
基于《知网》的词语相似度算法研究
2010-06-05 06:31刘青磊顾小丰
中文信息学报 2010年6期
刘青磊,顾小丰
(电子科技大学 计算机科学与工程学院,四川 成都 611731)
1 引言
在信息检索、文本分类、信息抽取、基于实例的机器翻译等各领域中,词语相似度都有着广泛的应用。刘群[1]把词语的相似度计算方法分为两类:一类是通过统计语料上下文中词语之间的相关性来得到其相似性,另一类是基于某种世界知识或者分类体系的方法,如Agirre[2]利用WordNet来计算英语词语的语义相似度,李峰[3]用《知网》[4]来进行汉语词汇语义相似度方面的研究。
基于《知网》的相似度计算方法通常是根据整体相似度可由部分相似度合成而来的思想,通过寻找两个词语义原集合间的最相似元素来进行一一匹配,词语的相似度就等于各匹配对的加权均值。由于其计算的基本单位是一对一的义原匹配对,因此也就割裂了构成词语的各个义原间的内在联系,不能从整体的角度给出客观的义原匹配选择,并且由于较多的加权值和参数,使得最终的结果或多或少地会带有一些主观因素。
本文从信息论的角度出发,分别对两个义原集合间的共有信息和差异信息进行统计,并据此得出两个义原集合的相似度,最终的词语相似度计算是以集合为基本单位的。
2 《知网》中义原的相似度
在《知网》中,是用“概念”来对汉语中的每一个词语进行描述和定义的,而构成这种概念描述语言的核心词汇就是“义原”,这里试以“打”的其中一个义项“weave|辫编”为例,其在《知网》中记录为:
NO.=015492 W_C=打 G_C=V E_C=~毛衣,~毛裤,~双毛袜子,~草鞋,
~一条围巾,~麻绳,~条辫子 W_E=knit G_E=V E_E= DEF=weave|辫编
其中“weave|辫编”就是“义原”,“E_C”的用途在于为消除歧义提供可靠的帮助。根据义原的上下位关系和分类特点,所有的义原构成了层次鲜明的义原森林,这个义原森林所要表达的层次分类体系正是接下来我们计算词语(句子)相似度的基础。
我们截取了以“entity|实体”为根节点的树中的一个分支,并据此来讨论目前几种主要的义原相似度比对算法的特点(简便起见,下文中都省去了义原中的英语):
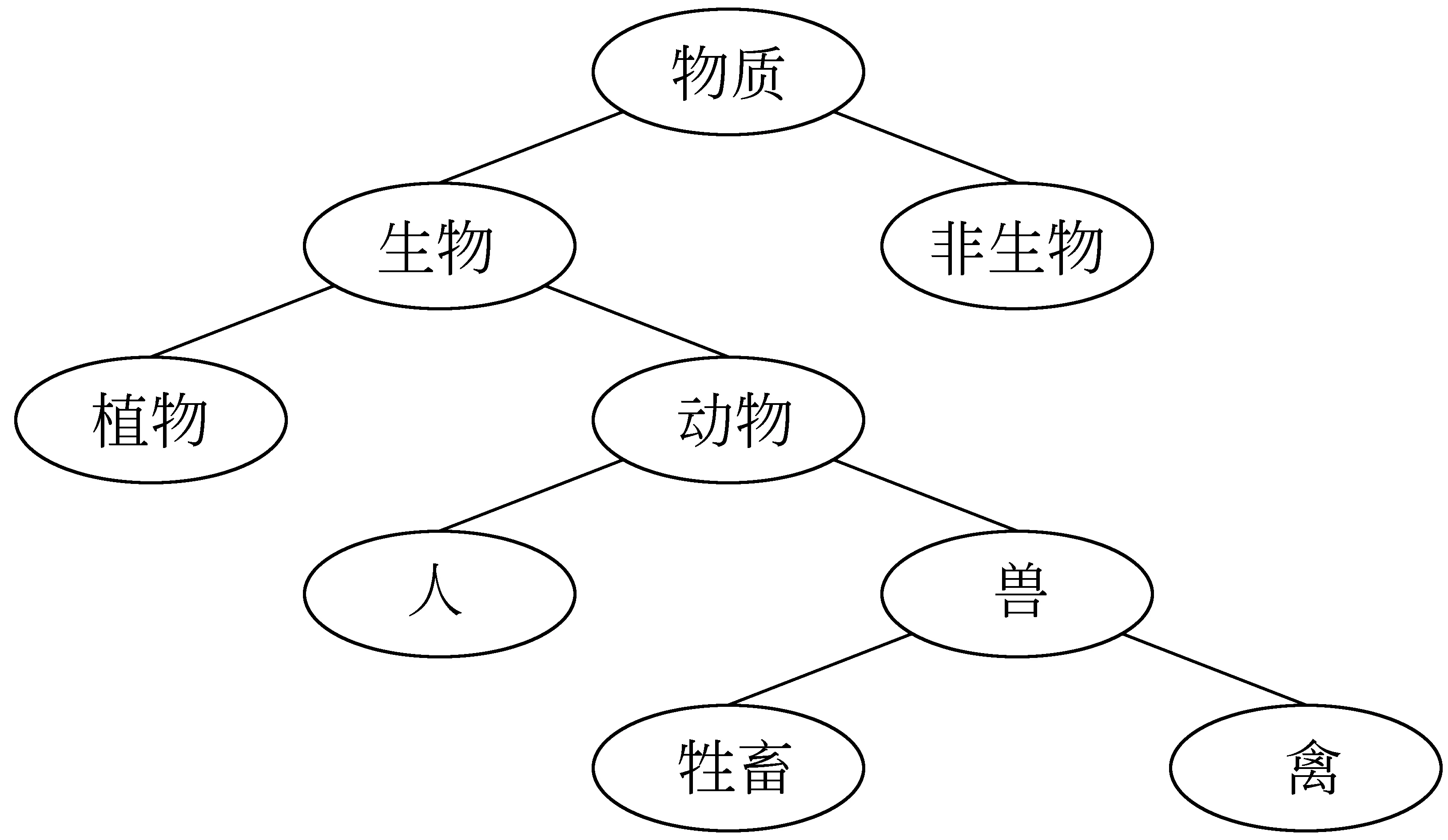
图1 根节点为“entity|实体”的树中的一个分支
a. 刘群通过计算两个义原(Primitive)节点之间的路径长度来得出两个义原的相似度,公式为:
(1)
其中p1和p2表示两个义原,Dis(p1,p2)为它们在义原层次体系中的路径长度,α(1.6)为可调节参数。
