种绝对情况,显然式(4)的度量更加客观实际;式(4)的值域为[0,1],起到归一化的作用,有利于同其他度量方法结合使用。
若连续属性的样本间的相异性直接采用欧氏距离的度量方式,则异构样本之间的距离用式(5)计算:
(i≠j,1≤i≤n,1≤j≤n,1≤h≤m)

(5)
不难证明公式(5)总能满足距离的:①非负性,即d(xi,xj)≥0;②对称性,即d(xi,xj)=d(xj,xi);③规范性,d(xi,xj)=0当且仅当xi与xj完全相同,但不能总是满足三角不等式的距离测度原则,所以公式(5)是一个半度量的(Semi-metric)距离测度,也称为广义(Generalized) 距离测度。式(5)具有“距离”定义的通用形式,综合考虑了不同属性之间的相异性。
2.2 异构属性样本的核分类方法
假设有一个二分类问题的训练样本如下:
(x1,y1),(x2,y2),…,(xi,yi),…,(xm,ym)
其中,xi∈X,xi是异构样本,类标记yi∈{-1,1}。
核方法的本质就是把一个输入空间变换到一个内积空间的过程,从而实现各种算法,而语义数据集、异构数据集上通常无法定义内积,本文的解决办法是选用高斯核函数作为核方法中的核投影函数,用相异性度量测度代替投影中的范数,通过此方法来完成输入空间到特征空间的映射,其好处是:既完成了核方法中的核变换,又简化了语义数据和异构数据的内积运算。最终的核函数定义为:
(6)
其中,式(6)中的d即式(5)。根据核矩阵在核方法中的作用可知,通过式(6)的核变换以后,支撑向量的求解过程实质上同样是一个二次规划问题,上述过程描述成如下算法。
语义数据的核分类(Kernel-based Nominal Data Classification,KNDC)方法:
步骤 1 根据式(5)计算样本集X的d;
步骤 2 用式(6)计算样本X的内积,并求解二次规划问题:
得到最优解:
α*={α1,α2,…,αl}
步骤3 用α*构造超平面:
其决策函数为:
F(x)=sign(f(x)+b) 其中b为决策阈值;
步骤4 计算F(x)的值,对样本进行分类:

由于语义数据和异构数据中很难界定噪声数据, 所以上述算法中那些被拒识的样本很可能会增加误识所造成的损失。
