
一种面向查询的多文档摘要方法
2010-06-05 06:31蔡东风
中文信息学报 2010年6期
叶 娜,蔡东风
(沈阳航空航天大学 知识工程研究中心, 辽宁 沈阳 110136)
1 引言
多文档自动摘要(Multi-Document Summarization)的任务是识别多篇同主题文档中的有用信息,压缩其中的冗余信息,生成一篇简短、流畅的摘要。该技术可以帮助用户快速形成对特定主题的全面了解,提高获取信息的效率。
多文档摘要可分为一般性摘要(General Summarization)和面向查询的摘要(Query-Focused Summarization)。与一般性摘要不同,面向查询的多文档摘要允许用户提交当前主题下自己最为关心的问题,并根据问题的要求生成摘要,为用户带来更大的便利。
在面向查询的多文档摘要领域,研究人员已经做了许多工作。Goldstein[1]将文档切分为基本片段,过滤掉与查询相关度低的片段,利用MMR(Maximum Marginal Relevance)技术消除信息冗余,生成摘要。Pingali[2]设计了基于句子与查询的相关度和无关度两方面因素的打分函数进行内容选择。NeATS系统[3]利用WordNet[4]进行查询扩展,并根据文档句里的基本要素[5](Basic Elements)数目对句子排序,作为选择摘要内容的依据,并使用简化的MMR技术来消除冗余。GISTexter系统[6]用句法分析器对查询进行分解,将分解后的查询送入文档集检索,识别出相关的句子,并对句子进行聚类,从每个簇选择文本以消除冗余。Filippova[7]利用相关网页资源对查询进行扩展,过滤掉与查询匹配度低的句子,并依据新颖度(Novelty)对余下的句子进行排序。
从上述研究现状来看,目前面向查询的多文档摘要技术存在两个问题。第一,为了保证所生成的摘要与查询密切相关,现有方法通常选取与查询之间相似度较高的句子加入摘要。但是这种策略容易造成摘要句之间的内容重复,影响摘要的全面性。虽然一些研究人员采用了冗余消除技术[1,3,6]来提高摘要的覆盖率,但仍然无法很好地解决这个问题。实际上,与查询的相关程度只是影响内容选择的一个因素,除此之外,还应该从整个文档集的角度出发,尽量全面地选择信息。第二,在计算文档句与查询的相关度时,仅使用原始查询难以准确地描述用户的隐含意图,需进行查询扩展。而现有方法多依赖语义词典[3,6]和大规模语料库[7]等外部知识和资源,来识别词语之间的深层语义关系,在一定程度上受限于具体领域。
针对以上问题,本文提出一种基于主题分析的面向查询的多文档摘要方法。其基本思想是,同一主题下的文档集包含多个子主题,分别论述主题的不同侧面。子主题信息将为摘要提供有价值的线索。文献[8-10]曾提出基于子主题的多文档摘要方法,但这些算法适用于一般性摘要任务,而本文的研究重点是面向查询的摘要。
本文利用主题分析技术,识别出子主题,并综合考虑子主题与查询的相关度以及子主题在当前主题下的重要度两方面因素,对子主题进行打分排序,从排序靠前的子主题中选取句子形成摘要,使得摘要在符合查询要求的前提下,覆盖更多的子主题,更全面地反映文档集的主要内容。另外,本文认为,词语在不同子主题下的共现越频繁,其语义相关性越强。通过选取与查询词的子主题分布最为相似的词语,可以在不依赖外部语义资源和知识的情况下,对查询进行扩展。在DUC2006评测语料上的实验结果表明,与Baseline系统相比,本系统取得了更高的ROUGE评价值,基于子主题的查询扩展方法则进一步提高了摘要的质量。
2 面向查询的多文档摘要方法
2.1 总体流程
图1为本文提出的SEG_SUM摘要方法的系统流程图。可以看出,系统主要分为主题分析、查询扩展、子主题筛选排序和摘要生成等阶段。
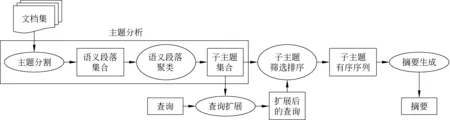
图1 SEG_SUM摘要系统流程图
2.2 主题分析
本文先对文档进行了预处理,包括去除html标记、分句、禁用词过滤和词根还原等。为了识别当前主题下的子主题,对目标文档集进行了主题分析,包括主题分割和语义段落聚类两个步骤。