b. 李峰在刘群公式的基础上考虑了义原的层次深度:
Sim(p1,p2)
(2)
其中min(depth(p1),depth(p2))表示p1和p2两者在义原树中深度的最小值。
c. Dekang Lin[5]认为任何两个事物的相似度取决于他们的共性和个性:
其中,common(E1,E2)表示E1和E2共同拥有的信息量大小,description(E1,E2)表示完整描述出E1和E2所需的全部信息量大小。
在层次体系中层次越深的节点包含的信息量就越大,那么如何具体的去衡量一个节点所包含的信息量有多少呢?由于义原体系是一个分类体系,子节点总是父节点的分类,当我们把节点本身看成是其父节点不具有的特征集合时,就容易推断出:子节点总是拥有其自身和父节点。以图1中的节点“人”为例,它所拥有的信息节点集合就为:{物质,生物,动物,人},假设集合里面每个元素的地位都相同,这里可以简单认为义原“人”所拥有的信息量为4,此时引入Dekang Lin公式的内涵:

(3)
这里挑选了图1中的几组义原来实验讨论公式(1)、(2)、(3)各自的特点。
首先对比下表1中的前两行:A中义原深度都为1,B中都为4,从直观感觉来讲,B的相似度显然要大于A。(1)的结果对A和B并没有区分度,(2)和(3)表现较好。其原因是在式(1)中只要义原距离即Dis(p1,p2)相等,那么最终结果就会相同;而(2)和(3)都考虑了深度。

表1 距离相等时义原对的相似度
再来观察后两行:C中义原深度都为2,D中 “动物”深度为2,“牲畜”为4,从直观角度来看,D的相似度应该要大于C。此时(2)的结果都为0.62,已经没有了区分度,(3)表现依然较好。究其原因,式(2)中的min(depth(p1),depth(p2))只考虑了义原深度中的较小值,而式(3)在进行信息节点统计的同时把两个义原的深度都考虑了进去。同时,细心的读者会发现,式(2)的计算结果在数值上都显得过于偏大。从整体上讲,式(3)的结果更加合理。
3 词语之间的相似度
词语相似度(孤立词语之间的相似度)在《知网》中体现为描述词语的概念之间的相似度,用公式表示为:
Sim(W1,W2)=maxSim(S1i,S2j)
(i=1…n,j=1…m)
(4)
其中,词W1、W2分别有n和m个义项(概念),S1i为W1的第i个义项,S2j为W2的第j个义项,最终的词语相似度结果取W1和W2的各个义项相似度的最大者。