KNDC方法同SVM算法相比能一次性构造任意给定的语义数据样本集或异构数据样本集的核函数,克服了SVM算法中有关核矩阵计算量过大的不足,显著地提高了算法的收敛速度,并有效地扩展了SVM的应用范围。
3 标准样本集的仿真实验及分析
(1) 分类器的衡量指标
本节用错分率来衡量分类器对不同样本的分类精度,错分率是指被错分的样本数量占样本总数的比值。如式(7)所示,分类正确率如式(8)所示:
(7)

(8)
numberi为正类和负类中被错误分类的样本个数,n为样本的总数。γerror值越小,就说明分类准确度高,分类效果好, 越大,则刚好相反。
(2) 样本的组成及初始化方法
为了评价核分类器的分类能力,仿真实验使用了三个纯语义数据样本集[2,4]和一个异构属性数据样本集[1],样本集的组成如表1所示[16],并把方法在网络异常检测中进行了应用研究,除monks-1、 monks-3两个样本集有固定的训练样本集和测试样本集外,其余样本的训练样本均是简断无回放地从样本集中抽取。实验中对样本集中的连续属性用极差标准化方法进行预处理,见式(9):
(9)
处理后的变化区间在[0,1]之间,以方便算法的处理。
第1、2个样本集是Monks难题,它一共有3组样本集,每一组样本集都有自己的专门的训练样本和测试样本,是国际上第一次用来比较学习算法的标准样本,本文采用了其中的两个样本集monks-1、monks-3,每个样本集均分为两类,其中monks-3训练样本集中有5%的离群数据;第3个样本集是tic-tac-toe游戏样本集,数据集中的样本是对tic-tac-toe游戏最后结束时所有可能造型结果的编码。第4个澳大利亚信用凭证样本集(Australian Credit Approval),描写的是信用卡的应用记录,样本属性的真实值全部被符号化,分为两大类:正类307个样本、负类383个样本。

表1 实验样本集的组成
(3) 分类器中的参数选择