1) 主题分割
主题分割是一项较为成熟的技术,其任务是自动识别出一篇文本内部不同子主题的边界,并将其线性分割开来,形成多个语义段落,其中相邻的语义段落论述不同的子主题。目前方法[11-13]主要是利用一些语言学线索,如新词出现、重现特性、命名实体和代词使用、线索短语等来判断文本的主题连贯性,从而识别子主题边界。本文使用C99算法[12]进行主题分割。该算法不需外部资源,仅利用文档内部的词汇重现信息,分割效果较好,并且可以自动确定语义段落数目。
2) 语义段落聚类
对文档集内每篇文档进行主题分割后,需要对全部语义段落进行聚类,得到子主题集合。本文采用自底向上的聚类方法,其基本过程如下:
设语义段落集合Ω= {S1,S2, …,Sn}
STEP1:计算n个语义段落两两之间的相似度Sim(Si,Sj),记为初始相似度矩阵。
STEP2:初始构造n个簇,每个语义段落自成一簇。
STEP3:寻找相似度矩阵中的最小元素,合并相似度最小的两簇形成一个新语义段落簇。
STEP4:计算新簇与当前各簇的相似度,更新相似度矩阵。若矩阵中的最大值高于阈值threshold,则跳至步骤3,否则跳至步骤5。
STEP5:输出聚类结果,即子主题集合Φ={T1,T2, …,TN}。
在聚类过程中,涉及到两个相似度计算过程,一是语义段落之间的相似度,二是语义段落簇之间的相似度。语义段落之间的相似度通过向量余弦来计算。语义段落簇之间的相似度计算方法是,将两个簇内语义段落之间的最小相似度作为两个簇的相似度。
假设两个语义段落词频向量分别为x=(x1,x2,…,xn) 和y=(y1,y2,…,yn),则其相似度为:
(1)
假设两个语义段落簇分别为Ti={Si1,Si2, …,Sin} 和Tj={Sj1,Sj2, …,Sjn},则其相似度为:
(2)
2.3 查询扩展
首先识别出原始查询中的关键词,将查询表示为关键词集合Q={w1,w2, …,wt}。
为了进行查询扩展,需要找到与查询关键词语义最为相关的词语。本文认为,词语的主题相关性可以反映其语义相关性。如果两个词wi和wj同时出现于子主题T内,那么这两个词具有一定的主题相关性,也就是可以反映同一个子主题的内容,说明它们在一定程度上语义相关。两个词共现的子主题越多,即在子主题之间的分布越相似,表示它们的语义相关性越强。
本文将词语表示为子主题向量w=(t1,t2, …,tN)。其中如果词w在子主题Ti中出现过,那么ti取值为1,否则取值为0。通过向量余弦来计算两个词之间的主题相关度。
假设词x和词y的子主题向量分别为x=(x1,x2,…,xN) 和y=(y1,y2,…,yN),则它们之间的主题相关度为:
(3)
对于每个查询关键词wi,选取文档集里与之主题相关度最大的词来进行扩展,形成扩展词集合Q′,则扩展后的查询Qs=Q∪Q′。
2.4 子主题筛选排序
面向查询的多文档摘要系统中,为保证摘要内容与查询密切相关,需要对子主题进行筛选,过滤掉与查询无关或相关度低的子主题。同时由于摘要长度的限制,摘要应尽量覆盖当前主题下的重要子主题,因此还需根据重要度对相关子主题进行排序。
1) 子主题筛选
本文过滤掉与查询之间相关度为0的子主题,得到与查询相关的子主题。相关度计算方法是,将查询与子主题内每个句子之间的最大相似度值作为查询与子主题的相关度。其中查询与子主题句之间的相似度通过向量余弦来计算。
假设查询和子主题句的词频向量分别为q=(q1,q2,…,qn) 和s=(s1,s2,…,sn),则它们之间的相似度为:
(4)
假设子主题T有m个句子,则子主题可表示为句子集合T={t1,t2,…,tm},查询q与子主题T之间的相关度为:
(5)
2) 子主题排序
本文认为,子主题的重要程度可以根据其大小来度量。包含句子个数较多的子主题由于在原始文本中所占的篇幅比例较大,可认为是描述了当前主题下较为重要的侧面,应优先予以涵盖。因此本文将子主题所包含的句子数目m作为子主题的重要度,对相关子主题进行排序,选择前K个子主题,用于最终的摘要生成。