刘群认为描述词语概念的义原可以分为第一基本义原、其他基本义原、关系义原和关系符号描述义原。李峰把其中的第一基本义原和其他基本义原合成为“直接义原”,关系义原和关系符号义原合成为“间接义原”,通过分别计算这两组集合的相似度再经过加权平均来得到整体相似度。
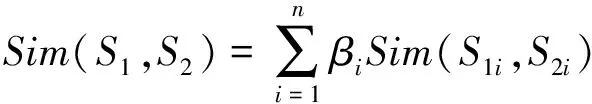
(5)
其中,S1、S2表示两条概念,n取4(刘群)或2(李峰),βi为权值调节参数,满足β1,β2…βn之和为1,S1i、S2i分别对应S1和S2的第i个义原集合。
本文中我们参考李峰的思路,仍然是把义原分割为直接义原和间接义原两个集合。
3.1 直接义原集合的相似度计算
常用的义原集合相似度计算方法可以分为两个步骤:①通过计算两个集合中各个义原之间的相似度来寻找最优匹配(即相似度最大的义原对);②对各个义原对加权求平均值或是根据某种条件对各部分赋权值后再求和。
这里试以词“颜色”和“蓝色”为例来说明上述方法:
颜色 { 属性,颜色 }
蓝色 { 属性值,颜色,蓝 }
A: < 属性,属性值 > 0或δ
B: < 颜色,颜色 > 1
C: < 蓝,φ> (φ表空值) 0或δ
其中“属性”、“属性值”、“蓝”三个义原分别位于不同的义原树中,故三者可随意配对并且任意两者之间要么不存在相似度,要么可由数据平滑技术给定为一较小值δ。察看表中三个配对,A和C都不存在相似度,那么就只有B才对最终的计算具有意义。实际上在义原分类体系中,B中的“颜色”是C中“蓝”的父节点,也就是说B和C拥有的信息量几乎是相同的,但在合成时,前者起到了决定作用,而后者却几乎没有作用,这显然是不合理的。
我们认为应该这样配对:A <属性,属性值>、B <{颜色},{颜色,蓝}>。此时由分组B可知关键点就在于如何计算两个集合的相似度。我们从整个集合所包含的信息量出发,把集合包含的所有信息量做为一个不可分割的整体,在比较两个集合的相似度时,不再进行元素最优匹配,而是把元素所组成的集合视为元素所包含的信息量的集合。根据上文中我们对义原信息量的分析可以描述为:
{ 义原1,义原2,…,义原n}={ 义原1信息节点∪义原2信息节点∪…∪义原n信息节点 }
这时计算两个义原集合的相似度就归结为计算两个信息量集合的相似度,可以引入和扩展公式(3):
Sim(D1,D2)

(6)
其中,D1和D2代表两个直接义原集合,其元素个数分别为m和n,information(p)表示p在义原分类体系中其自身以及父节点所包含的信息节点集合。实际上,在m=1且n=1时公式(6)就表现为公式(3)。
3.2 间接义原集合的相似度计算