KNDC方法同样面临惩罚因子C和核参数δ的优化选取问题,由于这两个参数与样本本身的分布密切相关,所以具有一般指导意义的共性选择方法不是很多见[12-13],本文采用试探法选择核分类器的参数。通过对表1中各训练样本选用不同的惩罚因子和核参数的组合反复实验。实验中对惩罚因子的选择,并不要求支撑向量的个数为零或者不再变化,而是只要求分类器满足稳定性条件,并且惩罚因子的改变对支撑向量、边界支撑向量数目影响不大即可。因为过多考虑惩罚因子对分类器的影响,其一意味着使用了可分模型;其二增加了参数选择的难度。这是不可取的。实验结果如图1、图2所示。
图1、图2分别说明了分类准确率与分类器中的两个重要参数的关系。图1说明:当惩罚因子C一定时,分类准确率随sigma的变化情况。sigma在[0.1,1.0]区间变化时,若分类准确率缺省,则表示当前的分类算法无法实现样本集的分类,并且,从图1不难发现,所有四个样本集的曲线都向上凸,说明在当前的条件,其分类准确率存在最优。当从图1中得到分类准确率最好的参数sigma的值后,反过来求在sigma一定时,分类准确率随惩罚因子C的变化情况,如图2所示,特别值得注意的是,当惩罚因子超过一定的值后,分类准确率不再受其影响,即分类算法很稳定,这一现象说明:虽然分类算法中参数初始值的选择具有一定的偶然性,但取值是合理的。综合考虑图1、图2,可以比较方便地确定算法中的两个重要参数,惩罚因子C=5时,样本monks1、monks3、tic-tac-toe、credit的参数sigma分别取:0.7、0.4、0.7、0.9。
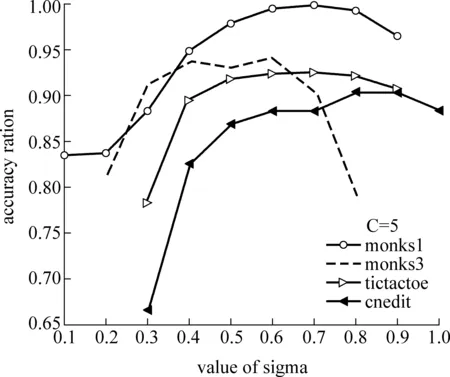
图1 分类准确率与sigma的关系
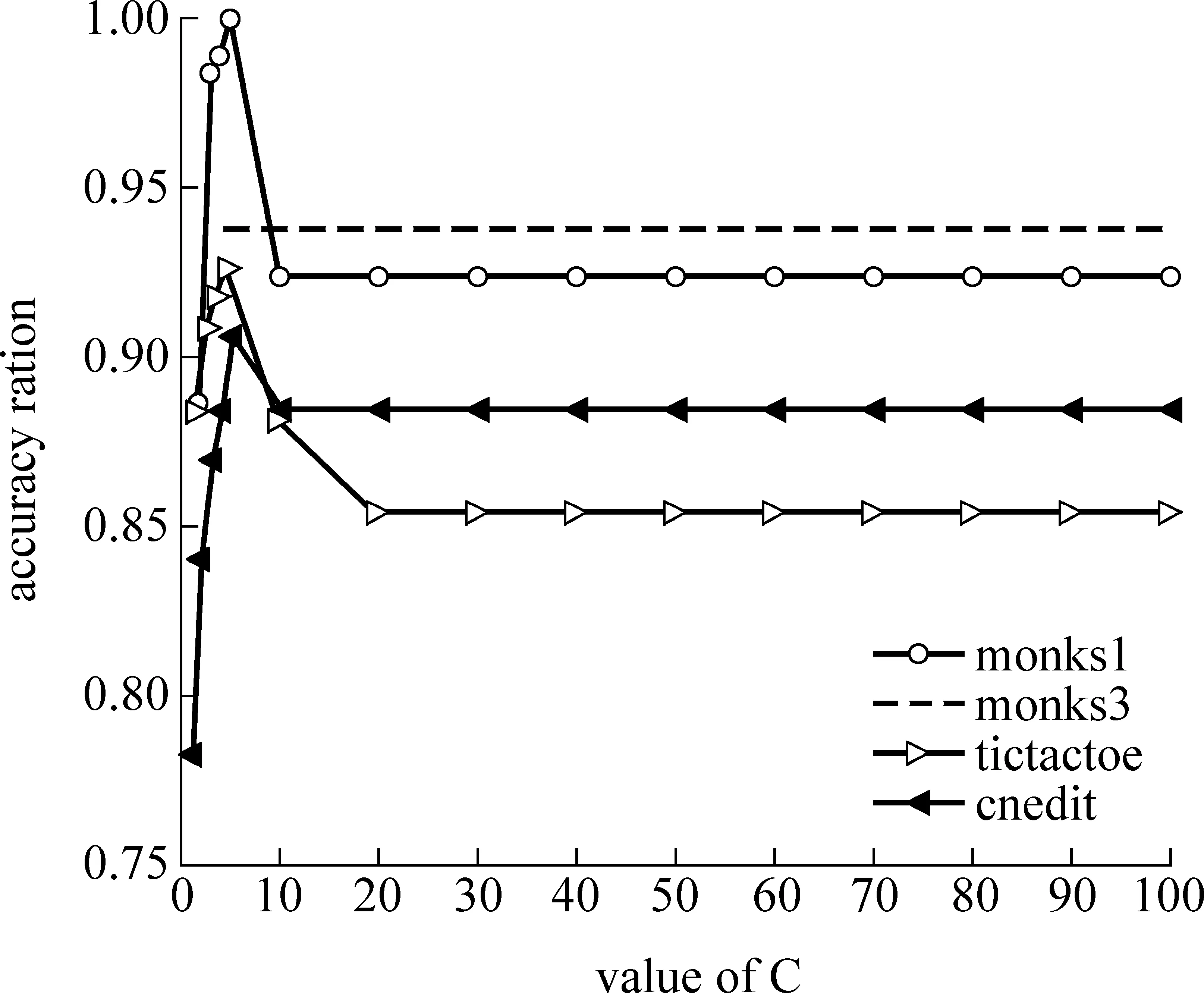
图2 分类准确率与惩罚因子的关系
(4) 实验结果及分析
表2给出了KNDC算法、C4.5算法、文献[2-4]算法的错分率比较结果。由于C4.5是一种决策分类算法,没有用到“度量”的概念,并且该算法根据信息增益来约简和选择分类属性,不一定能保持最优,所以对其中3个样本集的错分率最高,对于样本集monks-3的错分率稍低于文献[2];文献[2]首先把待比较的属性转换成“串”,最后采用类似海明距离进行度量,文献[3]是用待比较的两个属性相对同一个类属性的条件概率之差的平方加权的方式进行度量,文献[2-3]都是基于样本属性是相互独立的假设,复略了属性之间的关联性,均采用RBF分类器。