2.5 摘要生成
至此得到了与查询相关的K个重要的子主题有序序列。从第一个子主题开始,循环选取其中与查询相似度最大的句子作为摘要句,连接起来形成摘要,直到摘要长度达到最大长度限制为止。其中重要度较高的子主题可能贡献出多个摘要句,这是符合实际情况的,即对于较重要的主题侧面,摘要应涵盖其中的更多内容。
3 实验
3.1 实验设置
本文使用DUC2006评测中用于面向查询的多文档摘要任务的语料来评价摘要系统的性能。该语料共包含50个测试文档集,均为英文语料。语料中的文章来自美联社(Associated Press)、《纽约时报》(New York Times)和新华美通(Xinhua Newswire)的新闻报道。每个文档集里面有25篇文档和一个topic statement,其中指出了文档集的主题和需要回答的问题。每个文档集由4名评委分别做出人工摘要,作为标准答案。系统提交的摘要规定为250个词。
实验使用DUC2006会议提供的ROUGE-1.5.5工具包[14]对摘要进行评价。该工具包用多个评价指标实现了对摘要的自动评价。评价指标包括:ROUGE-1、ROUGE-2、ROUGE-3、ROUGE-4、ROUGE-L、ROUGE-W、ROUGE-S和ROUGE-SU。对于多文档摘要的评价来讲,ROUGE-1、ROUGE-2、ROUGE-S4、ROUGE-SU4等几个指标的评价效果较好。
3.3 实验结果及分析
为了进行对比实验,本文构建了一个Baseline系统,系统的设计遵循面向查询的多文档摘要系统的一般框架。首先,利用2.2小节的公式(1)计算文档集里的每个句子与查询的相似度,据此对句子进行排序,选取相似度较高的句子,作为摘要的候选句;然后,为了减少摘要中的冗余,使用了一个简化的MMR方法,即计算句子与当前摘要的重复度,若重复度低于阈值t,则将句子加入摘要,直至达到最大字数为止。
本文在DUC2006评测语料上对Baseline系统、未进行查询扩展的SEG_SUM_NE系统,以及SEG_SUM系统的摘要结果进行了对比。
SEG_SUM_NE和SEG_SUM系统有两个参数,即聚类的阈值threshold和子主题的个数K。Baseline系统也有一个参数,即摘要重复度的阈值t。参数的选择对于摘要系统的性能有一定影响。为得到系统的最优参数,本文进行了5重交叉检验。将全部测试语料随机分为5部分,每次选取4部分作为训练语料,余下的1部分作为测试语料。表1为进行5重交叉检验后选择的各个系统的最优参数值。
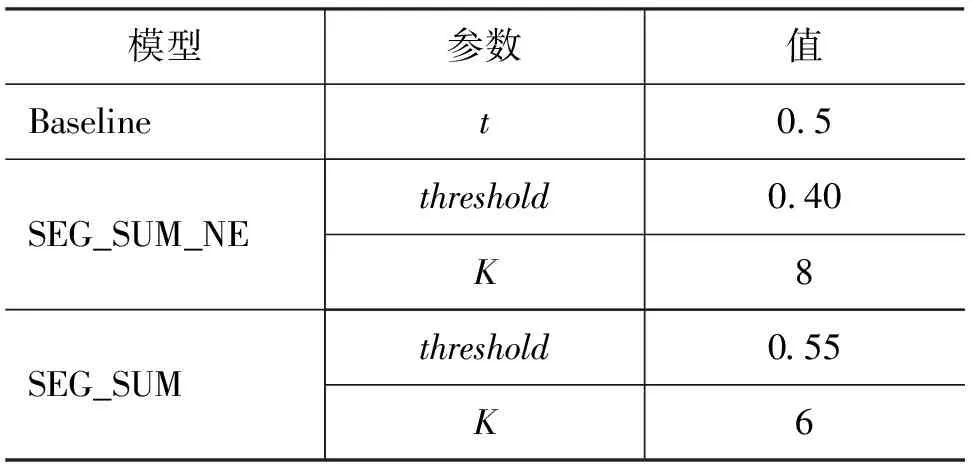
表1 交叉检验估计出的系统参数值
表2给出了各个摘要系统的对比实验结果。

表2 与Baseline系统的对比实验结果
对比实验结果表明,与baseline系统相比,基于主题分析的SEG_SUM系统取得了更好的评价结果,ROUGE-1、ROUGE-2、ROUGE-S4和ROUGE-SU4召回率分别提高了9.2%、18.7%、16.0%和15.8%。
从表2中还可以看出,进行查询扩展后,生成的摘要质量有所提高,ROUGE-1、ROUGE-2、ROUGE-S4和ROUGE-SU4召回率与未扩展时相比,分别提高了2.3%、7.3%、5.3%和4.9%。这表明基于子主题分布的查询扩展方法是有效的。词语之间的子主题相关度能够从一定程度上反映其语义相关度。
通过分析SEG_SUM系统和Baseline系统生成的摘要,我们发现,前者所涉及的方面较广,涵盖了文档集内与查询相关的多个事件或论点。而Baseline系统主要根据句子与查询的相似度来生成摘要,并不考虑摘要中的子主题分布情况,经常造成大量摘要句来自同一子主题的现象,虽然Baseline系统通过计算文本重复度,尽量防止加入内容重复的摘要句,从一定程度上缓解了这个问题,但仍难以保证摘要中信息的全面性。
以评测语料中的D0603C文档集为例,该文档集的主题和查询描述如图2所示。

图2 D0603C评测文档集的主题和查询描述