间接义原即带符号的义原。对其进行的计算较为简单,首先根据它们所带的符号是否相同来进行分组(如果没有与其对应的符号,就与空值对应),再对各分组分别进行义原相似度计算,整体的相似度计算结果就等于各部分的加权之和。例如:
球迷 {*喜欢,#看,#体育}
歌迷 {*喜欢,#音乐}
A: <喜欢,喜欢>
B: <{看,体育},{音乐}>
其中的分组A可按式(3)计算、分组B可按式(6)计算,间接义原与空值的相似度设为一个较小值 (本文中取值为0.2)。我们认为表中的分组A和B在集合的相似度计算中所占的地位并不相同,这可以简单的取决于分组内部的义原数量。
间接义原集合的相似度计算公式为:

(7)
公式中I1和I2分别表示两个间接义原集合,m为分组个数,n为两个集合中的义原个数之和,ni为第i个分组中的义原个数,Sim(Ai)表示第i个分组的相似度。
3.3 概念相似度的计算
由于直接义原和间接义原在描述词语的概念中所起作用和所占地位都不能一概而论,所以概念相似度最终应由两部分加权计算后合成而来。根据式(5)有:
(8)
其中,Sim(D1,D2)表示直接义原集合的相似度,计算方法由式(6)给出,Sim(I1,I2)表示间接义原集合的相似度,计算方法由式(7)给出。由于在对词语的描述中,不同词语的间接义原差异会比较大,经过相关实验后,权重调节参数β设置如上。
4 词语相似度算法的扩展应用
常用的句子相似度比对算法可以分为三类:一类是基于句子的结构和语法特征,如穗志方[6]提出的基于骨架依存结构的句子相似度计算模型;另一类是根据句子中的词类串来进行计算,如王荣波[7]等提出的句子结构相似度计算方法;最后一类是基于句子语义信息的方法,如张奇[8]等利用《知网》进行的比对算法。
实际上,上文中对词语相似度的计算方法也极易扩展到句子的相似度比对中去,接下来对此做一些简要介绍。
4.1 句子的相似度计算
在进行句子相似度比对时,一些常用的虚词、介词等比较的意义并不大,因此这里只考虑名词、动词、形容词等实词。另外,在计算前还要对句子中的多义词进行词义消歧,使其得到一个唯一的义项。这里我们先假定已经进行了词义消歧(4.2节介绍)。有两个句子:
Sentence1={W1,W2,…Wm}
Sentence2={W1,W2,…Wn}
其中,Sentence1和Sentence2代表句子1和句子2,它们的实词个数分别为m和n。
在不考虑句子语法特征的情况下,可以把句子看成是词的集合(Bag of Words),根据上文中词语相似度计算的思想,可以把词语看成义原的集合,籍此我们也就可以把句子看成是义原的集合;义原又分为直接义原和间接义原,那么一个句子就分为直接义原集合和间接义原集合两个部分;再由公式(3),义原所含的信息量是其包含的信息节点的集合,最后根据式(8)有:
Sim(S1,S2)=(1-γ)Sim(D1,D2)+γSim(I1,I2)
(9)
上式中,S1和S2表示两个句子,D1、D2分别表示两个句子的直接义原集合,I1和I2代表间接义原集合,γ为一可调节参数,经相关实验后调整为0.2。
实际上,式(8)是式(9)中两个句子词语个数都为1时的特例,故在本文中我们认为句子相似度是词语相似度的扩展,词语相似度是义原相似度的扩展。
4.2 词义消歧
词义消歧有时也称为词义标注,其任务就是确定一个多义词在给定的上下文语境中的具体含义[9]。基于《知网》的词义排歧可以归类为基于义类词典的消歧方法,这类方法的基本思想是:多义词的不同义项在使用时往往具有不同的上下文语义类。因此,利用《知网》提供的短语搭配“E_C”(第二部分可见)进行排歧的基本思路就是:比较该词所在的上下文环境和每一个实例提供的环境之间的相似性,可以认为语境最相似的实例所代表的词语义项就为该词在给定上下文中的含义。
以“打”为例,打在《知网》中共有28个义项。对于歧义句:妈妈给我打了一件毛衣,首先提取出歧义词的上下文环境A为:{妈妈,毛衣},再提取出《知网》中各个搭配实例的环境B1,B2,…Bn等,利用上文中的式(9)进行A和B的相似度计算,结果最大的实例所在的义项就为该词的义项。用公式表示为:
S=S(maxSim(A,Bi))i=1,2,…,n
(10)
这里假设歧义词在《知网》中有n个搭配实例,S代表该词的义项,Bi表示提取出的第i个实例环境,S(maxSim(A,Bi))表示Bi所在的义项。
公式(9)中已经假设每一个词都给出了明确的含义,因此,在环境A和B的提取中,要尽量只提取没有歧义的词语,如果必须具有歧义词,就需要把歧义词的义项一一代入取其最大值。
5 实验及结果分析
5.1 实验一(词语相似度)
这里我们选取出刘群、李素建以及李峰论文中共有的一些词语,通过对这些词语的实验结果进行比对分析来讨论几种算法的特点。
表2中第3列为李峰给出的结果,其文中给出的直接义原计算公式为:
其中
(11)
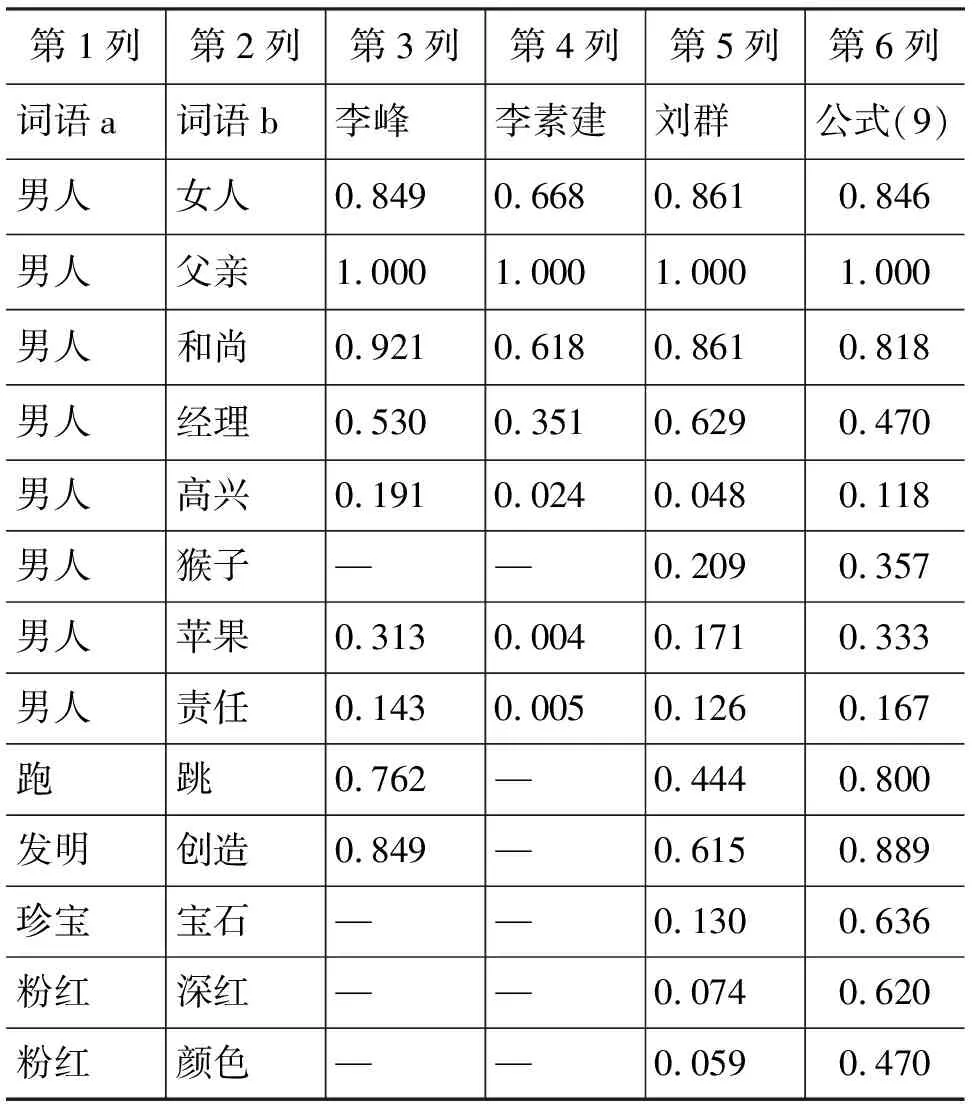
表2 词语相似度实验数据
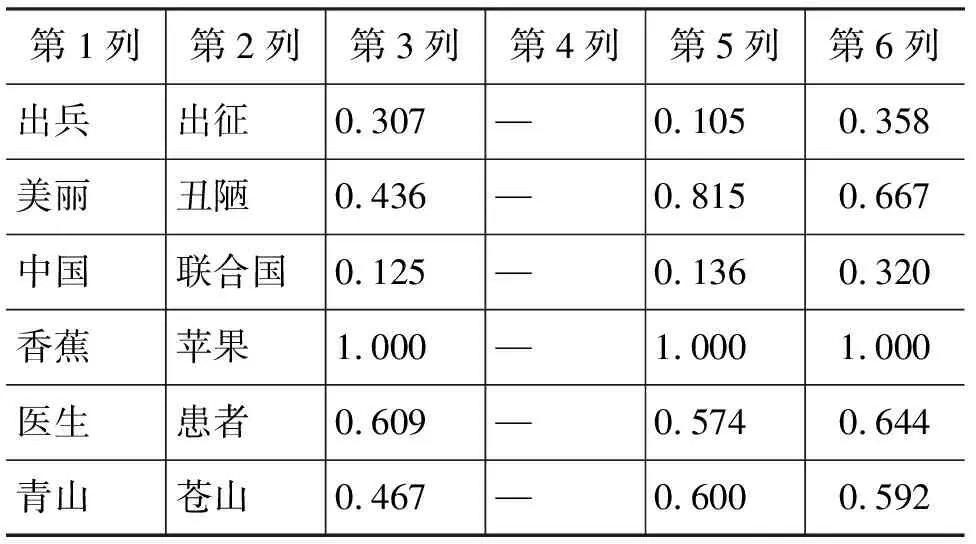
续表