文献[4]是把待比较的两个向量的各维属性间的“距离”构成一个相异性矩阵,并用Hadamard内积近似计算矩阵[4],最后通过对结果优化寻找类别判定的估计函数,文献[4]虽然考虑了属性间的关联性,但算法的计算复杂。文献[4]及本文算法KNDC均采用SVM分类器。对于credit、tic-tac-toe、monks-1这些属性间的关联性比较强的样本,KNDC和文献[4]的算法错分率远低于其他三个算法,并且对于前两个样本集KNDC算法的错分率低于文献[4]的算法,事实上对于monks-1样本, KNDC算法仅有一个样本被错分,而对于异构样本集credit,KNDC算法的错分率在所有参与比较的算法中最低,这充分说明考虑样本属性间关联性的重要性;样本集monks-3比较特殊,有5%的离群数据[2,4],KNDC方法的错分率高于文献[3-4],而低于文献[2]和著名的C4.5算法,可见KNDC算法具有一定的抗离群数据干扰能力。
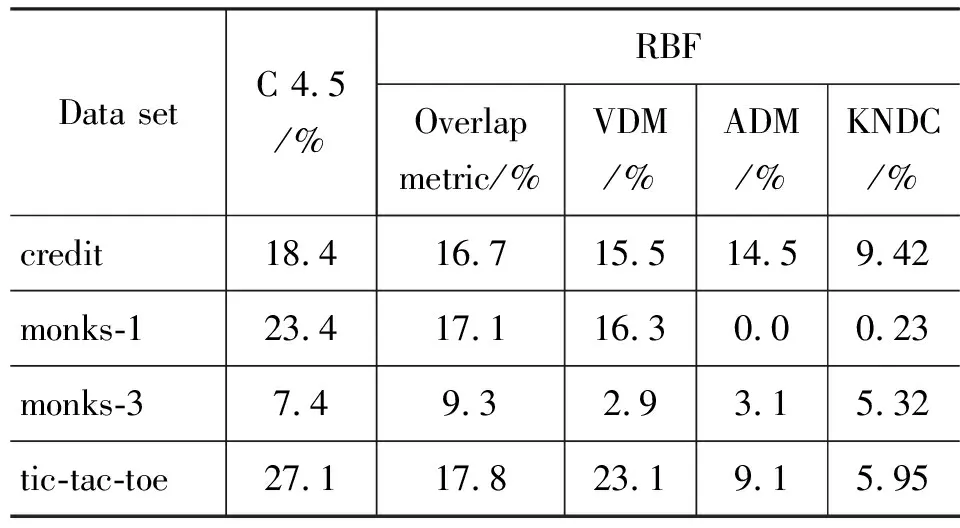
表2 不同方法的错分率比较
4 分类方法的应用示例
网络实际环境中正常连接记录往往要比异常攻击记录多得多,即异常连接记录占整个网络连接记录的比例极小。基于这样的认识,完全可以认为网络异常检测就是一个发现离群数据的过程。著名的KDD CUP 1999样本集,通常使用它的10%的子集来测试方法的性能,子集中有23种攻击方式,归成四大类入侵DOS、Probe、R2L和U2R,已有文献研究表明[14],该样本集是一个分布极度不平衡的样本,并且样本集属性组成比较复杂,含有大量的语义数据,如TCP、ICMP、SF等,又包含有大量的连续属性。实验中分别按1%、2%、3%、4%、5%、10%的比例来选取不同类别的攻击样本,选取样本总数分别为1 000、2 000、3 000、4 000和5 000的5个独立的样本子集,实验中每间隔10条抽取一条作为训练样本,剩余的作为测试样本,实验中用文献[13]的两个指标检测正确率和错分率来衡量方法的实用价值。检测正确率和错分率随异常样本所占比例的变化如图3、图4所示,图中的检测正确率和错分率是在5个样本子集上进行10次实验的统计平均。