对于上述文档集,DUC提供的标准摘要的内容涉及湿地对于生态环境的重要作用、湿地受到威胁和破坏的原因、湿地的衰竭现状、保护湿地的拉姆萨尔公约、世界各国(包括乌干达、中国、美国等)为保护和管理湿地采取的措施、湿地保护受到的阻碍等多个方面。可见人工书写的摘要涵盖的信息极为广泛,内容丰富多样。
而Baseline系统生成的摘要中,有3个句子都是关于中国保护湿地的信息,可以归为同一个子主题。该子主题占据了摘要中将近一半的篇幅。来自相同子主题的句子多次出现,一方面增加了摘要的冗余度,另一方面使得摘要不得不丢弃了其余的重要信息,降低了摘要的覆盖度。实际上,Baseline系统主要通过句子与查询的相关度来提取摘要,虽然系统也考虑了降低摘要句之间的重复度,但实验结果表明,这个问题仍无法很好地解决。
在SEG_SUM系统中,主题分析模块将中国保护湿地的相关信息合并为一个子主题,从该子主题内仅提取1个代表句,同时兼顾其余重要子主题,生成了冗余度低、覆盖度高的摘要,取得了更好的性能。
本文也与系统DUC2006参赛系统[15]的评测性能进行了比较。DUC2006评测还提供了一个Baseline系统。其实现方法是从最新的文档里抽取前250个词作为摘要。实验也引用了该系统的性能作为对比。DUC2006采用ROUGE-2和ROUGE-SU4的召回率作为主要评价指标。

表3 与DUC参赛系统的对比实验结果
与DUC2006参赛系统相比,SEG_SUM系统的性能高于参赛系统的总体平均性能,其中ROUGE-2召回率高出7.6%,ROUGE-SU4召回率高出0.5%。但是,大部分参赛系统都利用了语言工具、外部语料和人工构造的知识库等资源的帮助,以实现对文档内容的深层理解。而SEG_SUM系统仅对文档进行浅层分析,利用词汇分布和文档结构特点进行主题分析,进而根据子主题的词汇使用和大小等表层信息,识别出与查询相关的重要子主题,生成摘要。系统不依赖于任何外部资源,是一种独立于具体领域的方法。
4 结论
本文提出了一种面向查询的多文档摘要方法。该方法利用主题分析技术所提供的子主题信息,综合考虑子主题与查询的相关度及其在当前主题下的重要度,对子主题进行筛选和排序,并从中分别选取代表句生成摘要。由于涵盖了与查询相关的多个重要子主题,因此摘要在符合查询要求的前提下,更全面地覆盖了当前主题下的重要信息。本文还利用词语在子主题之间的分布情况,提出了不依赖任何外部语义资源的查询扩展方法。在DUC2006评测语料上进行的对比实验结果表明,查询扩展是有效的,同时与baseline系统相比,SEG_SUM系统取得了更好的摘要性能。
在未来的工作中,我们将考虑对摘要句进行修剪,削除其中的修饰性成分,以进一步提高摘要的覆盖率。语义分析、指代消解和语言生成技术也将进一步改善摘要质量。
[1] Jade Goldstein, Mark Kantrowitz, Vibhu Mittal, et al. Summarizing Text Documents:Sentence Selection and Evaluation Metrics[C]//Proceedings of SIGIR-99. Berkeley, CA. 1999:121-128.
[2] Prasad Pingali, Rahul K and Vasudeva Varma. IIIT Hyderabad at DUC 2007[C]//Proceedings of DUC 2007. 2007.
[3] Liang Zhou, Chin-Yew Lin, and Eduard Hovy. A BE-based Multi-document Summarizer with Query Interpretation[C]//Proceedings of DUC 2005. B.C. Canada. 2005.
[4] G.A. Miller. WordNet:A Lexical Databases for English. Communications of the ACM[J]. New York. 1995:39-41.