在计算时我们发现,文中对<φ,A2i>的深度并未给出明确的说明,例如,在计算上表中“男人”和“猴子”的相似度时,前者概念为“人,家,男”(多个义原),后者为“走兽”(仅有一个义原),最优匹配显然为:<人, beast|走兽>、<φ,家>和<φ,男>。那么<φ,家>和<φ,男>的最小深度和权重该怎样计算,文中并没有给出相关说明。籍此原因,在接下来的数据分析中,我们把重点放在第4、5、6列。
① “男人”与“女人”,“男人”与“和尚”,“男人”与“经理”。在这三对词的比较中,第6列可以说是对第4、5列一个很好的折衷。
② “跑”与“跳”,“发明”与“创造”。第5列给出的结果要低于它们实际的相似度,原因是并没有考虑义原的深度。第6列给出的值要高于第3、5列,结果上较为合理。
③ “珍宝”和“宝石”,“粉红”和“深红”,“粉红”和“颜色”。第5列给出的相似度分别为0.130、0.074 和0.059,显然低于人们实际经验中的相似度,原因是第5列在计算时过于倚重第一个义原。
④ “医生”与“患者”。从意义上讲,对这两个词的相似度衡量实际上已经转移到了对其相关性的衡量上。第3、5、6列给出的结果都较为合理。
从总体上来看,第6列中我们给出的数据更为合理,整体上的表现也更加稳定。
5.2 实验二(句子相似度)
为了便于手工识别,我们在新浪网主页上的标签“财经、体育、军事、教育、房产、天气、健康、旅游”8个分类网站中各抽取出20个句子总共160句(大部分都为各类文章的题目),其中的每一句要么不存在未登录词,要么已经用《知网》中存在的同义词来代替未登录词;然后我们用手工识别的方法对每一类中的20个句子根据其相似度分为4类(每一类中有5个句子);接下来把每一句作为待比对句,和剩余的所有句子一一比对,分别取比对后相似度值排序最前的5个、8个和10个句子做为输出并计算出结果中和手工分类中相同的句子数目correct,那么召回率recall=correct/5。下面表3为几种方法的实验结果。

表3 句子相似度实验数据表
从表3中可见,基于词形词序的方法在三种输出下的提高并不大,其原因是只考虑了句子中相同的词汇而没有兼顾语义。第三行中词义消歧后再进行相似度计算的方法可以说是集成了本文中提出的几个主要观点,其结果明显优于第一、第二种方法,召回率较为令人满意,这也进一步证明了本文中各个办法的有效性。
6 结论
本文提出的词语(句子)相似度计算方法是从信息论的角度出发,利用《知网》中提供的义原上下位关系把义原做为信息节点的集合,并据此提出了自已的计算义原相似度的公式;把构成词语(句子)的所有直接义原看成是一个大的信息融合了的集合,根据其共性和个性来计算出两个集合的相似度,进而得到词语(句子)的相似度;文中还利用新的句子相似度计算方法提出了一种简单直观的词义消歧办法。最后通过实验和数据分析验证了新方法的正确性和实用性。