图3 检测率随异常比例的变化图
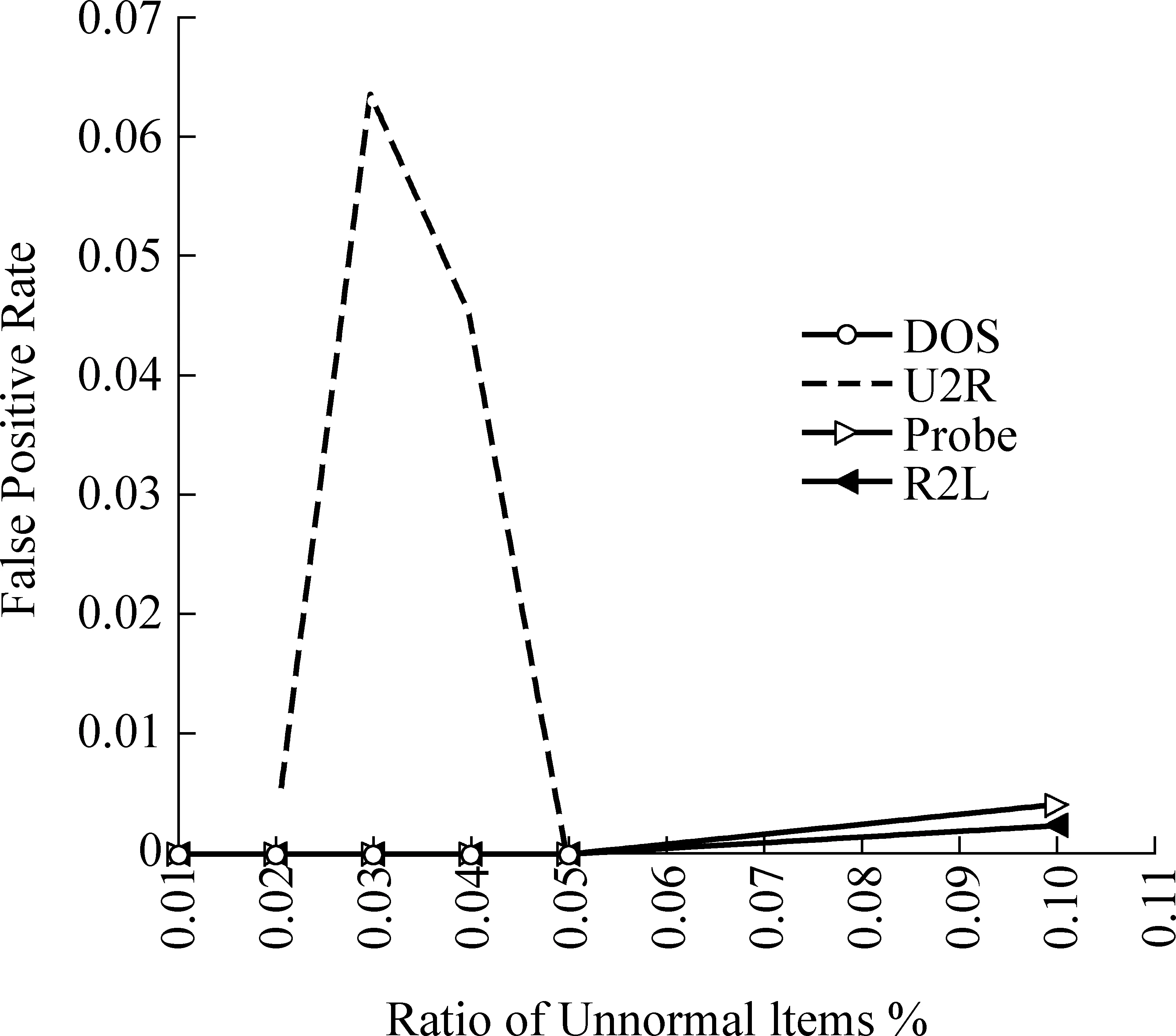
图4 错报率随异常比例的变化图
由于U2R类攻击的样本总数为48条,所以U2R所占比例最多只能达到5%,即为不平衡数据。从图3、图4可以看出,本文的分类方法对于U2R、Probe和R2L三类攻击的检测结果趋势明显,检测率随着异常样本所占比例的升高呈下降趋势,错报率随着比例的升高有微弱的上升趋势,指标总体上比较理想,说明算法针对异构属性数据集分类问题的优越性、具有一定的应用价值。对于比例为3%、4%的DOS类攻击的检测正确率和错报率都有一个明显的突变,通过深入研究样本数据的组成发现,主要是因为在所有5个样本子集中,随机抽取的这两个比例值的DOS类攻击样本大多只有neptune和smurf两类,这两类样本,特别是neptune同正常网络连接记录normal重复率极高[14-15],造成正常和异常间的分类边界不清晰,样本的拒识率增加,最终造成检测准确率急激下降、错报率急激上升。
5 结束语
本文研究了语义数据的分类问题,提出了一种语义数据的核分类方法,并向语义数据和连续属性的异构属性数据集进行了拓展,有意义地拓展了非线性支撑向量机的适用范围。从实验中发现算法的总体性能优于著名的C4.5算法,对大多数标准样本集的分类指标优于文献[2-4],特别是对于异构属性数据集的分类,在参预比较的各种分类方法中,KNDC方法的指标最佳、性能最优。并通过在异常检测领域的应用研究发现,KNDC方法具有一定的抗离群数据干扰能力和处理不平衡数据的能力,但对标准样本集的仿真实验说明,KNDC方法的抗离群数据干扰能力不及文献[3-4],如何进一步提高KNDC方法的抗离群数据干扰能力是下一步的研究重点。
[1] Minho Kim,R.S.Ramakrishna,Projected Clustering for Categorical Datasets[J].Pattern Recognition Letters,2006,27:1405-1417.