[5] Eduard Hovy, Chin-Yew Lin, Junichi Fukumoto. Automated Summarization Evaluation With Basic Elements[C]//Proceedings of the 5th International Conference on Language Resources and Evaluation. 2006.
[6] Finley Lacatusu, Andrew Hickl. LCC’s GISTexter at DUC 2006:Multi-Strategy Multi-Document Summarization[C]//Proceedings of DUC 2006. 2006.
[7] Katja Filippova, Mihai Surdeanu, Massimiliano Ciaramita, et al. Company-Oriented Extractive Summarization of Financial News[C]//Proceedings of the 12th Conference of the European Chapter of the ACL, Athens, Greece. 2009:246-254.
[8] 秦兵, 刘挺, 陈尚林,等. 多文档文摘中句子优化选择方法研究[J].计算机研究与发展, 2006, 43(6):1129-1134.
[9] 郑义, 黄萱菁, 吴立德. 文本自动综述系统的研究与实现[J]. 计算机研究与发展, 2003, 40(11):1606-1611.
[10] Kathleen R. McKeown, Judith L. Klavans, Vasileios Hatzivassiloglou, et al. Towards multi-document summarization by reformulation:Progress and prospects[C]//Proceedings of the 17th National Conference on Artificial Intelligence. 1999.
[11] Olivier Ferret. Finding document topics for improving topic segmentation[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. Prague, Czech Republic. 2007:480-487.
[12] Freddy Y. Y. Choi. Advances in domain independent linear text segmentation[C]//Proceedings of North American chapter of the Association for Computational Linguistics annual meeting. Seattle. 2000.
[13] Fragkou Pavlina, Petridis Vassilios, Kehagias Athanasios. A Dynamic Programming Algorithm for Linear Text Segmentation[J]. Journal of Intelligent Information Systems. 2004, 23(2):179-197.
[14] Chin-Yew Lin. Looking for a few good metrics:ROUGE and its evaluation[C]//Proceedings of NTCIR Workshop. Tokyo, Japan. 2004.
[15] Hoa Trang Dang. Overview of DUC 2006[C]//Proceedings of DUC 2006. 2006