[1] 刘群,李素建. 基于《知网》的词汇语义相似度的计算[C]//第三届汉语词汇语义学研讨会,中国台北,2002.
[2] Agirre E, Rigau G. A Proposal for Word Sense Disambiguation using Conceptual Distance[C]//Proceedings of the First International Conference on Recent Advanced in NLP. 1995.
[3] 李峰,李芳. 中文词语语义相似度计算——基于《知网》2000 [J]. 中文信息学报, 2007, 21(3):99-105
[4] 董振东,董强. 《知网》[P]. http://www.keenage.com.
[5] Dekang Lin. An Information-Theoretic Definition of Similarity Semantic distance in WordNet [C]//Proceedings of the Fifteenth International Conference on Machine Learning. 1998.
[6] 穗志方. 基于骨架依存树的语句相似度计算模型[C]//计算语言学文集, 1998, (3):176-184.
[7] 王荣波,池哲儒. 基于词类串的汉语句子结构相似度计算方法[J]. 中文信息学报, 2005, 19(1):21-29.
[8] 张奇,黄萱菁,吴立德. 一种新的句子相似度度量及其在文本自动摘要中的应用[J]. 中文信息学报, 2005,19(2):93-99.
[9] 宗成庆. 统计自然语言处理[M]. 清华大学出版社, 2008.
猜你喜欢
房地产导刊(2022年1期)2022-02-28
少年文艺(1953)(2021年2期)2021-03-17
西南交通大学学报(2018年5期)2018-11-08
长江文艺·好小说(2018年2期)2018-02-11
民间文学(2017年12期)2018-01-22
北方文学(2017年9期)2017-07-31
现代交际(2017年13期)2017-07-18
北方文学·下旬(2017年3期)2017-04-20
成才之路(2016年18期)2016-07-08
科技视界(2016年5期)2016-02-22