[2] F.Esposito,D.Malerba,V.Tamma,H.H.Bock,Classical resemblance measure,in:H.-H.Bock,E.Diday(Eds.),Analysis of Symbolic Data,Springer[C]//Berlin,2000,139-152.
[3] C.Stanfill,D.Waltz,Towards memory-based reasoning[J].Commun,ACM,1986, 29(12):1213-1228.
[4] Victor Cheng,Chun-Hung Li,James T.Kwokb,Chi-Kwong Lic,Dissimilarity learning for nominal data[J].Pattern Recognition, 2004,37:1471-1477.
[5] J.C.Gower,P.Legendre,Metric and Euclidean properties of dissimilarity coefficients[J].J.Classif.1986,3:5-48.
[6] H.Spath,Cluster Analysis Algorithm for Data Reduction and Classification[J].Ellis Horwood,Chichester,1980.
[7] Burges J.C.,A tutorial on support vector machine for pattern recognition[J].Data Mining and Knowledge Discoverty,1998,2(2):121-167.
[8] V apnik V N. Statistical learning theo ry [M]. New York:John W iley & Sons, INC, 1998.
[9] Scholkopf B, MIka S, Burges C, et al. Input Space Versus Feature Space in Kernel-based Methods [J]. IEEE Trans on Neural Networks, 1999,10(5):1000-1017.
[10] Defeng Wang,Daniel S.Yeung,Eric C.C.Tsang,Weighted Mahalanobis Distance Kernels for Support Vector Machines[J]. IEEE Transaction on Neural networks,2007,18:1453-1462.
[11] Richard O.Duda,Peter E.Hart,David G.Stork,Pattern Classification,John Wiley,2001:318-347.
[12] 韩先培,赵军. 基于Wikipedia 的语义元数据生成[J].中文信息学报,2009,23(2):108-114.
[13] 李文法,段毅,刘 悦,孙春来. 一种面向流分类的特征选择算法[J].中文信息学报,2009,23(3):51-57.
[14] 孙济洲.网络入侵检测技术的研究[D].博士学位论文,天津大学,2003.
[15] 李志华,王士同,等.基于离群聚类的异常检测研究[J].系统工程与电子技术,2009,31(5):1227-1230.(LI Zhi-hua,WANG Shi-tong,Clustering with outliers-based anomalous intrusion detection[J].Systems Engineering and Electronics,2009,31(5):1227-1230.
[16] UCI repository of machine learning database[EB/OL]. http://www.ics.UCI.edu/~mlearn/MLRepository.html,1998.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
河南化工(2021年3期)2021-04-16
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
湖南教育·C版(2017年12期)2018-01-03
电子技术与软件工程(2017年14期)2017-09-08
读写算·高年级(2017年6期)2017-06-27
计算机应用(2017年4期)2017-06-27
中国学术期刊文摘(2016年1期)2016-02-13
读写算·高年级(2015年7期)2015-07-12
